C++牛客知识点2
提示:接上文
文章目录
- 前言
- 一、pandas是什么?
- 二、使用步骤
- 1.引入库
- 2.读入数据
- 总结
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:接上文
12月1号
牛客网公司真题_免费模拟题库_企业面试|笔试真题
1、题目一
能用友元函数重载的运算符是(A)?
A、+
B、=
C、[]
D、->
解释:C++规定=,[ ],(),->这四个运算符只能被重载为类的非静态成员函数,其他的可以被友元重载,主要是因为其他的运算符重载函数都会根据参数类型或数目进行精确匹配,这四个不具有这种检查的功能,用友元定义就会出错。
2、题目二
下列程序段执行后,输出d的值为(A)
int main()
{
int a=1,b=0,c=-1,d=0;
d=++a||++b&&++c;
cout<A、1
B、2
C、3
D、0
解释:评论区有人说是因为&&优先级高于||,验证一下
看f的打印结果,确实是先算&&,而没有被||截断。
int main()
{
int a=1,b=0,c=-1,d=0,e = 0, f = 0;
d=++a||++b&&++c;
cout<< "d:" << d <2023-12-25 17:40:08
没看懂为什么d=1,是因为是||,取真或假。
优化代码
int main()
{
int a=1,b=0,c=-1,d=0,e = 0, f = 0;
d=++a||++b&&++c;
cout<< "d:" << d <3、题目3
下面哪些特性可能导致代码体积膨胀:答案ABC
A、宏定义 B、模板 C、内联函数 D、递归
2023年12月25日17:41:48
为什么模板和内联会导致代码膨胀?
A宏定义会单纯的替换,也就是如果宏定义替换的内容会成倍复制,所以会导致代码膨胀
B模板的调用,会根据调用的参数,生成模板对应的实际调用的函数体,如果调用的参数不同,会生成不同的代码,所以会导致代码膨胀
C内联函数会拷贝至调用的位置,如果调用多次回导致代码膨胀
12月9号
来源:牛客网公司真题_免费模拟题库_企业面试|笔试真题
1、题目1
在C++程序中,如有如下语句:
int b = 5;
int a = 10;
int &i = b;
int *j = &a;
int *&k = j;
请问下列哪个操作不能实现把a赋值为5。答案B。
A、a = i;
B、k = &b;
C、*k = i;
D、*j = *&b;
解释:答案作对了,但是我当时对int *&k = j;是很懵逼的,看了牛客评论区,感觉有个知识盲区,就是【int &a=b这种a是指针常量】
int *&k = j; //这里也是个声明:代表k 是 j 的另一个别名,可以把 j 和 k 等价(类型是int*)
2、题目2
64 位电脑运行 C++ 结果输出(C)
#include
using namespace std;
class A {
char a[2];
public:
virtual void aa() {};
};
class B : public virtual A {
char b[2];
char a[2];
public:
virtual void bb() {};
virtual void aa() {};
};
class C : public virtual B {
char a[2];
char b[2];
char c[2];
public:
virtual void cc() {};
virtual void aa() {};
virtual void bb() {};
};
int main() {
cout << sizeof(A) << endl << sizeof(B) << endl << sizeof(C);
return 0;
} A、8 16 24
B、16 32 36
C、16 32 48
D、8 20 24
解释:
对于对象 A,包含一个虚函数指针,因此对齐到 8 字节,然后有 2 个 char 型,最后补齐到 8 字节整倍数,因此其长度为 16 。
对于对象 B,包含一个虚函数指针,也是对齐到 8 字节,然后是 4 个 char 型,最后补齐到 8 字节整倍数,变成 16 字节。然后加上对象 A 的大小,共计 32 字节。
对于对象 C,包含一个虚函数指针,也是对齐到 8 字节,然后是 6 个 char 型,最后补齐到 8 字节整倍数,变成 16 字节。然后加上对象 B 的大小,共计 48 字节。
GCC共享虚函数表指针,也就是说父类如果已经有虚函数表指针,那么子类***享父类的虚函数表指针空间,不在占用额外的空间,这一点与VC不同,VC在虚继承情况下,不共享父类虚函数表指针
这个题目我发现其实我并没有完全理解啊,当我想验证不加virtual继承的时候,突然发现没理解
验证代码
#include
using namespace std;
class A {
char a[2];
public:
virtual void aa() {};
};
class B : public virtual A {
char b[2];
char a[2];
public:
virtual void bb() {};
virtual void aa() {};
};
class C : public virtual B {
char a[2];
char b[2];
char c[2];
public:
virtual void cc() {};
virtual void aa() {};
virtual void bb() {};
};
int main() {
cout << sizeof(A) << endl << sizeof(B) << endl << sizeof(C);
return 0;
}
//8
//16
//28
这边并没有出现8-16-24是因为sizeof(c) = sizeof(a) + sizeof(b) + 3*sizeof(char) * 2 + 4,加上对齐,就是sizeof(c) = sizeof(a) + sizeof(b) + 8+4 = 28。
不加virtual结果是这样的
#include
using namespace std;
class A {
char a[2];
public:
virtual void aa() {};
};
class B : public A {
char b[2];
char a[2];
public:
virtual void bb() {};
virtual void aa() {};
};
class C : public B {
char a[2];
char b[2];
char c[2];
public:
virtual void cc() {};
virtual void aa() {};
virtual void bb() {};
};
int main() {
cout << sizeof(A) << endl << sizeof(B) << endl << sizeof(C);
return 0;
}
//8
//12
//16 这边又不不懂了,评论区有人评论: 普通继承的时候共享,虚继承的时候不共享
这边还要仔细了解下啊
2023年12月21日16:16:40
在看这题的时候,对于自己写的两个demo,竟然不知道为什么打印结果是这样的。重新跑了一下demo,然后突然发现自己64位电脑上的codeblock竟然是32位的。打印指针大小得知
int main() {
int *p = NULL;
cout << "ptrSize:" << sizeof(p) << endl;
return 0;
}
//ptrSize:42024年1月2日17:02:34
今天看不加virtual的时候继续懵逼啊,理了一会,又增加了下面的验证代码
#include
using namespace std;
class A {
char a[2];
public:
virtual void aa() {};
};
class B : public A {
char b[2];
char a[2];
public:
virtual void bb() {};
virtual void aa() {};
};
class C : public B {
char a[2];
char b[2];
char c[2];
public:
virtual void cc() {};
virtual void aa() {};
virtual void bb() {};
};
class D : public A {
