八股文个人整理
h1.1 开始
1.2 内容准备
一、熟练使用开发构建管理工具Idea、Eclipse、Git、svn、maven、tomcat等
Git提交代码的过程:

二、良好的编码习惯,Java基础扎实,熟悉多线程,io操作,了解jvm、反射、泛型、
Java创建对象得五种方式?
(1)new关键字 (2)Class.newInstance (3)Constructor.newInstance
(4)Clone方法 (5)反序列化
集合 + 数据结构
Java集合详解_keep one's resolveY的博客-CSDN博客_java集合详解
Collection 接口的接口 对象的集合(单列集合)
├——-List 接口:元素按进入先后有序保存,可重复
│—————-├ LinkedList 接口实现类, 链表, 插入删除, 没有同步, 线程不安全
│—————-├ ArrayList 接口实现类, 数组, 随机访问, 没有同步, 线程不安全
│—————-└ Vector 接口实现类 数组, 同步, 线程安全
│ ———————-└ Stack 是Vector类的实现类(Stack就是栈,底层也是数组,它具有先进后出的特点。不建议使用)
└——-Set 接口: 仅接收一次,不可重复,并做内部排序
├—————-└HashSet 使用hash表(数组)存储元素
│————————└ LinkedHashSet 链表维护元素的插入次序
└ —————-TreeSet 底层实现为二叉树,元素排好序
Map 接口 键值对的集合 (双列集合)
├———Hashtable 接口实现类, 同步, 线程安全
├———HashMap 接口实现类 ,没有同步, 线程不安全-
│—————–├ LinkedHashMap 双向链表和哈希表实现
│—————–└ WeakHashMap
├ ——–TreeMap 红黑树对所有的key进行排序
└———IdentifyHashMap
集合的遍历:fori循环遍历,foreach遍历,迭代器遍历
map的遍历:keySet或values方法遍历key或value,map entrySet的遍历。
Foreach底层:
数组:先来关注数组的增强for循环的底层原理,从下图反编译出的源码可以看出,对数组进行增强for遍历其实底层实现就是运用了普通数组遍历是采用的带索引下标的迭代(遍历):
集合:再来看看对集合使用增强for遍历时其底层实现方式,从下图中可以直观清晰的看出对集合使用增强for遍历就是获取该集合迭代器完成迭代操作,其原理就是获取迭代器(Iterator)对集合元素进行迭代操作
线程安全的集合:
Map:
-
Map
-
Map
Set:
-
Set
set = Collections.synchronizedSet(new HashSet<>()) -
Set
set = new CopyOnWriteArraySet<>();
List:
List
List
List
Set中的对象要重写hashmap和equals方法,原因:
-
因为再将对象加入到HashSet中时,
-
会首先调用hashCode方法计算出对象的hash值,接着根据此hash值调用HashMap中的hash方法,
-
得到的值& (length-1)得到该对象在hashMap的transient Entry[] table中的保存位置的索引,
-
接着找到数组中该索引位置保存的对象,并调用equals方法比较这两个对象是否相等,如果相等则不添加,
-
注意:所以要存入HashSet的集合对象中的自定义类必须覆盖hashCode(),equals()两个方法,
-
才能保证集合中元素不重复。
集合的排序:
自然排序要求元素(实体类)必须实现Compareable接口,并重写里面的compareTo()方法
比较器排需要在TreeSet初始化是时候传入一个实现Comparator接口的比较器对象,或者采用匿名内部类的方式new一个Comparator对象,重写里面的compare()方法;
集合中直接使用的sort方法:是插入排序,快速排序,归并排序三种排序的组合。进行判断选取。
扩容机制:
ArrayList
底层实现方式是数组,默认大小是10个,当指定容量大小时用指定大小的容量;当数组满了以1.5倍扩容,特点是查询快,增删改慢。数组自己是没办法进行扩容的,只是我们人为用逻辑的方式对数组进行扩容。
HashMap
底层实现是数组+链表+红黑树,默认大小16,当指定容量大小时,用大于该容量的最小的2的幂次方作为初始容量;当table使用了容量的0.75倍时扩容,扩容为2倍,当table容量超过64且链表数量大于8时,链表会树化。线程不安全。
HashSet
对HashMap进行了封装,无序且不能重复,其他与HashMap一致。线程不安全。
ConcurrentHashMap
1.7底层是Segment数组+HashEntry数组+链表,每个Segment继承了ReentrantLock。
1.8底层是Node数组+链表+红黑树,使用了CAS和Synchronized保证并发安全。
ConcurrentHashMap原如何保证的线程安全?
JDK1.7:使用分段锁,将一个Map分为了16个段,每个段都是一个小的hashmap,每次操作只对其中一个段加锁
JDK1.8:采用CAS+Synchronized保证线程安全,每次插入数据时判断在当前数组下标是否是第一次插入,是就通过CAS方式插入,然后判断f.hash是否=-1,是的话就说明其他线程正在进行扩容,当前线程也会参与扩容;删除方法用了synchronized修饰,保证并发下移除元素安全
数据结构常见结构梳理:
数据结构的意义及基础知识_数据结构中各种数据结构的意义?_keep one's resolveY的博客-CSDN博客
1、数组结构: 存储区间连续、内存占用严重、空间复杂度大
优点:随机读取和修改效率高,原因是数组是连续的(随机访问性强,查找速度快)
缺点:插入和删除数据效率低,因插入数据,这个位置后面的数据在内存中都要往后移动,且大小固定不易动态扩展。
2、链表结构:存储区间离散、占用内存宽松、空间复杂度小
优点:插入删除速度快,内存利用率高,没有固定大小,扩展灵活
缺点:不能随机查找,每次都是从第一个开始遍历(查询效率低)
3、哈希表结构:是根据关键码和值 (key和value) 直接进行访问的数据结构,哈希表是基于数组衍生的数据结构
4、栈
栈是一种特殊的线性表,仅能在线性表的一端操作,栈顶允许操作,栈底不允许操作。 栈的特点是:先进后出,从栈顶放入元素的操作叫入栈,取出元素叫出栈。栈常应用于实现递归功能方面的场景,例如斐波那契数列。
5、队列
队列与栈一样,也是一种线性表,不同的是,队列可以在一端添加元素,在另一端取出元素,也就是:先进先出。从一端放入元素的操作称为入队,取出元素为出队,因为队列先进先出的特点,在多线程阻塞队列管理中非常适用
6、树
二叉树是一种比较有用的折中方案,它添加,删除元素都很快,并且在查找方面也有很多的算法优化,所以,二叉树既有链表的好处,也有数组的好处,是两者的优化方案,在处理大批量的动态数据方面非常有用。
7、堆
是一种比较特殊的数据结构,可以被看做一棵树的数组对象,因为堆有序的特点,一般用来做数组中的排序,称为堆排序
多线程
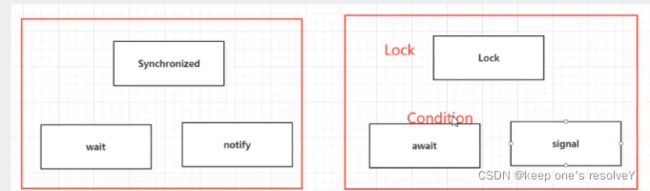
synchronized和lock区别?
3. Synchronized 与Lock 的区别
1、Synchronized 内置的Java关键字,Lock是一个Java接口,JUC包下的
2、Synchronized 无法判断获取锁的状态,Lock可以判断
3、Synchronized 会自动释放锁,lock必须要手动加锁和手动释放锁!可能会遇到死锁
4、Synchronized 线程1(获得锁->阻塞)、线程2(等待);lock就不一定会一直等待下去,lock会有一个trylock去尝试获取锁,不会造成长久的等待。
5、Synchronized 是可重入锁,不可以中断的,非公平的;
Lock接口,可重入的,可以判断锁,可以自己设置公平锁和非公平锁;一般使用ReentrantLock(可重入锁)实现类,lock会有一个trylock去尝试获取锁,不会造成长久的等待。
6、Synchronized 适合锁少量的代码同步问题,Lock适合锁大量的同步代码;
7、synchronized是JVM层次通过监视器实现的,Lock是通过AQS实现的
名词解释:
AQS:AQS是一个抽象类,可以用来构造锁和同步类,如ReentrantLock,Semaphore,CountDownLatch,CyclicBarrier。
AQS 核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制是将暂时获取不到锁的线程加入到同步阻塞队列中。这个队列是用双向链表实现的。
可重入锁:获取外层的锁就自动获取里面的锁。
非公平锁:线程执行获取锁可以插队,公平锁不能插队,必须按顺序执行。锁谁问题:
一、锁不同位置分类
synchronized是Java中的关键字,是一种同步锁。方法锁和对象锁说的是一个东西,即只有方法锁或对象锁 和类锁两种锁(锁加在方法上和类上作用是一样的,没有区别)
它修饰的对象有以下几种:
1.1 修饰一个代码块
被修饰的代码块称为同步语句块,其作用的范围是大括号{}括起来的代码,作用的对象是调用这个代码块的对象;
1.2 修饰一个方法
被修饰的方法称为同步方法,其作用的范围是整个方法,作用的对象是调用这个方法的对象;
1.3 修饰一个静态的方法
其作用的范围是整个静态方法,作用的对象是这个类的所有对象;
1.4. 修饰一个类
其作用的范围是synchronized后面括号括起来的部分,作用主的对象是这个类的所有对象。juc下集合不安全:
list
* 1. List list = new Vector<>();
* 2. List list = Collections.synchronizedList(new ArrayList<>());
* 3. List list = new CopyOnWriteArrayList<>(); 底层:可重入锁lock unlock
set
1. Set set = Collections.synchronizedSet(new HashSet<>());
* 2. Set set = new CopyOnWriteArraySet<>(); 底层:可重入锁lock unlock
map Map map = Collections.synchronizedMap(new HashMap<>());
* Map map = new ConcurrentHashMap<>(); 底层? 进程是程序运行的进程,进程可以包含多个线程,线程就是并发操作,可以提高效率。
四种多线程实现方式,继承thread。实现runnable,callbale接口,通过线程池的方式。
线程6种状态:
线程有6种状态,下面有错误:
public enum State {
//线程刚创建
NEW,
//在JVM中正在运行的线程
RUNNABLE,
//线程处于阻塞状态,等待监视锁,可以重新进行同步代码块中执行
BLOCKED,
//等待状态 WAITING,
//调用sleep() join() wait()方法可能导致线程处于等待状态
TIMED_WAITING,
//线程执行完毕,已经退出
TERMINATED;
}线程的方法:
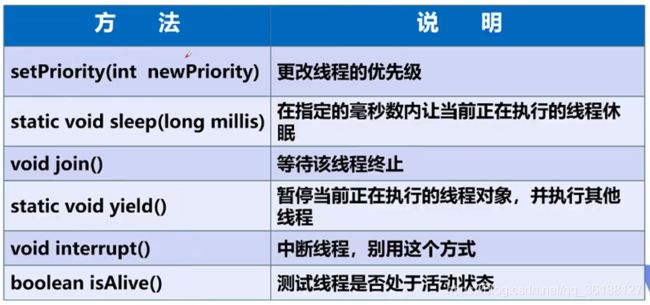
线程池:
三大方法
- ExecutorService threadPool = Executors.newSingleThreadExecutor();//单个线程
- ExecutorService threadPool2 = Executors.newFixedThreadPool(5); //创建一个固定的线程池的大小
- ExecutorService threadPool3 = Executors.newCachedThreadPool(); //可伸缩的
线程池7大参数:ThreadPoolExecutor(我们的服务器8核16g)
public ThreadPoolExecutor(int corePoolSize, //核心线程池大小
int maximumPoolSize, //最大的线程池大小
long keepAliveTime, //超时时间,超时了没有人调用就会释放
TimeUnit unit, //超时单位
BlockingQueue workQueue, //阻塞队列
ThreadFactory threadFactory, //线程工厂 创建线程的 一般不用动
RejectedExecutionHandler handler //拒绝策略
) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
} 网上这么说:cpu密集型:cpu核心数+1;io密集型:cpu数*2
我的设置核心线程数是:8核,最大线程数设置是8*2,阻塞队列设置为512。
线程执行过程:
1、线程在有任务的时候会创建核心的线程数corePoolSize
2、当线程满了(有任务但是线程被使用完)不会立即扩容,而是放到阻塞队列中,当阻塞队列满了之后才会继续创建线程。
3、如果队列满了,线程数达到最大线程数则会执行拒绝策略。
4、当线程数大于核心线程数事,超过KeepAliveTime(闲置时间),线程会被回收,最终会保持corePoolSize个线程。
4种拒绝策略:
1:丢弃任务,抛异常,默认策略
2:丢弃不抛异常
3:丢弃队列最前面的任务,打回被拒绝的任务,重新提交。
4:尝试与最老的线程竞争


死锁:
死锁指多个线程在执行过程中,因争夺资源造成的一种相互等待的僵局
死锁形成的4个必要条件:
互斥条件:同一资源同时只能由一个线程读取
不可抢占条件:不能强行剥夺线程占有的资源
请求和保持条件:请求其他资源的同时对自己手中的资源保持不放
循环等待条件:在相互等待资源的过程中,形成一个闭环
预防死锁:
只需要破坏其中一个条件即可,比如使用定时锁、尽量让线程用相同的加锁顺序,还可以用银行家算法可以预防死锁
保证并发安全的三大特性?
