Linux基础——进程初识(二)
1. 对当前目录创建文件的理解
我们知道在创建一个文件时,它会被默认创建到当前目录下,那么它是如何知道当前目录的呢?
对于下面这样一段代码
#include
#include
int main()
{
fopen("tmp.txt", "w");
while (1)
{
printf("这是一个进程\n");
sleep(1);
}
return 0;
} 在它被加载成为一个进程时,我们查看相应的PID有
![]()
在Linux中所有进程是被存放在一个/proc目录中的,即

我们找到对应的PID就能进入并查看该进程,进入后发现

可以看到,在进程中有一个cwd文件,即current work dir(当前工作目录),在代码中使用fopen向磁盘中写入文件tmp.txt时,会自动的将cwd中的路径拼接到它的前面
2. 进程标识符
①PID
PID是进程标识符(Process Identifier)的缩写,它是一个唯一标识符,用于标识正在运行的每个进程。每个进程在系统中都有一个唯一的PID,可以通过PID来识别和管理进程。PID是一个非负整数,通常在系统启动时自动分配给进程,并且在一个给定的时间内是唯一的。
以以下代码为例
编译后运行有

有了标识符之后我们可以通过使用对应进程的PID使用kill命令来干掉该进程,即
kill -9 12489
那么我们如何知道当前进程的PID呢?
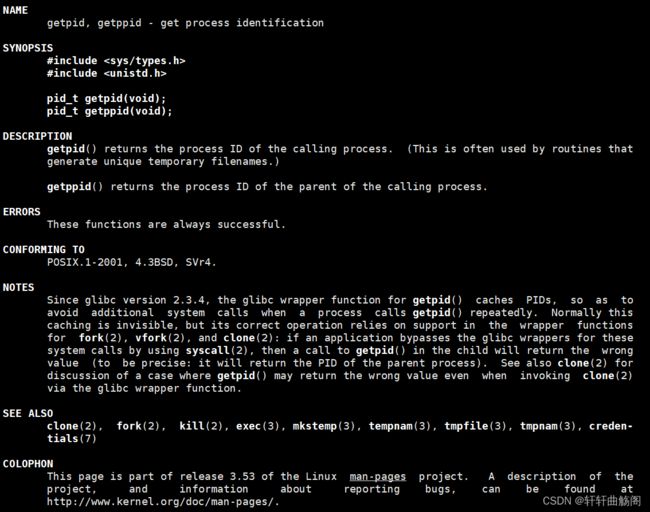
首先我们要知道PID是存放在task_struct中的,在我们使用ps命令时,它的本质就是遍历一遍task_struct链表,那么我们怎么获取呢——Linux肯定是不希望我们直接通过使用域访问符.来取得PID的,因此它提供了一个系统调用的接口即函数getpid(),它的手册如下
我们多运行几次后可以发现

对PID来说,PID只会保证当前运行期间有效,所以在不同的运行期间,其会不断变化
②PPID
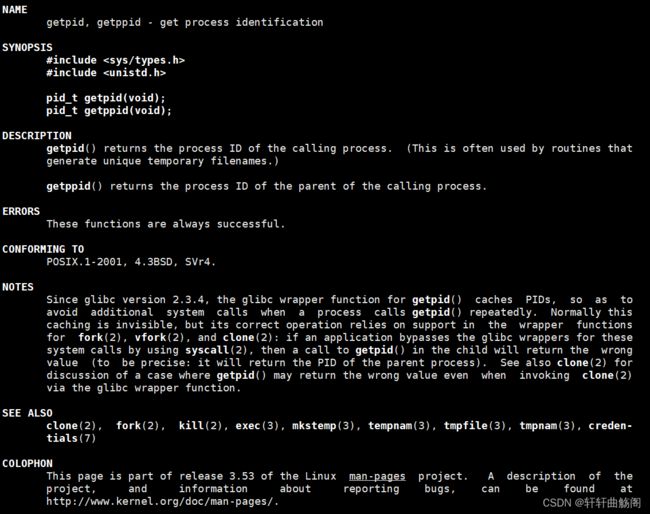
PPID指的是父进程的PID,即父进程的进程ID号。与PID类似,要获取PPID我们也可以使用对应函数getppid(),其手册如下
在上面的多次运行中我们可以发现在不同运行期间PPID一般不变,我们查看可以发现

