【python高级用法】线程
前言
Python通过标准库的 threading 模块来管理线程。这个模块提供了很多不错的特性,让线程变得无比简单。实际上,线程模块提供了几种同时运行的机制,实现起来非常简单。
线程模块
- 线程对象
- Lock对象
- RLock对象
- 信号对象
- 条件对象
- 事件对象
简单调用方式
class threading.Thread(group=None,
target=None,
name=None,
args=(),
kwargs={})group: 一般设置为None,这是为以后的一些特性预留的target: 当线程启动的时候要执行的函数name: 线程的名字,默认会分配一个唯一名字Thread-Nargs: 传递给target的参数,要使用tuple类型kwargs: 同上,使用字典类型dict
创建线程的方法非常实用,通过`target`参数、`arg`和`kwarg`告诉线程应该做什么。下面这个例子传递一个数字给线程(这个数字正好等于线程号码),目标函数会打印出这个数字。
import threading
def function(i):
print ("function called by thread %i\n" % i)
return
threads = []
for i in range(5):
t = threading.Thread(target=function , args=(i, ))
threads.append(t)
t.start()
for i in range(5):
t.join() 线程被创建之后并不会马上运行,需要手动调用 start() , join() 让调用它的线程一直等待直到执行结束(即阻塞调用它的主线程, t 线程执行结束,主线程才会继续执行)
实现一个线程
使用threading模块实现一个新的线程,需要下面3步:
- 定义一个
Thread类的子类 - 重写
__init__(self [,args])方法,可以添加额外的参数 - 最后,需要重写
run(self, [,args])方法来实现线程要做的事情
当你创建了新的 Thread 子类的时候,你可以实例化这个类,调用 start() 方法来启动它。线程启动之后将会执行 run() 方法。
为了在子类中实现线程,我们定义了 myThread 类。其中有两个方法需要手动实现:
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print("Starting " + self.name)
print_time(self.name, self.counter, 5)
print("Exiting " + self.name)
def print_time(threadName, delay, counter):
while counter:
if exitFlag:
# 译者注:原书中使用的thread,但是Python3中已经不能使用thread,以_thread取代,因此应该
# import _thread
# _thread.exit()
thread.exit()
time.sleep(delay)
print("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
# Create new threads
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# Start new Threads
thread1.start()
thread2.start()
# 以下两行为译者添加,如果要获得和图片相同的结果,
# 下面两行是必须的。疑似原作者的疏漏
thread1.join()
thread2.join()
print("Exiting Main Thread")threading 模块是创建和管理线程的首选形式。每一个线程都通过一个继承 Thread 类,重写 run() 方法来实现逻辑,这个方法是线程的入口。在主程序中,我们创建了多个 myThread 的类型实例,然后执行 start() 方法启动它们。调用 Thread.__init__ 构造器方法是必须的,通过它我们可以给线程定义一些名字或分组之类的属性。调用 start() 之后线程变为活跃状态,并且持续直到 run() 结束,或者中间出现异常。所有的线程都执行完成之后,程序结束。
join() 命令控制主线程的终止。
Lock用法
当两个或以上对共享内存的操作发生在并发线程中,并且至少有一个可以改变数据,又没有同步机制的条件下,就会产生竞争条件,可能会导致执行无效代码、bug、或异常行为。
竞争条件最简单的解决方法是使用锁。锁的操作非常简单,当一个线程需要访问部分共享内存时,它必须先获得锁才能访问。此线程对这部分共享资源使用完成之后,该线程必须释放锁,然后其他线程就可以拿到这个锁并访问这部分资源了。
很显然,避免竞争条件出现是非常重要的,所以我们要保证,在同一时刻只有一个线程允许访问共享内存。
然而,在实际使用的过程中,我们发现这个方法经常会导致一种糟糕的死锁现象。当不同的线程要求得到一个锁时,死锁就会发生,这时程序不可能继续执行,因为它们互相拿着对方需要的锁。
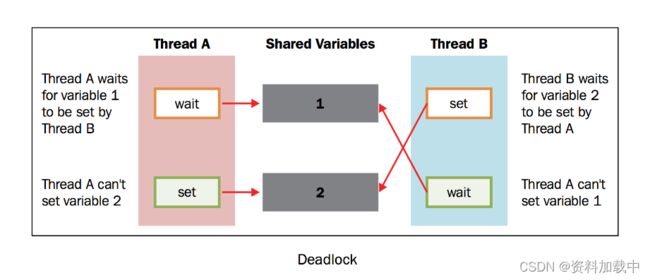
为了简化问题,我们设有两个并发的线程( 线程A 和 线程B ),需要 资源1 和 资源2 .假设 线程A 需要 资源1 , 线程B 需要 资源2 .在这种情况下,两个线程都使用各自的锁,目前为止没有冲突。现在假设,在双方释放锁之前, 线程A 需要 资源2 的锁, 线程B 需要 资源1 的锁,没有资源线程不会继续执行。鉴于目前两个资源的锁都是被占用的,而且在对方的锁释放之前都处于等待且不释放锁的状态。
# -*- coding: utf-8 -*-
import threading
shared_resource_with_lock = 0
shared_resource_with_no_lock = 0
COUNT = 100000
shared_resource_lock = threading.Lock()
# 有锁的情况
def increment_with_lock():
global shared_resource_with_lock
