操作系统--第四章文件管理
第四章、文件管理
一、初识文件管理
1.1. 文件的属性

1.2. 文件内部的数据应该怎样组织起来?

- 记录:是一组相关数据项的集合
- 所谓的“目录”其实就是找熟悉的“文件夹”
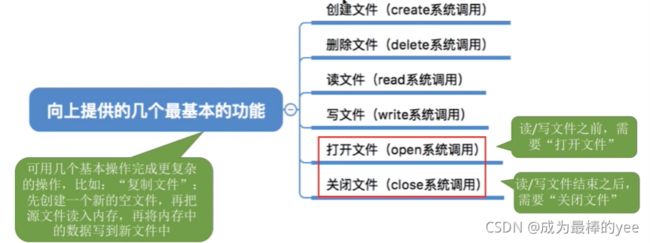
1.3.操作系统应该向上提供哪些功能?
1.4. 从上往下看,文件应如何存放在外存?—“文件的物理结构回答的这个问题”
- 与内存一样,外存也是由一个个存储单元组成的,每个存储单元可以存储一定量的数据(如1B)。
-
每个存储单元对应一个物理地址 - 内存分为“内存块”,外存会分为一个个“块/磁盘块/物理块”。
- 每个磁盘块的大小是相等的,每块一般包含2的整数幂个地址(如本例中,一块包含210个地址,即1KB)。
- 文件的逻辑地址也可以分为(逻辑块号,块内地址)
- 操作系统同样将逻辑地址转换为外存的物理地址(物理块号,块内地址)的形式。
-
块内地址的位数取决于磁盘块的大小
二、文件的逻辑结构
2.1.文件的逻辑结构与物理结构
逻辑结构:在用户看来,文件内部的数据应该是如何组织起来的;
物理结构:在操作系统看来,文件的数据是如何存放到外存中的。
有结构文件+无结构文件


2.2. 顺序文件:文件中的记录一个接一个地顺序排列(逻辑上),记录可定长的或可变长:
各个记录在物理上可以顺序存储(相当于顺序表)或链式存储(相当于链表)。

缺点:增/删记录比较困难
2.3. 索引文件:索引表本身是定长记录的顺序文件。因此可以快速找到第i个记录对应的索引项。
可将关键字作为索引号内容,若按关键字顺序排列,则还可以支持按照关键字折半查找。
每当要增加/删除一个记录时,需要对索引表进行修改。
====》每个记录对应一个索引表项
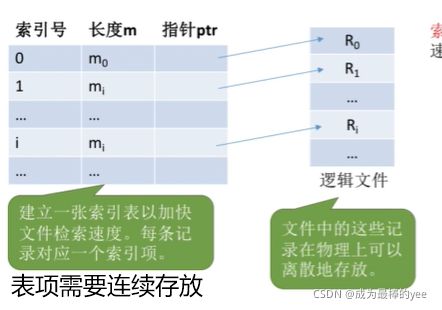
优点:检索速度快,可以用不同的数据项建立多个索引表
2.4. 索引顺序文件:对记录进行分组,索引顺序文件的索引项不需要按关键字顺序排列,这样可以极大地方便新表项的插入
====》一组记录对应一个索引表项,不是每个记录对应一个索引表项
优点:为了进一步提高检索效率,可以为顺序文件建立多级索引表。

