aws Opensearch 拼音插件
一、背景
OpenSearch 是一款开源的分布式搜索和分析套件。Amazon OpenSearch Service 是一项托管服务,可让您轻松部署、操作和扩展 OpenSearch 集群,并安全地实时搜索、监控和分析业务和运营数据,适合应用程序监控、日志分析、可观察性和网站搜索等使用场景。
OpenSearch 的拼音插件,可以将中文字符转换为拼音,使得 OpenSearch 能够更好地处理和搜索中文数据。在处理中文数据时,我们经常需要进行拼音搜索。例如,用户可能会用拼音来搜索中文关键词,或者在输入时使用拼音自动补全。此外,拼音搜索还可以作为一种备选的搜索方式,当直接的中文搜索没有返回满意结果时,用户可以尝试拼音搜索。
二、拼音插件配置
目前使用 Amazon OpenSearch Service 创建 v1.3 及以上版本的 OpenSearch 集群时,都提供了对拼音插件的支持。接下来,我们演示安装配置拼音插件的步骤。
首先,进入到域管理页面,创建一个 OpenSearch 域(OpenSearch 域是 OpenSearch 集群的同义词)。本示例中,选择 v2.11 版本的 OpenSearch 域,如下图所示。
|
|

接下来,进入“程序包”菜单,打开“插件”页面,并选择“OpenSearch 2.11”。在列表中找到“analysis-pinyin”链接,点击它进入拼音插件配置页面,如下图所示。
|
|

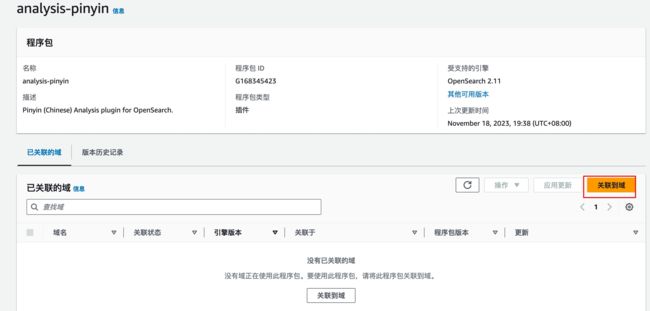
在拼音插件的配置页面中,点击“关联到域”按钮,在弹出的页面中选择此前创建的 OpenSearch 域,确认后点击“关联”按钮,如下面两图所示。
|
|
|
|

待关联状态显示为“有效”时,就可以在 OpenSearch 中使用拼音插件了。
|
|

三、拼音插件应用
插件生效验证
在 Amazon OpenSearch Service 域详情页面中,找到 Dashboards URL,打开 Dashboard 页面(本文出于简化演示过程的目的,在网络设置中配置 OpenSearch 为公有访问权限)。
|
|

在 Dashboard 中可以对索引中的数据进行搜索、查看、交互和可视化。接下来,进入“Dev Tools” 页面,以便使用 Restful 接口与 OpenSearch 进行交互,执行命令。
|
|

