雾天条件下 SLS 融合网络的三维目标检测
论文地址:3D Object Detection with SLS-Fusion Network in Foggy Weather Conditions
论文代码:https://github.com/maiminh1996/SLS-Fusion
论文摘要
摄像头或激光雷达(光检测和测距)等传感器的作用对于自动驾驶汽车的环境意识至关重要。然而,在雾、雨、雪等极端天气条件下,从这些传感器收集的数据可能会出现失真。这个问题可能会导致在操作自动驾驶车辆时出现许多安全问题。
论文的研究目的是分析雾对驾驶场景中目标的影响,然后提出改进方法。在恶劣天气条件下收集和处理数据通常比在良好天气条件下收集和处理数据更困难。因此,可以模拟恶劣天气条件的合成数据集是验证方法的一个不错的选择,因为在使用真实数据集之前它更简单、更经济。
论文中,在公共 KITTI 数据集上应用雾合成来生成图像和点云的 Multifog KITTI 数据集。在处理任务方面,测试了之前基于 LiDAR 和摄像头的 3D 目标检测器,名为 Spare LiDAR 立体融合网络(SLS-Fusion),看看它如何受到雾天条件的影响。建议使用原始数据集和增强数据集进行训练,以提高雾天条件下的性能,同时在正常条件下保持良好的性能。
论文在 KITTI 和提出的 Multifog KITTI 数据集上进行了实验,结果表明,在进行任何改进之前,雾天气条件下中等物体的 3D 目标检测性能下降了 42.67%。通过使用特定的训练策略,结果显着提高了 26.72%,并且在原始数据集上保持了很好的表现,仅下降了 8.23%。综上所述,雾往往会导致行车场景 3D 目标检测失败。通过使用增强数据集进行额外训练,显着提高了所提出的雾天条件下自动驾驶汽车 3D 目标检测算法的性能。
论文背景
如今的趋势是将自动化应用带入生活,以降低成本、人力并提高工作效率。人类使用眼睛、耳朵、鼻子和触觉等感觉器官来感知周围的世界,而工业应用则使用相机、雷达(无线电探测和测距)、Kinect、LiDAR(光探测和测距)、IMU 等传感器(惯性测量单元)在通过复杂算法处理之前收集数据。这项研究主要集中在自动驾驶汽车上,其中摄像头和激光雷达在环境感知中发挥着至关重要的作用。
摄像头、激光雷达和雷达、GPS/IMU等其他传感器的融合为自动驾驶汽车带来了感知环境并做出操作决策的能力。
Waymo、Uber、Lyft、Tesla 等大型科技公司已经将自动驾驶汽车投入了不同自动化程度的测试甚至商业用途,但这些汽车尚未达到全环境、全天气的性能水平状况。许多因素会影响自动驾驶汽车的感知能力,从而可能对其他道路使用者的生活造成严重后果。原因之一是从这些传感器收集的数据因环境影响而失真,可能直接影响自动驾驶汽车的意识。

虽然使用这些传感器的应用在受控照明或不受天气影响的室内环境中表现良好,但户外应用面临许多问题。例如,使用摄像头感知环境的应用程序在极端照明条件下(例如晒伤、弱光或夜间条件)通常会失败。自动驾驶汽车在雾、雨或雪等恶劣天气条件下会遇到重大挑战,其中摄像头和 LiDAR 都受到严重影响,如图所示。
因此,论文重点关注使用摄像头和激光雷达在雾天条件下运行进行 3D 目标检测。
产生最佳结果的方法大多基于深度学习架构,通过使用与标签相关的大量数据(监督学习)来训练模型。虽然在白天或晴朗天气等良好条件下标记和收集数据需要时间,但在极端天气下则需要更多的时间和精力。因此,与正常条件下记录的数据量相比,极端天气条件下记录的数据量存在不平衡。此外,在收集数据时,不同级别的雾、雨或雪可能会出现不平衡。大多数数据仅在给定时间和地点收集,因此数据无法完全覆盖所有情况,因此使用有限数据范围训练的模型可能会出错。因此,除了真实数据之外,创建可以在许多受控参数下进行模拟的合成数据也同样重要。
论文旨在在白天和温和阳光条件下收集的著名数据集上生成基于物理的雾数据,以在雾天条件下提供改进。
论文贡献
1.提出了一个从 KITTI 数据集增强的新公共数据集,用于通过 20 到 80 m 的不同可见度范围(雾中)的图像和点云,以尽可能接近真实的雾环境。
2.发现从相机和激光雷达收集的数据在雾天场景下明显失真。正如我们的实验所证实的,它直接影响自动驾驶汽车 3D 目标检测算法的性能。
3.从论文之前对原始数据的工作[1]延伸,提出了一种特定的训练策略,使用正常和有雾的天气数据集作为训练数据集。实验表明,该模型在雾天条件下可以更好地运行,同时保持性能接近正常天气条件下的性能。
[1] Mai, N.A.M.; Duthon, P.; Khoudour, L.; Crouzil, A.; Velastin, S.A. Sparse LiDAR and Stereo Fusion (SLS-Fusion) for Depth Estimation and 3D Object Detection. arXiv 2021, arXiv:2103.03977.
