【事件驱动编程】事件驱动编程的基础理论
文章目录
-
-
- 1. 网络编程中的同步与异步、阻塞与非阻塞
- 2. 什么是事件驱动编程
- 3. 事件驱动编程优缺点分析
- 4. Nginx事件驱动模型解析
- 5. Redis事件驱动模型解析
-
1. 网络编程中的同步与异步、阻塞与非阻塞
同步是否等同于阻塞?异步是否等同于非阻塞?
- 同步和阻塞并不是同一回事,尽管它们常常出现在一起。同步操作意味着执行一个操作时,必须等待这个操作完成后才能继续执行下一步。阻塞则是指在等待操作完成期间,无法响应其他的事件或操作。在很多情况下,同步操作是阻塞的,但它们不是必然相等的。
- 异步与非阻塞也是两个不同的概念。异步操作允许程序在等待一个操作完成时继续执行其他任务。非阻塞则是指在等待操作完成的过程中,程序能够响应其他事件或操作。虽然异步操作通常是非阻塞的,但这两者并不是同义词。
异步IO和非阻塞IO是一回事吗?
- 异步IO和非阻塞IO不是一回事。异步IO指的是发起一个IO操作(如读写文件)后,可以立即返回去做其他事情,不必等待IO操作完成。在异步IO模型中,IO操作的完成通常通过回调、事件或者轮询来通知程序。
- 非阻塞IO指的是当一个IO操作无法立即完成时,不会使调用者阻塞,而是立即返回一个标志,例如“数据还未准备好”。非阻塞IO需要程序显式地检查IO操作是否完成,这通常涉及到轮询。
存在同步非阻塞吗?
- 同步非阻塞是一种相对少见的情况,但它是存在的。在这种模式下,操作是同步发生的,即调用者会等待操作的结果,但在等待的过程中,调用者不会被阻塞,可以继续处理其他任务。这通常是通过某些特殊的编程技巧实现的,如使用多线程或协程,其中一个线程或协程等待IO操作的结果,而其他线程或协程继续执行。
同步和异步表达的是获取结果的方式,如果需要去主动获取这个结果,一般称为同步;如果是被动的等待这个结果的通知, 那么称之为异步。
阻塞和非阻塞表达的是执行者在执行某个动作之后它的状态,如果执行者执行某个动作之后它的线程被挂起了,这个时候就不能再做其它事了,那么称之为阻塞;如果执行者执行某个动作之后它的线程并没有被挂起了,而是可以继续去做其它事情,那么称之为非阻塞。
两者的区别需要分场景
- 方法调用的场景
同步就是阻塞的调用,异步就是非阻塞的调用
- Linux IO模型的场景——Linux五种IO模型
| IO模型 | 第一步 (物理设备->内核缓冲) |
第二步 (内核缓冲->应用缓冲) |
分类 |
|---|---|---|---|
| 阻塞IO | 阻塞 | 阻塞 | 同步IO |
| 非阻塞IO | 非阻塞,一直在轮询 | 阻塞 | 同步IO |
| IO多路复用 | 进程阻塞在select/poll/epoll上,只要有任何一个IO可读写即返回 | 阻塞 | 同步IO |
| 信号驱动IO | 非阻塞,内核准备好数据之后会发通知 | 阻塞 | 同步IO |
| 异步IO | 非阻塞 | 非阻塞,所有操作都由内核完成,完成之后会发通知 | 异步IO |
2. 什么是事件驱动编程
同步编程模式
同步编程是最传统和直观的编程方式。在这种模式下,程序的执行流程是线性的,即每一个操作或函数调用都按顺序执行,而且每个操作必须完成后才能开始下一个操作。这种方式易于理解和调试,因为代码的执行顺序与其在源文件中的顺序相符。
特点
- 线性执行流程:程序按照代码的顺序执行,每个步骤依次进行。
- 阻塞性质:如果当前的操作没有完成,程序就会在那里停顿,不会执行后续的代码。
- 简单性和直观性:对于编程新手来说,同步编程更容易理解和实现。
- 资源利用率:在等待(如IO操作)期间,程序可能无法执行其他任务,这可能导致资源利用率不高。
缺点
- 在涉及长时间操作(如网络请求、文件读写等)时,程序的响应性可能会降低。
- 在单线程应用中,长时间的同步操作可能导致用户界面冻结或服务器响应延迟。
当然,我可以为您提供一个使用C++编写的同步编程示例。在这个例子中,我们将创建一个简单的程序来读取文件,并对文件内容进行处理。与Python示例类似,这个过程在C++中也是同步的,即程序会等待文件读取操作完成后才继续执行。
示例:同步文件读取
假设一个程序需要从文件中读取数据,然后处理这些数据。在同步编程模式下,这个过程可能看起来是这样的:
#include 在这个示例中:
readFile函数同步地从文件中读取数据。程序将在这个函数完成读取操作之前等待。- 读取完毕后,
processData函数处理这些数据。 - 主函数
main中,按顺序调用这些函数并输出处理后的数据。
这个例子体现了同步编程的典型特点:代码的执行顺序与其在源文件中的顺序一致,且每个操作必须完成后才能进行下一个操作。
事件驱动编程模式
- 一种异步编程范式
- 执行流程取决于事件的发生
事件驱动编程是一种异步编程范式,它的核心思想是程序的执行流程取决于外部事件的发生,如用户输入、文件读取完成、网络请求返回等。在事件驱动模型中,程序的主要任务是监听和响应这些事件,而不是按照预设的顺序执行代码。
事件驱动编程的特点
- 非线性执行流程:程序的执行不是按代码的书写顺序,而是由事件触发的。
- 高响应性:程序可以立即响应外部事件,而不是被动地等待操作的完成。
- 并发处理能力:能够同时处理多个事件,提高程序的效率和用户体验。
示例:基于事件的文件读取
假设我们要修改之前的同步文件读取示例,使之成为一个事件驱动的程序。在C++中,实现真正的事件驱动模型需要使用特定的库,如Boost.Asio或Qt框架。但为了简化,我们可以使用一些基本的概念来模拟事件驱动行为。
这里我们使用伪代码来展示如何将文件读取转换为事件驱动模型。假设有一个FileReader类,它可以异步地读取文件,并在完成时触发一个事件。
#include 在这个例子中:
FileReader类提供了一个readFileAsync函数,它接受一个回调函数callback,当文件读取完成时会调用这个函数。- 在
main函数中,我们创建一个FileReader实例,并调用readFileAsync。我们传递一个匿名函数作为回调,该函数将处理读取到的数据。 - 程序启动异步文件读取后,可以立即继续执行其他代码,不需要等待文件读取完成。这就是事件驱动编程的特点。
核心要素
- 事件源
- 事件循环(事件收集、分发者)
- 事件处理(事件消费者)
事件驱动编程的核心要素包括事件源、事件循环以及事件处理。这些要素共同构成了事件驱动架构的基础,让程序能够以非阻塞的方式响应各种外部和内部事件。
-
事件源 (Event Source):
- 事件源是产生事件的起点。这可以是用户的输入(如键盘敲击、鼠标点击)、系统信号、网络消息、定时器或任何其他可以触发事件的源。在一个网络应用中,事件源可以是一个新的客户端连接,或者是现有连接上的新数据。在图形界面程序中,每次用户交互(如按钮点击)都可能成为事件源。
-
事件循环 (Event Loop):
- 事件循环,也称为消息循环,是事件驱动程序的核心。它不断检查并等待事件的发生,然后决定下一步的行动。事件循环的任务包括:
- 事件收集:从事件源收集或接收事件。
- 事件分发:将收集到的事件传递给相应的事件处理程序。
- 事件循环确保程序能够持续响应各种事件,同时保持正常运行。它在等待事件时通常处于休眠状态,从而降低资源消耗。
- 事件循环,也称为消息循环,是事件驱动程序的核心。它不断检查并等待事件的发生,然后决定下一步的行动。事件循环的任务包括:
-
事件处理 (Event Handler):
- 事件处理程序,也称为事件监听器或事件消费者,是对特定事件作出反应的代码部分。当事件循环检测到一个事件时,它会调用与该事件关联的事件处理程序。
- 事件处理程序的职责是对事件作出响应,这可能包括更新用户界面、读取或写入文件、处理数据等。不同类型的事件可能有不同的处理程序。
- 在很多情况下,程序员可以注册多个事件处理程序,以便对同一事件源产生的不同事件作出不同反应。
这三个要素共同工作,使得事件驱动的程序能够以高效和响应性的方式处理各种场景。事件驱动模型特别适合于需要大量用户交互或处理多种输入源的应用程序,如图形用户界面(GUI)应用、网络服务器等。
3. 事件驱动编程优缺点分析
重点讨论的是:Linux网络服务事件驱动编程
优点
- 高效处理能力(事件驱动 + IO多路复用)
- 占用系统资源少(固定线程数 + 绑定CPU亲和性)
- 逻辑处理可单线程闭环,没有多线程同步问题
缺点
- 流程不直观,不太容易理解
- 对开发人员要求高
4. Nginx事件驱动模型解析
Nginx是一个高性能的Web服务器和反向代理服务器,它广泛使用了事件驱动模型来处理高并发、高性能的网络连接。这个模型对Nginx的性能和效率至关重要。
