python统计分析——透视表
参考资料:用Python动手学统计学
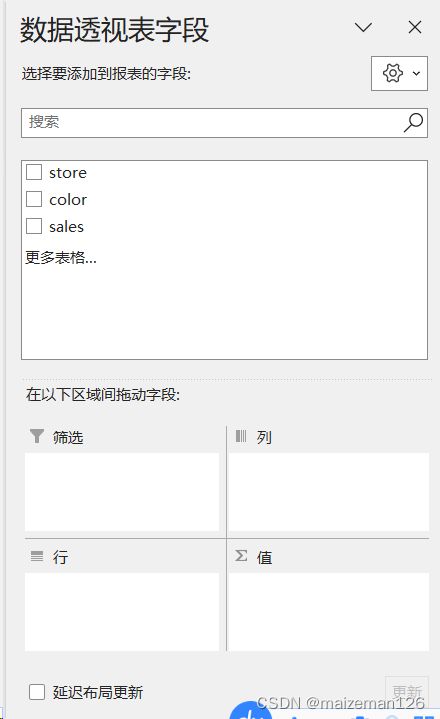
pandas库的pivot_table函数相当于excel的透视表功能。此图为excel数据透视表字段设置窗口,下面将参照excel数据透视表相关设置图片学习pivot_table函数:
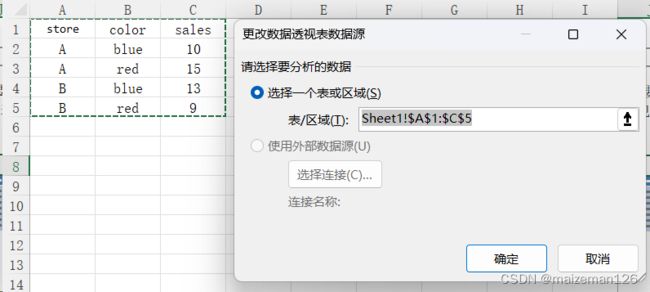
本次使用的数据集内容如下:
import pandas as pd
data_set=pd.DataFrame({"store":["A","A","B","B"],
"color":['blue','red','blue','red'],
"sales":[10,15,13,9]
})pivot_table参数介绍,
pivot_table(data, values, index, columns, aggfunc, fill_value, margins, dropna, margins_name, observed, sort)
1、data
data为数据透视表的数据源,要求是DataFrame结构。相当于excel中要进行数据透视的区域:
2、values、index、columns
values相当于excel透视表中值字段设置,index为相当于行字段设置,columns相当于列字段设置。

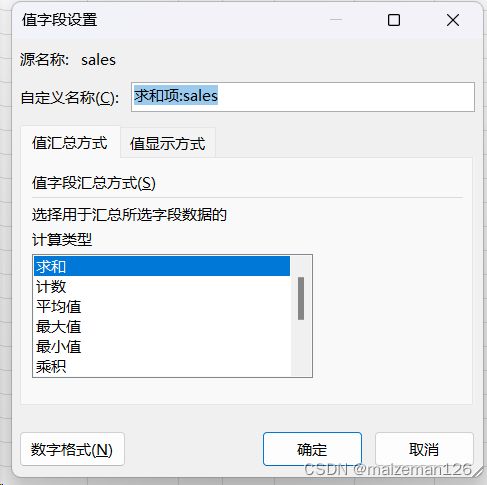
3、aggfunc
aggfunc参数设置的是对值字段的汇总统计,相当于excel中的值字段设置对话框。pandas中默认是均值,而excel默认是求和。
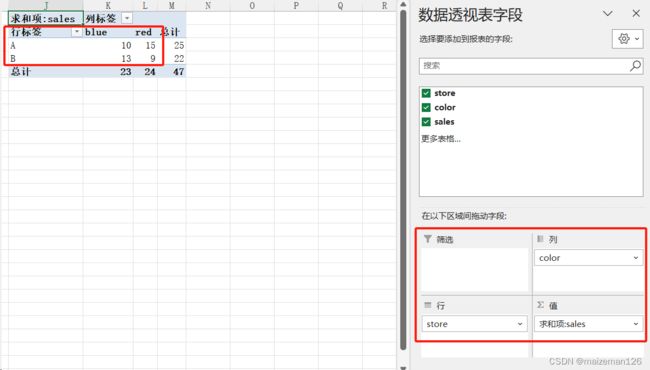
将数据store设置为行字段,color设置为列字段,sales设置为值字段,aggfunc设置为sum,代码如下:
pd.pivot_table(data_set,index='store',columns='color',values='sales',aggfunc='sum')结果为:

相对于excel下图红框内的部分
4、margins、margins_name
margins相当于excel中对行列进行汇总,但只能设置为True或False,因此只能对行列整体进行汇总,而不能单独对行或列进行汇总。
margins_name是汇总列或汇总行的名称,默认名称为“All”。

将数据store设置为行字段,color设置为列字段,sales设置为值字段,aggfunc设置为sum,margins设置为True,代码如下:
pd.pivot_table(data_set,index='store',columns='color',values='sales',aggfunc='sum',margins=True)结果为:

margins相当于excel下图红框内的部分

设置margins_name代码如下:
pd.pivot_table(data_set,index='store',columns='color',values='sales',aggfunc='sum',margins=True,margins_name="求和")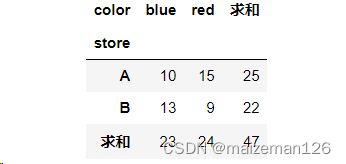
5、fill_value
当透视表结果中出现缺失值时,此参数用于设置填充值。若fill_value不设置,则默认显示为NaN。
import pandas as pd
import numpy as np
df = pd.DataFrame({"A": ["foo", "foo", "foo", "foo", "foo",
"bar", "bar", "bar", "bar"],
"B": ["one", "one", "one", "two", "two",
"one", "one", "two", "two"],
"C": ["small", "large", "large", "small",
"small", "large", "small", "small",
"large"],
"D": [1, 2, 2, 3, 3, 4, 5, 6, 7],
"E": [2, 4, 5, 5, 6, 6, 8, 9, 9]})示例演示如下,当不设置fill_values时:
pd.pivot_table(df,values="D",index=["A","B"],columns='C',aggfunc='sum')
当设置fill_values=0时,显示如下:
pd.pivot_table(df,values="D",index=["A","B"],columns='C',aggfunc='sum',fill_value=0)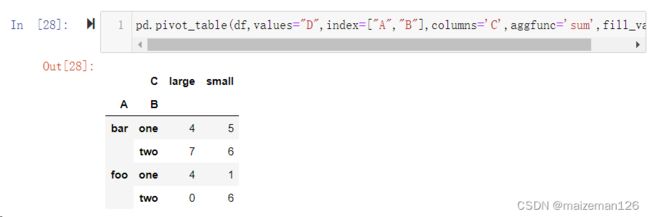
相当于excel透视表选项的红框中的设置。

6、dropna
当margins设置为True时,dropna用于对空列数据汇总的设置,默认为True。
df = pd.DataFrame({"A": ["foo", "foo", "foo", "foo", "foo",
"bar", "bar", "bar", "bar"],
"B": ["one", "one", "one", "two", "two",
"one", "one", "two", "two"],
"C": ["small", "large", "large", "small",
"small", "large", "small", "small",
"large"],
"D": [1, 2, 2, 3, np.nan, 4, 5, 6, 7],
"E": [2, 4, 5, 5, 6, 6, 8, 9, 9],
"F": [np.nan, np.nan, np.nan, np.nan,
np.nan, np.nan, np.nan, np.nan, np.nan]
})
当margins和dropna同为Ture时,代码和显示效果如下:
pd.pivot_table(df,values=["D","F"],index=["A","B"],columns='C',aggfunc='sum',margins=True,dropna=True)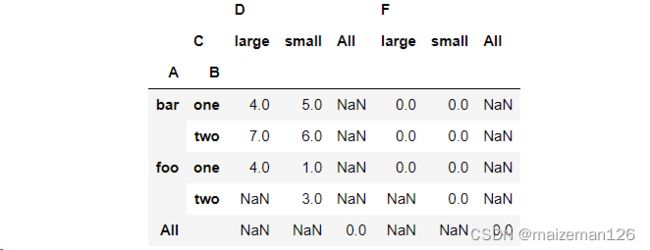
当margins为True,dropna为False时,显示效果如下:
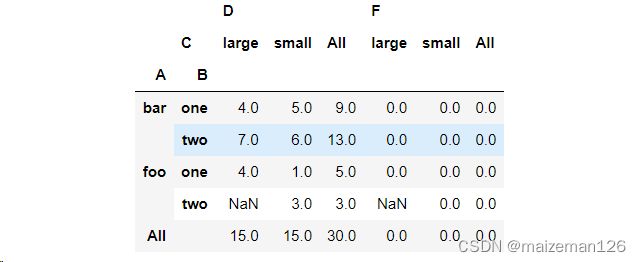
7、sort
默认为True,用于设置是否需要对数据进行排序,用于对透视表字段中包含的分类类型的排序。
8、observed
不常用,待遇到相关资料时及时补充,或待有缘人补充。