云应用系统开发技术考点(面试题相关)
#云应用系统开发技术考点(面试题相关)
1、CAP理论
概述:一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
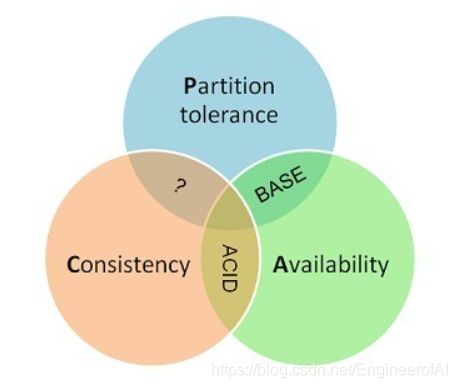
Consistency 一致性
一致性指“all nodes see the same data at the same time”,即所有节点在同一时间的数据完全一致。
一致性是因为多个数据拷贝下并发读写才有的问题,因此理解时一定要注意结合考虑多个数据拷贝下并发读写的场景。
对于一致性,可以分为从客户端和服务端两个不同的视角。
- 客户端
从客户端来看,一致性主要指的是多并发访问时更新过的数据如何获取的问题。
- 服务端
从服务端来看,则是更新如何分布到整个系统,以保证数据最终一致。
对于一致性,可以分为强/弱/最终一致性三类
从客户端角度,多进程并发访问时,更新过的数据在不同进程如何获取的不同策略,决定了不同的一致性。
- 强一致性
对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性。
- 弱一致性
如果能容忍后续的部分或者全部访问不到,则是弱一致性。
- 最终一致性
如果经过一段时间后要求能访问到更新后的数据,则是最终一致性。
Availability 可用性
可用性指“Reads and writes always succeed”,即服务在正常响应时间内一直可用。
好的可用性主要是指系统能够很好的为用户服务,不出现用户操作失败或者访问超时等用户体验不好的情况。可用性通常情况下可用性和分布式数据冗余,负载均衡等有着很大的关联。
Partition Tolerance分区容错性
分区容错性指“the system continues to operate despite arbitrary message loss or failure of part of the system”,即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性或可用性的服务。
2、进程间通信(IPC)概念和原理
概念:
操作系统内的并发执行进程可以是独立的也可以是协作的:
- 如果一个进程不能影响其他进程或受其他进程影响,那么该进程是独立的,换句话说,不与任何其他进程共享数据的进程是独立的;
- 如果一个进程能影响其他进程或受其他进程所影响,那么该进程是协作的。换句话说,与其他进程共享数据的进程为协作进程。
提供环境允许进程协作,具有许多理由:
- 信息共享:由于多个用户可能对同样的信息感兴趣(例如共享文件),所以应提供环境以允许并发访问这些信息。
- 计算加速:如果希望一个特定任务快速运行,那么应将它分成子任务,而每个子任务可以与其他子任务一起并行执行。注意,如果要实现这样的加速,那么计算机需要有多个处理核。
- 模块化:可能需要按模块化方式构造系统,即将系统功能分成独立的进程或线程。
- 方便:即使单个用户也可能同时执行许多任务。例如,用户可以并行地编辑、收听音乐、编译。
协作进程需要有一种进程间通信机制(简称 IPC),以允许进程相互交换数据与信息。进程间通信有两种基本模型:共享内存和消息传递(消息队列):
- 共享内存模型会建立起一块供协作进程共享的内存区域,进程通过向此共享区域读出或写入数据来交换信息。
- 消息传递模型通过在协作进程间交换消息来实现通信。
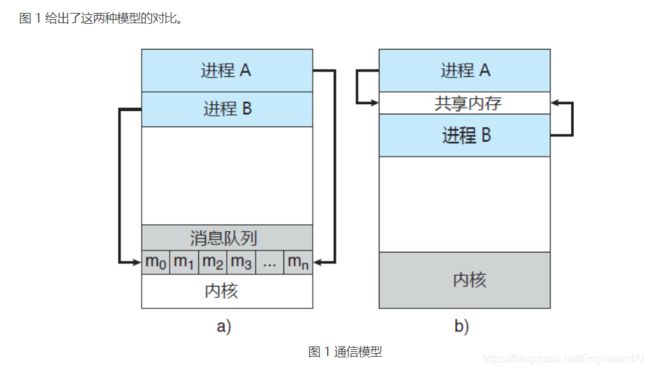
共享内存系统
**采用共享内存的进程间通信,需要通信进程建立共享内存区域。**通常,共享内存区域驻留在创建共享内存段的进程地址空间内。其他希望使用这个共享内存段进行通信的进程应将其附加到自己的地址空间。
消息传递系统(消息队列)
前面讲解了协作进程如何可以通过共享内存进行通信。此方案要求这些进程共享一个内存区域,并且应用程序开发人员需要明确编写代码,以访问和操作共享内存。达到同样效果的另一种方式是,操作系统提供机制,以便协作进程通过消息传递功能进行通信。
消息传递提供一种机制,以便允许进程不必通过共享地址空间来实现通信和同步。对分布式环境(通信进程可能位于通过网络连接的不同计算机),这特别有用。
3、Socket API的概念
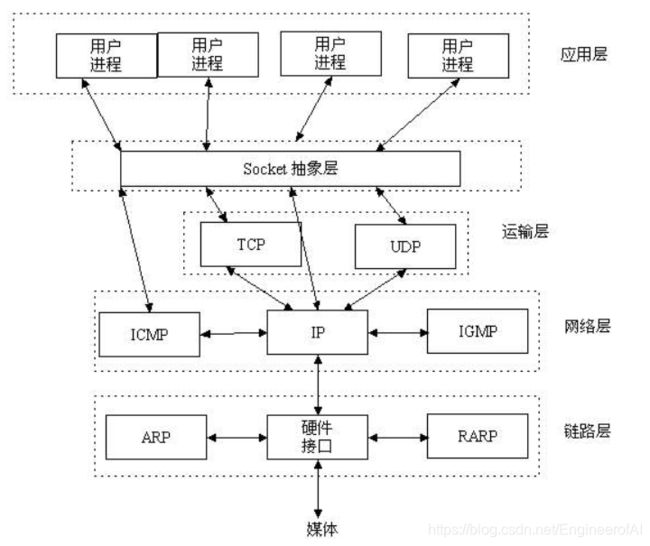
socket概念
socket是在应用层和传输层之间的一个抽象层,它把TCP/IP层复杂的操作抽象为几个简单的接口供应用层调用已实现进程在网络中通信。
socket起源于UNIX,在Unix一切皆文件哲学的思想下,socket是一种"打开—读/写—关闭"模式的实现,服务器和客户端各自维护一个"文件",在建立连接打开后,可以向自己文件写入内容供对方读取或者读取对方内容,通讯结束时关闭文件。
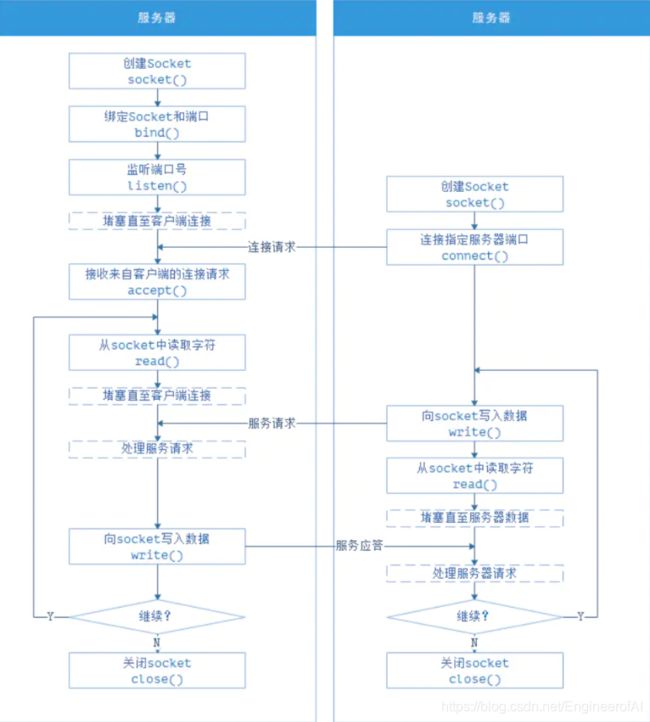
Socket通信流程
Socket可理解为一种特殊的文件,在服务器和客户端各自维护一个文件,并使用SocketAPI函数对其进行文件操作。在建立连接打开后,可以向各自文件写入内容供对方读取或读取对方内容,通信结束时关闭文件。在UNIX哲学中“一切皆文件”,文件的操作模式基本为“打开-读写-关闭”三大步骤,Socket其实就是这个模式的一个实现。
socket API
API概念
API,英文全称Application Programming Interface,翻译为“应用程序编程接口”。是一些预先定义的函数,目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力,而又无需访问源码,或理解内部工作机制的细节。
Socket API概念
即网络通信接口(每对通信套接字接口),通过IP地址+端口形式进行进程间的通信访问。
套接字为通信的端点。通过网络通信的每对进程需要使用一对套接字。
套接字组成: IP地址 + 端口号
套接字采用客户机——服务器架构。
服务器通过监听指定端口,来等待客户请求。
实现特定服务的服务器监听众所周知的端口:
- telent服务器端口,23
- ftp服务器监听端口,21
- web或http服务器,80
所有低于1024的端口都是众所周知的。
4、HTTP协议与常见的状态码,会话机制与技术原理,HTTPS协议与使用场景
协议
是指计算机通信网络中两台计算机之间进行通信所必须共同遵守的规定或规则,超文本传输协议(HTTP)是一种通信协议,它允许将超文本标记语言(HTML)文档从Web服务器传送到客户端的浏览器。
HTTP协议
即超文本传输协议(Hypertext transfer protocol)。是一种详细规定了浏览器和万维网(WWW = World Wide Web)服务器之间互相通信的规则,通过因特网传送万维网文档的数据传送协议。
HTTP协议是用于从WWW服务器传输超文本到本地浏览器的传送协议。它可以使浏览器更加高效,使网络传输减少。它不仅保证计算机正确快速地传输超文本文档,还确定传输文档中的哪一部分,以及哪部分内容首先显示(如文本先于图形)等。
HTTP是一个应用层协议,由请求和响应构成,是一个标准的客户端服务器模型。HTTP是一个无状态的协议。
在Internet中所有的传输都是通过TCP/IP进行的。HTTP协议作为TCP/IP模型中应用层的协议也不例外。
常用状态码:
| 状态码 | 类别 | 原因短语 |
|---|---|---|
| 1XX | Informational(信息性状态码) | 接受的请求正在处理 |
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出错 |
-
200 OK:请求已正常处理。
-
204 No Content:请求处理成功,但没有任何资源可以返回给客户端,一般在只需要从客户端往服务器发送信息,而对客户端不需要发送新信息内容的情况下使用。
-
206 Partial Content:是对资源某一部分的请求,该状态码表示客户端进行了范围请求,而服务器成功执行了这部分的GET请求。响应报文中包含由Content-Range指定范围的实体内容。