char a[2];
char b[2];
char c[2];
public:
virtual void cc() {};
virtual void aa() {};
virtual void bb() {};
};
class E : public B {
public:
};
class F : public B {
char a[2];
char b[2];
public:
};
class G : public B {
char a[2];
public:
};
int main() {
cout << sizeof(A) << endl << sizeof(B) << endl << sizeof(C) << endl;
cout << sizeof(D) << endl << sizeof(E) << endl << sizeof(F) << endl << sizeof(G);
return 0;
}
//8
//12
//16
//12
//12
//16
//12 G的大小是12,理解为虽然A的大小是8,但是有字节对齐的。虽然G增加了两个字节,但是G和A共享内存。所以G的两个字节放在A里对齐了。所以G大小是12 3、题目3
下面程序的执行结果:答案E
class A{
public:
long a;
};
class B : public A {
public:
long b;
};
void seta(A* data, int idx) {
data[idx].a = 2;
}
int main(int argc, char *argv[]) {
B data[4];
for(int i=0; i<4; ++i){
data[i].a = 1;
data[i].b = 1;
seta(data, i);
}
for(int i=0; i<4; ++i){
std::cout << data[i].a << data[i].b;
}
return 0;
}A、11111111
B、12121212
C、11112222
D、21212121
E、22221111
3、题目3
下面程序的执行结果:答案E
class A{
public:
long a;
};
class B : public A {
public:
long b;
};
void seta(A* data, int idx) {
data[idx].a = 2;
}
int main(int argc, char *argv[]) {
B data[4];
for(int i=0; i<4; ++i){
data[i].a = 1;
data[i].b = 1;
seta(data, i);
}
for(int i=0; i<4; ++i){
std::cout << data[i].a << data[i].b;
}
return 0;
}A、11111111
B、12121212
C、11112222
D、21212121
E、22221111
解释:
首先明确, A类 大小为 4字节;B 类大小为 8字节
因为B继承自A,基类A有一个long,4字节,派生类B继承A的long加上自身定义了一个long,4+4=8个字节。所以,A类指针+1移动4字节,B类指针+1移动8字节,所以A类指针和B类指针的移动步长不相同
void seta(A* data, int idx) { data[idx].a = 2; }
由代码可知,此处传入的实参为B类,而形参却为A类,所以这里就是使用基类A类指针来操作,子类B类的数据。
因为A类和B类指针步长不同的原因,就会出现指针实际操作的目标地址,与想象中的目标地址不相同下面展示,此例题中,因为指针步长不同的原因,所对应的操作地址
因此每执行一次此函数,就会进行4字节对应地址的数据替换。
所以答案就为22221111
因此类推,若将此函数void seta(A* data, int idx);中的A类改为B类,就不会存在指针步长不同的问题,答案就会是21212121
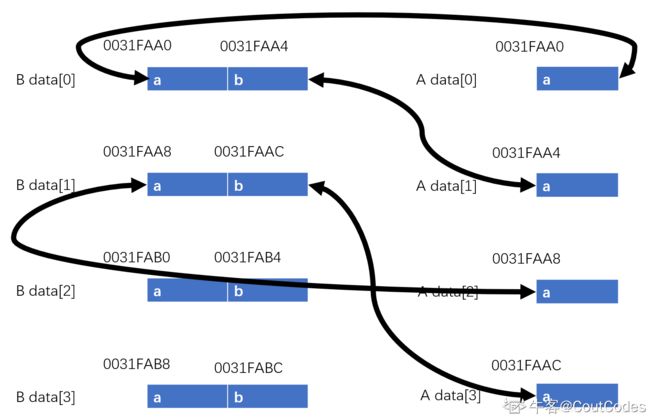
个人感想,这个题目还涉及到有个点就是实参和形参是基类和子类的时候,指向的数据内存其实是实现的内存空间,后面这个点加以注意。这个好像经常出现的情况,比如基类指针指向子类对象或者基类对象,情况是不用的。
2023年12月21日16:26:07
自己画的示意图是这样

12月10号
牛客网公司真题_免费模拟题库_企业面试|笔试真题
1、题目1
通过基类对象名、指针只能使用从基类继承的成员。答案A
A、T
B、F
解释:这个题目就涉及到一个问题,基类指针、子类指针、基类对象、子类对象等问题。
我来整理一下吧,
就是基类指针可以指向基类和子类对象。但是基类指针指向子类对象不能访问子类的新的成员。子类指针指向基类对象有风险。
基类指针指向子类对象需要使用虚函数virtual实现多态,即调用子类的重写的成员函数。基类指针指向基类虚函数,还是调用基类虚函数。即基类指针调用实际指向的对象中的虚函数。
基类指针只能访问基类的重定义函数。子类对象只能访问子类的重定义函数。
传参时,比如子类传给基类,这边搞不清了。不过上述都对应题目和解答,再回顾一下就可以。
看上述的解答,子类传参赋给基类,还是调用子类的虚函数。调用不是虚函数则调用基类的成员函数。基类传给基类不用说了。基类传给子类有风险。
下面代码是验证上面的表述
#include
using namespace std;
class A
{
public:
A()
{
}
virtual ~A()
{
}
void funWithoutVirtual()
{
std::cout << "it is A funWithoutVirtual()" << endl;
}
virtual func()
{
std::cout << "it is A func()" << endl;
}
int funcA()
{
std::cout << "it is A funcA()" << endl;
}
};
class B : public A
{
public:
B()
{
}
virtual ~B()
{
}
void funWithoutVirtual()
{
std::cout << "it is B funWithoutVirtual()" << endl;
}
virtual func()
{
std::cout << "it is B func()" << endl;
}
int funcB()
{
std::cout << "it is B funcB()" << endl;
}
};
void testFunc(A* a)
{
a->func(); //看下子类传给基类是不是正常调用子类虚函数,验证是的
//预测 it is B func()
//a->funcB(); //error: 'class A' has no member named 'funcB'
}
int main()
{
A* a = new A;
a->func(); //预测 it is A func()
//a->funB();
B b;
b.funcA(); //验证子类对象可以基类成员,可以
//预测 it is A funcA()
A* a2 = new B;
a2->func(); //看下基类指针指向子类对象是否正常调用子类虚函数,验证是的
//预测 it is B func()
testFunc(&b);
return 0;
}
//2023年12月21日18:46:59
//it is A func()
//it is A funcA()
//it is B func()
//it is B func() 12月11号
牛客网公司真题_免费模拟题库_企业面试|笔试真题
1、题目1
在64位系统中,有如下类:
class C
{
public:
char a;
static char b;
void *p;
static int *c;
virtual void func1();
virtual void func2();
};那么sizeof(C)的数值是(D)
A、9
B、17
C、32
D、24
解释:参考答案:应该是D sizeof(类)计算的是类中存在栈中的变量的大小,而类中的b和*c都是static静态变量,存在全局区中,因此不在计算范围之内,于是只剩下char a,void *p和两个virtual虚函数,a是char类型,占用一个字节,p是指针,在64位系统的指针占用8个字节,而两个虚函数只需要一个虚函数表指针,也是八个字节,加上类中的对齐方式(char a对齐时后面补上7个字节),故答案为24.