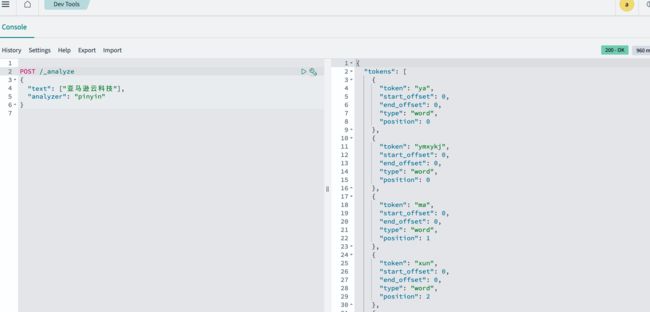
在 Console 中输入如下命令,验证拼音插件是否生效。若能返回如下截图中的内容,则说明拼音插件生效。
POST /_analyze
{
"text": ["亚马逊云科技"],
"analyzer": "pinyin"
}
|
|
插件简单使用
OpenSearch 中,一个完整的文本分析过程(analyzer)包含三部分:
- 字符串过滤器(character-filter):用于对原始文本做简单字符过滤与映射,例如剔除文本中的 HTML 标签。
- 分词器(tokenizer):把原始的文本按照一定的规则切分一个个单词。对于中文文本而言,分词效果取决于所选分词器。
- 分词过滤器(token-filter):用于对分词器切换后的单词进一步的过滤与转换。例如停用词。
本文介绍的 OpenSearch 拼音插件,默认包含了分析器 pinyin,分词器 pinyin 与分词过滤器 pinyin。
在上文验证插件生效时,就是使用了默认的分析器 pinyin。接下来我们继续使用默认的拼音分析器,来创建索引、插入数据和搜索数据。首先,我们创建了一个名为 test 的索引,该索引只有一个字段:city,并设置拼音分析器;然后向该索引插入了“北京”、“成都”、“哈尔滨”、“西安”等四条记录;最后使用“北京”的拼音首字母“bj”,成功搜索出来“北京”。
输入命令:
PUT /test
{
"mappings": {
"properties": {
"city": {
"type": "text",
"analyzer": "pinyin"
}
}
}
}
POST /test/_doc
{
"city": "北京"
}
POST /test/_doc
{
"city": "成都"
}
POST /test/_doc
{
"city": "哈尔滨"
}
POST /test/_doc
{
"city": "西安"
}
GET /test/_search
{
"query": {
"match": {
"city": "bj"
}
}
}
输出结果:
{
"took": 927,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.3331056,
"hits": [
{
"_index": "test",
"_id": "7IIuDIwBkL3QXh08v51F",
"_score": 0.3331056,
"_source": {
"city": "北京"
}
}
]
}
}
自定义分析器
我们再来观察一下默认拼音分析器的分词结果。
输入如下命令:
POST /_analyze
{
"text": ["亚马逊云科技"],
"analyzer": "pinyin"
}
输出如下结果:
{
"tokens": [
{
"token": "ya",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 0
},
{
"token": "ymxykj",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 0
},
{
"token": "ma",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 1
},
{
"token": "xun",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 2
},
{
"token": "yun",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 3
},
{
"token": "ke",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 4
},
{
"token": "ji",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 5
}
]
}
通过如上的返回结果可以看出,拼音分析器默认的分词结果,是分别按照文本的拼音首字母以及文本中每个汉字的拼音进行了分词。然而,在有的场景中,可能还需要文本的拼音全拼组合,或者需要在索引中保留文本的中文原文,此时就需要自定义分本分析器。接下来,演示如何创建自定义分析器。如下面命令所示,在自定义分析器中设置要求保留文本的原文(”keep_original” : true),取消基于每个汉字拼音的分词(”keep_full_pinyin” : false),但保留所有汉字拼音全拼的字符串拼接(”keep_joined_full_pinyin” : true)、以及所有汉字拼音首字母的字符串拼接(”keep_first_letter” : true)。
输入命令:
PUT /test2/
{
"settings" : {
"analysis" : {
"analyzer" : {
"my_pinyin_analyzer" : {
"tokenizer" : "my_pinyin"
}
},
"tokenizer" : {
"my_pinyin" : {
"type" : "pinyin",
"keep_first_letter" : true,
"keep_joined_full_pinyin" : true,
"keep_full_pinyin" : false,
"keep_original" : true
}
}
}
}
}
POST /test2/_analyze
{
"text": ["亚马逊云科技"],
"analyzer": "my_pinyin_analyzer"
}
输出结果:
{
"tokens": [
{
"token": "亚马逊云科技",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 0
},
{
"token": "yamaxunyunkeji",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 0
},
{
"token": "ymxykj",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 0
}
]
}上面示例仅展示了部分参数,拼音插件的全部可选参数及其默认值,如下所示。大家可以根据自己的场景,设置所需参数,灵活自定义自己的拼音分析器。
keep_first_letter : 当此选项启用时,例如:亚马逊云科技>ymzykt,默认值:true
keep_separate_first_letter : 当此选项启用时,将保持首字母分开,例如:亚马逊云科技>y,m,z,y,k,t,默认值:false,注意:由于词项过于频繁,查询结果可能过于模糊
limit_first_letter_length : 设置first_letter结果的最大长度,默认值:16
keep_full_pinyin : 当此选项启用时,例如:亚马逊云科技> [ya,ma,xun,yun,ke,ji],默认值:true
keep_joined_full_pinyin : 当此选项启用时,例如:亚马逊云科技> [yamaxunyunkeji],默认值:false
keep_none_chinese : 在结果中保留非中文字母或数字,默认值:true