论文相关
3d 目标检测
根据用作输入的传感器,自动驾驶汽车的 3D 目标检测算法通常分为基于摄像头的方法、基于 LiDAR 的方法和基于融合的方法等类别。由于图像不提供深度信息,因此在尝试预测 3D 空间中目标的位置时,使用 RGB 图像的方法会遇到许多困难和模糊性。 Mono3D 是单目 3D 目标检测的开创性工作。它基于 Fast RCNN,这是一种流行的 2D 目标检测器,加上许多 handcrafted 特征来预测 3D 边界框。这些方法尝试预测 RGB 图像上的 2D 关键点,然后通过结合每个特定车辆的一些约束,它可以推断 3D 中的其他点以获得最终的 3D 边界框。伪激光雷达提出了一种表示数据的新方法。它通过简单地转换图像的预测深度图来生成伪点云。然后它可以利用任何基于激光雷达的方法在伪点云上进行检测。相比之下,LiDAR 提供 3D 点云数据,从中可以获得从自我车辆到物体的非常准确的深度信息。基于激光雷达的方法通常在感知任务中给出非常好的结果,并且近年来受到了广泛的关注。
PointRCNN 是一个两级检测器,尝试将 Faster RCNN 和 Mask RCNN 扩展到点云表示。 VoxelNet 和 PointPillars 尝试将点云编码为 3D 单元(体素或柱),类似于图像但具有高度通道,然后使用 3D CNN 提取特征。与此同时,尝试结合图像和点云的方法尽管吸收了两种信息流,但尚未真正从激光雷达方法中脱颖而出。 FPointNet 或 F-ConvNet 首先使用从图像中检测到的目标的 2D 边界框来查找 3D 空间中的截锥体区域。然后,使用 PointNet 分割来查找每个视锥体中的对象。 MV3D 使用点云生成 3D 建议框,加上传感器融合层来细化最终的 3D 边界框。点云表示为图像(鸟瞰图和前视图)。这些方法通常相当麻烦并且还不能实时运行。
恶劣天气条件下的数据集
大多数常见的现有数据集都是在良好的条件下收集的,例如 KITTI、Cityscape,或在不同的光照条件下收集,例如 BDD100K、Waymo、NuScenes。最近的注意力集中在自动驾驶汽车在恶劣天气条件下的感知能力,因为这种条件会对摄像头和激光雷达传感的质量产生负面影响,导致性能下降。因此,一些数据集是在雾天条件下收集的,包括 Foggy Driving、Foggy Zurich、SeeingThroughFog、nuscenes、BDD100k、Oxford 数据集、雨或雪条件。
然而,在这种条件下收集数据并不容易,并且可能会导致后处理问题,例如不平衡问题或标签错误。相比之下,合成数据集越来越接近真实数据,可以避免此类问题。合成数据集可以分为两类:基于物理的,例如 Foggy Cityscapes 、RainCityscapes、Foggy Cityscapes、Rain Augmented 和基于生成对抗网络(基于 GAN)。
尽管上述这些数据集很有用,但 KITTI 数据集在文献中很常用,而且很容易处理。论文决定使用该数据集作为基础数据集,以对其进行进一步的雾渲染。虽然大多数合成数据集仅关注图像,但这项工作旨在从良好的天气数据集开始考虑图像和点云的雾。论文使用 [2] 中提出的基于物理的程序来保留像真实雾一样的物理属性。
[2] Bijelic, M.; Gruber, T.; Mannan, F.; Kraus, F.; Ritter, W.; Dietmayer, K.; Heide, F. Seeing Through Fog Without Seeing Fog: Deep Multimodal Sensor Fusion in Unseen Adverse Weather. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11679–11689. [CrossRef]
恶劣天气条件下的感知
