(10-2-04)贷款预测模型
请大家关注我,本文章粉丝可见,我会一直更新下去,完整代码进QQ群获取:323140750,大家一起进步、学习。
10.2.4 数据预处理
数据预处理 (Data Preprocessing) 是数据分析和机器学习中的一个重要步骤,旨在准备原始数据以供分析或训练模型使用。数据预处理的目标是清洗、转换和整理数据,以便使其适合分析或模型的输入。
(1)从数据框 df 中删除了名为 "Loan_ID" 的列,其中 axis=1 表示删除列,而不是行。删除 "Loan_ID" 列后,数据框 df 将不再包含这一列的信息。具体实现代码如下所示。
df = df.drop(['Loan_ID'], axis = 1)通常,可以删除不需要用于建模或分析的列,以简化数据集并提高计算效率。
(2)填充数据框 df 中特定列的缺失值,将数据框中的缺失值被替换为相应列的众数,以确保数据在建模前没有缺失值。其中参数inplace=True 表示在原始数据框上进行修改,而不是创建一个新的数据框。具体实现代码如下所示。
df['Gender'].fillna(df['Gender'].mode()[0],inplace=True)
df['Married'].fillna(df['Married'].mode()[0],inplace=True)
df['Dependents'].fillna(df['Dependents'].mode()[0],inplace=True)
df['Self_Employed'].fillna(df['Self_Employed'].mode()[0],inplace=True)
df['Credit_History'].fillna(df['Credit_History'].mode()[0],inplace=True)
df['Loan_Amount_Term'].fillna(df['Loan_Amount_Term'].mode()[0],inplace=True)(3)填充数据框 df 中 "LoanAmount" 列的缺失值。具体来说,它使用 "LoanAmount" 列的均值(平均值)来填充缺失值。这样做的目的是用该列的平均值来代替缺失值,以保持数据的完整性。具体实现代码如下所示。
df['LoanAmount'].fillna(df['LoanAmount'].mean(),inplace=True)其中参数inplace=True表示在原始数据框上进行修改,而不是创建一个新的数据框。这有助于确保在建模前不会有缺失值。
(4)将数据准备成适用于机器学习模型的形式,其中分类变量已被转换为数值形式,不需要的列已被删除,并且列名已被更新,以便进行进一步的分析和建模。具体实现代码如下所示。
df = pd.get_dummies(df)
# 删除列
df = df.drop(['Gender_Female', 'Married_No', 'Education_Not Graduate',
'Self_Employed_No', 'Loan_Status_N'], axis = 1)
# 列重命名
new = {'Gender_Male': 'Gender', 'Married_Yes': 'Married',
'Education_Graduate': 'Education', 'Self_Employed_Yes': 'Self_Employed',
'Loan_Status_Y': 'Loan_Status'}
df.rename(columns=new, inplace=True)对上述代码的具体说明如下:
- 使用 pd.get_dummies(df) 将数据框 df 中的分类变量转换为哑变量(独热编码)。这意味着原始的分类变量将被拆分成多个二元变量,以表示每个可能的类别。这通常用于处理机器学习模型只能处理数值数据的情况。
- 使用 df.drop(...) 删除了不再需要的哑变量列。具体来说,删除了 'Gender_Female', 'Married_No', 'Education_Not Graduate', 'Self_Employed_No', 'Loan_Status_N' 这些列。
- 使用 df.rename(...) 重命名了列名,以便它们更具可读性和一致性。例如,'Gender_Male' 列被重命名为 'Gender','Married_Yes' 列被重命名为 'Married',以此类推。
(5)实现数据清洗工作,目的是删除数据中的异常值,以确保模型的稳健性和准确性。具体实现代码如下所示。
Q1 = df.quantile(0.25)
Q3 = df.quantile(0.75)
IQR = Q3 - Q1
df = df[~((df < (Q1 - 1.5 * IQR)) |(df > (Q3 + 1.5 * IQR))).any(axis=1)]对上述代码的具体说明如下:
- 使用 df.quantile(0.25) 和 df.quantile(0.75) 分别计算了数据框 df 中数值变量的第一四分位数(Q1)和第三四分位数(Q3)。这些分位数用于计算箱线图的上下限。
- 使用 Q3 - Q1 计算了四分位数范围的IQR(四分位数间距),它是箱线图的一个关键参数。
- 使用 ((df < (Q1 - 1.5 * IQR)) |(df > (Q3 + 1.5 * IQR))) 这个条件来识别数据框 df 中哪些数据点被认为是离群值。条件检查是否存在任何小于Q1减去1.5倍IQR或大于Q3加上1.5倍IQR的数据点。
