理解 MappedByteBuffer 及其实现类 DirectByteBuffer
MappedByteBuffer
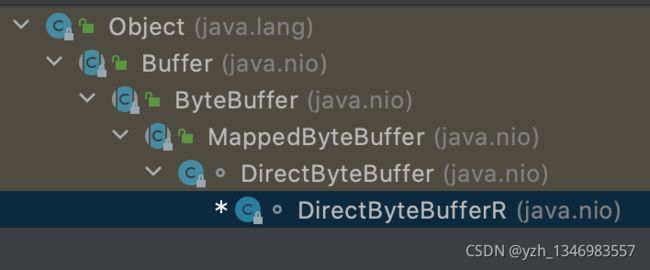
MappedByteBuffer 类结构图:
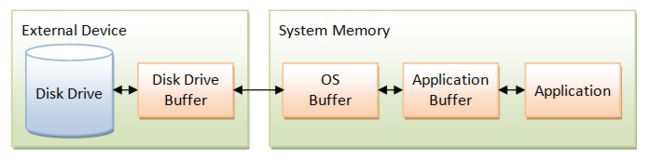
快:实现类direct buffer读写文件内容,是直接使用操作系统内核层的数据,没有JVM和系统之间的复制操作,即减少了一次cpu的数据copy,在一些场景下可带来极大性能提升,例如大文件的读取。
使用的虚拟内存:MappedByteBuffer 可以用它来在进程(或线程)间传递消息,基本上能达到和“共享内存页”相同的作用。
MappedByteBuffer通过FileChannel mmap()出来之后, MappedByteBuffer访问的是一块内存,跟原来的文件之间的同步是不确定的,这就需要看底层的os是什么时候刷新数据和请求数据了。
因为Java GC的缘故,当我们通过FileChannel写文件的时候,如果不是使用DirectBuffer,JDK会开辟一个DirectBuffer来缓存数据,以防止GC造成的数据移动,下面是JDK源码:
package sun.nio.ch;
public class IOUtil {
static int write(FileDescriptor fd, ByteBuffer src, long position,
NativeDispatcher nd)
throws IOException
{
if (src instanceof DirectBuffer)
return writeFromNativeBuffer(fd, src, position, nd);
// Substitute a native buffer
int pos = src.position();
int lim = src.limit();
assert (pos <= lim);
int rem = (pos <= lim ? lim - pos : 0);
ByteBuffer bb = Util.getTemporaryDirectBuffer(rem);
try {
bb.put(src);
bb.flip();
// Do not update src until we see how many bytes were written
src.position(pos);
int n = writeFromNativeBuffer(fd, bb, position, nd);
if (n > 0) {
// now update src
src.position(pos + n);
}
return n;
} finally {
Util.offerFirstTemporaryDirectBuffer(bb);
}
}
}MappedByteBuffer、FileChannel、DirectBuffer总结
1.FileChannel的写入和MapperByteBuffer的写入只能有一个在起作用。原因是他们各自为政,各自只能刷新自己的内容
2.mmap出来的MapperByteBuffer会作为page cache的一部分
3.FileChannel结合DirectBuffer会提高写入性能,避免了堆内存的一次拷贝
4.FileChannel写DirectBuffer之后,数据就到了PageCache里面,或者自己sync,或者依赖操作系统的刷新策略
5.FileChannel写DirectBuffer之后,数据就到了PageCache里面,就到了MapperByteBuffer里面,因为MapperByteBuffer被用作了文件的cache
以上参考:MappedByteBuffer的一点优化 | Lost
PageCache
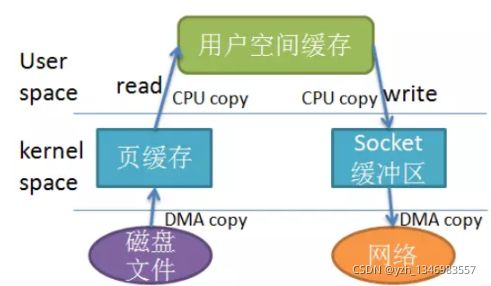
从写文件理解PageCache。它是用户内存和磁盘之间的一层缓存,而java的写都是到PageCache 便是完成认为逻辑落盘成功,后续操作系统会把它刷到磁盘文件上。
mmap
mmap基于 OS 的 mmap 的内存映射技术,通过 MMU 映射文件,将文件直接映射到用户态的内存地址,使得对文件的操作不再是 write/read,而转化为直接对内存地址的操作,使随机读写文件和读写内存相似的速度。
mmap 把文件映射到用户空间里的虚拟内存,省去了从内核缓冲区复制到用户空间的过程,文件的位置在虚拟内存中有了对应的地址,可以像操作内存一样操作这个文件,这样的文件读写少了数据从内核缓存到用户空间的拷贝,效率很高。
mmap 是直接把 MappedByteBuffer 中的数据写入到磁盘吗?
