BigQuery Clustered Table 简介 - 聚簇表
Clustered Table的定义
聚簇可以提高某些类型的查询(例如,使用过滤条件子句的查询和聚合数据的查询)的性能。当通过查询作业或加载作业将数据写入聚簇表时,BigQuery 会使用聚簇列中的值对这些数据进行排序。这些值用于将数据整理到 BigQuery 存储的多个块中。当您提交的查询包含基于聚簇列过滤数据的子句时,BigQuery 会使用已排序的块来避免扫描不必要的数据。 如果表或分区低于 1 GB,则聚簇表和未聚簇表之间的查询性能可能不会有显著差异。
以下是创建聚簇表的示例:
CREATE TABLE dataset.clustered_table
(
column1 INT64,
column2 STRING,
column3 DATE,
...
)
CLUSTER BY column1;
在上面的示例中,通过将column1列指定为聚簇键,dataset.clustered_table将按照column1的值进行排序和分组。
值得注意的是,创建聚簇表是一个一次性的操作,无法在表创建后更改聚簇键。如果需要更改聚簇键,您需要创建一个新的聚簇表并将数据导入其中。
通俗点来讲, Clustered表就是存放数据会已 设定的 字段来排序, 这样以这个字段来做filter 就不用全表扫描了(2分法?), 跟索引的原理类似。
还有 Clustered 表和分区表 并不冲突, 1张表既可以分区 也可以 Cluster , 不过如何分区和Cluster 都是同1个列的我觉得意义不大, 如果是两个不同的field的话代表查询时要同时加上这个两个field的filter, 总之看实际需求!
准备测试数据
本码农发文从不只发定义, 既然上面说了大数量量才有效果, 我们就准备个大的
[gateman@manjaro-x13 chapter-02]$ ls -lh
total 401M
-rw-r--r-- 1 gateman gateman 401M Dec 24 01:24 automobiles.csv
-rwxrwxrwx 1 gateman gateman 2.7K May 5 2022 chapter-02-steps.sql
-rwxrwxrwx 1 gateman gateman 250 May 5 2022 link_to_automobiles_dataset.txt
[gateman@manjaro-x13 chapter-02]$ head automobiles.csv
maker,model,mileage,manufacture_year,engine_displacement,engine_power,body_type,color_slug,stk_year,transmission,door_count,seat_count,fuel_type,date_created,date_last_seen,price_eur
ford,galaxy,151000,2011,2000,103,,,None,man,5,7,diesel,2015-11-14 18:10:06.838319+00,2016-01-27 20:40:15.46361+00,10584.75
skoda,octavia,143476,2012,2000,81,,,None,man,5,5,diesel,2015-11-14 18:10:06.853411+00,2016-01-27 20:40:15.46361+00,8882.31
bmw,,97676,2010,1995,85,,,None,man,5,5,diesel,2015-11-14 18:10:06.861792+00,2016-01-27 20:40:15.46361+00,12065.06
skoda,fabia,111970,2004,1200,47,,,None,man,5,5,gasoline,2015-11-14 18:10:06.872313+00,2016-01-27 20:40:15.46361+00,2960.77
skoda,fabia,128886,2004,1200,47,,,None,man,5,5,gasoline,2015-11-14 18:10:06.880335+00,2016-01-27 20:40:15.46361+00,2738.71
skoda,fabia,140932,2003,1200,40,,,None,man,5,5,gasoline,2015-11-14 18:10:06.894643+00,2016-01-27 20:40:15.46361+00,1628.42
skoda,fabia,167220,2001,1400,74,,,None,man,5,5,gasoline,2015-11-14 18:10:06.915376+00,2016-01-27 20:40:15.46361+00,2072.54
bmw,,148500,2009,2000,130,,,None,auto,5,5,diesel,2015-11-14 18:10:06.924123+00,2016-01-27 20:40:15.46361+00,10547.74
skoda,octavia,105389,2003,1900,81,,,None,man,5,5,diesel,2015-11-14 18:10:06.936239+00,2016-01-27 20:40:15.46361+00,4293.12
[gateman@manjaro-x13 chapter-02]$ wc -l automobiles.csv
3552913 automobiles.csv
[gateman@manjaro-x13 chapter-02]$
如上图, 有个automobile.csv 的测试数据集
400 多MB
355万行
用libreOffice 打开这个csv 直接提示数据函数超过了1,048,576的上限(2的20次方), 只能打开1,048,576 部分的数据。
别笑, 微软的Excel也是这个上限, 而且LibreOffice 还能对这个1,048,576 正常作处理。
LibreOffice 的确神器, 相比之下另1个office 软件 OnlyOffice 直接报错内存不够。
上传数据表到BigQuery
[gateman@manjaro-x13 chapter-02]$ bq load --autodetect --source_format=CSV DS2.automobile_o automobiles.csv
Updates are available for some Google Cloud CLI components. To install them,
please run:
$ gcloud components update
/home/gateman/devtools/google-cloud-sdk/platform/bq/bq.py:17: DeprecationWarning: 'pipes' is deprecated and slated for removal in Python 3.13
import pipes
Upload complete.