原子性:一次或多次操作在执行期间不被其他线程影响(因为被锁住了)
可见性:当一个线程在工作内存修改了变量,其他线程能立刻知道
有序性:JVM对指令的优化会让指令执行顺序改变,有序性是禁止指令重排
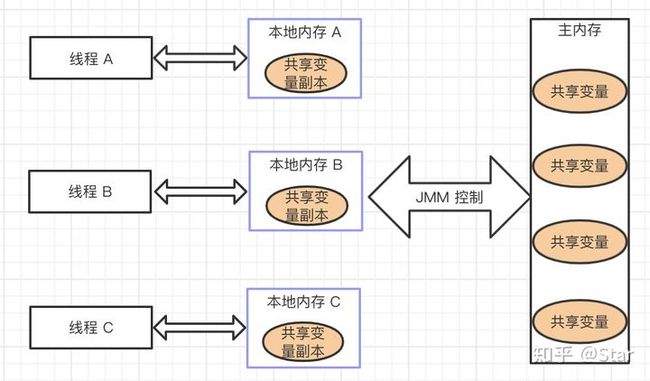
JMM(Java内存模型):
JMM是围绕着在并发过程中如何处理可见性、原子性、有序性这三个特性而建立的模型。
JMM(Java Memory Model):Java 内存模型,是 Java 虚拟机规范中所定义的一种内存模型,Java 内存模型是标准化的,屏蔽掉了底层不同计算机的区别。也就是说,JMM 是 JVM 中定义的一种并发编程的底层模型机制。
JMM 定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存中,每个线程都有一个私有的本地内存,本地内存中存储了该线程以读/写共享变量的副本。
JMM 的规定:
- 所有的共享变量都存储于主内存。这里所说的变量指的是实例变量和类变量,不包含局部变量,因为局部变量是线程私有的,因此不存在竞争问题。
- 每一个线程还存在自己的工作内存,线程的工作内存,保留了被线程使用的变量的工作副本。
- 线程对变量的所有的操作(读,取)都必须在工作内存中完成,而不能直接读写主内存中的变量。
- 不同线程之间也不能直接访问对方工作内存中的变量,线程间变量的值的传递需要通过主内存中转来完成。
synchronized关键字在JMM内存模式中的规定(可见性原子性有序性的原理如下:)
synchronized关键字在JMM内存模式中有下列规定:
synchronized是同步锁,同步块内的代码相当于同一时刻单线程执行,故不存在原子性和指令重排序的问题synchronized关键字的语义JMM有两个规定,保证其实现内存可见性:- 线程加锁前,将清空工作内存中共享变量的值,从主内存中重新取值。
- 线程释放锁前,必须把共享变量的最新值刷新到主内存中;
- 加锁和解锁是同一把锁;
Synchronized锁原理和优化
Synchronize是通过对象头的markwordk来表明监视器的,监视器本质是依赖操作系统的互斥锁实现的。操作系统实现线程切换要从用户态切换为核心态,成本很高,此时这种锁叫重量级锁,在JDK1.6以后引入了偏向锁、轻量级锁、重量级锁
偏向锁:当一段代码没有别的线程访问,此时线程去访问会直接获取偏向锁
轻量级锁:当锁是偏向锁时,有另外一个线程来访问,会升级为轻量级锁。线程会通过CAS方式获取锁,不会阻塞,提高性能,
重量级锁:轻量级锁自旋一段时间后线程还没有获取到锁,会升级为重量级锁,重量级锁时,来竞争锁的所有线程都会阻塞,性能降低
注意,锁只能升级不能降级
volatile 修饰符适用于以下场景:某个属性被多个线程共享,其中有一个线程修改了此属性,其他线程可以立即得到修改后的值;或者作为状态变量,如 flag = ture,实现轻量级同步。
Volatile定义在JMM内存模式中的规定(可见性原理如下:):
volatile定义:
- 当对volatile变量执行写操作后,JMM会把工作内存中的最新变量值强制刷新到主内存
- 写操作会导致其他线程中的缓存无效
这样,其他线程使用缓存时,发现本地工作内存中此变量无效,便从主内存中获取,这样获取到的变量便是最新的值,实现了线程的可见性。
Synchronized和Volatile区别:
Synchronized可以保证可见性,原子性、有序性,是重量级同步机制
Volatile 是 Java 虚拟机提供 最轻量级的同步机制,保证可见性,不保证原子性,禁止指令重排,保证有序性(是通过编译器在生成字节码时,在指令序列中添加“内存屏障”来禁止指令重排序的)。
Volatile 是 Java 虚拟机提供 轻量级的同步机制,性能好,用来修饰变量。使用 volatile 的成本更低,因为它不会引起线程上下文的切换和调度。但 volatile 无法像 synchronized 一样保证操作的原子性。
volatile关键字只能用于变量而synchronized关键字可以修饰方法以及代码块。
多线程访问volatile关键字不会发生阻塞,而synchronized关键字可能会发生阻塞。、
volatile关键字主要用于解决变量在多个线程之间的可见性,而 synchronized关键字解决的是多个线程之间访问资源的同步性。
volatile关键字能保证数据的可见性,但不能保证数据的原子性。synchronized关键字两者都能保证。
双重检测锁的单例使用到了Volatile(保证了指令重排)
饿汉式单例使用较多:线程安全
public class Singleton {
private static Singleton instance = new Singleton();
private Singleton (){}
public static Singleton getInstance() {
return instance;
}
}多线程的使用场景:


1、后台任务,例如:定时向大量(100w以上)的用户发送邮件;
springboot使用线程池发送邮件demo_酸酸酱的博客-CSDN博客_线程池发送邮件
2、我们在后台需要清理一些垃圾数据的时候,可以使用多线程处理;
3、我们需要把数据库中的表写入下载大数据量的表格时,我们使用多线程处理;
4、取钱,生成者消费者问题
5、耗时操作
多线程的状态:

Sleep() 方法和 Wait() 方法区别和共同点?
推荐使用wait()方法,sleep()是使线程暂停执行一段时间的方法。wait()也是一种使线程暂停执行的方法
相同点:
两者都可以暂停线程的执行,都会让线程进入等待状态。
不同点:
(1)wait()是Object的方法,sleep()是Thread类的方法
(2)wait()会释放锁,sleep()不会释放锁
(3)wait()要在同步方法或者同步代码块中执行,sleep()没有限制
(4)wait()要调用notify()或notifyall()唤醒,sleep()自动唤醒
乐观锁
乐观锁就是持比较乐观态度的锁。在操作数据时非常乐观,认为别的线程不会同时修改数据,只有到数据提交的时候才通过一种机制来验证数据是否存在冲突。一般使用CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量。
CAS 即 Compare and Swap,它体现的一种乐观锁的思想
CAS锁可以保证原子性,思想是更新内存时会判断内存值是否被别人修改过,如果没有就直接更新。如果被修改,就重新获取值,直到更新完成为止。这样的缺点是
(1)只能支持一个变量的原子操作,不能保证整个代码块的原子操作
(2)CAS频繁失败导致CPU开销大
(3)ABS问题:线程1和线程2同时去修改一个变量,将值从A改为B,但线程1突然阻塞,此时线程2将A改为B,然后线程3又将B改成A,此时线程1将A又改为B,这个过程线程2是不知道的,这就是ABA问题,可以通过版本号或时间戳解决
java.util.concurrent中提供了原子操作类,可以提供线程安全的操作,例如:AtomicInteger、 AtomicBoolean等,它们底层就是采用 CAS 技术 + volatile 来实现的。
悲观锁
比较悲观的锁,总是想着最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁。比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。在Java中,synchronized从偏向锁、轻量级锁到重量级锁,全是悲观锁。JDK提供的Lock实现类全是悲观锁。一般用于多写的场景。
什么是AQS锁?
AQS是一个抽象类,可以用来构造锁和同步类,如ReentrantLock,Semaphore,CountDownLatch,CyclicBarrier。
AQS 核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制是将暂时获取不到锁的线程加入到同步阻塞队列中。这个队列是用双向链表实现的。
为什么AQS使用的双向链表?
因为有一些线程可能发生中断 ,而发生中断时候就需要在同步阻塞队列中删除掉,这个时候用双向链表方便删除掉中间的节点
有哪些常见的AQS锁
AQS分为独占锁和共享锁
ReentrantLock(独占锁):可重入,可中断,可以是公平锁也可以是非公平锁,非公平锁就是会通过两次CAS去抢占锁,公平锁会按队列顺序排队
Semaphore(信号量):设定一个信号量,当调用acquire()时判断是否还有信号,有就获取一个信号量,没有就阻塞等待其他线程释放信号量,当调用release()时释放一个信号量,唤醒阻塞线程。
应用场景:允许多个线程访问某个临界资源时,如上下车,买卖票
CountDownLatch(倒计数器):给计数器设置一个初始值,当调用CountDown()时计数器减一,当调用await() 时判断计数器是否归0,不为0就阻塞,直到计数器为0。
应用场景:启动一个服务时,主线程需要等待多个组件加载完毕,之后再继续执行
CyclicBarrier(循环栅栏):给计数器设置一个目标值,当调用await() 时判断计数器是否达到目标值,未达到就阻塞,直到计数器达到目标值
应用场景:多线程计算数据,最后合并计算结果的应用场景
ThreadLocal
ThreadLocal类提供了一种线程局部变量(ThreadLocal),即每一个线程都会保存一份变量副本,每个线程都可以独立地修改自己的变量副本,而不会影响到其他线程,是一种线程隔离的思想。MDC工具类的原理用到了ThreadLocal,在MDC中设置traceId,能使用MDC保存traceId等参数的根本原因是,用户请求到应用服务器,Tomcat会从线程池中分配一个线程去处理该请求。那么该请求的整个过程中,保存到MDC的ThreadLocal中的参数,也是该线程独享的,所以不会有线程安全问题。
JVM
JVM运行时内存结构
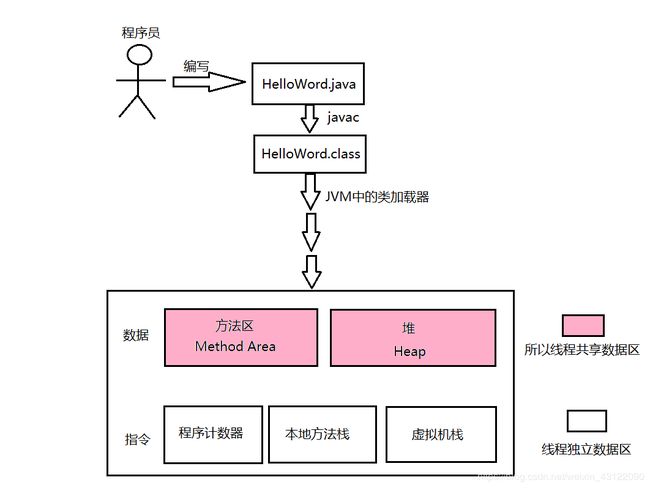
线程私有区:
(1)虚拟机栈:每次调用方法都会在虚拟机栈中产生一个栈帧,每个栈帧中都有方法的参数、局部变量、方法出口等信息,方法执行完毕后释放栈帧
(2)本地方法栈:为native修饰的本地方法提供的空间,在HotSpot中与虚拟机合二为一
(3)程序计数器:保存指令执行的地址,方便线程切回后能继续执行代码
线程共享区:
(4)堆内存:Jvm进行垃圾回收的主要区域,存放对象,分为新生代和老年代,内存比例为1:2,新生代的Eden区内存不够时时发生轻GC,老年代内存不够时发生重GC
(5)方法区:存放类信息、静态变量、常量池、运行时常量池等信息。JDK1.8之前用持久代实现,JDK1.8后用元空间实现,元空间使用的是本地内存,而非在JVM内存结构中
Java堆内存分区
-
在 Java 中,堆被划分成两个不同的区域:新生代和老年代,占用大小:新生代:老年代1:2
-
老年代就一个区域。新生代 ( Young ) 又被划分为三个区域:Eden(伊甸园)、From Survivor(幸存区)、To Survivor。 Edem : From Survivor : To Survivor = 8 : 1 : 1
-
新生代采用复制算法,老年代采用标记整理算法,还有标记清除算法(会造成内存碎片)
-
判断对象存活:可达性计数法(主流算法),引用计数法(难解决对象之间相互循环引用的问题。)
类加载过程
(1)加载 :把字节码通过二进制的方式转化到方法区中的运行数据区
(2)连接:
验证:验证字节码文件的正确性。
准备:正式为类变量在方法区中分配内存,并设置初始值,final类型的变量在编译时已经赋值了
解析:将常量池中的符号引用(如类的全限定名)解析为直接引用(类在实际内存中的地址)
(3)初始化 :执行类构造器(不是常规的构造方法),为静态变量赋初值并初始化静态代码块。
对象的创建过程
(1)检查类是否已被加载,没有加载就先加载类
(2)为对象在堆中分配内存,使用CAS方式分配,防止在为A分配内存时,执行当前地址的指针还没有来得及修改,对象B就拿来分配内存。
(3)初始化,将对象中的属性都分配0值或null
(4)设置对象头
(5)为属性赋值和执行构造方法
对象头中有哪些信息
对象头中有两部分,一部分是MarkWork标记工作,存储对象运行时的数据,如对象的hashcode、GC分代年龄、GC标记、锁的状态、获取到锁的线程ID等;另外一部分是表明对象所属类,如果是数组,还有一个部分存放数组长度
类加载器和双亲委派机制
双亲委派机制,其工作原理的是,如果一个类加载器收到了类加载请求,它并不会自己先去加载,而是把这个请求委托给父类的加载器去执行,如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的启动类加载器,如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载,这就是双亲委派模式,即每个儿子都很懒,每次有活就丢给父亲去干,直到父亲说这件事我也干不了时,儿子自己才想办法去完成。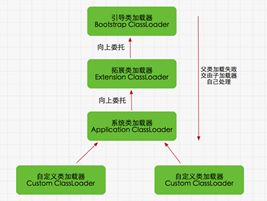
双亲委派机制的优势:采用双亲委派模式的是好处是Java类随着它的类加载器一起具备了一种带有优先级的层次关系,通过这种层级关可以避免类的重复加载,当父亲已经加载了该类时,就没有必要子ClassLoader再加载一次。其次是考虑到安全因素,java核心api中定义类型不会被随意替换,假设通过网络传递一个名为java.lang.Integer的类,通过双亲委托模式传递到启动类加载器,而启动类加载器在核心Java API发现这个名字的类,发现该类已被加载,并不会重新加载网络传递的过来的java.lang.Integer,而直接返回已加载过的Integer.class,这样便可以防止核心API库被随意篡改。
从父类加载器到子类加载器分别为:
启动类加载器 BootStrapClassLoader 加载路径为:JAVA_HOME/jre/lib
扩展类加载器 ExtensionClassLoader 加载路径为:JAVA_HOME/jre/lib/ext
系统类加载器 ApplicationClassLoader 加载路径为:classpath
还有一个自定义类加载器
当一个类加载器收到类加载请求时,会先把这个请求交给父类加载器处理,若父类加载器找不到该类,再由自己去寻找。该机制可以避免类被重复加载,还可以避免系统级别的类被篡改。
如何打破双亲委派模型?
其实双亲委派模型并不是具有强制性约束的模型,虽然它有助于保证类的隔离和加载的顺序,但有时候我们可能需要打破这种机制,比如我们在特殊情况下需要自定义类加载逻辑或实现热部署的时候。
上周面试问道了这个问题,所以在这里也介绍几种打破Java中双亲委派机制的方法:
自定义类加载器:我们自定义一个继承自ClassLoader的类加载器,重写loadClass方法,可以实现自己的类加载逻辑。在我们定义的这个方法中,可以在需要时跳过父类加载器并直接加载类,从而打破双亲委派机制。但是,在自定义类加载器中打破双亲委派机制可能会导致类的隔离性和安全性问题,所以我们在使用时要慎重。
线程上下文类加载器:Java中提供了线程上下文类加载器(Thread Context ClassLoader)的概念,它可以在某些情况下打破双亲委派机制。例如,在JNDI、SPI(Service Provider Interface)和一些框架中,线程上下文类加载器可以用来加载指定的类,从而不受双亲委派机制的限制。
通过反射机制:使用反射机制可以直接调用Class类的defineClass方法,这样可以绕过双亲委派机制直接加载指定的类。但是,在使用这种方式时,我们需要自行处理类加载的顺序和依赖关系,因为双亲委派机制不再起作用。
综上所述,不正确地使用或滥用这些方法可能导致类加载冲突、安全问题以及代码的不稳定性 ,因此我们还需要在明确的需求和充分的理解下使用
JVM内存参数:
-Xmx[]:堆空间最大内存
-Xms[]:堆空间最小内存,一般设置成跟堆空间最大内存一样的
-Xmn[]:新生代的最大内存
-xx:[survivorRatio=3]:eden区与from+to区的比例为3:1,默认为4:1
-xx[use 垃圾回收器名称]:指定垃圾回收器
-xss:设置单个线程栈大小
一般设堆空间为最大可用物理地址的百分之80
GC的回收机制和原理
GC的目的实现内存的自动释放,判断分配的内存是否够用,进行GC。采用了分代回收思想,将堆分为新生代、老年代,新生代中采用复制算法,老年代采用整理算法,当新生代内存不足时会发生minorGC,老年代不足时会发送fullGC。使用可达性分析法判断对象是否可回收。
JDK1.8默认垃圾回收Parallel Scavenge + ParallelOld , JDK1.9默认垃圾收集器是G1
性能问题调优:
阿里巴巴Arthas(阿尔萨斯)常用:
通过全局视角实时查看应用 load、内存、gc、线程的状态信息,并能在不修改应用代码的情况下,对业务问题进行诊断,包括查看方法调用的出入参、异常,监测方法执行耗时,类加载信息等,大大提升线上问题排查效率。
一篇文章掌握整个JVM,JVM超详细解析!!!_keep one's resolveY的博客-CSDN博客_jvm是什么意思
反射和注解
反射是通过获取类的class对象,然后动态的获取到这个类的内部结构,动态的去操作类的属性和方法。
应用场景有:要操作权限不够的类属性和方法时、实现自定义注解时、动态加载第三方jar包时、按需加载类,节省编译和初始化时间;
获取class对象的方法有:class.forName(类路径),类.class(),对象的getClass()
1)Java反射机制的作用
1. 在运行时判断任意一个对象所属的类
2. 在运行时构造任意一个类的对象
3. 在运行时判断任意一个类所具有的成员变量和方法
4. 在运行时调用任意一个对象的方法
2)什么是反射机制?