for i in range(COUNT):
shared_resource_lock.acquire()
shared_resource_with_lock += 1
shared_resource_lock.release()
def decrement_with_lock():
global shared_resource_with_lock
for i in range(COUNT):
shared_resource_lock.acquire()
shared_resource_with_lock -= 1
shared_resource_lock.release()
# 没有锁的情况
def increment_without_lock():
global shared_resource_with_no_lock
for i in range(COUNT):
shared_resource_with_no_lock += 1
def decrement_without_lock():
global shared_resource_with_no_lock
for i in range(COUNT):
shared_resource_with_no_lock -= 1
if __name__ == "__main__":
t1 = threading.Thread(target=increment_with_lock)
t2 = threading.Thread(target=decrement_with_lock)
t3 = threading.Thread(target=increment_without_lock)
t4 = threading.Thread(target=decrement_without_lock)
t1.start()
t2.start()
t3.start()
t4.start()
t1.join()
t2.join()
t3.join()
t4.join()
print ("the value of shared variable with lock management is %s" % shared_resource_with_lock)
print ("the value of shared variable with race condition is %s" % shared_resource_with_no_lock)RLock用法
这种锁对比Lock有是三个特点:
1. 谁拿到谁释放。如果线程A拿到锁,线程B无法释放这个锁,只有A可以释放;
2. 同一线程可以多次拿到该锁,即可以acquire多次;
3. acquire多少次就必须release多少次,只有最后一次release才能改变RLock的状态为unlocked)
import threading
import time
class Box(object):
lock = threading.RLock()
def __init__(self):
self.total_items = 0
def execute(self, n):
Box.lock.acquire()
self.total_items += n
Box.lock.release()
def add(self):
Box.lock.acquire()
self.execute(1)
Box.lock.release()
def remove(self):
Box.lock.acquire()
self.execute(-1)
Box.lock.release()
## These two functions run n in separate
## threads and call the Box's methods
def adder(box, items):
while items > 0:
print("adding 1 item in the box")
box.add()
time.sleep(1)
items -= 1
def remover(box, items):
while items > 0:
print("removing 1 item in the box")
box.remove()
time.sleep(1)
items -= 1
## the main program build some
## threads and make sure it works
if __name__ == "__main__":
items = 5
print("putting %s items in the box " % items)
box = Box()
t1 = threading.Thread(target=adder, args=(box, items))
t2 = threading.Thread(target=remover, args=(box, items))
t1.start()
t2.start()
t1.join()
t2.join()
print("%s items still remain in the box " % box.total_items)信号量用法
信号量是由操作系统管理的一种抽象数据类型,用于在多线程中同步对共享资源的使用。本质上说,信号量是一个内部数据,用于标明当前的共享资源可以有多少并发读取。
在threading模块中,信号量的操作有两个函数,即 acquire() 和 release()
- 每当线程想要读取关联了信号量的共享资源时,必须调用
acquire(),此操作减少信号量的内部变量, 如果此变量的值非负,那么分配该资源的权限。如果是负值,那么线程被挂起,直到有其他的线程释放资源。 - 当线程不再需要该共享资源,必须通过
release()释放。这样,信号量的内部变量增加,在信号量等待队列中排在最前面的线程会拿到共享资源的权限。

存在的问题:
假设有两个并发的线程,都在等待一个信号量,目前信号量的内部值为1。假设第线程A将信号量的值从1减到0,这时候控制权切换到了线程B,线程B将信号量的值从0减到-1,并且在这里被挂起等待,这时控制权回到线程A,信号量已经成为了负值,于是第一个线程也在等待。
# -*- coding: utf-8 -*-
"""Using a Semaphore to synchronize threads"""
