Java LinkedList解密
一、LinkedList最底层的原理
LinkedList其实底层是链表:
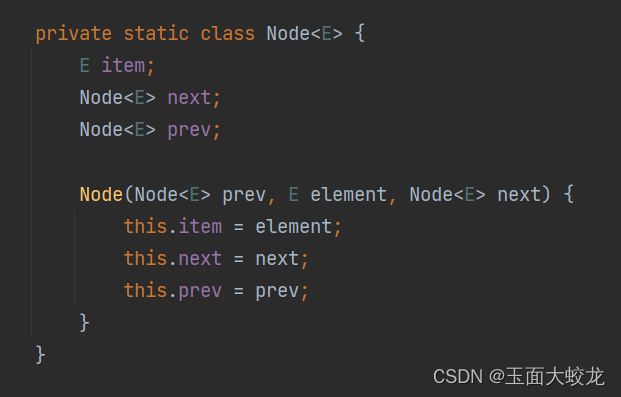
当初始化的时候,会将链表这个节点的值、prev指针和next指针初始化。
二、LinkedList初始化
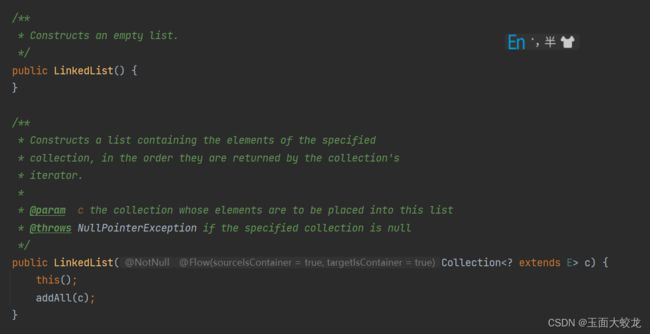
无参构造并没有做什么。有参构造会先调用无参构造,然后调用addAll方法将链表的节点都初始化:
二、增加元素
2.1 add(object)

调用了linkLast方法。就是在尾部添加元素
2.1.1 linkLast
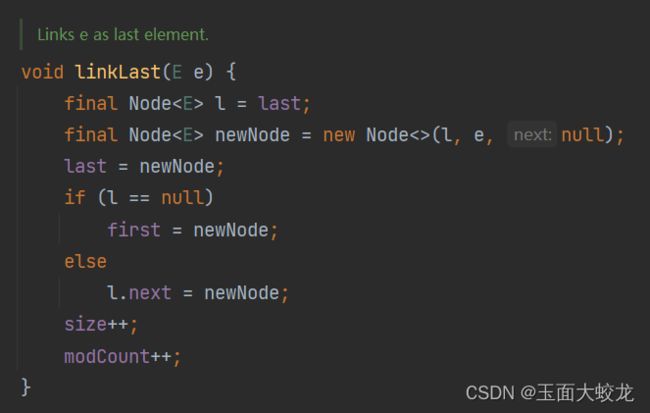
void linkLast(E e) {
final Node l = last; // 获取链表的最后一个节点
final Node newNode = new Node<>(l, e, null); // 创建一个新的节点,并将其设置为链表的最后一个节点
last = newNode; // 将新的节点设置为链表的最后一个节点
if (l == null) // 如果链表为空,则将新节点设置为头节点
first = newNode;
else
l.next = newNode; // 否则将新节点链接到链表的尾部
size++; // 增加链表的元素个数
}
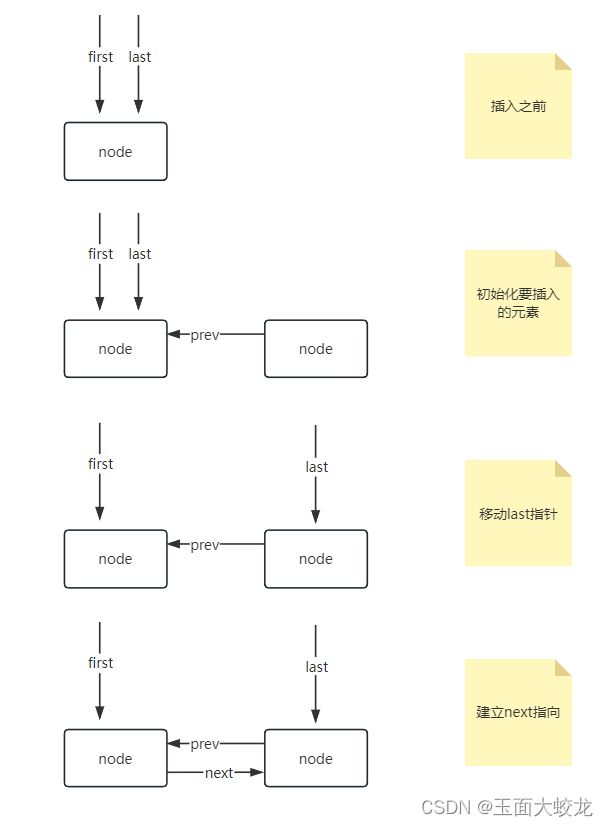
常见的双向链表插入元素的逻辑。不得不说,jdk的代码还是很简洁的。这里画个图示:
当插入空链表时:
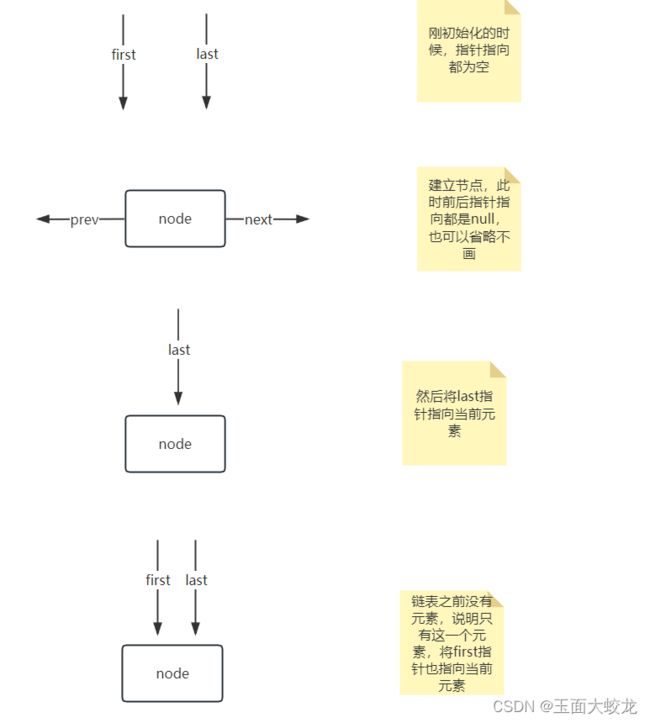
当链表中有一个元素时:
二、删除元素
2.1 remove()

