Flume
Flume
Flume 是一种分布式、可靠且可用的服务 高效收集、聚合和移动大量日志数据。
它具有基于流媒体的简单灵活的架构 数据流。它坚固耐用,容错,可靠性可调机制以及许多故障转移和恢复机制。
它使用允许在线分析的简单可扩展数据模型应用。
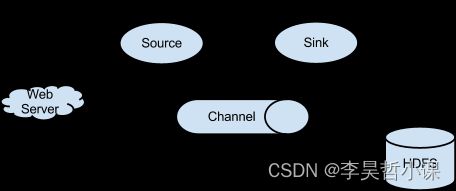
数据流模型

系统要求
- Java 运行时环境 - Java 1.8 或更高版本
- 内存 - 为源、通道或接收器使用的配置提供足够的内存
- 磁盘空间 - 为通道或接收器使用的配置提供足够的磁盘空间
- 目录权限 - 代理使用的目录的读/写权限
创建软件存放目录
mkdir -p /opt/soft
cd /opt/soft
下载安装包
wget https://dlcdn.apache.org/flume/1.11.0/apache-flume-1.11.0-bin.tar.gz
解压安装包并改名
tar -zxvf apache-flume-1.11.0-bin.tar.gz
mv apache-flume-1.11.0-bin flume
配置系统环境变量
vim /etc/profile.d/my_env.sh
export FLUME_HOME=/opt/soft/flume
export PATH=$PATH:$FLUME_HOME/bin
source /etc/profile.d/my_env.sh
printenv
创建配置文件目录
mkdir -p /opt/soft/flume-conf
cd /opt/soft/flume-conf
采集网络数据
编写配置文件
vim netcat.conf
# netcat.conf: 这是一个单节点flume配置
# 定义这个 agent 各个组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置 source 组件 r1
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
# 描述和配置 sink 组件 k1
# logger 控制台打印
a1.sinks.k1.type = logger
# 描述和配置 channel 组件 c1 缓存事件在内存中
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 绑定 source 和 sink 到 channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动 agent
flume-ng agent --conf conf --conf-file /opt/soft/flume-conf/netcat.conf --name a1 -Dflume.root.logger=INFO,console
flume-ng agent -c conf -f /opt/soft/flume-conf/netcat.conf -n a1 -Dflume.root.logger=INFO,console
flume-ng agent --conf conf -conf-file --name a1 netcat.conf
flume-ng agent -c conf -f netcat.conf -n a1
在线安装网络工具 netcat
yum -y install nc
netcat 发送 socket 数据
nc spark01 44444
spooldir
exec source 适用于监控一个实时追加的文件,但不能保证数据不丢失;
spooldir source 能够保证数据不丢失,且能够实现断点续传,但延迟较高,不能实时监控(原文件而非新增文件),监控目录;
taildir source 既能够实现断点续传,又可以保证数据不丢失,还能够进行实时监控,监控一批文件。
编写配置文件
vim spooldir.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/data/region
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://lihaozhe/region
a1.sinks.k1.hdfs.filePrefix = region
a1.sinks.k1.hdfs.fileSuffix = .csv
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.channels.c1.type = file
a1.channels.c1.dataDirs = /opt/cache/data/region/data
a1.channels.c1.checkpointDir = /opt/cache/data/region/checkpoint
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
mkdir -p /opt/cache/data/region/data
mkdir -p /opt/cache/data/region/checkpoint
启动 agent
flume-ng agent -n a1 -c conf -f spooldir.conf
taildir
exec source 适用于监控一个实时追加的文件,但不能保证数据不丢失;
spooldir source 能够保证数据不丢失,且能够实现断点续传,但延迟较高,不能实时监控(原文件而非新增文件),监控目录;
taildir source 既能够实现断点续传,又可以保证数据不丢失,还能够进行实时监控,监控一批文件。
编写配置文件
vim taildir.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /root/data/app.*
a1.sources.r1.positionFile = /root/flume/taildir_positon.json
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = spark01:9092,spark02:9092,spark03:9092
a1.sinks.k1.kafka.topic = lihaozhe
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
mkdir -p /opt/cache/data/region/data
mkdir -p /opt/cache/data/region/checkpoint
启动 agent
flume-ng agent -n a1 -c conf -f taildir.conf
exec
运行web应用实时生成log日志
编写配置文件
vim exec2hdfs.conf
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/logs/info.log
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://lihaozhe/logs/%Y-%m-%d/%H%M/
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.filePrefix = info
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k2.type = logger
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
启动 agent
flume-ng agent -n a1 -c conf -f exec2hdfs.conf
avro
flume-avro-01 spark01
flume-avro-02 spark02
flume-hdfs spark03


flume-avro-01.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/logs/info.log
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = spark03
a1.sinks.k1.port = 44444
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
flume-avro-02.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/logs/info.log
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = spark03
a1.sinks.k1.port = 44444
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
avro-to-hdfs.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://lihaozhe/logs/%Y-%m-%d/%H
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.filePrefix = info
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动 agent
flume-ng agent -n a1 -c conf -f avro-to-hdfs.conf
flume-ng agent -n a1 -c conf -f flume-avro-01.conf
flume-ng agent -n a1 -c conf -f flume-avro-02.conf
interceptor
编写配置文件
vim interceptor.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/data/flume
a1.sources.r1.interceptors = i1 i2 i3
a1.sources.r1.interceptors.i1.type = search_replace
a1.sources.r1.interceptors.i1.searchPattern = "type":"video_info"
a1.sources.r1.interceptors.i1.replaceString = "type":"videoInfo"
a1.sources.r1.interceptors.i2.type = search_replace
a1.sources.r1.interceptors.i2.searchPattern = "type":"user_info"
a1.sources.r1.interceptors.i2.replaceString = "type":"userInfo"
a1.sources.r1.interceptors.i3.type = search_replace
a1.sources.r1.interceptors.i3.searchPattern = "type":"gift_record"
a1.sources.r1.interceptors.i3.replaceString = "type":"giftRecord"
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://lihaozhe/moreType
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动 agent
flume-ng agent -n a1 -c conf -f interceptor.conf
selector
replicating