-
301 Moved Permanently:资源的uri已更新,你也更新下你的书签引用吧。永久性重定向,请求的资源已经被分配了新的URI,以后应使用资源现在所指的URI。
-
302 Found:资源的URI已临时定位到其他位置了,姑且算你已经知道了这个情况了。临时性重定向。和301相似,但302代表的资源不是永久性移动,只是临时性性质的。换句话说,已移动的资源对应的URI将来还有可能发生改变。
-
303 See Other:资源的URI已更新,你是否能临时按新的URI访问。该状态码表示由于请求对应的资源存在着另一个URL,应使用GET方法定向获取请求的资源。303状态码和302状态码有着相同的功能,但303状态码明确表示客户端应当采用GET方法获取资源,这点与302状态码有区别。
-
当301,302,303响应状态码返回时,几乎所有的浏览器都会把POST改成GET,并删除请求报文内的主体,之后请求会自动再次发送。
-
304 Not Modified:资源已找到,但未符合条件请求。该状态码表示客户端发送附带条件的请求时(采用GET方法的请求报文中包含If-Match,If-Modified-Since,If-None-Match,If-Range,If-Unmodified-Since中任一首部)服务端允许请求访问资源,但因发生请求未满足条件的情况后,直接返回304.。
-
307 Temporary Redirect:临时重定向。与302有相同的含义。
-
400 Bad Request:服务器端无法理解客户端发送的请求,请求报文中可能存在语法错误。
-
401 Unauthorized:该状态码表示发送的请求需要有通过HTTP认证(BASIC认证,DIGEST认证)的认证信息。
-
403 Forbidden:不允许访问那个资源。该状态码表明对请求资源的访问被服务器拒绝了。(权限,未授权IP等)
-
404 Not Found:服务器上没有请求的资源。路径错误等。
-
500 Internal Server Error:貌似内部资源出故障了。该状态码表明服务器端在执行请求时发生了错误。也有可能是web应用存在bug或某些临时故障。
-
503 Service Unavailable:抱歉,我现在正在忙着。该状态码表明服务器暂时处于超负载或正在停机维护,现在无法处理请求。
HTTP协议通常承载于TCP协议之上,有时也承载于TLS或SSL协议层之上,这个时候,就成了我们常说的HTTPS。
会话机制
概念:Web程序中常用的技术,用来跟踪用户的整个会话。常用的会话跟踪技术是Cookie与Session。Cookie通过在客户端记录信息确定用户身份,Session通过在服务器端记录信息确定用户身份。
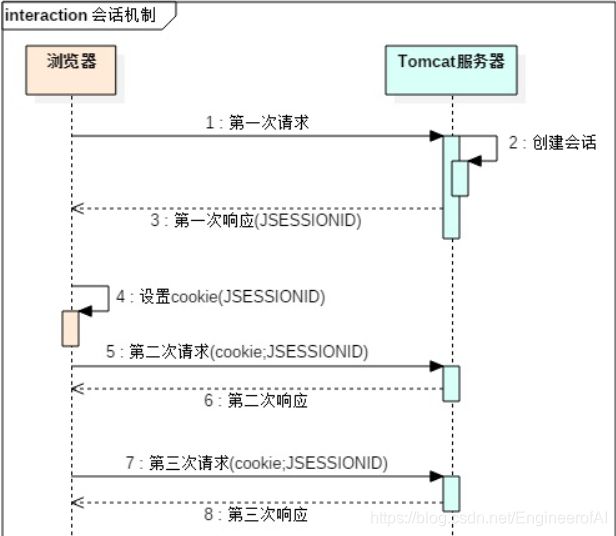
(1)浏览器在第一次访问Tomcat服务器的时候,Tomcat服务器会在服务端创建session对象,并存储到map中.key是session的id,value是session对象本身.
(2)在响应的时候会把session的id通过cookie的方式写到客户端浏览器中.
(3)浏览器会在本地的目录中把session的id写入到本地的cookie中.
(4)在后续的请求中,都自动会读取本地的cookie中的内容,并在请求的时候带上对应的cookie.
(5)服务端会根据传递的cookie,直接找到对应的session对象
5、CGI与Java Servlet的技术原理
CGI概念
CGI是Web服务器和一个独立的进程之间的协议,它会把HTTP请求Request的Header头设置成进程的环境变量,HTTP请求的Body正文设置成进程的标准输入,进程的标准输出设置为HTTP响应Response,包含Header头和Body正文。

CGI功能及处理步骤
绝大多数的CGI程序被用来解释处理杰自表单的输入信息,并在服 务器产生相应的处理,或将相应的信息反馈给浏览器。CGI程序使 网页具有交互功能。
CGI处理步骤:
⑴通过Internet把用户请求送到服务器。
⑵服务器接收用户请求并交给CGI程序处理。
⑶CGI程序把处理结果传送给服务器。
⑷服务器把结果送回到用户。
Servlet定义
Servlet是一个Java应用程序,运行在服务器端,用来处理客户端请求并作出响应的程序。
Servlet的特点
(1)Servlet对像,由Servlet容器(Tomcat)创建。
(2)Servlet是一个接口:位于javax.servlet包中。
(3)service方法用于接收用户的请求并返回响应。
(4)用户访问时多次被执行(可以统计网站的访问量)。
Servlet原理
Servlet多线程体系结构是建立在Java多线程机制之上的,它的生命周期是由Web容器负责的。
当客户端第一次请求某个Servlet时,Servlet容器将会根据web.xml配置文件实例化这个Servlet类,此时它贮存于内存中。。当有新的客户端请求该Servlet时,一般不会再实例化该Servlet类,也就是有多个线程在使用这个实例。 这样,当两个或多个线程同时访问同一个Servlet时,可能会发生多个线程同时访问同一资源的情况,数据可能会变得不一致。所以在用Servlet构建的Web应用时要注意线程安全的问题。每一个请求都是一个线程,而不是进程,因此,Servlet对请求的处理的性能非常高。
对于Servlet,它被设计为多线程的(如果它是单线程的,你就可以想象,当1000个人同时请求一个网页时,在第一个人获得请求结果之前,其它999个人都在郁闷地等待),如果为每个用户的每一次请求都创建 一个新的线程对象来运行的话,系统就会在创建线程和销毁线程上耗费很大的开销,大大降低系统的效率。
因此,Servlet多线程机制背后有一个线程池在支持,线程池在初始化初期就创建了一定数量的线程对象,通过提高对这些对象的利用率,避免高频率地创建对象,从而达到提高程序的效率的目的。(由线程来执行Servlet的service方法,servlet在Tomcat中是以单例模式存在的, Servlet的线程安全问题只有在大量的并发访问时才会显现出来,并且很难发现,因此在编写Servlet程序时要特别注意。线程安全问题主要是由实例变量造成的,因此在Servlet中应避免使用实例变量。如果应用程设计无法避免使用实例变量,那么使用同步来保护要使用的实例变量,但为保证系统的最佳性能,应该同步可用性最小的代码路径)
Struts2的Action是原型,非单实例的;会对每一个请求,产生一个Action的实例来处理。
解决servlet线程安全的方案:同步对共享数据的操作 Synchronized (this){…}、避免使用实例变量

①客户端向服务器端发出请求;
②这个过程比较重要,这时Tomcat会创建两个对象:HttpServletResponse和HttpServletRequest。并将它们的引用(注意是引用)传给刚分配的线程;
③线程开始着手接洽servlet;
④servlet根据传来的是GET和POST,分别调用doGet()和doPost()方法进行处理;
⑤和⑥servlet将处理后的结果通过线程传回Tomcat,并在之后将这个线程销毁或者送还线程池;
⑦Tomcat将处理后的结果变成一个HTTP响应发送回客户端,这样,客户端就可以接受到处理后的结果了。
6、P2P的技术原理和概念
P2P概念
P2P被称为“点对点”。“对等”技术,是一种网络新技术,依赖网络中参与者的计算能力和带宽,而不是把依赖都聚集在较少的几台服务器上。P2P还是英文Point to Point (点对点)的简称。它是下载术语,意思是在你自己下载的同时,自己的电脑还要继续做主机上传,这种下载方式,人越多速度越快但缺点是对硬盘损伤比较大(在写的同时还要读,之前的迅雷下载模式就是采用的P2P模式),还有对内存占用较多,影响整机速度。
P2P发展历程
(1)非中心化
P2P 网络中资源和服务是分散在所有结点上的,信息的传输和服务的实现直接在结点间就可以完成,无需服务器的介入。P2P的非中心化特点是现代网络向边缘发展的体现,也为其可扩展性和健壮性带来优势。