Waiting on bqjob_r3a61ac818de36f56_0000018c97cbb415_1 ... (12s) Current status: DONE
[gateman@manjaro-x13 chapter-02]$ bq show DS2.automobile_o
/home/gateman/devtools/google-cloud-sdk/platform/bq/bq.py:17: DeprecationWarning: 'pipes' is deprecated and slated for removal in Python 3.13
import pipes
Table jason-hsbc:DS2.automobile_o
Last modified Schema Total Rows Total Bytes Expiration Time Partitioning Clustered Fields Total Logical Bytes Total Physical Bytes Labels
----------------- --------------------------------- ------------ ------------- ------------ ------------------- ------------------ --------------------- ---------------------- --------
24 Dec 01:51:31 |- maker: string 3552912 305423773 305423773 71803365
|- model: string
|- mileage: integer
|- manufacture_year: integer
|- engine_displacement: integer
|- engine_power: integer
|- body_type: string
|- color_slug: string
|- stk_year: string
|- transmission: string
|- door_count: string
|- seat_count: string
|- fuel_type: string
|- date_created: timestamp
|- date_last_seen: timestamp
|- price_eur: float
这样我们就得到1个355万行的非分区和非clustered的表. 表名: automobile_o
创建1个具有相同数据的Cluster表
需求是, 我想这个Clustered表的是按maker, manufacture_year (厂家和生产年份) 来排序存储的.
方法1: 使用bq command 上传多次, 但是加上–clustering_fileds 的参数
[gateman@manjaro-x13 chapter-02]$ bq load --autodetect --source_format=CSV --clustering_fields=maker,manufacture_year DS2.automobile_c automobiles.csv
/home/gateman/devtools/google-cloud-sdk/platform/bq/bq.py:17: DeprecationWarning: 'pipes' is deprecated and slated for removal in Python 3.13
import pipes
Upload complete.
Waiting on bqjob_r1b1de085f8ee2e04_0000018c982d988a_1 ... (10s) Current status: DONE
[gateman@manjaro-x13 chapter-02]$ bq show DS2.automobile_c
/home/gateman/devtools/google-cloud-sdk/platform/bq/bq.py:17: DeprecationWarning: 'pipes' is deprecated and slated for removal in Python 3.13
import pipes
Table jason-hsbc:DS2.automobile_c
Last modified Schema Total Rows Total Bytes Expiration Time Partitioning Clustered Fields Total Logical Bytes Total Physical Bytes Labels
----------------- --------------------------------- ------------ ------------- ------------ ------------------- ------------------------- --------------------- ---------------------- --------
24 Dec 03:38:30 |- maker: string 3552912 305423773 maker, manufacture_year 305423773
|- model: string
|- mileage: integer
|- manufacture_year: integer
|- engine_displacement: integer
|- engine_power: integer
|- body_type: string
|- color_slug: string
|- stk_year: string
|- transmission: string
|- door_count: string
|- seat_count: string
|- fuel_type: string
|- date_created: timestamp
|- date_last_seen: timestamp
|- price_eur: float
方法2: 用sql 基于已存在的表创建
create table DS2.automobile_c2
cluster by maker, manufacture_year
as
select * from DS2.automobile_o
效果是一样的
[gateman@manjaro-x13 chapter-02]$ bq show DS2.automobile_c2
/home/gateman/devtools/google-cloud-sdk/platform/bq/bq.py:17: DeprecationWarning: 'pipes' is deprecated and slated for removal in Python 3.13
import pipes
Table jason-hsbc:DS2.automobile_c2
Last modified Schema Total Rows Total Bytes Expiration Time Partitioning Clustered Fields Total Logical Bytes Total Physical Bytes Labels
----------------- --------------------------------- ------------ ------------- ------------ ------------------- ------------------------- --------------------- ---------------------- --------
24 Dec 03:38:04 |- maker: string 3552912 305423773 maker, manufacture_year 305423773
|- model: string
|- mileage: integer
|- manufacture_year: integer
|- engine_displacement: integer
|- engine_power: integer
|- body_type: string
|- color_slug: string
|- stk_year: string
|- transmission: string
|- door_count: string
|- seat_count: string
|- fuel_type: string
|- date_created: timestamp
|- date_last_seen: timestamp
|- price_eur: float
比较查询性能
我们已经同时具有 一般表 automobile_o 和 clustered 表automobile_c 接下来就是比较查询性能了
当然国际管理, 查询之前都必须禁用cache !