keep_none_chinese_together : 保持非中文字母在一起,默认值:true,例如:DJ音乐家 -> DJ,yin,yue,jia,当设置为false时,例如:DJ音乐家 -> D,J,yin,yue,jia,注意:首先应启用keep_none_chinese
keep_none_chinese_in_first_letter : 在first letter中保留非中文字母,例如:亚马逊云科技AT2016->ymzyktat2016,默认值:true
keep_none_chinese_in_joined_full_pinyin : 在joined full pinyin中保留非中文字母,例如:亚马逊云科技2016->yamaxunyunkeji2016,默认值:false
none_chinese_pinyin_tokenize : 如果它们是拼音,将非中文字母分解为单独的拼音词项,默认值:true,例如:yamaxunyunkeji13zhuanhuan -> ya,ma,xun,yun,ke,ji,13,zhuan,huan,注意:首先应启用keep_none_chinese和keep_none_chinese_together
keep_original : 当此选项启用时,将同时保留原始输入,默认值:false
lowercase : 小写非中文字母,默认值:true
trim_whitespace : 移除前后空格,默认值:true
remove_duplicated_term : 当此选项启用时,重复的词项将被删除以节省索引,例如:de的>de,默认值:false,注意:位置相关的查询可能会受到影响
拓展应用
在实际应用中,存入索引字段的内容可能是一大段中文文本,若直接使用拼音插件,无论将整段文本转换为拼音、还是逐字分词再转换为拼音,可能最终的搜索效果都不理想。此时,就需要将拼音插件与 IK 中文插件一起使用(IK 中文插件从 Amazon OpenSearch 1.0 版本开始默认安装,无需额外配置)。
上文提到,一个完整的文本分析过程(analyzer)包含三部分:字符串过滤器(character-filter)、分词器(tokenizer)、分词过滤器(token-filter)。比较常见的一种拼音分词策略是在 tokenizer 上使用 ik 分词器进行正常的中文分词,然后在 token-filter 使用 pinyin 分词过滤器,对于 ik 分词器输出的每个 token,都应用拼音分词过滤器进行转换。接下来,我们通过示例索引 test3 进行演示。
输入命令:
PUT /test3/
{
"settings" : {
"analysis" : {
"analyzer" : {
"my_cn_analyzer" : {
"tokenizer" : "ik_max_word",
"filter" : ["my_pinyin", "my_stop"]
}
},
"filter": {
"my_pinyin" : {
"type" : "pinyin",
"keep_first_letter" : true,
"keep_joined_full_pinyin" : true,
"keep_full_pinyin" : false,
"keep_original" : true,
"none_chinese_pinyin_tokenize" : false,
"keep_none_chinese_together" : true
},
"my_stop": {
"type": "stop",
"stopwords": ["的", "是", "在","与"]
}
}
}
}
}
POST /test3/_analyze
{
"text": ["亚马逊云科技提供安全、广泛且可靠的全球云基础设施"],
"analyzer": "my_cn_analyzer"
}
输出结果:
{
"tokens": [
{
"token": "亚马逊",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 0
},
{
"token": "yamaxun",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 0
},
{
"token": "ymx",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 0
},
{
"token": "云",
"start_offset": 3,
"end_offset": 4,
"type": "CN_CHAR",
"position": 1
},
{
"token": "yun",
"start_offset": 3,
"end_offset": 4,
"type": "CN_CHAR",
"position": 1
},
{
"token": "y",
"start_offset": 3,
"end_offset": 4,
"type": "CN_CHAR",
"position": 1
},
{
"token": "科技",
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 2
},
{
"token": "keji",
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 2
},
{
"token": "kj",
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 2
},
{
"token": "提供",
"start_offset": 6,
"end_offset": 8,
"type": "CN_WORD",
"position": 3
},
{
"token": "tigong",
"start_offset": 6,
"end_offset": 8,
"type": "CN_WORD",
"position": 3
},
{
"token": "tg",
"start_offset": 6,
"end_offset": 8,
"type": "CN_WORD",
"position": 3
},
{
"token": "安全",
"start_offset": 8,
"end_offset": 10,
"type": "CN_WORD",
"position": 4
},
{
"token": "anquan",
"start_offset": 8,
"end_offset": 10,
"type": "CN_WORD",
"position": 4
},
{
"token": "aq",
"start_offset": 8,
"end_offset": 10,
"type": "CN_WORD",
"position": 4
},
{
"token": "广泛",
"start_offset": 11,
"end_offset": 13,
"type": "CN_WORD",
"position": 5
},
{
"token": "guangfan",
"start_offset": 11,
"end_offset": 13,
"type": "CN_WORD",
"position": 5
},
{
"token": "gf",
"start_offset": 11,
"end_offset": 13,
"type": "CN_WORD",
"position": 5
},
{
