【基础】【Python网络爬虫】【11.字体反扒】认识字体、字体加密(附大量案例代码)(建议收藏)
Python网络爬虫基础
- 字体反扒
-
- 1. 认识字体
-
- 字体概述
- 2. 处理字体
- 3. 练习案例 - 某小说网址字体解密
-
- 3.1 请求数据 - 发现问题
- 3.2 下载字体文件
- 3.3 解析字体文件
- 3.4 替换字体
- 4. 字符串形式字体文件
-
- 4.1 请求数据 - 发现乱码
- 4.2 下载字体
- 4.3 解析字体
- 4.4 替换数据
- 5. 字体加密
-
- 5.1 请求数据 - 发现偏移量
- 5.2 构建字体映射规则
- 5.3 替换字体
- 5.4 多套字体
字体反扒
1. 认识字体
在爬虫爬取页面的时候,页面中的代码是乱码,但是在人眼看到的是原文,这样的映射关系让爬虫无法顺利爬取到网站内容。
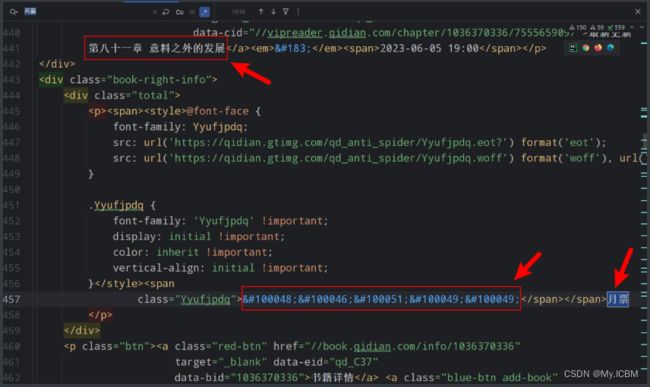
以下是在网页中能够正常显示的文本内容,但是在Elements元素面板显示的是看不懂的字符
基于以上的情况,首先在网页的页面我们是能够看到正常显示的字符信息的,但是一旦我们请求数据的时候我们看到的就是看不懂的字符,如下所示:
- 因此,我们可以想一想为什么导致这样的情况。为什么浏览器能够得到正常的数据,咱们请求下来就不行?难道浏览器背后做了什么转化?答案是:“yes”。
- 首先,网站使用的是自定义的字体文件,浏览器在渲染数据的时候会根据字体文件引用关系读取字体文件,然后按照每一个字体的映射关系,将每一个正确的字体在网页渲染出来,从而我们在网页中可以看到正常的字体。但是原本的数据并没有变,因此我们请求下来的内容是看不懂的字符。

字体概述
- 网页字体是一个字形集合,而每个字形是描述字母或符号的矢量形状。很多网站的数据肉眼看着很像,但是是由一些特殊文件渲染出来的,即使得到了数据,但是读取出来会有文件。
- 在字体加密的网站中用户也是无法直接进行复制网页内容的。
- 因此,特定字体文件的大小由两个简单变量决定:每个字形矢量路径的复杂程度和特定字体中字形的数量。

网页字体是一个字形集合,而每个字形是描述字母或符号的矢量形状。 因此,特定字体文件的大小由两个简单变量决定:每个字形矢量路径的复杂程度和特定字体中字形的数量。

目前网络上使用的字体容器格式有以下几种: EOT、TTF2、WOFF。但是各个浏览器对字体的支持程度不一致。所以为了兼容性考虑,有的网站会给多个字体文件,哪个字体文件能解析,就是使用哪个。浏览器上使用网址通常是以 @font-face 引入使用类型。
2. 处理字体
如果想要把自定义的字体文字变化为系统能够识别的内容,就需要获取自定义字体与通用字体的映射规则,经过转化后就能得到正常文字信息。
安装以下软件即可查看字体文件
- 安装方式:双击安装包,选择路径,一直点击下一步安装即可。

字体解密的大致流程:
- 先找到字体文件的位置,查看源码大概就是xxx.woff这样的文件
- 重复上面那个操作,将两个字体文件保存下来
- 用上面的软件或者网址打开,并且通过 Python fontTools 将字体文件解析为 xml 文件
- 根据字体文件解析出来的 xml 文件与类似上面的字体界面找出相同内容的映射规律(重点)
- 在 Python 代码中把找出的规律实现出来,让你的代码能够通过这个规律还原源代码与展示内容的映射
3. 练习案例 - 某小说网址字体解密
3.1 请求数据 - 发现问题
import requests
url = 'https://www.qidian.com/rank/yuepiao/'
headers = {
'Cookie': '_yep_uuid=16401b3f-da18-36f9-250b-44791c444165; e1=%7B%22l6%22%3A%22%22%2C%22pid%22%3A%22qd_P_rank_19%22%2C%22eid%22%3A%22%22%2C%22l1%22%3A5%7D; e2=%7B%22l6%22%3A%22%22%2C%22pid%22%3A%22qd_P_rank_19%22%2C%22eid%22%3A%22%22%2C%22l1%22%3A5%7D; newstatisticUUID=1689595424_1606659668; _csrfToken=6aCHItSuH6xVc1FVDCb7nGXnnDYFr6r6UdurzC7a; fu=801177549; traffic_utm_referer=; Hm_lvt_f00f67093ce2f38f215010b699629083=1689595425; Hm_lpvt_f00f67093ce2f38f215010b699629083=1689595425; _ga=GA1.2.225339841.1689595425; _gid=GA1.2.485020634.1689595425; _ga_FZMMH98S83=GS1.1.1689595425.1.1.1689595594.0.0.0; _ga_PFYW0QLV3P=GS1.1.1689595425.1.1.1689595594.0.0.0',
'Host': 'www.qidian.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
print(response.text)
with open('乱码.html', mode='w', encoding='utf-8') as f:
f.write(response.text)
"""
1. 下载字体文件
2. 解析字体, 获取字体的映射关系
3. 替换请求到的数据
"""
3.2 下载字体文件
import re
import requests
# 导入包 pip install fontTools
url = 'https://www.qidian.com/rank/yuepiao/'
headers = {
