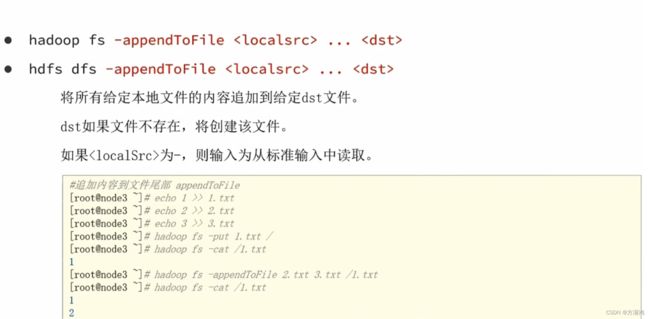
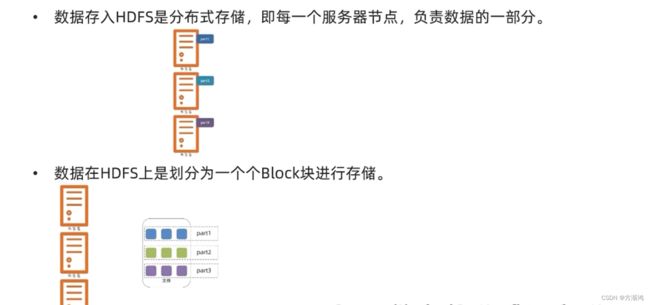
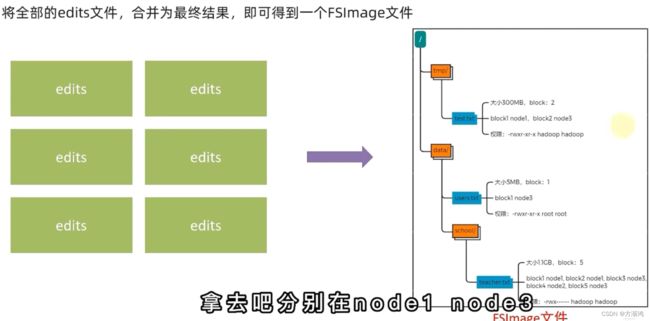
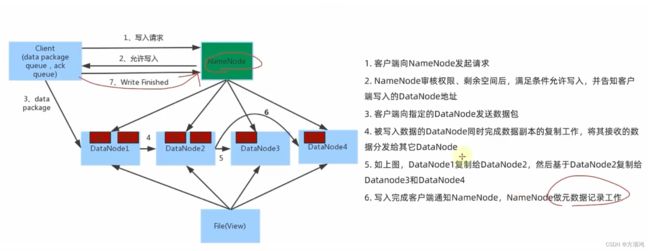
- 系统学习Python——并发模型和异步编程:进程、线程和GIL
分类目录:《系统学习Python》总目录在文章《并发模型和异步编程:基础知识》我们简单介绍了Python中的进程、线程和协程。本文就着重介绍Python中的进程、线程和GIL的关系。Python解释器的每个实例都是一个进程。使用multiprocessing或concurrent.futures库可以启动额外的Python进程。Python的subprocess库用于启动运行外部程序(不管使用何种
- Flask框架入门:快速搭建轻量级Python网页应用
「已注销」
python-AIpython基础网站网络pythonflask后端
转载:Flask框架入门:快速搭建轻量级Python网页应用1.Flask基础Flask是一个使用Python编写的轻量级Web应用框架。它的设计目标是让Web开发变得快速简单,同时保持应用的灵活性。Flask依赖于两个外部库:Werkzeug和Jinja2,Werkzeug作为WSGI工具包处理Web服务的底层细节,Jinja2作为模板引擎渲染模板。安装Flask非常简单,可以使用pip安装命令
- Python Flask 框架入门:快速搭建 Web 应用的秘诀
Python编程之道
Python人工智能与大数据Python编程之道pythonflask前端ai
PythonFlask框架入门:快速搭建Web应用的秘诀关键词Flask、微框架、路由系统、Jinja2模板、请求处理、WSGI、Web开发摘要想快速用Python搭建一个灵活的Web应用?Flask作为“微框架”代表,凭借轻量、可扩展的特性,成为初学者和小型项目的首选。本文将从Flask的核心概念出发,结合生活化比喻、代码示例和实战案例,带你一步步掌握:如何用Flask搭建第一个Web应用?路由
- python_虚拟环境
阿_焦
python
第一、配置虚拟环境:virtualenv(1)pipvirtualenv>安装虚拟环境包(2)pipinstallvirtualenvwrapper-win>安装虚拟环境依赖包(3)c盘创建虚拟目录>C:\virtualenv>配置环境变量【了解一下】:(1)如何使用virtualenv创建虚拟环境a、cd到C:\virtualenv目录下:b、mkvirtualenvname>创建虚拟环境nam
- Python爱心光波
系列文章序号直达链接Tkinter1Python李峋同款可写字版跳动的爱心2Python跳动的双爱心3Python蓝色跳动的爱心4Python动漫烟花5Python粒子烟花Turtle1Python满屏飘字2Python蓝色流星雨3Python金色流星雨4Python漂浮爱心5Python爱心光波①6Python爱心光波②7Python满天繁星8Python五彩气球9Python白色飘雪10Pyt
- Python流星雨
Want595
python开发语言
文章目录系列文章写在前面技术需求完整代码代码分析1.模块导入2.画布设置3.画笔设置4.颜色列表5.流星类(Star)6.流星对象创建7.主循环8.流星运动逻辑9.视觉效果10.总结写在后面系列文章序号直达链接表白系列1Python制作一个无法拒绝的表白界面2Python满屏飘字表白代码3Python无限弹窗满屏表白代码4Python李峋同款可写字版跳动的爱心5Python流星雨代码6Python
- 分布式学习笔记_04_复制模型
NzuCRAS
分布式学习笔记架构后端
常见复制模型使用复制的目的在分布式系统中,数据通常需要被分布在多台机器上,主要为了达到:拓展性:数据量因读写负载巨大,一台机器无法承载,数据分散在多台机器上仍然可以有效地进行负载均衡,达到灵活的横向拓展高容错&高可用:在分布式系统中单机故障是常态,在单机故障的情况下希望整体系统仍然能够正常工作,这时候就需要数据在多台机器上做冗余,在遇到单机故障时能够让其他机器接管统一的用户体验:如果系统客户端分布