评论区一个评论:
1 sizeof是用来计算栈大小,不涉及全局区,故类的静态成员大小sizeof不涉及。
2 本题中的虚函数属于同一个类,故只需要一个指针指向虚函数表,所以在64位系统中占用8个字节。就算本题有100个虚函数,那么也只占用8个字节。
综上,占用栈空间的成员有:a, p, func1, func2,由于64位对其,故总空间为8+8+8=24字节。
2、题目2
以下程序的打印结果是(A)
#include
using namespace std;
void swap_int(int a , int b)
{
int temp = a;
a = b;
b = temp;
}
void swap_str(char*a , char*b)
{
char*temp = a;
a = b;
b = temp;
}
int main(void)
{
int a = 10;
int b = 5;
char*str_a = "hello world";
char*str_b = "world hello";
swap_int(a , b);.
swap_str(str_a , str_b);
printf("%d %d %s %s\n",a,b,str_a,str_b);
return 0;
} A、10 5 hello world world hello
B、10 5 world hello hello world
C、5 10 hello world world hello
D、5 10 world hello hello world
解释
#include
using namespace std;
void swap_int_with_yinyong(int &a , int &b)
{
int temp = a;
a = b;
b = temp;
}
void swap_int_with_pointer(int* a , int* b)
{
int temp = *a;
*a = *b;
*b = temp;
}
void swap_str(char*a , char*b)
{
char*temp = a;
a = b;
b = temp;
}
void swap_str_with_pointer(char**a , char**b)
{
char*temp = *a;
*a = *b;
*b = temp;
}
int main(void)
{
int a = 10;
int b = 5;
char*str_a = "hello world";
char*str_b = "world hello";
printf("before exchange: %d %d\n",a,b);
swap_int_with_yinyong(a , b);
printf("exchange a b with yinyong:");
printf("%d %d\n",a,b);
printf("\nbefore exchange: %d %d\n",a,b);
swap_int_with_pointer(&a , &b);
printf("exchange a b with pointer:");
printf("%d %d\n",a,b);
printf("\nbefore exchange: %s %s\n",str_a,str_b);
swap_str(str_a , str_b);
printf("exchange str useless:");
printf("%s %s\n",str_a,str_b);
printf("\nbefore exchange: %s %s\n",str_a,str_b);
swap_str_with_pointer(&str_a , &str_b);
printf("exchange str with pointer:");
printf("%s %s\n",str_a,str_b);
return 0;
}
//before exchange: 10 5
//exchange a b with yinyong:5 10
//
//before exchange: 5 10
//exchange a b with pointer:10 5
//
//before exchange: hello world world hello
//exchange str useless:hello world world hello
//
//before exchange: hello world world hello
//exchange str with pointer:world hello hello world
12月14号
牛客网公司真题_免费模拟题库_企业面试|笔试真题
1、题目1
下面有关c++内存分配堆栈说法错误的是?答案D
A、对于栈来讲,是由编译器自动管理,无需我们手工控制;对于堆来说,释放工作由程序员控制
B、对于栈来讲,生长方向是向下的,也就是向着内存地址减小的方向;对于堆来讲,它的生长方向是向上的,是向着内存地址增加的方向增长。
C、对于堆来讲,频繁的 new/delete 势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。对于栈来讲,则不会存在这个问题
D、一般来讲在 32 位系统下,堆内存可以达到4G的空间,但是对于栈来讲,一般都是有一定的空间大小的。
解释:我做对了,但是对于D选项还是不太懂。看了解释,32位系统寻址大小是2^32=4,294,967,296Byte(字节)。2^32=4,294,967,296Byte(字节)/1024(KB)=4,194,304KB=4,194,304KB/1024(M)=4096M=4GB;
而且评论区有人这样说:一般0~3G是用户空间,3G~4G是内核空间, 所以堆内存不应该达到4G。
2、题目2
What’s the runtime behavior of below code piece?(单选B)
int *p = (int *)malloc(sizeof(int));
p = NULL;
free(p);
A、Compiling error: free can't be applied on NULL pointer
B、Memory leak happens
C、Dangling pointer is generated
D、May crash when free() is called with NULL input
解释:这题做对了。但是是查了下free空指针后。
free可以作用于空指针,不会报错。
Dangling pointer悬挂指针、空指针。指指针对应的内存空间已经释放了,但是指针依然指向那块内存空间。这种指针指向的内存空间释放后没有置空的指针,就叫Dangling pointer。处理方法,指向内存空间释放后指针置空。
12月15号
牛客网公司真题_免费模拟题库_企业面试|笔试真题
1、题目1
下列说法错误的是(ABCD)
A、派生类不能访问通过私有继承的基类的保护成员
B、多继承的虚基类不能够实例化
C、如果基类没有默认构造函数,派生类就应当声明带形参的构造函数
D、基类的析构函数和虚函数都不能够被继承,需要在派生类中重新实现
解释:我自己选的是C。
这里还有个知识点盲区就是虚基类。
2023年12月21日18:49:19
A选项中,派生类无论是public、protected、private继承,都能够访问和修改基类的public和protected成员,而派生类对象仅当public继承时才能够访问和修改基类成员,因此在基类中定义的protected成员在私有继承的派生类中可访问可修改的,A错误
2024年1月2日17:53:44
再看这个题目,CD为什么是错的也不知道了。
B选项中,虚基类是用来避免多继承带来的二义性问题,即:派生类从同一个基类,沿不同继承方向,得到多个相同的拷贝,此时派生类不知道要访问哪一个。虚基类能够让公共基类只产生一个拷贝,即只对第一个调用的有效,对其他的派生类都是虚假的,可以认为虚基类只实例化一次,而派生类也只得到一套虚基类的成员,B错误
C选项正确,如果基类没有默认构造函数,派生类中的构造函数必须显式地调用基类的带参构造函数
D选项中,析构函数不能够被继承,但是虚函数不仅能够被派生类继承,还能够被派生类改写,D错误
再看答案,发现C选项是错的,因为【C选项错的,亲测,在派生类声明不带形参的构造函数,然后构造参数初始化列表里面初始化基类时带个参数就行】
这边就有个问题,什么是默认构造函数?