'Cookie': '_yep_uuid=16401b3f-da18-36f9-250b-44791c444165; e1=%7B%22l6%22%3A%22%22%2C%22pid%22%3A%22qd_P_rank_19%22%2C%22eid%22%3A%22%22%2C%22l1%22%3A5%7D; e2=%7B%22l6%22%3A%22%22%2C%22pid%22%3A%22qd_P_rank_19%22%2C%22eid%22%3A%22%22%2C%22l1%22%3A5%7D; newstatisticUUID=1689595424_1606659668; _csrfToken=6aCHItSuH6xVc1FVDCb7nGXnnDYFr6r6UdurzC7a; fu=801177549; traffic_utm_referer=; Hm_lvt_f00f67093ce2f38f215010b699629083=1689595425; Hm_lpvt_f00f67093ce2f38f215010b699629083=1689595425; _ga=GA1.2.225339841.1689595425; _gid=GA1.2.485020634.1689595425; _ga_FZMMH98S83=GS1.1.1689595425.1.1.1689595594.0.0.0; _ga_PFYW0QLV3P=GS1.1.1689595425.1.1.1689595594.0.0.0',
'Host': 'www.qidian.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
# print(response.text)
with open('乱码.html', mode='w', encoding='utf-8') as f:
f.write(response.text)
"""
1. 下载字体文件
2. 解析字体, 获取字体的映射关系
3. 替换请求到的数据
"""
"""下载字体文件"""
# format\('eot'\); src: url\('(.*?)'\) format\('woff'\), url\('
font_results = re.findall("format\('eot'\); src: url\('(.*?)'\) format\('woff'\), url\('",
response.text,
re.S)
print('解析到的字体地址: ', font_results)
font_link = font_results[0]
response_font = requests.get(url=font_link).content # 字体文件是二进制数据|
with open('qidian.woff', mode='wb') as f:
f.write(response_font)
print('字体文件下载完成.........')
3.3 解析字体文件
import re
import requests
url = 'https://www.qidian.com/rank/yuepiao/'
headers = {
'Cookie': '_yep_uuid=16401b3f-da18-36f9-250b-44791c444165; e1=%7B%22l6%22%3A%22%22%2C%22pid%22%3A%22qd_P_rank_19%22%2C%22eid%22%3A%22%22%2C%22l1%22%3A5%7D; e2=%7B%22l6%22%3A%22%22%2C%22pid%22%3A%22qd_P_rank_19%22%2C%22eid%22%3A%22%22%2C%22l1%22%3A5%7D; newstatisticUUID=1689595424_1606659668; _csrfToken=6aCHItSuH6xVc1FVDCb7nGXnnDYFr6r6UdurzC7a; fu=801177549; traffic_utm_referer=; Hm_lvt_f00f67093ce2f38f215010b699629083=1689595425; Hm_lpvt_f00f67093ce2f38f215010b699629083=1689595425; _ga=GA1.2.225339841.1689595425; _gid=GA1.2.485020634.1689595425; _ga_FZMMH98S83=GS1.1.1689595425.1.1.1689595594.0.0.0; _ga_PFYW0QLV3P=GS1.1.1689595425.1.1.1689595594.0.0.0',
'Host': 'www.qidian.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
# print(response.text)
with open('乱码.html', mode='w', encoding='utf-8') as f:
f.write(response.text)
"""下载字体文件"""
# format\('eot'\); src: url\('(.*?)'\) format\('woff'\), url\('
font_results = re.findall("format\('eot'\); src: url\('(.*?)'\) format\('woff'\), url\('",response.text,re.S)
print('解析到的字体地址: ', font_results)
font_link = font_results[0]
response_font = requests.get(url=font_link).content # 字体文件是二进制数据|
with open('qidian.woff', mode='wb') as f:
f.write(response_font)
print('字体文件下载完成.........')
