【设计模式】十.结构型模式之组合模式
组合模式
一. 说明
组合模式将对象组合成树形结构来表示部分与整体的层次结构,是结构型模式之一。组合模式使得我们对单个对象和组合对象的使用具有一致性。
组合模式创建了一个包含自己对象组的类,该类提供了修改相同对象组的方式。
生活中组合模式的例子比比皆是,像文件和文件夹、公司的组织架构等都是部分与整体的反应,都是树形结构。所以我们开发中遇到能形成树形结构的地方,就可以使用组合模式统一管理单个对象和组合对象。
二.应用场景
- 后台系统中常见的树形菜单列表
- 开发中经常遇到的树形省市区结构
- 在java.awt包中绘制界面的组件Container、Button、Checkbox等都是组合模式的应用
- 在Spring中,提供了CacheManager接口用来管理缓存,它有一个实现CompositeCacheManager类就是组合模式的应用
三.代码示例
1. 我们由浅入深,先以公司的组织架构为例子简单描述以下组合模式的写法。
先创建一个抽象类,用来表示公司中的单个部分,它们都有添加和删除子部门的功能
@Data
public abstract class Component {
//部门名称
private String name;
//部门层级
private int depth;
public Component(String name, int depth) {
this.name = name;
this.depth = depth;
}
abstract void add(Component component);
abstract void remove(Component component);
abstract List<Component> getChildren();
//绘制部门层级关系
public void display() {
for (int i = 0; i < depth; i++) {
System.out.print("-");
}
System.out.println(this.name);
List<Component> children = getChildren();
children.forEach(componet -> {
for (int i = 0; i <= depth; i++) {
System.out.print("-");
}
System.out.println(componet.getName());
componet.getChildren().forEach(c -> c.display());
});
}
}
再建立部门实体,所有部门都是Component的子类
public class Department extends Component {
private List<Component> children = new ArrayList<>();
public Department(String name, int depth) {
super(name, depth);
}
@Override
void add(Component component) {
children.add(component);
}
@Override
void remove(Component component) {
children.remove(component);
}
@Override
List<Component> getChildren() {
return children;
}
}
编写测试打印结果
public static void main(String[] args) {
Department company = new Department("总公司", 0);
Department hr = new Department("HR部门", 1);
Department dp = new Department("研发部", 1);
Department ad = new Department("行政部", 1);
Department fd = new Department("财务部", 1);
company.add(hr);
company.add(dp);
company.add(ad);
company.add(fd);
Department f = new Department("前台", 2);
Department b = new Department("后勤", 2);
ad.add(f);
ad.add(b);
Department front = new Department("前端组", 2);
Department backend = new Department("后端组", 2);
dp.add(front);
dp.add(backend);
company.display();
}
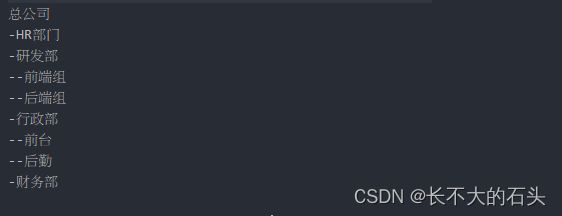
由此可见,我们可以使用组合模式将多个单一部分组合成一个整体,并且在使用过程中单一和整体的使用方式是一致的。
2. 我们再看看Spring的CacheManager是如何使用组合模式的。
CacheManager接口只提供了两个方法getCache()和getCacheNames()。
public interface CacheManager {
@Nullable
Cache getCache(String name);
Collection<String> getCacheNames();
}
在实现类CompositeCacheManager中实现了这两个方法并且维护了一个CacheManager的List。
public class CompositeCacheManager implements CacheManager, InitializingBean {
private final List<CacheManager> cacheManagers = new ArrayList();
private boolean fallbackToNoOpCache = false;
public CompositeCacheManager() {
}
public CompositeCacheManager(CacheManager... cacheManagers) {
this.setCacheManagers(Arrays.asList(cacheManagers));
}
public void setCacheManagers(Collection<CacheManager> cacheManagers) {
this.cacheManagers.addAll(cacheManagers);
}