如果你对所定义的类没有提供构造函数,则编译器会自动为你生成一个默认的无参数构造函数;一旦你为你的类定义了构造函数,哪怕只是一个,那么编译器将不再生成默认的构造函数。
来自:C++ 默认构造函数_c++默认的无参构造是什么-CSDN博客
12月18号
牛客网公司真题_免费模拟题库_企业面试|笔试真题
1、题目1
下列关于多态性说法不正确的是:答案AB
A、重载函数名相同,但是参数列表个数和顺序,参数类型,以及返回类型一定不同
B、重载 overload 和 重写 override 是一个意思
C、多态行有静态和动态多态两种
D、c++中 final 关键字表示函数不能再次被override
解释:我选错成ABCD。
其中,多态分为静态多态和动态多态。

另外,final用来修饰类的虚函数,使得该虚函数在子类中,不能被重写,理解:使得该功能终结!
2、题目2
以下关于引用和指针的描述,正确的是(BCD)
A、引用和指针都是指向变量的内存地址
B、引用可以表示指针
C、引用和指针都是实现多态效果的手段
D、引用本身是目标变量的别名,对引用的操作就是对目标变量的操作
解释:选错成ABD。
引用实现多态效果:
C++基类指针或引用指向或引用派生类对象(实现动态多态四种手段)父类指针访问子类成员变量(需要dynamic_cast)_c++ 基类指针指向派生类-CSDN博客
12月19号
牛客网公司真题_免费模拟题库_企业面试|笔试真题
1、题目1
在32位环境下,以下代码输出的是(A)
#include
class A {
public:
A(){ printf("A");}
~A(){ printf("~A");}
};
class B : public A {
public:
B(){ printf("B");}
~B(){ printf("~B");}
};
int main() {
A *c = new B[2];
delete[] c;
return 0;
} A、ABAB~A~A
B、ABAB~B~A~B~A
C、ABAB~B~A
D、ABAB~A~B~A~B
解释:选错B。
在C++中,析构函数的作用是:当一个对象被销毁时,调用析构函数对类对象和对象成员进行释放内存资源。
当我们定义一个指向派生类类型对象指针时,构造函数按照从基类到派生类的顺序被调用,但是当删除指向派生类的基类指针时,派生类的析构函数没有被调用,只是调用了基类的析构函数,此时派生类将会导致内存泄漏
我们需要将基类的析构函数声明为虚函数,此时在调用析构函数的时候是根据ptr指向的具体类型来调用析构函数,此时会调用派生类的析构函数。
自己验证:析构函数加上virtual
#include
class A {
public:
A(){ printf("A");}
virtual ~A(){ printf("~A");}
};
class B : public A {
public:
B(){ printf("B");}
virtual ~B(){ printf("~B");}
};
int main() {
A *c = new B[2];
delete[] c;
return 0;
}
//ABAB~B~A~B~A 其中有个评论玄乎玄乎的,暂时没有看明白。
2023年12月25日09:47:31
这个题目其实还存在一个问题,那就是为什么不加virtual就只调用基类析构函数,加了virtual就能调用子类析构函数。
https://wenku.csdn.net/answer/fc1d8d6b828e4ea6a58ca7b4c590480f
这个题目基本说了一些原因。其中提到的创建子类对象的时候,是先构造基类对象,再构建子类对象。那析构的时候就要先析构子类对象,再析构基类对象。不然就会造成内存泄露。加上virtual就能实现这个效果。这种析构函数也成为虚析构函数。
2023年12月28日10:45:29
这个问题今天做的时候竟然有出问题啦。不过经过自己的理解和琢磨感觉有更进一步理解啦。害,真是体现了方法的先进性啊。
首先是做了一个新的牛客的题目,并且做错了,这个题目来自第3题:牛客网公司真题_免费模拟题库_企业面试|笔试真题
先展示题目
#include
using namespace std;
class A {
public:
A() {
cout<<"1";
}
~A() {
cout<<"2";
}
};
class B : public A {
public:
B() {
cout<<"3";
}
~B() {
cout<<"4";
}
};
int main()
{
B b;
return 0;
} A、1234
B、1324
C、1342
D、3142
这个题目的答案是C。我选错我B。当时做这个题目的时候就想到了关于虚析构函数的问题,所以想多了选的B。但是看答案的时候大家都是按照构造函数反向得到析构顺序的。那么我就想到帖子里的上面那题。
于是就觉得纳闷。还以为跟指针或者数组有关。于是写下了下面的验证代码
#include
using namespace std;
class A {
public:
A() {
cout<<"1";
}
~A() {
cout<<"2";
}
};
class B : public A {
public:
B() {
cout<<"3";
}
~B() {
cout<<"4";
}
};
int main()
{
//B b;
B* ptr = new B;
delete ptr; //预测1342
cout << endl;
B* ptr1 = new B[2];
delete ptr1; //预测13134242
cout << endl;
}
//1342
//13134242
上面的也是正常析构的,并且析构函数也不是虚函数。
那么问题在哪里。仔细研究了上面题目的代码,发现好像是基类指针指向派生类对象,于是写下下面的代码。
#include
using namespace std;
class A {
public:
A() {
cout<<"1";
}
~A() {
cout<<"2";
}
};
class B : public A {
public:
B() {
cout<<"3";
}
~B() {
cout<<"4";
}
};
int main()
{
//B b;
B* ptr = new B;
delete ptr; //预测1342
cout << endl;
B* ptr1 = new B[2];
delete[] ptr1; //预测13134242
cout << endl;
A* ptr2 = new B[2];
delete[] ptr2;
cout << endl;
A* ptr3 = new B;
delete ptr3;
cout << endl;
B* ptr4 = new B[2];
delete ptr4; //只析构一次
cout << endl;
return 0;
}
//1342
//13134242
//131322
//132
//131342
所以问题被我复现了。当基类指针指向派生类对象的时候,如果基类析构函数不是虚函数,析构时不会析构派生类对象。
写下下面的验证代码,下面的验证代码中,基类析构函数是虚函数。
#include
using namespace std;
class A {
public:
A() {
cout<<"1";
}
virtual ~A() {
cout<<"2";
}
};
class B : public A {
public:
B() {
cout<<"3";
}
~B() {
cout<<"4";
}
};
int main()
{
A* ptr3 = new B;
delete ptr3; //预测1342
cout << endl;
A* ptr2 = new B[2];
delete[] ptr2; //预测13134242
cout << endl;
return 0;
}
//1342
//13134242
所以这个题目就涉及到一个概念,虚析构函数。虚析构函数详解-CSDN博客
bingo!