无参的remove调用的是removeFirst(),可以看出是从头开始删的。这个函数放在后面讲。
2.2 remove(object)
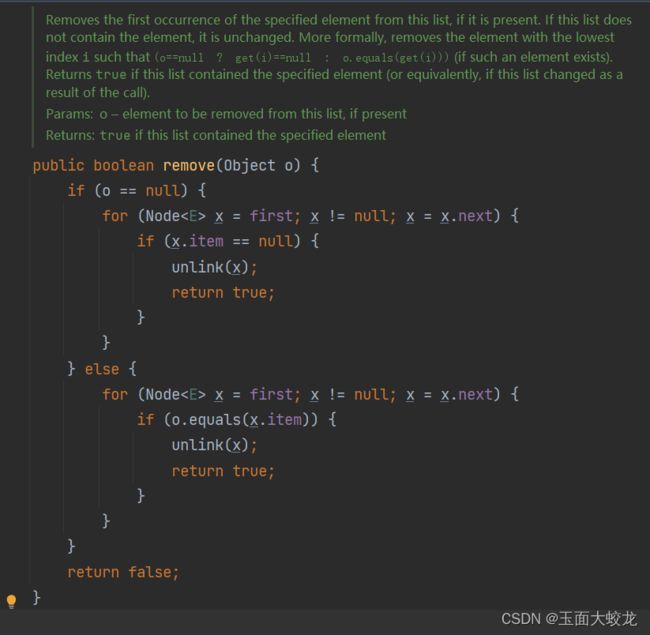
删除指定的元素,这个删除逻辑和ArrayList一样,有兴趣的可以看看我讲解的ArrayList源码:Java ArrayList解密-CSDN博客
public boolean remove(Object o) {
if (o == null) { // 如果要删除的元素为 null
for (Node x = first; x != null; x = x.next) { // 遍历链表
if (x.item == null) { // 如果节点的元素为 null
unlink(x); // 删除节点
return true; // 返回 true 表示删除成功
}
}
} else { // 如果要删除的元素不为 null
for (Node x = first; x != null; x = x.next) { // 遍历链表
if (o.equals(x.item)) { // 如果节点的元素等于要删除的元素
unlink(x); // 删除节点
return true; // 返回 true 表示删除成功
}
}
}
return false; // 如果链表中不包含要删除的元素,则返回 false 表示删除失败
} 2.2.1 unlink()
顾名思义,其实就是取消这个节点和链表的连接关系。他更新要删除的这个节点的prev和next指针,并将当前节点置为null便于GC