(2)可扩展性
在P2P网络中,随着用户的加入,不仅服务的需求增加了,而且系统整体的资源和服务能力也随之提升,理论上P2P网络的可扩展性是无限的,因此系统始终能满足用户的需求。例如,在传统C/S模式的文件下载中,当服务器接受的用户数量增加后,文件的下载速度就会变慢;而在P2P系统中恰恰相反,加入的用户结点越多,网络中的资源就越多,下载速度反而加快了。
(3)健壮性
由于P2P网络中资源和服务是分散在各结点之间的,部分结点和网络遭到破坏时,其他结点还可以作为补充,因此具有很强的耐攻击性和容错性。一般,P2P网络是自组织方式建立起来的,允许结点的自由加入和退出。因此当P2P网络的部分结点失效时能够自动调整网络拓扑,保持与周围结点的连通性。
(4)高性价比
在企业应用中关注最多的是利润,传统C/S模式使企业花费大量资金在中心服务器的更新和维护上,增加了企业产品成本。但随着硬件技术按照摩尔定律的飞速发展,个人计算能力和存储能力在不断提高,且伴着移动互联网时代的到来,各种移动设备使用计算无处不在,在使得资源的分布更加分散化。采用P2P技术使众多计算结点的闲置资源得到充分利用,已完成高性能的计算和海量存储的任务,是未来互联网发展的趋势。使用P2P技术的降低了企业维护中心服务器和购买大量网络设备的费用,目前主要运用在基因学和天文学等海量信息的学术研究中,一旦成熟,便可在企业中推广。
(5)隐私保护
在P2P网络中,信息和服务的传输是分散在网络结点间进行的,无需经过集中环节,用户的隐私信息被窃听和泄露的可能性大大减少。通常,互联网上隐私问题主要采用的是中继转发的方式,从而将通信的参与者隐藏在众多的网络实体中。在传统C/S模式中常采用中继服务器结点来实现匿名的灵活性和可靠性,能够更好地保护隐私。
(6)负载均衡
在传统C/S模式中,由于受到服务器计算和存储能力的限制,连接到服务器的用户数是有一定控制的,超过限量就有可能发生机的危险。在P2P网络中,节点是服务器和客户端的结合体,将计算和存储任务分配到各结点中进行,缓解了中心服务器的压力,更有利于实现网络的负载均衡。
P2P技术原理
在P2P网络中,每个节点既可以从其他节点得到服务,也可以向其他节点提供服务。这样,庞大的终端资源被利用起来,一举解决了C/S模式中的两个弊端。
P2P网络有3种比较流行的组织结构,被应用在不同的P2P应用中。
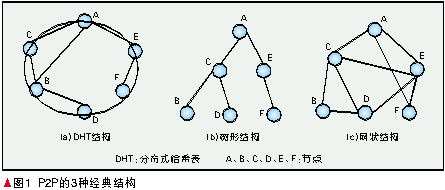
(1)DHT结构
分布式哈希表(DHT)[1]是一种功能强大的工具,它的提出引起了学术界一股研究DHT的热潮。虽然DHT具有各种各样的实现方式,但是具有共同的特征,即都是一个环行拓扑结构,在这个结构里每个节点具有一个唯一的节点标识(ID),节点ID是一个128位的哈希值。每个节点都在路由表里保存了其他前驱、后继节点的ID。如图1(a)所示。通过这些路由信息,可以方便地找到其他节点。这种结构多用于文件共享和作为底层结构用于流媒体传输[2]。
(2)树形结构
P2P网络树形结构如图1(b)所示。在这种结构中,所有的节点都被组织在一棵树中,树根只有子节点,树叶只有父节点,其他节点既有子节点也有父节点。信息的流向沿着树枝流动。最初的树形结构多用于P2P流媒体直播[3-4]。
(3)网状结构
网状结构如图1©所示,又叫无结构。顾名思义,这种结构中,所有的节点无规则地连在一起,没有稳定的关系,没有父子关系。网状结构[5]为P2P提供了最大的容忍性、动态适应性,在流媒体直播和点播应用中取得了极大的成功。当网络变得很大时,常常会引入超级节点的概念,超级节点可以和任何一种以上结构结合起来组成新的结构,如KaZaA[6]。
7、java Web应用程序(CounterWebApp),JSP运行原理,War包的部署
Java web应用程序
一个 web 应用程序是由一组 Servlet,HTML 页面,类,以及其它的资源组成的运行在 web 服务器上的完整的应用程序,以一种结构化的有层次的目录形式存在。
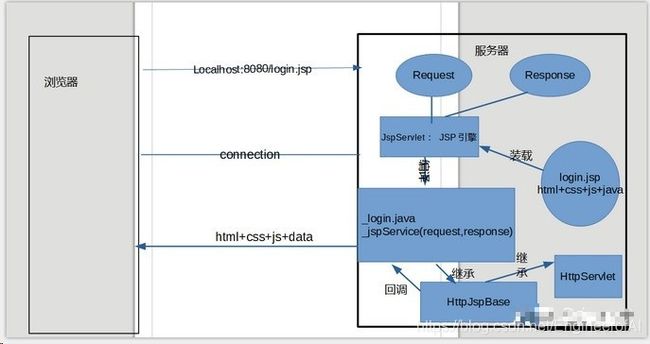
JSP的运行原理
(1)WEB容器JSP页面的访问请求时,它将把该访问请求交给JSP引擎去处理。Tomcat中的JSP引擎就是一个Servlet程序,它负责解释和执行JSP页面。
(2)每个JSP页面在第一次被访问时,JSP引擎先将它翻译成一个Servlet源程序,接着再把这个Servlet源程序编译成Servlet的class类文件,然后再由WEB容器像调用普通Servlet程序一样的方式来装载和解释执行这个由JSP页面翻译成的Servlet程序。
(3)Tomcat 5把为JSP页面创建的Servlet源文件和class类文件放置在“apache-tomcat-5.5.26\work\Catalina\localhost<应用程序名>\”目录中,Tomcat将JSP页面翻译成的Servlet的包名为org.apache.jsp(即:apache-tomcat-5.5.26\work\Catalina\localhost\org\apache\jsp\文件下)
8、单元测试/集成测试/测试驱动开发的概念
单元测试。
单元测试也称为模块测试,测试的对象是可以独立编译的程序模块、软件构件或面向对象的类,其目的是检查每个模块能够正确的实现其设计的功能、性能、接口和其他设计约束等条件。单元测试通常是由模块开发人员自己完成的,也就是说,开发人员编码实现一个功能模块,同时也完成其单元测试的编码并通过测试。由开发人员在编写功能模块具体实现代码的时候一并完成提交,它可以是白盒测试(即内部处理过程可见)也可以是黑盒测试,这也是最基础的测试,保障基础的功能模块能够正常工作。
单元测试案例
构建IntOperations
package com.example.math;
/**
* Integer arithmetical operations.
*
* @author bobyuan
*/
public class IntOperations {
/**
* Get the name of this class.
* @return A string name.
*/
public static final String getName() {
return "IntOperations";
}
/**
* Add 2 integers.
* @param a The first integer value.
* @param b The second integer value.
* @return The result of a add b.
*/
public int add(int a, int b) {
return a + b;
}
/**
* Subtract 2 integers.
* @param a The first integer value.
* @param b The second integer value.
* @return The result of a subtract b.
*/
public int subtract(int a, int b) {
return a - b;
}
/**
* Calculate the average value of 2 integers.
* @param a The first integer value.
* @param b The second integer value.
* @return The average of the 2 input integers.
*/
public double average(int a, int b) {
//return (a + b) / 2.0; //may cause overflow!
return (a / 2.0) + (b / 2.0);
}
}
构建IntOperationsTest
package com.example.math;
import junit.framework.Assert;
import junit.framework.TestCase;
/**
* Unit test for IntOperations using JUnit3.