简单说,反射机制值得是程序在运行时能够获取自身的信息。在java中,只要给定类的名字,那么就可以通过反射机制来获得类的所有信息。
3)java反射机制提供了什么功能?
1. 在运行时能够判断任意一个对象所属的类
2. 在运行时构造任意一个类的对象
3. 在运行时判断任意一个类所具有的成员变量和方法
4. 在运行时调用任一对象的方法
5. 在运行时创建新类对象
4)哪里用到反射机制?
各种框架用的最多的就是反射
加载驱动
读取配置文件
5)运用反射的优缺点
优点:
反射提高了程序的灵活性和扩展性,降低耦合性,提高自适应能力。它允许程序创建和控制任何类的对象,无需提前硬编码目标类
缺点:
(1)性能问题:使用反射基本上是一种解释操作,用于字段和方法接入时要远慢于直接代码。因此反射机制主要应用在对灵活性和扩展性要求很高的系统框架上,普通程序不建议使用。
(2)使用反射会模糊程序内内部逻辑:程序员希望在源代码中看到程序的逻辑,反射等绕过了源代码的技术,因而会带来维护问题。反射代码比相应的直接代码更复杂。
6)如何使用java的反射?
a. 通过一个全限类名创建一个对象
1)、Class.forName(“全限类名”); 例如:com.mysql.jdbc.Driver Driver类已经被加载到 jvm中,并且完成了类的初始化工作就行了
2)、类名.class; 获取Class<?> clz 对象
3)、对象.getClass();
b. 获取构造器对象,通过构造器new出一个对象
1). Clazz.getConstructor([String.class]);
2). Con.newInstance([参数]);
c. 通过class对象创建一个实例对象(就相当与new类名()无参构造器)
1). Clazz.newInstance();
d. 通过class对象获得一个属性对象
1)、Field c=clz.getFields():获得某个类的所有的公共(public)的字段,包括父类中的字段。
2)、Field c=clz.getDeclaredFields():获得某个类的所有声明的字段,即包括public、private和proteced,但是不包括父类的申明字段 e.
e、通过class对象获得一个方法对象
1). Clazz.getMethod(“方法名”,class……parameaType);(只能获取公共的)
2). Clazz.getDeclareMethod(“方法名”);(获取任意修饰的方法,不能执行私有)
3) M.setAccessible(true);(让私有的方法可以执行)
f. 让方法执行
1). Method.invoke(obj实例对象,obj可变参数);-----(是有返回值的)IO流
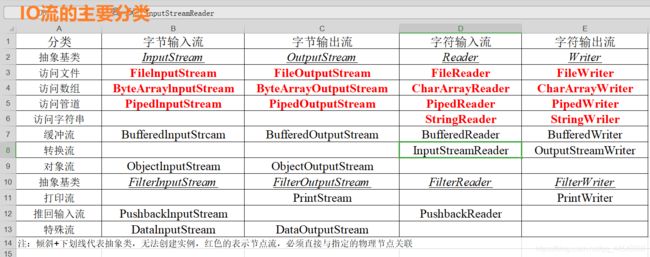
1.java中有几种类型的流?jdk为每种类型的流提供了一些抽象类以供继承,请说出它们分别是什么?
解题思路:了解io流的体系(重要)就可以了
从大的方面来分可以分为字节流和字符流.字符流提供了提供了reader和writer;字节流提供了outputstream 和inputstream.
2.字符流和字节流有什么区别?(重要)
解题思路:从读写的原理上来进行区分会好记一点(字符流处理的单元为 2 个字节的 Unicode 字符,分别操作字符、字符数组或字符串;而字节流处理单元为 1 个字节,操作字节和字节数组。所以字符流是由Java虚拟机将字节转化为2个字节的Unicode字符为单位的字符而成的,如果是音频文件、图片、歌曲,就用字节流好点(避免数据丢失);如果是关系到中文(文本)的,用字符流好点)
字符流以字符或者字符数组的形式读写数据,只能读写二进制文件;字节流能读写各种类型的数据.
3.什么是java序列化,如何实现java序列化?(重要)
解题思路:像这样的题,一般先做名词解释,然后阐述作用和使用方法
序列化就是一种用来处理对象流的机制,所谓对象流也就是将对象的内容进行流化(将对象转换成二进制)。可以对流化后的对象进行读写操作,也可将流化后的对象传输于网络之间。序列化是为了解决在对对象流进行读写操作时所引发的问题。
注解:当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把这个Java对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为Java对象。
将需要序化的类实现Serializable接口就可以了,该接口没有任何方法,可以理解为一个标记,即表明这个类可以序列化。注意的是被关键字static、transient修饰的变量不能被序列化。在被序列化后,transient修饰的变量会被设为初始值。如int型的是0、对象型的是null.
1.概念
序列化:把Java对象转换为字节序列的过程。
反序列化:把字节序列恢复为Java对象的过程。
2.用途
对象的序列化主要有两种用途:
1) 把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中;
2) 在网络上传送对象的字节序列。
4.什么是比特(Bit),什么是字节(Byte),什么是字符(Char),它们长度是多少,各有什么区别(一般是笔试题的选择题里面出的多一点)
Bit是最小的传输单位,byte是最小的存储单位,1byte=8bit,char 是一种基本数据类型,1char=2byte.
5.BufferedReader属于哪种流,它主要是用来做什么的,它里面有那些经典的方法
解题思路:望文知意,Reader是字符流,而buffer是缓冲的作用,缓冲区是基于内存的,起到读写高效的作用;所以BufferedReader是高效字符流
BufferedReader是字符流,也是一种包装流,用来增强reader流.主要用来读取数据的,最经典的方法是readline,可以一次读一行,是reader不具备的.
6.什么是节点流,什么是处理流,它们各有什么用处,处理流的创建有什么特征
节点流: 直接与数据源相连,用于输入或者输出
处理流:在节点流的基础上对之进行加工,进行一些功能的扩展
处理流的构造器必须要传入节点流的子类
7.如果我要对字节流进行大量的从硬盘读取,要用那个流,为什么?
解题思路:因为明确说了是对字节流的读取,所以肯定是inputstream或者他的子类,又因为要大量读取,肯定要考虑到高效的问题,自然想到缓冲流。
用BufferedInputStream,原因:BufferedInputStream是InputStream的缓冲流,使用它可以防止每次读取数据时进行实际的写操作,代表着使用缓冲区。不带缓冲的操作,每读一个字节就要写入一个字节,由于涉及磁盘的IO操作相比内存的操作要慢很多,所以不带缓冲的流效率很低。带缓冲的流,可以一次读很多字节,但不向磁盘中写入,只是先放到内存里。等凑够了缓冲区大小的时候一次性写入磁盘,这种方式可以减少磁盘操作次数,速度就会提高很多!并且也可以减少对磁盘的损伤。
8.如果我要打印出不同类型的数据到数据源,那么最适合的流是那个流,为什么?
解题思路:要考虑到打印的问题,就要用到打印输出流(printstream:操作字节流;或者是PrintWriter操作字符流)
用printstream,因为只有字节流才能读写各种类型的数据.
9.怎么样把输出字节流转换成输出字符流,说出它的步骤?
解题思路:把字节流转成字符流,这里肯定就要用到适配器模式,很自然的要想到outputstreamwriter。它继承了Writer接口,但要创建它必须在构造函数中传入一个outputstream的实例,outputstreamwriter的作用也就是将outputstream适配到Writer。,它实现了Reader接口,并且持有了InputStream的引用。(关于适配器的作用,可以想一下电脑转接头的例子)
利用转换流outputstreamwriter.创建一个字节流对象,将其作为参数传入转换流outputstreamwriter中,得到字符流对象.
10.什么叫对象序列化,什么是反序列化,实现对象序列化需要做哪些工作?
对象序列化:将对象以二进制的形式保存到硬盘上;
反序列化:将二进制文件转化为对象读取.
将需要序化的类实现Serializable接口
11.说说你对io流的理解
解题思路:个人觉得,可以讲io流的作用和体系
io流就相当于读写数据的一个管道.主要分为输入流和输出流,分别对应读数据和写数据.
12.谈一谈io流中用到的适配器模式和装饰者模式
解题思路:首先,要知道装饰者模式和适配器模式的作用;其次,可以自己举个例子把它的作用生动形象地讲出来;最后,简要说一下要完成这样的功能需要什么样的条件。
装饰器模式:就是动态地给一个对象添加一些额外的职责(对于原有功能的扩展)。
1.它必须持有一个被装饰的对象(作为成员变量)。
2.它必须拥有与被装饰对象相同的接口(多态调用、扩展需要)。
3.它可以给被装饰对象添加额外的功能。
比如,在io流中,FilterInputStream类就是装饰角色,它实现了InputStream类的所有接口,并持有InputStream的对象实例的引用,BufferedInputStream是具体的装饰器实现者,这个装饰器类的作用就是使得InputStream读取的数据保存在内存中,而提高读取的性能。
适配器模式:将一个类的接口转换成客户期望的另一个接口,让原本不兼容的接口可以合作无间。
1.适配器对象实现原有接口
2.适配器对象组合一个实现新接口的对象
3.对适配器原有接口方法的调用被委托给新接口的实例的特定方法(重写旧接口方法来调用新接口功能。)
比如,在io流中, InputStreamReader类继承了Reader接口,但要创建它必须在构造函数中传入一个InputStream的实例,InputStreamReader的作用也就是将InputStream适配到Reader。 InputStreamReader实现了Reader接口,并且持有了InputStream的引用。这里,适配器就是InputStreamReader类,而源角色就是InputStream代表的实例对象,目标接口就是Reader类。
适配器模式主要在于将一个接口转变成另一个接口,它的目的是通过改变接口来达到重复使用的目的;而装饰器模式不是要改变被装饰对象的接口,而是保持原有的接口,但是增强原有对象的功能,或改变原有对象的方法而提高性能。
泛型
【泛型】Java中的泛型,泛型类,泛型接口,泛型方法,泛型擦除_keep one's resolveY的博客-CSDN博客
JDK用到的设计模式:
JDK中设计模式_keep one's resolveY的博客-CSDN博客
单例模式:
用来确保类只有一个实例。Joshua Bloch在Effetive Java中建议到,还有一种方法就是使用枚举。
java.lang.Runtime.getRuntime()
工厂模式:
1:Integer.valueOf(1); //工厂 包装类的valueof也是工厂
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
-----------
2:Arrays.asList(); //数组转list用的是工厂
@SafeVarargs
@SuppressWarnings("varargs")
public static List asList(T... a) {
return new ArrayList<>(a);
}
3:装饰器模式:为类添加新的功能;防止类继承带来的爆炸式增长
(1)java.io包
(2)java.util.Collections#synchronizedList(List)
4:适配器模式:使不兼容的接口相容
(1)java.io.InputStreamReader(InputStream)
(2)java.io.OutputStreamWriter(OutputStream)
5:Chain of Responsibility(责任链)
作用:请求会被链上的对象处理,但是客户端不知道请求会被哪些对象处理
JDK中体现:
(1)java.util.logging.Logger会将log委托给parent logger
(2)ClassLoader的委托模型
6:Strategy(策略)
作用:提供不同的算法
JDK中的体现:ThreadPoolExecutor中的四种拒绝策略
7:Abstract Factory(抽象工厂)
作用:创建某一种类的对象
JDK中体现:
(1)java.sql包 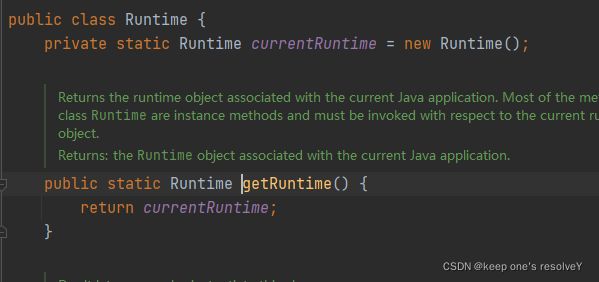
Spring用到的设计模式:
【设计模式】Spring 中经典的 9 种设计模式_keep one's resolveY的博客-CSDN博客
工厂设计模式 : Spring的ioc原理,
使用工厂模式通过 BeanFactory、ApplicationContext 创建 bean 对象。
代理设计模式 : Spring AOP 功能的实现。可用于权限认证、日志、事务处理,mybatis是生成mapper
Spring AOP实现的关键在于动态代理,主要有两种方式,JDK动态代理和CGLIB动态代理,
优先会使用JDK动态代理。
JDK动态代理只提供接口的代理,不支持类的代理,要求被代理类实现接口
如果被代理类没有实现接口,那么Spring AOP会选择使用CGLIB来动态代理目标类,
CGLIB是通过继承的方式做的动态代理,因此如果某个类被标记为final,
那么它是无法使用CGLIB做动态代理的。
单例设计模式 : Spring 中的 Bean 默认都是单例的。可以设置成单例
模板方法模式 : Spring 中 jdbcTemplate、rabbitTemplate RestTemplate等
以 Template 结尾的对数据库操作的类,它们就使用到了模板方法模式。
模板就是一个方法,这个方法定义了算法的骨架,即将算法的实现定义成了一组步骤,
并将一些步骤延迟到子类中实现,子类重写抽象类中的模板方法实现算法骨架中特定的步骤。
模板模式可以不改变一个算法的结构即可重新定义该算法的某些特定步骤。
在模板方法模式中,我们可以将相同部分的代码放在父类中,而将不同的代码放入不同的子类中,
从而解决代码重复的问题。
SpringMVC中handlerAdaper用来适配器模式,
在SpringAOP中有一个很重要的功能就是使用的 Advice(通知) 来增强被代理类的功能,
Advice主要有MethodBeforeAdvice、AfterReturningAdvice、ThrowsAdvice这几种。
每个Advice都有对应的拦截器,
Spring需要将每个 Advice 都封装成对应的拦截器类型返回给容器,
所以需要使用适配器模式对 Advice 进行转换。对应的就有三个适配器。
Spring里的事件监听器用了观察者模式
策略模式:Spring的Resource类,针对不同的资源,Spring定义了不同的Resource类的实现类,以此实现不同的访问方式
UrlResource: 访问网络资源的实现类。
ClassPathResource: 访问类加载路径里资源的实现类。
FileSystemResource: 访问文件系统里资源的实现类。
ServletContextResource: 访问相对于 ServletContext 路径里的资源的实现类.