虽然室外感知算法在不同的照明条件下通常比室内更敏感,但极端天气条件下的感知更具挑战性,因为传感器退化、对比度较低、可见度有限,从而导致错误在预测中
。事实上,之前的研究已经表明分割、2D 目标检测和深度估计中的性能如何下降。一些研究还表明,通过学习合成数据[、去雾或使用基于后期的融合可以提高性能。
与之前的工作一样,论文旨在分析雾天场景下自动驾驶汽车的感知算法,特别强调3D模板检测任务。事实上,雾场景中 3D 目标检测的性能会大大降低,但通过使用正常数据集和合成数据集进行训练,性能可能会得到提高。
论文内容
雾现象
雾是水蒸气凝结成微小的云状颗粒的现象,这些颗粒出现在地面上和附近,而不是天空中。地球上的水分慢慢蒸发,当蒸发时,它会向上移动、冷却并凝结形成雾。雾可以看作低云的一种形式。
从物理上讲,雾是一种引起分散的现象。光线在落入图像传感器之前被悬浮的水滴散射。这种散射现象有两个主要影响。 首先,主光线在落入传感器之前会衰减,其次,存在散射光的信号层 。这些效果会降低对比度,如图 2 所示,强度范围充满强度值(每个像素的灰度图像的单个值),这些值随着雾的强度(清晰、80、50、20 m)而减小)。因此,图像的对比度与雾浓度成反比,这可能会给人类驾驶员和基于传感器的自动系统或驾驶辅助设备带来驾驶困难。
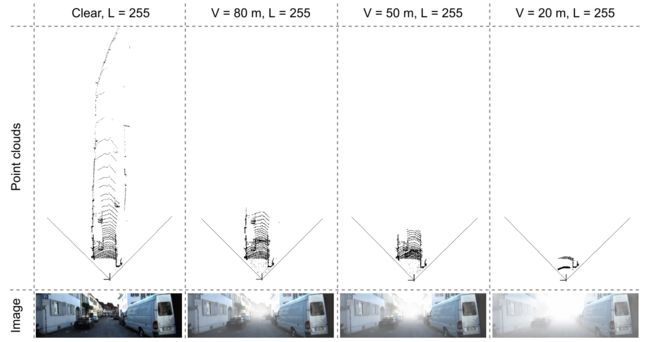
气象光学范围 (MOR),也称为能见度,用 V 表示,是在白色和黑色目标上不再区分对比度的距离(以米为单位)。当白色和黑色的目标在雾中移开时,人眼会看到均匀的灰色。标准中定义了 5% 的对比度限制水平。 MOR 越低,雾越浓。根据国际协议,当能见度 V 小于 1 公里时,使用术语“雾。
雾渲染
极端天气条件下的数据集数量少于正常条件(晴朗天气)下的数据集。首先,恶劣天气条件并不经常发生。其次,这类数据的清理和标注难度较大。它会导致不同类型天气条件之间的真实数据集出现不平衡问题。因此,合成数据集的生成对于开发在恶劣天气条件下工作的系统很有用。
在雾天条件下生成人工数据有不同的方法:(a)在受控条件下获取或(b)在正常条件数据集上进行增强。对于第二种类型,也有不同的方法来建模雾,例如基于物理的或基于GAN的建模。在论文文中,我们使用基于物理的方法,因为它可以保持天气的物理特性,并且已经研究了很长时间。
虽然雷达不会受到雾的显着影响,但从 LiDAR 和相机收集的数据却相当失真。
Camera in Fog
[3] Sakaridis, C.; Dai, D.; Van Gool, L. Semantic Foggy Scene Understanding with Synthetic Data. Int. J. Comput. Vis. 2018, 126, 973–992. [CrossRef]
Sakaridis 等人根据 1924 年的 Koschmieder Law。 [3]制定了方程以获得像素 ( u , v ) (u,v) (u,v) 处的观测雾图像 I f o g g y ( u , v ) I_{foggy}(u,v) Ifoggy(u,v)如下:
I f o g g y ( u , v ) = t ( u , v ) I c l e a r ( u , v ) + ( 1 − t ( u , v ) ) L (1) \tag1 I_{foggy}(u,v) = t(u,v)I_{clear}(u,v)+(1-t(u,v))L Ifoggy(u,v)=t(u,v)Iclear(u,v)+(1−t(u,v))L(1)
其中 I c l e a r ( u , v ) I_{clear}(u, v) Iclear(u,v) 表示潜清晰图像, L L L 表示大气光,假设全局恒定(通常仅对白天图像有效),在均匀介质的情况下,透射系数为:
t ( u , v ) = e x p ( − β D ( u , v ) ) (2) \tag2 t(u,v) = exp(-\beta D(u,v)) t(u,v)=exp(−βD(u,v))(2)
其中 β β β 是雾密度(或衰减)系数, D ( u , v ) D(u, v) D(u,v) 是像素 ( u , v ) (u, v) (u,v) 处的场景深度。
雾的厚度由 β β β 控制。使用 Koschmieder 定律,可见度 V V V 可以通过下面方程中的一个描述:
C T = e x p ( − β V ) (3) \tag3 C_T=exp(-\beta V) CT=exp(−βV)(3)
V = − ln ( C T ) β (4) \tag4 V= {-}\frac{\ln(C_T)}{\beta} V=−βln(CT)(4)
其中 C T C_T CT 是对比度阈值。根据国际照明委员会(CIE)的数据,CT 的白天能见度估计值为 0.05 0.05 0.05。还可以将 t ( u , v ) t(u, v) t(u,v) 表示为对可见性 V V V 和深度图 D D D 的依赖关系,如下所示:
t ( u , v ) = e x p ( ln ( C T ) D ( u , v ) V ) (5) \tag5 t(u,v) = exp(\frac{\ln(C_T)D(u,v)}{V}) t(u,v)=exp(Vln(CT)D(u,v))(5)
LiDAR in Fog
Gruber et al. 假设光束发散度不受雾的影响。在此模型中,只要接收到的激光强度大于有效本底噪声,就会始终记录返回的脉冲回波。然而,雾的严重反向散射可能会导致散射雾体积内点的直接反向散射,这通过透射率 t ( u , v ) t(u, v) t(u,v) 进行量化。然后,观测到的雾状激光雷达 L f o g g y ( u , v ) L_{foggy}(u, v) Lfoggy(u,v) 可以使用以下方程进行建模:
L f o g g y ( u , v ) = t ( u , v ) L c l e a r ( u , v ) (6) \tag 6 L_{foggy}(u,v) = t(u,v)L_{clear}(u,v) Lfoggy(u,v)=t(u,v)Lclear(u,v)(6)
其中 L c l e a r ( u , v ) L_{clear}(u, v) Lclear(u,v)和 L f o g g y ( u , v ) L_{foggy}(u, v) Lfoggy(u,v) 分别是 LiDAR 发射的光脉冲的强度和接收到的信号强度。
现代扫描激光雷达系统采用自适应激光增益来增加给定本底噪声的信号,从而产生最大距离:
d m a x = 1 2 β ln ( n L c l e a r + g ) , (7) \tag7 d_{max} = \frac{1}{2\beta}\ln(\frac{n}{L_{clear}+g}), dmax=2β1ln(Lclear+gn),(7)
其中 n n n 是可检测的本底噪声。
3D 目标检测算法
在这里,使用之前的 3D 目标检测算法,称为 SLS-Fusion,其灵感来自 Qiu 等人的工作。 图 3 显示了该 3D 探测器的框图。它以一对立体图像和模拟 4 光束 LiDAR 在左右图像上的重新投影深度图作为输入。它使用后期融合,分为 3 部分:深度估计、转换数据表示和基于 LiDAR 的 3D 目标检测。
[4] Mai, N.A.M.; Duthon, P.; Khoudour, L.; Crouzil, A.; Velastin, S.A. Sparse LiDAR and Stereo Fusion (SLS-Fusion) for Depth Estimation and 3D Object Detection. arXiv 2021, arXiv:2103.03977.