2、题目2
下面对于构造方法的描述,正确的有哪些?ABC
A、方法名必须和类名相同
B、方法名的前面没有返回值类型的声明
C、在方法名中不能使用return语句返回一个值
D、当定义了带参数的构造方法,系统默认的不带参数的构造方法依然存在
解释:错选为ABCD。
C++中必须有构造函数,默认有个无参数的构造函数,但是一旦用户编写了构造函数,那么默认构造函数就丢失了,要想有默认构造函数就必须自己手动实现。
C构造方法可以使用return语句返回一个值,但是一般情况下不建议在构造方法中使用return语句返回值
10月20号
牛客网公司真题_免费模拟题库_企业面试|笔试真题
1、题目1
c++语言中,类ClassA的构造函数和析构函数的执行次数分别为()
ClassA *pclassa=new ClassA[5];
delete pclassa;A、5,1
B、1,1
C、5,5
D、1,5
解释:正确答案:A。你的答案:C
参考答案:A Class A *pclassa=newClassA[5]; new了五个对象,所以构造5次,然后Pclass指向这五个对象 deletepclassa; 析构一次,delete[]pclassa 这样就析构5次
这边考察delete和delete[] 的区别。delete和delete[]都能释放指针所指向的内存区域。但delete只会调用一次析构函数,而delete[]还会调用后续所有对象的析构函数。当数据类型为基本数据类型时,用delete和delete[]都可以,因为基本数据类型没有析构函数。
2、题目2
有以下程序
#include
using namespace std;
class A {
float *p; int n;
public:
A(int s){
n=s;
p=new float[n];
}
~A() {
delete[] p;
}
int Getn() const {
return n;
}
float & operator[](int i) {
return _________;
}
void Print() {
int i;
for(i=0;i< this->Getn();i++)
{cout< 运行结果是12345,请为横线处选择合适的程序( AD )
A、p[i]
B、*p
C、p+i
D、*(p+i)
解释:这个题目我做对了,也是提交答案前依赖了codeblock验证。其中一开始不能理解的是
float & operator[](int i) {
return _________;
} 比如填入*(p+i),这边返回的是数组其中一个成员p[i],然后 a[i]=i+1; 就是实现p[i] = i + 1;
原来是这样,豁然开朗!
12月21号
牛客网公司真题_免费模拟题库_企业面试|笔试真题
1、题目1:
以下程序片段输出什么内容:答案C
#include
using namespace std;
class Demo {
public:
Demo() :count(0) {}
~Demo() {}
void say(const string& msg) {
fprintf(stderr, "%s\n", msg.c_str());
}
private:
int count;
};
int main(int argc, char** argv) {
Demo* v = NULL;
v->say("hello world");
} A、运行错误
B、编译错误
C、输出 "hello world"
D、不确定答案
解释:这个歌题目我等于是瞎选的,选c对了。但是我完全没get到这个程序的点,看了评论才知道。
初始化为NULL的类指针,可以安全的调用不涉及类成员变量的类成员函数而不会出错。
2、题目2
如下程序的执行结果是什么:答案B。
#include "stdio.h"
class Base
{
public:
Base()
{
Init();
}
virtual void Init()
{
printf("Base Init\n");
}
void func()
{
printf("Base func\n");
}
};
class Derived: public Base
{
public:
virtual void Init()
{
printf("Derived Init\n");
}
void func()
{
printf("Derived func\n");
}
};
int main()
{
Derived d;
((Base *)&d)->func();
return 0;
}A、Base Init Derived func
B、Base Init Base func
C、Derived Init Base func
D、Derived Init Derived func
解释:我错选了C。
在构造函数不要调用虚函数。在基类构造的时候,虚函数是非虚,不会走到派生类中,既是采用的静态绑定。显然的是:当我们构造一个子类的对象时,先调用基类的构造函数,构造子类中基类部分,子类还没有构造,还没有初始化,如果在基类的构造中调用虚函数,如果可以的话就是调用一个还没有被初始化的对象,那是很危险的,所以C++中是不可以在构造父类对象部分的时候调用子类的虚函数实现。但是不是说你不可以那么写程序,你这么写,编译器也不会报错。只是你如果这么写的话编译器不会给你调用子类的实现,而是还是调用基类的实现。
在析构函数中也不要调用虚函数。在析构的时候会首先调用子类的析构函数,析构掉对象中的子类部分,然后在调用基类的析构函数析构基类部分,如果在基类的析构函数里面调用虚函数,会导致其调用已经析构了的子类对象里面的函数,这是非常危险的。
至于为什么是执行Base func,是因为func不是虚函数,根据指针类型是基类还是派生类来执行。
2024年1月3日09:39:50
今天再看这个题目,疑惑为啥派生类没有构造函数。然后我以为是继承了基类的构造函数。百度了一下,派生类会继承基类的构造函数吗?
查到这篇帖子:C++继承和多态特性——继承详解(2)_c++基类指针构造父类-CSDN博客
派生类并不继承基类的构造和析构函数,只继承成员变量和普通成员方法。
牢记构造函数的2大作用:初始化成员,分配动态内存
现在的问题是派生类没有构造函数,不影响派生类生成吗?
查到这篇帖子:关于派生类和基类构造函数的规则 - 简书
现在的 理解就是如果派生类不需要初始化变量其实是不需要构造函数。百度一下,构造函数是必须的吗?看下。
查到的意思是不是必须的,如果没有写构造函数,类中是有一个默认构造函数的,会调用默认构造函数。
12月21号下午
牛客网公司真题_免费模拟题库_企业面试|笔试真题
1、题目1
在C++中输出多少?答案A
const int i = 0;
int *j = (int *) &i;
*j = 1;
printf("%d,%d", i, *j)A、0,1
B、1,1
C、1,0
D、0,0
解释:c语言中const只是指定这个变量是只读的,并非真正意义上的常量,并且可以通过指针修改。c++中常量都会有一张常量表,任何对常量的读取都是从这个表里直接读取,而通过指针进行修改,修改的是常量在栈上对应地址空间的内容,本身常量表里的内容不会被改变
个人疑问:那么c和c++中还有输出区别吗?