*
* Integer.MAX_VALUE = 2147483647
* Integer.MIN_VALUE = -2147483648
*
* @author bobyuan
*/
public class IntOperationsTest extends TestCase {
/**
* Default constructor.
*/
public IntOperationsTest() {
super();
}
/**
* Constructor.
* @param name The name of this test case.
*/
public IntOperationsTest(String name) {
super(name);
}
/* (non-Javadoc)
* @see junit.framework.TestCase#setUp()
*/
// @Override
// protected void setUp() throws Exception {
// //System.out.println("Set up");
// }
/* (non-Javadoc)
* @see junit.framework.TestCase#tearDown()
*/
@Override
protected void tearDown() throws Exception {
//System.out.println("Tear down");
}
/**
* Example of testing the static method.
*/
public void test_getName() {
Assert.assertEquals("IntOperations", IntOperations.getName());
}
/**
* Test case for add(a, b) method.
*/
// public void test_add() {
// IntOperations io = new IntOperations();
// Assert.assertEquals(0, io.add(0, 0));
// Assert.assertEquals(1, io.add(0, 1));
// Assert.assertEquals(1, io.add(1, 0));
//
// Assert.assertEquals(4, io.add(1, 3));
// Assert.assertEquals(0, io.add(-3, 3));
//
// Assert.assertEquals(Integer.MIN_VALUE, io.add(Integer.MIN_VALUE + 1, -1));
// Assert.assertEquals(Integer.MAX_VALUE, io.add(Integer.MAX_VALUE - 1, 1));
// }
/**
* Test case for subtract(a, b) method.
*/
public void test_subtract() {
IntOperations io = new IntOperations();
Assert.assertEquals(0, io.subtract(0, 0));
Assert.assertEquals(-1, io.subtract(0, 1));
Assert.assertEquals(-2, io.subtract(1, 3));
Assert.assertEquals(2, io.subtract(3, 1));
Assert.assertEquals(Integer.MIN_VALUE, io.subtract(Integer.MIN_VALUE + 1, 1));
Assert.assertEquals(Integer.MAX_VALUE, io.subtract(Integer.MAX_VALUE - 1, -1));
}
/**
* Test case for average(a, b) method.
*/
public void test_average() {
IntOperations io = new IntOperations();
Assert.assertEquals(0.0, io.average(0, 0));
Assert.assertEquals(2.0, io.average(1, 3));
Assert.assertEquals(2.5, io.average(2, 3));
Assert.assertEquals(Integer.MIN_VALUE / 2.0, io.average(Integer.MIN_VALUE, 0));
Assert.assertEquals(Integer.MIN_VALUE / 2.0, io.average(0, Integer.MIN_VALUE));
Assert.assertEquals(Integer.MAX_VALUE / 2.0, io.average(Integer.MAX_VALUE, 0));
Assert.assertEquals(Integer.MAX_VALUE / 2.0, io.average(0, Integer.MAX_VALUE));
Assert.assertEquals(Integer.MIN_VALUE + 0.0, io.average(Integer.MIN_VALUE, Integer.MIN_VALUE));
Assert.assertEquals(Integer.MAX_VALUE + 0.0, io.average(Integer.MAX_VALUE, Integer.MAX_VALUE));
}
}
单元测试目录结构:

参考链接地址https://cloudappdev.netlify.app/book/content.html#_5-1-%E5%8D%95%E5%85%83%E6%B5%8B%E8%AF%95
集成测试。
所谓集成,即是将各个功能模块组装成为一个相对独立的应用程序,从整体的角度进行功能验证,看它是否达到设计目标。集成测试的目的是检查模块之间,以及模块和已集成的软件之间的接口关系,验证已集成的软件是否符合设计要求。在进行集成测试前,这些模块应该都已经通过单元测试。集成测试是黑盒测试,可以由开发人员或由专门的测试团队(有的称为 Quality Assurance 团队,或 QA 团队)完成。
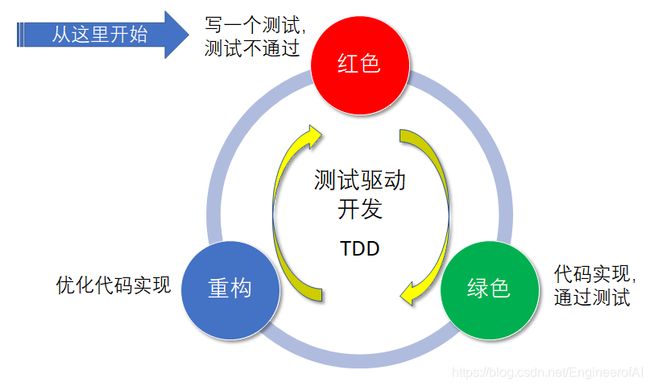
测试驱动开发(Test-Driven Development,TDD)
是一种不同于传统软件开发流程的新型的开发方法。传统软件开发流程是先开发再测试,而测试驱动开发则要求在编写实现某个功能之前先编写测试案例的代码,然后只编写使测试通过的功能代码(即最小化实现),通过测试来推动整个开发的进行。这有助于编写简洁可用和高质量的代码,并加速开发过程。
测试驱动开发的基本过程如下:
- 新增一个单元测试案例,从需求角度清晰定义待实现功能的输入参数和预期输出结果。
- 运行所有的单元测试(有时候只需要运行一个或一部分),发现新增的单元测试不能通过(甚至不能编译)。通常在集成开发环境上测试执行后显示红色,表示不通过。
- 快速编写实现代码,尽快地让单元测试可运行通过,为此可以在程序中使用一些不合情理的“快捷”实现方法。通常在集成开发环境上测试执行后显示绿色,表示通过。
- 代码重构(Refactoring)。在所有单元测试全部通过的前提下,优化代码的设计实现。
9、持续集成/交付/部署,搭建它使用到的工具软件(Jenkins,Git,Maven,Tomcat等)调试和使用
持续集成
持续集成是一种软件开发实践,即团队协作开发的软件代码每天至少集成一次或多次。每次集成都通过自动化的构建(包括编译,自动化测试,打包生成发行版等)来验证,从而尽早地发现集成错误。
持续集成就是把多个开发人员写的代码集成到同一个分支,然后经过编译、测试、打包之后将程序保存到项目存储库(Artifact Repository)里。 它强调开发人员提交了新代码之后,立刻进行构建、(单元)测试。根据测试结果,我们可以确定新代码和原有代码能否正确地集成在一起。如下图所示:
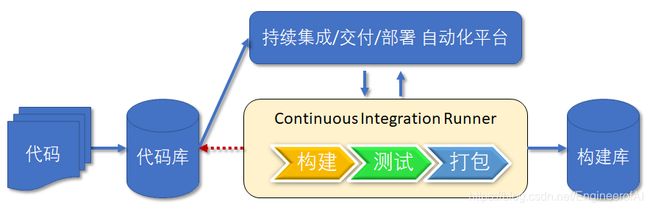
如果项目开发的规模比较小,比如一个人的项目,如果它对外部系统的依赖很小,那么软件集成不是问题。随着软件项目复杂度的增加,就会对集成后确保各个组件能够在一起工作提出了更高的要求。早集成、常集成、频繁的集成能够帮助项目在早期发现质量问题,如果到后期才发现这些问题,那么解决问题代价就很大,很有可能导致项目延期或者项目失败。
Martin Fowler 对持续集成的原文请参考 Continuous Integration(网址是 https://www.martinfowler.com/articles/continuousIntegration.html),滕云的中文翻译版请参考 http://www.cnblogs.com/CloudTeng/archive/2012/02/25/2367565.html。
知名的持续集成软件有:
- Jenkins(网址是 https://jenkins.io/) 它是开源软件,功能丰富,足够个人和小团队使用。
- TeamCity(网址是 https://www.jetbrains.com/teamcity) 它是商业软件,免费的 “Professional Server License” 已足够个人和小团队使用。
持续交付
持续交付就是定时地、自动地从项目存储库(Artifact Repository) 将最新的程序部署到测试环境里。持续交付建立在持续集成的基础上,将集成后的代码部署到更贴近真实运行环境的“类生产环境”(Production-like Environments)中。比如,我们完成单元测试后,可以把代码部署到连接数据库的 Staging 环境中进行更多的测试。如果代码没有问题,可以继续手动部署到生产环境中。如下图所示:
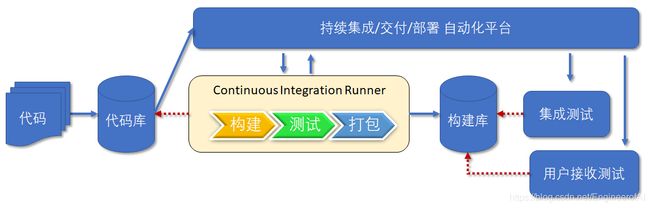
图7.2.1 持续交付
关于持续交付,请参考 Continuous Delivery(网址是 https://www.thoughtworks.com/continuous-delivery),里面提到了一本于2010年经 Addison Wesley 出版的书《Continuous Delivery》。此书中文翻译版《持续交付:发布可靠软件的系统方法》由人民邮电出版社于2011年出版。
知名的持续交付软件有:
- Jenkins(网址是 https://jenkins.io/) 它是开源软件,功能丰富,足够个人和小团队使用。
- GoCD(网址是 https://www.gocd.org/) 它是 ThoughtWorks 公司最初开发发起和资助的开源软件。
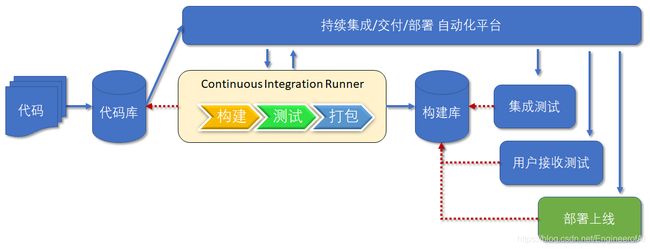
持续部署
持续部署就是定时地、自动地将过去一个稳定的发布版本部署到生产环境里。持续部署是在持续交付的基础上,把部署到生产环境的过程自动化。如下图所示:
Jenkins使用
Ubuntu安装Jenkins命令及使用命令
//获取下载包
wget -q -O - https://pkg.jenkins.io/debian/jenkins.io.key | sudo apt-key add -
sudo sh -c 'echo deb http://pkg.jenkins.io/debian-stable binary/ > /etc/apt/sources.list.d/jenkins.list'