public void setFallbackToNoOpCache(boolean fallbackToNoOpCache) {
this.fallbackToNoOpCache = fallbackToNoOpCache;
}
public void afterPropertiesSet() {
if (this.fallbackToNoOpCache) {
this.cacheManagers.add(new NoOpCacheManager());
}
}
@Nullable
public Cache getCache(String name) {
Iterator var2 = this.cacheManagers.iterator();
Cache cache;
do {
if (!var2.hasNext()) {
return null;
}
CacheManager cacheManager = (CacheManager)var2.next();
cache = cacheManager.getCache(name);
} while(cache == null);
return cache;
}
public Collection<String> getCacheNames() {
Set<String> names = new LinkedHashSet();
Iterator var2 = this.cacheManagers.iterator();
while(var2.hasNext()) {
CacheManager manager = (CacheManager)var2.next();
names.addAll(manager.getCacheNames());
}
return Collections.unmodifiableSet(names);
}
}
在getCache()方法中,取缓存时则是遍历所有的CacheManager挨个获取,取到则已。
3. 组合模式在营销活动中的应用
这里引用小傅哥《重写设计模式》一书里的案例,在营销业务上,我们经常需要变动营销规则,类似根据用户画像给不同用户发放优惠券的场景,男性用户发放电子产品的优惠券,女性用户发放美妆的优惠券,或者根据年龄区分,不同年龄段的人适用的条件也不相同。
这些营销条件,在实际活动中不是一成不变的,大多情况下都会各种组合叠加并用,在大型的营销系统下,我们可以借助第三方工具规则引擎去实现这些复杂变动的业务逻辑,而如果营销活动或者营销功能不是那么的庞大,但规则依然是频繁变动的,我们又不想引入第三方的组件来实现,这种情况下,只能在代码里编写ifelse,不断叠加和修改活动条件来达到目的,随着频繁的变动,代码就会非常晦涩和臃肿。
那这里,小傅哥就告诉我们,可以使用组合模式编织我们的规则决策树结构,通过抽象化的代码去实现这种业务。
我们这里设定案例场景,根据用户的性别和年龄做发放不同的优惠券,男性在22岁以下的发放游戏券,22岁以上的发放电脑券;女性在22岁以下的发放衣服券,22岁以上的发放美妆券。
我们构建决策树时,用户的性别和年龄这些条件实际上就是树枝的枝干节点,游戏券电脑券等优惠券就是树枝的叶子节点。
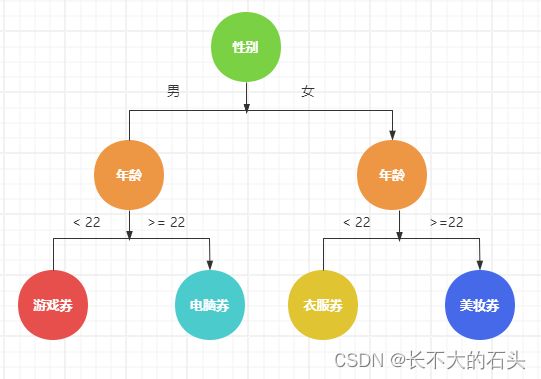
整个规则决策器分为三大部分:决策树模块,规则过滤器,决策引擎。
a. 决策树模块
在这个案例中,我们根据模型建立决策树,如图所示
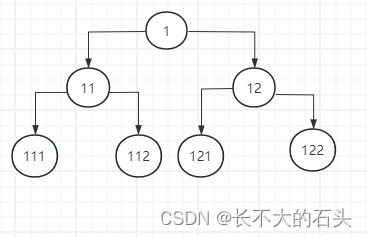
节点中的数字表示的是节点的id, 节点有两种类型,一种是有子节点的树枝节点,表示的是逻辑条件,就是例子中用户的性别和年龄等条件;一种是没有子节点的叶子节点,表示的是最终的决策结果,就是例子中的优惠券。
节点与子节点通过链接连接,这里的链接表示逻辑判断单元,例如从1到11,表示的是从性别中判断是否等于男性;从12到122表示的是用户为女性的在22岁以上的决策结果。逻辑判断单元可以抽象为五种,即等于,大于,小于,大于等于,小于等于。
这里我们开始用组合模式的代码来构建这个决策树,代码默认集成lombok插件。
整个代码结构如图所示
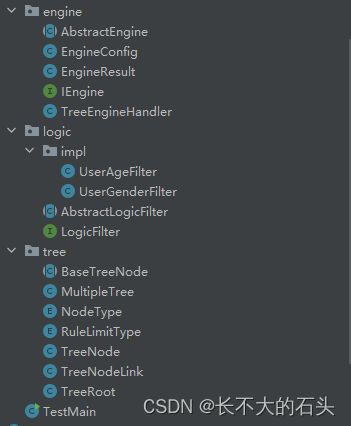
先创建一个抽象树节点类,它让所有节点具有添加删除子节点,添加删除链接的功能
@Data
public abstract class BaseTreeNode implements Cloneable {
public abstract void addNode(BaseTreeNode treeNode);
public abstract void removeNode(BaseTreeNode treeNode);
public abstract void addLink(TreeNodeLink treeNodeLink);
public abstract void removeLink(TreeNodeLink treeNodeLink);
public abstract List<BaseTreeNode> getChildren();
public abstract List<TreeNodeLink> getTreeNodeLinks();
}
再创建树节点类和树链接类
//树节点类
@Data
public class TreeNode extends BaseTreeNode {
private String treeId; //树id
private Long treeNodeId; //树节点id
private NodeType nodeType; //节点类型;树枝,叶子
private String nodeValue; //节点值[nodeType=2];表示叶子节点的值,可以是优惠券id
private String ruleKey; //规则Key
private String ruleDesc; //规则描述
private List<TreeNodeLink> treeNodeLinks = new ArrayList<>(); //节点链路
private List<BaseTreeNode> children = new ArrayList<>(); //子节点
@Override
public void addNode(BaseTreeNode treeNode) {
children.add(treeNode);
}
@Override
public void removeNode(BaseTreeNode treeNode) {
children.remove(treeNode);
}
@Override
public void addLink(TreeNodeLink treeNodeLink) {
treeNodeLinks.add(treeNodeLink);