"""解析字体文件"""
from fontTools.ttLib import TTFont
font_path = 'qidian.woff' # 字体文件路径
base_font = TTFont(font_path)
# # 将字体关系保存为 xml 格式
# base_font.saveXML('font.xml')
map_list = base_font.getBestCmap()
print('字体文件读取出来的规则:', map_list)
eng_2_num = {
'period': ".",
'two': '2',
'zero': '0',
'five': '5',
'nine': "9",
'seven': '7',
'one': '1',
'three': '3',
'six': '6',
'four': '4',
'eight': '8'
}
for key in map_list.keys():
map_list[key] = eng_2_num[map_list[key]]
print('最终的字体映射规则:', map_list)
3.4 替换字体
import re
import requests
url = 'https://www.qidian.com/rank/yuepiao/'
headers = {
'Cookie': '_yep_uuid=16401b3f-da18-36f9-250b-44791c444165; e1=%7B%22l6%22%3A%22%22%2C%22pid%22%3A%22qd_P_rank_19%22%2C%22eid%22%3A%22%22%2C%22l1%22%3A5%7D; e2=%7B%22l6%22%3A%22%22%2C%22pid%22%3A%22qd_P_rank_19%22%2C%22eid%22%3A%22%22%2C%22l1%22%3A5%7D; newstatisticUUID=1689595424_1606659668; _csrfToken=6aCHItSuH6xVc1FVDCb7nGXnnDYFr6r6UdurzC7a; fu=801177549; traffic_utm_referer=; Hm_lvt_f00f67093ce2f38f215010b699629083=1689595425; Hm_lpvt_f00f67093ce2f38f215010b699629083=1689595425; _ga=GA1.2.225339841.1689595425; _gid=GA1.2.485020634.1689595425; _ga_FZMMH98S83=GS1.1.1689595425.1.1.1689595594.0.0.0; _ga_PFYW0QLV3P=GS1.1.1689595425.1.1.1689595594.0.0.0',
'Host': 'www.qidian.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
# print(response.text)
with open('乱码.html', mode='w', encoding='utf-8') as f:
f.write(response.text)
"""下载字体文件"""
# format\('eot'\); src: url\('(.*?)'\) format\('woff'\), url\('
font_results = re.findall("format\('eot'\); src: url\('(.*?)'\) format\('woff'\), url\('",
response.text,
re.S)
print('解析到的字体地址: ', font_results)
font_link = font_results[0]
response_font = requests.get(url=font_link).content # 字体文件是二进制数据|
with open('qidian.woff', mode='wb') as f:
f.write(response_font)
print('字体文件下载完成.........')
"""解析字体文件"""
from fontTools.ttLib import TTFont
font_path = 'qidian.woff' # 字体文件路径
base_font = TTFont(font_path)
# # 将字体关系保存为 xml 格式
# base_font.saveXML('font.xml')
map_list = base_font.getBestCmap()
print('字体文件读取出来的规则:', map_list)
eng_2_num = {
'period': ".",
'two': '2',
'zero': '0',
'five': '5',
'nine': "9",
'seven': '7',
'one': '1',
'three': '3',
'six': '6',
'four': '4',
'eight': '8'
}
for key in map_list.keys():
map_list[key] = eng_2_num[map_list[key]]
print('最终的字体映射规则:', map_list)
"""替换字体"""
with open('乱码.html', mode='r', encoding='utf-8') as f:
old_html = f.read()
new_html = old_html
for key, value in map_list.items():
# 在循环中每一次替换结果用相同的变量覆盖掉
new_html = new_html.replace('&#' + str(key) + ';', value)
print(key, value, sep='|')
with open('替换以后的数据.html', mode='w', encoding='utf-8') as f:
f.write(new_html)
print('替换完成.......')