//更新apt软件
sudo apt-get update
//安装Jenkins
sudo apt-get install jenkins
//查看Jenkins状态
sudo systemctl status jenkins
# stop Jenkins service.
sudo systemctl stop jenkins
# change from "HTTP_PORT=8080" to "HTTP_PORT=9090" in this file.
sudo vi /etc/default/jenkins
# restart Jenkins service.
sudo systemctl start jenkins
# check service status, should be active now.
sudo systemctl status jenkins
Git使用
git安装
//Ubuntu安装openJDK
sudo apt install openjdk-11-jdk
//查看openJDK安装路径
which java
# update system to latest.
sudo apt update -y
sudo apt upgrade -y
# install OpenJDK 8.
sudo apt install openjdk-8-jdk
# list the installed JDKs.
sudo update-java-alternatives --list
# set to use the specific JDK from the list.
sudo update-java-alternatives --set java-1.8.0-openjdk-amd64
//添加全局变量,修改/ect/profile
# added by nick_jackson.
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre
export PATH=$JAVA_HOME/bin:$PATH
git常用命令
查看下面的12题考点答案
maven使用
Ubuntu使用apt命令进行安装
# install apache-maven package.
sudo apt install maven
# 查找maven下载包路径
which mvn
#查看maven版本
mvn --version
Ubuntu下载解压包进行安装
# move to the target directory.
cd /usr/local
# extract the release package.
sudo tar zxf ~/apache-maven-3.6.1-bin.tar.gz
# create symbolic link to the real installation.
sudo ln -s apache-maven-3.6.1 apache-maven
#用 root 用户修改 /etc/profile 文件。如下例所示,添加了 M2_HOME 环境变量,并修改了环境变量 PATH,将 M2_HOME/bin 添加到 PATH 路径中。
# added by nick_jackson.
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre
export M2_HOME=/usr/local/apache-maven
export PATH=$JAVA_HOME/bin:$M2_HOME/bin:$PATH
# 查找maven下载包路径
which mvn
#查看maven版本
mvn --version
mvn常用命令
mvn compile 将 src/main/java 下的文件编译为 class 文件输出到 target目录下
mvn clean clean 是 maven 工程的清理命令,执行 clean 会删除 target 目录及内容
mvn test test 是 maven 工程的测试命令 mvn test,会执行src/test/java下的单元测试类
mvn package package是maven 工程的打包命令,对于java工程执行package打成jar包,对于web工程成war包
mvn install install是maven工程的安装命令,执行install将mave打成jar包或war包发布到本地仓库
10、DevOps的概念,技术原理
DevOps(英文 Development 和 Operations 的组合词)是一种方法或者实践,强调软件开发、技术运营,以及质量保障(QA)部门之间的沟通协作,共同促进软件变更和交付流程的自动化,让构建、测试、发布上线更加快捷、频繁与可靠。

DevOps 原理
DevOps 集文化理念、实践和工具于一身,可以提高组织快速交付应用程序和服务的能力,与使用传统软件开发和基础设施管理流程相比,能够帮助组织更快地发展和改进产品。这种速度使组织能够更好地服务其客户,并在市场上更高效地参与竞争。
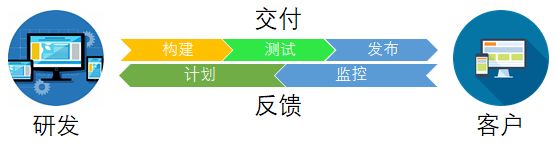
在 DevOps 模式下,开发团队和运营团队都不再是“孤立”的团队。有时,这两个团队会合为一个团队,他们的工程师会在应用程序的整个生命周期(从开发测试到部署再到运营)内相互协作,开发出一系列不限于单一职能的技能。
在一些 DevOps 模式下,质保和安全团队也会与开发和运营团队更紧密地结合在一起,贯穿应用程序的整个生命周期。当安全是所有 DevOps 团队成员的工作重心时,这有时被称为“DevSecOps”。
这些团队会使用实践经验自动执行之前手动操作的缓慢流程。他们使用能够帮助其快速可靠地操作和开发应用程序的技术体系和工具。这些工具还可以帮助工程师独立完成通常需要其他团队协作才能完成的任务(例如部署代码或预置基础设施),从而进一步提高团队的工作效率。
总而言之,DevOps 的关键是流程的自动化 —— 让代码完成过去手工的操作,从而大大节省成本,提高效率。 需要注意的是,在现实世界里,DevOps 更多是应用在大企业,因为小企业的协作相对容易,产品线不稳定,引入DevOps 的投入产出优势不明显。
11、容器Docker的原理,常见的操作命令(列出镜像,列出容器,端口映射等)
Docker 原理
Docker 容器的实质就是一个虚拟环境,容器内包含单一应用程序和它所需的全部依赖环境,相当于最小化的虚拟机。它的状态不会影响到宿主机,反过来宿主机的状态也不会影响到容器。只有容器预先设置好的端口和存储卷才能与外界环境通信,除此之外,对外界而言容器就是一个黑箱,外界看不到它的内在,也不需要关心。
Docker 的部署较简单,容器从镜像创建,而镜像内包含所需的全部依赖环境,做到了一个镜像直接部署,不再需要修改服务器的系统配置。注意 Docker 镜像(Image)是无状态的,而容器(Container)是有状态的,容器在运行时生成的数据是被保存在容器内的,这就是说容器内的进程生成的临时文件仍然被存放在容器内,并且当整个容器被删除时也会跟着被删除。如果生成的文件包含重要资料,则需要把对应生成的目录指向宿主机目录或者数据卷容器。数据卷容器与普通容器没有区别,只不过里面不包含应用进程,只为了保存数据而存在的容器。不要在容器内保存重要数据(除已挂载的数据卷位置),也就是说,容器的内部状态应该是不重要的,容器可以随时删除随时新建。不应在容器内部保存配置文件,而应将调试确认好的配置文件移出容器并妥善保存。
Docker 的每个容器只运行单一应用,完成最基本的服务,比如单纯的 MySQL 数据库服务,单纯的 Redis 缓存服务。要实现一个产品功能,往往需要多个基本服务共同协作完成。即通常需要多个容器协同工作,才能组成一个功能完善的应用,实现产品功能。
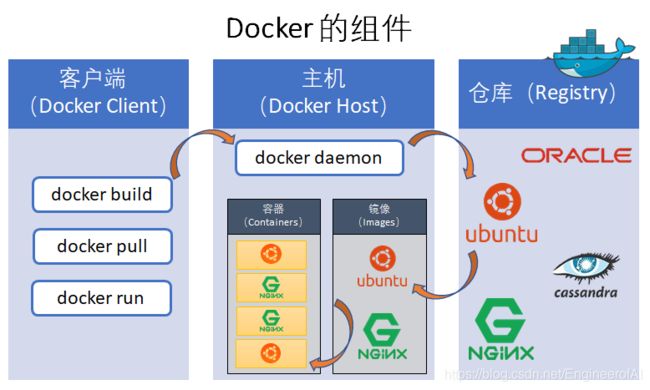
Docker 的运行涉及到3个基本组件:
- 一个运行 docker 命令的客户端(Docker Client)
- 一个以容器(Docker Container)形式运行镜像(Docker Image)的主机(Docker Host)
- 一个镜像(Docker Image)的仓库(Registry)
客户端(Docker Client)与主机(Docker Host)上面运行的 “Docker daemon” 通信。客户端与主机可以运行于同一台机器上。默认的仓库(Registry)是 Docker Hub(网址是 https://hub.docker.com/),它是一个分享和管理镜像的 SaaS 服务。可以去注册一个免费账号,免费用户只能发布公开的镜像。
Docker使用以下操作系统的功能来提高容器技术效率:
- Namespaces 充当隔离的第一级。确保一个容器中运行一个进程而且不能看到或影响容器外的其它进程。
- Control Groups 是 LXC 的重要组成部分,具有资源核算与限制的关键功能。
- UnionFS 文件系统作为容器的构建块。为了支持 Docker 的轻量级以及速度快的特性,它创建了用户层。
利用 Docker 来运行任何应用程序,需要两个步骤:
- 构建一个镜像;