import threading
import time
import random
# The optional argument gives the initial value for the internal
# counter;
# it defaults to 1.
# If the value given is less than 0, ValueError is raised.
semaphore = threading.Semaphore(0)
def consumer():
print("consumer is waiting.")
# Acquire a semaphore
semaphore.acquire()
# The consumer have access to the shared resource
print("Consumer notify : consumed item number %s " % item)
def producer():
global item
time.sleep(10)
# create a random item
item = random.randint(0, 1000)
print("producer notify : produced item number %s" % item)
# Release a semaphore, incrementing the internal counter by one.
# When it is zero on entry and another thread is waiting for it
# to become larger than zero again, wake up that thread.
semaphore.release()
if __name__ == '__main__':
for i in range (0,5) :
t1 = threading.Thread(target=producer)
t2 = threading.Thread(target=consumer)
t1.start()
t2.start()
t1.join()
t2.join()
print("program terminated") queue线程通信
Python的threading模块提供了很多同步原语,包括信号量,条件变量,事件和锁。如果可以使用这些原语的话,应该优先考虑使用这些,而不是使用queue(队列)模块。队列操作起来更容易,也使多线程编程更安全,因为队列可以将资源的使用通过单线程进行完全控制,并且允许使用更加整洁和可读性更高的设计模式。
Queue常用的方法有以下四个:
put(): 往queue中放一个itemget(): 从queue删除一个item,并返回删除的这个itemtask_done(): 每次item被处理的时候需要调用这个方法join(): 所有item都被处理之前一直阻塞
from threading import Thread, Event
from queue import Queue
import time
import random
class producer(Thread):
def __init__(self, queue):
Thread.__init__(self)
self.queue = queue
def run(self) :
for i in range(10):
item = random.randint(0, 256)
self.queue.put(item)
print('Producer notify: item N° %d appended to queue by %s' % (item, self.name))
time.sleep(1)
class consumer(Thread):
def __init__(self, queue):
Thread.__init__(self)
self.queue = queue
def run(self):
while True:
item = self.queue.get()
print('Consumer notify : %d popped from queue by %s' % (item, self.name))
self.queue.task_done()
if __name__ == '__main__':
queue = Queue()
t1 = producer(queue)
t2 = consumer(queue)
t3 = consumer(queue)
t4 = consumer(queue)
t1.start()
t2.start()
t3.start()
t4.start()
t1.join()
t2.join()
t3.join()
t4.join()
生产者使用 Queue.put(item [,block[, timeout]]) 来往queue中插入数据。Queue是同步的,在插入数据之前内部有一个内置的锁机制。
可能发生两种情况:
- 如果
block为True,timeout为None(这也是默认的选项,本例中使用默认选项),那么可能会阻塞掉,直到出现可用的位置。如果timeout是正整数,那么阻塞直到这个时间,就会抛出一个异常。 - 如果
block为False,如果队列有闲置那么会立即插入,否则就立即抛出异常(timeout将会被忽略)。本例中,put()检查队列是否已满,然后调用wait()开始等待。
消费者从队列中取出整数然后用 task_done() 方法将其标为任务已处理。
消费者使用 Queue.get([block[, timeout]]) 从队列中取回数据,queue内部也会经过锁的处理。如果队列为空,消费者阻塞。

参考链接:
Python并行编程 中文版 — python-parallel-programming-cookbook-cn 1.0 文档