4. 字符串形式字体文件
案例网址:https://data.cyzone.cn/event/list-0-1-0-0-0-0-1/0?clear=1
打开目标网址。选择时间数字内容,就可以观察到字体显示的是特殊的符号,这种就是被加密了,可以查看其在网页中是什么样的内容。可以看到这个标签类名上引用了一个特殊的字体cyzone-secret。
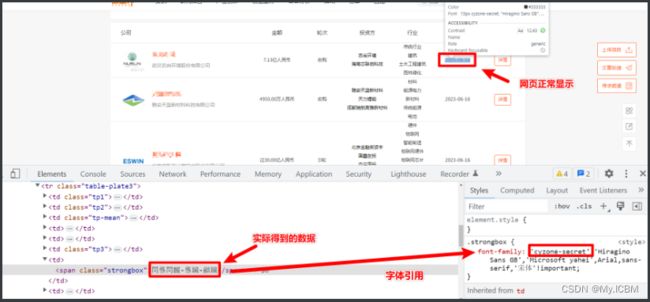
查看Elements文件,看到了一段字体样式:

找遍网页所有文件,都没有发现这个字体cyzone-secret 的代码。并且查看网页源码,没有看到相关代码,断定是动态生成的样式片段。
经过观察,发现页面里边有以下这么一段自执行的代码,执行这段代码以后会出现字体,其中的数据经过了url编码,那么我们可以试试,这个数据中有没有字体文件。

4.1 请求数据 - 发现乱码
# 目标网址: https://data.cyzone.cn/event/list-0-1-0-0-0-0-1/0?clear=1
import requests
import parsel
def send_request():
"""请求返回数据和需要解密的字符"""
url = 'https://data.cyzone.cn/event/list-0-1-0-0-0-0-1/0?clear=1'
headers = {
'Authority': 'data.cyzone.cn',
'Cookie': 'dfxafjs=js/dfxaf3-2cbeaf6b.js; gr_user_id=b033627a-3aae-4a1e-84b4-0f7d97122c12; __bid_n=1887ff83061cab5cb34207; __utmz=22723113.1685774152.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); PHPSESSID=aavtvg47v9gjnmdrf3o6rb03pp; _ga_s=SP03_2; 83f2446e48563cb9_gr_session_id=8de7d4c2-ad4f-48e9-9802-0b75909730fa; 83f2446e48563cb9_gr_session_id_sent_vst=8de7d4c2-ad4f-48e9-9802-0b75909730fa; Hm_lvt_5f6b02d88ea6aa37bfd72ee1b554bf6f=1685774152,1686139691; Hm_lpvt_5f6b02d88ea6aa37bfd72ee1b554bf6f=1686139691; __utma=22723113.525378970.1685774152.1685774152.1686139691.2; __utmc=22723113; __utmt=1; __utmb=22723113.1.10.1686139691; MRGCY_referrer=https%3A%2F%2Fdata.cyzone.cn%2Fevent%2Flist-0-1-0-0-0-0-1%2F0%3Fclear%3D1; SERVERID=b3cd016c79d33550bea8f593c3ab00e6|1686139693|1686139689; FPTOKEN=1UWRTmznbYsDw5BI3QjXku+nXS84LhtQWq4JhegorZrpfhNgilvhTvubnoMbA7HnWajZPYtd/kH1plvzvrGpQEpmnHDpDGmajS3ulLeczK1+BiYgYojlokT8Sn2PeyRa9PeUWk0jTNgTknnmJwB83xdsYPh3jfPkp8AyRULnMi9QOthmdeH/Erub6CyyJj+j0SNM+RU9B7YvB9GGoz9U+Jr2Hk884DTqaChyCo3spgAZAXmqRj6w2D5yk+iasIpNxM3OdHpjyf0PgVDe7yI6SXcO4RGj/NzeQmjcGbkjVnwjrWK+oiATOoMQAlw/UeK7jmJ0wskRiclWJ845Gf7IuJxgPN/rzZsazldOHfP1rlneha5vCDvFBXB4jqBjpyMUnnYQedhL2fUZNqDPWORbpg==|5XPx2vC7FRbU593hbypxicg9gNsdsgH3YMHIMnuL4gc=|10|f6d0cbefe79313e727b47e3669f78dcb',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
html_data = response.text
selector = parsel.Selector(html_data)
time_data = selector.css('.list-table3 tr>td:nth-child(7)>span::text').getall()
print('需要解密的字体:' , time_data)
return html_data, time_data
if __name__ == '__main__':
# 发送请求
html_data, time_data = send_request()
4.2 下载字体
# 目标网址: https://data.cyzone.cn/event/list-0-1-0-0-0-0-1/0?clear=1
import base64
import re
import requests
import parsel
def send_request():
"""请求返回数据和需要解密的字符"""
url = 'https://data.cyzone.cn/event/list-0-1-0-0-0-0-1/0?clear=1'
headers = {
'Authority': 'data.cyzone.cn',
