AI绘画stable diffusion及webui可视化工具安装使用
如果只是想体验stable diffusion 绘画功能不必按照本教程安装可以移步下面B站Up主课程安装别人配置好的整合包:B站第一套系统的AI绘画课!零基础学会Stable Diffusion,这绝对是你看过的最容易上手的AI绘画教程 | SD WebUI 保姆级攻略_哔哩哔哩_bilibili
注意:我是为了了解整个安装使用流程,也是为了后续代码修改,二次编译进行的配置。
AI绘画原理diffusion(扩散), 将图片通过增加噪声的方式进行“扩散”(即让图片变得更模糊),AI通过深度学习神经网络来学习不同风格的图像特征,并使用逆扩散(去噪)的方法,对图片进行二次创作生成。

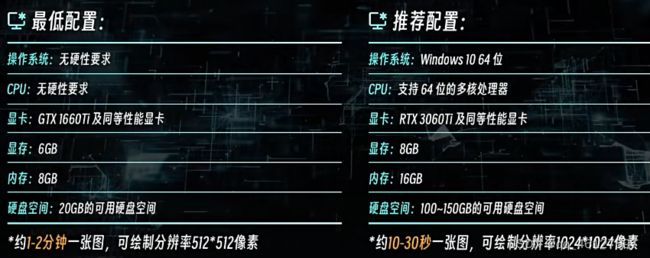
玩转stable diffusion电脑最低配置要求
可以现在anaconda下创建一个虚拟环境如下面SD是我的虚拟环境
一、stable diffusion-webui安装前置应用
1、python 3.10.6版本(可以直接去官网找对应版本下载)

2、git 实现软件安装及更新的工具

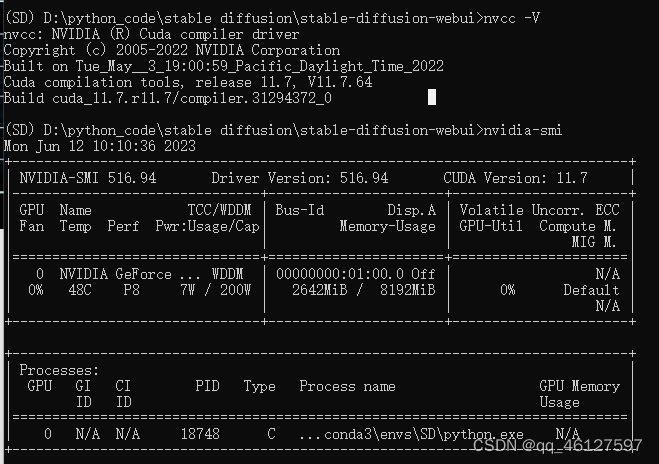
3、CUDN 查看显卡支持的cudn版本(nvidia-smi),记住版本号然后去官网下载
二、在github上下载stable diffusion-webui的项目文件
1、在电脑的D盘或E盘创建一个项目文件夹,后续可以把stable diffusion相关项目文件放在这个文件夹下方便管理。
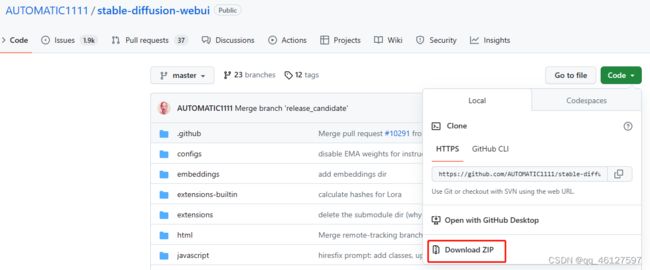
方法一、直接下载项目的压缩包然后解压到相应文件夹下
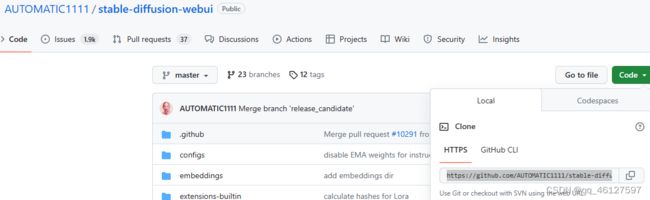
方法二、通过git clone下载项目文件

以上安装完后不要执行webui.bat。 webui.bat运行后会在你的系统中创建一个它配置的虚拟环境然后安装一系列的依赖软件包。
三、去github下载stable diffusion源码

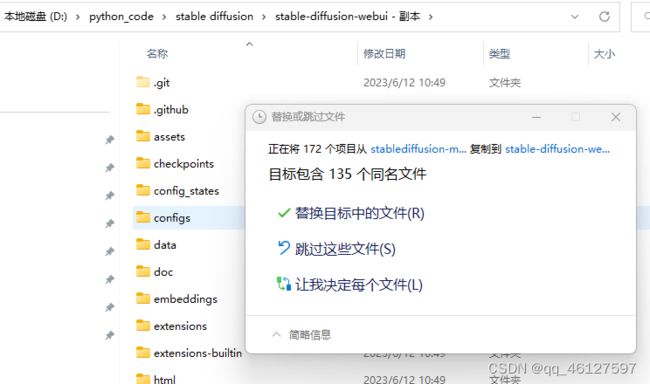