首先先检查表大小
[gateman@manjaro-x13 chapter-02]$ bq show DS2.automobile_o
/home/gateman/devtools/google-cloud-sdk/platform/bq/bq.py:17: DeprecationWarning: 'pipes' is deprecated and slated for removal in Python 3.13
import pipes
Table jason-hsbc:DS2.automobile_o
Last modified Schema Total Rows Total Bytes Expiration Time Partitioning Clustered Fields Total Logical Bytes Total Physical Bytes Labels
----------------- --------------------------------- ------------ ------------- ------------ ------------------- ------------------ --------------------- ---------------------- --------
24 Dec 01:51:31 |- maker: string 3552912 305423773 305423773 71803365
|- model: string
|- mileage: integer
|- manufacture_year: integer
|- engine_displacement: integer
|- engine_power: integer
|- body_type: string
|- color_slug: string
|- stk_year: string
|- transmission: string
|- door_count: string
|- seat_count: string
|- fuel_type: string
|- date_created: timestamp
|- date_last_seen: timestamp
|- price_eur: float
[gateman@manjaro-x13 chapter-02]$ bq show DS2.automobile_c
/home/gateman/devtools/google-cloud-sdk/platform/bq/bq.py:17: DeprecationWarning: 'pipes' is deprecated and slated for removal in Python 3.13
import pipes
Table jason-hsbc:DS2.automobile_c
Last modified Schema Total Rows Total Bytes Expiration Time Partitioning Clustered Fields Total Logical Bytes Total Physical Bytes Labels
----------------- --------------------------------- ------------ ------------- ------------ ------------------- ------------------------- --------------------- ---------------------- --------
24 Dec 03:38:30 |- maker: string 3552912 305423773 maker, manufacture_year 305423773 66970872
|- model: string
|- mileage: integer
|- manufacture_year: integer
|- engine_displacement: integer
|- engine_power: integer
|- body_type: string
|- color_slug: string
|- stk_year: string
|- transmission: string
|- door_count: string
|- seat_count: string
|- fuel_type: string
|- date_created: timestamp
|- date_last_seen: timestamp
|- price_eur: float
可以看出两个表具有相同的schema, 相同的数据行和数据大小, 305423773 bytes = 291.27 MB
先看正常表 automobile_o
无论是select * from DS2.automobile_o 还是 select * from DS2.automobile_o where maker=‘bmw’
的处理数据都是291.27MB (全表处理) , 正常操作, 相当不省钱
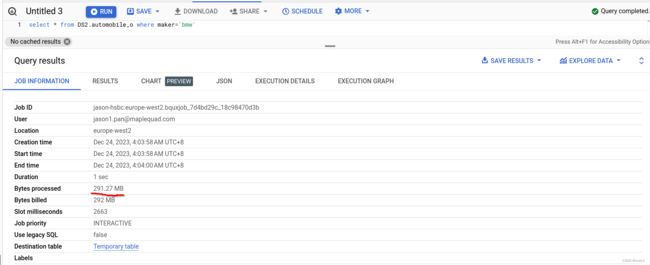
好了, 下面对比查询clustered 表 DS2.automobile_c

当我们输入sql时, web_ui 预估的will process 数据还是291.27MB? 这是因为跟分区表不一样, bigquery在查询之前并不能准确预估clustered 表的预估数据。
因为分区表可以明白地根据查询条件得到sql 将在那几个表分区里查询, 而分区表存在多少个分区, 每个分区的数据行这些元数据BigQuery是清楚的, 其他无关表分区可以忽略
但是, clustered表的原理是数据按照某个or若干列的排序存放。
例如上面的sql条件是maker=‘bmw’, 在clustered表中的 所有bmw 的数据都应该存放一起, 但是BigQuery并没有这些数据的元数据, 例如bmw的数据有多少行, 大概占全表的什么位置, 这些数据都要执行知道才知道, 所以这里预估的will process就是全表了
但是,当我们执行这条数据后, 在真正的query信息得到实际处理的data 量是99 MB, Clustered 生效!
