论文阅读DIFFUSION POLICIES AS AN EXPRESSIVE POLICY CLASS FOR OFFLINE REINFORCEMENT LEARNING

作者:Zhendong Wang,Jonathan J Hunt,Mingyuan Zhou
论文链接:https://www.aminer.cn/pub/62fa0d1490e50fcafd2462dd/
AI综述(大模型驱动):offline reinforcement学习(RL),旨在学习一个有效的政策,使用以前收集的静态数据集,是RL的一个重要范畴。标准的RL方法通常在这一任务中表现不佳,因为在外部收集动作对齐错误造成的函数近似错误。然而,已经提出了许多适当的规则化方法来解决这个问题,但这些方法通常受到有限的表达能力限制,有时会导致几乎不optimal的解决方案。在本文中,我们提出了一种新的基于条件传播模型的动态调整算法,该算法利用了条件传播模板作为高度表达性的政策类。在我们的方法中,我们在决策损失中学习了一个决策值函数,并添加了一个最大化决策值的时间限制。我们表明,基于模型的政策的表达性和决策改善结合在一起,产生了卓越的性能
摘要
离线强化学习( Reinforcement Learning,RL )是一种重要的强化学习范式,旨在利用先前收集的静态数据集学习最优策略。标准的RL方法在这种情况下往往表现不佳,因为它对分布外操作的函数逼近错误。虽然已经提出了多种正则化方法来缓解这一问题,但它们通常受到具有有限表达能力的策略类的约束,这可能导致高度次优的解决方案。在本文中,我们提出将政策表示为一种扩散模型,这是最近一类具有高度表现力的深度生成模型。我们引入了扩散Q学习( Diffusion-QL ),它使用条件扩散模型来表示策略。在我们的方法中,我们学习了一个动作-价值函数,并在条件扩散模型的训练损失中加入了一个最大化动作-价值的项,从而得到了一个寻找行为策略附近的最优动作的损失。我们展示了基于扩散模型的政策的表达能力,扩散模型下的行为克隆和政策改进的耦合都有助于Diffusion - QL的出色表现。我们在一个简单的具有多模态行为策略的2D赌博机例子中说明了我们的方法相比于先前工作的优越性。然后,我们证明了我们的方法可以在大多数D4RL基准测试任务上达到最先进的性能。
论文概述
1.提出了Diffusion-QL算法,将强化学习中的policy看作一个Diffusion model,利用Condition Diffusion model表示策略。
2.Diffusion-QL通过学习动作价值函数并将最大化动作值的项添加到Condition Diffusion model的训练损失中,寻求接近行为策略的最优动作。
3.在实验中,作者展示了基于Diffusion model的Policy的有效性,以及behavior cloning和策略改进在扩散模型中的耦合对Diffusion-QL的帮助,并在离线强化学习数据集D4RL上取得了优秀的性能。
一、INTRODUCTION
在离线强化学习(RL)中,我们的目标是从先前收集的数据集中学习最优策略,而无需与环境进行实时交互。离线 RL 在许多实际应用中具有吸引力,例如自动驾驶和病人治疗计划,因为与在线交互相比,依赖先前收集的数据更安全、更便宜、更省时。然而,仅依赖先前收集的数据使得离线 RL 成为一项具有挑战性的任务。
本文提出了一种新的离线 RL 算法 Diffusion-QL,该算法利用扩散模型(一种高度表达性的深度生成模型)表示策略。我们的方法在 D4RL 基准任务上的表现优于先前的方法。我们还通过一个简单的 2D 多模态行为策略强化学习任务展示了我们方法的优越性。