'Cookie': 'dfxafjs=js/dfxaf3-2cbeaf6b.js; gr_user_id=b033627a-3aae-4a1e-84b4-0f7d97122c12; __bid_n=1887ff83061cab5cb34207; __utmz=22723113.1685774152.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); PHPSESSID=aavtvg47v9gjnmdrf3o6rb03pp; _ga_s=SP03_2; 83f2446e48563cb9_gr_session_id=8de7d4c2-ad4f-48e9-9802-0b75909730fa; 83f2446e48563cb9_gr_session_id_sent_vst=8de7d4c2-ad4f-48e9-9802-0b75909730fa; Hm_lvt_5f6b02d88ea6aa37bfd72ee1b554bf6f=1685774152,1686139691; Hm_lpvt_5f6b02d88ea6aa37bfd72ee1b554bf6f=1686139691; __utma=22723113.525378970.1685774152.1685774152.1686139691.2; __utmc=22723113; __utmt=1; __utmb=22723113.1.10.1686139691; MRGCY_referrer=https%3A%2F%2Fdata.cyzone.cn%2Fevent%2Flist-0-1-0-0-0-0-1%2F0%3Fclear%3D1; SERVERID=b3cd016c79d33550bea8f593c3ab00e6|1686139693|1686139689; FPTOKEN=1UWRTmznbYsDw5BI3QjXku+nXS84LhtQWq4JhegorZrpfhNgilvhTvubnoMbA7HnWajZPYtd/kH1plvzvrGpQEpmnHDpDGmajS3ulLeczK1+BiYgYojlokT8Sn2PeyRa9PeUWk0jTNgTknnmJwB83xdsYPh3jfPkp8AyRULnMi9QOthmdeH/Erub6CyyJj+j0SNM+RU9B7YvB9GGoz9U+Jr2Hk884DTqaChyCo3spgAZAXmqRj6w2D5yk+iasIpNxM3OdHpjyf0PgVDe7yI6SXcO4RGj/NzeQmjcGbkjVnwjrWK+oiATOoMQAlw/UeK7jmJ0wskRiclWJ845Gf7IuJxgPN/rzZsazldOHfP1rlneha5vCDvFBXB4jqBjpyMUnnYQedhL2fUZNqDPWORbpg==|5XPx2vC7FRbU593hbypxicg9gNsdsgH3YMHIMnuL4gc=|10|f6d0cbefe79313e727b47e3669f78dcb',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
html_data = response.text
selector = parsel.Selector(html_data)
time_data = selector.css('.list-table3 tr>td:nth-child(7)>span::text').getall()
print('需要解密的字体:' , time_data)
return html_data, time_data
def download_font(html_str):
"""传入html, 通过正则表达式提取字体文件数据内容保存"""
# let code = unescape\("(.*?)"\);
result = re.findall('let code = unescape\("(.*?)"\);', html_str, re.S)[0]
# requests.utils.unquote url解码
unquote_code = requests.utils.unquote(result)
print('url解码后的内容:', unquote_code)
result2 = re.findall(r"base64,(.*?)'\) format\('truetype", unquote_code, re.S)[0]
print('提取出来的字符串形式的字体文件:', result2)
# b64decode() 把字符串形式转化成二进制
bytes_img = base64.b64decode(result2)
# 保存二进制形式的图片
with open('font.woff', mode='wb') as f:
f.write(bytes_img)
return None
if __name__ == '__main__':
# 发送请求
html_data, time_data = send_request()
# 解析保存字体文件
download_font(html_data)
以上是提取出来后的结果,可以发现url解码后的数据是一段标签字符串,设置了style标签,标签内容中引用的是字体样式cyzone-secret,后续还有base64编码的数据内容。由此推测大概率base64编码的数据就是字体文件数据了,由此下保存字体文件。
4.3 解析字体
首先将字体文件转化成xml文件,打开字体文件, 观察字体映射规则,发现字体映射规则是固定不变的,由此用字典构建字体映射规则。

# 目标网址: https://data.cyzone.cn/event/list-0-1-0-0-0-0-1/0?clear=1
import base64
import re
import requests
import parsel
from fontTools.ttLib import TTFont
def send_request():
"""请求返回数据和需要解密的字符"""
url = 'https://data.cyzone.cn/event/list-0-1-0-0-0-0-1/0?clear=1'
headers = {
'Authority': 'data.cyzone.cn',
'Cookie': 'dfxafjs=js/dfxaf3-2cbeaf6b.js; gr_user_id=b033627a-3aae-4a1e-84b4-0f7d97122c12; __bid_n=1887ff83061cab5cb34207; __utmz=22723113.1685774152.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); PHPSESSID=aavtvg47v9gjnmdrf3o6rb03pp; _ga_s=SP03_2; 83f2446e48563cb9_gr_session_id=8de7d4c2-ad4f-48e9-9802-0b75909730fa; 