PID为6116的只有一个——bash,我们之前提到过,对于输入的命令,系统会单独创建一个bash来处理输入的命令,这样就能做到在输入命令时,会将其作为bash的子进程运行。而在断开主机重连后可以看到

此时PPID发生了变化,这是因为在登录到主机时,系统会单独新创建一个bash。
![]()
3. 创建进程——fork
我们以下面的代码为例

对其编译运行后我们可以使用
while :; do ps ajx | head -1 ; ps ajx | grep mycode | grep -v grep;sleep 1;done来不断查看与mycode相关进程的状态
即
我们查看fork手册有

可以看到在手册中提到fork会返回两个值,返回id==0时,标识其为子进程,id>0时,标识其为父进程,而在运行结果中我们可以看到,父进程就是当前进程,子进程是新分支。至此,我们对于创建一个新进程有两种方法,其中一个就是使用./文件的方式在指令层面创建一个进程,另外一个就是使用fork函数在代码层面创建一个进程。其实在调用fork函数之后,会产生两个执行流。
在这里我们可以提出几个问题:
1. 为什么fork要给子进程返回0, 给父进程返回PID?
首先我们要知道,fork返回不同的值是为了让不同的执行流去执行不同的代码块,因为fork之后的代码是父子进程共享的,因此控制if等条件即可控制不同执行流。给子进程返回0只是一个标记,标志着子进程创建成功,而给父进程返回PID是因为对于一个父进程,其可能会有多个子进程,拿到子进程PID是为了标识唯一性。
2. fork函数是如何做到返回两次的?

首先我们要知道,创建一个子进程对于Linux来说就是创建一个新的task_struct,即只需要将原来的父进程task_struct拷贝一份,再对其中的部分属性做修改(如:PID,PPID等)即可,而在fork后父子进程访问这之后的同一份代码,因为代码不可修改,但是由于数据可能被修改,因此不能让父子进程共享同一份数据,那么就该让子进程拷贝一份父进程的数据,但是如果拷贝之后没有对数据进行修改那么又会导致资源的浪费,因此Linux规定在子进程尝试修改数据时,操作系统会为其申请一份新空间(使用多少申请多少),子进程修改这份新空间的数据即可,这样的方式也被称为数据层面的写实拷贝。
而对于fork来说,他是一个函数其内部也有其自己的实现,其内部可能包含:1. 创建子进程task_struct; 2. 填充task_struct;3. 让它指向同一份代码;4. 使它可以被自由调度;......在完成了这一系列的任务之后,子进程已经被创建好了,此时由于父子进程共享同一份代码,到最后的return 语句时,父进程与子进程会各自返回一次数据。
3. 对于id变量,它是怎么做到拥有不同内容的?
在代码中可以看到,pid_t id = fork();这个id就是数据内容,在fork返回两次后,对于id来说发生了数据的写实拷贝。
在了解了进程的创建后,我们对于bash也有了一个新的认识,即它在使用的途中一定会调用fork函数,并用其来创建子进程(执行解释命令)。
4. 进程状态
①一般操作系统学科中的进程状态
1. 运行
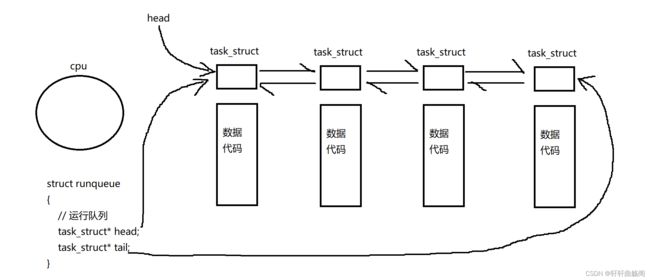
这些task_struct已经准备好了,可以随时被调度,此时在队列中的状态称为运行态(R),一般来说在队列中是到了谁就执行谁。那么只要进程放到CPU中,是不是一定要执行完毕所有的内容,才能执行下一个进程呢(如while(1))?答案肯定是否定的,其实对于每个进程都具有一个属性——时间片,有了时间片后,在一段时间内,所有的进程代码都会执行(并发执行)。而在这个过程中,一定会有大量的把进程从cpu上放上与拿下的动作,我们将其称为进程切换。
2. 阻塞