- Python之七彩花朵代码实现
PlutoZuo
Pythonpython开发语言
Python之七彩花朵代码实现文章目录Python之七彩花朵代码实现下面是一个简单的使用Python的七彩花朵。这个示例只是一个简单的版本,没有很多高级功能,但它可以作为一个起点,你可以在此基础上添加更多功能。importturtleastuimportrandomasraimportmathtu.setup(1.0,1.0)t=tu.Pen()t.ht()colors=['red','skybl
- Python 脚本最佳实践2025版
前文可以直接把这篇文章喂给AI,可以放到AI角色设定里,也可以直接作为提示词.这样,你只管提需求,写脚本就让AI来.概述追求简洁和清晰:脚本应简单明了。使用函数(functions)、常量(constants)和适当的导入(import)实践来有逻辑地组织你的Python脚本。使用枚举(enumerations)和数据类(dataclasses)等数据结构高效管理脚本状态。通过命令行参数增强交互性
- (Python基础篇)了解和使用分支结构
EternityArt
基础篇python
目录一、引言二、Python分支结构的类型与语法(一)if语句(单分支)(二)if-else语句(双分支)(三)if-elif-else语句(多分支)三、分支结构的应用场景(一)提示用户输入用户名,然后再提示输入密码,如果用户名是“admin”并且密码是“88888”则提示正确,否则,如果用户名不是admin还提示用户用户名不存在,(二)提示用户输入用户名,然后再提示输入密码,如果用户名是“adm
- (Python基础篇)循环结构
EternityArt
基础篇python
一、什么是Python循环结构?循环结构是编程中重复执行代码块的机制。在Python中,循环允许你:1.迭代处理数据:遍历列表、字典、文件内容等。2.自动化重复任务:如批量处理数据、生成序列等。3.控制执行流程:根据条件决定是否继续或终止循环。二、为什么需要循环结构?假设你需要打印1到100的所有偶数:没有循环:需手动编写100行print()语句。print(0)print(2)print(4)
- (Python基础篇)字典的操作
EternityArt
基础篇python开发语言
一、引言在Python编程中,字典(Dictionary)是一种极具灵活性的数据结构,它通过“键-值对”(key-valuepair)的形式存储数据,如同现实生活中的字典——通过“词语(键)”快速查找“释义(值)”。相较于列表和元组的有序索引访问,字典的优势在于基于键的快速查找,这使得它在处理需要频繁通过唯一标识获取数据的场景中极为高效。掌握字典的操作,能让我们更高效地组织和管理复杂数据,是Pyt
- Python七彩花朵
Want595
python开发语言
系列文章序号直达链接Tkinter1Python李峋同款可写字版跳动的爱心2Python跳动的双爱心3Python蓝色跳动的爱心4Python动漫烟花5Python粒子烟花Turtle1Python满屏飘字2Python蓝色流星雨3Python金色流星雨4Python漂浮爱心5Python爱心光波①6Python爱心光波②7Python满天繁星8Python五彩气球9Python白色飘雪10Pyt
- php 高并发下日志量巨大,如何高效采集、存储、分析
贵哥的编程之路(热爱分享 为后来者)
PHP语言经典程序100题php开发语言
1.问题背景高并发系统每秒产生大量日志(如访问日志、错误日志、业务日志等)。单机写入、存储、分析能力有限,容易成为瓶颈。需要支持实时采集、分布式存储、快速检索与分析。2.主流架构方案一、分布式日志采集架构[应用服务器(PHP等)]|v[日志采集Agent(如Filebeat、Fluentd、Logstash)]|v[消息队列/缓冲(如Kafka、Redis、RabbitMQ)]|v[日志存储(如E
- 用OpenCV标定相机内参应用示例(C++和Python)