83f2446e48563cb9_gr_session_id_sent_vst=8de7d4c2-ad4f-48e9-9802-0b75909730fa; Hm_lvt_5f6b02d88ea6aa37bfd72ee1b554bf6f=1685774152,1686139691; Hm_lpvt_5f6b02d88ea6aa37bfd72ee1b554bf6f=1686139691; __utma=22723113.525378970.1685774152.1685774152.1686139691.2; __utmc=22723113; __utmt=1; __utmb=22723113.1.10.1686139691; MRGCY_referrer=https%3A%2F%2Fdata.cyzone.cn%2Fevent%2Flist-0-1-0-0-0-0-1%2F0%3Fclear%3D1; SERVERID=b3cd016c79d33550bea8f593c3ab00e6|1686139693|1686139689; FPTOKEN=1UWRTmznbYsDw5BI3QjXku+nXS84LhtQWq4JhegorZrpfhNgilvhTvubnoMbA7HnWajZPYtd/kH1plvzvrGpQEpmnHDpDGmajS3ulLeczK1+BiYgYojlokT8Sn2PeyRa9PeUWk0jTNgTknnmJwB83xdsYPh3jfPkp8AyRULnMi9QOthmdeH/Erub6CyyJj+j0SNM+RU9B7YvB9GGoz9U+Jr2Hk884DTqaChyCo3spgAZAXmqRj6w2D5yk+iasIpNxM3OdHpjyf0PgVDe7yI6SXcO4RGj/NzeQmjcGbkjVnwjrWK+oiATOoMQAlw/UeK7jmJ0wskRiclWJ845Gf7IuJxgPN/rzZsazldOHfP1rlneha5vCDvFBXB4jqBjpyMUnnYQedhL2fUZNqDPWORbpg==|5XPx2vC7FRbU593hbypxicg9gNsdsgH3YMHIMnuL4gc=|10|f6d0cbefe79313e727b47e3669f78dcb',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
html_data = response.text
selector = parsel.Selector(html_data)
time_data = selector.css('.list-table3 tr>td:nth-child(7)>span::text').getall()
print('需要解密的字体:' , time_data)
return html_data, time_data
def download_font(html_str):
"""传入html, 通过正则表达式提取字体文件数据内容保存"""
# let code = unescape\("(.*?)"\);
result = re.findall('let code = unescape\("(.*?)"\);', html_str, re.S)[0]
# requests.utils.unquote url解码
unquote_code = requests.utils.unquote(result)
print('url解码后的内容:', unquote_code)
result2 = re.findall(r"base64,(.*?)'\) format\('truetype", unquote_code, re.S)[0]
print('提取出来的字符串形式的字体文件:', result2)
# b64decode() 把字符串形式转化成二进制
bytes_img = base64.b64decode(result2)
# 保存二进制形式的图片
with open('font.woff', mode='wb') as f:
f.write(bytes_img)
return None
def get_mapping():
"""找到字体新的映射关系"""
text_font = TTFont('font.woff')
text_font.saveXML("text.xml")
# 获取映射规则
text_mapping = text_font.getBestCmap()
print(text_mapping)
# text_mapping = text_font['cmap'].tables[0].ttFont.tables['cmap'].tables[0].cmap
# print('text_mapping:::', text_mapping)
#
# 通过比对发现, glyph* 对应的坐标没有变化,即数字值没有变化
_mapping = {
'glyph00009': '8',
'glyph00005': '4',
'glyph00001': '0',
'glyph00008': '7',
'glyph00010': '9',
'glyph00002': '1',
'glyph00006': '5',
'glyph00003': '2',
'glyph00004': '3',
'glyph00007': '6',
}
__mapping = {}
for key, val in text_mapping.items():
__mapping[key] = _mapping[val]
print('字体映射规则:', __mapping)
return __mapping
if __name__ == '__main__':
# 发送请求
html_data, time_data = send_request()
# 解析保存字体文件
download_font(html_data)
# 处理字体, 找到字体的映射关系
font_mapping = get_mapping()
4.4 替换数据
# 目标网址: https://data.cyzone.cn/event/list-0-1-0-0-0-0-1/0?clear=1
import base64
import re
import requests
import parsel
# 导入包 pip install fontTools
from fontTools.ttLib import TTFont
def send_request():
"""请求返回数据和需要解密的字符"""
url = 'https://data.cyzone.cn/event/list-0-1-0-0-0-0-1/0?clear=1'
headers = {
'Authority': 'data.cyzone.cn',