事件模型

Nginx的事件模型基于非阻塞IO和事件通知机制。这意味着Nginx可以同时处理大量的网络连接,而不会因为某个连接的慢操作(如等待数据到达)而阻塞其他连接。核心要点包括:
- 非阻塞IO:Nginx使用非阻塞IO来管理网络连接。在这种模式下,当一个操作(如读取或写入数据)不能立即完成时,IO操作不会阻塞进程,而是立即返回,允许Nginx继续处理其他任务。
- 事件通知机制:为了有效地监控多个网络连接上的事件(如连接就绪、数据到达等),Nginx使用了诸如epoll(在Linux上)、kqueue(在BSD系统上)等高效的事件通知机制。这些机制可以通知Nginx哪些连接上有事件发生,从而仅处理活跃的或需要关注的连接。
Nginx事件处理流程

Nginx的事件处理流程是它性能高效的关键所在。这个流程大致可以分为以下几个步骤:
- 连接接受:当客户端尝试建立连接时,Nginx的主进程会接受这个连接。Nginx配置了非阻塞的监听套接字,所以即使有大量的并发连接尝试,它也能高效地接受。
- 事件循环:接受连接后,连接被传递给一个工作进程。每个工作进程都有自己的事件循环来处理连接上的事件。事件循环不断检查并处理新的事件,如读取请求、发送响应等。
- 请求处理:当事件循环检测到某个连接上有数据可读时,Nginx会解析这些数据(如HTTP请求),并根据配置和请求的内容进行相应的处理,比如静态内容的服务、代理请求等。
- 响应发送:处理完请求后,Nginx会准备相应的响应,并通过非阻塞IO将响应数据发送回客户端。这个过程同样是异步的,Nginx不会在发送过程中阻塞。
- 连接维护:Nginx会根据需要保持或关闭连接。如果使用了HTTP Keep-Alive,则连接可以保持开启状态,以便复用于后续的请求。
整个过程高度优化,确保了Nginx在处理大量并发请求时的高性能和低资源消耗。Nginx的这种事件驱动、异步非阻塞的处理方式是其成为高性能Web服务器的关键。
5. Redis事件驱动模型解析
Redis,作为一个高性能的键值存储数据库,同样采用了事件驱动模型来处理网络请求和内部任务。这种模型使得Redis能够高效地处理大量并发连接,同时维持低延迟。
Redis事件
- 文件事件 (File Events)
- 文件事件主要与网络IO相关,处理客户端的请求和响应。
- 它们是基于非阻塞的网络通信实现的,使用IO多路复用程序(如epoll、kqueue或select)来同时监听多个socket。
- 当客户端连接到Redis服务器时,连接会被注册为一个新的文件事件。当有数据可读(如客户端发来的命令)或可写(如向客户端发送响应)时,相应的文件事件会被触发。
- 时间事件 (Time Events)
- 时间事件与定时任务相关,比如定期执行的脚本、数据库维护任务、过期键的删除等。
- 这些事件不是由外部IO触发,而是根据预设的时间间隔或指定时间点自动执行。
- 时间事件由Redis内部的定时器管理,它们在特定时间触发,执行诸如数据持久化、键过期检查等操作。
Redis事件处理流程
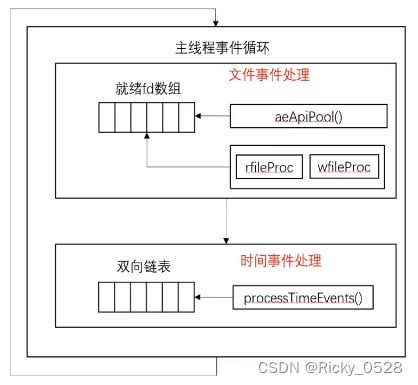
Redis的事件处理流程是它高效运行的核心,大致可以分为以下几个步骤:
- 事件循环启动:Redis服务器启动后,会进入一个事件循环(event loop),在这个循环中不断检测和处理事件。
- 文件事件处理:
- 事件循环首先检查文件事件,这些事件与网络IO操作有关。
- 当客户端发起连接请求时,IO多路复用程序会通知Redis,然后Redis接受这个连接,创建一个新的文件事件。
- 当客户端发送命令请求时,对应的文件事件会被触发,Redis读取请求数据并进行处理。
- 当需要向客户端发送响应时,Redis使用非阻塞IO将数据写回到客户端。
- 时间事件处理:
- 除了处理文件事件,事件循环还会检查时间事件。
- 这些事件是根据时间触发的,执行定时任务,如RDB/AOF持久化、过期键的处理等。
- 时间事件根据预定的时间间隔触发,事件循环会检查是否有任何时间事件到达执行时间,如果有,则执行相关任务。
- 事件循环继续:完成文件和时间事件的处理后,事件循环会继续回到开始,等待新的事件发生。
通过这种事件驱动的方式,Redis能够高效地处理大量的并发连接和内部任务,保证了其作为数据库的高性能和响应速度。