Diffusion-QL 的主要贡献在于使用扩散模型表示策略,使其具有更高的表达能力。此外,将行为克隆和策略改进融合到扩散模型中也有助于其优异性能。与此同时,我们的方法在简单的 2D 多模态行为策略强化学习任务中胜过了先前的工作。最后,我们展示了我们的方法在大多数 D4RL 基准任务上的表现优于先前的方法。
贡献
1.提出了一种新的离线RL算法,即Diffusion-QL,利用扩散模型进行精确的策略正则化,并成功地将Q学习指导注入反向扩散链以寻求最优行动。
2.通过在D4RL基准任务上进行离线RL测试,发现Diffusion-QL在大多数任务上优于先前的方法。
3.通过在一个简单的土匪任务上进行可视化,展示了Diffusion-QL相较于先前方法的优势之处。
二、PRELIMINARIES AND RELATED WORK
Offline RL
离线强化学习环境可以被建模为马尔可夫决策过程(MDP) M = {S, A, P, R,d0,γ} γ:折扣因子(Discount Factor)γ∈[ 0 , 1 ),初始状态分布d0
累计折扣奖励:(目标是学习以θ为参数的策略 ![]() ,使得累积折扣奖励最大化)
,使得累积折扣奖励最大化)
![]()
动作价值函数:
![]()
离线数据集:(静态数据集代替环境,离线RL算法完全从这个静态的离线数据集D中学习一个策略,而不需要与环境进行在线交互)

Diffusion Model

前向扩散链以预定义的方差表βi在T步中逐步向数据x0~q ( x0 )添加噪声。
通过最大化定义为Eq的证据下界来优化一个反向扩散链。
经过训练后,扩散模型的采样由采样xT~p ( xT )和运行反向扩散链从t = T到t = 0组成。通过调节p θ ( xt - 1 | xt , c),扩散模型可以直接扩展到条件模型。
Related Work: Policy Regularization
- 在正则化策略类中,大多数离线RL的先前方法依赖于策略正则化的行为克隆:BCQ将策略构造为可学习的、最大价值约束的偏离于单独学习的Conditional - VAE ( CVAE )行为克隆模型;
- BEAR在策略改进步骤中通过最小化MMD增加了一个加权的行为克隆损失;
- TD3 + BC 采用与BEAR相同的最大似然估计( MLE )方法;
- BRAC 评估了多种行为克隆正则化方法,如KL散度、MMD和Wasserstein对偶形式;
- IQL是一种具有"样本内"学习Q值函数的优势加权行为克隆方法。
- Goo & Niekum强调线下学习中进行外显行为克隆的必要性,而Ajay et al 则承认条件生成模型在决策中的力量。
Related Work: Diffusion Models in RL
Pearce等人提出通过具有表达能力和稳定性的扩散模型来更好地模拟人类行为。扩散器采用扩散模型作为轨迹发生器。状态-动作对的完整轨迹构成了扩散模型的单一样本。学习一个单独的回报模型来预测每个轨迹样本的累积回报。然后将回归模型的指导注入到反向采样阶段。该方法类似于Decision Transformer (DT),同样借助真实轨迹返回结果,通过GPT2 学习一个轨迹生成器。当在线使用时,序列模型不再能够预测来自状态自回归(因为状态是环境的结果)的动作。因此,在评估阶段,每个状态只需执行第一个动作即可预测一条完整的轨迹,这将导致较大的计算代价。我们的方法以不同的方式使用了RL的扩散模型。
