15.操作系统——文件IO,page cache保证内存与磁盘一致性与设备管理
文件系统
Linux 存储系统的 I/O 软件分层,分为三个层次,分别是文件系统层、通用块层、设备层。
- 文件系统层,包括虚拟文件系统和其他文件系统的具体实现,它向上为应用程序统一提供了标准的文件访问接口,向下会通过通用块层来存储和管理磁盘数据。
- 通用块层,包括块设备的 I/O 队列和 I/O 调度器,它会对文件系统的 I/O 请求进行排队,再通过 I/O 调度器,选择一个 I/O 发给下一层的设备层。
-设备层,包括硬件设备、设备控制器和驱动程序,负责最终物理设备的 I/O 操作。

文件I/O
常见的IO分为三类:
缓冲与非缓冲 I/O
直接与非直接 I/O
阻塞与非阻塞 I/O VS 同步与异步 I/O
阻塞 I/O、非阻塞 I/O,还是基于非阻塞 I/O 的多路复用都是同步调用。因为它们在 read 调用时,内核将数据从内核空间拷贝到应用程序空间,过程都是需要等待的,也就是说这个过程是同步的,如果内核实现的拷贝效率不高,read 调用就会在这个同步过程中等待比较长的时间。
1.缓冲与非缓冲IO
根据是否利用标准库缓冲:
- 缓冲IO:利用标准库缓存实现文件的加速范围跟,标准库则再通过系统调用访问文件。
- 非缓冲:直接通过系统调用访问文件,不经过标准库缓存
比如linux中输入密码经常看不见,是因为直到遇见换行指令,才进行IO,之前的内容都是先被标准库暂时缓存起来,这样做可以减少系统调用次数。
2.直接与非直接IO
Linux 内核为了减少磁盘 I/O 次数,在系统调用后,会把用户数据拷贝到内核中缓存起来,这个内核缓存空间也就是「页缓存」,只有当缓存满足某些条件的时候,才发起磁盘 I/O 的请求。
根据是否利用操作系统缓存:
- 直接IO,不会发送内核缓存与用户程序之间的数据复制,而是直接经过文件系统访问磁盘。
- 非直接IO,读操作时,数据从内核缓存拷贝到用户程序,进行写操作时,数据从用户程序拷贝给内核缓存,再由内核决定什么时候写入数据到磁盘。
触发内核缓存写磁盘的操作
- 调用write函数的最后 ,发现内核缓存数据太多,内核会把数据写到磁盘上。
- 用户主动sync,内核缓存写到磁盘上。
- 内存紧张,无法再分配页面
- 内核缓存数据超过某个时间。
3.阻塞与非阻塞IO 与 同步与异步IO
阻塞IO:
执行read,线程先被阻塞,一直到内核数据准备好,并把数据从内核拷贝到应用程序的缓冲区中,拷贝完成read返回。
阻塞得等1.内核准备好数据 2.数据从内核态拷贝到用户态 两个过程
非阻塞IO
read请求在数据尚未准备好就立即返回,此时应用程序不断轮询,直到数据准备好,内核将数据拷贝到应用程序缓冲区,read获取到结果。
即read发起系统调用一直轮询返回,直到数据准备好,而后从内核拷贝到应用进程。
最后一次read,获取数据是一个同步的过程,需要等待,同步指内核态数据拷贝到用户态程序缓存区的过程。

访问管道或者socket ,设置O_NONBLOCK,就表示非阻塞。
IO多路复用——使用一个进程来维护多个 Socket
socket:IP+端口;
为了解决非阻塞IO傻乎乎的轮询,通过IO事件分发select /poll,等内核数据准备好,再以事件通知应用程序操作。
这个做法大大改善了应用进程对 CPU 的利用率,在没有被通知的情况下,应用进程可以使用 CPU 做其他的事情。
- select阻塞系统调用
- 数据直到准备好,从内核拷贝到应用进程