}
@Override
public void removeLink(TreeNodeLink treeNodeLink) {
treeNodeLinks.remove(treeNodeLink);
}
@Override
protected TreeNode clone() {
try {
TreeNode treeNode = (TreeNode) super.clone();
List<BaseTreeNode> list = new ArrayList<>(this.children.size());
list.addAll(this.children);
treeNode.setChildren(list);
return treeNode;
} catch (CloneNotSupportedException e) {
throw new RuntimeException(e);
}
}
}
//树链接类
@Data
public class TreeNodeLink implements Cloneable{
private Long nodeIdFrom;//节点From
private Long nodeIdTo;//节点To
private RuleLimitType ruleLimitType; //逻辑运算类型
private String ruleLimitValue; //规则限定值
@Override
protected TreeNodeLink clone(){
try {
return (TreeNodeLink) super.clone();
} catch (CloneNotSupportedException e) {
throw new RuntimeException(e);
}
}
}
//枚举类
@Getter
public enum NodeType {
/**
* 树节点
*/
TREE_NODE,
/**
* 叶子节点
*/
LEFT_NODE
}
@Getter
public enum RuleLimitType {
EQ,
GT,
LT,
GE,
LE
}
这里使用了原型克隆的模式将节点的子节点做了深克隆,方便我们后面做对象转换。
我们再创建一个类TreeRoot表示整个树的信息,创建一个类MultipleTree做为多个决策树的容器,因为项目中会存在多组条件相互组合的情况,我们需要给单个树编个号,决策时传入树编号,选择某个树去执行。
@Data
public class TreeRoot {
private String treeId;
private Long treeRootNodeId;
private String treeName;
private Map<Long, TreeNode> treeNodeMap;
public TreeRoot(String treeName, TreeNode root) {
this.treeId = root.getTreeId();
this.treeRootNodeId = root.getTreeNodeId();
this.treeName = treeName;
this.treeNodeMap = new HashMap<>(8);
addTreeNodeMap(root);
}
private void addTreeNodeMap(TreeNode treeNode) {
TreeNode clone = treeNode.clone();
clone.getChildren().clear();
treeNodeMap.put(clone.getTreeNodeId(), clone);
if (CollectionUtils.isEmpty(treeNode.getChildren())) {
return;
}
for (BaseTreeNode node : treeNode.getChildren()) {
addTreeNodeMap((TreeNode) node);
}
}
}
@Data
public class MultipleTree implements Serializable {
private List<TreeRoot> trees;
public MultipleTree() {
}
public MultipleTree(TreeRoot treeRoot) {
List<TreeRoot> trees = new ArrayList<>(1);
trees.add(treeRoot);
this.trees = trees;
}
public MultipleTree(List<TreeRoot> trees) {
this.trees = trees;
}
/**
* 根据treeId从多条决策树中获取对应的树
*/
public TreeRoot getTreeRoot(String treeId) {
if (trees == null || trees.size() == 0) {
return null;
}
for (TreeRoot tree : trees) {
if (tree.getTreeId().equals(treeId)) {
return tree;
}
}
return null;
}
}
模型都有了,编写构建代码
@Slf4j
public class Test {
public static MultipleTree buildTree() {
// 节点:1
TreeNode treeNode_01 = new TreeNode();
treeNode_01.setTreeId("10001");
treeNode_01.setTreeNodeId(1L);
treeNode_01.setNodeType(NodeType.TREE_NODE);
treeNode_01.setNodeValue(null);
treeNode_01.setRuleKey("userGender");
treeNode_01.setRuleDesc("用户性别[男/女]");
// 链接:1->11
TreeNodeLink treeNodeLink_11 = new TreeNodeLink();
treeNodeLink_11.setNodeIdFrom(1L);
treeNodeLink_11.setNodeIdTo(11L);
treeNodeLink_11.setRuleLimitType(RuleLimitType.EQ);
treeNodeLink_11.setRuleLimitValue("man");
// 链接:1->12
TreeNodeLink treeNodeLink_12 = new TreeNodeLink();