我们将扩散模型应用于动作空间,并将其形成为以状态为条件的条件扩散模型。这种方法是无模型的,扩散模型是一次采样单个动作。进一步,我们的Q值函数指导在训练过程中被注入,这在我们的案例中提供了良好的实证性能。虽然Diffuser ( Janner等人, 2022年)和我们的工作都在离线RL中应用了扩散模型,但Diffuser是从基于模型的轨迹规划角度出发的,而我们的方法是从离线无模型策略优化角度出发的。
三、DIFFUSION Q-LEARNING(本文的方法)
如何在训练阶段将Q - learning指导加入到我们的扩散模型的学习中,并将行为克隆项作为策略正则化的一种形式。
由于diffusion 过程和reinforcement learning使用不同的时间步,所以作者这里使用两种不同的时间步,其中下标i ∈ {1, . . . , N } 表示diffusion的时间步,下标t ∈ {1, . . . , T }表示trajectory(轨迹)的时间步。
作者通过conditional diffusion model的reverse过程来表示强化学习的Policy:
![]()
在diffusion model的逆过程中,最后用动作 a0 来评估RL。通常来说, pθ(ai−1 | ai, s)可以被表示为高斯分布 N (ai−1; μθ(ai, s, i), Σθ(ai, s, i))。
作者基于DDPM中的(重参数)技巧,将pθ(ai−1 | ai, s) 视为噪声预测模型,协方差矩阵固定为Σθ(ai, s, i)= βiI,将均值表示为:

具体做法,先从 aN ~N (0, I) 采样得到第一步,然后基于diffusion的reverse过程,将动作向前推,最终得到动作, 具体如下:
![]()
当i = 1时,ε设为0,以提高采样质量。
作者通过模仿DDPM中对目标函数简化的方式,简化了条件ε-model通过下述公式:
![]()
其中u 是在离散集合 {1, . . . , N } 的均匀分布,D 表示基于行为策略 πb 收集的离线数据集,diffusion model的损失Ld(θ) 是行为克隆损失,旨在学习行为策略πb(a | s)。
在Diffusion 的reverse 过程,提供了一个隐式的、表达性强的分布,可以捕捉离线数据的复杂分布特性,如偏度和多峰性。此外,该正则化是基于采样的,只需要从离线数据集D中和当前策略中随机采样。
可以在每个diffusion过程中对每个数据点通过采样,使得Ld(θ) 非常有效地优化。
Q函数本身是以传统方式学习的,通过使用Double Q-learning技巧和贝尔曼算子进行优化。构建两个Q网络: Qφ1 , Qφ2 ,,以及目标网络 Qφ′ 1 , Qφ′ 2和策略πθ′。通过下面目标函数,优化 φ1,φ2 :![]()
论文伪代码

四、Experiment
A simple Bandit task
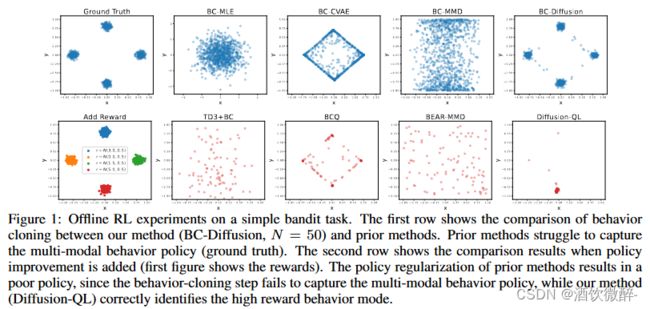
一个简单的赌博任务,其中行动是在二维空间中实值的,a ∈ [−1, 1]2 。构建了一个离线数据集D = {(aj)}M j=1 ,其中M = 10000 个行动示例,这些行动是从四个高斯分布的等量混合中收集的,这些高斯分布的中心μ ∈ {(0.0, 0.8), (0.8, 0.0), (0.0, −0.8), (−0.8, 0.0)} ,标准偏差为σd = (0.05, 0.05))。该实验展示了行为策略分布中的强多模性,这通常是在由不同策略收集数据集时出现的情况。
实验对比了diffusion在behavior cloning任务上的效果.