- 通知数据可读
- read调用系统调用
- 拷贝完成,返回结果
多进程模型:
如果服务器要支持多个客户端,其中比较传统的方式,就是使用多进程模型,也就是为每个客户端分配一个进程来处理请求。
服务器的主进程负责监听客户的连接,一旦与客户端连接完成,accept() 函数就会返回一个「已连接 Socket」,这时就通过 fork() 函数创建一个子进程,实际上就把父进程所有相关的东西都复制一份,包括文件描述符、内存地址空间、程序计数器、执行的代码等。
又因为子进程复制了父进程的文件描述符,可以直接用socket。可以发现,子进程不需要关心「监听 Socket」,只需要关心「已连接 Socket」;父进程则相反,将客户服务交给子进程来处理,因此父进程不需要关心「已连接 Socket」,只需要关心「监听 Socket」。

子进程再使用结束推出时,会变成僵尸进程,需要用wait() 和waitpid()函数回收资源。
多线程模型:
线程是运行在进程中的一个“逻辑流”,单进程中可以运行多个线程,同进程里的线程可以共享进程的部分资源的,比如文件描述符列表、进程空间、代码、全局数据、堆、共享库等,这些共享些资源在上下文切换时是不需要切换,而只需要切换线程的私有数据、寄存器等不共享的数据,因此同一个进程下的线程上下文切换的开销要比进程小得多。
当服务器与客户端 TCP 完成连接后,通过 pthread_create() 函数创建线程,然后将「已连接 Socket」的文件描述符传递给线程函数,接着在线程里和客户端进行通信,从而达到并发处理的目的。
使用线程池的方式来避免线程的频繁创建和销毁,所谓的线程池,就是提前创建若干个线程,这样当由新连接建立时,将这个已连接的 Socket 放入到一个队列里,然后线程池里的线程负责从队列中取出已连接 Socket 进程处理。

这个队列是全局的,每个线程都会操作,为了避免多线程竞争,线程在操作这个队列前要加锁。
1.select:
select 实现多路复用的方式是,将已连接的 Socket 都放到一个文件描述符集合,然后调用 select 函数将文件描述符集合拷贝到内核里,让内核来检查是否有网络事件产生,检查的方式很粗暴,就是通过遍历文件描述符集合的方式,当检查到有事件产生后,将此 Socket 标记为可读或可写, 接着再把整个文件描述符集合拷贝回用户态里,然后用户态还需要再通过遍历的方法找到可读或可写的 Socket,然后再对其处理。
所以,对于 select 这种方式,需要进行 2 次「遍历」文件描述符集合,一次是在内核态里,一个次是在用户态里 ,而且还会发生 2 次「拷贝」文件描述符集合,先从用户空间传入内核空间,由内核修改后,再传出到用户空间中。select 使用固定长度的 BitsMap,表示文件描述符集合,而且所支持的文件描述符的个数是有限制的,在 Linux 系统中,由内核中的 FD_SETSIZE 限制, 默认最大值为 1024,只能监听 0~1023 的文件描述符。
2.poll
poll 不再用 BitsMap 来存储所关注的文件描述符,取而代之用动态数组,以链表形式来组织,突破了 select 的文件描述符个数限制,当然还会受到系统文件描述符限制。
但是 poll 和 select 并没有太大的本质区别,都是使用「线性结构」存储进程关注的 Socket 集合,因此都需要遍历文件描述符集合来找到可读或可写的 Socket,时间复杂度为 O(n),而且也需要在用户态与内核态之间拷贝文件描述符集合,这种方式随着并发数上来,性能的损耗会呈指数级增长。