InputStreamResource: 访问输入流资源的实现类。
ByteArrayResource: 访问字节数组资源的实现类。
工作中使用的设计模式:
java实战,工作中常用到哪些设计模式_重庆阿汤哥的博客-CSDN博客_java 工作流 设计模式
混合使用太香了:策略设计模式+工厂模式+模板方法模式_哔哩哔哩_bilibili·
1:使用策略设计模式+工厂模式+模版方法模式,去优化复杂多重的if else判断
策略(Strategy)模式的定义:该模式定义了一系列算法,并将每个算法封装起来,使它们可以相互替换,且算法的变化不会影响使用算法的客户。策略模式属于对象行为模式,它通过对算法进行封装,把使用算法的责任和算法的实现分割开来,并委派给不同的对象对这些算法进行管理。
2:使用责任连模式,做多种参数校验时使用,
在责任链模式中,客户只需要将请求发送到责任链上即可,无须关心请求的处理细节和请求的传递过程,请求会自动进行传递。所以责任链将请求的发送者和请求的处理者解耦了。
3:使用模版方法模式,模板方法(Template Method)模式的定义如下:定义一个操作中的算法骨架,而将算法的一些步骤延迟到子类中,使得子类可以不改变该算法结构的情况下重定义该算法的某些特定步骤。它是一种类行为型模式
4:观察者模式,登陆注册时需要发短信,发消息通知用户。
定义:指多个对象间存在一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。这种模式有时又称作发布-订阅模式、模型-视图模式,它是对象行为型模式。
登陆注册应该是最常见的业务场景了。就拿注册来说事,我们经常会遇到类似的场景,就是用户注册成功后,我们给用户发一条消息,又或者发个邮件等等。这块代码会有什么问题呢? 如果产品又加需求:现在注册成功的用户,再给用户发一条短信通知。于是你又得改register方法的代码了。。。这是不是违反了开闭原则啦。
并且,如果调发短信的接口失败了,是不是又影响到用户注册了?!这时候,是不是得加个异步方法给通知消息才好。。。
实际上,我们可以使用观察者模式优化。
5:单例模式,枚举实现
其他问题
==和equals 区别 见收藏:
==比较基本类型,比较的是值,==比较引用类型,比较的是内存地址
equlas是Object类的方法,本质上与==一样,但是有些类重写了equals方法,比如String的equals被重写后,比较的是字符值。另外重写了equlas后,也必须重写hashcode()方法,
如果不这样做,你的类违反了hashCode的通用约定,对于HashSet, HashMap, HashTable等基于hash值的类就会出现问题。
java是值传递 见收藏
无论传递的是基本类型还是引用类型,本质上都是值传递;只不过基本类型是对变量值的拷贝,引用类型是对地址值的拷贝(地址值也是值)。
new string(“test”)创建了几个对象 见收藏
-
如果
abc这个字符串常量不存在,则创建两个对象,分别是abc这个字符串常量,以及new String这个实例对象。 -
如果
abc这字符串常量存在,则只会创建一个对象
String和StringBuffer和StringBuilder的区别:
String的值是不可变的,这就导致每次对String的操作都会生成新的String对象,不仅效率低下,而且浪费大量优先的内存空间
为了应对经常性的字符串相关的操作,就需要使用Java提供的其他两个操作字符串的类——StringBuilder类和StringBuffer类来对此种变化字符串进行处理。String 类不同的是,StringBuilder 类和StringBuffer的对象能够被多次的修改,并且不产生新的未使用对象。
StringBuilder:线程不安全,StringBuffer:线程安全。因为 StringBuffer 的所有公开方法都是 synchronized 修饰的,而 StringBuilder 并没有 synchronized 修饰。
StringBuilder 的性能要远大于 StringBuffer。单线程场景一般常用StringBuilder。
StringBuffer 适用于用在多线程操作同一个 StringBuffer 的场景,如果是单线程场合 StringBuilder 更适合。
String的方法:

三、熟悉Spring、SpringMVC、SpringBoot、Springcloud、Mybatis、swagger等常用框架;
Spring理解:
核心博客:
SpringBoot启动过程详解_启动一个springboot项目_keep one's resolveY的博客-CSDN博客
Spring容器的启动流程:
详细内容可以阅读这篇文章:Spring容器的启动流程_张维鹏的博客-CSDN博客
(1)初始化Spring容器,注册内置的BeanPostProcessor的BeanDefinition到容器中:
① 实例化BeanFactory【DefaultListableBeanFactory】工厂,用于生成Bean对象
② 实例化BeanDefinitionReader注解配置读取器,用于对特定注解(如@Service、@Repository)的类进行读取转化成 BeanDefinition 对象,(BeanDefinition 是 Spring 中极其重要的一个概念,它存储了 bean 对象的所有特征信息,如是否单例,是否懒加载,factoryBeanName 等)
③ 实例化ClassPathBeanDefinitionScanner路径扫描器,用于对指定的包目录进行扫描查找 bean 对象
(2)将配置类的BeanDefinition注册到容器中:
(3)调用refresh()方法刷新容器:
① prepareRefresh()刷新前的预处理:
② obtainFreshBeanFactory():获取在容器初始化时创建的BeanFactory:
③ prepareBeanFactory(beanFactory):BeanFactory的预处理工作,向容器中添加一些组件:
④ postProcessBeanFactory(beanFactory):子类重写该方法,可以实现在BeanFactory创建并预处理完成以后做进一步的设置
⑤ invokeBeanFactoryPostProcessors(beanFactory):在BeanFactory标准初始化之后执行BeanFactoryPostProcessor的方法,即BeanFactory的后置处理器:
⑥ registerBeanPostProcessors(beanFactory):向容器中注册Bean的后置处理器BeanPostProcessor,它的主要作用是干预Spring初始化bean的流程,从而完成代理、自动注入、循环依赖等功能
⑦ initMessageSource():初始化MessageSource组件,主要用于做国际化功能,消息绑定与消息解析:
⑧ initApplicationEventMulticaster():初始化事件派发器,在注册监听器时会用到:
⑨ onRefresh():留给子容器、子类重写这个方法,在容器刷新的时候可以自定义逻辑
⑩ registerListeners():注册监听器:将容器中所有的ApplicationListener注册到事件派发器中,并派发之前步骤产生的事件:
⑪ finishBeanFactoryInitialization(beanFactory):初始化所有剩下的单实例bean,核心方法是preInstantiateSingletons(),会调用getBean()方法创建对象;
⑫ finishRefresh():发布BeanFactory容器刷新完成事件:
BeanFactory和ApplicationContext有什么区别?
BeanFactory和ApplicationContext是Spring的两大核心接口,都可以当做Spring的容器。
(1)BeanFactory是Spring里面最底层的接口,是IoC的核心,定义了IoC的基本功能,包含了各种Bean的定义、加载、实例化,依赖注入和生命周期管理。ApplicationContext接口作为BeanFactory的子类,除了提供BeanFactory所具有的功能外,还提供了更完整的框架功能:
继承MessageSource,因此支持国际化。
资源文件访问,如URL和文件(ResourceLoader)。
载入多个(有继承关系)上下文(即同时加载多个配置文件) ,使得每一个上下文都专注于一个特定的层次,比如应用的web层。
提供在监听器中注册bean的事件。
(2)①BeanFactroy采用的是延迟加载形式来注入Bean的,只有在使用到某个Bean时(调用getBean()),才对该Bean进行加载实例化。这样,我们就不能提前发现一些存在的Spring的配置问题。如果Bean的某一个属性没有注入,BeanFacotry加载后,直至第一次使用调用getBean方法才会抛出异常。
②ApplicationContext,它是在容器启动时,一次性创建了所有的Bean。这样,在容器启动时,我们就可以发现Spring中存在的配置错误,这样有利于检查所依赖属性是否注入。
③ApplicationContext启动后预载入所有的单实例Bean,所以在运行的时候速度比较快,因为它们已经创建好了。相对于BeanFactory,ApplicationContext 唯一的不足是占用内存空间,当应用程序配置Bean较多时,程序启动较慢。
(3)BeanFactory和ApplicationContext都支持BeanPostProcessor、BeanFactoryPostProcessor的使用,但两者之间的区别是:BeanFactory需要手动注册,而ApplicationContext则是自动注册。
(4)BeanFactory通常以编程的方式被创建,ApplicationContext还能以声明的方式创建,如使用ContextLoader。
FactoryBean存在的意义:
一般情况下,Spring通过反射机制利用bean的class属性指定支线类去实例化bean,在某些情况下,实例化Bean过程比较复杂,如果按照传统的方式,则需要在bean中提供大量的配置信息。配置方式的灵活性是受限的,这时采用编码的方式可能会得到一个简单的方案。Spring为此提供了一个org.springframework.bean.factory.FactoryBean的工厂类接口,用户可以通过实现该接口定制实例化Bean的逻辑。FactoryBean接口对于Spring框架来说占用重要的地位,Spring自身就提供了70多个FactoryBean的实现。它们隐藏了实例化一些复杂bean的细节,给上层应用带来了便利。从Spring3.0开始,FactoryBean开始支持泛型,即接口声明改为FactoryBean的形式
Spring中bean的生命周期及bean的扩展点总结_spring拓展点的bean如何先于普通bean_keep one's resolveY的博客-CSDN博客
Spring中BeanFactory和FactoryBean区别:
1)BeanFactory 是接口,提供了IOC容器最基本的形式,给具体的IOC容器的实现提供了规范,顶层接口。
2)FactoryBean 也是接口,为IOC容器中Bean的实现提供了更加灵活的方式,FactoryBean在IOC容器的基础上给Bean的实现加上了一个简单的工厂模式和装饰模式 ,我们可以在getObject()方法中灵活配置.
区别:FactoryBean是个Bean.在Spring中,所有的Bean都是由BeanFactory(也就是IOC容器)来进行管理的。但对FactoryBean而言,这个Bean不是简单的Bean,而是一个能生产或者修饰对象生成的工厂Bean,它的实现与设计模式中的工厂模式和修饰器模式类似
Spring中BeanFactory和FactoryBean详解_流烟默的博客-CSDN博客
BeanFactory与FactoryBean的区别_beanfactory和factorybean的区别_石头城程序猿的博客-CSDN博客
Spring Bean的生命周期?
简单来说,Spring Bean的生命周期只有四个阶段:实例化 Instantiation --> 属性赋值 Populate --> 初始化 Initialization --> 销毁 Destruction
但具体来说,Spring Bean的生命周期包含下图的流程:
(1)实例化Bean:
对于BeanFactory容器,当客户向容器请求一个尚未初始化的bean时,或初始化bean的时候需要注入另一个尚未初始化的依赖时,容器就会调用createBean进行实例化。
对于ApplicationContext容器,当容器启动结束后,通过获取BeanDefinition对象中的信息,实例化所有的bean。
(2)设置对象属性(依赖注入):实例化后的对象被封装在BeanWrapper对象中,紧接着,Spring根据BeanDefinition中的信息 以及 通过BeanWrapper提供的设置属性的接口完成属性设置与依赖注入。
(3)处理Aware接口:Spring会检测该对象是否实现了xxxAware接口,通过Aware类型的接口,可以让我们拿到Spring容器的一些资源:
①如果这个Bean实现了BeanNameAware接口,会调用它实现的setBeanName(String beanId)方法,传入Bean的名字;
②如果这个Bean实现了BeanClassLoaderAware接口,调用setBeanClassLoader()方法,传入ClassLoader对象的实例。
②如果这个Bean实现了BeanFactoryAware接口,会调用它实现的setBeanFactory()方法,传递的是Spring工厂自身。
③如果这个Bean实现了ApplicationContextAware接口,会调用setApplicationContext(ApplicationContext)方法,传入Spring上下文;
(4)BeanPostProcessor前置处理:如果想对Bean进行一些自定义的前置处理,那么可以让Bean实现了BeanPostProcessor接口,那将会调用postProcessBeforeInitialization(Object obj, String s)方法。
(5)InitializingBean:如果Bean实现了InitializingBean接口,执行afeterPropertiesSet()方法。
(6)init-method:如果Bean在Spring配置文件中配置了 init-method 属性,则会自动调用其配置的初始化方法。
(7)BeanPostProcessor后置处理:如果这个Bean实现了BeanPostProcessor接口,将会调用postProcessAfterInitialization(Object obj, String s)方法;由于这个方法是在Bean初始化结束时调用的,所以可以被应用于内存或缓存技术;
以上几个步骤完成后,Bean就已经被正确创建了,之后就可以使用这个Bean了。
(8)DisposableBean:当Bean不再需要时,会经过清理阶段,如果Bean实现了DisposableBean这个接口,会调用其实现的destroy()方法;
(9)destroy-method:最后,如果这个Bean的Spring配置中配置了destroy-method属性,会自动调用其配置的销毁方法。
如果对bean详细加载流程的感兴趣的读者,可以阅读这篇文章:Spring的Bean加载流程_张维鹏的博客-CSDN博客
Spring框架中的Bean是线程安全的么?如果线程不安全,那么如何处理?
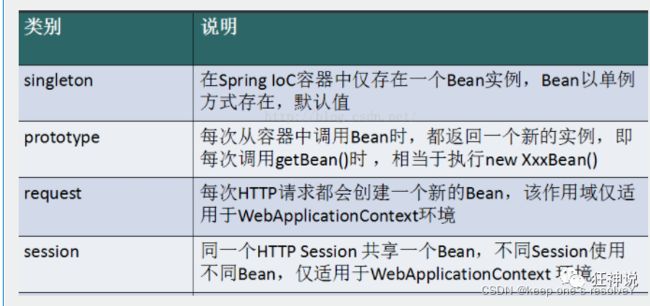
Spring容器本身并没有提供Bean的线程安全策略,因此可以说Spring容器中的Bean本身不具备线程安全的特性,但是具体情况还是要结合Bean的作用域来讨论。
(1)对于prototype作用域的Bean,每次都创建一个新对象,也就是线程之间不存在Bean共享,因此不会有线程安全问题。
(2)对于singleton作用域的Bean,所有的线程都共享一个单例实例的Bean,因此是存在线程安全问题的。但是如果单例Bean是一个无状态Bean,也就是线程中的操作不会对Bean的成员执行查询以外的操作,那么这个单例Bean是线程安全的。比如Controller类、Service类和Dao等,这些Bean大多是无状态的,只关注于方法本身。
有状态Bean(Stateful Bean) :就是有实例变量的对象,可以保存数据,是非线程安全的。
无状态Bean(Stateless Bean):就是没有实例变量的对象,不能保存数据,是不变类,是线程安全的。
对于有状态的bean(比如Model和View),就需要自行保证线程安全,最浅显的解决办法就是将有状态的bean的作用域由“singleton”改为“prototype”。
也可以采用ThreadLocal解决线程安全问题,为每个线程提供一个独立的变量副本,不同线程只操作自己线程的副本变量。
ThreadLocal和线程同步机制都是为了解决多线程中相同变量的访问冲突问题。同步机制采用了“时间换空间”的方式,仅提供一份变量,不同的线程在访问前需要获取锁,没获得锁的线程则需要排队。而ThreadLocal采用了“空间换时间”的方式。ThreadLocal会为每一个线程提供一个独立的变量副本,从而隔离了多个线程对数据的访问冲突。因为每一个线程都拥有自己的变量副本,从而也就没有必要对该变量进行同步了。
三级缓存解决循环依赖:
解决的核心原理就是:在对象实例化之后,依赖注入之前,Spring提前暴露的Bean实例的引用在第三级缓存中进行存储。
面试官:”Spring是如何解决的循环依赖?“
答:Spring通过三级缓存解决了循环依赖,其中一级缓存为单例池(singletonObjects),二级缓存为早期曝光对象earlySingletonObjects,三级缓存为早期曝光对象工厂(singletonFactories)。当A、B两个类发生循环引用时,在A完成实例化后,就使用实例化后的对象去创建一个对象工厂,并添加到三级缓存中,如果A被AOP代理,那么通过这个工厂获取到的就是A代理后的对象,如果A没有被AOP代理,那么这个工厂获取到的就是A实例化的对象。当A进行属性注入时,会去创建B,同时B又依赖了A,所以创建B的同时又会去调用getBean(a)来获取需要的依赖,此时的getBean(a)会从缓存中获取,第一步,先获取到三级缓存中的工厂;第二步,调用对象工工厂的getObject方法来获取到对应的对象,得到这个对象后将其注入到B中。紧接着B会走完它的生命周期流程,包括初始化、后置处理器等。当B创建完后,会将B再注入到A中,此时A再完成它的整个生命周期。至此,循环依赖结束!