三、文件目录

目录本身就是一种有结构文件,由一条条记录组成。
每条记录对应一个在该放在该目录下的文件
3.1.文件控制块~~FCB
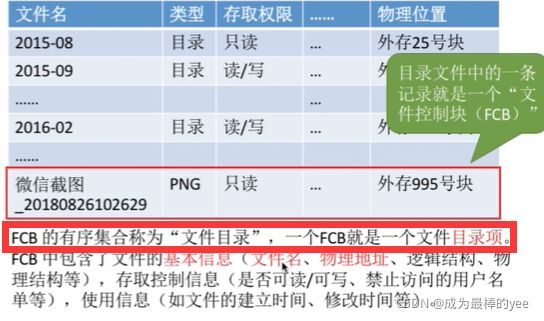
FCB实现了文件名和文件之间的映射。使用户(用户程序)可以实现“按名存取”
FCB对目录的操作:
3.2. 目录结构
3.2.1 单级目录结构==》实现“按名存取”
系统中只有一张目录表
不允许文件重名
缺点:单级目录结构不适用于多用户操作系统。
3.2.2 两级目录结构==》主文件目录+用户文件目录
主文件目录记录用户名及相应用户文件目录的存放位置
用户文件目录由该用户的文件FCB组成
允许不同用户的文件重名。
文件名虽然相同,但是对应的其实是不同的文件
缺点:两级目录结构缺乏灵活性,用户不能对自己的文件分类
优点:两级目录结构允许不文件重名,可以在目录上实现实现访问限制(检查此时登录的用户名是否匹配)
3.2.3 多级目录结构==》树形目录结构
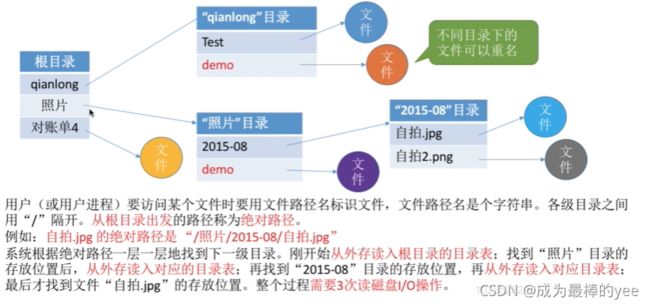
可设置一个当前目录==》相对路径
引入“当前目录”和“相对路径”后,磁盘l/oO的次数减少了。这就提升了访问文件的效率。
优点:树形目录结构可以很方便地对文件进行分类,层次结构清晰,也能够更有效地进行文件的管理和保护。
缺点:树形结构不便于实现文件的共享。为此,提出了“无环图目录结构”。
3.2.4无环图目录结构
优点:可以用不同的文件名指向同一个文件,甚至可以指向同一个目录(共享同一目录下的所有内容)。
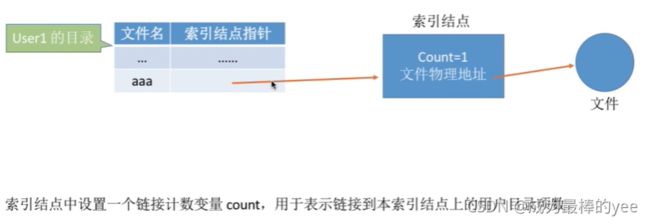
需要为每个共享结点设置一个共享计数器,用于记录此时有多少个地方共享该结点。
用户提出删除结点的请求时,只是删除该用户的FCB、并使共享计数器减1,并不会直接删除共享结点。只有共享计数器减为0时,才删除结点。
注意::共享文件不同于复制文件。在共享文件中,由于各用户指向的是同一个文件,因此只要其中一个用户修改了文件数据,那么所有用户都可以看到文件数据的变化。
3.3.索引节点==》FCB的改进==》让FCB瘦身
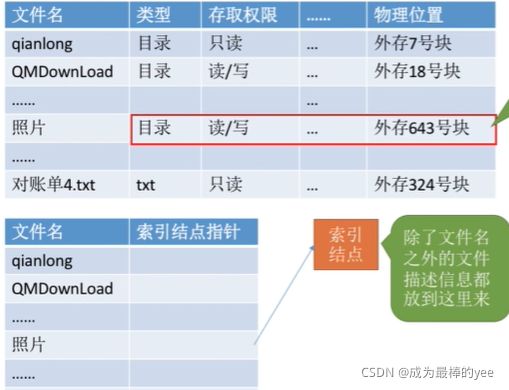
索引结点(包含除了文件名之外的文件描述信息)

优点:大大提升了文件检索速度
四、文件保护:保护文件安全

4.1.口令保护:一般存放在文件对应的FCB或索引结点中。
用户访问文件前需要先输入“口令”,操作系统会将用户提供的口令与FCB中存储的口令进行对比,
如果正确,则允许该用户访问文件
优点:保存口令的空间开销不多,验证口令的时间开销也很小。
缺点:正确的“口令”存放在系统内部,不够安全。
4.2.加密保护:使用某个“密码”对文件进行加密,在访问文件时需要提供正确的“密码”才能对文件进行正确的解密。
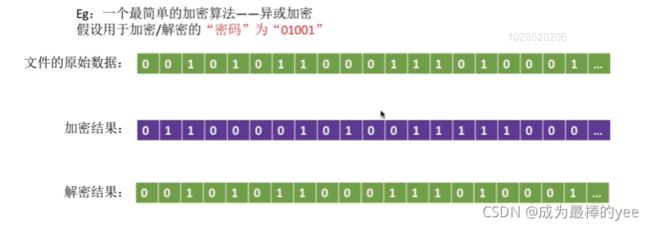
优点:保密性强,不需要在系统中存储“密码”
缺点:编码/译码,或者说加密/解密要花费一定时间。
4.3.访问控制
在每个文件的FCB(或索引结点)中增加一个访问控制列表(ACL),该表中记录了各个用户可以对该文件执行哪些操作。