3.epoll
epoll 通过两个方面,很好解决了 select/poll 的问题。
- epoll 在内核里使用红黑树来跟踪进程所有待检测的文件描述字,把需要监控的 socket 通过 epoll_ctl() 函数加入内核中的红黑树里,红黑树是个高效的数据结构,增删改一般时间复杂度是 O(logn)。而 select/poll 内核里没有类似 epoll 红黑树这种保存所有待检测的 socket 的数据结构,所以 select/poll 每次操作时都传入整个 socket 集合给内核,而 epoll 因为在内核维护了红黑树,可以保存所有待检测的 socket ,所以只需要传入一个待检测的 socket,减少了内核和用户空间大量的数据拷贝和内存分配。
- epoll 使用事件驱动的机制,内核里维护了一个链表来记录就绪事件,当某个 socket 有事件发生时,通过回调函数内核会将其加入到这个就绪事件列表中,当用户调用 epoll_wait() 函数时,只会返回有事件发生的文件描述符的个数,不需要像 select/poll 那样轮询扫描整个 socket 集合,大大提高了检测的效率。
异步IO aio_read
指 内核准备数据 以及 数据从内核态拷贝到用户态的应用进程 都不需要等待。
- aio_read发起系统调用,并立即返回
- 直到内核将数据准备好,并拷贝到应用进程,此时内核拷贝完成主动通知应用进程。
不同IO机制对比总结
在前面我们知道了,I/O 是分为两个过程的:
1.数据准备的过程
2.数据从内核空间拷贝到用户进程缓冲区的过程
阻塞 I/O 会阻塞在「过程 1 」和「过程 2」,而非阻塞 I/O 和基于非阻塞 I/O 的多路复用只会阻塞在「过程 2」,所以这三个都可以认为是同步 I/O。
例子小林总结的打饭过程蛮有意思的:

write过程

- 应用程序调用write
- 先到vfs,虚拟文件系统(用以屏蔽了多个文件系统的差别)
- 页缓存page cache
- 具体的文件系统ext4
- block IO层
- 驱动转化为SCSI指令,操作存储介质
page cache
本质时linux内核管理的内存区域,应用程序通过mmap以及vfs通过Buffer io将文件读取到内存空间,实际上读到了page cache
Page Cache 用于缓存文件的页数据,buffer cache 用于缓存块设备(如
磁盘)的块数据。
页是逻辑上的概念,因此 Page Cache 是与文件系统同级的;
块是物理上的概念,因此 buffer cache 是与块设备驱动程序同级的。
主要优点:1.缓存最近被访问的数据(根据时空局部性)2.预读功能
Page Cache 与 buffer cache 的共同目的都是加速数据 I/O过程:
写数据时首先写到缓存,将写入的页标记为 dirty,然后向外部存储 flush,也就是缓存写机制中的 write-back(另一种是 write-through,Linux 默认情况下不采用);
读数据时首先读取缓存,如果未命中,再去外部存储读取,并且将读取来的数据也加入缓存。操作系统总是积极地将所有空闲内存都用作 Page Cache 和 buffer cache,当内存不够用时也会用 LRU 等算法淘汰缓存页。
预读功能:
读取磁盘数据的时候,需要找到数据所在的位置,但是对于机械磁盘来说,就是通过磁头旋转到数据所在的扇区,再开始「顺序」读取数据,但是旋转磁头这个物理动作是非常耗时的,为了降低它的影响,PageCache 使用了「预读功能」。