1、 将下载的stablediffusion-main中的所有内容拷贝到stable-diffusion-webui的项目文件中,替换目标中的文件。

2、pip install requirements.txt 安装依赖软件包
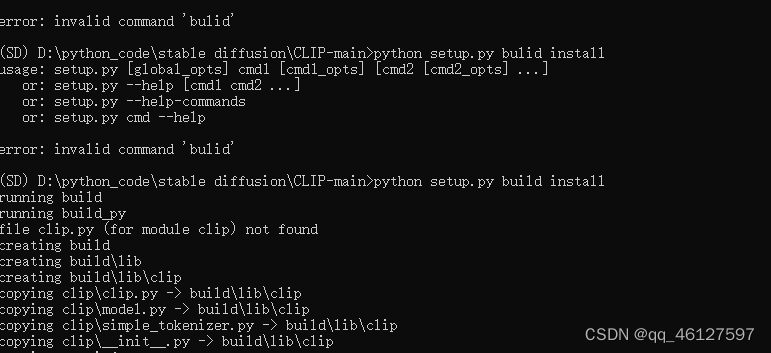
3、运行python webui.py 报错 如报错没有No module name 'CLIP'
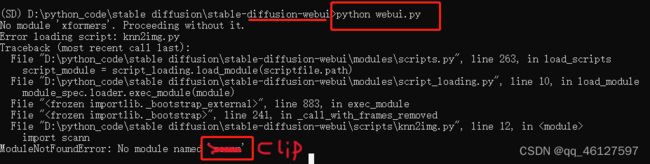
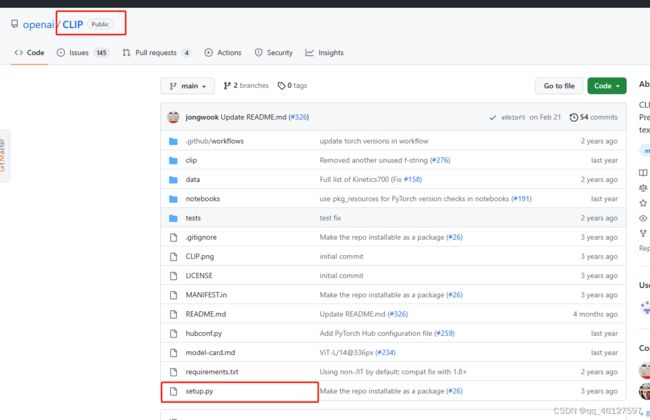
去github搜索CLIP,可以看到CLIP是一个可编译的文件setup.py
有些如CLIP的包是没有whl可pip install安装的编译好的文件,如CLIP只有tar包
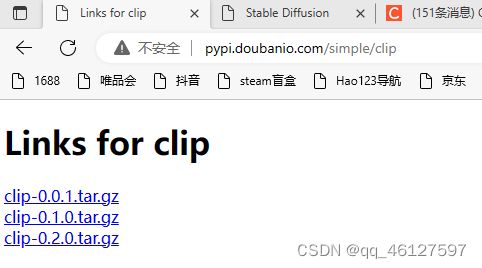
解决方法:github下载clip的项目文件放在stable-diffusion-webui同级目录下
再终端进入CLIP-main执行python setup.py build install 进行编译
后面所遇到到的问题大致一致,有些可以直接pip 安装,有些无法直接安装的安装此方法进行编译安装。
四、在终端运行python webui.py 得到webui的url,将url复制到浏览器中打开就可以体验stable diffusion了。
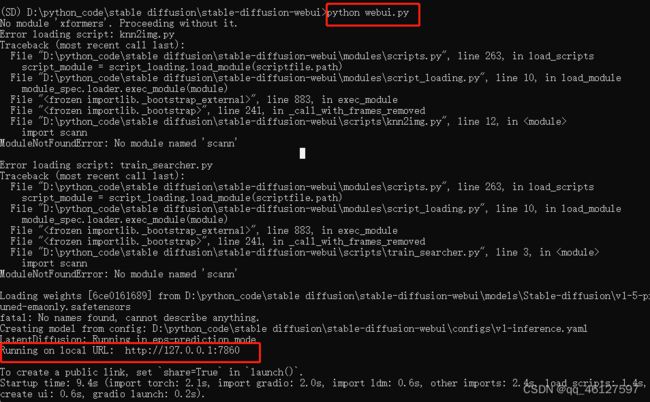 效果如下:
效果如下: 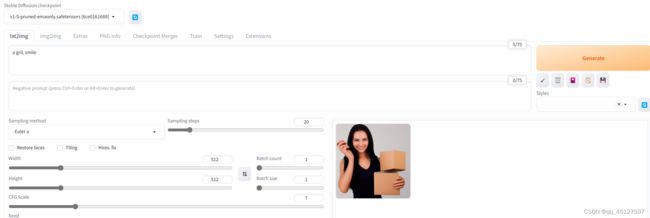
五、stable diffusion扩展插件的安装
1)ControlNet插件:控制姿态等,github上搜索sd-webui-controlnet,或点击下方链接Mikubill/sd-webui-controlnet: WebUI extension for ControlNet (github.com)
controlnet中内置了很多功能,如canny, openopse,instructp2p等,其权重文件下载链接如下:https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
2)roop插件:可实现换脸,sd-webui-roop, github链接如下
s0md3v/sd-webui-roop: roop extension for StableDiffusion web-ui (github.com)
3)segment-anything插件:抠图,sd-webui-segment-anything, github链接如下:
continue-revolution/sd-webui-segment-anything: Segment Anything for Stable Diffusion WebUI (github.com)
NSFW:安全审查,如果生成的图片不合规可以通过nsfw将其mask掉。 也是放在stable-diffusion-webui的extensions扩展中。AUTOMATIC1111/stable-diffusion-webui-nsfw-censor: stable-diffusion-webui-nsfw-censor (github.com)
其中权重文件下载CompVis/stable-diffusion-v1-4 at main (huggingface.co) 将其放在CompVis\stable-diffusion-safety-checker目录下
import torch
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from transformers import AutoFeatureExtractor
from PIL import Image
from modules import scripts, shared
safety_model_id = r"D:\Project\stable-diffusion-webui-1.6.0\CompVis\stable-diffusion-safety-checker"
safety_feature_extractor = None
safety_checker = None
def numpy_to_pil(images):
"""
Convert a PyTorch tensor or a batch of tensors to a PIL image.
"""
if images.ndim == 3:
images = images[None, ...]
