ClickHouse为什么这么快

ClickHouse作为一款开源列式数据库管理系统(DBMS)主要用于数据分析(OLAP)领域。
近年来国内开源社区非常火热,各个大厂纷纷跟进大规模使用。而提到ClickHouse最先想到的就是它极致的性能,计算速度开源公开benchmark显示比传统方法快100~1000倍,提供50MB~200MB/s的高吞吐实时导入能力。所谓“天下武功为快不破”,那ClickHouse到底是如何做到快速查询的呢?今天我们就来一起了解一下。
一、自下而上的设计
早在2019 年年末,ClickHouse 项目的创始人兼开源社区创始人 — Alexey Milovidov,就在北京举行的中国大数据技术大会(BDTC 2019)上分享过自下而上的设计理念,那他们是如何实现这种设计的呢?
1. 着眼硬件,先想后做
从硬件功能层面着手设计,包括 CPU、内存、硬盘、网络等等,基于将硬件功效最大化的目的,ClickHouse 会在内存中进行 GROUP BY,并且使用 HashTable 装载数据。与此同时,他们非常在意 CPU L3 级别的缓存,因为一次 L3 cache miss 会带来 70~100 纳秒的延迟,这意味着,在单核 CPU 上,它会浪费 4000 万/每秒的运算;而在一个 32 线程的 CPU 上,则可能会浪费5 亿/每秒的运算。
2. 算法在前,抽象在后
实现性能的最大化,算法的选择是重中之重。有时候,选择比努力更重要,以字符串搜索算法为例,针对不同的场景,ClickHouse 最终选择了这些算法:
对于常量,使用 Volnitsky 算法;
对于非常量,使用 CPU 的向量化执行 SIMD,暴力优化;
正则匹配使用 re2 和hyperscan 算法。
3. 特定场景,特殊优化
针对同一个场景的不同状况,使用不同的实现方式,尽可能地将性能最大化。例如去重计数 uniqCombined 函数,根据数据量的不同,会选择不同的实现方式:
当数据量较小的时候,会选择 Array 保存;
当数据量中等时候,则会选择 HashSet;
而当数据量很大的时候,则使用HyperLogLog 算法。
4. 勇于尝鲜,不行就换
除了字符串之外,在很多场景下ClickHouse 会使用最合适、最快的算法。如果市面上出现了号称性能强大的新算法,ClickHouse也会将其纳入并进行验证,如果效果可行,就保留使用。
5. 持续测试,持续改进
实践是检验真理的唯一标准,ClickHouse还拥有一个能够持续验证、持续改进的机制。
由于 Yandex 的天然优势,ClickHouse经常会使用真实的数据做测试,这一点很好地保证了测试场景的真实性。与此同时,ClickHouse是发版速度非常快的开源软件了,每个月都至少能发布一个版本,这得力于一个可靠的持续集成环境。也正是因为拥有这样的发版频率,ClickHouse才得以在快速迭代、快速改进中逐渐强大起来。
二、列式存储
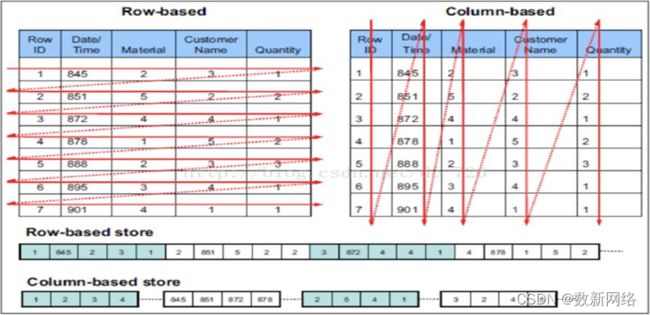
相比于行式存储,列式存储在分析场景下有着许多优良的特性。
1)分析场景中往往需要读大量行但是少数几个列。在行存模式下,数据按行连续存储,所有列的数据都存储在一个block中,不参与计算的列在IO时也要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计算的列即可,极大地减低了IO,加速了查询。
2)同一列中的数据属于同一类型,压缩效果显著。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本的同时,从磁盘中读取相应数据耗时也更短。
3)自由的压缩算法选择。不同列的数据具有不同的数据类型,适用的压缩算法也就不尽相同。可以针对不同列类型,选择最合适的压缩算法。
4)高压缩比,意味着同等大小的内存能够存放更多数据,系统cache效果更好。
官方数据显示,通过使用列存,在某些分析场景下,能够获得100倍甚至更高的加速效应。
三、 存储结构
ClickHouse 采用类 LSMTree 的结构,数据写入后定期在后台 Compaction。通过类LSM tree的结构,ClickHouse在数据导入时全部是顺序append写,写入后数据段不可更改,在后台compaction时也是多个段merge sort后顺序写回磁盘。顺序写的特性,充分利用了磁盘的吞吐能力。