下面是一个完整的使用OpenCV进行相机内参标定(CameraCalibration)的示例,包括C++和Python两个版本,基于棋盘格图案标定。一、目标:相机标定通过拍摄多张带有棋盘格图案的图像,估计相机的内参:相机矩阵(内参)K畸变系数distCoeffs可选外参(R,T)标定精度指标(如重投影误差)二、棋盘格参数设置(根据自己的棋盘格设置):棋盘格角点数:9x6(内角点,9列×6行);每个
- Anaconda 详细下载与安装教程
Anaconda详细下载与安装教程1.简介Anaconda是一个用于科学计算的开源发行版,包含了Python和R的众多常用库。它还包括了conda包管理器,可以方便地安装、更新和管理各种软件包。2.下载Anaconda2.1访问官方网站首先,打开浏览器,访问Anaconda官方网站。2.2选择适合的版本在页面中,你会看到两个主要的下载选项:AnacondaIndividualEdition:适用于
- python中 @注解 及内置注解 的使用方法总结以及完整示例
慧一居士
Pythonpython
在Python中,装饰器(Decorator)使用@符号实现,是一种修改函数/类行为的语法糖。它本质上是一个高阶函数,接受目标函数作为参数并返回包装后的函数。Python也提供了多个内置装饰器,如@property、@staticmethod、@classmethod等。一、核心概念装饰器本质:@decorator等价于func=decorator(func)执行时机:在函数/类定义时立即执行装饰
- Python中的静态方法和类方法详解
在Python中,`@staticmethod`和`@classmethod`是两种装饰器,它们用于定义类中的方法,但是它们的行为和用途有所不同。###@staticmethod`@staticmethod`装饰器用于定义一个静态方法。静态方法不接收类或实例的引用作为第一个参数,因此它不能访问类的状态或实例的状态。静态方法可以看作是与类关联的普通函数,但它们可以通过类名直接调用。classMath
- Python中类静态方法:@classmethod/@staticmethod详解和实战示例
在Python中,类方法(@classmethod)和静态方法(@staticmethod)是类作用域下的两种特殊方法。它们使用装饰器定义,并且与实例方法(deffunc(self))的行为有所不同。1.三种方法的对比概览方法类型是否访问实例(self)是否访问类(cls)典型用途实例方法✅是❌否访问对象属性类方法@classmethod❌否✅是创建类的替代构造器,访问类变量等静态方法@stati
- Python多版本管理与pip升级全攻略:解决冲突与高效实践
码界奇点
Pythonpythonpip开发语言python3.11源代码管理虚拟现实依赖倒置原则
引言Python作为最流行的编程语言之一,其版本迭代速度与生态碎片化给开发者带来了巨大挑战。据统计,超过60%的Python开发者需要同时维护基于Python3.6+和Python2.7的项目。本文将系统解决以下核心痛点:如何安全地在同一台机器上管理多个Python版本pip依赖冲突的根治方案符合PEP标准的生产环境最佳实践第一部分:Python多版本管理核心方案1.1系统级多版本共存方案Wind
- 基于Python的健身数据分析工具的搭建流程day1
weixin_45677320
python开发语言数据挖掘爬虫
基于Python的健身数据分析工具的搭建流程分数据挖掘、数据存储和数据分析三个步骤。本文主要介绍利用Python实现健身数据分析工具的数据挖掘部分。第一步:加载库加载本文需要的库,如下代码所示。若库未安装,请按照python如何安装各种库(保姆级教程)_python安装库-CSDN博客https://blog.csdn.net/aobulaien001/article/details/133298
- 数字孪生技术为UI前端注入新活力:实现产品设计的沉浸式体验
ui设计前端开发老司机
ui
hello宝子们...我们是艾斯视觉擅长ui设计、前端开发、数字孪生、大数据、三维建模、三维动画10年+经验!希望我的分享能帮助到您!如需帮助可以评论关注私信我们一起探讨!致敬感谢感恩!一、引言:从“平面交互”到“沉浸体验”的UI革命当用户在电商APP中翻看3D家具模型却无法感知其与自家客厅的匹配度,当设计师在2D屏幕上绘制汽车内饰却难以预判实际乘坐体验——传统UI设计的“平面化、静态化、割裂感”