no,mappedByteBuffer 的 put 行为实际将数据写到了虚拟内存(可以近似理解成 PageCache,但不是),而虚拟内存是依赖于操作系统的定时刷盘的,但也可以手动通过 mappedByteBuffer.force() 接口来手动控制刷盘。
定时刷盘,是为了防止数据丢失,MMAP 和 FileChannel (sendFile)都有 force 方法。
MappedByteBuffer 便是MMAP的操作类。
FileChannel
FileChannel 为什么比普通 IO 要快呢?
FileChannel 只有在一次写入 4kb 的整数倍时,才能发挥出实际的性能,这得益于 FileChannel 采用了 ByteBuffer 这样的内存缓冲区,让我们可以非常精准的控制写盘的大小,这是普通 IO 无法实现的。磁盘的4K对齐。
FileChannel 是直接把 ByteBuffer 中的数据写入到磁盘吗?
NO,ByteBuffer 中的数据和磁盘中的数据还隔了一层,这一层便是 PageCache,是用户内存和磁盘之间的一层缓存。我们都知道磁盘 IO 和内存 IO 的速度可是相差了好几个数量级。我们可以认为 filechannel.write 写入 PageCache 便是完成了落盘操作,但实际上,操作系统最终帮我们完成了 PageCache 到磁盘的最终写入,理解了这个概念,你就应该能够理解 FileChannel 为什么提供了一个 force() 方法,用于通知操作系统进行及时的刷盘。
虚拟地址空间
传统的IO操作,是操作系统将磁盘中的文件读入到系统空间里面,然后再拷贝到用户空间中,供用户使用。
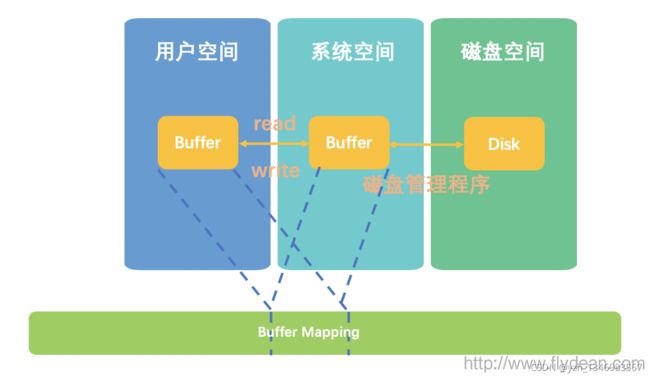
虚拟地址空间,单独划出一块内存区域,让系统空间和用户空间同时映射到同一块地址省略了拷贝的步骤。
这个被划出来的单独的内存区域叫做虚拟地址空间,而不同空间到虚拟地址的映射就叫做Buffer Map。 Java中是有一个专门的MappedByteBuffer来代表这种操作。
虚拟地址空间有两个好处:
第一个好处就是虚拟地址空间对于应用程序本身而言是独立的,从而保证了程序的互相隔离和程序中地址的确定性。比如说一个程序如果运行在虚拟地址空间中,那么它的空间地址是固定的,不管他运行多少次。如果直接使用内存地址,那么可能这次运行的时候内存地址可用,下次运行的时候内存地址不可用,就会导致潜在的程序出错。
第二个好处就是虚拟空间地址可以比真实的内存地址大,这个大其实是对内存的使用做了优化,比如说会把很少使用的内存写如磁盘,从而释放出更多的内存来做更有意义的事情,而之前存储到磁盘的数据,当真正需要的时候,再从磁盘中加载到内存中。
这样物理内存实际上可以看做虚拟空间地址的缓存。
MappedByteBuffer 抽象类,实现类:DirectByteBuffer、DirectByteBufferR(R 代表ReadOnly)。
可从FilChannel中调用map方法获得它的实例:
public abstract MappedByteBuffer map(MapMode mode,
long position, long size)
throws IOException;MapMode代表的是映射的模式,position表示是map开始的地址,size表示是ByteBuffer的大小。
MapMode
基本的MapMode:
FileChannel.MapMode.READ_ONLY 表示只读模式
FileChannel.MapMode.READ_WRITE 表示读写模式
FileChannel.MapMode.PRIVATE 表示copy-on-write模式,这个模式和READ_ONLY有点相似,它的操作是先对原数据进行拷贝,然后可以在拷贝之后的Buffer中进行读写。但是这个写入并不会影响原数据。可以看做是数据的本地拷贝,所以叫做Private。
Size
map方法中size的类型是long,在java中long能够表示的最大值是0x7fffffff,也就是2147483647字节,换算一下大概是2G。也就是说MappedByteBuffer的最大值是2G,一次最多只能map 2G的数据。
MappedByteBuffer来读数据:
public void readWithMap() throws IOException {
