目标检测YOLO3笔记1
目录
目标检测实现效果:
目标检测的实现思路:
如何划分候选区?
基础知识:
YOLO3
基本思想:
思考与总结:
怎么产生候选区域?
怎么比较出正样本负样本?
怎么设置类别标签?
Anchor是固定的,模型怎么进行Anchor的调整,输出预测框?
算法预测
流程图:
网络结构:
思考与总结:
(NMS)非极大值抑制:
作用:
怎么实现?怎么判断多个预测框预测同一个物体?
Iou:
NMS:
(学习资料:飞桨AI Studio星河社区 - 人工智能学习与实训社区 (baidu.com))
目标检测实现效果:
准确框选出目标所在的位置。

目标检测的实现思路:
依照某种方式生成一定数量和大小的候选框,候选框框选的区域为候选框,把每个候选区看成一张图像,对齐进行特征提取和分类,找到它所属的类别。相当于对每个候选区域做图像分类。模型的输出类似格式为【L,P,x1,y1,x2,y2】,L表示类别标签,P表示物体为L类的概率,x1,y1,x2,y2表示候选框的位置。

如何划分候选区?
1.穷举法,耗时太长;
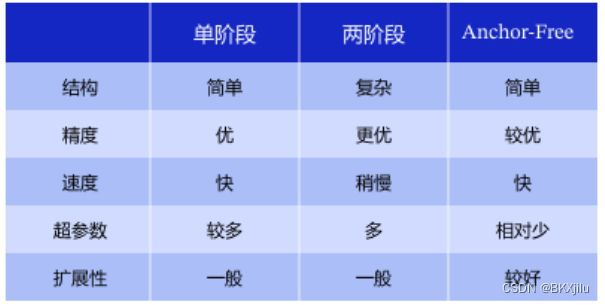
2.Anchor-Base:
Anchor表示锚框,是候选框的集合。
相较单阶段检测,两阶段模型通常具有较优的精度,但是预测速度较慢。
2.1两阶段检测:
两阶段指先生成Anchor再对候选区域进行分类。
2.2单阶段检测
在生成Anchor时进行候选区域的检测。
3.Anchor-Free:
Anchor-Base方法需要考虑Anchor的数量和尺寸,网络的超参数会增加,模型学习较为困难;更换不同的数据集需要更换Anchor。
Anchor-Free方法通常使用预测目标的中心或角点,对目标进行预测,模型简单,但是精度较Anchor-Free较低。
基础知识:
边框表示方式:![]() ,
,![]() 表示左上角坐标,
表示左上角坐标,![]() 表示右下角坐标
表示右下角坐标
。在目标检测任务中,模型预测出的框,表示预测框,训练集中目标物体所在的边界框表示真实框。
YOLO3
Yolo3是Anchor-Base的单阶段检测算法。
基本思想:
1.依照一定规则生成一系列候选框,采用策略比较候选框和真实框的位置,将偏离大的设置为负样本,偏离小的设置为负样本。
2.获取正样本的位置,根据真实框获得正样本的标签;网络对正样本区域进行分类预测,得到模型的类别预测值和预测框,将类别预测值和预测框与类别标签和真实框比较,建立损失函数。
思考与总结:
怎么产生候选区域?
介绍其中一种生成Anchor的方法。
1.设置最小图片划分区域,如32x32,将图片进行划分:
2.以每个单位区域为中心点,设置三个Anchor框

怎么比较出正样本负样本?
比较正样本和负样本是一个分类问题。分类标准是IoU,IoU能反映两块区域的重叠程度。我们对每个Anchor和真实框计算Iou,设置阈值,如果超过阈值Anchor标签为1,反之为0.
IoU:表示交并比,图示如下
怎么设置类别标签?
训练集中物体类别可能是猫,狗,马等多种动物,怎么将文本标签转换成计算机能理解的形式?
使用one-hot向量来表示类别标签label。
比如有3个类别,真实框表示第一类的物体类别,则真是类别标签为(1,0,0).
Anchor是固定的,模型怎么进行Anchor的调整,输出预测框?
把Anchor看成基础,预测框是Anchor微调的结果,通过公式转换得到预测框的中心坐标和预测框的大小。例:
锚框Anchor的左上角坐标为Cx,Cy;中心坐标:![]() ,
,![]() ,尺寸为
,尺寸为
预测框Anchor中心坐标为![]() ,
,![]() ,尺寸为
,尺寸为![]()
![]() ,
,![]()
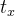 ,
,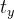 ,
, ,
,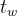 都是实数。
都是实数。
当预测框和真实框重合时:
根据Anchor,真实框的坐标和尺寸可以求出,,,的值
可以把t(,,,)当作网络预测值,将![]() (
(![]() ,
,![]() ,
,![]() ,
,![]() )为目标值,建立损失函数,通过网络的学习,使t接近
)为目标值,建立损失函数,通过网络的学习,使t接近![]() ,求出预测框的位置坐标和大小。
,求出预测框的位置坐标和大小。
(类似回归问题,回归方程y = wx+b,x在这里为t,y在这里为![]() )
)