'Cookie': 'dfxafjs=js/dfxaf3-2cbeaf6b.js; gr_user_id=b033627a-3aae-4a1e-84b4-0f7d97122c12; __bid_n=1887ff83061cab5cb34207; __utmz=22723113.1685774152.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); PHPSESSID=aavtvg47v9gjnmdrf3o6rb03pp; _ga_s=SP03_2; 83f2446e48563cb9_gr_session_id=8de7d4c2-ad4f-48e9-9802-0b75909730fa; 83f2446e48563cb9_gr_session_id_sent_vst=8de7d4c2-ad4f-48e9-9802-0b75909730fa; Hm_lvt_5f6b02d88ea6aa37bfd72ee1b554bf6f=1685774152,1686139691; Hm_lpvt_5f6b02d88ea6aa37bfd72ee1b554bf6f=1686139691; __utma=22723113.525378970.1685774152.1685774152.1686139691.2; __utmc=22723113; __utmt=1; __utmb=22723113.1.10.1686139691; MRGCY_referrer=https%3A%2F%2Fdata.cyzone.cn%2Fevent%2Flist-0-1-0-0-0-0-1%2F0%3Fclear%3D1; SERVERID=b3cd016c79d33550bea8f593c3ab00e6|1686139693|1686139689; FPTOKEN=1UWRTmznbYsDw5BI3QjXku+nXS84LhtQWq4JhegorZrpfhNgilvhTvubnoMbA7HnWajZPYtd/kH1plvzvrGpQEpmnHDpDGmajS3ulLeczK1+BiYgYojlokT8Sn2PeyRa9PeUWk0jTNgTknnmJwB83xdsYPh3jfPkp8AyRULnMi9QOthmdeH/Erub6CyyJj+j0SNM+RU9B7YvB9GGoz9U+Jr2Hk884DTqaChyCo3spgAZAXmqRj6w2D5yk+iasIpNxM3OdHpjyf0PgVDe7yI6SXcO4RGj/NzeQmjcGbkjVnwjrWK+oiATOoMQAlw/UeK7jmJ0wskRiclWJ845Gf7IuJxgPN/rzZsazldOHfP1rlneha5vCDvFBXB4jqBjpyMUnnYQedhL2fUZNqDPWORbpg==|5XPx2vC7FRbU593hbypxicg9gNsdsgH3YMHIMnuL4gc=|10|f6d0cbefe79313e727b47e3669f78dcb',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
html_data = response.text
selector = parsel.Selector(html_data)
time_data = selector.css('.list-table3 tr>td:nth-child(7)>span::text').getall()
print('需要解密的字体:' , time_data)
return html_data, time_data
def download_font(html_str):
"""传入html, 通过正则表达式提取字体文件数据内容保存"""
# let code = unescape\("(.*?)"\);
result = re.findall('let code = unescape\("(.*?)"\);', html_str, re.S)[0]
# requests.utils.unquote url解码
unquote_code = requests.utils.unquote(result)
print('url解码后的内容:', unquote_code)
result2 = re.findall(r"base64,(.*?)'\) format\('truetype", unquote_code, re.S)[0]
print('提取出来的字符串形式的字体文件:', result2)
# b64decode() 把字符串形式转化成二进制
bytes_img = base64.b64decode(result2)
# 保存二进制形式的图片
with open('font.woff', mode='wb') as f:
f.write(bytes_img)
return None
def get_mapping():
"""找到字体新的映射关系"""
text_font = TTFont('font.woff')
text_font.saveXML("text.xml")
# 获取映射规则
text_mapping = text_font.getBestCmap()
print(text_mapping)
# text_mapping = text_font['cmap'].tables[0].ttFont.tables['cmap'].tables[0].cmap
# print('text_mapping:::', text_mapping)
#
# 通过比对发现, glyph* 对应的坐标没有变化,即数字值没有变化
_mapping = {
'glyph00009': '8',
'glyph00005': '4',
'glyph00001': '0',
'glyph00008': '7',
'glyph00010': '9',
'glyph00002': '1',
'glyph00006': '5',
'glyph00003': '2',
'glyph00004': '3',
'glyph00007': '6',
}
__mapping = {}
for key, val in text_mapping.items():
__mapping[key] = _mapping[val]
print('字体映射规则:', __mapping)
return __mapping
def decode_text(mapping, string):
"""
替换字体数据
"""
ret_list = []
for char in string:
# ord(char) 返回一个字符串的unicode值
uni = ord(char)
print('转化后的字符串Unicode值为: ', uni)
# 字典有uni这个键就获取其值, 没有就返回设置的默认值char
value = mapping.get(uni, char)
ret_list.append(value)
return ''.join(ret_list)
if __name__ == '__main__':
# 发送请求
html_data, time_data = send_request()
# 解析保存字体文件
download_font(html_data)
# 处理字体, 找到字体的映射关系
font_mapping = get_mapping()
for char in time_data:
result = decode_text(font_mapping, char)
print(result)
5. 字体加密
