Linux的五种IO模型
众所周知,出于对 OS 安全性的考虑,用户进程是不能直接操作 I/O 设备的。必须通过系统调用请求操作系统内核来协助完成 I/O 动作。
下图展示了 Linux I/O 的过程。

操作系统内核收到用户进程发起的请求后,从 I/O 设备读取数据到 kernel buffer 中,再将 buffer 中的数据拷贝到用户进程的地址空间,用户进程获取到数据后返回给客户端。
在 I/O 过程中,对于输入操作通常有两个不同的阶段:
- 等待数据准备好
- 将数据从内核缓冲区拷贝到用户进程
根据这两个阶段等待方式的不同,可以将 Linux I/O 分为 5 种模式:
- blocking I/O,阻塞式 I/O
- nonblocking I/O,非阻塞式 I/O
- I/O multiplexing(select and poll),I/O 多路复用
- signal driven I/O(SIGIO),信号驱动 I/O
- asynchronous I/O(the POSIX aio_functions),异步 I/O
对于 Socket 上的输入操作:
- 第 1 步通常是等待网络上的数据到达。当数据包到达时,它被复制到内核的缓冲区中。
- 第 2 步是从内核缓冲区复制数据到应用程序缓冲区。
下面详细介绍 Linux 中的 5 种 I/O 模式。
1. Blocking I/O
默认情况下,所有的 Socket 都是阻塞式的。下图展示了一个基于 UDP 的网络数据获取流程。
用户进程调用了 recvfrom 系统调用,此后一直处于等待状态,直到数据包到达并被拷贝到应用程序缓冲区,或者发生 error 才返回。整个过程从开始 recvfrom 调用到它返回一直处于阻塞状态。当 recvfrom 调用返回后,应用进程才能处理数据。
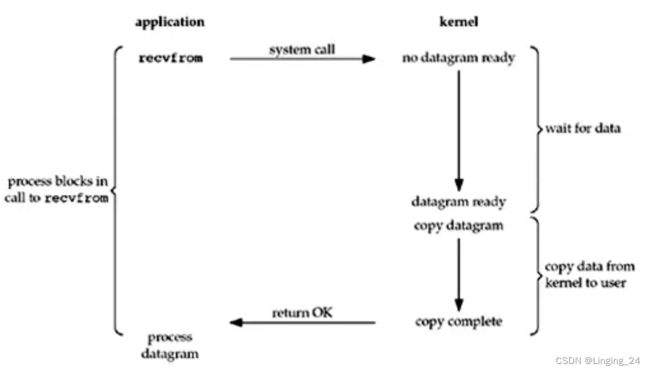
BIO的方式,每次客户端来一个连接,因为BIO是阻塞,所以服务端每次要创建一个线程去处理,主要是防止新的客户端连接被阻塞。
2. Nonblocking I/O
可以设置 Socket 为非阻塞模式。这种设置相当于告诉内核“当 I/O 操作时,如果请求是不可能完成的,不要把进程进入睡眠状态,返回一个错误即可“。下图展示了整个流程:在前三次调用 recvfrom 系统调用时,没有就绪的数据返回,所以内核立即返回 EWOULDBLOCK 错误。第四次调用 recvfrom 时,数据报已经准备好,它被复制到应用程序缓冲区中,然后 recvfrom 成功返回。最后应用进程对数据进行处理。当应用程序在一个非阻塞描述符上循环调用 recvfrom 系统调用时,这种方式也被称为轮询。应用程序不断轮询内核,以查看是否有某些操作准备好了。很明显,这通常会浪费 CPU 时间,但这种模式偶尔也会被使用。通常在专门用于一个功能的系统上使用。