"token": "且",
"start_offset": 13,
"end_offset": 14,
"type": "CN_CHAR",
"position": 6
},
{
"token": "qie",
"start_offset": 13,
"end_offset": 14,
"type": "CN_CHAR",
"position": 6
},
{
"token": "q",
"start_offset": 13,
"end_offset": 14,
"type": "CN_CHAR",
"position": 6
},
{
"token": "可靠",
"start_offset": 14,
"end_offset": 16,
"type": "CN_WORD",
"position": 7
},
{
"token": "kekao",
"start_offset": 14,
"end_offset": 16,
"type": "CN_WORD",
"position": 7
},
{
"token": "kk",
"start_offset": 14,
"end_offset": 16,
"type": "CN_WORD",
"position": 7
},
{
"token": "de",
"start_offset": 16,
"end_offset": 17,
"type": "CN_CHAR",
"position": 8
},
{
"token": "d",
"start_offset": 16,
"end_offset": 17,
"type": "CN_CHAR",
"position": 8
},
{
"token": "全球",
"start_offset": 17,
"end_offset": 19,
"type": "CN_WORD",
"position": 9
},
{
"token": "quanqiu",
"start_offset": 17,
"end_offset": 19,
"type": "CN_WORD",
"position": 9
},
{
"token": "qq",
"start_offset": 17,
"end_offset": 19,
"type": "CN_WORD",
"position": 9
},
{
"token": "云",
"start_offset": 19,
"end_offset": 20,
"type": "CN_CHAR",
"position": 10
},
{
"token": "yun",
"start_offset": 19,
"end_offset": 20,
"type": "CN_CHAR",
"position": 10
},
{
"token": "y",
"start_offset": 19,
"end_offset": 20,
"type": "CN_CHAR",
"position": 10
},
{
"token": "基础设施",
"start_offset": 20,
"end_offset": 24,
"type": "CN_WORD",
"position": 11
},
{
"token": "jichusheshi",
"start_offset": 20,
"end_offset": 24,
"type": "CN_WORD",
"position": 11
},
{
"token": "jcss",
"start_offset": 20,
"end_offset": 24,
"type": "CN_WORD",
"position": 11
},
{
"token": "基础",
"start_offset": 20,
"end_offset": 22,
"type": "CN_WORD",
"position": 12
},
{
"token": "jichu",
"start_offset": 20,
"end_offset": 22,
"type": "CN_WORD",
"position": 12
},
{
"token": "jc",
"start_offset": 20,
"end_offset": 22,
"type": "CN_WORD",
"position": 12
},
{
"token": "设施",
"start_offset": 22,
"end_offset": 24,
"type": "CN_WORD",
"position": 13
},
{
"token": "sheshi",
"start_offset": 22,
"end_offset": 24,
"type": "CN_WORD",
"position": 13
},
{
"token": "ss",
"start_offset": 22,
"end_offset": 24,
"type": "CN_WORD",
"position": 13
}
]
}
接下来,我们再设置索引 test3 的 mapping 信息,演示如何在字段级别设置自定义分析器,然后进行数据插入与搜索演示。
输入命令:
PUT /test3/_mapping
{
"properties" : {
"name" : {
"type" : "text"
},
"description" : {
"type" : "text",
"analyzer" : "my_cn_analyzer"
}
}
}
POST /test3/_doc
{
"name": "亚马逊云科技",
"description": "亚马逊云科技提供安全、广泛且可靠的全球云基础设施"
}
POST /test3/_doc
{
"name": "Amazon Opensearch",
"description": "Amazon Opensearch对PB级文本与非结构化数据提供搜索、可视化与分析"
}
GET /test3/_search
{
"query": {
"match": {
"description": "ymx"
}
}
}
输出结果:
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.39376214,
"hits": [
{
"_index": "test3",
"_id": "8ILtEIwBkL3QXh08jp1h",
"_score": 0.39376214,
"_source": {
"name": "亚马逊云科技",
"description": "亚马逊云科技提供安全、广泛且可靠的全球云基础设施"
}
}
]
}
}
四、总结
本文作为拼音插件的入门指南,介绍了如何在 Amazon OpenSearch Service 中安装配置拼音插件,并通过简单示例演示了如何在索引中设置默认的拼音分析器,随后通过插入数据以及搜索数据进行效果验证。接着,演示了如何设置拼音插件的相关参数来创建自定义分析器,以实现更加灵活的场景。最后,拓展了拼音插件的用法,将拼音插件与 IK 中文插件相结合,针对中文文本实现了更理想的拼音分词效果。总的来说,拼音插件可以极大地提高 OpenSearch 处理中文数据的能力,使其能够满足更多复杂的搜索需求。
本篇作者

张盼富
AWS 解决方案架构师,从业十三年,先后经过历云计算、供应链金融、电商等多个行业,担任过高级开发、架构师、产品经理、开发总监等多种角色,有丰富的大数据应用与数据治理经验。加入亚马逊云科技后,致力于通过大数据+AI 技术,帮助企业加速数字化转型。