python办公自动化视频教程,python自动化办公源代码
大家好,给大家分享一下python自动化办公真的有用吗 知乎,很多人还不知道这一点。下面详细解释一下。现在让我们来看看!

目录
1、普通文件自动化管理
1.1 文件的复制
1.2 文件内容的复制
1.3 文件的裁剪
1.4 文件的删除
1.5 文件的压缩与解压缩
1.6 文件的查找
1.7 查找含有指定内容的文件
1.8 清理重复的文件
1.9 批量修改目录中的文件名称
2、文件夹的自动化管理
2.1 文件夹的复制
2.2 文件的删除
2.3 文件夹的裁剪
3、Word自动化 -- 高效做文档
3.1 读取Word文档
3.2 小练习:简历筛选
3.3 生成word 文档
3.3 .1 标题
3.3 .2 段落
3.3 .3 图片
3.3 .4 表格
3.3 .5 分页
3.4设置 word 文档样式
3.4.1 全局样式
3.4.2 文本样式
3.4.3 图片样式
3.4.4 表格样式
3.5 WORD 转 PDF
3.5.1 网址 转 PDF
3.5.2 HTML字符串 转PDF
3.5.1 WORD 转 PDF
4、Excel 自动化
4.1 获取Excel 对象
4.1.1 获取工作簿
4.1.2 读取工作簿内容
4.2 写入Excel 数据
4.2.1 常用函数
4.2.2 代码书写
4.3 Excel 写入图表
4.3.1 常用函数
4.3.2 图表样式
4.3.3 代码书写
5、 PPT 自动化
5.1 创建PPT
5.2 段落的使用
5.3 插入表格+图片
5.4 读取PPT
6、邮件的操作
6.1 发送邮件的常规流程。
6.2 认识邮件协议
6.3 邮箱服务商开通SMTP 服务(网易邮箱为例)
6.4 普通邮件发送
6.5 HTML 邮件发送
6.6 带附件的邮件
6.7 定时发送邮件
6.8 为什么要使用while True 循环?
6.9 踩的一个坑
大家好,接下来我们来学习如何使用python 实现自动化办公,而不需要我们人工,或者说尽量减少我们人工的参与不学python可以学c语言吗。
自动化办公在我们的生活中非常的常见,让我们看看通过本博客你可以学习到python哪些自动化操作。
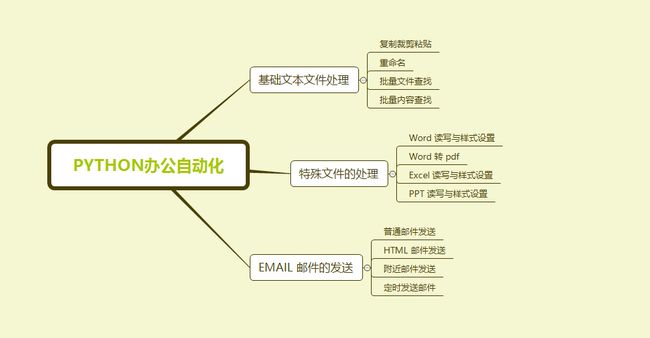
看完这幅图,大家就会发现,其实自动化处理,用的都是我们非常常用的一些办公工具,将它们自动化了。
1、普通文件自动化管理
首先我们先来学习普通的文件操作,那什么是属于普通的文件操作呢?
像 .txt /.ty 我们可以直接打开的文件看到里面具体信息的文件,我们都可以认为它们都是属于普通的文件。
既然有普通文件,就说明有不普通的文件,哪些又是不普通的文件呢?
例如:.docx / .xlsx / .psd / .ppt 我直接把它们放到IDE 里是看不到内容的,必须得用特定软件打开才行。
看过我以前博客的小伙伴都知道我们 os 这个模块,通过这个 os 模块我们可以对我们的系统文件或者一些命令进行操作。
那么在这里我们再去学习一个更加细粒度的去操作文本文件的模块,可以说,它是在OS 操作文本文件的基础上进行了升级,它的名字是 : shutil 。
shutil 是 python 3.8 的 内置模块,如果你正好 >= 这个版本,就不需要额外安装。
1.1 文件的复制
接下来我们就要使用到 shutil 这个模块来帮助我们进行文件的复制。
使用步骤:
导入包与模块:
from shutil import copy使用方法 : copy(来源文件,目标地址)
这里我们要注意的是,来源文件一定要是一个绝对路径和相对路径,而目标地址可以不包含具体的文件名。
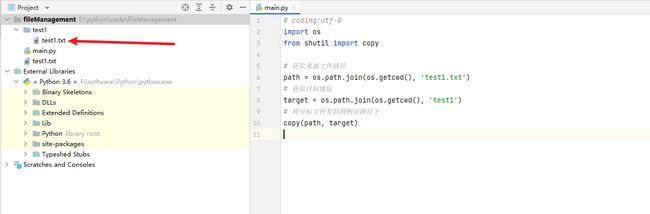
代码演示:

这里将 test1.txt 复制到 test1 文件夹下。
1.2 文件内容的复制
如何进行文件内容的复制?其实很简单。
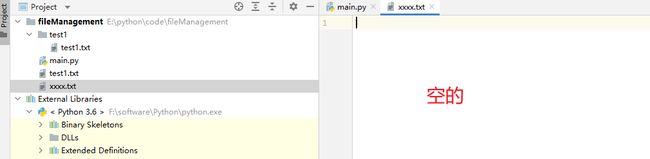
我们将获取目标地址改成 xxx.txt 。

执行

这样就实现了文件内容的复制,但是其实 shutil 有专门的函数来帮我们进行文件内容的复制。
使用步骤:
导入包与模块:
from shutil import copyfile使用方法 : copyfile(来源文件,目标文件)
这里就跟我们的 copy 有一定的区别了, 我们的copy的目标可以是一个文件夹也可以是一个文件,而 copyfile 只能是一个文件。这就是它们的一个区别。
代码演示:
xxx.txt:

text1.txt:

代码:

运行结果:

1.3 文件的裁剪
接下里我们学习一下文件的裁剪,所谓文件的裁剪就是从一个目标路径的文件 A 移动到 目标路径 B 中 去。
A 和 B 名称可能是相同的,也可能是不同的,当移动后 A 目标 这个路径下就不存在这个文件了,只存在目标 B 这个文件下。
当然,它也支持目标 A 裁剪到 直接裁剪到 目标 A ,但是它额可以支持将 目标 A 这个路径下的这个文件名称进行改变,所以它也是一个变相的重命名。
使用步骤:
导入包与模块:
from shutil import move使用方法 : move(来源地址,目标地址)
这里我们发现move 的使用方法跟我们的copy 的使用方式 其实是大同小异的,接下来我们来看看代码演示。
代码演示:

执行效果:
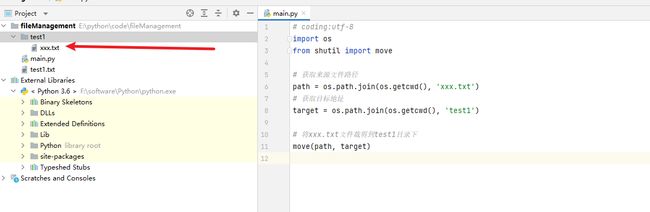
我们会发现 xxx.txt 文件已经移动到 test1 目录下了。
我们还可以实现移动的时候重命名。
# coding:utf-8
import os
from shutil import move
# 获取来源文件路径
path = os.path.join(os.getcwd(), 'xxx.txt')
# 获取目标地址
target = os.path.join(os.getcwd(), 'test1')
# 将xxx.txt文件裁剪到test1目录下并重命名
move(path, target+'/abc.txt')1.4 文件的删除
现在我们来学习文件的删除。
在 shutil 中,其实不支持一个单独的文件删除的,那该怎么办?
问题不大,我们可以用其他的方法帮助我们完成文件的删除。例如 os 包中的 remove 模块。
使用步骤:
导入包与模块:
from os import remove使用方法:remove(目标文件)
使用方法非常简单,我们直接看代码效果即可。