2、题目2
引用可以是void类型吗?答案A
A、不可以
B、可以
解释:引用只是一个别名,是已有变量的别名,而void类型是空类型,是没有分配内存的。所以引用不能是void类型。
2024年1月3日10:00:01
void是空类型,空类型是什么意思:void(计算机语言关键字)_百度百科
评论区还有人提到空引用,空引用是啥?
至于之前留下的疑问,什么是空引用,也查了一下。https://www.cnblogs.com/2018shawn/p/12724525.html
#include
void f(int & p)
{
//p = 0; //代码异常
if (&p) p = 0;
}
int main()
{
int * a = NULL;
int & b = *a;
f(b);
} 上面的p就是空引用。但是实际上面的代码毫无意义。
最后,请大家记住,引用不能为空,如果可能存在空对象时,请使用指针。
最后结论,空引用没有意义。
3、题目3
关于全局变量,下列说法正确的是(D)。
A、任何全局变量都可以被应用系统汇总任何程序文件中的任何函数访问
B、任何全局变量都只能被定义它的程序文件中的函数访问
C、任何全局变量都只能被定义它的函数中的语句访问
D、全局变量可用于函数之间传递数据
解释:针对选项A:
普通全局变量能被当前源文件函数及其他源文件函数访问,其他源文件函数访问全局变量需要使用extern关键字声明全局变量。
static全局变量则只能被当前源文件函数访问,作用域是从定义位置开始到源文件结束。
12月22号
牛客网公司真题_免费模拟题库_企业面试|笔试真题
1、题目1
在C++中,根据(D )识别类层次中不同类定义的虚函数版本。
A、参数个数
B、参数类型
C、函数名
D、this指针类型
解释:这个题目奇奇怪怪的。
评论区有人解释:
虚函数的调用是看对象是哪个类的实例就调用谁,而this就是指向当前对象的指针,其类型与该实例类型的指针一致。
这其实解释了虚函数调用的一个原理。
2、题目2
对于如下C++程序的输出是?答案C
int main() {
vector vInt;
for (int i=0; i<5; ++i)
{
vInt.push_back(i);
cout << vInt.capacity() << " ";
}
vector vTmp(vInt);
cout << vTmp.capacity() << "\n";
return 0;
} A、1 2 3 4 5 5
B、1 2 3 4 5 8
C、1 2 4 4 8 5
D、1 2 4 4 8 8
解释:
vector的内存扩容,是发生在当前容量无法容纳新元素时进行的,并且,每次扩容后的大小是原容量的2倍。
vector的初始容量为0,插入1个元素后,容量为1,插入2个元素后,容量为2,而当插入第3个元素时,容量变为4,直到4个容量全部用完后,再次插入新元素时,容量将扩充到8。
评论里有人说也不一定是两倍。这个题目就是考vector扩容方式嘛
12月23号
牛客网公司真题_免费模拟题库_企业面试|笔试真题
今天这个题目把我干懵逼了,感觉做的很艰难。本来觉得已经做了那么多题目了,做的应该很快很轻松了。但是其实做的很费劲。其中涉及到模板类、类模板、共有私有继承方式等知识点。感觉是我的盲点啊。
逐个击破吧。
1、题目1
下面有关C++类说法正确的是() 答案AD
A、对基类成员的访问必须是无二义性的
B、基类的公有成员在派生类中仍然是公有的
C、this指针保证基类保护成员在子类中可以被访问
D、派生类一般很少用私有派生
解释:选错为ABC
父类的成员及函数能否在子类中被访问是取决于继承方式的。 若是私有继承,父类成员都不可见; 若为保护继承,父类的成员都变为保护; 若为公有继承,父类成员访问限定符不变; 因此一般都为公有继承。
继承方式改变的是派生类的对象对于基类中成员访问的级别,对于派生类内部只取决于成员在基类中的访问修饰符
自己的验证代码如下:
#include
uasing namespace std;
class A
{
public:
A()
{
publicAData = 1;
protectedAData = 2;
privateAData = 3;
}
virtual ~A()
{
}
public:
void publicAFunc()
{
cout << "publicAFunc" << endl;
cout << "privateAData:" << privateAData << endl;
}
int publicAData;
protected:
void protectAFunc()
{
cout << "protectAFunc" << endl;
}
int protectedAData;
private:
void privateAFunc()
{
cout << "privateAFunc" << endl;
}
int privateAData;
};
class B : public A
{
public:
B()
{
}
virtual ~B()
{
}
public:
void publicBFunc()
{
publicAFunc();
protectAFunc();
//privateAFunc(); //派生类公有继承基类, 派生类不能访问基类私有成员
//this->privateAFunc(); //this指针也不能访问私有成员
cout << "publicAData:" << publicAData << endl;
cout << "protectedAData:" << protectedAData << endl;
//cout << "privateAFunc:" << privateAFunc << endl;
}
};
class C : private A //私有继承不影响派生类访问基类,访问基类的权限和基类内部访问权限一致
{
public:
C()
{
}
virtual ~C()
{
}
public:
void publicCFunc()
{
publicAFunc();
protectAFunc();
//privateAFunc(); //派生类公有继承基类, 派生类不能访问基类私有成员
//this->privateAFunc(); //this指针也不能访问私有成员
cout << "publicAData:" << publicAData << endl;
cout << "protectedAData:" << protectedAData << endl;
//cout << "privateAFunc:" << privateAFunc << endl;
}
};
int main()
{
cout << "下面演示派生类对共有继承基类的访问情况" << endl;
B b;
b.publicBFunc();
cout << "下面演示派生类对私有继承基类的访问情况" << endl;
C c;
c.publicCFunc();
//下面演示派生类成员对共有继承基类的访问情况
cout << "下面演示派生类成员对共有继承基类的访问情况" << endl;
b.publicAFunc();
//b.protectAFunc(); //共有继承派生类对象只能访问基类公共的成员,通过基类的公共成员可以访问基类的私有成员变量
//b.privateAFunc();
cout << "下面演示派生类成员对共有继承基类的访问情况" << endl;
//c.publicAFunc(); //私有继承派生类的对象无法访问基类的共有成员、私有成员
return 0;
}
//下面演示派生类对共有继承基类的访问情况
//publicAFunc
//privateAData:3
//protectAFunc
//publicAData:1
//protectedAData:2
//下面演示派生类对私有继承基类的访问情况
//publicAFunc
//privateAData:3
//protectAFunc
//publicAData:1
//protectedAData:2
//下面演示派生类成员对共有继承基类的访问情况
//publicAFunc
//privateAData:3
//下面演示派生类成员对共有继承基类的访问情况 2、题目2
关于虚函数,以下说法正确的是? 答案C
A、虚函数不能定义为private
B、虚函数不可以被子类覆盖
C、子类不能调用父类private的虚函数
D、虚函数的重载性和它声明的权限有关
解释:选错为B。
关于虚函数,正确的说法是:
A. 虚函数不能定义为private。虚函数必须被声明为public或protected,在派生类中才能被访问(覆盖)。
B. 虚函数可以被子类覆盖。虚函数是为了支持多态性而设计的,子类可以通过覆盖虚函数来改变父类的行为。
C. 子类不能调用父类private的虚函数。由于private函数在派生类中不可见,派生类无法调用父类的private函数,更不能覆盖它。
D. 虚函数的重载性和它声明的权限无关。虚函数的重载性是根据函数的参数类型和个数确定的,与函数的声明权限无关。当派生类中的函数与基类中的虚函数同名但参数列表不同,它并不会覆盖基类中的虚函数,而是在派生类中重载了该函数。
3、题目3
以下代码的输出为()答案C
#include
