深入理解JavaWeb技术内幕之中文编码
为什么要编码
1.计算机中存储信息的最小单元是1个字节,所能表示的字符范围为0~255个。
2.人类要表示的符号太多,无法用1个字节来完全表示。
常见的编码类型
ASCII码
总共128个,用1个字节的低7位表示。0~31是控制字符,32~126是打印字符。
ISO-8859-1
涵盖了大多数西欧语言字符,应用最广泛,单字节编码,能表示256个字符。
GB2312
双字节编码,中文编码字符集,表示六千多个汉字。
GBK
GB2312的扩充版,能表示两万多个汉字,与GB2312向下兼容。
GB18030
单字节,双字节或者四字节都有,兼容GB2312,应用并不广泛。
UTF-16
具体定义了Unicode字符在计算机中的存取方法。用两个字节表示Unicode的转化格式,采用定长的表示方法,即不论什么字符都可以用两个字节表示。是Java的内存字符存储格式。
UTF-8
采用变长的表示方法,每个编码区域有不同的字码长度。不同类型的字符可以由1~6个字节组成。
Java中哪里需要编码
I/O操作中的编码
Reader类是Java I/O 中读取字符的父类,InputStream是读取字节的父类。InputStreamReader负责将读取的字节转换成字符,具体的转换过程由StreamDecoder来做,解码格式由用户指定。
所以涉及I/O操作的时候,一定要注意指定统一的Charset字符集,如果没有指定,将使用操作系统的默认编码,这样在跨环境时,会出问题
内存操作的编码
String s = "这是一段中文编码";
byte[] b = s.getBytes("UTF-8");
String n = new String(b,"UTF-8");Java 编码原理
如果编码这样一句话
“编码 in Java”测试代码如下:
package com.study;
import java.io.UnsupportedEncodingException;
public class test {
private static String str = "编码 in Java";
public static void printHexString(byte[] b) {
for (int i = 0; i < b.length; i++) {
String hex = Integer.toHexString(b[i] & 0xFF);
if (hex.length() == 1) {
hex = '0' + hex;
}
System.out.print(hex.toUpperCase());
}
}
public static void main(String[] args) {
try {
byte[] b = str.getBytes("ISO-8859-1");
String n = new String(b, "ISO-8859-1");
/*测试其他编码格式只要将上面的参数改一下就行**/
printHexString(b);
System.out.println();
System.out.println(n);
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}按照ISO-8859-1编码
ISO-8859-1会将它不认识的字符全部转换为“?”字符,将认识的字符按照单字节编码。如下图:

3F---? 20---空格 其余的每个字母都用两个十六进制数字表示,即一个字节。
按照GB2312编码
如下图: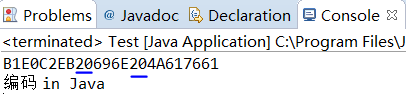
可以看出来每个汉字用了两个字节编码,其余同上。但是GB2312只支持6763个汉字。
按照GBK编码
如图:
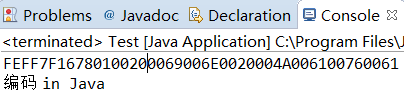
结果与上面一模一样,所以GBK是和GB2312向下兼容。
按照UTF-16编码
将结果与上面的图进行比较,可以看出除了汉字编码,每个编码前面都多了两个00。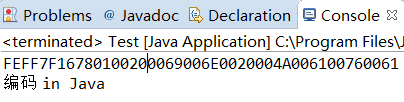
这种编码效率非常高(规则简单嘛),但是要注意不同处理器的大小端问题。
按照UTF-8编码
可以看到,汉字用了三个字节表示,其余字母用一个字节。
格式比较
UTF-16适合在本地编码,不适合在网络之间进行传输,网络传输很容易损坏字节流,一旦损坏难以恢复;与之相比UTF-8更容易传输,因为它对ASCII码单字节传输,所以即使单个字符损坏,也不影响后面的其他字符。
UTF-8是理想的中文编码方式。
Java Web中涉及到的编解码问题
在Java中一个char是16bit,两个字节。所以两个汉字用char存储,会占用4个字节空间。
只要涉及到网络I/O的地方都有可能引起中文乱码。
在Web中常见的就是发起http请求。此时会有三个地方存在编码:URL,Cookie,Parameter.
URL
比如输入下面的一个URL
http://localhost:8080/examples/servlets/servlet/例子?author=编码就以Tomcat为例:
很显然,这是一个GET请求。在PathInfo和QueryString部分都出现了中文。在Firefox浏览器中,PathInfo 是UTF-8编码, QueryString是GBK编码。
而且,URL还有一条规则就是,会将非ASCII码的字符按照某种编码格式编码成16进制数字之后,前面再加上%号。
在Tomcat的安装目录下有一个Conf文件夹,里面有一个配置文件server.xml,打开该文件,如下图所示。

会发现,URI编码是“UTF-8”,如果没有的话,默认为 ISO-8859-1.所以有中文URL时,最好将URIEncoding设置为UTF-8编码。
解析QueryString:
该解码字符集要么是Header中定义的Charset,要么是默认的ISO-8859-1。要使用ContentType中定义的编码,就要设置
所以,为了避免像上面那么麻烦应该尽量避免在URI中使用非ASCII字符。
HTTP Header的编解码
同理,不要在Header中传递非ASCII字符,如果一定要传递,先将这些字符用
org.apache.catalina.util.URLEncoder编码,然后添加到Header中。
POST表单
因为POST表单的参数提交方式与QueryString不同,它是通过HTTP的BODY传递到服务器端的。
页面上单击提交按钮,浏览器首先将根据ContentType的Charset编码格式对在表单中插入的参数进行编码,然后提交到服务器,在服务端,同样也是按照ContentTYpe的字符集进行解码。所以POST表单提交的参数一般不会出问题。
设置字符集编码的方式:
request.setCharacterEncoding(charset);注意:一定要在第一次调用request.getParameter方法之前就对编码进行设置。否则会按照默认的ISO-8859-1进行解析。
HTTP BODY
当用户请求的资源已经成功获取之后,这些内容将通过Response返回给客户端浏览器。这个过程需要先编码再解码。编解码的字符集设置
response.setCharacterEncoding(charset);并且通过Header的Content-Type返回给客户端,浏览器接收到返回的Socket流时将通过Content-Type的charset进行解码。
如果没有相应的设置,则浏览器将按照HTML中的 中的charset进行解码。
JDBC
如果是MySQL,可以通过URL进行设置。
URL:“jdbc:mysql://localhost:3306/DB?useUnicode=true&characterEncoding=GBK”.JS
引入js文件的编码格式与当前页面的编码格式不一样,会发生乱码。
JS中处理URL编码的函数有如下三个:
1.escape()
功能:将ASCII字母,标点符号,数字之外的其他字符转换成Unicode编码值,并且在编码值前加上"%u".
2.encodeURI()
功能:将这个URL中的字符进行UTF-8编码,并且在每个码值前加%。
解码用decodeURI()
3.encodeURIComponent()
功能:除了对少数标点符号,字母,数字不编码之外,对其他任何符号都编码,通常用于将一个URL参数放在另外一个URL中。