精简的访问列表: 以“组”为单位,标记各“组”用户可以对文件执行哪些操作。
如:分为系统管理员、文件主、文件主的伙伴、其他用户几个分组。

优点:实现灵活
五、文件共享
5.1基于索引节点的共享方式~~硬链接

共享:只有一份文件,一个人修改了,剩下的用户都可以看到数据变化
复制:很多很多文件,一个人修改文件了, 其他文件不会有影响

删除:

5.2基于符号链的共享方式~~软链接

user1和user2使用硬链接共享文件1,user想共享文件1并且采用软链接的方式
就先用link建立一个文件2====》相当于Windows的 快捷方式
![]()
删除:
文件1已经删除,但是文件2依然存在,通过路径找不到文件2,就是找不到原来的路径了
六、文件的物理结构==》文件分配方式
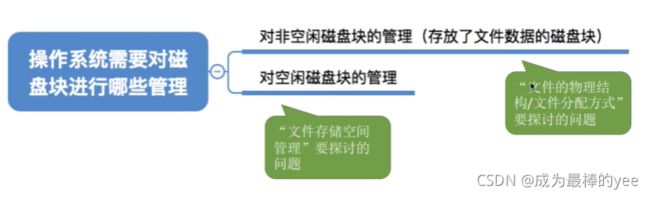
文件时如何存放在外存中的?===》文件的物理结构(文件分配方式)

文件快+磁盘块

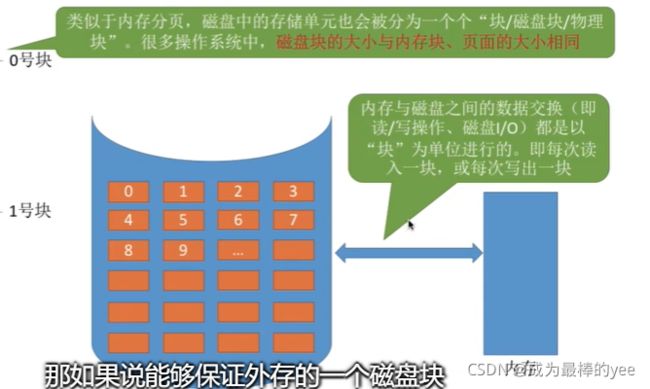
内存中:进程的逻辑地址空间被分为一个一个页面
=====》(页号,页内地址)
外存中:文件的逻辑地址空间被分为一个一个文件“块”
=====》(逻辑块号,块内地址)
❤❤主要问题:怎么把逻辑地址映射为物理快号
6.1文件分配方式–连续分配
操作系统为文件分配存储空间都是以块为单位的
-
连续分配方式要求每个文件在磁盘上占有一组连续的块。
-
逻辑止相邻的块===》 物理上也必须楫邻也必须是占用一组连续的块
-
(逻辑块号,块内地址)→(物理块号,块内地址)。只需转换块号就行,块内地址保持不变
-