- 运行容器。
docker常用命令
# remove the old version of Docker installed.
sudo apt-get remove docker docker-engine docker.io
# update the apt package list.
sudo apt-get update -y
# install Docker's package dependencies.
sudo apt-get install apt-transport-https ca-certificates \
curl software-properties-common
# download and add Docker's official public PGP key.
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
# verify the fingerprint.
sudo apt-key fingerprint 0EBFCD88
# add the `stable` channel's Docker upstream repository.
# 选择稳定版
# if you want to live on the edge, you can change "stable" below to "test" or
# "nightly". I highly recommend sticking with stable!
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
# update the apt package list (for the new apt repo).
sudo apt-get update -y
# install the latest version of Docker CE.
sudo apt-get install -y docker-ce
# allow your user to access the Docker CLI without needing root access.
# 将当前用户(这里 $USER=bobyuan) 添加到 “docker” 用户组。此用户组在安装 Docker CE 时已经被建立。
sudo usermod -aG docker $USER
# 需要退出当前用户并重新登录以生效。检查一下 “docker” 用户组已经出现。
groups
# 运行 “hello-world” 检查一下。
docker run hello-world
# check the docker service status.
systemctl status docker
# print help information.
docker help
# print help information for "run" command.
docker run --help
# show the Docker version information.
docker version
# display system-wide information.
docker info
# list running containers.
docker ps
# list all containers, including stopped ones.
docker ps --all
# 创建一个守护态的 Docker 容器,运行最新的 Ubuntu。注意参数 -itd,它是 --interactive --tty --detach 三个选项的最简缩写形式,也可以分开写作 -i -t -d。
docker run -itd ubuntu /bin/bash
# 查看所有本地已下载的镜像清单
docker images -a
# start the already stopped container, attach and interactive.
docker start -ai
# launch the Bash shell into the container.
docker exec -it /bin/bash
# display the running processes of a container
docker top
# kill specified container.
docker kill
# kill all running containers.
docker kill $(docker ps -q)
# remove specified container.
docker rm
# remove all running containers (kill before remove).
docker rm $(docker ps -a -q)
# remove specified image.
docker rmi
# remove all existing images.
docker rmi $(docker images -a -q)
# 查找镜像
docker search
# 查看镜像的历史版本
docker history
# 使用 push 命令将镜像上传到仓库(Docker registry)
docker push
###=============运行docker命令=================
# login "ubuntuvm1" VM as bobyuan.
cd ~
# git clone the CounterWebApp.
mkdir -p scm/gitlab
cd scm/gitlab
git clone https://gitlab.com/bobyuan/20190224_cloudappdev_code.git
cd 20190224_cloudappdev_code/spring_maven_webapp/CounterWebApp
# build the release package
mvn package
# download and run "tomcatserver" container (Apache Tomcat/8.5.32).
docker run -it --name tomcatserver -p 80:8080 tomcat /bin/bash
# Note: in case you have the container existed, just start it as below.
# docker start -ai tomcatserver
# start Tomcat server ($CATALINA_HOME=/usr/local/tomcat)
cd $CATALINA_HOME/bin
./catalina.sh run
# we can now access the Tomcat server via link: http://:80
# press Ctrl+C to stop Tomcat server.
# change directory to CounterWebApp project home.
cd scm/gitlab
cd 20190224_cloudappdev_code/spring_maven_webapp/CounterWebApp
# check the "war" file exists.
ls -l target/CounterWebApp.war
# copy the "war" file to Tomcat in the Container.
docker cp target/CounterWebApp.war tomcatserver:/usr/local/tomcat/webapps/
12、分布式版本管理工具Git,分支的概念和使用场景,冲突与冲突解决
Git分支概念和使用场景
分支概念
这是Git中最重要的也是最常用的概念和功能之一,分支功能解决了正在开发的版本与上线版本稳定性冲突的问题在Git使用过程中,我们的默认分支一般是Master,当然,这是可以修改的,我们在Master完成一次开发,生成了一个稳定版本,那么当我们需要添加新功能或者做修改时,只需要新建一个分支,然后在该分支上开发,完成后合并到主分支即可。
分支中有几个概念:
(1) 分支:分支就是每一次提交创建的点连接成的线。
(2) master分支:版本库创建后,会生成一个默认的分支,这个分支叫主分支,也叫master分支,所有的分支都围绕这根分支做扩展。
(3) 子分支:在master分支的基础上创建的分支,子分支的发展与主分支独立。
(4) 指针:每一根分支中都会有一个指向这个分支的指针,这个指针指向了当前版本库中使用的提交版本,也就是指向分支线上指定的点。master分支就有一个master指针,其他分支的指针类似。
(5) HEAD指针:指向当前版本库使用的分支指针。
使用场景
(1)删除不需要的分支。
(2)在不影响当前版本主功能更新的情况下去,修改底层代码
(3)多个功能同时构建
(4)bug修复、版本回退等等。
git常用命令
git remote add origin [email protected]:yeszao/dofiler.git # 配置远程git版本库
git pull origin master # 下载代码及快速合并
git push origin master # 上传代码及快速合并
git fetch origin # 从远程库获取代码
git branch # 显示所有分支
git checkout master # 切换到master分支
git checkout -b dev # 创建并切换到dev分支
git commit -m "first version" # 提交
git status # 查看状态
git log # 查看提交历史
git config --global core.editor vim # 设置默认编辑器为vim(git默认用nano)
git config core.ignorecase false # 设置大小写敏感
git config --global user.name "YOUR NAME" # 设置用户名