编写配置文件
vim replicating.conf
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
a1.sources.r1.selector.type = replicating
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://lihaozhe/replicating01
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.filePrefix = info
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = hdfs://lihaozhe/replicating02
a1.sinks.k2.hdfs.useLocalTimeStamp = true
a1.sinks.k2.hdfs.filePrefix = info
a1.sinks.k2.hdfs.fileSuffix = .log
a1.sinks.k2.hdfs.fileType = DataStream
a1.sinks.k2.hdfs.writeFormat = Text
a1.sinks.k2.hdfs.rollInterval = 3600
a1.sinks.k2.hdfs.rollSize = 134217728
a1.sinks.k2.hdfs.rollCount = 0
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
启动 agent
flume-ng agent -n a1 -c conf -f replicating.conf
multiplexing
编写配置文件
vim multiplexing.conf
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = regex_extractor
a1.sources.r1.interceptors.i1.regex = "region":"(\\w+)"
a1.sources.r1.interceptors.i1.serializers = s1
a1.sources.r1.interceptors.i1.serializers.s1.name = region
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = region
a1.sources.r1.selector.mapping.beijing = c1
a1.sources.r1.selector.default = c2
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://lihaozhe/multiplexing01
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.filePrefix = info
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = hdfs://lihaozhe/multiplexing02
a1.sinks.k2.hdfs.useLocalTimeStamp = true
a1.sinks.k2.hdfs.filePrefix = info
a1.sinks.k2.hdfs.fileSuffix = .log
a1.sinks.k2.hdfs.fileType = DataStream
a1.sinks.k2.hdfs.writeFormat = Text
a1.sinks.k2.hdfs.rollInterval = 3600
a1.sinks.k2.hdfs.rollSize = 134217728
a1.sinks.k2.hdfs.rollCount = 0
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
启动 agent
flume-ng agent -n a1 -c conf -f multiplexing.conf
测试数据
"name":"lhz","gender":1,"region":"jilin"
"name":"lz","gender":0,"region":"beijing"
processor
load_balance
load-balance-01 spark01
load-balance-02 spark02
load_balance spark03
load-balance-01.conf
vim load-balance-01.conf
a1.sources = r1
a1.sinks = k1
a1.sinks = k2
a1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://lihaozhe/load_balance
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.filePrefix = info
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k2.type = logger
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
load-balance-02.conf
vim load-balance-02.conf
a1.sources = r1
a1.sinks = k1
a1.sinks = k2
a1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://lihaozhe/load_balance
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.filePrefix = info
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k2.type = logger
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
load-balance.conf
vim load-balance.conf
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/data/region
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = spark01
a1.sinks.k1.port = 44444
a1.sinks.k1.batch-size = 1
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = spark02
a1.sinks.k2.port = 44444
a1.sinks.k2.batch-size = 1
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector = round_robin
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
启动 agent
flume-ng agent -n a1 -c conf -f load-balance-01.conf
flume-ng agent -n a1 -c conf -f load-balance-02.conf
flume-ng agent -n a1 -c conf -f load-balance.conf
failover
failover-01 spark01
failover-02 spark02
failover spark03
failover-01.conf
vim failover-01.conf
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://lihaozhe/failover
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.filePrefix = info
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
failover-02.conf
vim failover-02.conf
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://lihaozhe/failover
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.filePrefix = info
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
failover.conf
vim failover.conf
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/data
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = spark01
a1.sinks.k1.port = 44444
a1.sinks.k1.batch-size = 1
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = spark02
a1.sinks.k2.port = 44444
a1.sinks.k2.batch-size = 1
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 5
a1.sinkgroups.g1.processor.priority.k2 = 10
a1.sinkgroups.g1.processor.maxpenalty = 10000
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
启动 agent
flume-ng agent -n a1 -c conf -f failover-01.conf
flume-ng agent -n a1 -c conf -f failover-02.conf
flume-ng agent -n a1 -c conf -f failover.conf
e = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = spark01
a1.sinks.k1.port = 44444
a1.sinks.k1.batch-size = 1
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = spark02
a1.sinks.k2.port = 44444
a1.sinks.k2.batch-size = 1
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 5
a1.sinkgroups.g1.processor.priority.k2 = 10
a1.sinkgroups.g1.processor.maxpenalty = 10000
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
##### 启动 agent
```bash
flume-ng agent -n a1 -c conf -f failover-01.conf
flume-ng agent -n a1 -c conf -f failover-02.conf
flume-ng agent -n a1 -c conf -f failover.conf