PyTorch Tutorial
本文作为博客“Transformer - Attention is all you need 论文阅读”的补充内容,阅读的内容来自于
https://pytorch.org/tutorials/intermediate/char_rnn_classification_tutorial.html#recommended-preparation
建议的准备流程。
Deep Learning with PyTorch: A 60 Minute Blitz — PyTorch Tutorials 2.2.0+cu121 documentation
页面中的YouTube链接只是一个overview,没办法科学上网不看也没关系。
Tensors — PyTorch Tutorials 2.2.0+cu121 documentation
Tensor是一个特殊的数据结构,类似于数组和矩阵。在PyTorch中我们使用Tensor来encode模型的输入、输出以及参数。Tensor类似于NumPy 中的ndarray,区别在于Tensor可以在GPU上或者其他能够加速运算的硬件上运行。
引入相关库
import torch
import numpy as npTensor初始化
直接由数据生成Tensor
可以直接使用list来生成Tensor:
data = [[1, 2], [3, 4]]
x_data = torch.tensor(data)从NumPy数组生成Tensor
np_array = np.array(data)
x_np = torch.from_numpy(np_array)这里的data还是上面list中的,先把list转换成numpy array,再把这个numpy array转换到Tensor。
使用其他Tensor生成Tensor
x_ones = torch.ones_like(x_data)
# retains the properties of x_data
print(f"Ones Tensor: \n {x_ones} \n")
x_rand = torch.rand_like(x_data, dtype=torch.float)
# overrides the datatype of x_data
print(f"Random Tensor: \n {x_rand} \n")Ones Tensor:
tensor([[1, 1],
[1, 1]])Random Tensor:
tensor([[0.8823, 0.9150],
[0.3829, 0.9593]])
这里x_data是来自于直接从list生成的Tensor,torch.ones_like表示返回用标量1填充出来的size和输入的Tensor相同的Tensor。torch.rand_like则是返回用[0,1)的数字填充出来的size与输入的Tensor相同的Tensor。
使用随机或固定值生成Tensor
shape = (2, 3,)
rand_tensor = torch.rand(shape)
ones_tensor = torch.ones(shape)
zeros_tensor = torch.zeros(shape)
print(f"Random Tensor: \n {rand_tensor} \n")
print(f"Ones Tensor: \n {ones_tensor} \n")
print(f"Zeros Tensor: \n {zeros_tensor}")Random Tensor:
tensor([[0.3904, 0.6009, 0.2566],
[0.7936, 0.9408, 0.1332]])Ones Tensor:
tensor([[1., 1., 1.],
[1., 1., 1.]])Zeros Tensor:
tensor([[0., 0., 0.],
[0., 0., 0.]])
类似之前的操作,这里是指定Tensor的size,填充数据,分别是用[0,1)中的随机值填充,用1填充和用0填充。
Tensor属性
tensor = torch.rand(3, 4)
print(f"Shape of tensor: {tensor.shape}")
print(f"Datatype of tensor: {tensor.dtype}")
print(f"Device tensor is stored on: {tensor.device}")Shape of tensor: torch.Size([3, 4])
Datatype of tensor: torch.float32
Device tensor is stored on: cpu
Tensor运算
指定在GPU运算
# We move our tensor to the GPU if available
if torch.cuda.is_available():
tensor = tensor.to('cuda')
print(f"Device tensor is stored on: {tensor.device}")如果在colab上,可以直接改notebook设置
Device tensor is stored on: cuda:0
类numpy索引和切片
tensor = torch.ones(4, 4)
tensor[:,1] = 0
print(tensor)tensor([[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.]])