假设 read 方法每次只会读 32 KB 的字节,虽然 read 刚开始只会读 0 ~ 32 KB 的字节,但内核会把其后面的 32~64 KB 也读取到 PageCache,这样后面读取 32~64 KB 的成本就很低,如果在 32~64 KB 淘汰出 PageCache 前,进程读取到它了,收益就非常大。
page cache 与文件持久化的一致性、可靠性
任何系统引入缓存,就会引发一致性问题:内存中的数据与磁盘中的数据不一致
文件 = 数据 + 元数据。元数据用来描述文件的各种属性,也必须存储在磁盘上。因此,我们说保证文件一致性其实包含了两个方面:数据一致+元数据一致。
如果发生写操作并且对应的数据在 Page Cache 中,那么写操作就会直接作用于 Page Cache 中,此时如果数据还没刷新到磁盘,那么内存中的数据就领先于磁盘,此时对应 page 就被称为 Dirty page
linux 写穿和写回实现文件一致性(内存和磁盘一致)
- write through:写穿,向用户从提供特定接口,应用程序通过主动调用接口保证文件一致性。以牺牲系统 I/O 吞吐量作为代价,向上层应用确保一旦写入,数据就已经落盘,不会丢失;
- write back:写回,系统中存在一些内核线程作为定期任务,周期性同步文件系统中脏数据块。在系统发生宕机的情况下无法确保数据已经落盘,因此存在数据丢失的问题。不过,在程序挂了,例如被 kill -9,Page Cache 中的数据操作系统还是会确保落盘;
依赖于以下三种系统调用:
- fsync:文件的脏数据和脏元数据全部刷新至磁盘中。
- fdatasync:文件的脏数据刷新至磁盘,同时对必要的元数据刷新至磁盘中,这里所说的必要的概念是指:对接下来访问文件有关键作用的信息,如文件大小,而文件修改时间等不属于必要信息
- sync:对系统中所有的脏的文件数据元数据刷新至磁盘中
进程写文件崩溃是否会丢掉已经写的数据
不会,执行write系统调用,实际上会写到内核的page cache中,其作为一块缓冲区,即使进程崩溃,文件仍会保留。而后我们再次尝试读的时候,也是从page cache读的,因此数据没有丢。
内核会找个合适的时机,将 page cache 中的数据持久化到磁盘。但是如果 page cache 里的文件数据,在持久化到磁盘化到磁盘之前,系统发生了崩溃,那这部分数据就会丢失了。
解决方法:
程序里调用 fsync 函数,在写文文件的时候,立刻将文件数据持久化到磁盘,这样就可以解决系统崩溃导致的文件数据丢失的问题。
设备管理
设备控制器
作用:屏蔽每个设备用法功能的不同,通过操作系统把IO设备统一管理。
流程:设备 到 控制器 到 接口(内部有三种寄存器,分别管状态,命令和数据) 经过总线 直接到 CPU/内存
通过写入这些寄存器,操作系统可以命令设备发送数据、接收数据、开启或关闭,或者执行某些其他操作。
通过读取这些寄存器,操作系统可以了解设备的状态,是否准备好接收一个新的命令等。
块设备与字符设备
- 块设备:数据存在固定大小的块中,硬盘、USB。块设备通常传输的数据量会非常大,于是控制器设立了一个可读写的数据缓冲区。屯够一部分才IO。Linux 通过一个统一的通用块层,来管理不同的块设备。第一个功能,向上为文件系统和应用程序,提供访问块设备的标准接口,向下把各种不同的磁盘设备抽象为统一的块设备,并在内核层面,提供一个框架来管理这些设备的驱动程序;第二功能,通用层还会给文件系统和应用程序发来的 I/O 请求排队,接着会对队列重新排序、请求合并等方式,也就是 I/O 调度,主要目的是为了提高磁盘读写的效率。