执行效果:

1.5 文件的压缩与解压缩
接下里我们来学习文件压缩与解压缩。
我们先来看看文件压缩的函数。
导入包与模块:
from shutil import make_archive使用方法:make_archive(压缩之后的文件名,压缩后缀,希望压缩的文件或目录)。
返回值:生成的压缩包地址。
代码演示:
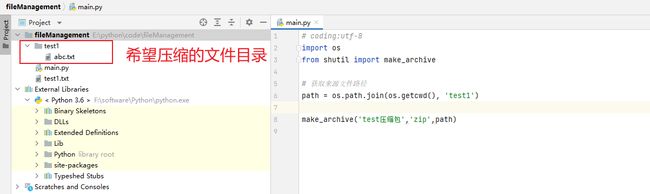
执行效果:
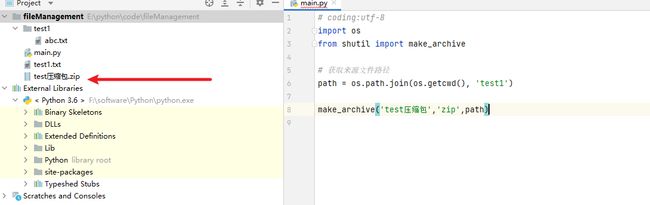
这里我们就对这个文件目录完成压缩的操作,那么接下来我们就对这个压缩包进行解压缩。
导入包与模块:
from shutil import unpack_archive使用方法:unpack_archive(要解压的文件,解压后的路径)
代码演示:

执行效果:

1.6 文件的查找
文件的查找我们要借助另一包 glob 来帮助我们实现。
glob 是一个快速查找文件夹中内容的包,我们可以通过模糊查找的形式找到我们想要的内容。
我们看看如何使用。
导入包与模块。
from glob import glob使用方法:glob(任意目录)
返回内容:指定路径下的内容列表,不存在的路径返回空列表。
代码演示:

*号就是我们学过的通配符,代表查询当前文件下所有文件。
我们还可以在通配符后面加上我们要查询的文件格式。

或者我们不使用通配符,直接指定我们要查找的文件。

很多情况下我们知道文件名字,但是不知道文件在什么地方,我们就可以使用递归的方式进行查找。
# coding:utf-8
import os
from glob import glob
path = os.path.join(os.getcwd(), '*')
final_result = []
"""
deion: 查询目录下的文件
path:要查找的目录
target:要查找的文件
"""
def search(path, target):
result = glob(path)
for data in result:
if os.path.isdir(data): # 如果是一个目录
_path = os.path.join(data, '*')
print('%s is filepath' % data)
# 继续往下找
search(_path, target)
else: # 如果不是一个目录
if target in data:
final_result.append(data)
return final_result
if __name__ == '__main__':
result = search(path, target='abc.txt')
print(result)执行效果:

1.7 查找含有指定内容的文件
文件中包含某些关键字,但是我们知道文件名个所在路径,这下该如何查找呢?
其实这跟我们递归查找指定文件差不多,但是得稍微改造一下代码。
我在def.txt 中写入: YiQie99903

代码编写:
# coding:utf-8
import os
from glob import glob
path = os.path.join(os.getcwd(), '*')
final_result = []
"""
deion: 查询目录下的文件
path:要查找的目录
target:要查找的文件
"""
def search(path, target):
result = glob(path)
for data in result:
if os.path.isdir(data): # 如果是一个目录
_path = os.path.join(data, '*')
print('%s is filepath' % data)
# 继续往下找
search(_path, target)
else: # 如果不是一个目录
f = open(data, 'r')
# 因为有些文件不是可读文件形式,例如压缩包,但是一般不可读文件太多,我们偷个懒就直接捕捉异常,但是如果在实际业务中有需要指定过滤指定格式,该做还得做
try:
content = f.read()
if target in content:
final_result.append(data)
except:
print('data read failed: %s' % data)
continue
finally:
f.close()
return final_result
if __name__ == '__main__':
result = search(path, target='YiQie99903')
print(result)这段代码查找一个目录(和子目录)下的所有文件,并在文件中搜索包含指定字符串("YiQie99903")的文件。
首先,它使用os.path.join函数和os.getcwd函数组合出目录的路径,然后使用glob函数查找所有匹配指定路径的文件和目录。
然后,它使用os.path.isdir函数判断一个文件是否是目录。
如果是目录,则使用_path变量继续查找子目录;如果不是目录,则打开文件并使用read函数读取文件内容。如果搜索字符串出现在文件内容中,则将文件的路径添加到final_result列表中。
最后,它返回最终的结果列表final_result。
该代码使用了递归,即查找函数自身调用自身,从而查找目录下的所有子目录。如果查找到的是一个文件,则打开文件并搜索指定字符串。
该代码还使用了try-except语句块来捕获异常,以处理不可读的文件。
执行效果:

1.8 清理重复的文件
在我们对电脑的日常使用中,多多少少产生一些重复的文件占用我们的硬盘,对它们进行及时的清理,也可以节省我们的硬盘空间。
那我们该如何进行操作呢?
首先我们不知道重复的文件在什么地方,也不知道有没有重复的文件。
我们可以从指定路径或者最上层路径开始读取,利用 glob 读取每个文件夹,读到文件,记录名称和大小,每次都监测之前是否读过相同的文件,如果存在,判断大小或者内容是否相同,相同,我们就认为它就是一个重复的文件,则删除。
了解了基本流程,我们进入代码实操。
# coding:utf-8
import glob
import hashlib
import os
# 用于存放文件信息
data = {}
def clear(path):
result = glob.glob(path)
for _data in result:
# 判断是否是文件夹
if os.path.isdir(_data):
_path = os.path.join(_data, '*')
clear(_path)
else:
# 拿到文件名称
name = os.path.split(_data)[-1]
# 用户判断是否需要转码
if_byte = False
# 这里也可以是其他不可直接读取的文件格式
if 'zip' in name:
if_byte = True
f = open(_data, 'rb')
else:
# 拿到文件内容
f = open(_data, 'r', encoding='utf-8')
content = f.read()
f.close()
if if_byte:
# 防止有些文件内容过大,将字典撑爆故将其转成md5的形式
hash_content_obj = hashlib.md5(content)
else:
hash_content_obj = hashlib.md5(content.encode('utf-8'))
hash_content = hash_content_obj.hexdigest()
# 文件名称是否相同
if name in data:
# 如果文件名称相同,放到二级目录下,因为可能存在不同文件夹下文件名相同文件内容不相同的情况
sub_data = data[name]
# 用于判断文件有没有删除
is_delete = False
# 循环遍历判断
for k, v in sub_data.items():
# 文件内容是否相同
if v == hash_content:
# 删除文件
os.remove(_data)
print('%s will delete' % _data)
is_delete = True
if not is_delete:
data[name][_data] = hash_content
else:
# 将数据塞到data中
data[name] = {
_data: hash_content
}
if __name__ == '__main__':
path = os.path.join(os.getcwd(), '*')
clear(path)
print(path)
for k, v in data.items():
print(k)
这段代码实现了对指定目录下的文件的遍历,并对遍历到的文件进行文件内容的校验,如果文件内容相同,就删除其中一个文件。
在这段代码中,首先使用了 glob 库中的 glob 函数,它可以用来遍历指定目录下的文件。
然后使用了 hashlib 库中的 md5 函数,对文件的内容进行哈希。
接着,对每一个遍历到的文件,都使用 open 函数打开该文件,并使用 read 函数读取文件内容。
最后,使用 os 库中的 remove 函数,删除文件。
1.9 批量修改目录中的文件名称
首先我们知道文件名需要修改的指定字符串,至于实现方法,那当然是通过循环,将目标字符串加入到文件名并进行修改。
# coding:utf-8
import glob
import shutil
def update_name(path):
result = glob.glob(path)
# 循环遍历
for index, data in enumerate(result):
# 判断是否是一个文件夹
if glob.os.path.isdir(data):
# 是 生成新的链接
_path = glob.os.path.join(data, '*')
update_name(_path)
else:
# 不是文件夹,是文件了
path_list = glob.os.path.split(data)
# 单独把名字拿出来
name = path_list[-1]
# 生成一个新的名称
new_name = '%s_%s' % (index, name)
# 替换旧旧名称
new_data = glob.os.path.join(path_list[0], new_name)
shutil.move(data, new_data)
if __name__ == '__main__':
path = glob.os.path.join(glob.os.getcwd(), '*')
update_name(path)来看看代码执行效果