官方公开 benchmark 测试显示能够达到 50MB-200MB/s 的写入吞吐能力,按照每行 100Byte 估算,大约相当于50W-200W 条/s 的写入速度。
四、索引
ClickHouse支持主键索引(一级索引),它将每列数据按照index granularity(默认8192行)进行划分,每个index granularity的开头第一行被称为一个mark行。主键索引存储该mark行对应的primary key的值。
对于where条件中含有primarykey的查询,通过对主键索引进行二分查找,能够直接定位到对应的index granularity,避免了全表扫描从而加速查询。
ClickHouse还支持二级索引(跳数索引),二级索引是在一级索引的基础上建立的,有一个重要的参数:granularity = 3,这个参数的意思是:在3段一级索引上创建二级索引。
二级索引支持的类型
-
minmax: 以index_granularity为单位,存储指定表达式计算后的min、max值;在等值和范围查询中能够帮助快速跳过不满足要求的块,减少IO;
-
set(max_rows):以index_granularity为单位,存储指定表达式的disinct value集合,用于快速判断等值查询是否命中该块,减少IO;
-
ngrambf_v1(n,size_of_bloom_fiter_in_bytes,number_of_hash_functions, random_seed):将string进行ngram分词后,构建bloom filter,能够优化 等值、like、in 等查询条件;
-
tokenbf_v1(size_of_bloom_fiter_in_bytes,number_of_hash_functions,random_seed):与ngrambf_v1类似,区别是不使用ngram进行分词,而是通过标点符号进行词语分割;
-
bloom_filter([false_positive]):对指定列构建bloomfilter,用于加速等值、like、in 等查询条件执行。

五、数据压缩
Clickhouse的数据存储文件column.bin中存储的是一列数据,在进行压缩的时候:一个压缩数据块由头信息和压缩数据两部分组成,头信息固定使用9位字节表示,具体由1个UInt8(1字节)整型和2个UInt32(4字节)整型组成,分别代表使用的压缩算法类型、压缩后的数据大小和压缩前的数据大小。每个压缩数据块的体积,按照其压缩前的数据字节大小,都被严格控制在64KB ~ 1MB,其上下限分别由min_compress-block_size(默认65535=64KB)与max_compress_block_size(默认1MB)参数指定。

1)单个批次数据 size <64KB:如果单个批次数据小于64KB,则继续获取下一批数据,直至累计到size >= 64KB时,生成下一个压缩数据块,如果平均每条记录小于8byte,多个数据批次压缩成一个数据块;
2)单个批次数据 64KB <=size <= 1MB:如果单个批次数据大小在64KB与1MB之间,则直接生成下一个压缩数据块;
3)> 单个批次数据 size > 1MB:如果单个批次数据直接超过1MB,则首先按照1MB大小截断并生成下一个压缩数据块,剩余数据继续依照上述规则执行。此时,会出现一个批次数据生成多个压缩数据块的情况,如果平均每条记录的大小超过128byte,则会把当前这一个批次的数据压缩成多个数据块。
注意:在一个xxx.bin字段存储文件中,并不是一个压缩块对应到一条一级索引,而是每8192条数据,构建一条一级索引。
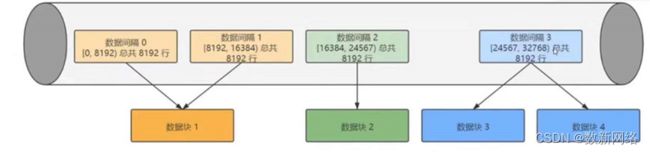
六、标记
上面一部分已经给读者介绍了什么是一级索引,但一级索引并不能单独实现快速查找的目的,或者说,一级索引只实现了数据到block的映射。这样的话就还存在一个问题——即便我已经知道我的数据存储在了第一个block,那我如何定位到这个block的位置呢?这个就需要通过标记文件来实现了,换句话说,标记文件存储了block到文件偏移量的映射。
每个颗粒会对应一个mark,该mark主要存储着2项信息:
1)当前block在压缩后的物理文件中的offset;
2)当前granularity(颗粒)在解压后block中的offset。
Block是ClickHouse与磁盘进行IO交互、压缩/解压缩的最小单位,而granularity是ClickHouse在内存中进行数据扫描的最小单位。