面试官:”为什么要使用三级缓存呢?二级缓存能解决循环依赖吗?“
答:如果要使用二级缓存解决循环依赖,意味着所有Bean在实例化后就要完成AOP代理,这样违背了Spring设计的原则,Spring在设计之初就是通过AnnotationAwareAspectJAutoProxyCreator这个后置处理器来在Bean生命周期的最后一步来完成AOP代理,而不是在实例化后就立马进行AOP代理。
1).从一级缓存中获取,若为空,则检查是否在创建中
2).检查的时候要加锁,防止并发创建
3).从二级bean中获取bean,如果正在加载,则不处理,否则调用addSingletonFactory 方法将对应的objectFactory 初始化策略存储在 singletonFactories,也就是三级缓存中,三级缓存存储的也是早期bean。在解决循环依赖中,三级缓存是可以对早期的类对象进行自定义处理,将处理完的对象,放在二级缓存中,若还有循环依赖的处理,拿的是二级循环中的对象。
(优质)Spring常见面试题总结(超详细回答)_张维鹏的博客-CSDN博客_spring面试题
IOC
控制反转,不用new对象,xml还有注解的方式通过工厂模式+反射去new对象,完成解耦。
简单工厂模式又叫做静态工厂方法(StaticFactory Method)模式,但不属于23种GOF设计模式之一。
简单工厂模式的实质是由一个工厂类根据传入的参数,动态决定应该创建哪一个产品类。
spring中的BeanFactory就是简单工厂模式的体现,根据传入一个唯一的标识来获得bean对象,但是否是在传入参数后创建还是传入参数前创建这个要根据具体情况来定。
如下配置,就是在 HelloItxxz 类中创建一个 itxxzBean,xml文件的配置
Hello! 这是singletonBean!value>
Hello! 这是itxxzBean! value>
1.1 实现方式
- Spring使用工厂模式可以通过
BeanFactory或ApplicationContext创建 bean 对象。
两者对比:
BeanFactory:延迟注入(使用到某个 bean 的时候才会注入),相比于BeanFactory来说会占用更少的内存,程序启动速度更快。ApplicationContext:容器启动的时候,不管你用没用到,一次性创建所有 bean 。BeanFactory仅提供了最基本的依赖注入支持,ApplicationContext扩展了BeanFactory,除了有BeanFactory的功能还有额外更多功能,所以一般开发人员使用ApplicationContext会更多。
ApplicationContext的三个实现类:
ClassPathXmlApplication:把上下文文件当成类路径资源。FileSystemXmlApplication:从文件系统中的 XML 文件载入上下文定义信息。XmlWebApplicationContext:从Web系统中的XML文件载入上下文定义信息。
1.2 实现原理(spring是如何加载bean的通过xml文件)
(1)bean容器的启动阶段:
- 读取bean的xml配置文件,将bean元素分别转换成一个BeanDefinition对象。
- 然后通过BeanDefinitionRegistry将这些bean注册到beanFactory中,保存在它的一个ConcurrentHashMap中。
- 将BeanDefinition注册到了beanFactory之后,在这里Spring为我们提供了一个扩展的切口,允许我们通过实现接口BeanFactoryPostProcessor 在此处来插入我们定义的代码。典型的例子就是:PropertyPlaceholderConfigurer,我们一般在配置数据库的dataSource时使用到的占位符的值,就是它注入进去的。
(2)容器中bean的实例化阶段:
实例化阶段主要是通过反射或者CGLIB对bean进行实例化,在这个阶段Spring又给我们暴露了很多的扩展点:
- 各种的Aware接口 ,比如 BeanFactoryAware,对于实现了这些Aware接口的bean,在实例化bean时Spring会帮我们注入对应的BeanFactory的实例。
- BeanPostProcessor接口 ,实现了BeanPostProcessor接口的bean,在实例化bean时Spring会帮我们调用接口中的方法。
- InitializingBean接口 ,实现了InitializingBean接口的bean,在实例化bean时Spring会帮我们调用接口中的方法。
- DisposableBean接口 ,实现了BeanPostProcessor接口的bean,在该bean死亡时Spring会帮我们调用接口中的方法。
1.3 设计意义
- 松耦合。 可以将原来硬编码的依赖,通过Spring这个beanFactory这个工厂来注入依赖,也就是说原来只有依赖方和被依赖方,现在我们引入了第三方——spring这个beanFactory,由它来解决bean之间的依赖问题,达到了松耦合的效果.(IOC)
- bean的额外处理。 通过Spring接口的暴露,在实例化bean的阶段我们可以进行一些额外的处理,这些额外的处理只需要让bean实现对应的接口即可,那么spring就会在bean的生命周期调用我们实现的接口来处理该bean。[非常重要]
Bean的生命周期:
1. 实例化 Bean (为 Bean 分配内存空间)
2. 设置属性 ( Bean 注入和装配)
3.Bean 初始化
- 实现了各种 Aware 通知的方法,如 BeanNameAware、BeanFactoryAware、
- ApplicationContextAware 的接口方法;
- 执行 BeanPostProcessor 初始化前置方法;
- 执行 @PostConstruct 初始化方法,依赖注入操作之后被执行;
- 执行自己指定的 init-method 方法(如果有指定的话);
- 执行 BeanPostProcessor 初始化后置方法。
4. 使用 Bean
5. 销毁 Bean

AOP
面向切面编程,底层是动态代理
mybatis事务就是通过aop方式实现的,还有日志的实现方式也是通过aop。
工作中你有用过aop编程吗?
我们的菜单按钮权限控制就是通过aop实现的。
AOP编程:
使用@Aspect切面注解,@Pointcut对应切点(execution切点函数或@annotation()注解)
具体的前后置方法的注解:
@Before
标识一个前置增强方法,相当于BeforeAdvice的功能
@AfterReturning
后置增强,相当于AfterReturningAdvice,方法退出时执行
@AfterThrowing
异常抛出增强,相当于ThrowsAdvice
@After
final增强,不管是抛出异常或者正常退出都会执行
@Around
环绕增强,相当于MethodInterceptor

我们需要指定顺序,最简单的方式就是在Aspect切面类上加上@Order(1)注解即可,order越小最先执行,也就是位于最外层。像一些全局处理的就可以把order设小一点,具体到某个细节的就设大一点。
SpringBoot_AOP增强编程_keep one's resolveY的博客-CSDN博客
拦截器过滤器:
若依登陆过程及过滤器拦截器的使用:
用户登陆接口:1、把用户信息通过uuid即token作为key,存储在缓存中,并设置过期时间,2、通过jwt存储token,userId,userName在map中,设置过期时间,通过jwt创建一个编码后的access_token和expireTime,并返回token在前端
过滤器:用户前端传递的access_token通过Jwt解析,尝试获取userkey(即token),userid,username
并判断是否过期,为空等。如果异常即刻报错,否则将解析的userkey,userid,username纳入请求头中,请求接着交给拦截器。
拦截器:拦截器从请求头中获取userkey,userid,username,通过userkey从缓存中获取用户信息,并刷新缓存中用户信息的过期时间。并将用户信息加入到本地的TransmittableThreadLocal
过滤器 和 拦截器 均体现了AOP的编程思想,若依先登录鉴权先经过过滤器,后经过拦截器。
过滤器:
直接实现Filter 接口:
-
init():该方法在容器启动初始化过滤器时被调用,它在Filter的整个生命周期只会被调用一次。注意:这个方法必须执行成功,否则过滤器会不起作用。 -
doFilter():容器中的每一次请求都会调用该方法,FilterChain用来调用下一个过滤器Filter。 -
destroy(): 当容器销毁 过滤器实例时调用该方法,一般在方法中销毁或关闭资源,在过滤器Filter的整个生命周期也只会被调用一次
过滤器 是基于函数回调的,这个接口是在Servlet规范中定义的,只能在web程序中使用;
拦截器:
请求的拦截是通过HandlerInterceptor 来实现,看到HandlerInterceptor 接口中也定义了三个方法。
-
preHandle():这个方法将在请求处理之前进行调用。注意:如果该方法的返回值为false,将视为当前请求结束,不仅自身的拦截器会失效,还会导致其他的拦截器也不再执行。 -
postHandle():只有在preHandle()方法返回值为true时才会执行。会在Controller 中的方法调用之后,DispatcherServlet 返回渲染视图之前被调用。 有意思的是:postHandle()方法被调用的顺序跟preHandle()是相反的,先声明的拦截器preHandle()方法先执行,而postHandle()方法反而会后执行。 -
afterCompletion():只有在preHandle()方法返回值为true时才会执行。在整个请求结束之后, DispatcherServlet 渲染了对应的视图之后执行。
拦截器 则是基于Java的反射机制(动态代理)实现的。
过滤器和拦截器详解_keep one's resolveY的博客-CSDN博客_过滤器、拦截器
全局异常处理:
使用 @RestControllerAdvice+@ExceptionHandler注解能够进行近似全局异常处理,这种方式推荐使用。
一般说它只能处理控制器中抛出的异常,这种说法并不准确,其实它能处理DispatcherServlet.doDispatch方法中DispatcherServlet.processDispatchResult方法之前捕捉到的所有异常,包括:拦截器、参数绑定(参数解析、参数转换、参数校验)、控制器、返回值处理等模块抛出的异常。
此种方式是通过异常处理器实现的,使用HandlerExceptionResolverComposite异常处理器中的ExceptionHandlerExceptionResolver异常处理器处理的。
SpringBoot 全局异常处理_keep one's resolveY的博客-CSDN博客_springboot处理全局异常
package com.ruoyi.common.security.handler;
import javax.servlet.http.HttpServletRequest;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.validation.BindException;
import org.springframework.web.HttpRequestMethodNotSupportedException;
import org.springframework.web.bind.MethodArgumentNotValidException;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.RestControllerAdvice;
import com.ruoyi.common.core.constant.HttpStatus;
import com.ruoyi.common.core.exception.DemoModeException;
import com.ruoyi.common.core.exception.InnerAuthException;
import com.ruoyi.common.core.exception.ServiceException;
import com.ruoyi.common.core.exception.auth.NotPermissionException;
import com.ruoyi.common.core.exception.auth.NotRoleException;
import com.ruoyi.common.core.utils.StringUtils;
import com.ruoyi.common.core.web.domain.AjaxResult;
/**
* 全局异常处理器
*
* @author ruoyi
*/
@RestControllerAdvice
public class GlobalExceptionHandler
{
private static final Logger log = LoggerFactory.getLogger(GlobalExceptionHandler.class);
/**
* 权限码异常
*/
@ExceptionHandler(NotPermissionException.class)
public AjaxResult handleNotPermissionException(NotPermissionException e, HttpServletRequest request)
{
String requestURI = request.getRequestURI();
log.error("请求地址'{}',权限码校验失败'{}'", requestURI, e.getMessage());
return AjaxResult.error(HttpStatus.FORBIDDEN, "没有访问权限,请联系管理员授权");
}
/**
* 角色权限异常
*/
@ExceptionHandler(NotRoleException.class)
public AjaxResult handleNotRoleException(NotRoleException e, HttpServletRequest request)
{
String requestURI = request.getRequestURI();
log.error("请求地址'{}',角色权限校验失败'{}'", requestURI, e.getMessage());
return AjaxResult.error(HttpStatus.FORBIDDEN, "没有访问权限,请联系管理员授权");
}
/**
* 请求方式不支持
*/
@ExceptionHandler(HttpRequestMethodNotSupportedException.class)
public AjaxResult handleHttpRequestMethodNotSupported(HttpRequestMethodNotSupportedException e,
HttpServletRequest request)
{
String requestURI = request.getRequestURI();
log.error("请求地址'{}',不支持'{}'请求", requestURI, e.getMethod());
return AjaxResult.error(e.getMessage());
}
/**
* 业务异常
*/
@ExceptionHandler(ServiceException.class)
public AjaxResult handleServiceException(ServiceException e, HttpServletRequest request)
{
log.error(e.getMessage(), e);
Integer code = e.getCode();
return StringUtils.isNotNull(code) ? AjaxResult.error(code, e.getMessage()) : AjaxResult.error(e.getMessage());
}
/**
* 拦截未知的运行时异常
*/
@ExceptionHandler(RuntimeException.class)
public AjaxResult handleRuntimeException(RuntimeException e, HttpServletRequest request)
{
String requestURI = request.getRequestURI();
log.error("请求地址'{}',发生未知异常.", requestURI, e);
return AjaxResult.error(e.getMessage());
}
/**
* 系统异常
*/
@ExceptionHandler(Exception.class)
public AjaxResult handleException(Exception e, HttpServletRequest request)
{
String requestURI = request.getRequestURI();
log.error("请求地址'{}',发生系统异常.", requestURI, e);
return AjaxResult.error(e.getMessage());
}
/**
* 自定义验证异常
*/
@ExceptionHandler(BindException.class)
public AjaxResult handleBindException(BindException e)
{
log.error(e.getMessage(), e);
String message = e.getAllErrors().get(0).getDefaultMessage();
return AjaxResult.error(message);
}
/**
* 自定义验证异常
*/
@ExceptionHandler(MethodArgumentNotValidException.class)
public Object handleMethodArgumentNotValidException(MethodArgumentNotValidException e)
{
log.error(e.getMessage(), e);
String message = e.getBindingResult().getFieldError().getDefaultMessage();
return AjaxResult.error(message);
}
/**
* 内部认证异常
*/
@ExceptionHandler(InnerAuthException.class)
public AjaxResult handleInnerAuthException(InnerAuthException e)
{
return AjaxResult.error(e.getMessage());
}
/**
* 演示模式异常
*/
@ExceptionHandler(DemoModeException.class)
public AjaxResult handleDemoModeException(DemoModeException e)
{
return AjaxResult.error("演示模式,不允许操作");
}
}
Springboot的注解:
@ComponentScan 作用:自动扫描并加载符合条件的组件或者bean , 将这个bean定义加载到IOC容器中
@EnableAutoConfiguration 开启自动配置功能
@SpringBootConfiguration 作用:SpringBoot的配置类 ,标注在某个类上 , 表示这是一个SpringBoot的配置类;
@SpringBootApplication 标注在某个类上说明这个类是SpringBoot的主配置类
@AutoConfigurationPackage :自动配置包
@RestController :修饰类,该控制器会返回Json数据
@RequestMapping("/path") :修饰类,该控制器的请求路径
@Autowired : 修饰属性,按照类型进行依赖注入
@PathVariable : 修饰参数,将路径值映射到参数上
@ResponseBody :修饰方法,该方法会返回Json数据
@RequestBody(需要使用Post提交方式) :修饰参数,将Json数据封装到对应参数中
@Controller@Service@Compont: 将类注册到ioc容器
@Transaction:开启事务
Springboot自动配置原理
启动类@SpringbootApplication注解下,有三个关键注解
(1)@springbootConfiguration:表示启动类是一个自动配置类
(2)@CompontScan:扫描启动类所在包外的组件到容器中
(3)@EnableConfigutarion:最关键的一个注解,他拥有两个子注解,其中@AutoConfigurationpackageu会将启动类所在包下的所有组件到容器中,@Import会导入一个自动配置文件选择器,他会去加载META_INF目录下的spring.factories文件,这个文件中存放很大自动配置类的全类名,这些类会根据元注解的装配条件生效,生效的类就会被实例化,加载到ioc容器中
过程:@springbootConfiguration--@EnableAutoConfiguration--@AutoConfigurationPackage+ @Import(AutoConfigurationImportSelector.class)--自动配置文件选择器,他会去加载META_INF目录下的spring.factories文件,加载到ioc容器中
自动配置真正实现是从classpath中搜寻所有的META-INF/spring.factories配置文件 ,并将其中对应的 org.springframework.boot.autoconfigure. 包下的配置项,通过反射实例化为对应标注了 @Configuration的JavaConfig形式的IOC容器配置类 , 然后将这些都汇总成为一个实例并加载到IOC容器中。
Spring的bean是线程安全的吗?