E unlink(Node x) {
final E element = x.item; // 获取要删除节点的元素
final Node next = x.next; // 获取要删除节点的下一个节点
final Node prev = x.prev; // 获取要删除节点的上一个节点
if (prev == null) { // 如果要删除节点是第一个节点
first = next; // 将链表的头节点设置为要删除节点的下一个节点
} else {
prev.next = next; // 将要删除节点的上一个节点指向要删除节点的下一个节点
x.prev = null; // 将要删除节点的上一个节点设置为空
}
if (next == null) { // 如果要删除节点是最后一个节点
last = prev; // 将链表的尾节点设置为要删除节点的上一个节点
} else {
next.prev = prev; // 将要删除节点的下一个节点指向要删除节点的上一个节点
x.next = null; // 将要删除节点的下一个节点设置为空
}
x.item = null; // 将要删除节点的元素设置为空
size--; // 减少链表的元素个数
return element; // 返回被删除节点的元素
} 2.3 removeFirst()

先判断链表内有没有元素,然后调用unlinkFist()方法删除
2.3.1 unlinkFist()

private E unlinkFirst(Node f) {
final E element = f.item; // 获取要删除的节点的元素
final Node next = f.next; // 获取要删除的节点的下一个节点
f.item = null; // 将要删除的节点的元素设置为 null
f.next = null; // 将要删除的节点的下一个节点设置为 null
first = next; // 将链表的头节点设置为要删除的节点的下一个节点
if (next == null) // 如果链表只有一个节点
last = null; // 将链表的尾节点设置为 null
else
next.prev = null; // 将要删除节点的下一个节点的前驱设置为 null
size--; // 减少链表的大小
return element; // 返回被删除节点的元素
}
说白了就是把first指针指向的节点去掉,然后将first指针指向下一个节点,再将当前first的prev置为null
2.4 removeLast()
逻辑上和removeFirst()差不多,就不多赘述了。

三、修改
3.1 set(index, object)

public E set(int index, E element) {
checkElementIndex(index); // 检查索引是否超出范围
Node x = node(index); // 获取要替换的节点
E oldVal = x.item; // 获取要替换节点的元素
x.item = element; // 将要替换的节点的元素设置为指定元素
return oldVal; // 返回替换前的元素
} 3.1.1 node方法
找到索引位置的元素。
比较有意思的点是,他会判断索引位置在链表前半段还是后半段。如果在前半段,就从前面遍历链表;如果在后半段,就从后面遍历链表

Node node(int index) {
if (index < (size >> 1)) { // 如果索引在链表的前半部分
Node x = first;
for (int i = 0; i < index; i++) // 从头节点开始向后遍历链表,直到找到指定位置的节点
x = x.next;
return x; // 返回指定位置的节点
} else { // 如果索引在链表的后半部分
Node x = last;
for (int i = size - 1; i > index; i--) // 从尾节点开始向前遍历链表,直到找到指定位置的节点
x = x.prev;
return x; // 返回指定位置的节点
}
} 四、查找元素
4.1 get(index)
查找索引处元素

检查索引后,调用node方法找到元素,node方法在前面讲过了,这里略去。
4.2 indexOf(object)
查找指定元素
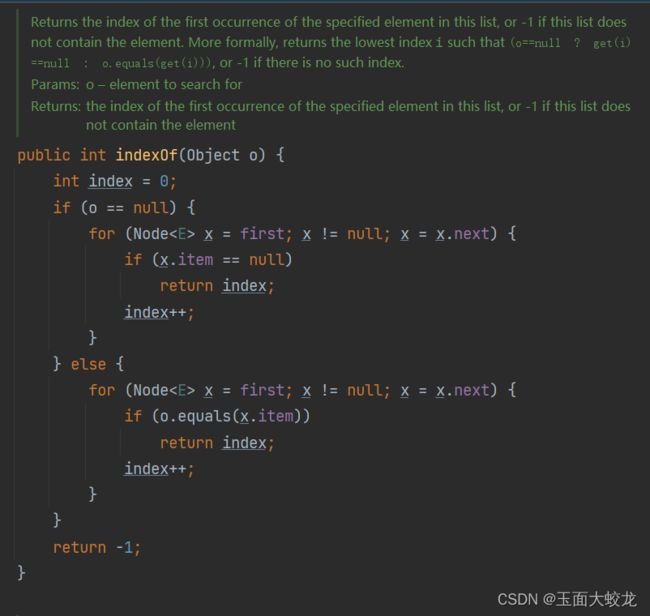
逻辑和ArrayList的indexOf一致,都是直接遍历
五、和ArrayList的比较
敬请期待下一章