由于BIO的阻塞,当连接数很多时,会创建很多线程,浪费资源,所以进行改进,将处理连接的方式改为非阻塞,出现了NIO,客户端轮询进行系统调用,向内核询问,是否准备好数据。数据未准备好返回一个BWOULDBLOCK标识,不会阻塞。
3. I/O Multiplexing
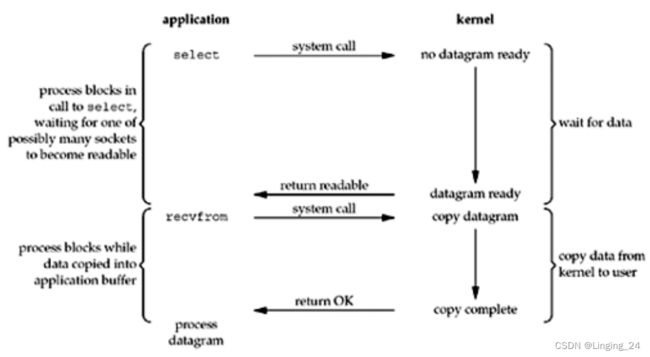
I/O 多路复用通常使用 select 或者 poll 或者 epoll 系统调用。这种方式下的阻塞只是被 select 或者 poll 或者 epoll 系统调用阻塞,而不会阻塞实际的 I/O 系统调用(即数据输入、输出不会被阻塞)。下图展示了整个过程。当调用 select 时,应用进程被阻塞。同时,系统内核会“监视”所有 select 负责的 Socket。只要其中有 1 个 Socket 的数据准备好了,select 调用就返回。然后调用 recvfrom 将数据报复制到应用程序缓冲区,最后返回给用户进程。
乍一看,这种方式和 blocking I/O 相比似乎更差,因为整个过程产生了 2 次系统调用,select 和 recvfrom。但是使用 select 的好处是可以同时等待多个描述符准备好。换句话说可以同时“聆听”多个 Socket 通道,同时处理多个连接。select 的优势不是对于单个连接处理得更快,而是能同时处理更多的连接。这和多线程阻塞式 I/O 有点类似。只不过后者是使用多个线程(每个文件描述符对应一个线程)来处理 I/O,每个线程都可以自由地调用阻塞式系统调用,比如 recvfrom。我们知道线程多了会带来上下文切换的开销,因此未必优于 select 方式。
Linux 内核将所有外部设备都当成一个个文件来操作。我们对文件的读写都通过调用内核提供的系统调用;内核给我们返回一个文件描述符(file descriptor)。而对一个 Socket 的读写也会有相应的描述符,称为 socketfd。应用进程对文件的读写通过对 fd 的读写完成。
由于NIO在内核准备数据阶段,客户端会轮询很多次无用的系统调用去询问内核是否准备好数据,并且每个客户端都会询问内核,都是单个的,为了改进去除不必要的操作,将NIO的主动询问和单个操作改为批量的,等待通知的方式,就是IO多路复用select、poll。客户端的多个连接会被注册到select或者poll中进行监听,当监听到read或write事件,则将内核注册的连接集合全部复制到用户空间,由用户空间遍历判断哪些连接需要处理。
每次select和poll都需要将注册管理的多个client连接从用户空间拷贝到内核,在管理百万连接时,拷贝操作会带来较大资源开销,影响性能,所以出现了epoll。epoll改进就是注册时将连接复制一次到内核,在系统调用时,不拷贝连接,在返回数据时,不拷贝全部连接,而是将就绪链表中的连接准确返回给用户进程。
4. Signal Driven I/O
信号驱动方式就是等数据准备好后,由内核发出 SIGIO 信号通知应用进程。示意图如下:

应用进程通过 sigaction 系统调用建立起 SIGIO 信号处理通道,然后此系统调用就返回,不阻塞。当数据准备好后,内核会产生一个 SIGIO 信号通知到应用进程。此时既可以使用 SIGIO 信号处理器通过 recvfrom 系统调用读取数据,然后通知应用进程数据准备好了,可以处理了;也可以直接通知应用进程读取数据。不管使用何种方式,好处都是应用进程不会阻塞,可以继续执行,只要等待信号通知数据准备好被处理了、数据准备好被读取了。
IO多路复用在等待数据准备时,客户端还是阻塞状态的,而信号驱动,则发起一次系统调用之后就返回,不会阻塞。
5. asynchronous I/O
异步 I/O 是由 POSIX 规范定义的。和信号驱动 I/O 模型的区别是前者内核告诉我们何时可以开始一个 I/O 操作,而后者内核会告诉我们一个 I/O 操作何时完成。示意图如下:

当用户进程发起系统调用后会立刻返回,并把所有的任务都交给内核去完成,不会被阻塞等待 I/O 完成。内核完成之后,只需返回一个信号告诉用户进程已经完成就可以了。
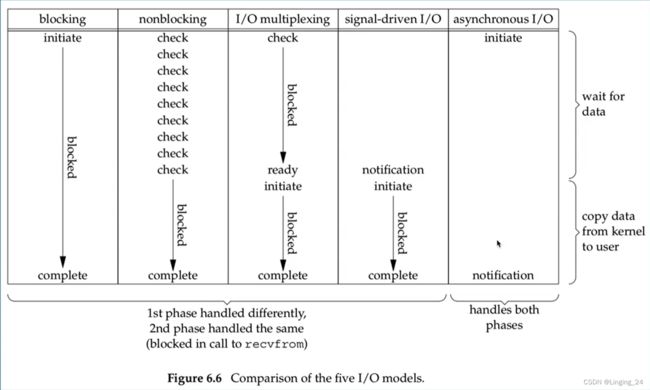
五种 I/O 模式可以从同步、异步,阻塞、非阻塞两个维度来划分:

select、poll、epoll的区别:
select
从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,效率更差。但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个socket,然后不断地调用select读取就绪的socket,即可达到在同一个线程内同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
select的缺点
- 每次调用select,都需要把fd_set集合从用户态拷贝到内核态,如果fd_set集合很大时,那这个开销也很大
- 同时每次调用select都需要在内核遍历传递进来的所有fd_set,如果fd_set集合很大时,那这个开销也很大
- 为了减少数据拷贝带来的性能损坏,内核对被监控的fd_set集合大小做了限制,并且这个是通过宏控制的,大小不可改变(限制为1024)
poll
poll的机制与select类似,与select在本质上没有多大差别,管理多个描述符也是进行轮询,根据描述符的状态进行处理,但是poll没有最大文件描述符数量的限制。也就是说,poll只解决了上面的问题3,并没有解决问题1,2的性能开销问题。
epoll
epoll在Linux2.6内核正式提出,是基于事件驱动的I/O方式,相对于select来说,epoll没有描述符个数限制,使用一个文件描述符管理多个描述符,将用户关心的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。
获取事件的时候,它无须遍历整个被侦听的描述符集,只要遍历那些被内核IO事件异步唤醒而加入Ready队列的描述符集合就行了。
epoll的边缘触发ET和水平触发LT模式的区别:

引用:https://zhuanlan.zhihu.com/p/543661648