第一行展示了不同BC-diffusion(N=50)与其他baseline的对比结果,BC-diffusion捕获了行为策略的所有四个密度模式。而相比于其他正则方法,没有很好地捕捉到密度模式。之后为每一个数据点分配了一个高斯分布的采样的奖励,其平均值由数据中心确定,标准偏差为0.5,如在上图第二行所示。之后作对比了Diffusion-QL和其他baseline,发现Diffusion-QL能比较好地收敛到最优的分布上,而其他baseline收敛到次优策略上,有的甚至无效果。
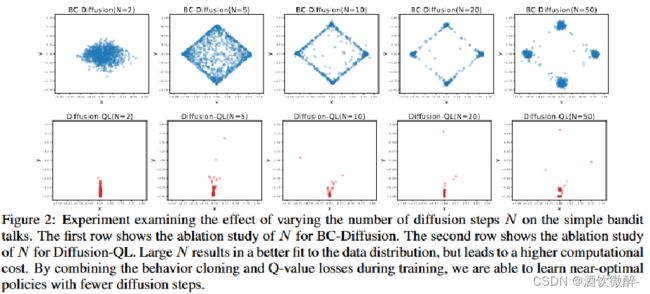
检验了步数N对Diffusion model的影响实验,第一行显示了BC-Diffusion中N的消融实验,第二行显示了Diffusion-QL中 N的消融实验。当N越大,可以更好地拟合数据,但是会导致更大的计算成本。
D4RL data:在Gym tasks、AntMaze tasks、Adroit tasks、Kitchen tasks等离线强化学习任务上,Diffusion-QL均能达到较好的结果。
Results for Gym Domain

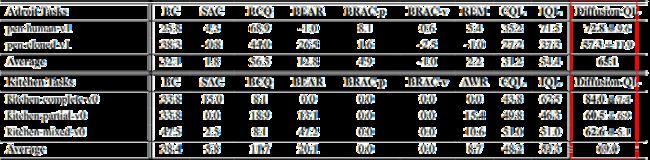
虽然大多数基线在Gym任务上已经很好地工作,但Diffusion - QL往往能以明显的幅度进一步提高它们的性能,特别是在"medium"和"medium-replay"任务中。值得注意的是,"medium"数据集包括一个在线SAC代理收集的轨迹,该代理训练的性能约为专家性能的1 / 3。因此,当时的Tanh - Gaussian策略通常是探索性的,不具有集中性,这使得收集到的数据分布难以学习。
即使在复杂情况下,扩散模型也具有模仿行为策略的表达能力,策略改进项将引导策略收敛于探索行动空间子集中的最优行动。这两个部分是Diffusion - QL具有良好经验性能的关键。
Results for AntMaze Domain
稀疏的奖励和大量的次优轨迹使得AntMaze任务尤为困难。为了获得良好的性能,需要强而稳定的Q学习。例如,基于BC的方法很容易在"中等"和"大型"任务上失败。我们证明了在条件扩散模型的训练过程中加入的Q学习指导是稳定有效的。在实证上,当η取适当值时,我们发现Diffusion - QL明显优于现有方法,特别是在更难的任务上,如"large-diverse"任务。
Results for Adroit and Kitchen Domain
我们发现Adroit域需要较强的策略正则化来克服离线强化学习中的外推误差,这是由于人工示教的狭隘性造成的。在较小的η下,Diffusion - QL以其基于反向扩散的策略容易战胜其他baseline,具有较高的表达能力和较好的策略正则性。此外,对于Kitchen任务,需要进行长期的值优化,而我们发现Diffusion - QL在这个领域也有很好的表现。
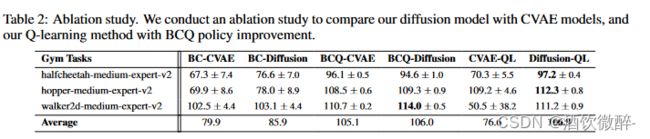
消融实验