treeNodeLink_12.setNodeIdFrom(1L);
treeNodeLink_12.setNodeIdTo(12L);
treeNodeLink_12.setRuleLimitType((RuleLimitType.EQ));
treeNodeLink_12.setRuleLimitValue("woman");
// 节点:11
TreeNode treeNode_11 = new TreeNode();
treeNode_11.setTreeId("10001");
treeNode_11.setTreeNodeId(11L);
treeNode_11.setNodeType(NodeType.TREE_NODE);
treeNode_11.setNodeValue(null);
treeNode_11.setRuleKey("userAge");
treeNode_11.setRuleDesc("用户年龄");
// 链接:11->111
TreeNodeLink treeNodeLink_111 = new TreeNodeLink();
treeNodeLink_111.setNodeIdFrom(11L);
treeNodeLink_111.setNodeIdTo(111L);
treeNodeLink_111.setRuleLimitType(RuleLimitType.LT);
treeNodeLink_111.setRuleLimitValue("22");
// 链接:11->112
TreeNodeLink treeNodeLink_112 = new TreeNodeLink();
treeNodeLink_112.setNodeIdFrom(11L);
treeNodeLink_112.setNodeIdTo(112L);
treeNodeLink_112.setRuleLimitType(RuleLimitType.GE);
treeNodeLink_112.setRuleLimitValue("22");
// 节点:12
TreeNode treeNode_12 = new TreeNode();
treeNode_12.setTreeId("10001");
treeNode_12.setTreeNodeId(12L);
treeNode_12.setNodeType(NodeType.TREE_NODE);
treeNode_12.setNodeValue(null);
treeNode_12.setRuleKey("userAge");
treeNode_12.setRuleDesc("用户年龄");
// 链接:12->121
TreeNodeLink treeNodeLink_121 = new TreeNodeLink();
treeNodeLink_121.setNodeIdFrom(12L);
treeNodeLink_121.setNodeIdTo(121L);
treeNodeLink_121.setRuleLimitType(RuleLimitType.LT);
treeNodeLink_121.setRuleLimitValue("22");
// 链接:12->122
TreeNodeLink treeNodeLink_122 = new TreeNodeLink();
treeNodeLink_122.setNodeIdFrom(12L);
treeNodeLink_122.setNodeIdTo(122L);
treeNodeLink_122.setRuleLimitType(RuleLimitType.GE);
treeNodeLink_122.setRuleLimitValue("22");
// 节点:111
TreeNode treeNode_111 = new TreeNode();
treeNode_111.setTreeId("10001");
treeNode_111.setTreeNodeId(111L);
treeNode_111.setNodeType(NodeType.LEFT_NODE);
treeNode_111.setNodeValue("游戏券");
// 节点:112
TreeNode treeNode_112 = new TreeNode();
treeNode_112.setTreeId("10001");
treeNode_112.setTreeNodeId(112L);
treeNode_112.setNodeType(NodeType.LEFT_NODE);
treeNode_112.setNodeValue("电脑券");
// 节点:121
TreeNode treeNode_121 = new TreeNode();
treeNode_121.setTreeId("10001");
treeNode_121.setTreeNodeId(121L);
treeNode_121.setNodeType(NodeType.LEFT_NODE);
treeNode_121.setNodeValue("衣服券");
// 节点:122
TreeNode treeNode_122 = new TreeNode();
treeNode_122.setTreeId("10001");
treeNode_122.setTreeNodeId(122L);
treeNode_122.setNodeType(NodeType.LEFT_NODE);
treeNode_122.setNodeValue("美妆券");
treeNode_01.addNode(treeNode_11);
treeNode_01.addNode(treeNode_12);
treeNode_01.addLink(treeNodeLink_11);
treeNode_01.addLink(treeNodeLink_12);
treeNode_11.addNode(treeNode_111);
treeNode_11.addNode(treeNode_112);
treeNode_11.addLink(treeNodeLink_111);
treeNode_11.addLink(treeNodeLink_112);
treeNode_12.addNode(treeNode_121);
treeNode_12.addNode(treeNode_122);
treeNode_12.addLink(treeNodeLink_121);
treeNode_12.addLink(treeNodeLink_122);
return new MultipleTree(new TreeRoot("规则决策树", treeNode_01));
}