try (RandomAccessFile file = new RandomAccessFile(new File("src/main/resources/big.www.flydean.com"), "r"))
{
//get Channel
FileChannel fileChannel = file.getChannel();
//get mappedByteBuffer from fileChannel
MappedByteBuffer buffer = fileChannel.map(FileChannel.MapMode.READ_ONLY, 0, fileChannel.size());
// check buffer
log.info("is Loaded in physical memory: {}",buffer.isLoaded()); //只是一个提醒而不是guarantee
log.info("capacity {}",buffer.capacity());
//read the buffer
for (int i = 0; i < buffer.limit(); i++)
{
log.info("get {}", buffer.get());
}
}
}MappedByteBuffer来写数据的例子:
public void writeWithMap() throws IOException {
try (RandomAccessFile file = new RandomAccessFile(new File("src/main/resources/big.www.flydean.com"), "rw"))
{
//get Channel
FileChannel fileChannel = file.getChannel();
//get mappedByteBuffer from fileChannel
MappedByteBuffer buffer = fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, 4096 * 8 );
// check buffer
log.info("is Loaded in physical memory: {}",buffer.isLoaded()); //只是一个提醒而不是guarantee
log.info("capacity {}",buffer.capacity());
//write the content
buffer.put("www.flydean.com".getBytes());
}
}MappedByteBuffer是没有close方法的,即使它的FileChannel被close了,MappedByteBuffer仍然处于打开状态,只有JVM进行垃圾回收的时候(fullGC)才会被关闭。而这个时间是不确定的。
参考:小师妹学JavaIO之:MappedByteBuffer多大的文件我都装得下 - flydean - 博客园
MappedByteBuffer较之ByteBuffer新增的三个方法:
fore()缓冲区是READ_WRITE模式下,此方法对缓冲区内容的修改强行写入文件
load()将缓冲区的内容载入内存,并返回该缓冲区的引用
isLoaded()如果缓冲区的内容在物理内存中,则返回真,否则返回假
MappedByteBuffer也有不足,就是在数据量很小的时候,表现比较糟糕,那是因为direct buffer的初始化时间较长,所以建议大家只有在数据量较大的时候,再用MappedByteBuffer。
零拷贝
零拷贝两种方式分别是:mmap+write方式,sendfile方式;
所有现代操作系统都使用虚拟内存,使用虚拟的地址取代物理地址。
利用虚拟内存可以把内核空间地址和用户空间的地址映射到同一个虚拟地址,也即同一个物理地址,这样DMA就可以填充对内核和用户空间进程同时可见的缓冲区了。
mmap+write方式
使用mmap+write方式代替原来的read+write方式,mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系;这样就可以省掉原来内核read缓冲区copy数据到用户缓冲区,但是还是需要内核read缓冲区将数据copy到内核socket缓冲区,大致如下图所示:

sendfile方式
sendfile系统调用在内核版本2.1中被引入,目的是简化通过网络在两个通道之间进行的数据传输过程。sendfile系统调用的引入,不仅减少了数据复制,还减少了上下文切换的次数,大致如下图所示:

数据传送只发生在内核空间,所以减少了一次上下文切换;但是还是存在一次copy,能不能把这一次copy也省略掉,Linux2.4内核中做了改进,将Kernel buffer中对应的数据描述信息(内存地址,偏移量)记录到相应的socket缓冲区当中,这样连内核空间中的一次cpu copy也省掉了;
Java零拷贝
FileChannel 的 map()方法:大致就是通过native方法获取内存映射的地址,如果失败,手动gc再次映射;最后通过内存映射的地址实例化出MappedByteBuffer,MappedByteBuffer本身是一个抽象类,其实这里真正实例话出来的是DirectByteBuffer。
若经常需要从一个位置将文件传输到另外一个位置,FileChannel提供了transferTo()方法用来提高传输的效率。transferTo()允许将一个通道交叉连接到另一个通道,而不需要一个中间缓冲区来传递数据;这里不需要中间缓冲区有两层意思:第一层不需要用户空间缓冲区来拷贝内核缓冲区,另外一层两个通道都有自己的内核缓冲区,两个内核缓冲区也可以做到无需拷贝数据。
Netty零拷贝
netty提供了零拷贝的buffer,在传输数据时,最终处理的数据会需要对单个传输的报文,进行组合和拆分,Nio原生的ByteBuffer无法做到,netty通过提供的Composite(组合)和Slice(拆分)两种buffer来实现零拷贝;看下面一张图会比较清晰:

TCP层HTTP报文被分成了两个ChannelBuffer,这两个Buffer对我们上层的逻辑(HTTP处理)是没有意义的。但是两个ChannelBuffer被组合起来,就成为了一个有意义的HTTP报文,这个报文对应的ChannelBuffer,才是能称之为”Message”的东西,这里用到了一个词”Virtual Buffer”。
系统IO调用
首先来看一下一般的IO调用。在传统的文件IO操作中,我们都是调用操作系统提供的底层标准IO系统调用函数 read()、write() ,此时调用此函数的进程(在JAVA中即java进程)由当前的用户态切换到内核态,然后OS的内核代码负责将相应的文件数据读取到内核的IO缓冲区,然后再把数据从内核IO缓冲区拷贝到进程的私有地址空间中去,这样便完成了一次IO操作。如下图右半边所示。

注意两点:
OS的read函数会在内核IO缓冲区中预读取数据,减少磁盘IO操作(Step2)
Java的BufferedReader或BufferedInputStream的缓冲区的作用是减少系统调用(Step1)
内存映射文件
内存文件映射适用于对大文件的读写。虚拟地址空间有一块区域: “Memory mapped region for shared libraries” ,这段区域就是在内存映射文件的时候将某一段的虚拟地址和文件对象的某一部分建立起映射关系,此时并没有拷贝数据到内存中去,而是当进程代码第一次引用这段代码内的虚拟地址时,触发了缺页异常,这时候OS根据映射关系直接将文件的相关部分数据拷贝到进程的用户私有空间中去,如下图所示。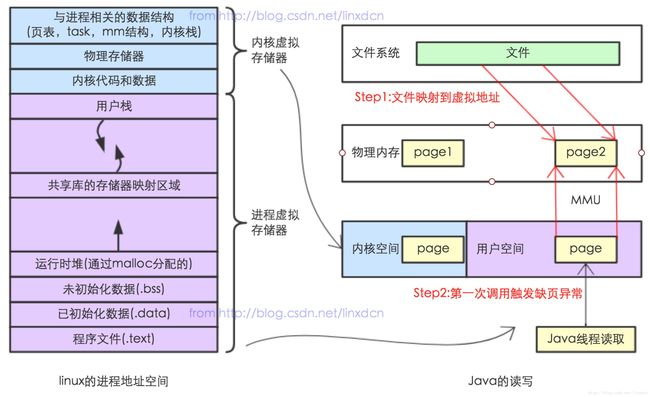
内存映射文件的效率比标准IO高的重要原因就是因为少了把数据拷贝到OS内核缓冲区这一步。
DirectByteBuffer继承了MappedByteBuffer,主要是实现了get byte 方法,即对内存的直接操作:
private long ix(int i) {
return address + ((long)i << 0);
}
public byte get() {
return ((unsafe.getByte(ix(nextGetIndex()))));
}
public byte get(int i) {
return ((unsafe.getByte(ix(checkIndex(i)))));
}由于已经通过map0()函数返回内存文件映射的address,这样就无需调用read或write方法对文件进行读写,通过address就能够操作文件。底层采用unsafe.getByte方法,通过(address + 偏移量)获取指定内存的数据。