- 字符设备:以字符为单位IO一个字符流,不可寻址,没有寻道操作,鼠标。
CPU如何与设备控制器和数据缓冲区通信
- 端口IO:每个控制寄存器被分配一个IO端口,可以通过特殊汇编指令操作,如in out
- 内存映射I/O:将所有控制寄存器映射到内存中,这样就可以读内存一样读写数据缓冲区。
IO控制方式——DMA
频繁的中断对磁盘类的设备不友好,会让CPU经常被打断。
DMA:直接内存访问 使设备再CPU不参与的情况下,自行完成设备IO数据到内存。简单理解就是,在进行 I/O 设备和内存的数据传输的时候,数据搬运的工作全部交给 DMA 控制器,而 CPU 不再参与任何与数据搬运相关的事情,这样 CPU 就可以去处理别的事务。
具体过程:
- 用户进程调用read /write,向操作系统发出IO请求,请求读数据到内存缓冲区,进程从而阻塞。
- 操作系统收到请求,将IO请求转发给DMA,让CPU执行其他任务。
- DMA进一步把IO请求发给磁盘,磁盘把数据督导磁盘控制器缓冲区中,当磁盘控制器的缓冲区读满,即可向DMA发起中断信号,告知自己满了。
- DMA收到信号,将磁盘控制缓冲区中的数据拷贝到内核缓冲区中,此时不需要CPU参与,因此CPU可以处理其他任务。
- DMA读到足够的数据,中断信号发给CPU。cpu收到DMA,知道万事俱备了,直接把数据从内核拷贝到用户空间,系统调用返回。
常问
提高IO效率(优化文件传输性能)
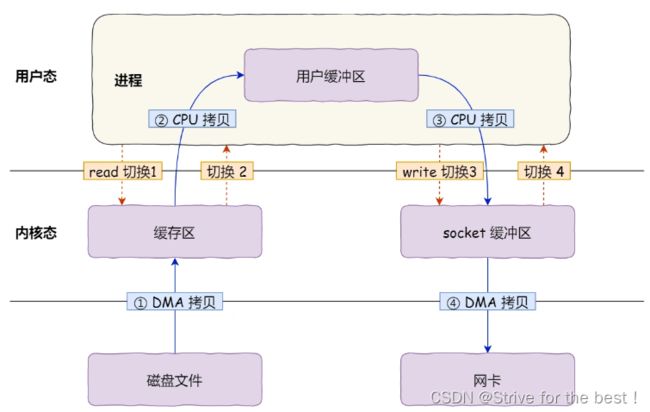
传输文件,需要read 一次,write一次,正常4次用户态和内核态切换,4次数据拷贝
第一次拷贝,把磁盘上的数据拷贝到操作系统内核的缓冲区里,这个拷贝的过程是通过 DMA 搬运的。
第二次拷贝,把内核缓冲区的数据拷贝到用户的缓冲区里,于是我们应用程序就可以使用这部分数据了,这个拷贝到过程是由 CPU 完成的。
第三次拷贝,把刚才拷贝到用户的缓冲区里的数据,再拷贝到内核的 socket 的缓冲区里,这个过程依然还是由 CPU 搬运的。
第四次拷贝,把内核的 socket 缓冲区里的数据,拷贝到网卡的缓冲区里,这个过程又是由 DMA 搬运的。
存储系统的 I/O 是整个系统最慢的一个环节,所以 Linux 提供了不少缓存机制来提高 I/O 的效率:
要想减少上下文切换的次数,就要减少系统调用。
- 为了提高文件访问的效率,会使用页缓存、索引节点缓存、目录项缓存等多种缓存机制,目的是为了减少对块设备的直接调用。
- 为了提高块设备的访问效率, 会使用缓冲区,来缓存块设备的数据
- 在文件传输场景里,由于在用户空间并不会对数据做再加工,数据其实没有必要搬运到用户空间,这种情况不经过用户缓冲区,直接把数据从内核缓冲区拷贝到socket缓冲区就行。见下mmap+write
大文件:
在高并发的场景下,针对大文件的传输的方式,应该使用「异步 I/O(不等数据就返回,等内核准备好了通知) + 直接 I/O(不使用page cache)」来替代零拷贝技术。
总结:大文件:异步IO+直接IO。 小文件:零拷贝
零拷贝(kafka,nginx有利用)
定义:没有在内存层面去拷贝数据,也就是说全程没有通过 CPU 来搬运数据,所有的数据都是通过 DMA 来进行传输的。