可以按index访问,也可以切片
按行/列方向拼接Tensor
>>> x = torch.randn(2, 3)
>>> x
tensor([[ 0.6580, -1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497]])
>>> torch.cat((x, x, x), 0)
tensor([[ 0.6580, -1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497],
[ 0.6580, -1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497],
[ 0.6580, -1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497]])
>>> torch.cat((x, x, x), 1)
tensor([[ 0.6580, -1.0969, -0.4614, 0.6580, -1.0969, -0.4614, 0.6580,
-1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497, -0.1034, -0.5790, 0.1497, -0.1034,
-0.5790, 0.1497]])Tensor乘法
# This computes the element-wise product
print(f"tensor.mul(tensor) \n {tensor.mul(tensor)} \n")
# Alternative syntax:
print(f"tensor * tensor \n {tensor * tensor}")tensor.mul(tensor)
tensor([[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.]])tensor * tensor
tensor([[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.]])
乘法,但是是对应元素和对应元素相乘。
print(f"tensor.matmul(tensor.T) \n {tensor.matmul(tensor.T)} \n")
# Alternative syntax:
print(f"tensor @ tensor.T \n {tensor @ tensor.T}")tensor.matmul(tensor.T)
tensor([[3., 3., 3., 3.],
[3., 3., 3., 3.],
[3., 3., 3., 3.],
[3., 3., 3., 3.]])tensor @ tensor.T
tensor([[3., 3., 3., 3.],
[3., 3., 3., 3.],
[3., 3., 3., 3.],
[3., 3., 3., 3.]])
乘法,但是矩阵乘法
Tensor加法
print(tensor, "\n")
tensor.add_(5)
print(tensor)tensor([[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.]])tensor([[6., 5., 6., 6.],
[6., 5., 6., 6.],
[6., 5., 6., 6.],
[6., 5., 6., 6.]])
A Gentle Introduction to torch.autograd — PyTorch Tutorials 2.2.0+cu121 documentation
autograd是PyTorch的自动微分引擎,为神经网络训练提供动力,autograd如何帮助神经网络训练?
神经网络是一组嵌套函数的集合,这些函数在一些输入数据上执行。这些函数由参数(由权重和偏置组成)定义,这些参数在PyTorch中存储在张量中。
训练一个神经网络分为两个步骤:
前向传播:在前向传播中,神经网络对正确的输出做出最好的猜测。它通过每个函数运行输入数据来进行猜测。
反向传播:在反向传播中,神经网络根据其猜测中的误差调整其参数。它通过从输出向后遍历,收集误差相对于函数参数(梯度)的导数,并使用梯度下降优化参数来实现这一点。
(个人经验来看,这样说不好理解,前向传播就是给输入之后,输入通过网络走到输出,而反向传播就是输出的结果计算出的loss逆着网络方向走到输入位置,目的是为了调整参数的大小,希望下一次输入走过来能够得到更好的结果)
这里推荐了3Blue1Brown的视频,不过这里给的是YouTube链接,B站上有up搬运,链接(p1)如下:
3blue1brown-深度学习(英文搬运)_哔哩哔哩_bilibili
PyTorch使用
本例中从torchvision加载一个预训练的resnet18模型。我们创建了一个random data tensor来表示具有3个通道的单个图像,高度和宽度为64,并将其相应的标签初始化为一些随机值。预训练模型中的标签具有形状(1,1000)。且只能使用在CPU上。
换言之,图像实际上只是随机生成的有着固定size的Tensor,这些Tensor的标签也是随机生成的。
import torch
from torchvision.models import resnet18, ResNet18_Weights
model = resnet18(weights=ResNet18_Weights.DEFAULT)
data = torch.rand(1, 3, 64, 64)
labels = torch.rand(1, 1000)Downloading: "https://download.pytorch.org/models/resnet18-f37072fd.pth" to /var/lib/jenkins/.cache/torch/hub/checkpoints/resnet18-f37072fd.pth
0%| | 0.00/44.7M [00:00 16%|#6 | 7.27M/44.7M [00:00<00:00, 61.4MB/s]
39%|###9 | 17.6M/44.7M [00:00<00:00, 86.5MB/s]
64%|######3 | 28.5M/44.7M [00:00<00:00, 98.6MB/s]
90%|########9 | 40.1M/44.7M [00:00<00:00, 107MB/s]
100%|##########| 44.7M/44.7M [00:00<00:00, 100MB/s]
这里,从torchvision里面直接获得resnet18的参数,生成的图像是64*64*3,图像的数量是1,labels是1*1000的大小在[0,1)的Tensor。