七、多线程与分布式
数据Partitioning
ClickHouse支持PARTITIONBY子句,在建表时可以指定按照任意合法表达式进行数据分区操作。比如通过toYYYYMM()将数据按月进行分区、通过toMonday()将数据按周进行分区、对Enum类型的列可以直接把相同的值作为一个分区等。
数据Partition在ClickHouse中主要有两方面应用:
在partition key上进行分区裁剪,只查询必要的数据。灵活的partition expression设置,使得我们可以根据SQL Pattern进行分区设置,最大化贴合业务特点。
每个partition再进一步划分为多个indexgranularity,然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。
数据Sharding
ClickHouse支持单机模式,也支持分布式集群模式。在分布式模式下,ClickHouse会将数据分为多个分片,并且分布到不同节点上。不同的分片策略在应对不同的SQL Pattern时,各有优势。ClickHouse提供了丰富的sharding策略,让业务可以根据实际需求选用。
1) random随机分片:写入数据会被随机分发到分布式集群中的某个节点上。
2) constant固定分片:写入数据会被分发到固定一个节点上。
3)column value分片:按照某一列的值进行hash分片。
4)自定义表达式分片:指定任意合法表达式,根据表达式被计算后的值进行hash分片。
数据分片,让ClickHouse可以充分利用整个集群的大规模并行计算能力,快速返回查询结果。
更重要的是,多样化的分片功能,为业务优化打开了想象空间。比如在hashsharding的情况下,JOIN计算能够避免数据shuffle,直接在本地进行local join;支持自定义sharding,可以为不同业务和SQL Pattern定制最适合的分片策略;利用自定义sharding功能,通过设置合理的sharding expression可以解决分片间数据倾斜问题等。
另外,sharding机制使得ClickHouse可以横向线性拓展,构建大规模分布式集群,从而具备处理海量数据的能力。
数据Replacing
ClickHouse通过主备复制提供了高可用能力,在集群模式下对shard配置副本,但1个节点只能拥有1个分片,也就是说如果要实现1分片、1副本,则至少需要部署2个服务节点。相比于其他系统它的实现有着自己的特色:
1)默认配置下,任何副本都处于active模式,可以对外提供查询服务;
2)可以任意配置副本个数,副本数量可以从0个到任意多个;
3)不同shard可以配置不同副本个数,用于解决单个shard的查询热点问题。

八、向量化执行引擎
为了高效地使用CPU,数据不仅仅按列存储,同时还按向量(列的一部分)进行处理。利用CPU的SIMD指令(SIMD的全称是Single Instruction Multiple Data)——即用单条指令操作多条数据,它的原理是在CPU寄存器层面实现数据的并行操作。ClickHouse目前利用SSE4.2指令集实现向量化执行,媒介越接近CPU,速度越快。
九、动态代码生成Runtime Codegen
在经典的数据库实现中,通常对表达式计算采用火山模型,也就是将查询转换成一个个的operator。为了连接不同的算子,operator之间采用统一的接口,在每个算子内部都实现了父类的这些虚函数。另外,在每个算子内部都要考虑多种变量,因为会存在由于if-else分支判断过多导致CPU分支预测失效的情况。
ClickHouse实现了Expression级别的runtime codegen,动态地根据当前SQL直接生成代码,然后编译执行。如下图例子所示,Expression直接生成代码,不仅消除了大量的虚函数调用,并且由于在运行时表达式的参数类型、个数等都是已知的,也消除了不必要的if-else分支判断。

十、近似计算
近似计算以损失一定结果精度为代价,极大地提升了查询性能。在海量数据处理中,近似计算价值更加明显。
ClickHouse实现了多种近似计算功能:
近似估算distinct values、中位数、分位数等多种聚合函数;
建表DDL支持SAMPLE BY子句,支持对于数据进行抽样处理。
linux安装ClickHouse
相信通过上面的介绍大家已经了解到了Clickhouse的强大之处,那么下面就一起来实际安装一下ClickHouse吧。
一、系统要求
ClickHouse可以在任何具有x86_64,AArch64或PowerPC64LE CPU架构的Linux,FreeBSD或Mac OSX上运行。
官方预构建的二进制文件通常针对x86_64进行编译,并利用SSE 4.2指令集,因此,除非另有说明,支持它的CPU使用将成为额外的系统需求。下面是检查当前CPU是否支持SSE 4.2的命令:

要在不支持SSE 4.2或AArch64,PowerPC64LE架构的处理器上运行ClickHouse,您应该通过适当的配置调整从源代码构建ClickHouse。
二、下载安装包
ClickHouse支持很多种安装,
-
DEB安装包
-
RPM安装包
-
TGZ安装包
-
Docker安装包
-
其他环境安装包,对于非linux操作系统和Arch64 CPU架构,ClickHouse将会以master分支的最新提交的进行编译提供
-
源代码安装
这里选择TGZ安装包安装
下载地址:Index of /clickhouse/tgz/
所需的版本可以通过curl或wget从存储库https://repo.clickhouse.tech/tgz/中下载,也可以下载好上传服务器。
选择自己需要的版本进行下载,这里选择在stable目录下的21.9.4.35版本,分别是:

在服务器上依次将这四个安装包解压并执行一下解压文件夹下install下的doinst.sh脚本。
在执行./clickhouse-server-21.9.4.35/install/doinst.sh后,clickhouse会默认创建一个default的用户,让你设置密码,不设置密码可以按回车。
三、启动
可以有以下几种形式启动ClickHouse Server

默认日志路径是/var/log/clickhouse-server/,配置文件路径是/etc/clickhouse-server/config.xml。
通过客户端连接clickhouse

--multiline的意思是对长的SQL进行转义,否则执行跨行SQL时,会提示错误,如下所示,他会将每行都当作独立的SQL执行,可简写为-m。
如果登录后查询发现返回有乱码,就要将你的终端软件字符集调整为UTF-8

再次查询

注:文章部分参考来源于网络,如有侵权,请联系删除!