零拷贝技术实现的方式通常有 2 种:
- mmap+write:因为read()系统调用会把内核缓冲区数据拷贝到用户缓冲区,用mmap()函数替代read()系统调用,mmap()直接把内核缓冲区数据映射到用户空间,双方共享缓冲区,即不需要数据拷贝。
- sendfile
mmap+write具体步骤:
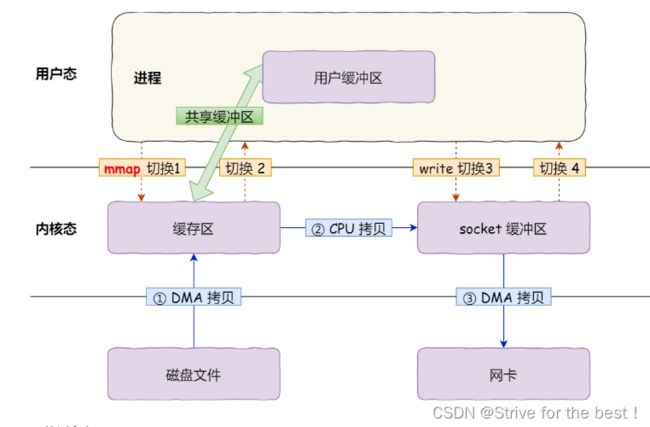
- 应用调用mmap(),DMA把磁盘数据拷贝到内核缓冲区,接着应用进程和操作系统共享该内核缓冲区。
- 应用进程再调用write(),操作系统直接将内核缓冲区的数据拷贝到socket缓冲区中,cpu只负责搬运数据
- 最后,内核的socket缓冲区里的数据拷贝到网卡的缓冲区,由DMA负责拷贝。
我们可以得知,通过使用 mmap() 来代替 read(), 可以减少一次数据拷贝的过程。但仍然需要 4 次上下文切换,因为系统调用还是 2 次。
sendfile
#include
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
文件传输函数,可以替代前面的 read() 和 write() 这两个系统调用,这样就可以减少一次系统调用,也就减少了 2 次上下文切换的开销。
其次,该系统调用,可以直接把内核缓冲区里的数据拷贝到 socket 缓冲区里,不再拷贝到用户态,这样就只有 2 次上下文切换,和 3 次数据拷贝。如下图:

但这仍然有3次拷贝,如果网卡支持 SG-DMA,sendfile() 系统调用的过程发生了点变化,具体过程如下:
第一步,通过 DMA 将磁盘上的数据拷贝到内核缓冲区里;
第二步,缓冲区描述符和数据长度传到 socket 缓冲区,这样网卡的 SG-DMA 控制器就可以直接将内核缓存中的数据拷贝到网卡的缓冲区里,此过程不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中,这样就减少了一次数据拷贝;

只需要 2 次上下文切换和数据拷贝次数,就可以完成文件的传输,而且 2 次的数据拷贝过程,都不需要通过 CPU,2 次都是由 DMA 来搬运。零拷贝技术可以把文件传输的性能提高至少一倍以上。
键盘输入字母到显示期间发生了什么
架构:CPU的内存接口通过系统总线接入IO桥接器,桥接器另一端通过内存总线连接内存。这样CPU和内存可以通信。
从IO桥接器拉出到IO总线,IO总线通过设备控制器连接外设。

发生了什么:
- 敲键盘,键盘控制器产生扫描码数据,将其缓存在键盘控制器的寄存器中,而控制器通过总线给CPU发送中断请求。
- CPU收到中断请求,保存CPU上下文,调用对应的中断处理程序。该中断处理程序是安装键盘驱动就初始化注册好的。功能就是从控制器寄存器中读扫描码,然后根据扫描码找到用户输入了哪个字符,如果是显示字符,就翻译成ASCLL码。将ascll码放到内存中的读缓冲队列中。
- 显示器驱动设备从读缓冲队列中读取数据,将其放到写缓冲队列中,显示在屏幕上。
- CPU最后需要恢复被中断的上下文。
注:显示的过程显卡处于图形模式(如果计算机刚刚加电启动,显卡最开始处于文本模式),屏幕分辨率为 1024x768,即把屏幕分成 768 行,每行 1024 个像素点,但每个像素点占用显存的 32 位数据(4 字节,红、绿、蓝、透明各占 8 位)。我们只要往对应的显存地址写入相应的像素数据,屏幕对应的位置就能显示了。