Hadoop入门概念
Hadoop作者:Dong Cutting.
受Google三篇论文的启发.
版本:
Apache:官方版本
Cloudera:官方版本的封装,优化,打很多patch,商业版本
HortonWorks:基于apache的版本进行了集成
hadoop是什么?
一个适合大数据的分布式存储和计算平台.
是一个平台,分布式的存储和分布式的计算,在平台之上跑的一般都是大数据.抽象的层面理解hadoop就是一个分布式的平台.
什么是分布式的存储系统?
数据实际被分散存储,但是对于开发人员而言感觉不到.
什么是分布式计算?
一台tomcat不行的话,我们用多台tomcat来应对,用户的请求就被分散到多台机器上去了,一定要有一个请求的分发机制.
什么是分布式计算系统?
用户的请求过来之后,被分散到多台机器上运行,但是开发人员感觉不到,不需要去管,是不是真的在很多机器上在运行,对用户操作透明的计算系统就是一种分布式计算系统.
分布式存储和计算的平台是跨操作系统的,封装了操作系统,操作系统的差异对我们用户来说是透明的,适合大数据的.小数据放在hadoop上计算,效率低
什么样的数据可以称为大数据呢?
上百G,PB,TB级别的,传统的应用搞不定的数据
为什么要有有分布式存储?
数据在单服务器下存储搞不定了,这时候,逼着我们要把数据存在很多台机器上存储,但是,很多台服务器对我们开发人员而言必须要知道他们,识别他们,才处理它上边的数据,对我们开发人员而言我们期望有一个透明的系统去管理分布式存储
为什么要有分布式计算?
集中式计算的瓶颈是在磁盘IO上.把数据分不到多台服务器上存储,计算请求分散到多台服务器上同时执行,计算任务很少,
Hadoop核心项目:
HDFS:Hadoop Distributed File System分布式文件系统,用来管理文件的.在hdfs上存储的数据是分散很多服务器之上的,但是用户感觉不到,文件真的分布在很多台机器上,就像一台机器上似的.
MapReduce:分布式并行计算框架.实现的是分布式计算,大数据分布在很多台服务器上,需要它去并行地去执行
Map:在每个分散的机器上进行计算的那部分.Reduce:主要做最后的一个汇总
HDFS架构:
hdfs和MapReduce都是主从结构.管理与被管理这种关系,分为管理者和被管理者.被管理者通常做具体的事物的,管理者通常是组织,协调,管理工作的.
节点:网络环境中的每一台服务器.
主节点:只有一个NameNode,负责各个节点数据的组织管理,
从节点:有很多个DataNode,负责存储数据,数据节点
NameNode对外,DataNode对内,NameNode接收用户的操作请求,NameNode负责协调管理,不是真正的存放数据,会把数据分散到各个节点上去存储
海量数据是单节点处理不了的,所以我们的数据需要存放在多台服务器上,作为管理的NamNode知道数据具体存放在DataNode的哪些节点上面
NameNode如何知道数据存放在DataNode节点的位置的呢?
NameNode对外暴漏的就是目录的文件系统
用户要进行hdfs操作的时候,首先和NameNode打交道,NameNode上边有一个文件系统的目录结构,用户通过看文件系统的目录结构,就知道我们的数据是存放在那个路径下面,文件叫什么名字,文件的路径,文件有多大,我们的数据具体存放在那些节点上,客户是不需要关心的
NamNode负责:接收用户操作请求,是用户操作的入口.维护文件系统的目录结构,称作命名空间.
DataNode负责:存储文件数据
MapReduce架构:
主节点执行一个管理者的角色,从节点执行一个被管理者的角色.管理和被管理完成数据的一个计算(任何对数据的处理都叫做计算,查询,过滤,数据的检索..利用cpu和内存进行数据处理).