prediction = model(data) # forward pass这个就是前向传播,直接把图片放到model里面(因为直接把参数拉下来了,所以当然可以直接predict)
loss = (prediction - labels).sum()
loss.backward() # backward pass使用模型的预测和相应的标签来计算误差(损失)。下一步是通过网络反向传播这个错误。当我们在loss(Tensor)上调用. backward()时,反向传播被启动。然后autograd计算并存储每个模型参数的梯度在参数的.grad属性中。注意这里使用了sum,这是计算predict的结果对于1000个分类的loss的和。
optim = torch.optim.SGD(model.parameters(), lr=1e-2, momentum=0.9)加载一个优化器,在本例中是学习率为0.01,momentum为0.9的SGD
关于momentum:
Stochastic Gradient Descent with momentum | by Vitaly Bushaev | Towards Data Science
帮助梯度矢量向正确方向加速,从而加快收敛速度的方法。
简单来说就是对梯度进行一些移动,相当于是一个加速收敛的trick

optim.step() #gradient descent最后,我们调用.step()来启动梯度下降。优化器根据存储在.grad中的梯度调整每个参数
Neural Networks — PyTorch Tutorials 2.2.0+cu121 documentation
一个简单的前馈网络。它接受输入,将其通过几个层一个接一个地传递,然后最后给出输出。
A typical training procedure for a neural network is as follows:
Define the neural network that has some learnable parameters (or weights)
Iterate over a dataset of inputs
Process input through the network
Compute the loss (how far is the output from being correct)
Propagate gradients back into the network’s parameters
Update the weights of the network, typically using a simple update rule:
weight = weight - learning_rate * gradient
定义神经网络的训练过程步骤如下:
1. 定义网络
2. 在输入部分循环放dataset里面的data进去
3. 网络处理输入
4. 计算损失
5. 将梯度传回网络参数
6. 更新网络的weight
可以明显看出,不同的gradient给weight带来的变化是不一样的,比如某个neuron的gradient是1000,另一个和这个neuron差不多位置(层数,output链接的neuron)的neuron的gradient是1,那么在loss回来的时候,那个gradient是1000的显然会更新的更多(受的影响更大)。
定义网络
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 5x5 square convolution
# kernel
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 5*5 from image dimension
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square, you can specify with a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = torch.flatten(x, 1) # flatten all dimensions except the batch dimension
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
print(net)简单解释一下,这是一个简单的卷积神经网络,首先x是一个二维的Tensor(比如图像),这个图像的channel是1(可能是黑白的,当然也可能是彩色图像但是只使用其中的某个通道),对这个Tensor使用6个kernel大小为5*5,步长为1,padding为0的卷积(使用6个就代表输出会有6个channel),然后接入ReLU(激活函数,提供非线性),接着是max pooling(2*2,stride=kernel size=2)
重复上面的步骤,但是此时的输入channel为6,输出channel为16
把得到的二维的Tensor拍扁,变成向量。
接入全连接层,这里假定经过两层conv的结果是一个5*5*16的feature map。也就可以反推最初的image的大小。
input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d
-> flatten -> linear -> relu -> linear -> relu -> linear
进入flatten之前为5*5*16(16为channel大小),这也是第二个max pooling的结果
在进入第二个max pooling之前为10((x-2)/2+1=5)*10*16,这是第二个conv的结果
在进入第二个conv之前为14((x-5)/1+1=10)*14*6,这是第一个max pooling的结果
在进入第一个max pooling之前为28((x-2)/2+1=14)*28*6,这是第一个conv的结果
在进入第一个conv之前为32((x-5)/1+1=28)*32*1,这就是image的尺寸
Net(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
只需要定义前向函数,后向函数(计算梯度)会使用autograd自动为你定义,模型的可学习参数由net.parameters()返回。
params = list(net.parameters())
print(len(params))
print(params[0].size()) # conv1's .weight现在,我们尝试一个随机的32x32输入。注:此网(LeNet)的预期输入大小为32x32。注意使用任何数据集都要把图片尺寸调整成合适的大小(经常常用的比如裁剪,缩放)。
