textbox如何在输入完成后再进行判断_单招不好使,连招才管用:为Android应用生成高质量测试输入...
从我的一个朋友说起
曾经有一个朋友热爱艺术,经常在PxxxHub等等一系列艺术电影网站上下载观看艺术电影。但是他是一个自私的人,不愿意与别人分享,甚至不愿让自己的女朋友看到自己手机上存储的艺术电影。所以每次与女朋友见面前,他都会用一个文件管理应用把保存有艺术电影的文件夹隐藏起来。然而有一天晚上,他翻了车:女朋友在用他的手机整理照片的时候,为了看得更清楚一些,在这个文件管理应用的设置界面打开了新推出的夜间模式。神(惊)奇(悚)的事情发生了,已经隐藏起来的艺术电影文件夹居然在夜间模式下重新出现在了屏幕上,而这位朋友的女朋友惊怒于他居然藏私,让他度过了一个痛苦的周末。

这是怎么回事?这位朋友事后愤怒地找应用的开发者问罪,而在想起开心的事情之后,开发者经过一番排查也找到了原因:隐藏文件夹的功能在应用内通过修改其保存在数据库内的信息进行标志,并在之后绘制文件列表时,通过读取这些标志信息决定是否要绘制这一文件夹。在日间模式中,这些逻辑没有问题。然而在新推出的夜间模式中,工程师居然忘了在绘制列表时要先读一下标志位,于是gg。
至于为什么上线前居然没有检测到这个bug,测试小哥也是一肚子苦水:现在竞争这么激烈,平均每天上线3.14个版本,平均每个版本给我的测试时间也就几个小时,我哪有时间写那么多测试输入?我也试过用比如Monkey啥的自动工具生成,测测应用的单个功能还行,但是这个bug要先执行应用隐藏文件夹的功能,然后去设置界面打开夜间模式,再回到文件夹列表,几个功能离得巨远。这些自动工具要么用随机或者简单的启发式策略生成输入,测测局部功能还行,要生成这么长且有意义的输入门也没有;要么就用特别慢的系统策略详细分析慢慢生成,等它在我们这个规模的应用上跑完,我早就换了第三家公司了。所以这个真的没办法,你们杀了我祭天吧。

为复杂功能生成测试输入
上面例子这样的问题在智能手机应用上并不少见,应用快速迭代,测试资源受限,测试输入自动生成技术要么无法生成探索应用深层状态的输入以测试复杂功能,要么效率低下无法应用在大规模应用上,而人工测试输入生成虽然质量有保证,但是耗费人力时间,也难以保证测试充分。如果有一种技术,能够自动为应用的复杂功能生成测试输入,就太好了。
那么,有什么办法呢?其实可以发现,测试这些复杂的功能所需要的长且有意义的测试输入,其包含的事件序列往往不是密不可分的。就像On the naturalness of software[1]这篇文章所描述的,所有软件包括Android应用都是由人类编写,为人类编写,之后由人类使用的。为了减少开发复杂度,也为了提高用户体验,一个Android应用一般会包含很多简单的功能,用户可以通过很短的一段操作就能够执行这些功能。我们称这样执行了应用简单功能的事件序列为用例。而复杂的功能,用户则通过按照特定顺序执行简单功能来完成。如上面提到的存在bug的复杂功能,要执行它,其实就需要依次执行三个简单的功能:(1)先执行应用的隐藏文件夹功能,(2)执行应用的夜间模式功能,最后(3)执行应用的文件列表浏览功能。执行这三个功能的事件序列都很短,而组合起来,就行成了我们需要的长且有意义的测试输入。
这就为复杂功能生成测试输入提供了一个思路。由于执行应用简单功能的用例都很短,不管是自动方法还是人工手段,生成的事件序列中一般都会包含它们,只是支零破碎地隐藏在事件序列的各个片段中。那么,我们只需要提取出这些用例,再按特定的顺序把他们拼接起来,就可以快速得到所需要的长且有意义的测试输入了。
要真正实现这个方法,有两个关键点需要解决。第一是如何确定哪些自动或人工生成的事件序列片段是一个用例。用例执行了应用的简单功能,而确定一段事件序列是否满足这一条件需要对应用的语义有一定的理解。第二是当我们得到用例之后,如何进行拼接。显而易见的,只有选取特定的用例按照特定的顺序进行拼接,才能执行应用的复杂功能。如上面的例子,如果我们先浏览文件列表,再打开夜间模式,就无法触发bug了。
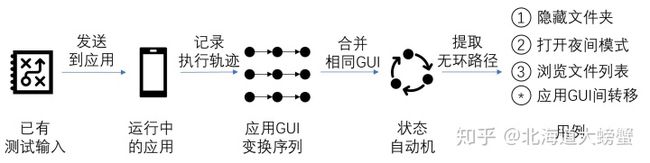
针对这两个关键点,我们提出一个循环的两阶段方法框架ComboDroid[2],分为用例提取阶段和用例组合阶段。下图展示了我们方法的总体流程。