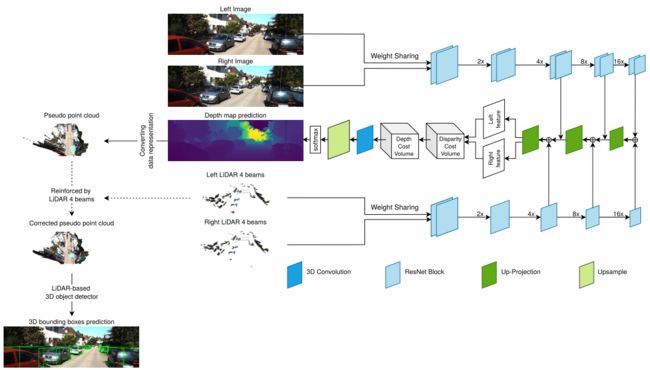
该模型通过投射 4 束 LiDAR 来拍摄左侧和右侧的立体图像 ( I l , I r ) (I_l , I_r) (Il,Ir) 和相应的模拟立体图像 ( S l , S r ) (S_l, S_r) (Sl,Sr)。 S l S_l Sl 和 S r S_r Sr 使用[5]中提出的公式进行模拟。编码器-解码器网络用于从图像和点云中提取特征。
[5] You, Y.; Wang, Y.; Chao, W.L.; Garg, D.; Pleiss, G.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-LiDAR++: Accurate Depth for 3D Object Detection in Autonomous Driving. In Proceedings of the 2020 International Conference on Learning Representations (ICLR), Virtual Conference, 26 April–1 May 2020.
所提出的网络具有针对 LiDAR 和图像 ( I l , S l ) (I_l,S_l) (Il,Sl) 和 ( I r , S r ) (I_r,S_r) (Ir,Sr) 的权重共享管道,而不是仅使用左右图像。一旦从解码阶段获得左右特征,它们就会被传递到 Depth Cost Volume(DeCV)以学习深度信息。这里,使用平滑的 L1loss函数:
∑ ( u , v ) ∈ I l ∣ d ( u , v ) − D ( u , v ) ∣ (8) \tag8 \sum_{(u,v)\in I_l}|d(u,v)-D(u,v)| (u,v)∈Il∑∣d(u,v)−D(u,v)∣(8)
其中 d ( u , v ) d(u, v) d(u,v) 表示有效深度地面事实。预测的深度图是 D D D,其中 D ( u , v ) D(u,v) D(u,v) 是对应于左图像 I l I_l Il中的像素 ( u , v ) (u,v) (u,v) 的深度。然后,使用针孔相机模型生成伪点云。给定深度 D ( u , v ) D(u, v) D(u,v) 和相机固有矩阵,每个像素 ( u , v ) (u, v) (u,v) 在相机坐标系中的 3D 位置 ( X c , Y c , Z c ) (X_c, Y_c, Z_c) (Xc,Yc,Zc) 由下式给出:
( d e p t h ) Z c = D ( u , v ) ( w i d t h ) X c = ( u − c U ) × Z c f U ( h e i g h t ) Y c = ( v − c V ) × Z c f V (9) \tag9 (depth)Z_c = D(u,v)\\ (width)X_c=\frac{(u-c_U)\times Z_c}{f_U}\\ (height) Y_c = \frac{(v-c_V)\times Z_c}{f_V} (depth)Zc=D(u,v)(width)Xc=fU(u−cU)×Zc(height)Yc=fV(v−cV)×Zc(9)