input = torch.randn(1, 1, 32, 32)
out = net(input)
print(out)tensor([[ 0.1453, -0.0590, -0.0065, 0.0905, 0.0146, -0.0805, -0.1211, -0.0394,
-0.0181, -0.0136]], grad_fn=)
输出的长度是10,一位之前定义了输出的长度。
net.zero_grad()
out.backward(torch.randn(1, 10))将所有参数和随机梯度backprops的梯度缓冲区归零。
注意:
torch.nnonly supports mini-batches. The entiretorch.nnpackage only supports inputs that are a mini-batch of samples, and not a single sample.For example,
nn.Conv2dwill take in a 4D Tensor ofnSamples x nChannels x Height x Width.If you have a single sample, just use
input.unsqueeze(0)to add a fake batch dimension.简单来说就是torch.nn对维度有要求,如果不匹配可以补零。
Loss Function
损失函数接受(输出,目标)对输入,并计算一个值来估计输出与目标的距离。常用的比如均方误差。
output = net(input)
target = torch.randn(10) # a dummy target, for example
target = target.view(1, -1) # make it the same shape as output
criterion = nn.MSELoss()
loss = criterion(output, target)
print(loss)tensor(1.3619, grad_fn=
)
现在我们能看到这样的计算图:
input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d
-> flatten -> linear -> relu -> linear -> relu -> linear
-> MSELoss
-> loss
print(loss.grad_fn) # MSELoss
print(loss.grad_fn.next_functions[0][0]) # Linear
print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # ReLUBackprop
要反向传播错误,我们所要做的就是使用loss.backward()。你需要清除现有的梯度,否则梯度会累积到现有的梯度上。
net.zero_grad() # zeroes the gradient buffers of all parameters
print('conv1.bias.grad before backward')
print(net.conv1.bias.grad)
loss.backward()
print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)conv1.bias.grad before backward
None
conv1.bias.grad after backward
tensor([ 0.0081, -0.0080, -0.0039, 0.0150, 0.0003, -0.0105])
更新参数
之前提到了参数更新的策略:
weight = weight - learning_rate * gradient
learning_rate = 0.01
for f in net.parameters():
f.data.sub_(f.grad.data * learning_rate)当你使用神经网络时,你想要使用各种不同的更新规则,如SGD、Nesterov-SGD、Adam、RMSProp等。因此可以使用torch.optim工具来做这件事。
import torch.optim as optim
# create your optimizer
optimizer = optim.SGD(net.parameters(), lr=0.01)
# in your training loop:
optimizer.zero_grad() # zero the gradient buffers
output = net(input)
loss = criterion(output, target)
loss.backward()
optimizer.step() # Does the updateTraining a Classifier — PyTorch Tutorials 2.2.0+cu121 documentation
数据
Generally, when you have to deal with image, text, audio or video data, you can use standard python packages that load data into a numpy array. Then you can convert this array into a
torch.*Tensor.
For images, packages such as Pillow, OpenCV are useful
For audio, packages such as scipy and librosa
For text, either raw Python or Cython based loading, or NLTK and SpaCy are useful
Specifically for vision, we have created a package called
torchvision, that has data loaders for common datasets such as ImageNet, CIFAR10, MNIST, etc. and data transformers for images, viz.,torchvision.datasetsandtorch.utils.data.DataLoader.This provides a huge convenience and avoids writing boilerplate code.