git config --global user.email "YOUR EMAIL ADDRESS" # 设置邮箱
//别名alias
git config --global alias.br="branch" # 创建/查看本地分支
git config --global alias.co="checkout" # 切换分支
git config --global alias.cb="checkout -b" # 创建并切换到新分支
git config --global alias.cm="commit -m" # 提交
git config --global alias.st="status" # 查看状态
git config --global alias.pullm="pull origin master" # 拉取分支
git config --global alias.pushm="push origin master" # 提交分支
git config --global alias.log="git log --oneline --graph --decorate --color=always" # 单行、分颜色显示记录
git config --global alias.logg="git log --graph --all --format=format:'%C(bold blue)%h%C(reset) - %C(bold green)(%ar)%C(reset) %C(white)%s%C(reset) %C(bold white)— %an%C(reset)%C(bold yellow)%d%C(reset)' --abbrev-commit --date=relative" # 复杂显示
//创建版本库
git clone # 克隆远程版本库
git init # 初始化本地版本库
//修改和提交
git status # 查看状态
git diff # 查看变更内容
git add . # 跟踪所有改动过的文件
git add # 跟踪指定的文件
git mv # 文件改名
git rm # 删除文件
git rm --cached # 停止跟踪文件但不删除
git commit -m “commit message” # 提交所有更新过的文件
git commit --amend # 修改最后一次提交
//查看历史
git log # 查看提交历史
git log -p # 查看指定文件的提交历史
git blame # 以列表方式查看指定文件的提交历史
//撤销
git reset --hard HEAD # 撤消工作目录中所有未提交文件的修改内容
git reset --hard # 撤销到某个特定版本
git checkout HEAD # 撤消指定的未提交文件的修改内容
git checkout -- # 同上一个命令
git revert # 撤消指定的提交分支与标签
//分支与标签
git branch # 显示所有本地分支
git checkout # 切换到指定分支或标签
git branch # 创建新分支
git branch -d # 删除本地分支
git tag # 列出所有本地标签
git tag # 基于最新提交创建标签
git tag -a "v1.0" -m "一些说明" # -a指定标签名称,-m指定标签说明
git tag -d # 删除标签
git checkout dev # 合并特定的commit到dev分支上
git cherry-pick 62ecb3
//远程与本地合并
git init # 初始化本地代码仓
git add . # 添加本地代码
git commit -m "add local source" # 提交本地代码
git pull origin master # 下载远程代码
git merge master # 合并master分支
git push -u origin master # 上传代码
13、基本的Ubuntu Linux操作命令,JDK8安装
Ubuntu Linux基本操作命令
# cd进入文件夹
cd 回车 进入自己的home 文件夹
cd ~ 回到自己的home文件夹
cd .当前目录
cd .. 上一层
cd - 上次所在目录
# ls 查看当前目录文件
ls -a 查看所有文件 包括隐藏文件
ls -l 查看当前文件以列表形式显示 不包括隐藏
ls -al 查看当前目录所有文件包含隐藏文件 以列表形式显示
ls -hl 更加人性化的显示文件
pwd 查看自己当前所在文件夹路径
# mkdir 创建文件夹
mkdir 文件夹名/文件夹名/.......... 在一个文件夹下创建文件夹
# touch 创建文件
touch 文件名.文件后缀
# rm 删除命令
rm -i 文件名.文件后缀 询问是否删除 yes / no
rm -f 文件名.文件后缀 不询问直接删除
rm -r 文件名.文件后缀 递归删除文件夹 删除所有文件 和文件夹 不询问
rm -ri 文件名.文件后缀 递归删除文件夹 删除所有文件 询问是否删除 yes /no
# clear 清屏
clear
# cat 打开查看文件
cat 文件名.后缀 查看当前目录文件
cat 文件名1.后缀 > 文件名2.后缀 打开文件1把文件1内容 写入到文件2中,如果没有文件2 则创建文件2,如果文件2中 有内容 则覆盖原有内容
# cp 复制文件到指定文件夹下面
cp 文件名.后缀 复制的文件夹路径
# mv 移动文件
mv 文件 移动路径
# tree 关系树状图
tree 文件夹 显示该文件夹的关系树状图
# tar打包命令
tar -c 创建包 –x 释放包 -v 显示命令过程 –z 代表压缩包
tar –cvf benet.tar /home/benet 把/home/benet目录打包
tar –zcvf benet.tar.gz /mnt 把目录打包并压缩
tar –zxvf benet.tar.gz 压缩包的文件解压恢复
tar –jxvf benet.tar.bz2 解压缩
# make编译
make 编译
make install 安装编译好的源码包
# apt命令
apt-cache search package 搜索包
apt-cache show package 获取包的相关信息,如说明、大小、版本等
sudo apt-get install package 安装包
sudo apt-get install package - - reinstall 重新安装包
sudo apt-get -f install 修复安装”-f = –fix-missing”
sudo apt-get remove package 删除包
sudo apt-get remove package - - purge 删除包,包括删除配置文件等
sudo apt-get update 更新源
sudo apt-get upgrade 更新已安装的包
sudo apt-get dist-upgrade 升级系统
sudo apt-get dselect-upgrade 使用 dselect 升级
apt-cache depends package 了解使用依赖
apt-cache rdepends package 是查看该包被哪些包依赖
sudo apt-get build-dep package 安装相关的编译环境
apt-get source package 下载该包的源代码
sudo apt-get clean && sudo apt-get autoclean 清理无用的包
sudo apt-get check 检查是否有损坏的依赖
sudo apt-get clean 清理所有软件缓存(即缓存在/var/cache/apt/archives目录里的deb包)
# 查看PCI设备
lspci
# 查看USB设备
lsusb
# 查看网卡状态
sudo ethtool eth0
# 查看CPU信息
cat /proc/cpuinfo
# 显示当前硬件信息
lshw
#硬盘 查看硬盘的分区
sudo fdisk -l
参考地址:https://www.jb51.net/os/Ubuntu/56362.html
JDK8安装
apt安装
// 安装jdk
sudo apt install openjdk-8-jdk-headless
// 验证是否成功安装
java -version
javac
java
java -v
压缩包安装
// 下载玩压缩包后进入压缩包目录解压
tar -zxvf jdk-8u121-linux-x64.tar.gz
// 打开profile文件,配置环境变量
sudo gedit /etc/profile
// 添加以下内容
#set Java environment
export JAVA_HOME=/路径名/jdk1.8.0_56(路径自己变通,都看得懂吧o(* ̄▽ ̄*)ブ)
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
14、Web Services,SOAP,REST(RESTful API)的概念,技术原理
关系
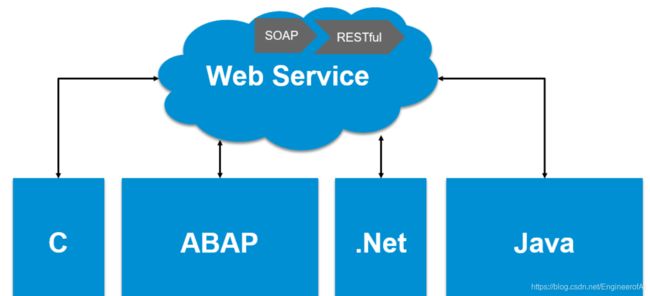
Web Service:一种跨编程语言、跨操作系统平台的远程调用技术。这个很好理解,Web Service主要可以实现不同系统之间的通信。如果以SAP系统为例,通过Web Service可以实现两个不同的SAP系统之间,或SAP系统与其它第三方系统(例如,可以是.Net或Java平台的应用)间进行通信。
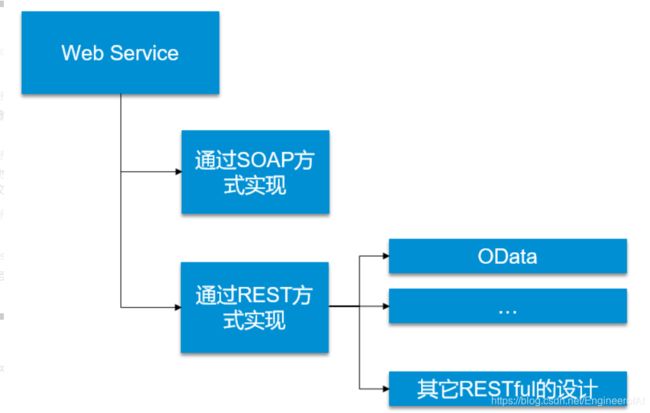
Web Service有两种实现方式,一种是SOAP协议方式,一种是REST方式。
REST是一组架构约束条件和原则,描述了一种如何访问/使用HTTP服务的方式。(如果一个架构符合REST的约束条件和原则,我们就称它为RESTful架构。)
OData是REST设计风格的一种实现,OData和其他Restful风格的Web service在于,OData提供了了描述数据和数据模型的一个统一的方式。所以说,OData并非是一种新的通信技术,OData也属于Web Service。
