PyTorch中常用的工具(4)Visdom
文章目录
- 前言
-
- 3.2 Visdom
前言
在训练神经网络的过程中需要用到很多的工具,最重要的是数据处理、可视化和GPU加速。本章主要介绍PyTorch在这些方面常用的工具模块,合理使用这些工具可以极大地提高编程效率。
由于内容较多,本文分成了五篇文章(1)数据处理(2)预训练模型(3)TensorBoard(4)Visdom(5)CUDA与小结。
整体结构如下:
- 1 数据处理
- 1.1 Dataset
- 1.2 DataLoader
- 2 预训练模型
- 3 可视化工具
- 3.1 TensorBoard
- 3.2 Visdom
- 4 使用GPU加速:CUDA
- 5 小结
全文链接:
- PyTorch中常用的工具(1)数据处理
- PyTorch常用工具(2)预训练模型
- PyTorch中常用的工具(3)TensorBoard
- PyTorch中常用的工具(4)Visdom
- PyTorch中常用的工具(5)使用GPU加速:CUDA
3.2 Visdom
Visdom是Facebook专门为PyTorch开发的一款可视化工具,开源于2017年3月。Visdom十分轻量级,支持非常丰富的功能,可以胜任大多数的科学运算可视化任务,它的可视化界面如下图所示。
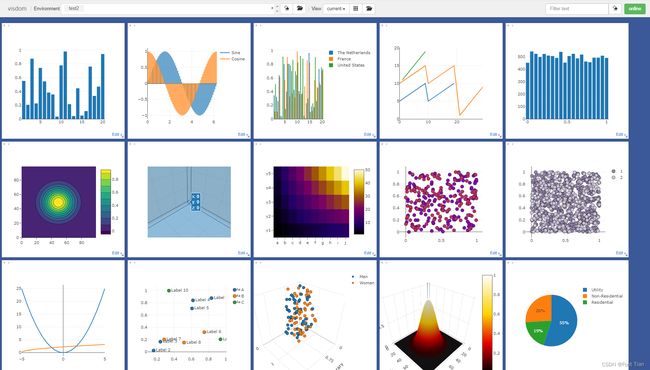
Visdom可以创造、组织和共享多种数据的可视化,包括数值、图像、文本,甚至是视频,同时支持PyTorch、Torch以及NumPy。用户可以通过编程组织可视化空间,或者通过用户接口为数据打造仪表板,以此检查实验结果或调试代码。
Visdom中有以下两个重要概念。
-
env:环境。不同环境的可视化结果相互隔离,互不影响,在使用时如果不指定env,则默认使用
main。不同用户、不同程序一般使用不同的env。 -
pane:窗格。窗格用于可视化图像、数值或打印文本等,它可以拖动、缩放、保存和关闭。一个程序可以使用同一个env中的不同pane,每个pane可视化或记录不同信息。
通过命令pip install visdom即可完成Visdom的安装,安装完成后,通过python -m visdom.server命令启动Visdom服务,或者通过nohup python -m visdom.server &命令将服务放至后台运行。Visdom服务是一个Web Server服务,默认绑定8097端口,客户端与服务器间通过tornado进行非阻塞交互。
使用Visdom时需要注意以下两点。
-
需要手动指定保存env,可在web界面点击save按钮或在程序中调用save方法,否则Visdom服务重启后,env等信息会丢失。
-
客户端与服务器之间的交互采用tornado异步框架,可视化操作不会阻塞当前程序,网络异常也不会导致程序退出。
Visdom以Plotly为基础,它支持丰富的可视化操作,下面举例说明一些最常用的操作:
%%sh
# 启动visdom服务器
nohup python -m visdom.server &
In: import torch as t
import visdom
# 新建一个连接客户端
# 指定env = u'test1',默认端口为8097,host是‘localhost'
vis = visdom.Visdom(env=u'test1', use_incoming_socket=False)
x = t.arange(0, 30, 0.01)
y = t.sin(x)
vis.line(X=x, Y=y, win='sinx', opts={'title': 'y=sin(x)'})
Out: 'sinx'
输出的结果如下图所示。