这里使用的是CIFAR10数据集,即图像和他们的分类,总共10类。
载入和正则化CIFAR10数据集
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
batch_size = 4
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')torchvision.datasets.CIFAR10:返回(image, target) where target is index of the target class.
注意,这里的transform若为None,不经过任何转换,则trainset中保存的图片的格式是
torch.utils.data.DataLoader该如何使用? - 知乎 (zhihu.com)
Dataset定义了数据集的内容,它相当于一个类似列表的数据结构,具有确定的长度,能够用索引获取数据集中的元素。
而DataLoader定义了按batch加载数据集的方法,它是一个实现了
__iter__方法的可迭代对象,每次迭代输出一个batch的数据。DataLoader能够控制batch的大小,batch中元素的采样方法,以及将batch结果整理成模型所需输入形式的方法,并且能够使用多进程读取数据。
在绝大部分情况下,用户只需实现Dataset的
__len__方法和__getitem__方法,就可以轻松构建自己的数据集,并用DataLoader进行加载。对于一些复杂的数据集,用户可能还要自己设计 DataLoader中的
collate_fn方法以便将获取的一个批次的数据整理成模型需要的输入形式。
作者:一个有毅力的吃货
链接:https://www.zhihu.com/question/455402789/answer/2647638722
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
展示数据集
(不一定要做,不过一般大家都有自己的熟悉数据集的方法,我个人会做一些基础的统计之类的)
import matplotlib.pyplot as plt
import numpy as np
# functions to show an image
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# get some random training images
dataiter = iter(trainloader)
images, labels = next(dataiter)
# show images
imshow(torchvision.utils.make_grid(images))
# print labels
print(' '.join(f'{classes[labels[j]]:5s}' for j in range(batch_size)))
frog plane deer car
定义CNN网络
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1) # flatten all dimensions except batch
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()这一网络同之前的网络相同。
定义Loss function和optimizer
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)训练
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}')
running_loss = 0.0
print('Finished Training')两个epoch,每次都只加载进来一个batch。首先把梯度归零,前向传播,得到当前的输出,计算loss,反向传播,更新参数。
每2000个mini-batch,输出一个平均损失。
PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)保存训练好的模型。
测试
net = Net()
net.load_state_dict(torch.load(PATH))重新加载保存的模型(注意:这里不需要保存和重新加载模型,只是说明可以这么做)
correct = 0
total = 0
# since we're not training, we don't need to calculate the gradients for our outputs
with torch.no_grad():
for data in testloader:
images, labels = data
# calculate outputs by running images through the network
outputs = net(images)
# the class with the highest energy is what we choose as prediction
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the network on the 10000 test images: {100 * correct // total} %')Accuracy of the network on the 10000 test images: 55 %
整体的正确率。
# prepare to count predictions for each class
correct_pred = {classname: 0 for classname in classes}