- RocketMQ 之死信队列
firepation
RocketMQrocketmq
在分布式消息系统中,消息的可靠传递和处理至关重要。然而,由于各种原因(如消息处理失败、消费超时等),一些消息可能无法被正常消费。这些无法被消费的消息如果不加以处理,会影响系统的稳定性和数据一致性。为了解决这一问题,RocketMQ提供了死信队列(DeadLetterQueue,DLQ)机制。本文将深入探讨RocketMQ的死信队列,包括其实现原理、应用场景以及使用示例。什么是死信队列?死信队列是一
- seaborn又一个扩展heatmapz
qq_21478261
#Python可视化matplotlib
推荐阅读:Pythonmatplotlib保姆级教程嫌Matplotlib繁琐?试试Seaborn!
- NGS测序基础梳理01-文库构建(Library Preparation)
qq_21478261
#生物信息生物学
本文介绍Illumina测序平台文库构建(LibraryPreparation)步骤,文库结构。写作时间:2020.05。推荐阅读:10W字《Python可视化教程1.0》来了!一份由公众号「pythonic生物人」精心制作的PythonMatplotlib可视化系统教程,105页PDFhttps://mp.weixin.qq.com/s/QaSmucuVsS_DR-klfpE3-Q10W字《Rg
- Python 常用内置函数详解(七):dir()函数——获取当前本地作用域中的名称列表或对象的有效属性列表
目录一、功能二、语法和示例一、功能dir()函数获取当前本地作用域中的名称列表或对象的有效属性列表。二、语法和示例dir()函数有两种形式,如果没有实参,则返回当前本地作用域中的名称列表。如果有实参,它会尝试返回该对象的有效属性列表。如果对象有一个名为__dir__()的方法,那么该方法将被调用,并且必须返回一个属性列表。dir()函数的语法格式如下:C:\Users\amoxiang>ipyth
- pythonjson中list操作_Python json.dumps 特殊数据类型的自定义序列化操作
场景描述:Python标准库中的json模块,集成了将数据序列化处理的功能;在使用json.dumps()方法序列化数据时候,如果目标数据中存在datetime数据类型,执行操作时,会抛出异常:TypeError:datetime.datetime(2016,12,10,11,04,21)isnotJSONserializable那么遇到json.dumps序列化不支持的数据类型,该怎么办!首先,
- Python 日期格式转json.dumps的解决方法
douyaoxin
pythonjson开发语言
classDateEncoder(json.JSONEncoder):defdefault(self,obj):ifisinstance(obj,datetime.datetime):returnobj.strftime('%Y-%m-%d%H:%M:%S')elifisinstance(obj,datetime.date):returnobj.strftime("%Y-%m-%d")json.d
- Python 爬虫实战:视频平台播放量实时监控(含反爬对抗与数据趋势预测)
西攻城狮北
python爬虫音视频
一、引言在数字内容蓬勃发展的当下,视频平台的播放量数据已成为内容创作者、营销人员以及行业分析师手中极为关键的情报资源。它不仅能够实时反映内容的受欢迎程度,更能在竞争分析、营销策略制定以及内容优化等方面发挥不可估量的作用。然而,视频平台为了保护自身数据和用户隐私,往往会设置一系列反爬虫机制,对数据爬取行为进行限制。这就向我们发起了挑战:如何巧妙地突破这些限制,同时精准地捕捉并预测播放量的动态变化趋势
- Python技能手册 - 模块module
金色牛神
Pythonpythonwindows开发语言
系列Python常用技能手册-基础语法Python常用技能手册-模块modulePython常用技能手册-包package目录module模块指什么typing数据类型int整数float浮点数str字符串bool布尔值TypeVar类型变量functools高阶函数工具functools.partial()函数偏置functools.lru_cache()函数缓存sorted排序列表排序元组排序