spring的默认bean作用域是单例的,单例的bean不是线程安全的,但是开发中大部分的bean都是无状态的,不具备存储功能,比如controller、service、dao,他们不需要保证线程安全。
如果要保证线程安全,可以将bean的作用域改为prototype,比如像Model View。
另外还可以采用ThreadLocal来解决线程安全问题。ThreadLocal为每个线程保存一个副本变量,每个线程只操作自己的副本变量。
mybatis+mybatisplus:
注解:@Transactional在方法上写,spring默认抛出RunTimeException 或 Error时回滚事务,其他异常不会回滚事务,如果在事务中抛出了其他异常,却希望spring能回滚事务,就需要指定rollbackFor属性,实际一般这样使用:@Transactional(rollbackFor=Exception.class);这个必须这么写
Spring事务失效原因:
(1)事务方法所在的类没有加载到容器中
(2)事务方法不是public类型,静态的方法
(3)同一类中,一个没有添加事务的方法调用另外以一个添加事务的方法,事务不生效;还有自调用
(4)spring事务默认只回滚运行时异常,可以用rollbackfor属性设置
(5)业务自己捕获了异常,事务会认为程序正常秩序
使用注解开发:
-
@select ()
-
@update ()
-
@Insert ()
-
@delete ()
多对一:
//javaType="teacher"因为mybatis核心配置文件中有全限定名的别名
一对多:
动态sql:
if和where常用

sql片段:
1.使用SQL标签抽取公共部分
title = #{title}
and author = #{author}
2.使用 include 引用sql片段
sql片段扩展:
mybatis xml 文件中对于重复出现的sql 片段可以使用标签提取出来,在使用的地方使用标签引用即可具体用法如下:
id,name
在中可以使用${}传入参数,如下:
${tableName}.id,${tableName}.name
对于多个xml文件需要同时引用一段相同的 可以在某个xml 中定义这个 sql 代码片段,在需要引用的地方使用全称引用即可,例子如下:
ShareMapper.xml
id,name
CustomMapper.xml
- 默认情况下,一级缓存开启(SqlSession级别的缓存,也称为本地缓存)
- 二级缓存需要手动开启和配置,他是基于namespace级别的缓存。 举例:namespace="com.yff.dao.BlogMapper" namespace级别即接口级别
Mybatis常见面试题总结_张维鹏的博客-CSDN博客_mybatis面试题
Mybatis延迟加载的概念:
延迟加载:就是在需要用到数据时才进行加载,不需要用到数据时就不加载数据。延迟加载也称懒加载。可以通过配置开启懒加载或立即加载,延迟加载主要用在一对多和多对多的场景。
好处:先从单表查询,需要时再从关联表去关联查询,大大提高数据库性能,因为查询单表要比关联查询多张表速度要快。
熟悉springcloud alibaba、gateway、nacos、openfeign、swagger、dynamic;
了解eureka、dubbo、zookeeper、xxl-job、quartz等
gateway
Spring Cloud Gateway面试攻略,微服务网关的作用以及案例_MateCloud微服务的博客-CSDN博客_gateway网关面试题
nacos
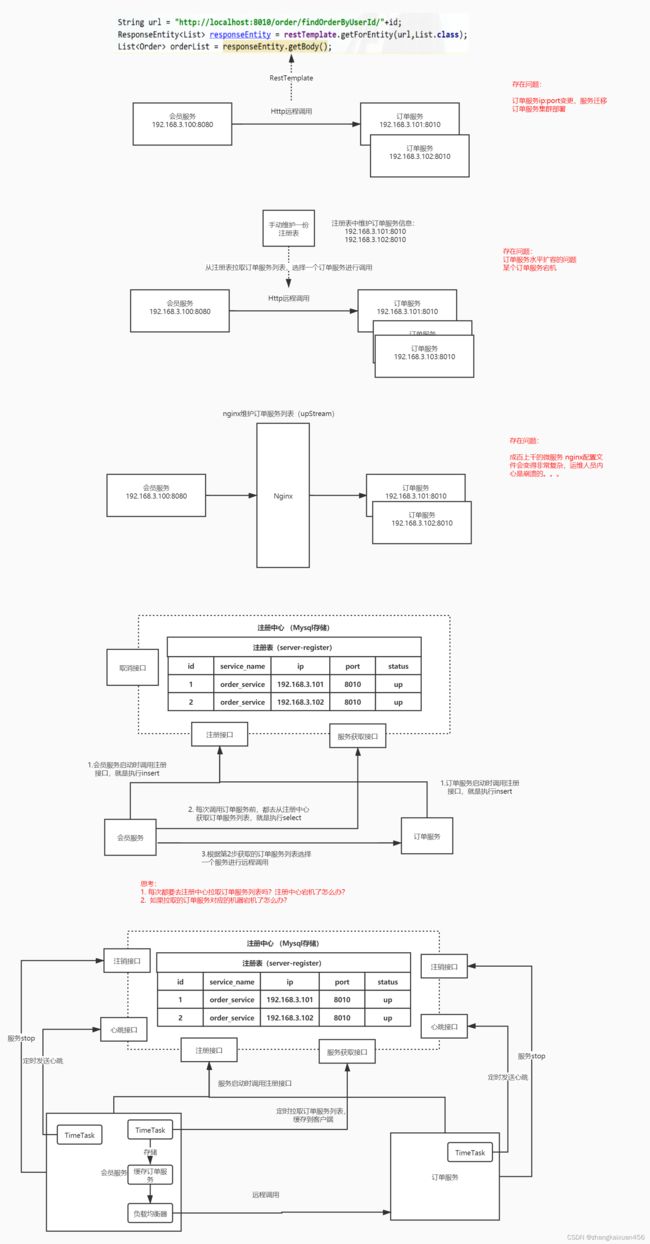
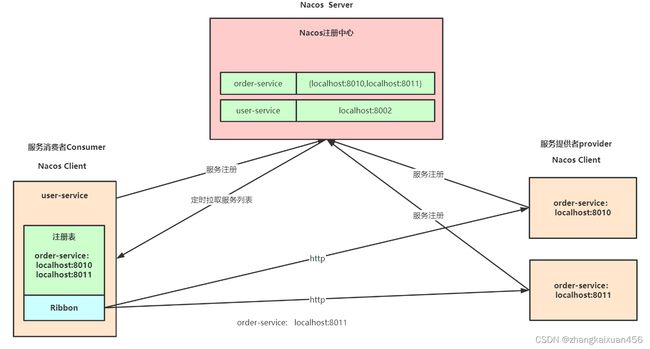
nacos注册中心面试总结_zhangkaixuan456的博客-CSDN博客_nacos面试
OpenFeign
feign和openFeign区别和openFeign教程_keep one's resolveY的博客-CSDN博客_feign和openfeign区别
feign的本质也是扩展了Ribbon。Ribbon原来的controller,通过Ribbon+restTemplate实现通信和负载均衡,使用feign通信省略了restTemplate。
springcloud使用restful模板去远程调用方法,而rpc框架dubbo需要接口一致并且远程引用,这是本质区别
对比:
| Dubbo | SpringCloud | |
|---|---|---|
| 服务注册中心 | Zookeeper | Spring Cloud Netfilx Eureka |
| 服务调用方式 | RPC | REST API |
| 服务监控 | Dubbo-monitor | Spring Boot Admin |
| 断路器 | 不完善 | Spring Cloud Netfilx Hystrix |
| 服务网关 | 无 | Spring Cloud Netfilx Zuul |
| 分布式配置 | 无 | Spring Cloud Config |
| 服务跟踪 | 无 | Spring Cloud Sleuth |
| 消息总栈 | 无 | Spring Cloud Bus |
| 数据流 | 无 | Spring Cloud Stream |
| 批量任务 | 无 | Spring Cloud Task |
最大区别:Spring Cloud 抛弃了Dubbo的RPC通信,采用的是基于HTTP的REST方式
严格来说,这两种方式各有优劣。虽然从一定程度上来说,后者牺牲了服务调用的性能,但也避免了上面提到的原生RPC带来的问题。而且REST相比RPC更为灵活,服务提供方和调用方的依赖只依靠一纸契约,不存在代码级别的强依赖,这个优点在当下强调快速演化的微服务环境下,显得更加合适。
dynamic
SpringBoot实现多数据源的两种方式_keep one's resolveY的博客-CSDN博客_druid dynamic
使用 @DS 注解切换数据源
Swagger:
我们集成了swagger管理我们的api文档,我们编写swagger配置类,并在上面使用@EnableSwagger2// 开启Swagger2的自动配置
1、用于controller类上:
注解 说明
@Api 对请求类的说明
2、用于方法上面(说明参数的含义):
注解 说明
@ApiOperation 方法的说明
@ApiImplicitParams、@ApiImplicitParam 方法的参数的说明;@ApiImplicitParams 用于指定单个参数的说明
3、用于方法上面(返回参数或对象的说明):
注解 说明
@ApiResponses、@ApiResponse 方法返回值的说明 ;@ApiResponses 用于指定单个参数的说明
4、对象类:
注解 说明
@ApiModel 用在JavaBean类上,说明JavaBean的 用途
@ApiModelProperty 用在JavaBean类的属性上面,说明此属性的的含议
eureka、 dubbo+zookeeper
1:dubbo(rpc通信框架:RPC就是要像调用本地的函数一样去调远程函数)zookeeper(dubbo官网建议使用zookeeper注册中心):
@Service //dubbo新版已更名@service注解为@dubboservice,必须添加@service注解
@Reference //远程引用指定的服务,他会按照全类名进行匹配,看谁给注册中心注册了这个全类名,新版本是:DubboReference
2:org.springframework.web.client.RestTemplate(spring通信框架)和Eureka(注册中心,Eureka是基于REST的服务)feign和Ribbon本质是一样的,都是RestTemplate。
3:Hystrix服务熔断或者降级
熔断和降级都是使用Hystrix
熔断:在SpringCloud框架里熔断机制通过Hystrix实现。Hystrix会监控微服务间调用的状况,当失败的调用到一定阀值缺省是5秒内20次调用失败,就会启动熔断机制
降级:可配置也可以直接关闭后,B和C暂时关闭一些服务功能,去承担A的部分服务,从而为A分担压力,叫做服务降级。若依使用降级!
定时任务
xxl-job的使用及简述原理_keep one's resolveY的博客-CSDN博客
SpringBoot定时任务整合Quartz_keep one's resolveY的博客-CSDN博客_若依框架quartz
Spring自带的定时任务:
异步注解:@Async ,@Enableasync注解主启动类开启异步 ,如果使用多线程实现比较麻烦(runable接口,callable接口)
定时任务:@Scheduled(cron=""),@EnableScheduling 在主启动类上开启, cron表达式
xxljob:
配置好configuration后,编写业务类继承IJobHandler 并使用类上注解
@JobHandler(value = "TestJob")即可
熟练掌握Mysql数据库语法及应用;redis,nginx,rabbitMQ
mysql
索引(B+树):聚集索引一般就是主键,非聚集索引就是其他的索引。
最左匹配原则:最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
a,ab,abc 用到索引
bc, b, c 没有从最左边开始
ac 不连续,如果不连续时,只用到了a列的索引,b列和c列都没有用到
复合索引的索引体积比单独索引的体积要小,而且只是一个索引树,相比单独列的索引要更加的节省时间复杂度和空间复杂度。
Explain 用法
使用方法:explain + sql 语句。
单列索引:
一个索引只包含单个列,但一个表中可以有多个单列索引。 这里不要搞混淆了
1:普通索引:MySQL中基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值,纯粹为了查询数据更快一 点。
2:唯一索引:索引列中的值必须是唯一的,但是允许为空值。
3:主键索引:是一种特殊的唯一索引,不允许有空值。(主键约束,就是一个主键索引)。
索引优化
0.不要使用select *,
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
2.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
3.应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
或
select id from t where num=10
union all
select id from t where num=20
参考:https://www.cnblogs.com/xiangxinhouse/p/6053134.html
4.in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)
对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
5.%在前的模糊查询 也将导致全表扫描:like “%aaa%” 不会使用索引而like “aaa%”可以使用索引。
select id from t where name like '%abc%'。
6.尽量避免在where条件中,不要在列上进行运算,对字段进行函数操作和加减乘除等表达式操作,
将导致索引失效而进行全表扫描
7.COUNT() 函数返回匹配指定条件的行数
7.1 count(*)和count(1)有什么区别
count(1),其实就是计算一共有多少符合条件的行。
1并不是表示第一个字段,而是表示一个固定值。
其实就可以想成表中有这么一个字段,这个字段就是固定值1,count(1),就是计算一共有多少个1.
同理,count(2),也可以,得到的值完全一样,count('x'),count('y')都是可以的。一样的理解方式。在你这个语句理都可以使用,返回的值完全是一样的。就是计数。
count(*),执行时会把星号翻译成字段的具体名字,效果也是一样的,不过多了一个翻译的动作,比固定值的方式效率稍微低一些。
7.2 count(*) 和 count(1)和count(列名)区别 执行效果上:
count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL
count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL
count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。
7.3 执行效率上:
列名为主键,count(列名)会比count(1)快
列名不为主键,count(1)会比count(列名)快
如果表多个列并且没有主键,则 count(1) 的执行效率优于 count(*)
如果有主键,则 select count(主键)的执行效率是最优的
如果表只有一个字段,则 select count(*)最优。1、索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 、delete、update 的效率
2、索引不会包含有NULL值的列:只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为NULL。
4、MySQL查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。
6、MySQL只针对以下的操作符才使用索引:<,<=,=,>,>=,between,in,以及某些时候的like(不以通配符%或_开头的情形)。而理论上每张表里面最多可创建16个索引,不过除非是数据量真的很多,否则过多的使用索引也不是那么好玩的
那些情况索引会失效
(1)where条件中有or,除非所有查询条件都有索引,否则失效
(2)like查询用%开头,索引失效
(3)索引列参与计算,索引失效
(4)违背最左匹配原则,索引失效
(5)索引字段发生类型转换,索引失效
(6)mysql觉得全表扫描更快时(数据少),索引失效
索引覆盖和索引下推理解
什么是快照读和当前读
快照读读取的是当前数据的可见版本,可能是会过期数据,不加锁的select就是快照都
当前读读取的是数据的最新版本,并且当前读返回的记录都会上锁,保证其他事务不会并发修改这条记录。如update、insert、delete、select for undate(排他锁)、select lockin share mode(共享锁) 都是当前读
慢查询的优化:
slow query log 慢查询日志
慢查询日志用来记录执行时间超过指定阈值的SQL语句,慢查询日志往往用于优化生产环境的SQL语句。可以通过以下语句查看慢查询日志是否开启以及日志的位置:
show variables like "%slow_query%";
慢查询日志的常用配置参数如下:
slow_query_log=1 #是否开启慢查询日志,0关闭,1开启
slow_query_log_file=/usr/local/mysql/mysql-8.0.20/data/slow-log.log #慢查询日志地址(5.6及以上版本)
long_query_time=1 #慢查询日志阈值,指超过阈值时间的SQL会被记录
log_queries_not_using_indexes #表示未走索引的SQL也会被记录
分析慢查询日志一般会用专门的日志分析工具。找出慢SQL后可以通过explain关键字进行SQL分析,找出慢的原因。
开启慢查询日志,然后 SET GLOBAL long_query_time=阈值;超过阈值的sql就会记录到慢查询日志当中。慢查询优化如下:
(1)分析sql语句,是否加载了不需要的数据列
(2)分析sql执行计划,字段有没有索引,索引是否失效,是否用对索引
(3)尽量将关联查询分解为单表查询,再将查询结果在程序中进行关联;
如果非要用关联查询的话,用联合查询来代替子查询,尽量将外连接转化为内连接(内连接取两表交集部分,左连接取左表全部右表匹部分,右连接取右表全部坐表匹部分),尽量让参与on条件的字段拥有索引
(4)分页查询时,如果偏移量太大,就查询主键id>=偏移量的n条数据。
(5)表中数据是否太大,是不是要分库分表
连表查询:
--LEFT Join
SELECT s.studentNo,studentName,SubjectNo,StudentResult
FROM student AS s
LEFT JOIN result AS r
ON s.studentNo = r.studentNo
--Right Join
SELECT s.studentNo,studentName,SubjectNo,StudentResult
FROM student AS s
RIGHT JOIN result AS r
ON s.studentNo = r.studentNo
SELECT s.studentNo,studentName,SubjectNo,StudentResult
FROM student AS s
INNER JOIN result AS r
ON s.studentNo=r.studentNo
通过上面3个查询得出结论:
内连接(INNER JOIN) :只连接匹配的行;
左外连接(LEFT JOIN或LEFT OUTER JOIN) :包含左边表的全部行
(不管右边的表中是否存在与它们匹配的行),以及右边表中全部匹配的行;
左表有右表没找到时自动填充null
右外连接(RIGHT JOIN或RIGHT OUTER JOIN) :包含右边表的全部行
(不管左边的表中是否存在与它们匹配的行),以及左边表中全部匹配的行;
右表有左表没找到时自动填充nullmysql事务
MySql默认是隔离级别是可重复读(历史原因造成),Oracle,SqlServer 的默认事务隔离级别是读已提交(Read Commited);
一般互联网项目中mysql的事务隔离级别设置成 Read Commited 读已提交,因为实际工作中不需要可重复读,可重复读有多缺点(死锁概率高;在RR隔离级别下,条件列未命中索引会锁表!而在RC隔离级别下,只锁行;等等)
- 原子性(A):事务是最小单位,不可再分
- 一致性(C):事务要求所有的DML语句操作的时候,必须保证同时成功或者同时失败
- 隔离性(I):并发时,事务A和事务B之间具有隔离性
- 持久性(D):是事务的保证,事务终结的标志(内存的数据持久到硬盘文件中)
数据库的表设计
(1)抽取实体,如用户信息,商品信息,评论
(2)分析其中属性,如用户信息:姓名、性别...