total_pred = {classname: 0 for classname in classes}
# again no gradients needed
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predictions = torch.max(outputs, 1)
# collect the correct predictions for each class
for label, prediction in zip(labels, predictions):
if label == prediction:
correct_pred[classes[label]] += 1
total_pred[classes[label]] += 1
# print accuracy for each class
for classname, correct_count in correct_pred.items():
accuracy = 100 * float(correct_count) / total_pred[classname]
print(f'Accuracy for class: {classname:5s} is {accuracy:.1f} %')Accuracy for class: plane is 43.5 %
Accuracy for class: car is 67.2 %
Accuracy for class: bird is 44.7 %
Accuracy for class: cat is 29.5 %
Accuracy for class: deer is 48.9 %
Accuracy for class: dog is 47.0 %
Accuracy for class: frog is 60.5 %
Accuracy for class: horse is 70.9 %
Accuracy for class: ship is 79.8 %
Accuracy for class: truck is 65.4 %
查看不同的种类的accuracy。
Learning PyTorch with Examples — PyTorch Tutorials 2.2.0+cu121 documentation
这是一个比较老的tutorial,所以主要是用比较from scratch的方法,可以看一看。
The Unreasonable Effectiveness of Recurrent Neural Networks (karpathy.github.io)
Recurrent Neural Networks
Sequences
循环网络允许我们对向量序列进行操作,无论是输入的sequence还是输出的sequence。

对上面图像从左到右依次举例为图像分类,图像字幕(获取图像并输出一个句子),情感分析(将给定的句子分类为表达积极或消极的情绪),翻译,视频分类。
RNN将输入向量与状态向量结合起来,并使用一个固定的(但可以学习的)函数来产生一个新的状态向量。在编程术语中,这可以解释为运行具有特定输入和一些内部变量的固定程序。从这个角度来看,RNN本质上是描述程序。
(我其实没太看明白这里是什么意思,大概猜测一下,要说的就是不进关注当前的输入也关注状态,这个状态很有可能和HMM是相关的,也就是在出现词A的前提下跳转到词B的概率这种)
RNN computation
接受一个输入向量x,并给你一个输出向量y。然而,关键的是,这个输出向量的内容不仅受到你刚刚输入的输入的影响,还受到你过去输入的整个历史的影响。
RNN类有一些内部状态,每次调用时都会更新这些状态。在最简单的情况下,这个状态由一个隐藏向量h组成。
class RNN:
# ...
def step(self, x):
# update the hidden state
self.h = np.tanh(np.dot(self.W_hh, self.h) + np.dot(self.W_xh, x))
# compute the output vector
y = np.dot(self.W_hy, self.h)
return y假设我们只有四个可能的字母“hello”的词汇表,并且想在训练序列“hello”上训练一个RNN。这个训练序列实际上是4个独立训练示例的来源:1。在“h”的背景下,“e”的概率应该是可能的。3. " l "应该出现在"he"的上下文中。考虑到“hel”的上下文,“l”也应该是可能的,最后4。考虑到“hell”的上下文,“o”应该是可能的。
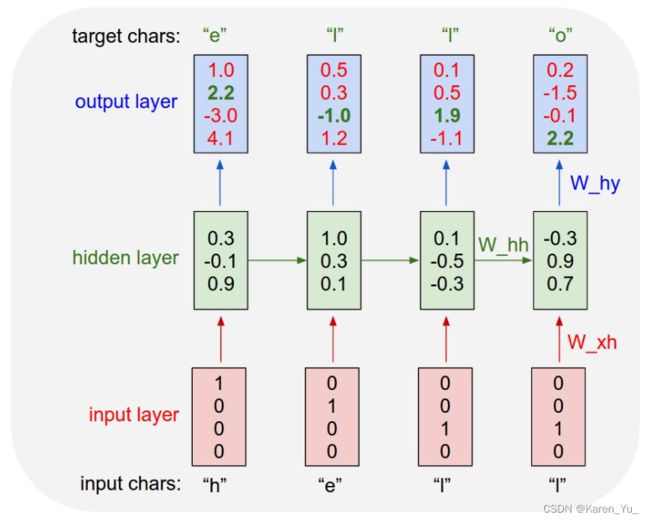
例如,我们看到,在第一个时间节点,当RNN看到字符“h”时,它为下一个字母“h”分配置信度为1.0,为字母“e”分配置信度为2.2,为“l”分配置信度为-3.0,为“o”分配置信度为4.1。由于在我们的训练数据(字符串“hello”)中,下一个正确的字符是“e”,我们希望增加它的置信度(绿色)并降低所有其他字母的置信度(红色)。
大概看了一下后续的内容都是举例了,感兴趣可以自己去看看。
Understanding LSTM Networks -- colah's blog
Humans don’t start their thinking from scratch every second. As you read this essay, you understand each word based on your understanding of previous words. You don’t throw everything away and start thinking from scratch again. Your thoughts have persistence.