-
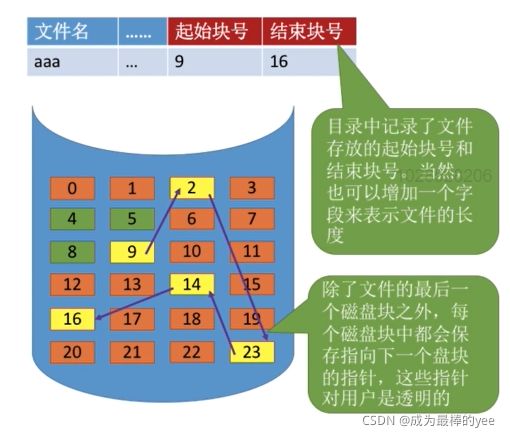
用户给出要访问的逻辑块号,操作系统找到该文件对应的目录项(FCB)
· 物理块号=起始块号+逻辑块号访问“aaa”:逻辑块号2+起始块号4=物理块号6
优点:
- 作业访问磁盘时需要的寻道时间和寻道数最小
- 要检查用户提供的逻辑块号是否合法(逻辑块号≥长度就不合法)
- 可以直接算出逻辑块号对应的物理块号, 连续分配支持顺序访问和直接访问(即随机访问)
- 连续分配的文件在顺序读、写的时候速度最快
缺点:
- 不方便文件拓展;存储空间利用率低,会产生磁盘碎片
6.2.1文件分配方式–链接分配==隐式分配
=== 》链接分配,默认为隐式链接
- 用户给出要访问的逻辑块号i,操作系统找到该文件对应的目录项(FCB)
从目录项中找到起始块号(即0号块),将0号逻辑块读入内存
由此知道1号逻辑块存放的物理块号,于是读入1号逻辑块,
再找到2号逻辑块的存放位置…以此类推。
读入i号逻辑块,总共需要i+1次磁盘I/o。
优点:
- 方便扩展文件:随便找到一个空闲裁判快,挂到磁盘块链尾,并且修改文件的FCB就好
- 所有的空闲磁盘块都会被利用,不会有碎片问题,外存的利用率高
缺点:
- 采用链式分配(隐式链接)方式的文牛,只支持顺序访问,不支持随机访问,查找效率低。
- 指向下一个盘块的指针需要耗费少量的存储空间。
6.2.2文件分配方式–链接分配==显式分配:建立FAT
把用于链接文件各物理块的指针显式地存放在一张表中。即文件分配表(FAT,File Allocation Table)
假设某个新创建的文件“aaa”依次存放在磁盘块2→>5→>0→>1

注意:
1. 一个磁盘仅设置一张FAT。开机时,将FAT读入内存,并常驻内存
2. FAT的各个表项在物理上连续存储,且每一个表项长度相同,因此“物理块号”字段可以是隐含的。
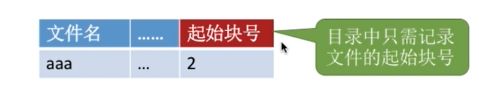
- 用户给出要访问的逻辑块号i,操作系统找到该文件对应的目录项( FCB)
从目录项中找到起始块号~~~aaa的起始块号是2,>0,查询FAT,就是2–5--0–1
若i>o,则查询内存中的文件分配表FAT,往后找到i号逻辑块对应的物理块号。
逻辑块号转换成物理块号的过程不需要读磁盘操作。
优点:
1. 采用链式分配(显式链接)方式的文件,支持顺序访问,也支持随机访问(想访问i号逻辑块时,并不需要依次访问之前的0~i-1号逻辑块)
2. 由于块号转换的过程不需要访问磁盘,因此相比于隐式链接来说,访问速度快很多。
缺点:
1. 文件分配表需要占用一定的存储空间
6.3文件分配方式–索引分配:建立索引表==允许文件离散分配在磁盘里
索引表中记录了文件的各个逻辑块对应的物理块
(索引表的功能类似于内存管理中的页表――建立逻辑页面到物理页之间的映射关系)。
索引表存放的磁盘块称为索引块。文件数据存放的磁盘块称为数据块。
假设某个新创建的文件“aaa”的数据依次存放在磁盘块2---->5----->13---- >9

注意:
1. 一个文件对应一张索引表。
2.可以用固定的长度表示物理块号(如:假设磁盘总容量为1TB=240B,磁盘块大小为1KB,则共有230个磁盘块,则可用4B表示磁盘块号)
索引表中的“逻辑块号”可以是隐含的。
- 用户给出要访问的逻辑块号i,操作系统找到该文件对应的目录项( FCB)
- 从目录项中可知索引表存放位置,将索引表从外存读入内存,并查找索引表即可只i号逻辑块在外存中的存放位置。
优点:
1. 索引分配方式可以支持随机访问。
2. 文件拓展也很容易实现(只需要给文件分配一个空闲块,并增加一个索引表项即可)
缺点:
1. 索引表需要占用一定的存储空间
问:若每个磁盘块1KB,一个索引表项4B,则一个磁盘块只能存放256个索引项。
如果一个文件的大小超过了256块,那么一个磁盘块是装不下文件的整张索引表的,如何解决:①链接方案②多层索引 ③混合索引
①链接方案:
若一个文件大小为256256KB=65,536 KB= 64MB,该文件共有256256个块,也就对应256*256个索引项,也就需要256个索引块来存储,这些索引块用链接方案连起来。
缺点:
若想要访问文件的最后一个逻辑块,就必须找到最后一个索引块(第256个索引块),而各个索引块之间是用指针链接起来的,因此必须先顺序地读入前255个索引块。
②多层索引:建立多层索引,相当于多级页表(一层一层的搞下去)