SOAP方式的Web Service
SOAP是一套Web Service(WS)的比较完整的实现方案。
在以SOAP方式实现的Web Service中,SOAP协议和WSDL构成了Web服务的结构单元。
SOAP也即“简单对象访问协议(Simple Object Access Protocol)”,我们知道Web Service通过HTTP协议发送和接收数据,SOAP协议中增加了一些特定的HTTP消息头,来说明HTTP消息的内容格式。客户端按照SOAP的格式便可以通过Web Service调用位于远程系统上的服务。
WSDL也即“Web服务描述语言(Web Services Description Language)”,客户端可以通过WSDL了解这个Web Service所提供的功能,描述了Web Service中提供的函数、函数的输入参数和返回值。平台和阿里云平台的概念,申请步骤,基本操作
REST方式的Web Service - OData
REST也即“表述性状态转移(Representational State Transfer)”,REST是一种HTTP服务的设计风格,描述了一套如何设计和访问HTTP服务的原则。
因此,相较于SOAP,REST并非是一个协议,仅是一种设计风格,并没有强制的约束力。
不同的设计者可以依据自己的实际项目和需求,设计REST风格的Web Service,也正是由于这种“各自为战”的Web Service实现方式,让REST方式的web service在性能和可用性上通常会优于依据SOAP发布的web service, 但由于在细节上没有太多约束,其统一性上不及SOAP。
OData是REST设计风格的一种实现,OData和其他Restful风格的Web service在于,OData提供了了描述数据和数据模型的一个统一的方式。
理解参考https://segmentfault.com/a/1190000017777211
https://blog.csdn.net/nkGavinGuo/article/details/105225997
技术原理
Web Service也叫XML Web Service WebService是一种可以接收从Internet或者Intranet上的其它系统中传递过来的请求,轻量级的独立的通讯技术。是:通过SOAP在Web上提供的软件服务,使用WSDL文件进行说明,并通过UDDI进行注册。WebService可用基于XML的SOAP来表示数据和调用请求,并且通过HTTP协议来传输这些XML格式的数据。
webservice最大优点就是实现异构平台间的互通,这也是使用WebService的主要原因之一。任何两个应用程序,只要他们能读写XML,就能相互通信。
1、webservice部署比较方便
2、webservice的编写,跟普通的class差不多
3、当然还有一个好处:平台无关。C#,Java写的ws可以相互调用
4、做分布式系统
XML:(Extensible Markup Language)扩展型可标记语言。面向短期的临时数据处理、面向万维网络,是Soap的基础。
Soap:(Simple Object Access Protocol)简单对象存取协议。是XML Web Service 的通信协议。当用户通过UDDI找到你的WSDL描述文档后,他通过可以SOAP调用你建立的Web服务中的一个或多个操作。SOAP是XML文档形式的调用方法的规范,它可以支持不同的底层接口,像HTTP(S)或者SMTP。
WSDL:(Web Services Description Language) WSDL 文件是一个 XML 文档,用于说明一组 SOAP 消息以及如何交换这些消息。大多数情况下由软件自动生成和使用。
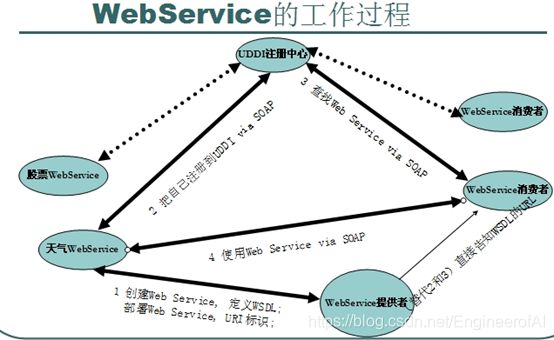
UDDI (Universal Description, Discovery, and Integration) 是一个主要针对Web服务供应商和使用者的新项目。在用户能够调用Web服务之前,必须确定这个服务内包含哪些商务方法,找到被调用的接口定义,还要在服务端来编制软件,UDDI是一种根据描述文档来引导系统查找相应服务的机制。UDDI利用SOAP消息机制(标准的XML/HTTP)来发布,编辑,浏览以及查找注册信息。它采用XML格式来封装各种不同类型的数据,并且发送到注册中心或者由注册中心来返回需要的数据。
15、AWS云平台和阿里云平台的概念,申请步骤,基本操作
AWS云平台
AWS 全称Amazon web service(亚马逊网络服务),是亚马逊公司旗下云计算服务平台,为全世界各个国家和地区的客户提供一整套基础设施和云解决方案。
AWS面向用户提供包括弹性计算、存储、数据库、物联网在内的一整套云计算服务,帮助企业降低IT投入和维护成本,轻松上云
从概念是来看,AWS提供了一系列的托管产品,帮助我们在没有物理服务器的情况下,照样可以正常完成软件开发中的各种需求,也就是我们常说的云服务。
阿里云平台
阿里云,阿里巴巴集团旗下云计算品牌,全球卓越的云计算技术和服务提供商,是全球领先的云计算及人工智能科技公司,致力于以在线公共服务的方式,提供安全、可靠的计算和数据处理能力,让计算和人工智能成为普惠科技。
AWS使用
aws注册
进入控制台
aws号称全球云服务最全的云平台,功能也是多种多样,不过新用户想要免费使用aws的云服务器,需要visa国外的信用卡,国内申请可能比较麻烦。
阿里云使用
阿里云注册,使用支付宝或其它方式进行注册
注册完成后,登录,登录后进入首页就可看到许多服务

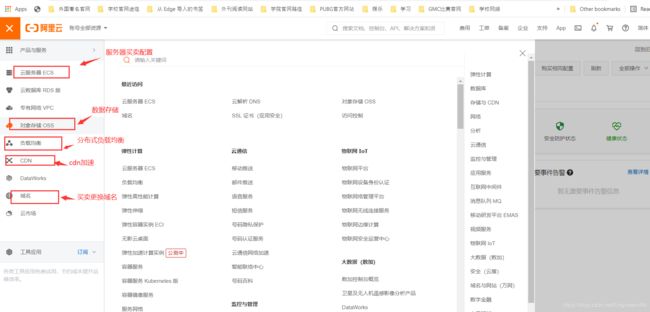
进入控制台
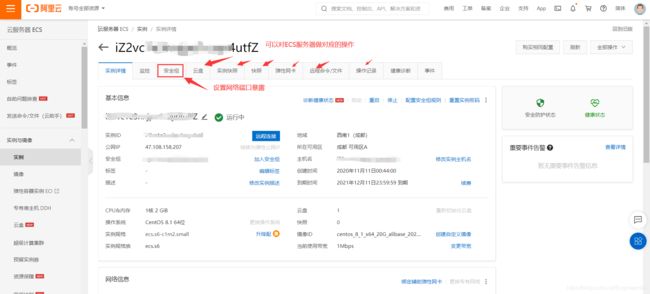
可以对控制台进行相应操作
16、云应用程序中采用的其他技术基本概念,如Queue,多重身份认证等。
Queue
队列是消息存储的目的地,队列可以分成普通队列和延时队列。 如果发送消息时不指定消息延时,被发送到普通队列的消息立刻可以被消费,而发送到延时队列需要经过设定的延时时间后才能被消费。
QueueURL
- 格式:
http://$AccountId.mns.。.aliyuncs.com/queues/$QueueName mns.:MNS访问域名,Region是MNS部署的地域,您可以根据应用需要选择不同的地域。.aliyuncs.com AccountId:队列所有者的账号ID。QueueName:队列名称,同一个AccountId在同地域中的队列名不能重名。
参考地址:https://help.aliyun.com/document_detail/27476.html
多重身份认证
概念:多重身份验证通过一系列简单的验证选项提供强身份验证,这些选项包括电话、短信或移动应用通知,用户可以根据自己的偏好选择所用的方法。
实例:Azure多重身份认证
17、云服务的分类(IaaS, PaaS, SaaS),云平台的测试和选择标准
云服务分类
云服务主要分为三类:分别是IaaS(基础架构即服务)、PaaS(平台即服务)以及SaaS(软件及服务)
- 本地IT基础架构就像拥有一辆汽车。 购买汽车时,要负责汽车的维护,而升级意味着购买新车。
- IaaS就像在租车。 当你租车时,你可以选择想要的车,然后随心所欲地驾驶它,但那辆车不是你的。想要升级吗?那就租一辆不同的车。
- PaaS就像打车。 你不必自己驾驶出租车,而只需告诉驾驶员你需要去后座放松的地方。
- SaaS就像乘公共汽车去。 巴士已分配路线,与其他乘客共享旅程。
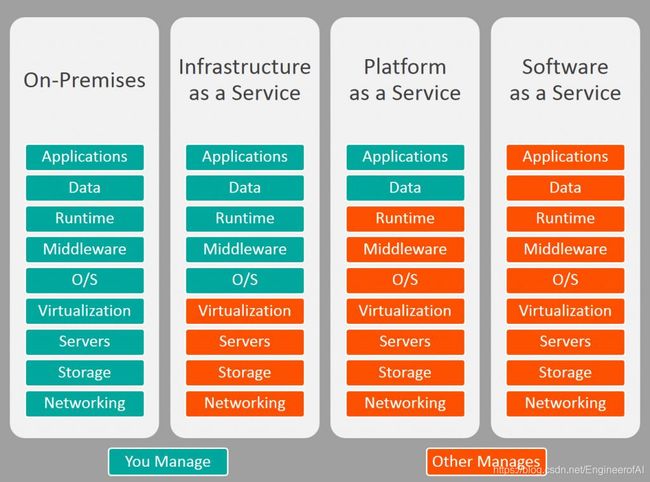
软件即服务(SaaS)
SaaS允许人们使用基于云的Web应用程序。

实际上,电子邮件服务(例如Gmail和Hotmail)就是基于云的SaaS服务的示例。SaaS服务的其他示例包括办公工具(Office 365和Google Docs),客户关系管理软件(Salesforce),事件管理软件(Planning Pod)等。
SaaS服务通常以即付即用(即订阅)定价模式提供。所有软件和硬件均由供应商提供和管理,因此无需安装或配置任何东西。获得登录名和密码后,即可开始使用该应用程序。
平台即服务(PaaS)
PaaS是指为运行时环境提供用于开发,测试和管理应用程序的云平台。
借助PaaS解决方案,软件开发人员可以部署从简单到复杂的应用程序,而无需所有相关基础架构(服务器,数据库,操作系统,开发工具等)。PaaS服务的示例包括Heroku和Google App Engine。
PaaS供应商为应用程序开发提供了完整的基础架构,而开发人员则负责代码。
与SaaS一样,平台即服务解决方案提供按需付费的定价模式。

基础架构即服务(IaaS)
IaaS是一种云服务,提供基本的计算基础结构:服务器,存储和网络资源。换句话说,IaaS是一个虚拟数据中心。
IaaS服务可用于多种目的,从托管网站到分析大数据。客户可以在所获得的基础架构上安装和使用他们喜欢的任何操作系统和工具。IaaS的主要提供商包括Amazon Web Services,Microsoft Azure和Google Compute Engine。
与SaaS和PaaS一样,IaaS服务可以按需付费使用。

如你所见,每种云服务(IaaS,PaaS和SaaS)都是针对其目标受众的业务需求量身定制的。从技术角度来看,IaaS可以为你提供最大的控制权,但需要广泛的专业知识来管理计算基础架构,而SaaS允许你使用基于云的应用程序而无需管理基础架构。因此,云服务可以描述为金字塔:
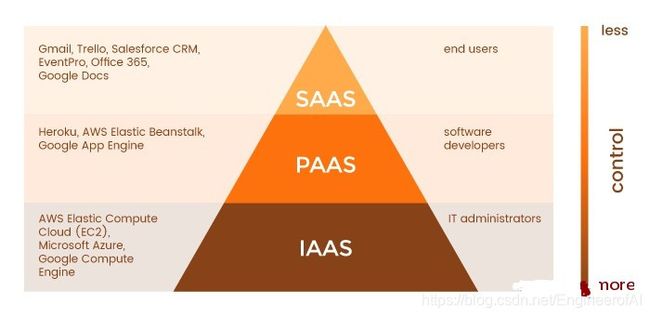
Reference
云应用开发技术https://cloudappdev.netlify.app/book/content.html
Web Service, SOAP, REST, OData之间的关系https://blog.csdn.net/nkGavinGuo/article/details/105225997
知乎云服务分类https://zhuanlan.zhihu.com/p/357877662