Traditional neural networks can’t do this, and it seems like a major shortcoming. For example, imagine you want to classify what kind of event is happening at every point in a movie. It’s unclear how a traditional neural network could use its reasoning about previous events in the film to inform later ones.
人类不会每一秒都从零开始思考。当你阅读这篇文章时,你是基于对前面单词的理解来理解每个单词的。你不会把所有东西都扔掉,重新开始思考。你的思想具有持久性。
传统的神经网络不能做到这一点,这似乎是一个主要的缺点。例如,假设您想对电影中每个点发生的事件进行分类。目前还不清楚传统的神经网络如何利用它对电影中先前事件的推理来通知后来的事件。(简单来说就是我们理解文章或者电影的时候并不是只理解当前读到或者看到的某个字/情节,而是会结合上下文或者其他的信息来理解)
在上图中,循环允许信息从网络的一个步骤传递到下一个步骤。
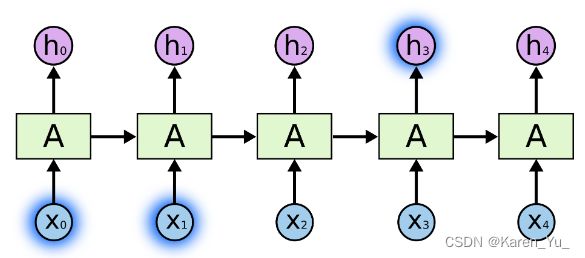
虽然看起来不太一样,但是实际上与普通的神经网络并没有什么不同。递归神经网络可以被认为是同一网络的多个副本,每个副本向后继网络传递一条消息。如果展开循环会得到:

有时,我们只需要查看最近的信息来执行当前的任务。例如,考虑一个语言模型,它试图根据前面的单词预测下一个单词。如果我们要预测“the clouds are in the ___”,我们不需要更多的上下文了,很明显下一个单词是sky。在这种情况下,相关信息与需要信息的地方之间的差距很小,rnn可以学习使用过去的信息。
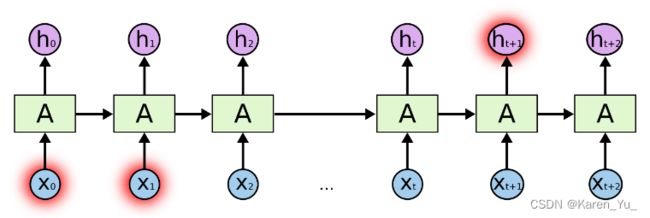
但也有一些情况我们需要更多的背景。试着预测“I grew up in France... I speak fluent _____”这篇文章的最后一个单词。最近的信息表明,下一个词可能是一种语言的名称,但如果我们想要缩小范围,我们需要法国的背景,从更远的地方。相关信息与需要信息的点之间的差距完全有可能变得非常大。
不幸的是,随着差距的扩大,rnn变得无法学习连接信息。
->LSTM
Long Short Term Memory Networks是一种特殊的RNN,能够学习长期依赖关系,被明确设计为避免长期依赖问题。长时间记住信息实际上是他们的默认行为,并不是学习所得。
所有的递归神经网络都具有神经网络重复模块链的形式。在标准的rnn中,这个重复模块将具有非常简单的结构,例如单个tanh层。
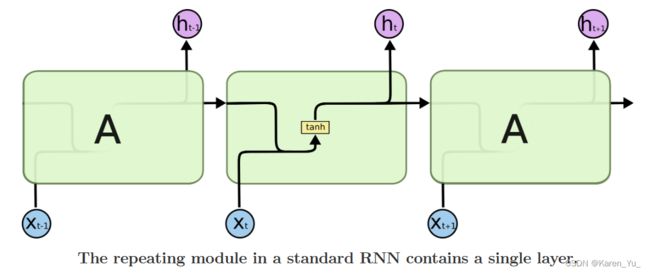
LSTM也具有这种链式结构,但重复模块具有不同的结构。

剩下的内容基本与课程中的类似,在此不做赘述。