- JAVA中的Enum
周凡杨
javaenum枚举
Enum是计算机编程语言中的一种数据类型---枚举类型。 在实际问题中,有些变量的取值被限定在一个有限的范围内。 例如,一个星期内只有七天 我们通常这样实现上面的定义:
public String monday;
public String tuesday;
public String wensday;
public String thursday
- 赶集网mysql开发36条军规
Bill_chen
mysql业务架构设计mysql调优mysql性能优化
(一)核心军规 (1)不在数据库做运算 cpu计算务必移至业务层; (2)控制单表数据量 int型不超过1000w,含char则不超过500w; 合理分表; 限制单库表数量在300以内; (3)控制列数量 字段少而精,字段数建议在20以内
- Shell test命令
daizj
shell字符串test数字文件比较
Shell test命令
Shell中的 test 命令用于检查某个条件是否成立,它可以进行数值、字符和文件三个方面的测试。 数值测试 参数 说明 -eq 等于则为真 -ne 不等于则为真 -gt 大于则为真 -ge 大于等于则为真 -lt 小于则为真 -le 小于等于则为真
实例演示:
num1=100
num2=100if test $[num1]
- XFire框架实现WebService(二)
周凡杨
javawebservice
有了XFire框架实现WebService(一),就可以继续开发WebService的简单应用。
Webservice的服务端(WEB工程):
两个java bean类:
Course.java
package cn.com.bean;
public class Course {
private
- 重绘之画图板
朱辉辉33
画图板
上次博客讲的五子棋重绘比较简单,因为只要在重写系统重绘方法paint()时加入棋盘和棋子的绘制。这次我想说说画图板的重绘。
画图板重绘难在需要重绘的类型很多,比如说里面有矩形,园,直线之类的,所以我们要想办法将里面的图形加入一个队列中,这样在重绘时就
- Java的IO流
西蜀石兰
java
刚学Java的IO流时,被各种inputStream流弄的很迷糊,看老罗视频时说想象成插在文件上的一根管道,当初听时觉得自己很明白,可到自己用时,有不知道怎么代码了。。。
每当遇到这种问题时,我习惯性的从头开始理逻辑,会问自己一些很简单的问题,把这些简单的问题想明白了,再看代码时才不会迷糊。
IO流作用是什么?
答:实现对文件的读写,这里的文件是广义的;
Java如何实现程序到文件
- No matching PlatformTransactionManager bean found for qualifier 'add' - neither
林鹤霄
java.lang.IllegalStateException: No matching PlatformTransactionManager bean found for qualifier 'add' - neither qualifier match nor bean name match!
网上找了好多的资料没能解决,后来发现:项目中使用的是xml配置的方式配置事务,但是
- Row size too large (> 8126). Changing some columns to TEXT or BLOB
aigo
column
原文:http://stackoverflow.com/questions/15585602/change-limit-for-mysql-row-size-too-large
异常信息:
Row size too large (> 8126). Changing some columns to TEXT or BLOB or using ROW_FORMAT=DYNAM
- JS 格式化时间
alxw4616
JavaScript
/**
* 格式化时间 2013/6/13 by 半仙
[email protected]
* 需要 pad 函数
* 接收可用的时间值.