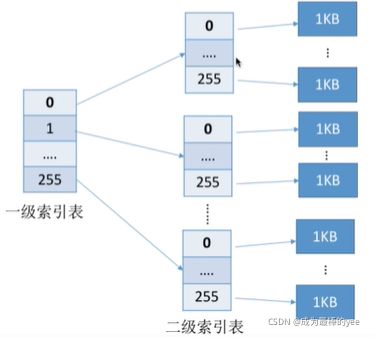
若某文件采用两层索引,则该文件的最大长度可以到2562561KB= 65,536 KB = 64MB
注意:
1. 若采用多层索引,则各层索引表大小不能超过一个磁盘块
可根据 逻辑块号算出应该查找索引表中的哪个表项。
如:要访问1026号逻辑块,则1026/256= 4,1026%256= 2
因此可以先将一级索引表调入内存,查询4号表项,将其对应的 二级索引表调入内存,再查询二级索引表的2号表项即可知道1026号逻辑块存放的磁盘块号了。 访问目标数据块,需要3次磁盘I/O。
若采用 三层索引,则文件的 最大长度为256256256*1KB= 16GB 访问目标数据块,需要4次磁盘I/o
缺点:
即使是小文件,访问一个数据块依然需要K+1次读磁盘。
采用K层索引结构,且顶级索引表未调入内存,则访问一个数据块只需要K+1次读磁盘操作
③混合索引:多种索引分配方式的结合。
例如,一个文件的顶级索引表中既包含直接地址索引(直接指向数据块),又包含一级间接索引(指向单层索引表)、还包含两级间接索引(指向两层索引表)。
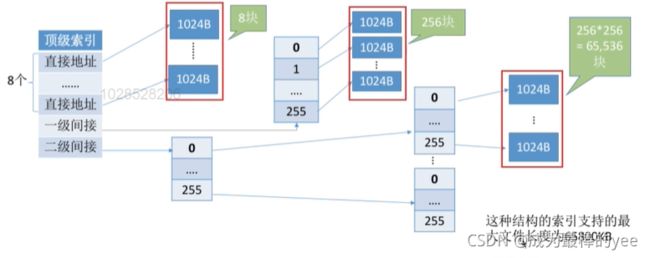
若顶级索引表还没读入内存
访问0--7号逻辑块:两次读磁盘
访问8~263:三次读磁盘
访问264~6579宝:四次读磁盘
优点:
对于小文件,只需较少的读磁盘次数就可以访问目标数据块。(一般计算机中小文件更多)

七、文件的物理结构==》文件分配方式
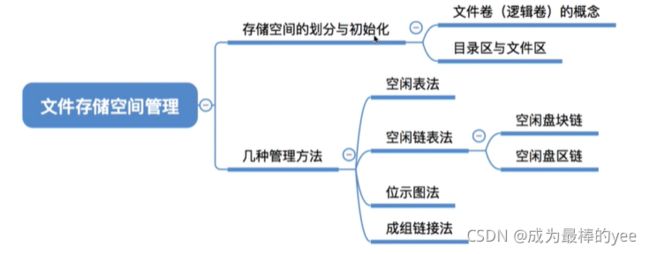
存储空间的划分与初始化
1. 划分:就是把物理磁盘划分成一个个文件卷(逻辑卷,逻辑盘)
2. 初始化:将各个文件卷划分为目录区、文件区
3. 目录区: 主要存放文件目录信息(FCB)、用于磁盘存储空间管理的信息
4. 文件区: 用于存放文件数据
7.1 存储空间管理――空闲表法