总结
(1)直接内存DirectMemory的大小默认为 -Xmx 的JVM堆的最大值,但是并不受其限制,而是由JVM参数 MaxDirectMemorySize单独控制。
(2)直接内存不是分配在JVM堆中。并且直接内存不受 GC(新生代的Minor GC)影响,只有当执行老年代的 Full GC时候才会顺便回收直接内存!直接内存是通过存储在JVM堆中的DirectByteBuffer对象来引用的。
(3)MappedByteBuffer在处理大文件时的确性能很高,但也存在一些问题,如内存占用、文件关闭不确定,被其打开的文件只有在垃圾回收的才会被关闭,而且这个时间点是不确定的。
参考:【Java8源码分析】NIO包-Buffer类:内存映射文件DirectByteBuffer与MappedByteBuffer(二)_linxd-CSDN博客
HeapByteBuffer与DirectByteBuffer
都是通过 ByteBuffer allocate 生成的,源码:
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}再看一下 DirectByteBuffer 的构造器:
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
long base = 0;
try {
// 核心:创建对象分配内存
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}可看到 DirectByteBuffer 对象的内存分配 allocateMemory() 是一个native方法,即不是jvm控制的内存区域,通常称为堆外内存,一般是通过c/c++分配的内存(malloc)。而HeapByteBuffer是堆上的ByteBuffer对象,属于jvm控制的范围。
在DirectByteBuffer的父类Buffer中,有一个address成员变量,这个就是堆外内存所分配对象的内存地址(虚拟地址),如此一来,jvm堆上的对象就会有一个堆外内存的一个引用,通过这个引用操作堆外内存。
对于HeapByteBuffer,数据的分配存储都在jvm堆上,当需要和io设备打交道的时候,会将jvm堆上所维护的byte[]拷贝至堆外内存,然后堆外内存和io设备交互。如果直接使用DirectByteBuffer,那么就不需要拷贝这一步,将大大提升io的效率,这种称之为零拷贝(zero-copy)。
为什么对io的操作都需要将jvm内存区的数据拷贝到堆外内存呢?是因为jvm需要进行GC,如果io设备直接和jvm堆上的数据进行交互,这个时候jvm进行了GC,jvm堆上正在IO的数据发生了位置移动,这样会导致正在进行的io操作相关的数据全部乱套。
堆外内存 之 DirectByteBuffer
DirectByteBuffer是通过虚引用(Phantom Reference)来实现堆外内存的释放的。
PhantomReference 是所有“弱引用”中最弱的引用类型。不同于软引用和弱引用,虚引用无法通过 get() 方法来取得目标对象的强引用从而使用目标对象,观察源码可以发现 get() 被重写为永远返回 null。
那虚引用到底有什么作用?其实虚引用主要被用来 跟踪对象被垃圾回收的状态,通过查看一个队列中是否包含对象所对应的虚引用来判断它是否 即将被垃圾回收。目标对象被回收前,它的引用会被放入一个 ReferenceQueue 对象中,从而达到跟踪对象垃圾回收的作用。
DirectByteBuffer是Java用于实现堆外内存的一个重要类,我们可以通过该类实现堆外内存的创建、使用和销毁。
参考:堆外内存 之 DirectByteBuffer 详解 - 简书
DirectByteBuffer内存释放
总结:java中,直接内存的申请与释放是通过Unsafe类的allocateMemory方法和freeMemory方法来实现的。DirectByteBuffer帮我们简化了直接内存的使用,我们不需要直接操作Unsafe类来进行直接内存的申请与释放。
分析见:DirectByteBuffer内存释放_netty教程_田守枝Java技术博客
JVM源码分析之堆外内存完全解读:JVM源码分析之堆外内存完全解读 - 你假笨