当task_struct对应的数据代码需要从键盘中读取数据时,但是此时却没有输入时,这种状态就称为阻塞状态,此时该task_struct会被链入键盘的waitqueue中,如果下一个需要键盘输入的task_struct直接链入之后的队列即可。
3. 挂起
在阻塞状态时,如果操作系统内部资源不足时,为了保证操作系统维持正常状态而要省出资源,此时操作系统会将task_struct保留,将代码和数据放在外设中(换出),此时的进程状态为挂起,而在需要时会将代码和数据加载回来(换入)。
②Linux中的进程状态
在Linux中定义如下
static const char * const task_state_array[] = {
"R (running)", /* 0 */
"S (sleeping)", /* 1 */
"D (disk sleep)", /* 2 */
"T (stopped)", /* 4 */
"t (tracing stop)", /* 8 */
"X (dead)", /* 16 */
"Z (zombie)", /* 32 */
};以下面的代码为例

我将其运行后查看
![]()
此时的S+(此处的+表示前台运行,不能输入bash命令)表示处于S状态(即阻塞状态),这是因为cpu的运行速度太快,而显示屏运行速度相等较慢,因此有极大的可能性时处于S状态,而我们将代码修改一下
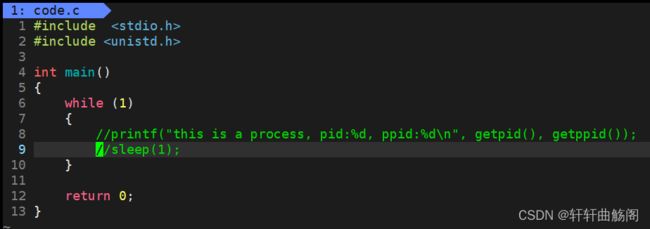
,即可发现
![]()
此时,由于不需要等待外设,因此一直处于运行态即R。
对于D状态,我们先举一个具体的例子,
若处于极端情况下时,进程被kill,磁盘写入数据失败时,反馈信息给进程时,进程却不见了,此时磁盘一般会选择丢失这部分数据,那么为了防止这种情况发生,我们只需要让进程在等待磁盘时,不能被杀掉即可,即将其设置为D状态,在磁盘写入完毕后再将其状态修改为S。由此,我们可以认识到S状态属于浅度睡眠,可以随时响应系统的调度,而D状态属于深度睡眠,它不会响应系统调度。
对于T状态,我们可以使用kill的命令来暂停进程,即

查看后,我们知道可以使用-19命令来发出暂停信号, 即

此时我们可以看到mycode处于暂停状态,而对于t状态,我们可以使用gdb来演示

可以看到,当我们使用断点停止在某一处时,此时mycode处于t状态。
对于X状态和Z状态,在一个进程死亡的时候,会先进入Z状态,其目的是需要维持相应的状态,直到被父进程读取到信息后,其状态才会转换成X(瞬时)。
我们以下面的代码举例

运行并监视有
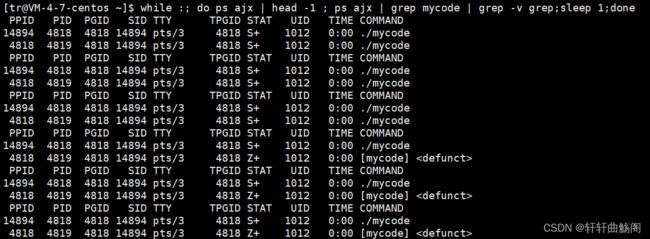
可以看到,在子进程结束,父进程未结束后,子进程处于Z+状态
将代码修改一下

运行并监视有

可以看到,对于操作系统本身来说,若父进程先退出,其子进程的父进程会被修改为1号进程(即操作系统)。孤儿进程会在后台运行,而且因为其父进程存在,不会变成僵尸进程即不会造成内存泄漏。对于父进程为1的进程我们将其称为孤儿进程,该进程被操作系统所领养。那么为什么要被领养呢?因为孤儿进程未来也要退出,也需要被释放,而操作系统本身具有回收功能。