用例提取阶段
在这一阶段,我们试图从已有的测试输入中提取出用例。我们发现,为了保证用户体验,Android应用中执行一个简单功能的事件序列即用例一般都很短,而人类又可以很快地理解应用的语义,因而不管是直接人工生成这些用例,还是从已有的测试输入中标记出这些用例,都是比较容易的。因而,我们提供接口让人类测试者帮助我们完成这一工作。人类测试者既可以直接生成一个个的用例,也可以在我们使用自动工具生成的测试输入中标记出可视为用例的事件序列片段,由我们的工具提取出来。这样,就可以借助很少的人力高效获得高质量的用例。

通过上述半自动方式,我们可以借助人类测试者的力量获得用例。那如果人类测试者不想或无法提供帮助呢(比如要去哄吵架的女朋友)?我们的方法同时也包含了一个全自动的算法,从已有的测试输入中自动提取用例。首先我们发现,为了保证用户体验,一般而言应用在执行完一个功能后,会到达一个稳定的状态,比如应用的GUI在不接收到新的事件前不会再自发地变化。而这时,用户可以输入新的事件开始执行应用的另一个功能。
这样的应用稳定状态是用例之间自然的分界线。因而,我们只需要发送已有的测试输入到应用,观察哪些事件序列片段前后应用是处于稳定状态的(可以通过应用一段时间没有GUI的改变判断),那么这些片段都可以被视为潜在的用例。我们可以都提取出来,保证没有遗漏。
这样就结束了吗?还没有。有些事件序列片段自身并不是一个用例,但与另一段片段拼接起来,就是一个用例了。我们也需要找到这样的片段,并进行相应拼接,以保证没有遗漏隐藏的用例。我们发现两个片段a和b,只有当a结束的GUI正是b开始的GUI时才可以拼接,否则b的起始事件无法找到接收它的GUI元素(如要点击按钮不存在了)。所以,我们观测测试输入中每个事件发送前后的GUI,将相同的GUI加入到同一个集合,把每个集合视为一个抽象状态,而每个事件作为对应抽象状态间的导致状态转移的边,这样就得到了一个应用的抽象状态自动机。这个自动机中的每条无环的状态转移路径,都可以被视作潜在的用例。我们把它们都提取出来,就得到了所有可能的用例。
在构建状态机时,还有一些细节需要考虑,如如何对应用的GUI进行抽象。应用的许多GUI实际上非常相似,只有微小的差别,如只有一段文字不同,或显示的时间不同。这些GUI都可以接收相同的事件,因而应当被放入同一个集合。因而在这一步,我们需要对GUI进行抽象,忽略一些细节(如所有的文字差异)。如何选取合适的抽象标准,是一个仍在研究的问题。如果抽象的太多,许多不应当放到一起的GUI就被放到一起了(然后许多事件就找不到接收的GUI元素了);如果不够抽象,许多应当放到一起的GUI就被分开了,导致丢失了很多用例。我们采取的是已有工作中做的较好的AMOLA[3]工具提供的抽象标准。另外,为了高效生成这一自动机,我们借鉴了SwiftHand[4]工具的生成方法,感兴趣的同学可以自行查看。
这一阶段,我们假定已经获得了已有的测试输入。这些测试输入既可以由人工生成,也可以通过已有的自动技术生成。为了我们方法的完整性,我们的方法附带了一个类似与A3E[5]的工具,通过深度优先探索应用GUI的方式,自动为应用生成测试输入。
用例组合阶段