- df[~((df < (Q1 - 1.5 * IQR)) |(df > (Q3 + 1.5 * IQR))).any(axis=1)] 这一行代码通过 any(axis=1) 来选择不包含任何离群值的行,并将结果重新分配给数据框 df,以删除这些离群值。
(6)对数据框 df 中的三个变量进行了平方根变换,这种变换可以有助于改善数据的分布,使其更符合线性模型的假设,从而提高模型的性能。通常,当数据呈现偏斜分布时,对其进行对数、平方根或其他数学变换是一种常见的数据预处理方法。具体实现代码如下所示。
df.ApplicantIncome = np.sqrt(df.ApplicantIncome)
df.CoapplicantIncome = np.sqrt(df.CoapplicantIncome)
df.LoanAmount = np.sqrt(df.LoanAmount)(7)创建了一个包含3个子图的图表,用两行两列进行展示,每个子图包含一种不同的数据分布信息:
- 第一个子图 (axs[0, 0]) 显示了 ApplicantIncome 变量的直方图(histogram),并添加了核密度估计(KDE)曲线。直方图表示了该变量的分布情况,KDE曲线则提供了更平滑的分布估计。这里的数据以绿色表示。
- 第二个子图 (axs[0, 1]) 显示了 CoapplicantIncome 变量的直方图和KDE曲线,这里的数据以天蓝色表示。
- 第三个子图 (axs[1, 0]) 显示了 LoanAmount 变量的直方图和KDE曲线,这里的数据以橙色表示。
具体实现代码如下所示。
sns.set(style="darkgrid")
fig, axs = plt.subplots(2, 2, figsize=(10, 8))
sns.histplot(data=df, x="ApplicantIncome", kde=True, ax=axs[0, 0], color='green')
sns.histplot(data=df, x="CoapplicantIncome", kde=True, ax=axs[0, 1], color='skyblue')
sns.histplot(data=df, x="LoanAmount", kde=True, ax=axs[1, 0], color='orange');执行效果如图10-20所示,这些图表有助于了解每个变量的数据分布情况,包括它们的中心趋势、离散性和偏斜程度。直方图显示了数据的分布形状,而KDE曲线则提供了更平滑的分布估计。这些信息对于进一步的数据分析和建模非常有用。
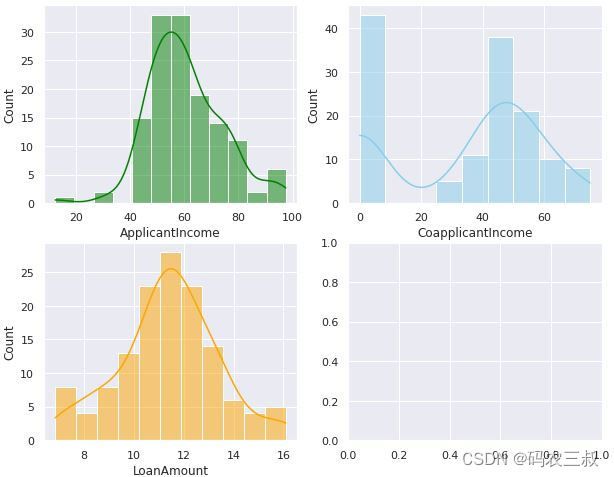
图10-20 每个变量的数据分布情况
(8)编写如下代码创建两个变量,目的是将数据集分为特征集和目标集,以便用于后面的机器学习模型的训练和评估工作。
- X:是一个包含了所有特征(自变量)的数据集,通过从 df 中删除 "Loan_Status" 列而获得。在机器学习中,通常将特征存储在 X 中,用于训练模型。
- y:是目标变量(或因变量),包含了要预测或分类的值,这里是 "Loan_Status" 列的数据。在监督学习中,通常将目标变量存储在 y 中,用于训练模型,并将模型的预测结果与 y 进行比较以评估模型的性能。
X = df.drop(["Loan_Status"], axis=1)
y = df["Loan_Status"](9)为了确保在机器学习模型的训练中,不同类别的样本数量相对平衡,以提高模型的性能和稳定性。通过使用 SMOTE 过采样技术,生成合成的数据样本来增加少数类别的样本数量,以达到平衡的效果。然后,使用sns.countplot可视化展示类别的分布情况。具体实现代码如下所示。
X, y = SMOTE().fit_resample(X, y)
sns.set_theme(style="darkgrid")
ns.countplot(y=y, data=df, palette="coolwarm")
plt.ylabel('Loan Status')
plt.xlabel('Total')
plt.show()执行效果如图10-21所示。
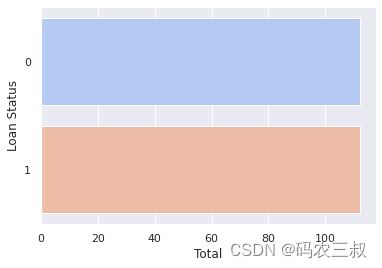
图10-21 类别的分布情况
(10)制作用于训练和评估机器学习模型的数据集,具体实现代码如下所示。
X = MinMaxScaler().fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)对上述代码的具体说明如下:
- 使用 MinMaxScaler 进行特征缩放:MinMaxScaler 是一种特征缩放方法,它将特征缩放到指定的最小值和最大值之间,通常是 [0, 1] 区间。这有助于确保不同特征具有相似的尺度,以提高机器学习模型的性能。
- 使用 fit_transform 方法将特征矩阵 X 标准化。这意味着每个特征都会被线性缩放,使其范围在 [0, 1] 区间内。
- 使用函数train_test_split将数据集分为训练集和测试集。test_size 参数指定了测试集的比例,这里是 20%。random_state 参数用于设置随机数种子,以确保每次运行代码时都得到相同的随机划分,以便结果可复现。
最终,将得到如下所示的4个变量:
- X_train:训练集特征矩阵,已经进行了特征缩放。
- X_test:测试集特征矩阵,已经进行了特征缩放。
- y_train:训练集的目标变量。
- y_test:测试集的目标变量。
这些数据集将用于训练和评估机器学习模型。
未完待续