如何回收磁盘块:与内存管理中的动态分区分配很类似,当回收某个存储区时需要有四种情况—―
①回收区的前后都没有相邻空闲区;
②回收区的前后都是空闲区;
③回收区前面是空闲区;
④回收区后面是空闲区。
回收时需要注意表项的合并问题。
7.2 存储空间管理――空闲链表法
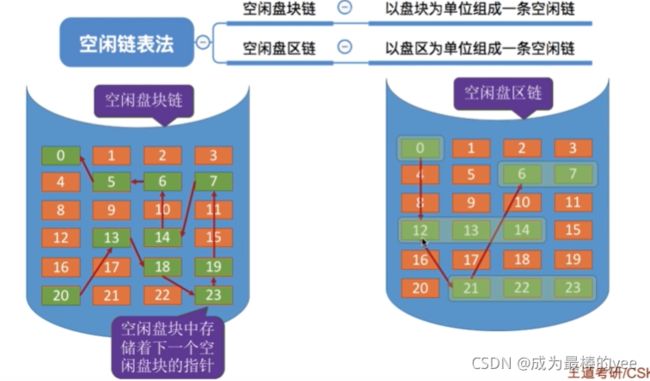
7.2.1空闲盘块链
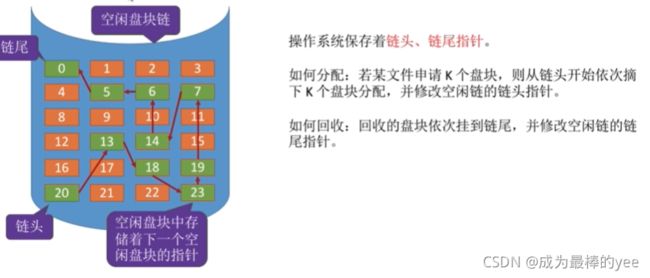
优点:
适用于离散分配的物理结构。
为文件分配多个盘块时可能要重复多次操作
7.2.1空闲盘区链
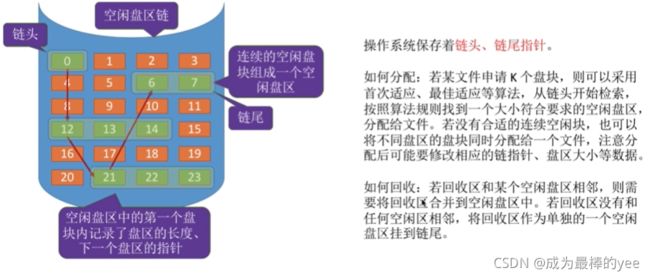
优点:
离散分配、连续分配都适用
为一个文件分配多个盘块时效率更高
7.3 存储空间管理――位示图法
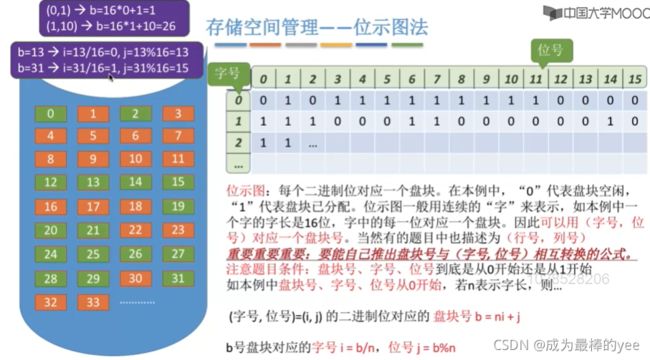
如何分配:
若文件需要K个块,
①顺序扫描位示图,找到K个相邻或不相邻的“O”﹔
②根据字号、位号算出对应的盘块号,将相应盘块分配给文件;
③将相应位设置为“1”。
如何回收:
①根据回收的盘块号计算出对应的字号、位号;
②将相应二进制位设为“o”
优点:
离散分配、连续分配都适用
7.4 存储空间管理――成组链接法
空闲表法、空闲链表法不适用于大型文件系统,因为空闲表或空闲链表可能过大。
所以 采用了成组链接法对磁盘空闲块进行管理。
文件卷的目录区中专门用一个磁盘块作为“超级块”,当系统启动时需要将超级块读入内存。并且要保证内存与外存中的“超级块”数据一致。


如何分配?
Eg :需要1个空闲块
①检查第一个分组的块数是否足够。1<100,因此是足够的。
②分配第一个分组中的1个空闲块,并修改相应数据
Eg:需要100个空闲块
①检查第一个分组的块数是否足够。100=100,是足够的。
②分配第一个分组中的100个空闲块。但是由于300号块内存放了再下一组的信息,因此300号块的数据需要复制到超级块中。

八、文件的基本操作

8.1创建文件
主要参数:
- 所需的外存空间大小(如:一个盘块,即1KB)
- 文件存放路径(“D:/Demo”)
- 文件名(默认为“新建文本文档.txt”)
主要操作:
- 在外存中找到文件所需的空间
- 根据文件存放路径的信息找到该目录对应的目录文件(此处就是D:/Demo目录),在目录中 创建该文件对应的目录项。目录项中包含了文件名、文件在外存中的存放位置等信息。
8.2删除文件
主要参数:
- 文件存放的路径(“D:/Demo”)
- 文件名(默认为“新建文本文档.txt”)
主要操作:
- 根据路径找到相应的目录文件,从目录中 找到文件名对应的目录项。
- 根据该目录项记录的文件在外存的存放位置、件大小等信息, 回收文件占用的磁盘块。
- 从目录表张 删除文件所对应的目录项
8.3打开文件