有了执行应用简单功能的用例,我们就可以把他们进行拼接生成能够执行应用复杂功能的测试输入了。如前文所述,我们不能随便拼接,不然生成的测试输入只是执行了几个毫不相关的功能,无法执行应用负责的功能。那么我们如何拼接才能保证生成真正长且有意义的测试输入呢?显然,当几个用例拼接后能够执行应用的复杂功能时,这几个用例执行的简单功能一定存在关联。如一开始的例子中,“隐藏文件”功能的执行会影响之后“文件列表浏览”功能的执行(影响显示哪些文件)。同样,“开启夜间模式”功能也会影响“文件列表浏览”功能。
通过这个例子,我们可以发现,要生成执行应用复杂功能的测试输入,需要我们用来组合的用例执行互相影响的功能,同时被影响的功能应当后于影响它的功能执行。那么,我们怎么判断功能是否会互相影响呢?执行功能都是通过执行应用代码实现的,那么如果两个功能对应执行的代码存在数据关联,那么有很大概率是会互相影响的。因而,我们需要发送每个用例到应用,记录其相应的共享数据访问如数据库读写等。然后,我们分析这些访问,找到访问了同一共享的数据的用例。如果一个用例a的执行写访问了一个共享数据,而另一个用例b的执行读访问了它,我们就可以判断a的执行会影响b的执行,即b依赖于a。我们称这样的关系为用例间的依赖关系。
当有了这些依赖关系之后,我们就可以找到多对具有依赖关系的用例,将其排列为一个序列,尽量保证被依赖的用例先去依赖其的用例。这样,我们就获得了一条长且有意义的测试输入的骨干。这里,我们强调尽量是因为用例间的依赖关系可能存在环,因为我们无法保证所有的依赖关系都可以被满足。
通过上述操作,我们已经得到了一条事件序列。这样就可以了吗?还不够。如上一节所述,两个事件序列片段进行拼接时,需要保证前一序列结束的GUI与前一序列开始的GUI足够相似,才能最大可能保证后一序列能够继续有意义地执行。我们称这样的关系为用例间对齐关系。这样的关系同样可以通过观测用例执行轨迹获得。因而,我们还需要在得到的事件序列中的用例间插入额外的用例,以保证每一对相邻的用例都可以满足这样的对齐关系。我们依次在每一对用例间,通过深度优先搜索的方式,搜索这样的用例序列。这样,我们就得到了执行应用复杂功能的,长且有意义的测试输入了。
两阶段的迭代循环
当我们生成了能够执行应用复杂功能的测试输入后,就可以将这些输入发送给应用进行测试了。但在测试过程中,可能会有这样的事情发生:由于我们的测试输入执行了应用之前未执行的功能,应用进入了一个全新的前所未探索的状态(一般表征为前所未探索的GUI界面),这个状态下应用有很多未被测试过的功能可以执行,但由于没有没探索过,因而没有执行这些功能的用例。为了应为这样的情况,我们的两阶段方法可以交替往复:当我们遇到这样的应用状态后,就返回用例提取阶段,获得关于新的应用状态的测试输入,并进一步提取新的用例。通过遮掩的迭代循环,逐步提升测试的充分性。
实验结果
我们一共选取了17个Android应用作为测试用例,包括已有技术反复测试过的应用和规模较大的开源应用。由于我们的用例既可以自动提取,也可以人工提取,我们分别实现了两个版本的工具,alpha全自动版本和beta半自动版本,分别为这些应用生成测试输入。实验结果表明,我们的alpha全自动版本能够比现有的顶尖自动测试输入生成技术APE[6]生成更好的测试输入,达到更高的指令覆盖率。另外,我们的工具还发现了4个前所未见的bug。而我们的beta半自动版本工具,人工加工具约一天半的工作时间,就能够达到纯人工约三天工作时间的代码覆盖率,且远高于自动工具的覆盖率。这些数据说明,我们的工具能够高效地生成更好的测试输入。
论文信息:“ ComboDroid: Generating High-Quality Test Inputs for Android Apps via Use Case Combinations”即将发表在2020年的International Conference on Software Engineering (ICSE’20)。工具的代码(https://github.com/skull591/ComboDroid-Artifact)也已经发布啦。
作者简介:本文作者包括南京大学的博士生王珏,助理研究员蒋炎岩博士,许畅教授,曹春教授,马晓星和吕建教授。
参考
- ^A. Hindle, E. T. Barr, Z. Su, M. Gabel and P. Devanbu, "On the naturalness of software," 2012 34th International Conference on Software Engineering (ICSE), Zurich, 2012, pp. 837-847.
- ^ J. Wang, Y. Jiang, C. Xu, C. Cao, X. Ma, J. Lu. ComboDroid: Generating High-Quality Test Inputs for Android Apps via Use Case Combinations. In the 42nd International Conference on Software Engineering (ICSE’20).
- ^Y.M. Baek, D.H. Bae. Autoamted Model-Based Android GUI Testing Using Multi-Level GUI Comparison Criteria. In Proceedings of the 31st IEEE/ACM International Conference of Automated Software Engineering (ASE’16).
- ^[3] W. Choi, G. Necula, K. Sen. Guided GUI Testing of Android Apps with Minimal Restart and Approximate Learning. In Proceedings of the 2013 ACM SIGPLAN international conference on Object Oriented Programming Systems Languages & Applications (OOPSLA’13).
- ^T. Azium, I. Nearnliu. Targeted and Depth-First Exploration for Systematic Testing of Android Apps. In Proceedings of the 2013 ACM SIGPLAN international conference on Object Oriented Programming Systems Lanaguage & Applications (OOPSLA’13).
- ^T. Gu, C. Sun, X. Ma, C. Cao, C. Xu, Y. Yao, Q. Zhang, J. Lu, Z. Su. Practical GUI Testing of Android Applications via Model Abstraction and Refinement. In 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE’19).