代码执行:

2、文件夹的自动化管理
前面我们学习了文件的管理,现在我们来学习一下如何使用 shutil 实现对文件夹的管理。
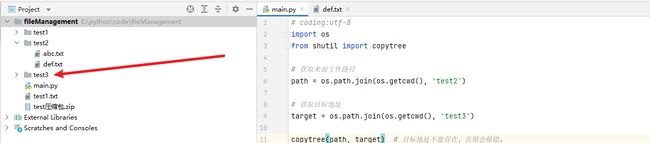
2.1 文件夹的复制
导入包与模块:
from shutil import copytree使用方法:copytree(来源目录,目标目录)

执行效果:
2.2 文件的删除
导入包与模块:
from shutil import rmtree使用方法:rmtree(目标目录)
代码演示:

执行效果:

值得注意的是,我们的目标目录一定要存在,否则会报错。
2.3 文件夹的裁剪
导入包与模块:
from shutil import move使用方法 : move(来源目录,目标目录)
这里我们发现文件夹的裁剪跟我们文件裁剪的使用函数其实是一样的。
代码演示:
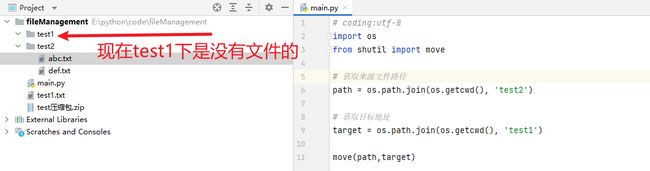
执行效果:

这里我们发现 test2 整个文件夹都移动到了test1 这个目录下。
如果目标目录不存在,那就是对原来的目录进行重命名。
而且我们还可以移动的同时并重命名。
move(path,target+'/test4') # 移动并重命名3、Word自动化 -- 高效做文档
接下来我们来学习如何使用python 来操作 word 文档,这里就要介绍一个 python Word 操作利器之 python - docx。
要想使用 python-docx,要先进行下载安装。
pip install python-docx
3.1 读取Word文档
我们来学习一下如何读取word 文档,这里我们要用到是的 pythton-docx 之 Document
首先要导入包和模块:
from docx import Document使用方法:
Document(word地址)返回值 : word 文件对象。
接下来我们先进行对word 段落内容的读取。
来看看我随便准备的一个word 文档。

接下来我们练习一下如何将这个word 段落里的内容读取出来。
# coding:utf-8
from docx import Document
# docx 只支持 .docx 这样的格式 如果是 doc 请转换成 docx
doc = Document('test.docx')
for p in doc.paragraphs:
print(p.text)
这些我们可以看到段落内容已经被我们读取出来了。
表格内容的读取。
# coding:utf-8
from docx import Document
# docx 只支持 .docx 这样的格式 如果是 doc 请转换成 docx
doc = Document('test.docx')
# 先获取表格对象
for t in doc.tables:
# 获取表格中的行
for row in t.rows:
_row_str = ''
# 获取行中的每个小表格
for cell in row.cells:
_row_str += cell.text + ','
print(_row_str)
3.2 小练习:简历筛选
学习如何读取 word 的段落内容 + 表格 的内容读取,接下来我们就要做一个简历筛选的小练习。
首先我们知道想要查找包含指定关键字的简历。比如 简历中包含 python , 爬虫 这样的关键字。
如何实现呢?
其实也很简单,我们直接批量读取每一个word (通过glob 获取 word信息 ), 将他们所有的可读内容 获取,并通过关键字方式筛选,拿到目标简历地址。
这里我随便从网上下载了两份简历,用作练习。


# coding:utf-8
import glob
from docx import Document
class ReadDoc(object):
def __init__(self, path):
self.doc = Document(path)
self.p_text = ''
self.table_text = ''
self.get_para()
self.get_table()
# 获取段落内容
def get_para(self):
for p in self.doc.paragraphs:
self.p_text += p.text + '\n'
# 获取表格内容
def get_table(self):
for table in self.doc.tables:
for row in table.rows:
_cell_str = ''
for cell in row.cells:
_cell_str += cell.text + ','
self.table_text += _cell_str + '\n'
def search_word(path, targets):
# 获取路径下所有文件
result = glob.glob(path)
final_result = []
for i in result:
isuse = True
# 是否是文件
if glob.os.path.isfile(i):
# 是否是 .docx 文件
if i.endswith('.docx'):
doc = ReadDoc(i)
p_text = doc.p_text
t_text = doc.table_text
all_text = p_text + t_text
# 循环遍历 判断是否存在关键字
for target in targets:
if target not in all_text:
isuse = False
break
if not isuse:
continue
final_result.append(i)
return final_result
if __name__ == '__main__':
path = glob.os.path.join(glob.os.getcwd(), '*')
res = search_word(path, ['Java', '本科'])
print(res)3.3 生成word 文档
接下来我们来学习如何通过python 脚本自动生成一个word 文档。
我们先来想想,一个word 文档会有哪些内容。
标题 、 段落 、 图片 、 表格 、分页。
3.3 .1 标题
首先我们来看看如何生成标题。
# coding:utf-8
from docx import Document
doc = Document()
# 添加标题 参数 : 标题内容,标题样式等级
title = doc.add_heading('My title', 0)
# 追加内容
title.add_run('\n 一切总会归于平淡')
# 生成 word 文档
doc.save('test.docx')我们来看看执行效果:

3.3 .2 段落
添加好标题之后,接下来我们就可以添加段落了。
# coding:utf-8
from docx import Document
doc = Document()
# 添加标题 参数 : 标题内容,标题样式等级
title = doc.add_heading('My title', 0)
# 追加内容
title.add_run('\n 一切总会归于平淡')
# 添加段落
p = doc.add_paragraph('欢迎来到这里学习python,求个点赞可还行')
# 追加内容
p.add_run('\n顺便求个关注')
# 生成 word 文档
doc.save('test.docx')执行效果:

3.3 .3 图片
接下来学习如何添加图片。
# coding:utf-8
from docx import Document
from docx.shared import Inches
doc = Document()
# 添加标题 参数 : 标题内容,标题样式等级
title = doc.add_heading('My title', 0)
# 追加内容
title.add_run('\n 一切总会归于平淡')
# 添加段落
p = doc.add_paragraph('欢迎来到这里学习python,求个点赞可还行')
# 追加内容
p.add_run('\n顺便求个关注')
# 添加图片 参数:图片路径 宽度 (可选),高度(可选)
image = doc.add_picture('这是一张图片.png', width=Inches(5), height=Inches(5))
# 生成 word 文档
doc.save('test.docx')执行效果:

3.3 .4 表格
添加表格
# coding:utf-8
from docx import Document
from docx.shared import Inches
doc = Document()
# 添加标题 参数 : 标题内容,标题样式等级
title = doc.add_heading('My title', 0)
# 追加内容
title.add_run('\n 一切总会归于平淡')
# 添加表格
# 表格内容
title = ['name', 'age', 'sex']
# 生成表格 参数 : 行数 列数
table = doc.add_table(rows=1, cols=3)
# 插入参数
title_cells = table.rows[0].cells
title_cells[0].text = title[0]
title_cells[1].text = title[1]
title_cells[2].text = title[2]
# 追加内容
data = {
('一切', '2', '男'),
('总会', '2', '男'),
('归于平淡', '4', '男')
}
for d in data:
row_cells = table.add_row().cells
row_cells[0].text = d[0]
row_cells[1].text = d[1]
row_cells[2].text = d[2]
# 生成 word 文档
doc.save('test.docx')执行效果:
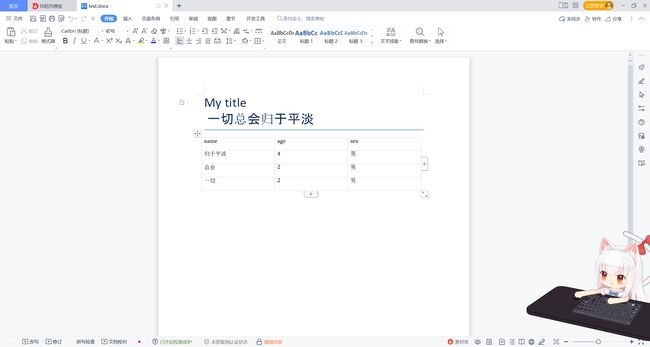
3.3 .5 分页
# coding:utf-8
from docx import Document
from docx.shared import Inches
doc = Document()
# 添加标题 参数 : 标题内容,标题样式等级
title = doc.add_heading('My title', 0)
# 添加新的一页
doc.add_page_break()
# 添加标题 参数 : 标题内容,标题样式等级
title = doc.add_heading('My title2', 0)
# 生成 word 文档
doc.save('test.docx')
以上就是我们学习如何创建一个word 的相关内容了。
3.4设置 word 文档样式
接下来我们来学习给我们的word 文档添砖加瓦,让其变得更好看些。
3.4.1 全局样式
# coding:utf-8
from docx import Document
from docx.shared import RGBColor, Pt
doc = Document()
# 定义全局样式
style = doc.styles['Normal']
# 设置字体
style.font.name = '微软雅黑'
# 设置字体 颜色
style.font.color.rgb = RGBColor(255, 0, 0)
# 设置字体大小
style.font.size = Pt(16)我们来看看执行效果:

我们可以看到,字体的颜色,大小,字体都发生的改变,除了标题,这是一个标题的特殊性,后面会为大家讲解。
3.4.2 文本样式
文本样式 包括 标题和段落。
# coding:utf-8
from docx import Document
from docx.shared import RGBColor, Pt
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
doc = Document()
# 添加标题 参数 : 标题内容,标题样式等级
title = doc.add_heading('My title', 0)
# 设置标题居中
title.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
# 设置标题字体大小
title.style.font.size = Pt(50)
# 追加内容
_t = title.add_run('\n 一切总会归于平淡')
# 设置标题倾斜 最开始的标题设置不了倾斜,只能在追加内容里,如果想要设置,就把最开始的标题设置为 空字符串,然后全都追加内容里写。
_t.italic = True
# 设置标题加粗
_t.bold = True
# 添加段落
p = doc.add_paragraph('欢迎来到这里学习python,求个点赞可还行')
# 追加内容 顺便设置倾斜
p.add_run('\n顺便求个关注').italic = True
# 设置段落居右
p.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT
# 生成 word 文档
doc.save('test.docx')执行效果:

如果大家还想知道有哪些样式,可以通过 dir(对象) 命令。
3.4.3 图片样式
我们不能直接对图片进行样式改造,需要借助段落帮助我们才行。
# coding:utf-8
from docx import Document
from docx.shared import RGBColor, Pt, Inches
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT, WD_ALIGN_PARAGRAPH
doc = Document()
# 添加标题 参数 : 标题内容,标题样式等级
title = doc.add_heading('My title', 0)
# 设置标题居中
title.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
# 设置标题字体大小
title.style.font.size = Pt(50)
# 追加内容
_t = title.add_run('\n 一切总会归于平淡')
# 设置标题倾斜 最开始的标题设置不了倾斜,只能在追加内容里,如果想要设置,就把最开始的标题设置为 空字符串,然后全都追加内容里写。
_t.italic = True
# 设置标题加粗
_t.bold = True
p = doc.add_paragraph()
# 设置居右
p.alignment = WD_ALIGN_PARAGRAPH.RIGHT
_p = p.add_run()
# 添加图片
image = _p.add_picture('这是一张图片.png', width=Inches(3), height=Inches(2))
# 生成 word 文档
doc.save('test.docx')这段代码使用python-docx库创建一个Word文档,并向文档中添加标题、图片和文本。
首先,它使用add_heading函数创建一个标题,并使用alignment属性将标题居中。然后,它使用style属性和font属性设置标题的字体大小。
然后,它使用add_run函数向标题中追加内容,并使用italic属性和bold属性设置内容的倾斜和加粗。
接下来,它使用add_paragraph函数创建一个段落,并使用alignment属性将段落设置为居右。然后,它使用add_run函数向段落中追加内容,并使用add_picture函数添加一张图片。
最后,它使用save函数保存文档。
执行效果:

3.4.4 表格样式
表格样式有很多,我们可以通过下面的方式来获取都有哪些表格样式。
for i in doc.styles:
if i.type == WD_STYLE_TYPE.TABLE:
print(i.name)执行结果:
Normal Table
Table Grid
Light Shading
Light Shading Accent 1
Light Shading Accent 2
Light Shading Accent 3
Light Shading Accent 4
Light Shading Accent 5
Light Shading Accent 6
Light List
Light List Accent 1
Light List Accent 2
Light List Accent 3
Light List Accent 4
Light List Accent 5
Light List Accent 6
Light Grid
Light Grid Accent 1
Light Grid Accent 2
Light Grid Accent 3
Light Grid Accent 4
Light Grid Accent 5
Light Grid Accent 6
Medium Shading 1
Medium Shading 1 Accent 1
Medium Shading 1 Accent 2
Medium Shading 1 Accent 3
Medium Shading 1 Accent 4
Medium Shading 1 Accent 5
Medium Shading 1 Accent 6
Medium Shading 2
Medium Shading 2 Accent 1
Medium Shading 2 Accent 2
Medium Shading 2 Accent 3
Medium Shading 2 Accent 4
Medium Shading 2 Accent 5
Medium Shading 2 Accent 6
Medium List 1
Medium List 1 Accent 1
Medium List 1 Accent 2
Medium List 1 Accent 3
Medium List 1 Accent 4
Medium List 1 Accent 5
Medium List 1 Accent 6
Medium List 2
Medium List 2 Accent 1
Medium List 2 Accent 2
Medium List 2 Accent 3
Medium List 2 Accent 4
Medium List 2 Accent 5
Medium List 2 Accent 6
Medium Grid 1
Medium Grid 1 Accent 1
Medium Grid 1 Accent 2
Medium Grid 1 Accent 3
Medium Grid 1 Accent 4
Medium Grid 1 Accent 5
Medium Grid 1 Accent 6
Medium Grid 2
Medium Grid 2 Accent 1
Medium Grid 2 Accent 2
Medium Grid 2 Accent 3
Medium Grid 2 Accent 4
Medium Grid 2 Accent 5
Medium Grid 2 Accent 6
Medium Grid 3
Medium Grid 3 Accent 1
Medium Grid 3 Accent 2
Medium Grid 3 Accent 3
Medium Grid 3 Accent 4
Medium Grid 3 Accent 5
Medium Grid 3 Accent 6
Dark List
Dark List Accent 1
Dark List Accent 2
Dark List Accent 3
Dark List Accent 4
Dark List Accent 5
Dark List Accent 6
Colorful Shading
Colorful Shading Accent 1
Colorful Shading Accent 2
Colorful Shading Accent 3
Colorful Shading Accent 4
Colorful Shading Accent 5
Colorful Shading Accent 6
Colorful List
Colorful List Accent 1
Colorful List Accent 2
Colorful List Accent 3
Colorful List Accent 4
Colorful List Accent 5
Colorful List Accent 6
Colorful Grid
Colorful Grid Accent 1
Colorful Grid Accent 2
Colorful Grid Accent 3
Colorful Grid Accent 4
Colorful Grid Accent 5
Colorful Grid Accent 6以上都是表格样式,我们挑一两个来试试。