8.4关闭文件
主要操作:
1.将进程的打开文件表相应表项删除
2.回收分配给该文件的内存空间等资源
3.系统打开文件表的打开计数器count 减1,若count =0,则删除对应表项。
8.5读文件
主要操作:
1. 需要指明是哪个文件(在支持“打开文件”操作的系统中,只需要提供文件在打开文件表中的索引号即可)
2. 需要指明要读入多少数据(如:读入1KB))
3. 指明读入的数据要放在内存中的什么位置。
4. 操作系统在处理read系统调用时,会从读指针指向的外存中,将用户指定大小的数据读入用户指定的内存区域中。
8.6写文件
主要操作:
1. 需要指明是哪一个文件
2. 需要指明要写多少数据
3. 写会外存的数据放在内存的什么位置
4. 操作系统在处理write系统调用时,会从用户指向的内存中,将指定大小的数据歇会写指针指向的外存
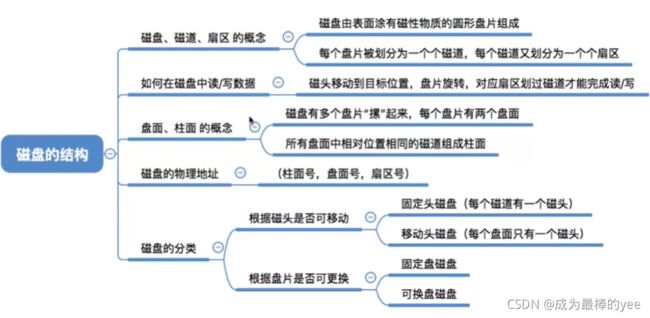
九、磁盘的结构

磁盘:
磁盘的表面由一些磁性物质组成,可以用这些磁性物质来记录二进制数据
磁道::
磁盘的盘面被划分成一个个磁道。这样的一个“圈”就是一个磁道

扇区::一个磁道又被划分成一个个扇区,每个扇区就是一个“磁盘块”。

各个扇区存放的数据量相同(如1KB)
最内侧磁道上的扇区面积最小,因此数据密度最大

如何在磁盘中读写数据?:
需要把“磁头”移动到想要读/写的扇区所在的磁道。
磁头臂带动磁头,带到指定的扇区,然后磁盘转动,让目标扇区从磁头下面划过,就可以完成对扇区的读/写操作。
盘面+柱面

定位一个“磁盘块”:可用(柱面号,盘面号,扇区号):
1.根据“柱面号”移动磁臂,让磁头指向指定柱面;
2.激活指定盘面对应的磁头;
3.磁盘旋转的过程中,指定的扇区会从磁头下面划过,这样就完成了对指定扇区的读/写。
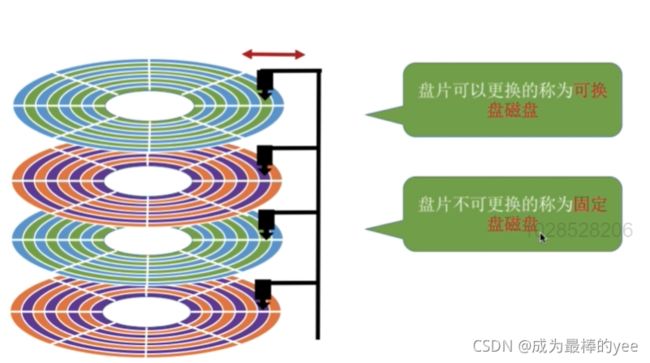
磁盘的分类