images = (images * 255).round().to(dtype=torch.uint8)
pil_images = [Image.fromarray(image.permute(1, 2, 0).cpu().numpy()) for image in images]
return pil_images
# check and replace nsfw content
def check_safety(x_image):
global safety_feature_extractor, safety_checker
if safety_feature_extractor is None:
safety_feature_extractor = AutoFeatureExtractor.from_pretrained(safety_model_id)
safety_checker = StableDiffusionSafetyChecker.from_pretrained(safety_model_id)
safety_checker_input = safety_feature_extractor(numpy_to_pil(x_image), return_tensors="pt")
x_checked_image, has_nsfw_concept = safety_checker(images=x_image, clip_input=safety_checker_input.pixel_values)
return x_checked_image, has_nsfw_concept
def censor_batch(x):
x_samples_ddim_numpy = x.cpu().permute(0, 2, 3, 1).numpy()
x_checked_image, has_nsfw_concept = check_safety(x_samples_ddim_numpy)
x = torch.from_numpy(x_checked_image).permute(0, 3, 1, 2)
return x
class NsfwCheckScript(scripts.Script):
def title(self):
return "NSFW check"
def show(self, is_img2img):
return scripts.AlwaysVisible
def postprocess_batch(self, p, *args, **kwargs):
images = kwargs['images']
images[:] = censor_batch(images)[:]
# from PIL import Image
# import torch
# import numpy as np
#
# # 加载你的PNG图像
# image_path = "test.png"
# image = Image.open(image_path)
#
# # 将图像转换为NumPy数组
# image_np = np.array(image)
#
# # 将NumPy数组转换为PyTorch张量
# x_image = torch.tensor(image_np, dtype=torch.float).permute(2, 0, 1) / 255.0
# x_image = x_image.unsqueeze(0) # 添加 batch 维度
#
# # 执行安全检测
# x_checked_image, has_nsfw_concept = check_safety(x_image)
#
# # 现在 x_checked_image 包含经安全检测后的图像,has_nsfw_concept 表示是否包含不安全内容
#
# # 可以根据需要保存经过安全检测后的图像
# x_checked_image_pil = Image.fromarray((x_checked_image[0].permute(1, 2, 0).numpy() * 255).round().astype(np.uint8)).convert("RGB")
# x_checked_image_pil.save("checked_image.png")
# print(123)
# 进一步处理 x_checked_image 或使用 has_nsfw_concept 进行判断
#
# from PIL import Image
# import torch
# import numpy as np
#
# # 请注意:您可以使用一个循环来处理多张图片
# image_paths = ["51.png", "52.png", "53.png", "test.png"]
# output_paths = ["output1.png", "output2.png", "output3.png", "output4.png"]
#
# for i, image_path in enumerate(image_paths):
# # 加载每张PNG图像
# image = Image.open(image_path)
#
# # 将图像转换为NumPy数组
# image_np = np.array(image)
#
# # 将NumPy数组转换为PyTorch张量
# x_image = torch.tensor(image_np, dtype=torch.float).permute(2, 0, 1) / 255.0
# x_image = x_image.unsqueeze(0) # 添加 batch 维度
#
# # 执行安全检测
# x_checked_image, has_nsfw_concept = check_safety(x_image)
#
# # 保存经过安全检测后的图像
# x_checked_image_pil = Image.fromarray((x_checked_image[0].permute(1, 2, 0).numpy() * 255).round().astype(np.uint8)).convert("RGB")
# x_checked_image_pil.save(output_paths[i])
#
# # 完成处理多张图片并保存的操作
from PIL import Image
import torch
import numpy as np
def process_images(image_paths, output_paths, safety_model_id):
for i, image_path in enumerate(image_paths):
# 加载每张PNG图像
image = Image.open(image_path)
# 将图像转换为NumPy数组
image_np = np.array(image)
# 将NumPy数组转换为PyTorch张量
x_image = torch.tensor(image_np, dtype=torch.float).permute(2, 0, 1) / 255.0
x_image = x_image.unsqueeze(0) # 添加 batch 维度
# 执行安全检测
x_checked_image, has_nsfw_concept = check_safety(x_image)
# 保存经过安全检测后的图像
x_checked_image_pil = Image.fromarray((x_checked_image[0].permute(1, 2, 0).numpy() * 255).round().astype(np.uint8)).convert("RGB")
x_checked_image_pil.save(output_paths[i])
# 示例用法
image_paths = ["51.png", "52.png", "53.png", "54.png"]
output_paths = ["output1.png", "output2.png", "output3.png", "output4.png"]
safety_model_id = r"D:\Project\stable-diffusion-webui-1.6.0\CompVis\stable-diffusion-safety-checker"
process_images(image_paths, output_paths, safety_model_id)