* 返回替换时间占位符后的字符串
*
* 时间占位符:年 Y 月 M 日 D 小时 h 分 m 秒 s 重复次数表示占位数
* 如 YYYY 4占4位 YY 占2位<p></p>
* MM DD hh mm
- 队列中数据的移除问题
百合不是茶
队列移除
队列的移除一般都是使用的remov();都可以移除的,但是在昨天做线程移除的时候出现了点问题,没有将遍历出来的全部移除, 代码如下;
//
package com.Thread0715.com;
import java.util.ArrayList;
public class Threa
- Runnable接口使用实例
bijian1013
javathreadRunnablejava多线程
Runnable接口
a. 该接口只有一个方法:public void run();
b. 实现该接口的类必须覆盖该run方法
c. 实现了Runnable接口的类并不具有任何天
- oracle里的extend详解
bijian1013
oracle数据库extend
扩展已知的数组空间,例:
DECLARE
TYPE CourseList IS TABLE OF VARCHAR2(10);
courses CourseList;
BEGIN
-- 初始化数组元素,大小为3
courses := CourseList('Biol 4412 ', 'Psyc 3112 ', 'Anth 3001 ');
--
- 【httpclient】httpclient发送表单POST请求
bit1129
httpclient
浏览器Form Post请求
浏览器可以通过提交表单的方式向服务器发起POST请求,这种形式的POST请求不同于一般的POST请求
1. 一般的POST请求,将请求数据放置于请求体中,服务器端以二进制流的方式读取数据,HttpServletRequest.getInputStream()。这种方式的请求可以处理任意数据形式的POST请求,比如请求数据是字符串或者是二进制数据
2. Form
- 【Hive十三】Hive读写Avro格式的数据
bit1129
hive
1. 原始数据
hive> select * from word;
OK
1 MSN
10 QQ
100 Gtalk
1000 Skype
2. 创建avro格式的数据表
hive> CREATE TABLE avro_table(age INT, name STRING)STORE
- nginx+lua+redis自动识别封解禁频繁访问IP
ronin47
在站点遇到攻击且无明显攻击特征,造成站点访问慢,nginx不断返回502等错误时,可利用nginx+lua+redis实现在指定的时间段 内,若单IP的请求量达到指定的数量后对该IP进行封禁,nginx返回403禁止访问。利用redis的expire命令设置封禁IP的过期时间达到在 指定的封禁时间后实行自动解封的目的。
一、安装环境:
CentOS x64 release 6.4(Fin
- java-二叉树的遍历-先序、中序、后序(递归和非递归)、层次遍历
bylijinnan
java
import java.util.LinkedList;
import java.util.List;
import java.util.Stack;
public class BinTreeTraverse {
//private int[] array={ 1, 2, 3, 4, 5, 6, 7, 8, 9 };
private int[] array={ 10,6,
- Spring源码学习-XML 配置方式的IoC容器启动过程分析
bylijinnan
javaspringIOC
以FileSystemXmlApplicationContext为例,把Spring IoC容器的初始化流程走一遍:
ApplicationContext context = new FileSystemXmlApplicationContext
("C:/Users/ZARA/workspace/HelloSpring/src/Beans.xml&q
- [科研与项目]民营企业请慎重参与军事科技工程
comsci
企业
军事科研工程和项目 并非要用最先进,最时髦的技术,而是要做到“万无一失”
而民营科技企业在搞科技创新工程的时候,往往考虑的是技术的先进性,而对先进技术带来的风险考虑得不够,在今天提倡军民融合发展的大环境下,这种“万无一失”和“时髦性”的矛盾会日益凸显。。。。。。所以请大家在参与任何重大的军事和政府项目之前,对
- spring 定时器-两种方式
cuityang
springquartz定时器
方式一:
间隔一定时间 运行
<bean id="updateSessionIdTask" class="com.yang.iprms.common.UpdateSessionTask" autowire="byName" />
<bean id="updateSessionIdSchedule
- 简述一下关于BroadView站点的相关设计
damoqiongqiu
view
终于弄上线了,累趴,戳这里http://www.broadview.com.cn
简述一下相关的技术点