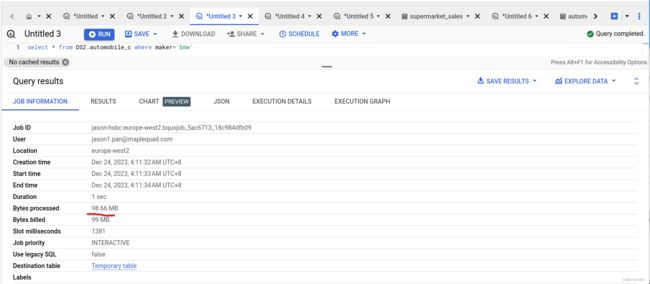
宝马毕竟是大厂, 如果查询条件换成冷门豪车阿士顿马田, 数据处理量会更加少
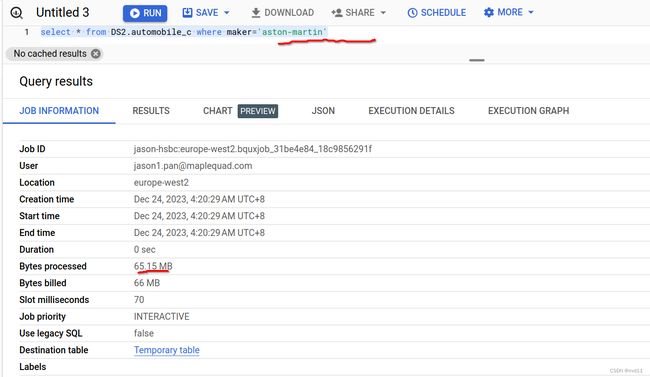
下一条sql
select * from DS2.automobile_c where manufacture_year<1994
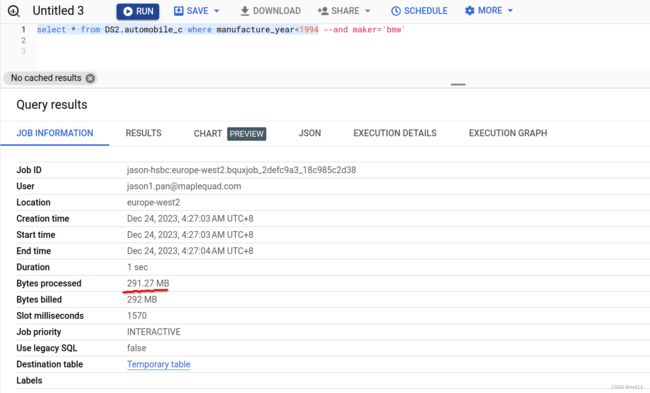
结果还是全表扫描
因为虽然manufacture_year 也是clustered列的一部分, 但是存储排序是先拍maker 再排 manufacture_year, 如果只查询manufacture_year, 还是会导致全表扫描, 跟索引的最左原则一样。
结下来
两个列一齐查
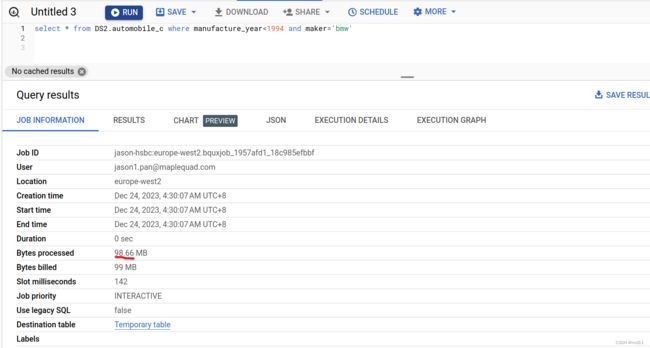
跟只差maker 的处理数据量居然一样, 可能我的测试数据样本还不足够大的原因。
分区表和Clustered 一齐上
既然要查两个field
那么我就建1个 用manufacture_year 来分区, maker来cluster的表, 作为对比