(3)分析表与表之间的关联关系
第一范式:每个列都不可以再拆分。
第二范式:在第一范式的基础上,非主键列完全依赖于主键,而不能是依赖于主键的一部分。
第三范式:在第二范式的基础上,非主键列只依赖于主键,不依赖于其他非主键。
共享锁排他锁:(表锁行锁间隙锁)
共享锁(S):SELECT * FROM table_name WHERE ... LOCK IN SHARE MODE
排他锁(X):SELECT * FROM table_name WHERE ... FOR UPDATERedis:

redis配置类重写:
package com.haoyun.redisspringboot.config;
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import java.net.UnknownHostException;
@Configuration
@SuppressWarnings("all")
//镇压所有警告
public class RedisConfig {
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
// 默认的连接配置,和源码保持一致即可
RedisTemplate template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
// 序列化配置
// json序列化配置--Jackson
Jackson2JsonRedisSerializer 
redis缓存持久化策略:RDB(默认)和AOF
rdb比较快,aof体积大,效率慢,但是rdb可能会丢数据。
rdb规则:
save 900 1 # 如果900秒15分钟内 至少1个key修改 我们就进行持久化操作
save 300 10 # 如果300秒5分钟内 至少10个key修改 我们就 进行持久化操作
save 60 10000 # 如果60秒内 至少10000个key修改(高迸发) 进行持久化操作
RDB:
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的。这就确保了极高的性能。如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
AOF:
每当 Redis 执行一个改变数据集的命令时(比如 SET), 这个命令就会被追加到 AOF 文件的末尾。这样的话, 当 Redis 重新启时, 程序就可以通过重新执行 AOF 文件中的命令来达到重建数据集的目的。
RDB和AOF对比:
一、形式不同
1、rdb:rdb在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
2、aof:aof以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。
二、启动效率不同
1、rdb:通过fork子进程来协助完成数据持久化工作的,因此,如果当数据集较大时,可能会导致整个服务器停止服务几百毫秒,甚至是1秒钟。
2、aof:由子进程完成这些持久化的工作,可以极大地避免服务进程执行IO操作。如果数据集很大,aof的启动效率会更高。
三、安全性不同
1、rdb:系统一旦在定时持久化之前出现宕机现象,此前没有来得及写入磁盘的数据都将丢失。
2、aof:由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中即使出现宕机现象,也不会破坏日志文件中已经存在的内容。
Redis如何实现key的过期删除?
采用的定期过期+惰性过期
定期删除 :Redis 每隔一段时间从设置过期时间的 key 集合中,随机抽取一些 key ,检查是否过期,如果已经过期做删除处理。
惰性删除 :Redis 在 key 被访问的时候检查 key 是否过期,如果过期则删除。
5.Redis缓存穿透如何解决?
缓存穿透是指频繁请求客户端和缓存中都不存在的数据,缓存永远不生效,请求都到达了数据库。
解决方案:
(1)在接口上做基础校验,比如id<=0就拦截
(2)缓存空对象:找不到的数据也缓存起来,并设置过期时间,可能会造成短期不一致
(3)布隆过滤器:在客户端和缓存之间添加一个过滤器,拦截掉一定不存在的数据请求
6.Redis如何解决缓存击穿?
缓存击穿是值一个key非常热点,key在某一瞬间失效,导致大量请求到达数据库
解决方案:
(1)设置热点数据永不过期
(2)给缓存重建的业务加上互斥锁,缺点是性能低
7.Redis如何解决缓存雪崩?
缓存雪崩是值某一时间Key同时失效或redis宕机,导致大量请求到达数据库
解决方案:
(1)搭建集群保证高可用
(2)进行数据预热,给不同的key设置随机的过期时间
(3)给缓存业务添加限流降级,通过加锁或队列控制操作redis的线程数量
(4)给业务添加多级缓存
8.Redis分布式锁的实现原理
原理是使用setnx+setex命令来实现,但是会有一系列问题:
(1)任务时常超过缓存时间,锁自动释放。可以使用Redision看门狗解决
(2)加锁和释放锁的不是同一线程。可以在Value中存入uuid,删除时进行验证。但是要注意验证锁和删除锁也不是一个原子性操作,可以用lua脚本使之成为原子性操作
(3)不可重入。可以使用Redision解决(实现机制类似AQS,计数)
(4)redis集群下主节点宕机导致锁丢失。使用红锁解决
9.Redis集群方案
(1)主从模式:个master节点,多个slave节点,master节点宕机slave自动变成主节点
(2)哨兵模式:在主从集群基础上添加哨兵节点或哨兵集群,用于监控master节点健康状态,通过投票机制选择slave成为主节点
(3)分片集群:主从模式和哨兵模式解决了并发读的问题,但没有解决并发写的问题,因此有了分片集群。分片集群有多个master节点并且不同master保存不同的数据,master之间通过ping相互监测健康状态。客户端请求任意一个节点都会转发到正确节点,因为每个master都被映射到0-16384个插槽上,集群的key是根据key的hash值与插槽绑定
10.Redis集群主从同步原理
主从同步第一次是全量同步:slave第一次请求master节点会根据replid判断是否是第一次同步,是的话master会生成RDB发送给slave。
后续为增量同步:在发送RDB期间,会产生一个缓存区间记录发送RDB期间产生的新的命令,slave节点在加载完后,会持续读取缓存区间中的数据
11.Redis缓存一致性解决方案
5分钟掌握缓存和数据库一致性问题
适用于:流量和并发不高的常规性缓存:
读:直接从缓存拿,缓存没有从数据库拿,并存入缓存
写:先更新db,再删除缓存
更新数据库时把缓存给删除是最优方案,可以更大概率避免并发问题,但是依旧会有缓存删除失败的问题。可以使用分布式事务,或者在删除失败后把key发送到rabbitMQ中进行异步删除重试
12.Redis内存淘汰策略
当内存不足时按设定好的策略进行淘汰,策略有(1)淘汰最久没使用的(2)淘汰一段时间内最少使用的(3)淘汰快要过期的
缓存穿透(查不到)
布隆过滤器
布隆过滤器是一种数据结构,对所有可能査询的参数以hash形式存储,在控制层先进行校验,不符合则丟弃,从而避免了对底层存储系统的查询压力;
缓存空对象
当存储层不命中后,即使返回的空对象也将其缓存起来,同时会设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护了后端数据源缓存击穿(量太大,缓存过期!)
设置热点数据永不过期缓存雪崩:
集群搭建,一主二从,数据预热分布式锁:因为分布式环境中,系统是会部署到不同的机器上面的
数据库事务悲观锁:select status from t_goods where id=1 for update;
数据库事务乐观锁(通过版本号控制,如果更新就版本号+1)
//1.查询出商品信息
select status,version from t_goods where id=#{id}
//2.根据商品信息生成订单
//3.修改商品status为2
update t_goods
set status=2,version=version+1
where id=#{id} and version=#{version};通过redis进行分布式锁:通过setnx命令,String 类型setnx方法,只有不存在时才能添加成功,返回true
springboot的RedisTemplate实现redis分布式锁:
Java基于redis实现分布式锁(SpringBoot) - happyjava - 博客园
获得锁 /** * 获得锁 */ public boolean getLock(String lockId, long millisecond) { Boolean success = redisTemplate.opsForValue().setIfAbsent(lockId, "lock", millisecond, TimeUnit.MILLISECONDS); return success != null && success; } setIfAbsent方法,就是当键不存在的时候,设置,并且该方法可以设置键的过期时间。 该方法对应到redis的原生命令就是: SET lockId content PX millisecond NX 至于设置多少的过期时间合适,这个是没有定论的,需要根据真是的业务场景来衡量。 释放锁 当处理完业务逻辑后,需要手动的把锁释放掉。 public void releaseLock(String lockId) { redisTemplate.delete(lockId); }jedis实现redis分布式锁:(没用过)
Redis分布式锁的正确实现方式(Java版) - 流浪码工 - 博客园
redisson分布式锁使用,这个redis官网推荐的:(如果你的项目中Redis是多机部署的,那么可以尝试使用
Redisson实现分布式锁)(没用过)
分布式事务 seata sei达
seata是两阶段提交事务,第一阶段解析业务sql并且生成对应快照,第二阶段是提交/回滚,并且删除快照。
步骤:建立seata数据库,业务库也建seata的回滚表,启动seata服务端,file.conf和registry.conf拷贝到微服务的resources目录下,在各自服务分别建立配置类@Configuration,然后在接口方法上使用@GlobalTransactional注解,就使用分布式事务了。
分布式事务框架Seata_keep one's resolveY的博客-CSDN博客_seata重写feign客户端
nginx
Nginx - 狂神_keep one's resolveY的博客-CSDN博客_关闭nginx命令
Nginx 配置文件详解_keep one's resolveY的博客-CSDN博客_nginx配置文件内容
nginx的作用:
1:Http代理,反向代理:作为web服务器最常用的功能之一,尤其是反向代理。
2:负载均衡
3:配置前端静态资源文件映射
配置的关键字:upstream weight ; location proxy_pass root alias
rabbitmq
RabbitMQ_尚硅谷bilibili_keep one's resolveY的博客-CSDN博客
RabbitMQ消息队列常见面试题总结_张维鹏的博客-CSDN博客_消息队列rabbitmq面试
1:优点 1、任务异步处理:2、应用程序解耦合:缺点:系统的可用性降低,系统复杂度提高,数据一致性问题:
2:Exchange分发消息时根据类型的不同分发策略有区别,目前共四种类型:direct、fanout、topic、headers:
(1)direct:消息中的路由键(RoutingKey)如果和 Bingding 中的 bindingKey 完全匹配,交换器就将消息发到对应的队列中。是基于完全匹配、单播的模式。
(2)fanout:把所有发送到fanout交换器的消息路由到所有绑定该交换器的队列中,fanout 类型转发消息是最快的。
(3)topic:通过模式匹配的方式对消息进行路由,将路由键和某个模式进行匹配,此时队列需要绑定到一个模式上。
匹配规则:
① RoutingKey 和 BindingKey 为一个 点号 '.' 分隔的字符串。 比如: java.xiaoka.show
② BindingKey可使用 * 和 # 用于做模糊匹配:*匹配一个单词,#匹配多个或者0个单词
(4)headers:不依赖于路由键进行匹配,是根据发送消息内容中的headers属性进行匹配,除此之外 headers 交换器和 direct 交换器完全一致,但性能差很多,目前几乎用不到了
3:如何保证消息不被重复消费?加version控制下,和乐观锁做法一样
正常情况下,消费者在消费消息后,会给消息队列发送一个确认,消息队列接收后就知道消息已经被成功消费了,然后就从队列中删除该消息,也就不会将该消息再发送给其他消费者了。不同消息队列发出的确认消息形式不同,RabbitMQ是通过发送一个ACK确认消息。但是因为网络故障,消费者发出的确认并没有传到消息队列,导致消息队列不知道该消息已经被消费,然后就再次消息发送给了其他消费者,从而造成重复消费的情况。
重复消费问题的解决思路是:保证消息的唯一性,即使多次传输,也不让消息的多次消费带来影响,也就是保证消息等幂性;幂等性指一个操作执行任意多次所产生的影响均与一次执行的影响相同。具体解决方案如下:
(1)改造业务逻辑,使得在重复消费时也不影响最终的结果。例如对SQL语句: update t1 set money = 150 where id = 1 and money = 100; 做了个前置条件判断,即 money = 100 的情况下才会做更新,更通用的是做个 version 即版本号控制,对比消息中的版本号和数据库中的版本号。
(2)基于数据库的的唯一主键进行约束。消费完消息之后,到数据库中做一个 insert 操作,如果出现重复消费的情况,就会导致主键冲突,避免数据库出现脏数据。
(3)通过记录关键的key,当重复消息过来时,先判断下这个key是否已经被处理过了,如果没处理再进行下一步。
① 通过数据库:比如处理订单时,记录订单ID,在消费前,去数据库中进行查询该记录是否存在,如果存在则直接返回。
② 使用全局唯一ID,再配合第三组主键做消费记录,比如使用 redis 的 set 结构,生产者发送消息时给消息分配一个全局ID,在每次消费者开始消费前,先去redis中查询有没有消费记录,如果消费过则不进行处理,如果没消费过,则进行处理,消费完之后,就将这个ID以k-v的形式存入redis中(过期时间根据具体情况设置)。
4:如何保证消息的有序性?
由于MQ一般都能保证内部队列是先进先出的,所以把需要保持先后顺序的一组消息使用某种算法都分配到同一个消息队列中。然后只用一个消费者单线程去消费该队列,这样就能保证消费者是按照顺序进行消费的了。
5:如何保证消息队列的高可用?
RabbitMQ 有三种模式:单机模式、普通集群模式、镜像集群模式。
使用镜像集群模式保证高可用。镜像队列集群是RabbitMQ 真正的高可用模式,集群中一般会包含一个主节点master和若干个从节点slave,如果master由于某种原因失效,那么按照slave加入的时间排序,"资历最老"的slave会被提升为新的master。
6:如何处理消息堆积情况?