算法预测
流程图:

网络结构:
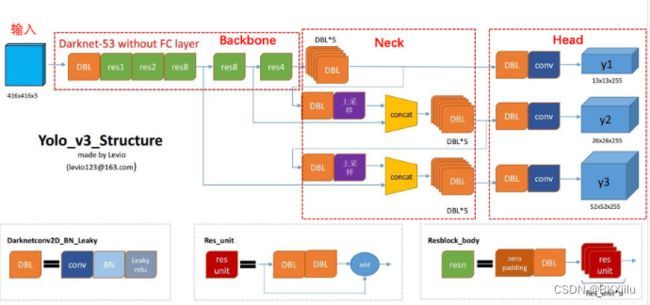
- Backbone:骨干网络,主要用于特征提取
输入图片,输出特征图C0,C1,C2
Darknet网络图如下,下图数据是按照输入为(1,3,256,256)计算的,C0[1,1024,8,8],C1[1,512,16,16],C2[1,256,32,32]

- Neck:在Backbone和Head之间提取不同阶段中特征图
基础知识提要:
特征图的stride:stride = 原图尺寸/特征图尺寸,C0为8x8,输入为256x256,C0的stride为32.
Neck实现方式如下:
输入三个特征图,输出三个特征图

- Head:检测头,用于预测目标的类别和位置
对每个预测框都得到一个概率数组:(P1,P2,,,Pc)c表示C个类别
对每个预测框都得到的信息:objectness(判断正负样本),(x1,y1,x2,y2)位置,概率数组
思考与总结:
(NMS)非极大值抑制:
作用:
去除冗余的预测框。
模型会产生多个预测框,它们可能都是预测同一个物体,如果输出格式为【L,P,x1,y1,x2,y2】,我们只要选择P最大的预测框即可。
怎么实现?怎么判断多个预测框预测同一个物体?
IoU能够反映两个区域的重合程度,设置IoU的阈值,计算预测框之间的IoU值,当IoU达到设置阈值时,认为预测框预测的是同一个物体。然后我们比较预测框的P值,去掉P值小的。
Iou:
# 计算IoU,矩形框的坐标形式为xyxy,这个函数会被保存在box_utils.py文件中
def box_iou_xyxy(box1, box2):
# 获取box1左上角和右下角的坐标
x1min, y1min, x1max, y1max = box1[0], box1[1], box1[2], box1[3]
# 计算box1的面积
s1 = (y1max - y1min + 1.) * (x1max - x1min + 1.)
# 获取box2左上角和右下角的坐标
x2min, y2min, x2max, y2max = box2[0], box2[1], box2[2], box2[3]
# 计算box2的面积
s2 = (y2max - y2min + 1.) * (x2max - x2min + 1.)
# 计算相交矩形框的坐标
xmin = np.maximum(x1min, x2min)
ymin = np.maximum(y1min, y2min)
xmax = np.minimum(x1max, x2max)
ymax = np.minimum(y1max, y2max)
# 计算相交矩形行的高度、宽度、面积
inter_h = np.maximum(ymax - ymin + 1., 0.)
inter_w = np.maximum(xmax - xmin + 1., 0.)
intersection = inter_h * inter_w
# 计算相并面积
union = s1 + s2 - intersection
# 计算交并比
iou = intersection / union
return iou
bbox1 = [100., 100., 200., 200.]
bbox2 = [120., 120., 220., 220.]
iou = box_iou_xyxy(bbox1, bbox2)
print('IoU is {}'.format(iou)) NMS:
输入:
bboxes:预测框的坐标,Nx4的数组,N表示预测框数量,4表示左下角和右下角的坐标;
score:表示预测框的P值,Nx1数组;
score_thresh:表示预测框P的阈值,比如设置P为0.1,则P为0.1的预测框直接删掉;
nums_thresh:表示IoU的阈值,比如设置为0.8,则nums_thresh大于0.8的预测框视为预测同一个物体
输出:
返回保留下来的预测框在bboxes数组的索引值。
# 非极大值抑制
def nms(bboxes, scores, score_thresh, nms_thresh):
"""
nms
"""
inds = np.argsort(scores)
inds = inds[::-1]
keep_inds = []
while(len(inds) > 0):
cur_ind = inds[0]
cur_score = scores[cur_ind]
# if score of the box is less than score_thresh, just drop it
if cur_score < score_thresh:
break
keep = True
for ind in keep_inds:
current_box = bboxes[cur_ind]
remain_box = bboxes[ind]
iou = box_iou_xyxy(current_box, remain_box)
if iou > nms_thresh:
keep = False
break
if keep:
keep_inds.append(cur_ind)
inds = inds[1:]
return np.array(keep_inds)