执行效果:

3.5 WORD 转 PDF
首先我们要认识一下 PDF 工具包 - pdfkit
# 安装
pip install pdfkit安装好pdfkit后,我们还需要一个依赖的工具。
下载链接:wkhtmltopdf
大家根据自己的系统下载对应的安装包。
3.5.1 网址 转 PDF
pdfkit.from_url('网址','保存的路径')代码演示:
# coding:utf-8
import pdfkit
# 给出wkhtmltopdf的位置
config = pdfkit.configuration(wkhtmltopdf=r"D:\installPath\wkhtmltopdf\bin\wkhtmltopdf.exe")
# 网址 转 PDF
pdfkit.from_url('https://www.baidu.com', 'baidu.pdf', configuration=config)执行效果:

3.5.2 HTML字符串 转PDF
# coding:utf-8
import pdfkit
# 给出wkhtmltopdf的位置
config = pdfkit.configuration(wkhtmltopdf=r"D:\installPath\wkhtmltopdf\bin\wkhtmltopdf.exe")
# html 字符串
htmlStr = """
一切总会归于平淡
"""
# 字符串转 PDF
pdfkit.from_string(htmlStr, '求个点赞.pdf', configuration=config)执行效果:

3.5.1 WORD 转 PDF
首先我们要安装一个新的依赖包:
pip install pydocx代码演示:
# coding:utf-8
import pdfkit
from pydocx import PyDocX
# 给出wkhtmltopdf的位置
config = pdfkit.configuration(wkhtmltopdf=r"D:\installPath\wkhtmltopdf\bin\wkhtmltopdf.exe")
# 先将word文档转成HTML
html = PyDocX.to_html('简历1.docx')
f = open('html1.html', 'w')
f.write(html)
f.close()
# 再转成pdf
pdfkit.from_file('html1.html', '简历1.pdf', configuration=config)
# 也可以直接通过字符串生成
html2 = PyDocX.to_html('简历2.docx')
pdfkit.from_string(html2, '简历2.pdf', configuration=config)这段代码使用pdfkit库将两个Word文档(简历1.docx和简历2.docx)转换成PDF格式。它使用了两个步骤:
将Word文档转换成HTML:首先,它使用PyDocX库的to_html函数将Word文档转换成HTML字符串。然后,它使用open函数打开一个名为"html1.html"的文件,并使用write函数将HTML字符串写入该文件。最后,它使用close函数关闭文件。
将HTML转换成PDF:首先,它使用pdfkit库的from_file函数从"html1.html"文件中读取HTML字符串,并使用pdfkit库的from_string函数将HTML字符串转换成PDF格式。
注意,pdfkit库需要wkhtmltopdf工具来进行转换。
因此,你需要在代码中指定wkhtmltopdf工具的位置(在这段代码中,wkhtmltopdf工具位于"D:\installPath\wkhtmltopdf\bin\wkhtmltopdf.exe")。
4、Excel 自动化
接下来我们学习 Python 对Excel 的操作,这里又要给大家介绍一个新模块 xlrd .
# 安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xlrd==1.2.0为什么指定版本呢? 因为更高的版本有可能会发生不兼容的情况。
4.1 获取Excel 对象
使用方法:
book = xlrd.open_workbook(excle文件)返回:excle 对象
4.1.1 获取工作簿
既然已经获取到了Excel 对象,我们都知道在每个Excel 里面都有很多个工作簿,那怎么获取里面的工作簿呢?
| 函数名 | 说明 |
|---|---|
| book.sheet_by_name() | 按照工作薄名称获取 |
| book.sheet by_index() | 按照索引获取 |
| book.sheets() | 获取所有工作薄列表 |
代码编写:
# coding:utf-8
import xlrd
excel = xlrd.open_workbook('技术新鲜事(一切总会归于平淡)_用户明细_20221204.xlsx')
# 按照工作薄名称获取
book = excel.sheet_by_name('用户明细')
print(book.name)
# 按照索引获取
book = excel.sheet_by_index(0)
print(book.name)
# 获取所有的工作簿列表
for i in excel.sheets():
print(i.name)执行效果:

4.1.2 读取工作簿内容
现在我们已经获取工作簿,接下来我们就来学习如何获取工作簿里面的内容。
| 函数名 | 说明 |
|---|---|
| sheet.nrows | 返回总行数 |
| sheet.ncols | 返回总列数 |
| sheet.get_rows0 | 返回每行内容列表 |
代码执行:
# coding:utf-8
import xlrd
excel = xlrd.open_workbook('技术新鲜事(一切总会归于平淡)_用户明细_20221204.xlsx')
# 按照工作薄名称获取
book = excel.sheet_by_name('用户明细')
print(book.name)
# 总行数
print('%s 行' % book.nrows)
# 总列数
print('%s 列' % book.ncols)
# 每行内容列表
for i in book.get_rows():
content = []
for j in i:
content.append(j.value)
print(content)这段代码打开了一个名为"技术新鲜事(一切总会归于平淡)用户明细20221204.xlsx"的Excel文件,然后使用sheet_by_name函数获取名为"用户明细"的工作表。\
它打印了工作表的名称,然后使用nrows和ncols属性获取工作表的总行数和总列数,最后使用get_rows函数遍历工作表的每一行,并将每一行的内容打印出来。
注意,get_rows函数返回的是一个生成器,因此你需要使用for循环遍历每一行。
对于每一行,你可以使用for循环遍历每一个单元格,并使用value属性获取单元格的值。
执行效果:

4.2 写入Excel 数据
接下来我们学习 Python 对Excel 写入数据的操作,这里又要给大家介绍一个新模块 xlsxwriter.
# 安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xlsxwriter4.2.1 常用函数
| 函数名 | 说明 | 参数 |
|---|---|---|
| xlsxwriter.Workbook() | 生成excel对象 | Excel文件名 |
| add_worksheet() | 添加工作薄 | 工作薄名称 |
| sheet.write() | 书写内容 | 行索引,列索引,内容 |
| book.close() | 关闭excel对象 | 无 |
4.2.2 代码书写
import xlrd
import xlsxwriter
# 读取技术新鲜事(一切总会归于平淡)_用户明细_20221204.xlsx
def read():
result = []
excel = xlrd.open_workbook('技术新鲜事(一切总会归于平淡)_用户明细_20221204.xlsx')
# 按照工作薄名称获取
book = excel.sheet_by_name('用户明细')
# 每行内容列表
for i in book.get_rows():
content = []
for j in i:
content.append(j.value)
result.append(content)
return result
def write(content):
# 创建excel对象
excel = xlsxwriter.Workbook('test.xlsx')
# 添加工作簿
book = excel.add_worksheet("test")
for index, data in enumerate(content):
for sub_index, sub_date in enumerate(data):
book.write(index, sub_index, sub_date)
# 关闭excel对象
excel.close()
if __name__ == '__main__':
result = read()
write(result)
这段代码实现了从一个名为"技术新鲜事(一切总会归于平淡)用户明细20221204.xlsx"的Excel文件中读取数据,然后将读取到的数据写入另一个名为"test.xlsx"的Excel文件中。
它首先使用xlrd库打开名为"技术新鲜事(一切总会归于平淡)用户明细20221204.xlsx"的Excel文件,然后使用sheet_by_name函数获取名为"用户明细"的工作表。接下来,它使用get_rows函数遍历工作表的每一行,将每一行的内容读取到一个列表中,然后将该列表添加到另一个列表中,最终得到一个二维列表。
然后,它调用write函数,使用xlsxwriter库创建一个名为"test.xlsx"的Excel文件,并在该文件中添加一个名为"test"的工作表。然后,它遍历传入的二维列表中的每一个元素,并将它们写入工作表中的相应位置。最后,它使用close函数关闭excel对象,保存文件。
4.3 Excel 写入图表
学习完如何书写一个excel 文件 ,我们来看看如何在excle 上生成一个比较简单的图表。
4.3.1 常用函数
我们先来看看所需要的几个函数。
| 函数名 | 说明 | 参数 |
|---|---|---|
| add _chart() | 创建图表对象 | {type: 样式) |
| add series() | 定义需要展示的数据 | 字典 |
| set title() | 定义图表title | 字符串 |
add series()的参数:
| 参数 | 说明 | 值 |
|---|---|---|
| categories | 展示的标题 | =Sheet1!$A$1:$A$4 |
| values | 展示的数据 | =Sheet1!$B$1:$B$4 |
| name | 表名 |
=Sheet1!$A$1:$A$4 : 这是一个 Excel 单元格引用。它表示 "Sheet1" 工作簿中的第一列,即从第一行到第四行的所有单元格。其中 "$A$1" 和 "$A$4" 分别表示第一列的第一行和第四行,"$A" 表示第一列,"$1" 和 "$4" 分别表示第一行和第四行。
4.3.2 图表样式
| 样式名 | 说明 |
|---|---|
| area | 区域样式表 |
| bar | 条形样式 |
| column | 柱状样式 |
| line | 线条样式 |
| pie | 饼图样式 |
| doughnut | 圆环样式 |
| scatter | 散点样式 |
| stock | 库存样式 |
| radar | 雷达样式 |
4.3.3 代码书写
import xlsxwriter
# 创建excel对象
excel = xlsxwriter.Workbook('test.xlsx')
# 添加工作簿
book = excel.add_worksheet('用户角色')
data = [
['社区成员', '社区之星', '社区管理员', '区长'],
[20, 23, 2, 1]
]
book.write_column('A1', data[0])
book.write_column('B1', data[1])
chart = excel.add_chart({'type': 'pie'})
chart.add_series({
'categories': '=用户角色!$A1:$A4',
'values': '=用户角色!$B1:$B4',
'name': '角色占比'
})
chart.set_title({
'name': '角色占比图表'
})
book.insert_chart('A7', chart)
# 关闭excel对象
excel.close()这段代码使用了 Python 的 xlsxwriter 库来创建一个名为 "test.xlsx" 的 Excel 文件,并在其中添加了一个工作簿,命名为 "用户角色"。
然后在该工作簿中写入了两列数据。
接着,它创建了一个饼图,将数据源设为工作簿中的第一列和第二列,并将图表插入到工作簿中。最后,关闭了 Excel 对象。
执行效果:

5、 PPT 自动化
从现在开始我们就来学习PPT 的自动化操作。
这里就要用到python PPT操作利器之 python - pptx 。
# 安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple python-pptx5.1 创建PPT
import pptx
# 创建ppt 对象
p = pptx.Presentation()
# 设置布局 一共有11种 从0开始
layout = p.slide_layouts[7]
# 创建第一个页ppt
slide = p.slides.add_slide(layout)
p.save('test.ppt')这段 Python 代码,它会创建一个 pptx.Presentation 对象,再设置布局并添加一张幻灯片,最后保存为 test.ppt 文件。
布局是指幻灯片的外观,我这里最多是11 种布局(可能跟我的pptx版本或者ppt 版本有关)。
可以使用 pptx.Presentation.slide_layouts 属性访问幻灯片布局,这个属性是一个列表,每一项都是一个 SlideLayout 对象,列表中第 7 项就是第 7 种布局。
使用 pptx.Presentation.slides.add_slide() 方法可以向幻灯片集合添加一张幻灯片,这个方法需要指定一个布局。
最后使用 pptx.Presentation.save() 方法保存幻灯片。
执行效果:

5.2 段落的使用
import pptx
from pptx.dml.color import RGBColor
from pptx.enum.text import PP_PARAGRAPH_ALIGNMENT
from pptx.util import Pt
# 创建ppt 对象
p = pptx.Presentation()
# 设置布局 一共有11种 从0开始
layout = p.slide_layouts[1]
# 创建第一页ppt
slide = p.slides.add_slide(layout)
# 获取标题 0 是 标题 1 段落
title = slide.placeholders[0]
title.text = 'ppt自动化'
# 获取段落
placeholder = slide.placeholders[1]
placeholder.text = '一切总会归于平淡\n求个关注'
# 添加段落
placeholder1 = placeholder.text_frame.add_paragraph()
# 添加内容
placeholder1.text = '点赞'
# 加粗
placeholder1.font.bold = True
# 倾斜
placeholder1.font.italic = True
# 字体大小
placeholder1.font.size = Pt(16)
# 下划线
placeholder1.font.underline = True
# 位置
placeholder1.alignment = PP_PARAGRAPH_ALIGNMENT.CENTER
# 添加第二个段落
placeholder2 = placeholder.text_frame.add_paragraph()
placeholder2.text = '转发'
# 字体大小
placeholder2.font.size = Pt(32)
# 位置 右
placeholder2.alignment = PP_PARAGRAPH_ALIGNMENT.RIGHT
# 颜色 红色
placeholder2.font.color.rgb = RGBColor(255, 0, 0)
p.save('test.ppt')这段代码用于创建一个 PowerPoint 文件,并在该文件中添加一张幻灯片。在幻灯片中,有一个标题和两个文本段落。
首先,使用
pptx库导入了需要的模块。然后,使用
pptx.Presentation()函数创建了一个 PowerPoint 对象,并通过使用幻灯片布局类型 1(第二种),使用slides.add_slide()函数向其添加了一张幻灯片。在幻灯片中,使用
placeholders[0]和placeholders[1]获取标题和第一个文本段落,并使用text属性指定其文本内容。然后,使用add_paragraph()函数为第一个文本段落添加了一个新段落,并使用font属性设置了该段落的文本格式,如字体大小、是否加粗、是否倾斜、是否有下划线以及文本颜色。使用
alignment属性设置了文本的对齐方式。最后,使用save()函数将该幻灯片保存为文件 "test.ppt"。
执行效果:

5.3 插入表格+图片
# 创建ppt 对象
import pptx
from pptx.util import Inches
p = pptx.Presentation()
# 设置布局 一共有11种 从0开始
layout = p.slide_layouts[1]
# 创建第一页ppt
slide = p.slides.add_slide(layout)
# 获取标题 0 是 标题 1 段落
title = slide.placeholders[0]
title.text = 'ppt自动化'
# 获取段落
placeholder = slide.placeholders[1]
placeholder.text = '一切总会归于平淡\n求个关注'
# 创建第二页
layout = p.slide_layouts[1]
slide = p.slides.add_slide(layout)
title = slide.placeholders[0]
title.text = '第二页'
# 定义表格属性
rows = 10
cols = 2
left = top = Inches(2)
width = Inches(6.0)
height = Inches(1.0)
# 创建表格
table = slide.shapes.add_table(rows, cols, left, top, width, height).table
# 添加内容
for index, _ in enumerate(range(rows)):
for sub_index in range(cols):
table.cell(index, sub_index).text = '%s:%s' % (index, sub_index)
layout = p.slide_layouts[6]
slide = p.slides.add_slide(layout)
# 插入图片
image = slide.shapes.add_picture(
image_file='C:\\Users\\24163\\Desktop\\封面\\85047173_p0-724x1024.jpg',
left=Inches(1),
top=Inches(1),
width=Inches(6),
height=Inches(6)
)
p.save('test.ppt')这段代码创建了一个 PowerPoint 幻灯片文件,并使用 Python 的 python-pptx 库进行操作。
首先,使用
pptx.Presentation()函数创建了一个 PowerPoint 对象,并使用slide_layouts属性选择了一个布局(在本例中为布局 1)。然后,使用add_slide()函数将一张幻灯片添加到演示文稿中。接下来,使用
placeholders属性获取幻灯片中的标题和段落,并设置其文本内容。然后,再次使用
add_slide()函数创建了另一张幻灯片,并使用add_table()函数将一个表格添加到幻灯片中。接着,使用嵌套循环遍历表格的所有单元格,并使用cell()方法设置单元格的文本内容。接着,又使用了
add_slide()函数创建了另一张幻灯片,并使用add_picture()函数将一张图片插入到幻灯片中。在这里,您指定了图片文件的路径,并使用Inches对象指定了图片的位置和尺寸。最后,使用
save()方法将演示文稿保存到文件中。
执行效果:

5.4 读取PPT
# coding:utf-8
import pptx
# 获取ppt对象
p = pptx.Presentation('test.ppt')
# 获取ppt中所有的幻灯片
for slide in p.slides:
# 获取所有形状
for shape in slide.shapes:
# 判断是否是文本类型(因为像图片这种类型是读取不了的)
if shape.has_text_frame:
print(shape.text_frame.text)
# 判断是否是表格
if shape.has_table:
for cell in shape.table.iter_cells():
print(cell.text)这段代码是在解析一个 PowerPoint 文件,然后打印出所有幻灯片中的文本内容。
首先,它使用了 pptx 库来打开 PowerPoint 文件。
然后,它遍历了所有幻灯片,对于每一张幻灯片,再遍历所有形状。
对于每个形状,如果它有文本框,就打印出文本框中的文本;如果它有表格,就遍历表格中的所有单元格,并打印出单元格中的文本。
6、邮件的操作
接下来我们来学习python对邮件的操作。
让我们来看看又可以认识哪些新模块吧。
-
smtplib:邮件协议与发送模块
-
email:内容定义模块
-
schedule:定时模块
6.1 发送邮件的常规流程。
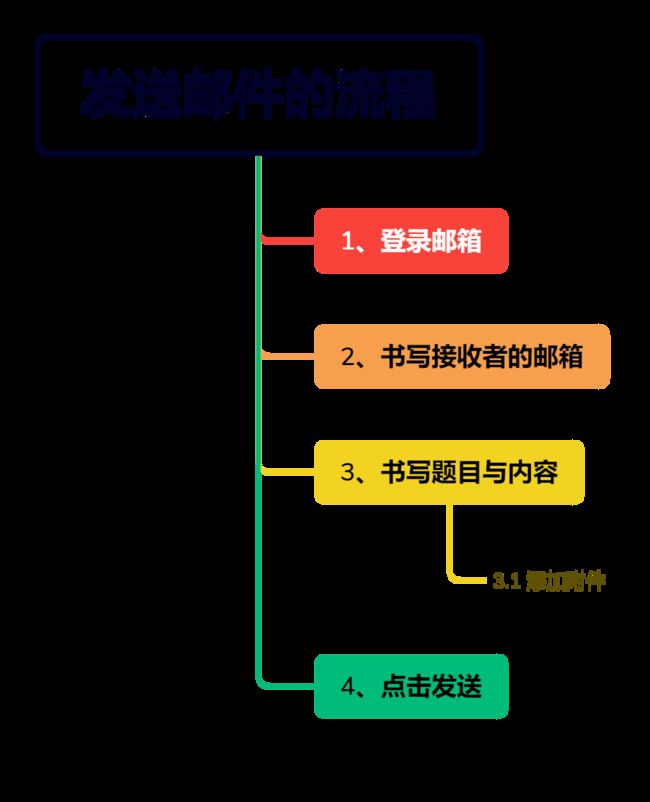
6.2 认识邮件协议
常见的邮件的协议有:
-
SMTP(Simple Mail Transfer Protocol):简单邮件传输协议,是一种用于发送邮件的应用层协议。它使用了一组专用的命令来指定邮件的发件人、收件人以及其他相关信息,并使用 TCP 协议传输数据。
-
IMAP(Internet Mail Access Protocol):互联网邮件访问协议,是一种用于访问远程邮件服务器上的邮件的应用层协议。它提供了一组命令,用于从服务器上检索、操作和删除邮件。
-
POP3(Post Office Protocol version 3)是一种应用层协议,用于从远程邮件服务器接收邮件。它是邮局协议(POP)的第三个版本,是目前使用最广泛的版本。
什么是协议?
协议就是一种规则已经被底层网络封装好,我们无需关心他的具体规则是什么,直接使用上层工具即可。
6.3 邮箱服务商开通SMTP 服务(网易邮箱为例)
登录网易邮箱,点击设置。