public static void main(String[] args) {
MultipleTree multipleTree = buildTree();
log.info("决策树组合结构信息:\r\n" + JsonUtil.beanToJson(multipleTree));
}
}
结果输出正确

这里插一句,TreeRoot中将整个树转成了map,是为了方便我们从数据库或者配置文件等其他地方获取规则配置。至此,我们树已经构建完成了。
b. 规则过滤器
我们的树结构有了,就需要对树里的每个节点做逻辑判断,通过循环判断节点,我们决策到每个节点的链接上,链接的nodeIdTo属性就是就是对应下一节点的id。
创建一个逻辑过滤器LogicFilter,它有两个方法,方法matterValue()获取决策值,在性别过滤器中就是获取是男还是女,方法filter做逻辑过滤。
public interface LogicFilter {
/**
* 获取决策值
*
* @param decisionMatter 决策物料
* @return 决策值
*/
String matterValue(String treeId, String userId, Map<String, String> decisionMatter);
/**
* 逻辑决策器
*
* @param matterValue 决策值
* @param treeNodeLinkList 决策节点
* @return 下一个节点Id
*/
Long filter(String matterValue, List<TreeNodeLink> treeNodeLinkList);
}
创建它的抽象实现类
public abstract class AbstractLogicFilter implements LogicFilter {
@Override
public Long filter(String matterValue, List<TreeNodeLink> treeNodeLinkList) {
for (TreeNodeLink treeNodeLink : treeNodeLinkList) {
if (decisionLogic(matterValue, treeNodeLink)) {
return treeNodeLink.getNodeIdTo();
}
}
return 0L;
}
private boolean decisionLogic(String matterValue, TreeNodeLink treeNodeLink){
switch (treeNodeLink.getRuleLimitType()){
case EQ:
return matterValue.equals(treeNodeLink.getRuleLimitValue());
case GT:
return Double.parseDouble(matterValue) > Double.parseDouble(treeNodeLink.getRuleLimitValue());
case LT:
return Double.parseDouble(matterValue) < Double.parseDouble(treeNodeLink.getRuleLimitValue());
case GE:
return Double.parseDouble(matterValue) >= Double.parseDouble(treeNodeLink.getRuleLimitValue());
case LE:
return Double.parseDouble(matterValue) <= Double.parseDouble(treeNodeLink.getRuleLimitValue());
default:
return false;
}
}
@Override
public abstract String matterValue(String treeId, String userId, Map<String, String> decisionMatter);
}
再就是决策实现类,这个案例有两个,一个性别,一个年龄,主要的作用是获取传参中对应的决策值
public class UserAgeFilter extends AbstractLogicFilter {
@Override
public String matterValue(String treeId, String userId, Map<String, String> decisionMatter) {
return decisionMatter.get("age");
}
}
public class UserGenderFilter extends AbstractLogicFilter {
@Override
public String matterValue(String treeId, String userId, Map<String, String> decisionMatter) {
return decisionMatter.get("gender");
}
}
c. 决策引擎
最后就是编写决策引擎,也是决策树执行的入口和结果
public interface IEngine {
/**
* @param treeId 树id
* @param userId 用户id
* @param multipleTree 决策树集合
* @param decisionMatter 传入参数,一般是决策键值
* @return
*/
EngineResult process(final String treeId, final String userId, MultipleTree multipleTree, final Map<String, String> decisionMatter);
}
//逻辑过滤器的配置类,这里可以动态实现(不写死)
public class EngineConfig {
static Map<String, LogicFilter> logicFilterMap;
static {
logicFilterMap = new ConcurrentHashMap<>();
logicFilterMap.put("userAge", new UserAgeFilter());
logicFilterMap.put("userGender", new UserGenderFilter());
}
public Map<String, LogicFilter> getLogicFilterMap() {
return logicFilterMap;
}