主节点只有一个:JobTracker,
把我们用户的操作请求,拿过来,分发给TaskTracker,接收用户提交的计算任务,把计算任务分配到TaskTracker去执行,监控TaskTracker的执行情况
从节点有很多个:TaskTracker,
是我们自己安装部署的,通常和DataNode在一起,执行用户的操作,运行时根据TaskTracker上DataNode的数据只执行一部分,执行程序时,去找DataNode本地的数据,然后加载DataNode上边的数据,去运行
MapReduce进行计算时,处理的数据就是用户提交的这些数据
TaskTracker通过反射将我们的程序读进内存中,然后在jvm中运行,程序在含有数据的DataNode的节点上运行
TaskTracker负责用户提交的计算任务
节点的数量越多,整体的计算时间越短,JobTracker管理执行任务的TaskTracker
NameNode和DataNode负责完成数据存储
JobTracker和TaskTracker完成数据的计算
NameNode和JobTracker不一定非要在同一台机器上,在生产中,通常是分开的,因为用户的请求,NameNode也接收,JobTracker也接收,为了防止NameNode操作慢,所以NameNode 最好是一台机器,充分利用cpu和内存,JobTracker也是一台机器,都是独立的
DataNode和TaskTracker通常是同一台机器,是因为TaskTracker在运行的时候,可以执行本地的数据,如果不在一起,就要经过网络传播(网络一不稳定,二耗时) DataNode只管理本地, 不管理远程
JobTracker和TaskTracker不从HDFS上读数据一样可以去做事情
用户存储数据首先和NameNode打交道,用户的数据直接和DataNode打交道,绕过了NameNode,就是说用户在进行存储的时候,去问NameNode我要去哪里读写数据,一旦用户知道了, 就没有NameNode的事了,直接去DataNode那去处理了.假设用户处理数据一定经过NameNode,那么两三个用户上来之后,NameNode内存几乎全爆了,因为是海量数据,内存肯定是装不下 的.只是向NameNode申请block块和blockId
架构的设计是让数据传输的时候不经过NameNode,所以架构没有瓶颈
Hadoop的特点:
扩容能力(Scalable):能可靠(reliably)地存储和处理PB级别的数据.这就是存储数据的,数据装不了了,再增加节点就可以了
成本低(Economical):可以通过普通机器组成的服务器群来分发以及处理数据.这些服务器群总即可达数千个节点.
高效率(Efficient):通过分发数据,hadoop可以在数据所在节点上并行地(parallel)处理他们,这使得处理非常的迅速.
可靠性(Reliable):hadoop能够自动地维护数据的多份副本,并且在任务失败后能够自动地重新部署(redeploy)计算任务.JobTracker可以监控TaskTracker运行情况,一旦TaskTracker崩了,在其他的节点上再起一个任务,可以保证任务的执行
Hadoop集群的物理分布: 
主节点只有一个,从节点有很多个,并且TaskTracker和DataNode都在一起,实际部署中JobTracker和NameNode各有一台机器,集群需要扩展的时候只需要增加从节点就可以了,机器之 间通信通过网络进行传输.用户通过一个外部网络连接到我们的这个局域网中
单节点的物理结构:
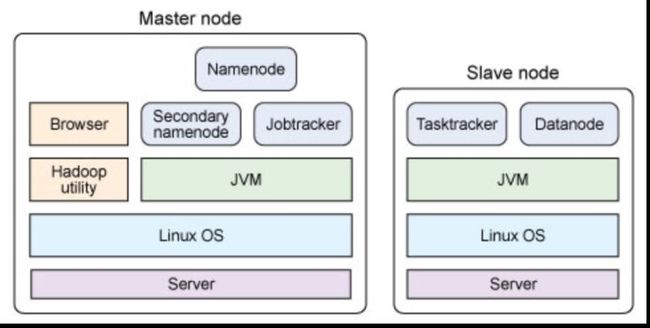
无论是主节点或者是从节点都有一个共同点,他们都是一台服务器,上边装的都是Linux操作系统,Linux之上又装了JVM,在虚拟机上跑的都是一些java程序.如果只有一个java程序运行的 话,叫做集中式的运行环境,如果会开启很多的java程序去运行的话,它就是一个分布式应用环境,hadoop运行时,会有很多的java程序
主节点和从节点的区分:
根据服务上运行的java程序的不同区分,有的程序扮演主节点,有的程序扮演从节点.一个节点可以有多个java进程, 也可以有一个,这些节点可以在一个机器上,也可以在很多台机器上 分散的.