下面逐一分析这几行代码。
-
vis = visdom.Visdom(env=u'test1'),用于构建一个客户端。客户端除了指定env,还可以指定host、port等参数。 -
vis作为一个客户端对象,可以使用以下常见的画图函数。
- line:类似MATLAB中的
plot操作,用于记录某些标量的变化,如损失、准确率等。 - image:可视化图片,可以是输入的图片,也可以是程序生成的图片,还可以是卷积核的信息。
- text:用于记录日志等文字信息,支持HTML格式。
- histgram:可视化分布,主要是查看数据、参数的分布。
- scatter:绘制散点图。
- bar:绘制柱状图。
- pie:绘制饼状图。
- 更多操作可以参考Visdom的GitHub主页。
- line:类似MATLAB中的
本小节主要介绍深度学习中常见的line、image和text操作。
Visdom同时支持PyTorch的Tensor和NumPy的ndarray两种数据结构,但不支持Python的int、float等数据类型,因此每次传入数据时需要将数据转成ndarray或Tensor类型。上述操作的参数一般不同,但以下两个参数是绝大多数操作都具备的。
-
win:用于指定pane的名字,如果不指定,那么Visdom将自动分配一个新的pane。如果两次操作指定的win名字一样,那么新的操作会覆盖当前pane的内容,因此建议每次操作都重新指定win。
-
opts:用来可视化配置,接收一个字典,常见的option包括
title、xlabel、ylabel、width等,主要用于设置pane的显示格式。
在训练网络的过程中,例如损失函数值、准确率等数值不是一成不变的,为了避免覆盖之前pane的内容,需要指定参数update='append'。除了使用update参数,还可以使用vis.updateTrace方法更新图。updateTrace不仅能在指定pane上新增一个和已有数据相互独立的trace,还能像update='append'那样在同一条trace上追加数据,下面举例说明:
In: # append 追加数据
for ii in range(0, 10):
# y = x
x = t.Tensor([ii])
y = x
vis.line(X=x, Y=y, win='polynomial', update='append' if ii > 0 else None)
# updateTrace 新增一条线
x = t.arange(0, 9, 0.1)
y = (x ** 2) / 9
vis.line(X=x, Y=y, win='polynomial', name='this is a new Trace', update='new')
Out: 'polynomial'
打开浏览器,输入http://localhost:8097,可以看到如图下图所示的结果。
append和updateTrace可视化效果
image的画图功能可以分为以下两类。
image接收一个二维或三维向量,形状为 H × W H\times W H×W(黑白图像)或 3 × H × W 3 \times H\times W 3×H×W(彩色图像)。images接收一个四维向量,形状为 N × C × H × W N\times C\times H\times W N×C×H×W,其中 C C C可以是1或3,分别代表黑白和彩色图像。images可以实现类似torchvision中make_grid的功能,将多张图片拼接在一起。images也可以接收一个二维或三维的向量,此时它所实现的功能与image一致。
In: # 可视化一个随机的黑白图片
vis.image(t.randn(64, 64).numpy())
# 可视化一张随机的彩色图片
vis.image(t.randn(3, 64, 64).numpy(), win='random2')
# 可视化36张随机的彩色图片,每一行6张
vis.images(t.randn(36, 3, 64, 64).numpy(), nrow=6, win='random3', opts={'title':'random_imgs'})
Out: 'random3'
images的可视化输出如下图所示。

vis.text用于可视化文本,它支持所有的HTML标签,同时也遵循着HTML的语法标准。例如,换行需使用\r\n无法实现换行,下面举例说明:
In: vis.text(u'''Validation
2021-04-18 20:09:00,399 - mmdet - INFO - Epoch(val) [21][160]
bbox_mAP: 0.8180, bbox_mAP_50: 0.9880, bbox_mAP_75: 0.9440, bbox_mAP_s: 0.1510,
bbox_mAP_m: 0.8390, bbox_mAP_l: 0.8040, bbox_mAP_copypaste: 0.818 0.988 0.944 0.151 0.839 0.804,
segm_mAP: 0.8180, segm_mAP_50: 0.9880, segm_mAP_75: 0.9570, segm_mAP_s: 0.2000, segm_mAP_m: 0.8250,
segm_mAP_l: 0.8120, segm_mAP_copypaste: 0.818 0.988 0.957 0.200 0.825 0.812''',
win='visdom',
opts={'title': u'validation' }
)
Out: 'visdom'

本小节主要介绍了深度学习中两种常见的可视化工具:TensorBoard和Visdom。合理地利用可视化工具便于记录与观察神经网络的中间层与网络整体的训练效果,从而帮助用户更好地对网络进行调整。