public void setLogicFilterMap(Map<String, LogicFilter> logicFilterMap) {
EngineConfig.logicFilterMap = logicFilterMap;
}
}
//抽象引擎类,实现决策核心逻辑
@Slf4j
public abstract class AbstractEngine extends EngineConfig implements IEngine {
@Override
public abstract EngineResult process(String treeId, String userId, MultipleTree multipleTree, Map<String, String> decisionMatter);
protected TreeNode engineDecisionMaker(MultipleTree multipleTree, String treeId, String userId, Map<String, String> decisionMatter) {
TreeRoot treeRoot = multipleTree.getTreeRoot(treeId);
if (treeRoot == null) {
return null;
}
//从root中获取所有子节点,组成map
Map<Long, TreeNode> treeNodeMap = treeRoot.getTreeNodeMap();
// 规则树根ID
Long rootNodeId = treeRoot.getTreeRootNodeId();
TreeNode treeNodeInfo = treeNodeMap.get(rootNodeId);
//节点类型[NodeType]
while (treeNodeInfo.getNodeType().equals(NodeType.TREE_NODE)) {
String ruleKey = treeNodeInfo.getRuleKey();
LogicFilter logicFilter = logicFilterMap.get(ruleKey);
String matterValue = logicFilter.matterValue(treeId, userId, decisionMatter);
Long nextNode = logicFilter.filter(matterValue, treeNodeInfo.getTreeNodeLinks());
treeNodeInfo = treeNodeMap.get(nextNode);
log.info("决策树引擎=>{} userId:{} treeId:{} treeNode:{} ruleKey:{} matterValue:{}", treeRoot.getTreeName(), userId, treeId, treeNodeInfo.getTreeNodeId(), ruleKey, matterValue);
}
return treeNodeInfo;
}
}
//基本的引擎实现类
public class TreeEngineHandler extends AbstractEngine {
@Override
public EngineResult process(String treeId, String userId, MultipleTree multipleTree, Map<String, String> decisionMatter) {
// 决策流程
TreeNode treeNode = engineDecisionMaker(multipleTree, treeId, userId, decisionMatter);
if (treeNode == null) {
return new EngineResult(false);
}
// 决策结果
return new EngineResult(userId, treeId, treeNode.getTreeNodeId(), treeNode.getNodeValue());
}
}
//执行结果对象
@Data
public class EngineResult {
private boolean success; //执行结果
private String userId; //用户ID
private String treeId; //规则树ID
private Long nodeId; //叶子节点id
private String nodeValue;//叶子节点值
public EngineResult() {
}
public EngineResult(boolean success) {
this.success = success;
}
public EngineResult(String userId, String treeId, Long nodeId, String nodeValue) {
this.success = true;
this.userId = userId;
this.treeId = treeId;
this.nodeId = nodeId;
this.nodeValue = nodeValue;
}
}
d. 测试代码
所有的模块编写完后,我们进行测试
public static void main(String[] args) {
MultipleTree multipleTree = buildTree();
log.info("决策树组合结构信息:\r\n" + JsonUtil.beanToJson(multipleTree));
Map<String, String> decisionMatter = new HashMap<>();
decisionMatter.put("gender", "man");
decisionMatter.put("age", "29");
IEngine engine = new TreeEngineHandler();
EngineResult result = engine.process("10001", "123456", multipleTree, decisionMatter);
log.info("测试结果:{}", JsonUtil.beanToJson(result));
}

测试结果正确
这里我们对规则引擎的编写基本完成,也是对组合模式的一个应用,使用这个引擎可以让我们的代码编写起来更简单,减少了繁重的ifelse逻辑。
四. 总结
组合模式保证了开闭原则,我们扩展新的节点是很便利的。在开发过程中也存在很多典型的模型可以让我们使用这个模式去优化代码,提高代码的扩展性,而不是只会简单的ifelse去达到目的。