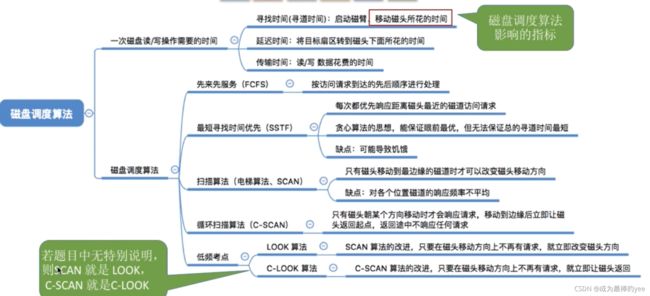
十、磁盘调度算法

10.1 一次磁盘的读/写操作需要的时间
寻找时间(寻道时间)Ts:在读/写数据前,将磁头移动到指定磁道所花的时间。
启动磁头臂是需要时间的。假设耗时为s;
移动磁头也是需要时间的。假设磁头匀速移动,每跨越一个磁道耗时为m,总共需要跨越n条磁道。则: 寻道时间Ts = s + m*n
延迟时间TR:转动磁盘到目标扇区需要的时间;
设磁盘转速为r(单位:转/秒,或转/分),则平均所需的延迟时间TR= (1/2)*(1/r)= 1/2r
1/r就是转一圈需要的时间。找到目标扇区平均需要转半圈,因此再乘以1/2
硬盘的典型转速:为5400转/分,或7200转/分
传输时间T:从目标扇区开头到目标扇区结结束的时间
假设磁盘转速为r,此次读/写的字节数为b,每个磁道上的字节数为N。则:传输时间T=(1/r)*(b/N) = b/(rN)
每个磁道要可存N字节的数据,因此b字节的数据需要b/N个磁道才能存储。而读/写一个磁道所需的时间刚好又是转一圈所需要的时间1/r
总的平均存取时间:Ta=Ts+1/2r+b/(rN)
影响因素:
-
延迟时间和传输时间都与磁盘转速相关,且为线性相关。
而转速是硬件的固有属性,因此操作系统也无法优化延迟时间和传输时间 -
操作系统的磁盘调度算法会直接影响寻道时间
10.2磁盘调度算法
10.2.1先来先服务(FCFS)====》根据磁盘访问的先后顺序

优点:
公平;如果请求访问的磁道比较集中的话,算法性能还算过的去
缺点:
如果有大量进程竞争使用磁盘,请求访问的磁道很分散,则FCFS在性能上很差,寻道时间长。
10.2.2最短寻找时间优先(SSTF)====》优先处理距离当前磁道距离最近的磁道,可以保证当前的寻道时间最短但是不保证整体的时间最短~~~贪心算法(只看到眼前最优,总体未必最好)

优点:
性能比较好,平均寻道时间缩短
缺点:
可能出现“饥饿”现象
产生饥饿的原因在:磁头在一个小区域内来回来去地移动
10.2.3扫描算法(SCAN):SSTF算法====》规定,只有磁头移动到最外侧磁道的时候才能往内移动,移动到最内侧磁道的时候才能往外移动。~~电梯算法。
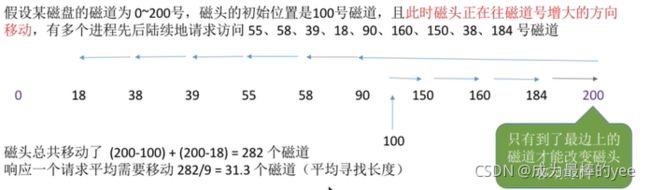
优点:
性能较好,平均寻道时间较短,不会产生饥饿现象
缺点:
1.只有到达最边上的磁道时才能改变磁头移动方向。
事实上,处理了184号磁道的访问请求之后就不需要再往右移动磁头了。
2.SCAN算法对于各个位置磁道的响应频率不平均
(如:假设此时磁头正在往右移动,且刚处理过90号磁道,那么下次处理90号磁道的请求就需要等磁头移动很长一段距离;而响应了184号磁道的请求之后,很快又可以再次响应184号磁道的请求了)
10.2.3.1 Look调度算法
扫描算法Bug2:只有到达最边上的磁道时才能改变磁头移动方向。事实上,处理了184号磁道的访问请求之后就不需要再往右移动磁头了。
LOOK调度算法就是为了解决这个问题,如果在磁头移动方向上已经没有别的请求,就可以立即改变磁头移动方向。(边移动边观察,因此叫LOOK)

10.2.3.2 循环扫描算法(c-SCAN)
扫描算法Bug1:对于各个位置磁道的响应频率不平均,
c-SCAN算法就是为了解决这个问题。规定只有磁头朝某个特定方向移动时才处理磁道访问请求,而返回时直接快速移动至起始端而不处理任何请求。

优点:
比起SCAN来,对于各个位置磁道的响应频率很平均。
缺点:
比起SCAN算法,平均寻道时间更长