其中 c U c_U cU和 c V c_V cV 是主点的坐标, f U f_U fU 和 f V f_V fV 分别是像素宽度和高度的焦距。使用四光束激光雷达来增强伪点云的质量。然后将每个点 ( X c , Y c , Z c , 1 ) (X_c,Y_c,Z_c,1) (Xc,Yc,Zc,1) 变换为LiDAR坐标系(现实世界坐标系)中的 ( X l , Y l , Z l , 1 ) (X_l,Y_l,Z_l,1) (Xl,Yl,Zl,1)。
通过添加反射率 1 来填充伪点云。给定相机外在矩阵 C = [ R t 0 1 ] C =\begin{bmatrix} R & t \\ 0 & 1 \end{bmatrix} C=[R0t1] ,其中 R R R 和 t t t 分别是旋转矩阵和平移向量。伪点云可以通过如下方式获得:
[ X l Y l Z l 1 ] = C − 1 [ X c Y c Z c 1 ] (10) \tag{10} \begin{bmatrix} X_l \\ Y_l \\ Z_l \\ 1 \end{bmatrix} = C^{-1}\begin{bmatrix} X_c \\ Y_c \\ Z_c \\ 1 \end{bmatrix} XlYlZl1 =C−1 XcYcZc1 (10)
一旦获得伪点云,就可以将其视为普通点云,尽管其准确性取决于预测深度的质量。与 PseudoLiDAR++ 类似,输入(4 光束点云)用于纠正伪点云中的错误。这是获得更准确点云的细化步骤。然后,将深度图转换为伪点云。这个想法是利用当前领先的基于 LiDAR 的方法的性能来检测目标。
论文结论
论文研究的主要目的是分析雾对 3D 目标检测算法的影响。为此,论文为雾天驾驶场景创建了一个新颖的合成数据集。它被称为 Multifog KITTI 数据集。该数据集是通过在不同能见度(20 至 80 m)级别应用雾从原始数据集 KITTI 数据集生成的。该数据集涵盖了左右图像、4 光束 LiDAR 数据和 64 光束 LiDAR 数据,尽管有雾的 64 光束数据尚未被利用。
这项工作发现,在图像和 LiDAR 数据中添加雾会导致图像不规则(对比度较低)以及 LiDAR 目标的 3D 点云失真。然后的目的是测试 SLS-Fusion 算法在处理图像和 LiDAR 数据退化方面的鲁棒性。第一个测试列表包括验证雾对检测算法的负面影响。将雾数据作为输入并在训练中使用正常数据会导致结果下降。因此,观察到 3D 物体检测性能下降(中等水平物体的检测率从 63.90% 下降到 21.23%)。第二个主要发现是,即使不去雾,也可以通过直接使用 KITTI 数据集和合成 Multifog KITTI 数据集进行训练来提高 3D 对象检测算法的性能。这些结果增加了在恶劣天气条件下,特别是在雾天场景中快速扩大的感知范围。
另一项测试是将 SLS-Fusion 算法与领先的基于低成本传感器的方法(伪 LiDAR++)进行比较。结果发现,我们的方法在所提出的 Multifog KITTI 数据集的不同指标上都优于 Pseudo-LiDAR++ 方法。这个结果非常令人满意,因为它显示了该方法在处理有雾数据集时的鲁棒性。
这项研究的范围在点云的影响方面受到限制。由于实验中使用的数据是4束点云,其特征不如图像或64束点云的特征丰富。这些发现为未来的研究提供了以下见解:在 Multifog KITTI 数据集上测试基于 64 束 LiDAR 的 3D 物体检测算法,以更清楚地显示雾对点云的影响。我们还计划处理相机或激光雷达因天气影响而损坏的情况。