如果是 bug 则处理 bug;如果是因为本身消费能力较弱,则优化消费逻辑
(1)先修复 consumer 的问题,确保其恢复消费速度,然后将现有的 consumer 都停掉;
(2)临时创建原先 N 倍数量的 queue ,然后写一个临时分发数据的消费者程序,将该程序部署上去消费队列中积压的数据,消费之后不做任何耗时处理,直接均匀轮询写入临时建立好的 N 倍数量的 queue 中;
(3)接着,临时征用 N 倍的机器来部署 consumer,每个 consumer 消费一个临时 queue 的数据
(4)等快速消费完积压数据之后,恢复原先部署架构 ,重新用原先的 consumer 机器消费消息。
这种做法相当于临时将 queue 资源和 consumer 资源扩大 N 倍,以正常 N 倍速度消费。
7:如何保证消息不丢失,进行可靠性传输?
每种MQ都要从三个角度来分析:生产者丢数据、消息队列丢数据、消费者丢数据
生产者丢数据--使用发布确认机制:(回调)
生产者将信道设置成 confirm 模式(springboot可以配置,见下方博客),一旦信道进入 confirm 模式,
所有在该信道上面发布的消息都将会被指派一个唯一的 ID(从 1 开始),
一旦消息被投递到所有匹配的队列之后,broker就会发送一个确认给生产者(包含消息的唯一 ID),
这就使得生产者知道消息已经正确到达目的队列了,如果消息和队列是可持久化的,
那么确认消息会在将消息写入磁盘之后发出,broker 回传给生产者的确认消息中 delivery-tag 域
包含了确认消息的序列号,此外 broker 也可以设置basic.ack 的 multiple 域,
表示到这个序列号之前的所有消息都已经得到了处理。confirm 模式最大的好处在于他是异步的,
一旦发布一条消息,生产者应用程序就可以在等信道返回确认的同时继续发送下一条消息,
当消息最终得到确认之后,生产者应用便可以通过回调方法来处理该确认消息,
如果 RabbitMQ 因为自身内部错误导致消息丢失,就会发送一条 nack 消息,
生产者应用程序同样可以在回调方法中处理该 nack 消息。(发布确认是通过回调处理消息!)
RabbitMQ中消息确认机制_李嘉图呀李嘉图的博客-CSDN博客_rabbitmq消息确认机制
消息队列丢数据:(队列持久化+消息持久化)
处理消息队列丢数据的情况,一般是开启持久化磁盘。持久化配置可以和生产者的 confirm 机制配合使用,在消息持久化磁盘后,再给生产者发送一个Ack信号。这样的话,如果消息持久化磁盘之前,即使 RabbitMQ 挂掉了,生产者也会因为收不到Ack信号而再次重发消息。
持久化设置如下(必须同时设置以下 2 个配置):
(1)创建queue的时候,将queue的持久化标志durable在设置为true,代表是一个持久的队列,这样就可以保证 rabbitmq 持久化 queue 的元数据,但是不会持久化queue里的数据;
(2)发送消息的时候将 deliveryMode 设置为 2,将消息设置为持久化的,此时 RabbitMQ 就会将消息持久化到磁盘上去。
消费者丢数据:(消息应答机制)
消费者丢数据一般是因为采用了自动确认消息模式。该模式下,虽然消息还在处理中,但是消费中者会自动发送一个确认,通知 RabbitMQ 已经收到消息了,这时 RabbitMQ 就会立即将消息删除。这种情况下,如果消费者出现异常而未能处理消息,那就会丢失该消息。
解决方案就是采用手动确认消息,设置 autoAck = False,等到消息被真正消费之后,再手动发送一个确认信号,即使中途消息没处理完,但是服务器宕机了,那 RabbitMQ 就收不到发的ack,然后 RabbitMQ 就会将这条消息重新分配给其他的消费者去处理。
但是 RabbitMQ 并没有使用超时机制,RabbitMQ 仅通过与消费者的连接来确认是否需要重新发送消息,也就是说,只要连接不中断,RabbitMQ 会给消费者足够长的时间来处理消息。另外,采用手动确认消息的方式,我们也需要考虑一下几种特殊情况:
如果消费者接收到消息,在确认之前断开了连接或取消订阅,RabbitMQ 会认为消息没有被消费,然后重新分发给下一个订阅的消费者,所以存在消息重复消费的隐患
如果消费者接收到消息却没有确认消息,连接也未断开,则RabbitMQ认为该消费者繁忙,将不会给该消费者分发更多的消息
需要注意的点:
1、消息可靠性增强了,性能就下降了,因为写磁盘比写 RAM 慢的多,两者的吞吐量可能有 10 倍的差距。所以,是否要对消息进行持久化,需要综合考虑业务场景、性能需要,以及可能遇到的问题。若想达到单RabbitMQ服务器 10W 条/秒以上的消息吞吐量,则要么使用其他的方式来确保消息的可靠传输,要么使用非常快速的存储系统以支持全持久化,例如使用 SSD。或者仅对关键消息作持久化处理,且应该保证关键消息的量不会导致性能瓶颈。
2、当设置 autoAck = False 时,如果忘记手动 ack,那么将会导致大量任务都处于 Unacked 状态,造成队列堆积,直至消费者断开才会重新回到队列。解决方法是及时 ack,确保异常时 ack 或者拒绝消息。
3、启用消息拒绝或者发送 nack 后导致死循环的问题:如果在消息处理异常时,直接拒绝消息,消息会重新进入队列。这时候如果消息再次被处理时又被拒绝 。这样就会形成死循环。
延时队列应用:通过死信队列
消息变成死信有以下几种情况:
消息被拒绝(basic.reject / basic.nack),并且requeue = false
消息TTL过期
队列达到最大长度
我们将消息发送到消息队列中,并设置一个过期时间,该队列没有消费者
消息的过期时间到了之后,由于没有消费者,就会进入死信队列
我们用一个消费者接收死信队列的消息,就能达到延迟消息的目的
熟悉常见的linux命令
tail命令
cat -n test.log |grep "debug" 得到关键日志的行号
cat -n test.log |grep "debug" | less
cat -n test.log | grep "debug" >debug.txt
tail -100f test.log 实时监控100行日志
vim 日志名称 /搜索关键字 N向上, n向下 去找日志
su 用户名 ---- 切换用户,目录信息不变
su - 用户名 ---- 切换用户,同时切换到属主目录
ps -ef |grep "" 进程名称:查看进程号 ps aux
top 查看性能
lost -i 端口 :查看端口占用情况,需要root权限
netstat -tunlp | grep 端口号 不需要root权限
top:查看系统负载情况,包括系统时间、系统所有进程状态、cpu情况
free:查看内存占用情况
kill:正常杀死进程,发出的信号可能会被阻塞
kill -9:强制杀死进程,发送的是exit命令,不会被阻塞
linux安装部署:
linux 系统下载安装文件命令的差异
linux系统部署微服务项目_北冥老妖的博客-CSDN博客_linux部署微服务项目
两类常见的Linux操作系统:
Debian,Ubuntu系列
默认的本地安装命令: dpkg
默认的网络源安装命令:apt-get
RedHat,CentOS系列
默认的本地安装命令: rpm
默认的网络源安装命令:yum
网络安装命令自动解决包依赖问题,而本地安装不会。
任一Linux发行版中不是只能使用默认的安装命令管理安装包,也就是说Ubuntu也可以安装yum命令用来安装程序。
Docker:
最常用就是构建dockerfile 然后build一下 然后run
# 基础镜像 FROM openjdk:8-jre # author MAINTAINER ruoyi # 挂载目录 VOLUME /home/ruoyi # 创建目录 RUN mkdir -p /home/ruoyi # 指定路径 WORKDIR /home/ruoyi # 复制jar文件到路径 COPY ./jar/ruoyi-modules-system.jar /home/ruoyi/ruoyi-modules-system.jar # 启动系统服务 ENTRYPOINT ["java","-jar","ruoyi-modules-system.jar"]
常用docker命令:container(翻译:docker容器)

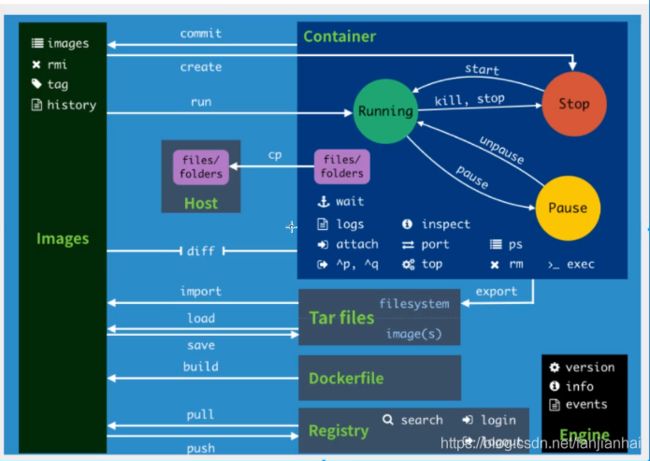
Docker狂神说_keep one's resolveY的博客-CSDN博客_docker狂神
简历项目准备
1、出行项目:公务车服务 租车服务 网关服务 xxjob服务 message服务 system服务 文件服务
ocr服务
对接华为ocr,msp框架,延时队列,支付对接,elk日志
2、商业项目:message服务 网关服务 售卖机服务 商业服务 system服务 文件服务
低代码框架,数据同步,接口鉴权,防重复提交,elk日志
3、船岸一体化系统 mrv inspect 电子记录簿 cctv system message服务 auth服务 job服务 i18n服务 0183服务 文件服务
拿手方案:
1、国际化方案:各自微服务建立自己的proerties国际化文件,微服务启动时解析proerties国家化文件后通过MQ发送到 I18N服务,通过 I18N服务存到数据库中,当前端登录进入系统后,请求i18n服务获取对应语言的国际化数据。
页面显示字段的国际化: 前端自行处理维护国际化;后端接口返回国际化:维护proerties国际化文件,通过获取请求头的语言类型,获取对应的语言,然后多层封装,获取result返回,例如:登录失败,接口超时,校验失败等。对于异常的国际化也是同理,通过异常全局处理器,获取请求头的语言类型,封装返回对应语言的报错信息;菜单国际化文件:通过系统菜单界面,用户维护上去。查询时候展示对应的国际化菜单名。
2、0183协议解析:通过多线程方式解析socket协议,入库并mq同步到云端,然后通过websocket给前段实时展示。
3、船云数据同步:
一、通过定时任务同步
数据表中增加同步时间字段;通过定时任务是扫表同步。
新增:定时任务扫表获取是否同步时间,没有同步时间就远程调新增同步,并修改本地数据增加同步时间。
修改和删除:定时任务扫表如果更新时间大于同步时间,就远程调更新和删除接口。(必须使用软删除,硬删除删完之后,通过定时任务同步就找不到数据了)
二、mq同步
通过mq做同步,失败消息直接入库,再起定时任务时重发。
springboot配置开启发布确认:
spring.rabbitmq.publisher-confirm-type=CORRELATED
spring.rabbitmq.publisher-returns=true
发布确认实现ConfirmCallback(mq到交换机)和ReturnCallback(交换机到队列)接口
springboot配置手动应答:
spring.rabbitmq.listener.simple.acknowledge-mode=manual
Channel.basicAck(deliveryTag, true);
channel.basicReject(deliveryTag, true);
channel.basicNack(deliveryTag, false, true);
channel.basicRecover(true);
4、定时备份还原,定时任务本来是想通过quaza实现,后面发现太重了,我们采用了SpringBoot框架自带的ThreadPoolTaskScheduler.schedule来做定时任务,实现时间并启停。ScheduledFuture中的cancel用来关闭;备份还原使用mysql的dumpmysql和mysql的命令,通过runtime.exec执行回调,另起线程判断process中的日志如果出现2行就返回false,因为有返回值所以用callable实现,new FutureTask作为new thread的入参创建线程,FutureTask通过get方法获取返回值。
5、若依通过自定义注解@innerAuth+AOP来拒绝外部请求
6、幂等性 _ 防重复提交
使用拦截器实现,在接口方法上添加@RepeatSubmit注解,使用redis缓存接口的请求URL及参数信息,如果存在且一致并在额定时间范围内,不让重复提交。
7、接口鉴权方案
注解+AOP实现:appId和secret+token+时间戳(重要),拦截器也可以做
8、分布式日志系统ELK
Elasticsearch + Logstash + Kibana
操作日志通过aop实现存储ES中,运行日志通过ELK安装部署配置实现
- 项目名称:游戏对战语音平台sdk:
项目描述:主要针对游戏对战语音开发的sdk,涉及小队语音国战语音,基于linknow现有的能力基础上,提供游戏语音服务。
mmeplayerservice主要负责:玩家相关
rommservice:房间相关
登录接口:/login 首先调用agc微服务拿到at,然后通过appid,openid生成servicetoken,调用鉴权接口,鉴权ok后,通过servicetoken解析拿到appid,写入online表和player表。
创建房间接口:首先通过解析servicetoken拿到appid,然后首先联表查询判断appid和status=1在online表中是否为空,不为空就返回已经在通话中,如果为空就在room表中新增记录,并更新online表
通知接口:通过接口一共有4种参数,加入房间,离开房间,禁言,心跳保活和房间保活,
我们通过notify接口去发送dmq消息,roomservice中消费dmq消息,消费到后更新room表,和stat表。
session鉴权接口:调用登录接口,鉴权接口,从缓存中拿到servicetoken后,解析servicetoken。
架构:使用springboot+cse(封装的注册中心zookeeper)+Dubbo (使用rpc通信)+nuwa(tomcat)+dcs(redis缓存)+dmq(kafka消息中间件)+mysql数据库
模块:playerservice微服务
自己负责的模块:创建房间接口,登录接口,通知接口,鉴权接口
- 项目名称:AGC运营管理台-开发者信用管理 职责:java开发
项目描述:对开发者的应用进行审核,并评级,进行信用管理:风险提示,封号,解封等,可以配置信用管理规则,通过审核开发者的每次操作进行对应的扣分和加分。
个人职责:1)参与产品的需求分析,编写story文档。
2)进行需求AR开发,部分数据库建模,编写业务代码。
3)数据库割接,通过定时任务执行还原开发者初始分数。
4)涉及多个外部件,进行接口联调。
架构:使用springboot+cse(封装的注册中心zookeeper)+Dubbo (使用rpc通信)+nuwa(tomcat)+dcs(redis缓存)+dmq(kafka消息中间件)+mysql数据库
模块:dms微服务
自己负责的模块:查询,封号等,定时任务执行(我们会每天调用接口更新初始化分数)
查询接口:设置组合索引查询
封号接口:
首先我们根据判断id联表查询开发者信息表和Approve审核中的表,如果status=0,审核表结果为空,否则返回有误,(只有状态为正常的账号才可以封号)
下来进行封号操作,写封号原因时间等,写Approve审核表和开发者信息表(状态改为审核中)
我们调用模板接口,然后调用cms电子流接口选择审核人,发送dmq消息,审核人收到dmq消息,审核后,更新开发者信息表和 Approve表。
难点:性能优化,调优(组合索引实现),mq(kafka)
自己擅长什么:数据库相关,分表,优化性能
- 项目名称:AGC运营管理台-套餐账单管理 职责:java开发
项目描述:运营可以配置包周期和即用即付套餐进行发布,涉及查询、修改、上架、下架、审核、版本历史,并通过账单系统查看cp端使用套餐的情况。
个人职责:1)编写接口开发文档,整理设计文档
2)业务逻辑开发,解决开发过程中遇到的技术问题等。
架构:使用springboot+cse(封装的注册中心zookeeper)+Dubbo (使用rpc通信)+nuwa(tomcat)+dcs(redis缓存)+dmq(kafka消息中间件)+mysql数据库+zuul网关
模块:
自己负责的模块:
难点:联调,沟通