分析了为什么在D4RL任务上,Diffusion - QL优于其他基于策略约束的方法。对Diffusion - QL的两个主要组成部分进行了消融研究:使用扩散模型作为表达性政策和Q - learning指导。
对于策略部分,我们将我们的扩散模型与流行的用于行为克隆的CVAE模型进行比较。
对于Q - learning部分,我们与BCQ方法在政策改进方面进行了比较。
在消融实验主要比较了diffusion模块的重要性,Diffusion对比与CVAE,Diffusion在各模块上的表现都比CVAE好。
实验细节
我们训练了1000个( 2000年的Gym任务)。每个历元由1000个梯度步长组成,批大小为256。训练通常相当稳定,如图3所示,但我们观察到Ant Maze任务的训练因其稀疏的奖励设置和离线数据中缺乏最优轨迹而存在变化。因此,我们在训练过程中保存多个模型检查点,并使用完全离线的方法,如附录D所述,选择最佳检查点进行性能评估。使用Ld loss作为在线性能的滞后指标,我们执行提前停止并选择Ld值第二或第三低的检查点。我们的主要论文中的结果都是基于离线模型选择的。当少量的在线交互可以用于模型选择时,我们可以达到甚至更好的结果。
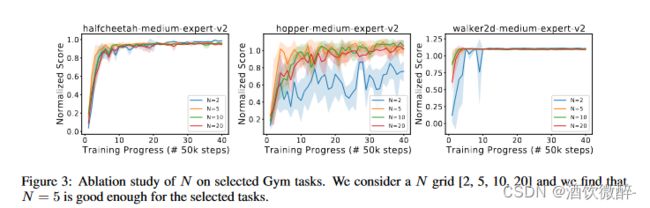
由图我们可知:随着N(超参数)的增加,模型收敛速度更快,性能更加稳定。
在接下来的D4RL任务中,设置了一个适中的值,N = 5,以平衡性能和计算成本。在N = 5的情况下,Diffusion - QL的训练时间与CQL 相似。其他超参数,如学习率和η,在附录E中提供。
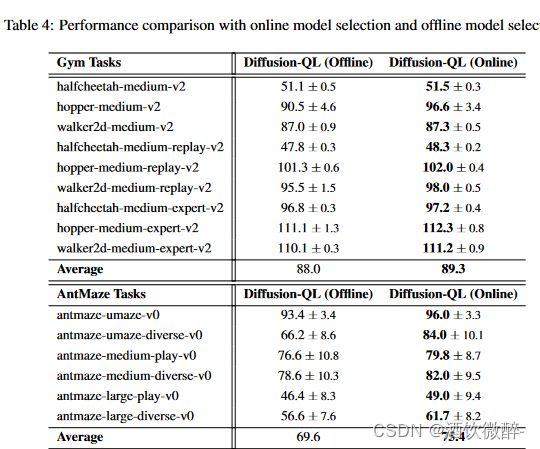
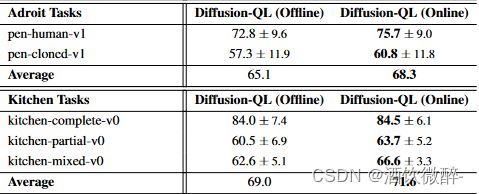
五、CONCLUSION
Offline RL(离线强化学习)是一种重要的RL(强化学习)范式,旨在使用先前收集的静态数据集学习最优策略,而无需与环境进行实时交互。离线RL的一个主要挑战是如何在仅依赖先前收集的数据的情况下,学习有效的策略。标准的策略改进方法在离线数据集上的应用通常导致过度估计了未在数据集中见过的动作的值,从而学习出低效的策略。
为了解决这个问题,研究人员提出了一种名为Diffusion-QL的方法,该方法将策略表示为扩散模型,这是一种具有高度表达能力的深度生成模型。Diffusion-QL有两个主要组成部分:
-
使用扩散模型作为策略:通过将策略建立在条件扩散模型的反向链上,扩散模型允许构建高度表达的策略类,同时其学习本身作为一种强大的策略正则化方法。
-
Q-学习引导:通过联合学习的Q值函数,将Q-学习引导注入扩散策略的学习中。这使得在探索区域内的去噪采样向最优区域进行导向。
Diffusion-QL在D4RL基准任务中的表现优于先前的方法,证明了该方法在离线RL中的优越性。
未来工作
最近有许多工作专注于提高扩散模型的采样速度,可用于提高Diffusion - QL的采样效率。例如,扩散策略可能在训练后被提炼为更简单的前馈策略。