案例网址:https://sh.ziroom.com/z/
- 分析流程:他所有的内容均在网页源代码中,不用去寻找api接口,皆大欢喜,但它的价格是css加密过的,即点击styles中的不显示红框中的内容,它的价格就会发生变化,复制它的url地址,会发现是一张雪碧图(爬取的价格图片背景像雪碧,所以叫做雪碧图),它的价格是根据像素点的变化,定位雪碧图的不同数字显示的。
- 实现思路:获得图片,通过图片识别,将像素点(偏移量)根雪碧图的数字一一对应,爬取像素点(偏移量),将识别出来的数字替换偏移量显示价格,实现价格的爬取。(css反爬一般都是通过这种位移的方式来保护它的数据的)

- 通过上述分析,咱们已经知道在网页前端中是通过一张图片,根据偏移量在图片中显示价格数字的。因此我们只需要把字体图片和价格的偏移量提取出来还原数据即可。
5.1 请求数据 - 发现偏移量
import pprint
import re
import ddddocr
import parsel
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36',
}
def send_request(url):
"""
@param url: 请求地址
@return: 字体图片地址, 解析后的数据
"""
response = requests.get(url=url, headers=headers)
html_data = response.text
with open('数据偏移的网页.html', mode='w', encoding='utf-8') as f:
f.write(html_data)
"""解析字体图片地址"""
#
# 5.2 构建字体映射规则
字体的偏移量数据我们可以在标签中可以看到,根据偏移量数据在字体文件图片中定位到特定的位置显示数字。因此我们需要分析每一个字体图片中每个字的偏移规则,然后使用OCR识图模块识别文字,将其字体关系一一映射出来。
- 通过分析,偏移量的偏移规律从
-0px开始,每个字体数字偏移间隔为-21.4px,分析思路如下图:

- 因为字体文件是一张图片,而且每次都会随时动态改变字体顺序,因此咱们可以使用识图OCR模块识图,不管怎么变,我们都会实时识别,具体代码如下所示:
import pprint
import re
import ddddocr
import parsel
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36',
}
def send_request(url):
"""
@param url: 请求地址
@return: 字体图片地址, 解析后的数据
"""
response = requests.get(url=url, headers=headers)
html_data = response.text
with open('数据偏移的网页.html', mode='w', encoding='utf-8') as f:
f.write(html_data)
"""解析字体图片地址"""
#
# 5.3 替换字体
import pprint
import re
import ddddocr
import parsel
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36',
}
def send_request(url):
"""
@param url: 请求地址
@return: 字体图片地址, 解析后的数据
"""
response = requests.get(url=url, headers=headers)
html_data = response.text
with open('数据偏移的网页.html', mode='w', encoding='utf-8') as f:
f.write(html_data)
"""解析字体图片地址"""
#
# 替换字体后,发现有的数据任然替换不了,后续通过分析发现某些页面中会有多套字体图片引用,每套字体的偏移规则不一样,后续通过分析每套字体偏移规则刷字体替换即可,思路和上诉情况一样。

5.4 多套字体
import pprint
import re
import ddddocr
import parsel
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36',
}
def decode_text(mapping, datas):
"""
替换字体数据
@param mapping: 字体映射规则
@param datas: 数据
@return: 替换后的数据
"""
for data in datas:
ret_list = [] # 存放偏移结果替换数据
for move in data['price_list']:
print('偏移量:', move)
value = mapping.get(move, move) # 字典有uni这个键就获取其值, 没有就返回设置的默认值char
ret_list.append(value)
# 重写数据
data['price_list'] = ret_list
return datas
def get_font(font_url, font_rule):
"""
请求字体图片数据, 构建字体映射规则
@param font_url: 字体图片地址
@param font_rule: 分析出来的字体偏移规则
@return: 返回字体映射规则
"""
font_data = requests.get(url=font_url, headers=headers).content
with open('font.png', mode='wb') as f:
f.write(font_data)
"""ddddocr识别图片文字"""
ocr = ddddocr.DdddOcr(beta=True) # 指定识别模型
res = ocr.classification(font_data)
print('字体图片识别结果:', res)
"""构建字体映射规则"""
font_rules = dict(zip(font_rule, res))
return font_rules
def send_request(url):
"""
@param url: 请求地址
@return: 字体图片地址, 解析后的数据
"""
response = requests.get(url=url, headers=headers)
html_data = response.text
with open('数据偏移的网页.html', mode='w', encoding='utf-8') as f:
f.write(html_data)
"""解析字体图片地址"""
#
#