首先查出 这个表的manufacture_year 的上下限
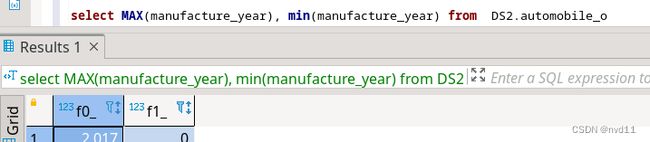
0 到2017
然后我们用下面的sql来建一张分区和clustered表 DS2.automobile_pc
create table DS2.automobile_pc
partition by
Range_bucket(manufacture_year, generate_array(0,2017,10))
cluster by maker
as
select * from DS2.automobile_o
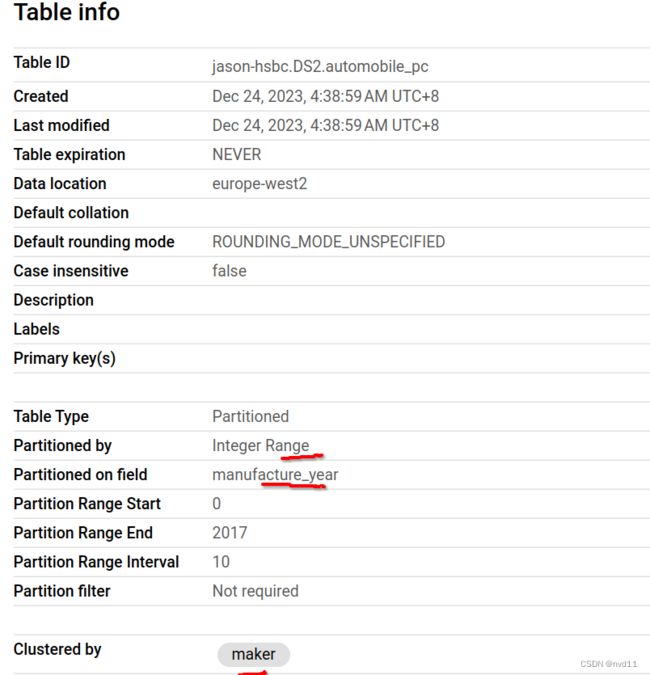
这时 当我们输入sql时, bq 已经能预估分区后的will process数据是51.52MB了, 但是在这些分区, 相同maker的数据还是黏在一齐的, 也就是将bq不必要扫描每个完整表分区

我们执行它
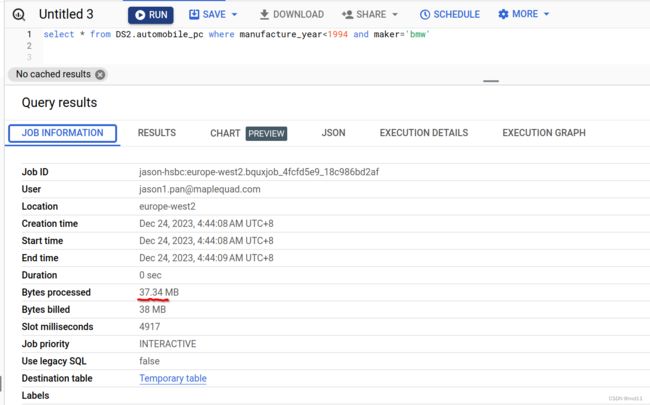
可以看出最终只process了 37MB数据比预估的要少, 看来如果固定用两个field来查询的话, 用分区 + clustered 表的确很暴力有效!!