using namespace std;
struct A {
A() { std::cout << "A"; }
};
struct B {
B() { std::cout << "B"; }
};
class C {
public:
C() : a(), b() { std::cout << "C"; }
private:
B b;
A a;
};
int main() {
C();
} A、ABC
B、CBA
C、BAC
D、ACB
解释:选错为B
C++ 类的构造顺序为先实例化类成员,然后才会执行构造函数。使用 : 进行实例化的类成员实例化顺序是按照其声明顺序决定。因此先实例化 B 对象,在实例化 A 对象,因此输出为 BAC。C 选项正确。
4、题目4
关于类模板,描述错误的是( A)?
A、一个普通基类不能派生类模板
B、类模板可以从普通类派生,也可以从类模板派生
C、根据建立对象时的实际数据类型,编译器把类模板实例化为模板类
D、函数的类模板参数需生成模板类并通过构造函数实例化
解释:选错为D
12月26号
牛客网公司真题_免费模拟题库_企业面试|笔试真题
1、题目1
阅读下面 C++ 代码,输出结果为(B)
#include
using namespace std;
class base1 {
private: int a, b;
public:
base1(int i) : b(i + 1), a(b) {}
base1():b(0), a(b) {}
int get_a() {
return a;
}
int get_b() {
return b;
}
};
int main() {
base1 obj1(11);
cout << obj1.get_a() << " " << obj1.get_b() << endl;
return 0;
} A、12 12
B、随机数 12
C、随机数 随机数
D、12 随机数
解释:选错为A
初始化列表的初始化顺序按照成员的声明顺序而来。因此 obj(11) 先初始化 a,但 a 的值由 b 决定,b 此时没有初始化,因此为随机值。然后初始化 b 为 12。因此答案为随机值,12。B 选项正确。
12月27号
牛客网公司真题_免费模拟题库_企业面试|笔试真题
1、题目1
静态变量可以用来计算类的实例变量,这句话是否正确?A
A、正确
B、错误
2、题目2
#include
using namespace std;
int n = 300;
int solve(int x) {
return x * (n - x);
}
int main() {
int l = 1, r = n;
int mid1, mid2;
int t = 50;
while (t--) {
mid1 = l + r >> 1;
mid2 = mid1 + r >> 1;
if (solve(mid1) > solve(mid2)) {
r = mid2;
} else {
l = mid1;
}
}
cout << l << endl;
return 0;
} 程序的输出为(C)
A、1
B、100
C、150
D、300
3、题目3
在32位计算机中,下面输出是多少( )
#include
using namespace std;
typedef enum
{
Char ,
Short,
Int,
Double,
Float,
}TEST_TYPE;
int main() {
TEST_TYPE val;
cout<< sizeof(val)< A、5
B、4
C、8
D、12
解释:枚举类型默认为int变量,所以为4
10月28号
牛客网公司真题_免费模拟题库_企业面试|笔试真题
1、题目1
下面代码的输出是()
#include
using namespace std;
class A {
public:
A() {
cout<<"1";
}
~A() {
cout<<"2";
}
};
class B : public A {
public:
B() {
cout<<"3";
}
~B() {
cout<<"4";
}
};
int main()
{
B b;
return 0;
} A、1234
B、1324
C、1342
D、3142
2、题目2
要求用成员函数重载的运算符是(A)。
A、=
B、==
C、<=
D、++
解释:只能使用成员函数重载的运算符有:=、()、[]、->、new、delete。
直白的说,重载操作符分为类内重载(声明为类的成员函数)和类外重载(声明为普通的非成员函数)。写法上有什么区别?比如要实现把值赋给对象,类内重载操作符要放在对象的右边。而类外重载操作符要放在对象的左边。我们在赋值的时候都是把右侧的内容赋值给左侧,如果写成类外重载就反过来了不符合逻辑习惯,也会造成定义的二义性。因此=、()、[]、->、new、delete需要类内实现。
这个回答中用类内和类外的区别来解释为什么以上几个操作符只能用成员函数重载。同时涉及到了类内和类外两种重载方式。还举了个例子:
//例,实现对象和值的+操作
class CNum //类内重载
{
public:
int m_nNum;
CNum():m_nNum(0){}
int operator+(int a) //在Int a左侧有隐藏的参数CNum & *this。
{
return this->m_nNum + a;
}
};
int main()
{
CNum num;
num + 123;
}
class CNum //类外重载
{
public:
int m_nNum;
CNum():m_nNum(0){}
};
int operator+(int a, CNum &num) //类外不可写成int operator+(CNum &num, int a)
{
return num.m_nNum + a;
}
int main()
{
CNum num;
123 + num;
}有几个疑问:
1、为什么类外只能写成int operator+(int a, CNum &num)形式。
2、类内和类外有什么区别呢,这依然是个问题。
查到了在这个贴子,讲的有点细有点复杂。面向对象和C++基础—面向对象(运算符重载篇)_c++int和double可以直接加减乘除吗-CSDN博客
3、题目3
写出下面程序的输出结果:答案C
#include
using namespace std;
class Base
{
int x;
public:
Base(int b): x(b) {}
virtual void display()
{
cout << x;
};
};
class Derived: public Base
{
int y;
public:
Derived(int d): Base(d), y(d) {} void display()
{
cout << y;
}
};
int main()
{
Base b(1);
Derived d(2);
Base *p = & d;
b.display();
d.display();
p->display();
return 0;
}
//122 A、121
B、222
C、122
D、运行出错
解释:这个题目做对了
现在的问题是我想验证当创建子类后,是不是也创建了个父类,就写了下面的代码验证。
#include
using namespace std;
class Base
{
public:
int x;
public:
Base(int b): x(b) {}
virtual void display()
{
cout << x;
};
};
class Derived: public Base
{
int y;
public:
Derived(int d): Base(d), y(d) {} void display()
{
cout << y;
}
};
int main()
{
Base b(1);
Derived d(2);
Base *p = &d;
b.display();
d.display();
p->display();
cout << endl;
cout << "b.x:" << b.x << endl;
cout << "p->x:" << p->x << endl;
return 0;
}
//122
//b.x:1
//p->x:2 事实上是创建了子类后,也同时创建了父类。这就是为什么析构时要子类、父类都释放。因为确实创建了个父类。
11月29号
牛客网公司真题_免费模拟题库_企业面试|笔试真题
1、题目1
以下代码执行结果是(答案B)
#include
using namespace std;
class Parent {
public:
virtual void output();
};
void Parent::output() {
printf("Parent!");
}
class Son : public Parent {
public:
virtual void output();
};
void Son::output() {
printf("Son!");
}
int main() {
Son s;
memset(&s, 0, sizeof(s));
Parent& p = s;
p.output();
return 0;
} A、Parent!
