Spark大数据分析与实战笔记(第二章 Spark基础-04)
文章目录
- 每日一句正能量
- 引言
- 章节概要
-
- 2.4 体验第一个Spark程序
-
- 2.4.1 运行Spark官方示例SparkPi
- 总结
每日一句正能量
“春风十里,不如你。”
这句来自现代作家安妮宝贝的经典句子,它表达了对他人的赞美与崇拜。每个人都有着不同的闪光点和特长,在这个世界上,不必去羡慕别人的光芒,自己所拥有的价值是独一无二的。每个人都有无限的潜力和能力,只要勇敢展现自己,就能在人生舞台上绽放光彩。每天鼓励自己,相信自己,发挥自己的优点和才能,你就能成为那道独特的风景,给世界带来不一样的美好。
引言
Spark是一个用于大规模数据处理的高性能分布式计算框架。它提供了一个简单易用的编程模型和丰富的API,可以帮助我们在分布式环境中快速地进行数据处理和分析。
在开始编写自己的Spark程序之前,我们可以先尝试运行Spark官方提供的示例程序来熟悉Spark的基本用法和工作原理。
其中一个经典的官方示例是SparkPi,它通过随机生成的点来估算圆周率π的值。我们可以通过这个程序来了解如何使用Spark进行并行计算和分布式数据处理。
接下来,我们将一步步地体验运行Spark官方示例SparkPi,并观察它在分布式集群上的运行效果。通过这个过程,我们可以更好地理解Spark的运行机制和优势,为编写自己的Spark程序打下良好的基础。让我们开始吧!
章节概要
Spark是一个快速、通用、可扩展的大数据处理引擎,具有高效的内存计算能力和丰富的数据处理功能。在大数据领域中,Spark已经成为一个重要的工具和平台,被广泛应用于数据分析、机器学习、图计算等多个领域。
了解Spark的运行架构和原理,对于高效地使用和优化Spark程序非常重要。Spark的运行架构和原理涉及到数据处理模型、任务调度机制、资源管理策略等多个方面的知识。理解这些知识可以帮助我们更好地理解Spark的工作原理,从而合理地配置和管理计算资源,设计和优化Spark程序。
本章节将深入探讨Spark的运行架构与原理。首先,我们将介绍Spark的基本概念和特点,以及Spark的集群模式和运行模式。然后,我们将详细解析Spark的执行引擎Spark Core,包括其任务划分与调度机制。接着,我们将介绍Spark的数据抽象模块RDD和DataFrame/Dataset,并分析其在数据处理中的作用和原理。此外,本章节还将对Spark的资源管理器和任务调度器进行详细讨论,包括Cluster Manager和DAG调度器的工作原理和实现方式。最后,我们将通过实际的运行架构实例分析,具体了解Spark在不同的集群模式下的运行架构和工作流程。
通过学习本章节内容,读者将能够全面了解Spark的运行架构与原理,掌握Spark程序的设计和优化方法。无论是初学者还是有一定经验的开发者,通过深入学习Spark的运行架构与原理,都能够更好地利用Spark处理大数据任务,并开发出高效、可扩展的Spark应用程序。
2.4 体验第一个Spark程序
2.4.1 运行Spark官方示例SparkPi
Spark集群已经部署完毕,接下来我们使用Spark官方示例SparkPi,体验Spark集群提交任务的流程。首先进入spark目录,执行命令如下。
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop01:7077 \
--executor-memory 1G \
--total-executor-cores 1 \
examples/jars/spark-examples_2.11-2.3.2.jar \
10
上述命令参数表示含义如下:
- 1、–master spark://hadoop01:7077:指定Master的地址是hadoop01节点
- 2、–executor-memory1G:指定每个executor的可用内存为1G
- 3、–total-executor-cores 1:指定每个executor使用的CPU核心数为1个
按【回车键】提交Spark作业后,观察Spark集群管理界面,其中“Running Applications”列表表示当前Spark集群正在计算的作业,执行几秒后,刷新界面,在Completed Applications表单下,可以看到当前应用执行完毕,返回控制台查看输出信息,出现了“Pi is roughly 3.140691140691141”,说明Pi值已经被计算完毕。,如下图所示。

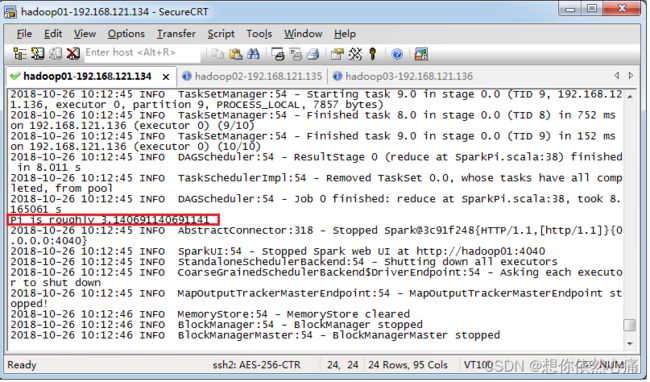
计算出来的结果准确是由参数(命令中最后的10)决定的,这个参数越大,准确度超高。
在高可用模式提交任务时,可能涉及多个Master,在提交任务时,需要让SparkContext指向一个Master列表 ,执行提交任务的命令如下。
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop01:7077,hadoop02:7077,hadoop03:7077 \
--executor-memory 1G \
--total-executor-cores 1 \
examples/jars/spark-examples_2.11-2.3.2.jar \
10
总结
在体验第一个Spark程序之前,确保已经安装好了Spark,并且配置环境变量和启动Spark集群。
首先,在终端中输入以下命令启动Spark集群:
sbin/start-all.sh
接着,创建一个新的Spark应用程序,命名为SparkPi,并在该应用程序中编写代码计算Pi的近似值。
import org.apache.spark.{SparkConf, SparkContext}
object SparkPi {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("SparkPi")
val sc = new SparkContext(conf)
val slices = if (args.length > 0) args(0).toInt else 2
val n = 100000 * slices
val count = sc.parallelize(1 to n, slices).map { i =>
val x = Math.random() * 2 - 1
val y = Math.random() * 2 - 1
if (x * x + y * y <= 1) 1 else 0
}.reduce(_ + _)
println("Pi is roughly " + 4.0 * count / n)
sc.stop()
}
}
代码解释:
- 创建SparkConf对象,设置应用程序的名称为"SparkPi"。
- 使用SparkConf创建SparkContext对象,该对象将作为Spark应用程序的入口点。
- 通过命令行参数获取切片的数量(默认为2),计算需要生成的随机点的总数。
- 使用parallelize方法创建一个RDD,该RDD包含了1到n的数字,并指定了切片的数量。
- 对每个数字进行映射操作,生成一个随机点,并判断该点是否在圆内。
- 对所有随机点的结果进行reduce操作,得到圆内点的数量。
- 根据公式计算Pi的近似值。
- 打印结果并停止SparkContext。
保存代码到一个文件中,例如"SparkPi.scala"。
接下来,在终端中输入以下命令来编译和打包程序:
$SPARK_HOME/bin/spark-submit --class SparkPi --master spark://<master-url> SparkPi.jar
其中,"“是Spark集群的URL,例如"spark://localhost:7077”。
程序会开始运行,输出Pi的近似值。
最后,可以在Spark集群的Web界面上查看运行日志和结果。
通过体验第一个Spark程序,我们了解了Spark应用程序的基本结构和运行方式。可以进一步学习和探索更复杂的Spark程序,以及使用Spark的其他功能和API。
转载自:https://blog.csdn.net/u014727709/article/details/132240278
欢迎 点赞✍评论⭐收藏,欢迎指正