前端:jQuery+BootStrap3.2+HandleBars,全站Ajax(貌似对SEO的影响很大啊!怎么破?),用Grunt对全部JS做了压缩处理,对部分JS和CSS做了合并(模块间存在很多依赖,全部合并比较繁琐,待完善)。
后端:U
- 运维 PHP问题汇总
dcj3sjt126com
windows2003
1、Dede(织梦)发表文章时,内容自动添加关键字显示空白页
解决方法:
后台>系统>系统基本参数>核心设置>关键字替换(是/否),这里选择“是”。
后台>系统>系统基本参数>其他选项>自动提取关键字,这里选择“是”。
2、解决PHP168超级管理员上传图片提示你的空间不足
网站是用PHP168做的,反映使用管理员在后台无法
- mac 下 安装php扩展 - mcrypt
dcj3sjt126com
PHP
MCrypt是一个功能强大的加密算法扩展库,它包括有22种算法,phpMyAdmin依赖这个PHP扩展,具体如下:
下载并解压libmcrypt-2.5.8.tar.gz。
在终端执行如下命令: tar zxvf libmcrypt-2.5.8.tar.gz cd libmcrypt-2.5.8/ ./configure --disable-posix-threads --
- MongoDB更新文档 [四]
eksliang
mongodbMongodb更新文档
MongoDB更新文档
转载请出自出处:http://eksliang.iteye.com/blog/2174104
MongoDB对文档的CURD,前面的博客简单介绍了,但是对文档更新篇幅比较大,所以这里单独拿出来。
语法结构如下:
db.collection.update( criteria, objNew, upsert, multi)
参数含义 参数
- Linux下的解压,移除,复制,查看tomcat命令
y806839048
tomcat
重复myeclipse生成webservice有问题删除以前的,干净
1、先切换到:cd usr/local/tomcat5/logs
2、tail -f catalina.out
3、这样运行时就可以实时查看运行日志了
Ctrl+c 是退出tail命令。
有问题不明的先注掉
cp /opt/tomcat-6.0.44/webapps/g
- Spring之使用事务缘由(3-XML实现)
ihuning
spring
用事务通知声明式地管理事务
事务管理是一种横切关注点。为了在 Spring 2.x 中启用声明式事务管理,可以通过 tx Schema 中定义的 <tx:advice> 元素声明事务通知,为此必须事先将这个 Schema 定义添加到 <beans> 根元素中去。声明了事务通知后,就需要将它与切入点关联起来。由于事务通知是在 <aop:
- GCD使用经验与技巧浅谈
啸笑天
GC
前言
GCD(Grand Central Dispatch)可以说是Mac、iOS开发中的一大“利器”,本文就总结一些有关使用GCD的经验与技巧。
dispatch_once_t必须是全局或static变量
这一条算是“老生常谈”了,但我认为还是有必要强调一次,毕竟非全局或非static的dispatch_once_t变量在使用时会导致非常不好排查的bug,正确的如下: 1
- linux(Ubuntu)下常用命令备忘录1
macroli
linux工作ubuntu
在使用下面的命令是可以通过--help来获取更多的信息1,查询当前目录文件列表:ls
ls命令默认状态下将按首字母升序列出你当前文件夹下面的所有内容,但这样直接运行所得到的信息也是比较少的,通常它可以结合以下这些参数运行以查询更多的信息:
ls / 显示/.下的所有文件和目录
ls -l 给出文件或者文件夹的详细信息
ls -a 显示所有文件,包括隐藏文
- nodejs同步操作mysql
qiaolevip
学习永无止境每天进步一点点mysqlnodejs
// db-util.js
var mysql = require('mysql');
var pool = mysql.createPool({
connectionLimit : 10,
host: 'localhost',
user: 'root',
password: '',
database: 'test',
port: 3306
});
- 一起学Hive系列文章
superlxw1234
hiveHive入门
[一起学Hive]系列文章 目录贴,入门Hive,持续更新中。
[一起学Hive]之一—Hive概述,Hive是什么
[一起学Hive]之二—Hive函数大全-完整版
[一起学Hive]之三—Hive中的数据库(Database)和表(Table)
[一起学Hive]之四-Hive的安装配置
[一起学Hive]之五-Hive的视图和分区
[一起学Hive
- Spring开发利器:Spring Tool Suite 3.7.0 发布
wiselyman
spring
Spring Tool Suite(简称STS)是基于Eclipse,专门针对Spring开发者提供大量的便捷功能的优秀开发工具。
在3.7.0版本主要做了如下的更新:
将eclipse版本更新至Eclipse Mars 4.5 GA
Spring Boot(JavaEE开发的颠覆者集大成者,推荐大家学习)的配置语言YAML编辑器的支持(包含自动提示,