B、Son!
C、编译出错
D、没有输出结果,程序运行出错
解释:memset 将s所指向的某一块内存中的每个字节的内容全部设置为ch指定的ASCII值, 本代码中, 不虚函数链表地址也清空了, 所以p.output调用失败。 output函数的地址编程0
2、题目2
子类必须覆盖基类的虚函数
12月30号
牛客网公司真题_免费模拟题库_企业面试|笔试真题
1、题目1
C++ 中,下面描述正确的是:答案C
int *p1 = new int[10];
int *p2 = new int[10]();A、p1和p2申请的空间里面的值都是随机值
B、p1和p2申请的空间里的值都已经初始化
C、p1申请的空间里的值是随机值,p2申请的空间里的值已经初始化
D、p1申请的空间里的值已经初始化,p2申请的空间里的值是随机值
解释:
对于内置类型而言,new仅仅是分配内存,除非后面显示加(),相当于调用它的构造函数,对于自定义类型而言,只要一调用new,那么编译器不仅仅给它分配内存,还调用它的默认构造函数初始化,即使后面没有加() ...
验证一下:
nt main()
{
int *p1 = new int[10];
int *p2 = new int[10]();
for(int i = 0; i < 10; i++)
{
cout << "p1[" << i << "]" << p1[i] << "," << "p2[" << i << "]" << p2[i] << endl;
}
return 0;
}
p1[0]18618272,p2[0]0
p1[1]18612416,p2[1]0
p1[2]100663302,p2[2]0
p1[3]36406,p2[3]0
p1[4]18618272,p2[4]0
p1[5]18612416,p2[5]0
p1[6]1113941103,p2[6]0
p1[7]1801678700,p2[7]0
p1[8]1936028764,p2[8]0
p1[9]1818584180,p2[9]03、题目3
下面程序程序运行后的结果是(答案C)
#include
using namespace std;
class P {
char nameP[30];
public:
P(const char* name = "123") { strcpy(nameP, name); }
const char* getName() {
return nameP;
}
virtual const char* getType() {
return "P";
}
};
class B :public P {
char nameB[30];
public:
B(const char* n1, const char* n2) : P(n1) { strcpy(nameB, n2); }
const char* getName() { return nameB; }
const char* getType() {
return "B";
}
};
void showP(P* p) {
cout << p->getType() << ":" << p->getName() << endl;
}
int main() {
B b("book1", "book2");
showP(&b);
return 0;
} A、P:book1
B、B:book2
C、B:book1
D、P:book2
解释:这个题目我做对了,但是记录一下的原因是它提供了一个做法,就是只创建派生类,但是同时可以是基类和派生类成员的定义不一样。不知道我表达清楚没。看这段代码:
class B :public P {
char nameB[30];
public:
B(const char* n1, const char* n2) : P(n1) { strcpy(nameB, n2); }
const char* getName() { return nameB; }
const char* getType() {
return "B";
}
};11月30号
牛客网公司真题_免费模拟题库_企业面试|笔试真题
这个试卷只对了4题
1、题目1
关于模板类不能放两个文件中
模板分离编译问题(函数模板的声明和定义无法放在两个文件的原因分析)_模板函数多文件间声明和调用-CSDN博客
2、题目2
下面哪几种是 STL 容器(C++ 11及以上)类型(A、B、D、E)
A、vector
B、set
C、multivector
D、multiset
E、array
解释:错选ABE
C++11 STL中的容器
==================================================
一、顺序容器:
vector:可变大小数组;
deque:双端队列;
list:双向链表;
forward_list:单向链表;
array:固定大小数组;
string:与vector相似的容器,但专门用于保存字符。
==================================================
二、关联容器:
按关键字有序保存元素:(底层实现为红黑树)
map:关联数组;保存关键字-值对;
set:关键字即值,即只保存关键字的容器;
multimap:关键字可重复的map;
multiset:关键字可重复的set;
--------------------------------------------------------------------------------
无序集合:
unordered_map:用哈希函数组织的map;
unordered_set:用哈希函数组织的set;
unordered_multimap:哈希组织的map;关键字可以重复出现;
unordered_multiset:哈希组织的set;关键字可以重复出现。
==================================================
三、其他项:
stack、queue、valarray、bitset
3、题目3
在C++里,同一个模板的声明和定义是不能在不同文件中分别放置的,否则会报编译错误。为了解决这个问题,可以采取以下办法有(ABC)
A、模板的声明和定义都放在一个.h文件中。
B、模板的声明和定义可以分别放在.h和.cpp文件中,在使用的地方,引用定义該模板的cpp文件。
C、使用export使模板的声明实现分离。
D、以上说法都不对
解释:选错A。
未完待续......
总结
总结牛客C++题目错题。