选择POP3/SMTP/IMAP
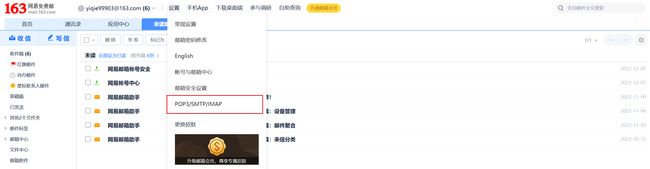
找到 SMTP 设置,将其开启。

然后你就看到一串复制保存,后续代码会用到。
6.4 普通邮件发送
# coding:utf-8
import smtplib
from email.header import Header
from email.mime.text import MIMEText
# 第三方的smtp
mail_host = 'smtp服务器'
mail_user = '你的邮箱'
mail_pass = '密钥'
# smtp 开通, 授权码
# 发送人邮箱
sender = '发送人的邮箱'
# 接收者邮箱
receivers = ['接收者的邮箱']
# 参数:1、内容 2、文件内容格式 3、编码格式
message = MIMEText('这是一个测试', 'plain', 'utf-8')
# 发送者信息
message['From'] = Header(sender)
# 标题 参数 : 1、内容 2、编码格式
message['Subject'] = Header('python脚本测试', 'utf-8')
try:
# 发送邮件
smtpobj = smtplib.SMTP()
# 连接
smtpobj.connect(mail_host, 25)
# 登录
smtpobj.login(mail_user, mail_pass)
# 发送
smtpobj.sendmail(sender, receivers, message.as_string())
except smtplib.SMTPException as e:
print('error: %s' % e)首先,它会使用
smtplib模块连接到你的 SMTP 服务器,然后使用你的邮箱账号和密码登录。然后,它会使用
MIMEText类创建一个电子邮件对象,该对象包含了邮件的文本内容、文件内容格式和编码格式。最后,它会调用
sendmail函数发送邮件。这个函数需要三个参数:发件人地址、收件人地址(可以是一个列表,表示同时发送给多个人)和邮件正文。在代码中,邮件正文是通过调用
as_string方法将电子邮件对象转换为字符串的形式传递的。如果发送邮件过程中出现了任何错误,就会抛出
SMTPException异常。你可以使用try-except语句来捕获这个异常,并在出错时打印错误信息。
6.5 HTML 邮件发送
# coding:utf-8
import smtplib
from email.header import Header
from email.mime.text import MIMEText
# 第三方的smtp
mail_host = 'smtp服务器'
mail_user = '你的邮箱'
mail_pass = '密钥'
# smtp 开通, 授权码
# 发送人邮箱
sender = '发送人的邮箱'
# 接收者邮箱
receivers = ['接收者的邮箱']
# 参数:1、内容 2、文件内容格式 3、编码格式
message = MIMEText('这是一个测试
', 'html', 'utf-8')
# 发送者信息
message['From'] = Header(sender)
# 标题 参数 : 1、内容 2、编码格式
message['Subject'] = Header('python脚本测试', 'utf-8')
try:
# 发送邮件
smtpobj = smtplib.SMTP()
# 连接
smtpobj.connect(mail_host, 25)
# 登录
smtpobj.login(mail_user, mail_pass)
# 发送
smtpobj.sendmail(sender, receivers, message.as_string())
except smtplib.SMTPException as e:
print('error: %s' % e)这里就改造了一下 message = MIMEText()。
6.6 带附件的邮件
# coding:utf-8
import smtplib
from email.header import Header
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
# 第三方的smtp
mail_host = 'smtp服务器'
mail_user = '你的邮箱'
mail_pass = '密钥'
# smtp 开通, 授权码
# 发送人邮箱
sender = '发送人的邮箱'
# 接收者邮箱
receivers = ['接收者的邮箱']
message = MIMEMultipart()
# 发送者信息
message['From'] = Header(sender)
# 标题 参数 : 1、内容 2、编码格式
message['Subject'] = Header('python脚本测试', 'utf-8')
# 定义发送邮件的内容
attr = MIMEText(open('test.ppt', 'rb').read(), 'base64', 'utf-8')
attr['Content-Type'] = 'application/octet-stream'
attr['Content-Disposition'] = 'attachment;filename="test.ppt"'
message.attach(attr)
message.attach(MIMEText('这是一个带附件的邮件', 'plain', 'utf-8'))
try:
# 发送邮件
smtpObj = smtplib.SMTP()
# 连接
smtpObj.connect(mail_host, 25)
# 登录
smtpObj.login(mail_user, mail_pass)
# 发送
smtpObj.sendmail(sender, receivers, message.as_string())
except smtplib.SMTPException as e:
print('error: %s' % e)首先,它使用
MIMEMultipart类创建了一个电子邮件对象,这个对象可以同时包含文本内容和附件。然后,它使用
MIMEText类创建了一个文本内容对象,并使用open函数将本地文件作为二进制数据读入。接着,它使用
MIMEText对象的Content-Type和Content-Disposition属性设置了附件的文件类型和文件名。最后,它使用
attach方法将文本内容对象和附件对象添加到电子邮件对象中,并使用sendmail函数发送邮件。和之前的代码一样,如果发送邮件过程中出现了任何错误,就会抛出
SMTPException异常,使用try-except语句来捕获这个异常,并在出错时打印错误信息。
6.7 定时发送邮件
这里我们又要认识一个新的库:schedule。
#安装
pip install schedulePython 的 schedule 库支持以下时间格式:
| 时间格式 | 描述 |
|---|---|
| @once | 在程序启动时运行一次 |
| @hourly | 每小时运行一次,例如 00:00, 01:00, 02:00 等 |
| @daily | 每天运行一次,例如 00:00 |
| @weekly | 每周运行一次,例如星期一的 00:00 |
| @monthly | 每月运行一次,例如每月第一天的 00:00 |
| @yearly | 每年运行一次,例如每年的 1 月 1 日的 00:00 |
| @cron | 使用 crontab 格式(用空格分隔的 5 个字段)来指定时间,例如 "0 0 * * *" 表示每天的 00:00 运行一次。具体的格式可以参考 crontab 文档。 |
| datetime object | 使用 Python 的 datetime 对象来指定时间 |
例如,你可以使用以下代码在每周一的 00:00 运行一次任务:
# coding:utf-8
import smtplib
import time
from email.header import Header
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
# 第三方的smtp
import schedule
mail_host = 'smtp服务器'
mail_user = '你的邮箱'
mail_pass = '密钥'
# smtp 开通, 授权码
# 发送人邮箱
sender = '发送人的邮箱'
# 接收者邮箱
receivers = ['接收者的邮箱']
message = MIMEMultipart()
# 发送者信息
message['From'] = Header(sender)
# 标题 参数 : 1、内容 2、编码格式
message['Subject'] = Header('python脚本测试', 'utf-8')
# 定义发送邮件的内容
attr = MIMEText(open('test.ppt', 'rb').read(), 'base64', 'utf-8')
attr['Content-Type'] = 'application/octet-stream'
attr['Content-Disposition'] = 'attachment;filename="test.ppt"'
message.attach(attr)
message.attach(MIMEText('这是一个带附件的邮件', 'plain', 'utf-8'))
def send():
try:
# 发送邮件
smtpObj = smtplib.SMTP()
# 连接
smtpObj.connect(mail_host, 25)
# 登录
smtpObj.login(mail_user, mail_pass)
# 发送
smtpObj.sendmail(sender, receivers, message.as_string())
except smtplib.SMTPException as e:
print('error: %s' % e)
if __name__ == '__main__':
# 每周一的 00:00 运行一次
schedule.every().monday.at("00:00").do(send)
while True:
schedule.run_pending()
time.sleep(60)
你也可以使用 crontab 格式来指定更精细的时间,例如每隔 10 分钟运行一次:
if __name__ == '__main__':
# 每隔 10 秒运行一次
schedule.every(10).seconds.do(send)
while True:
schedule.run_pending()
time.sleep(60)6.8 为什么要使用while True 循环?
在上面的代码中,while 循环被用来不断检查是否有挂起的任务需要执行。
每当你使用 schedule.every().XXX.do(job) 这样的语句来安排任务时,schedule 库会将这个任务添加到一个挂起任务列表中。然后,你可以使用 schedule.run_pending() 函数来检查是否有挂起任务的执行时间已经到了,如果有,就执行这个任务。
所以为了不断检查是否有挂起任务需要执行,我们使用了一个无限循环。在这个循环内部,我们每次都调用 schedule.run_pending() 函数来检查是否有挂起任务需要执行,然后再调用 time.sleep(60) 函数来睡眠一段时间。
这样做的好处是,在程序启动后,schedule 库就会不断地检查是否有挂起任务需要执行,并在到达执行时间时立即执行这个任务。这使得你可以很方便地使用 schedule 库来安排周期性任务,而不需要手动去检查是否有任务需要执行。
当然,你也可以使用其他方法来实现这个功能,例如使用多线程或者使用第三方库等。但是,使用 schedule 库可以让你省去很多麻烦,使得安排周期性任务变得非常简单。
6.9 踩的一个坑

错误原因:
运行debug调试找到 socket.py 这个文件的第676行:

上图中’name’ 这个参数编码错误,这个name参数好像是来自于自己计算机的名称,我的电脑名称是中文。
方法:建议一步到位直接把自己电脑名字改成英文字母,很多涉及到网络的代码都会报编码错误(我的系统是win11)
参考文章:(6条消息) Python连接SMTP服务器报错:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xce in position 0......Systemd的博客-CSDN博客smtputf8