get请求,中文乱码解决 之 百度如何正确获取中文请求参数(我猜测)
url查询串不直接支持中文等非ASCII码表符号的传输,需要经过浏览器采取一种编码方案将中文字符编码为可用于url传输的符号(也就是ASCII码的符号)。除这种类似中文查询串的情况外,url中有特殊用途的符号,例如%,@, :, &,#,?等也不能直接传输,同样需要编码后传输。关于URL编码的知识,大家可以看看 阮一峰<关于URL编码>,其中细节可能已经变化,比如Firefox也是UTF-8了,但总体思路没变。
但比较蛋疼的是,由于标准没有规定,一个浏览器究竟应该采取哪种编码应对这种情况。所以各家浏览器各行其是(其实主要是IE)。所以服务端在接收参数的时候必须知道浏览器是采用的哪种编码方式,然后才好在服务端程序中采用这一编码进行解码(纯英文的就不用了,各种编码方案都兼容ASCII,ASCII是各种编码的子集)。这里详细要讲的就是如何实现中文参数的正确获取;其实就是服务端获知浏览器采用的编码方案,用此方案来解码。post请求只能通过表单提交,而且是采用页面编码。页面编码是可以服务端约定的,不存在服务端不知情的情况,所以不讨论post提交方式。这里只说get请求包含中文的正确获取方式。
乱码的根本原因在于编码和解码采取的编码方案不一致
解码:如果知道请求就是用的utf-8来编码的,而Tomcat默认使用iso-8859-1来解码。因为编码解码方案不同,所以request.getParameter("")接收到的是一堆乱码。那么怎么获取到原本传输的字符呢,可以把getParameter("xxx")得到的用iso-8859-1编码的字符串,打回字节原型,再用这个字节数组解码为浏览器采用的编码。所以可以这样
String xxx = request.getParameter("xxx")
if(xxx!=null){
xxx = new String(xxx.getBytes("iso-8859-1"), "utf-8");也就是,只要我们确定了请求的编码方案,就可以完成中文参数的正确获取。可是问题在于,get请求采取的编码方案是不一定的,并不是一定是utf-8,也并不总是utf-8。
但是虽然采取的编码方案不同,传输形式都是相同的(IE地址栏直接输入除外),都是通过把查询串通过浏览器采取的编码方案编码成字节,每个字节用16进制表示,同时在前边加%;所以%在url中有特殊用途,如果真的想查询%,也需要编码。
以utf-8为例,如果我想要查询"我爱*java%",浏览器会编码为"%E6%88%91%E7%88%B1*java%25",其中
"%E6%88%91%E7%88%B1"是"我爱"的utf-8编码,
"*"不是特殊字符,编码后仍然是*,
"java"也不是特殊字符,编码后仍然是"java"。
"%",就是特殊字符,用utf-8编码为"%25"。
像"%"、"&"、"="...这些在URL中有用途的都是特殊字符,需要重新编码。就像java字符串中\需要转义为\\,"需要转义为\"道理是一样的。请参考<关于URL编码>。java中可以用如下两个工具类进行URL的编码和解码。
URLEncoder.encode("我爱*java%", "utf-8");//编码,使用utf-8,返回"%E6%88%91%E7%88%B1"
URLDecoder.decode("%E6%88%91%E7%88%B1", "utf-8"); //解码,使用utf-8,返回"我爱*java%"大家都知道,百度是最大的中文搜索引擎,而且搜索引擎都不会采用post方式的。所以以它为例(其实我是通过对百度对不同参数、不同方式,以及request.getParameter()和request.getQuerystring()相对应情况来研究学习的)。
经过测试,以及网络搜索。一个浏览器采取的编码根据get请求参数、方式的不同而不同。
get请求分两种:1、地址栏直接键入,回车。2、页面表单提交(其实还是地址栏,但表单是有标记,可控制的)。
1、通过表单提交:
因为表单提交默认采取页面编码,而页面编码是约定好的,是可知的,而且表单是可控制的。所以表单的情况相对简单,先说表单。请求消息头有一个属性叫referer,可以用request.getHeader("referer")获得,如果是通过表单,会有这个头存在的,他的值是表单所在url,如果是地址栏,这个值是没有的,通过request.getHeader("referer")是否==null,我们就可以分辩请求来自哪里,如果没有来源,就认为其是浏览器地址栏; 知道了请求来自表单,剩下的就是怎么知道表单页面的编码了。所以可以通过添加一个隐藏表单项,例如,键为encoding,值为约定的页面编码的英文表示,可以是类似"utf8"、"utf-8"这样的字符串,因为英文总是不会乱码的。这样服务端就可以获取这个encoding的值,根据request.getParameter("encoding")的值选取不同的编码方案解码。如果我们开发的系统只是自己使用,而且确定用的是utf-8,也就是说只要是表单,就是用的utf-8提交。其实这个隐藏也不是必要的,完全可以通过referer的有无,来分辨是不是表单提交,如果是表单,就utf-8。百度搜索时(后面都用百度举例),百度除了会传送wd搜索词外还会传送一些hiddeng的表单项,比如搜索“Test”,如下“
https://www.baidu.com/s?wd=Test&rsv_spt=1&issp=1&f=8&rsv_bp=0&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_sug3=2&rsv_sug1=2&rsv_sug2=0&inputT=3306&rsv_sug4=4981”,
其中两个参数比较感兴趣,wd=Test,ie=utf-8;wd=Test是搜索词,无需赘言;ie=utf-8是什么,我试着用各种浏览器(不止IE)百度搜索框(表单)搜索,发现都有ie=utf-8这个表单项,看来这个ie=utf-8并不是表示使用的什么浏览器,而是表达的页面的编码。类似上面说的encoding,百度可能是这样,这个ie的作用就是上面encoding的作用。百度之所以用ie而不用encoding等含义的词,可能是因为ie太奇葩了,为什么还给了utf-8这个值呢?我猜有几个原因:
1、可扩展性:页面的编码可能会换的,比如用gbk。
2、ie=utf-8作为一个接口,可以开放给别的网站、软件使用。很多网站(例如hao123导航,可能页面并不是用的utf-8)或者软件(比如浏览器的搜索栏)嵌入了百度搜索框,如果网站或软件本身用的就是gbk编码,完全可以传参ie=gbk,告知百度用gbk解析。到此ie或者encoding的值就起作用了。
2、地址栏直接输入
FireFox: "我"-----utf-8--encode------------"%E6%88%91"
360jisu: "我"-----utf-8--encode------------"%E6%88%91"
发现firefox等浏览器采用utf-8编码,仍然是%加字节16进制表示
IE:采用gbk,但不进行url编码,也就是直接二进制,而不是%加16进制的形式
一下是各浏览器请求的user-gent头user-agent:
FireFox : Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.0
IE : Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko
360jisu : Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/7.0)
至此,我们完成了无论是通过表单还是地址栏,无论采用哪种浏览器。我们都能在服务端获取到正确中文参数。貌似问题都解决了,但其实还有一个问题没有解决。百度的搜索结果是可传播的,这是采用get请求的一个主要原因。因为每个搜索结果页,对应一个地址(或者多个地址)。百度不希望,复制火狐中的搜索页地址,粘贴到IE中就成为一堆乱码的搜索结果。比如我用火狐搜索“我”的地址“http://www.baidu.com/s?wd=%E6%88%91”粘贴到IE中也应该是“我”的结果页,
而实际上百度(等等中文搜索引擎)甚至做到了
无论我地址栏输入下面哪个网址,在哪个浏览器:
http://www.baidu.com/s?wd=我
http://www.baidu.com/s?wd=%E6%88%91
http://www.baidu.com/s?wd=%CE%D2
更甚至:
http://www.baidu.com/s?wd=%
http://www.baidu.com/s?wd==
http://www.baidu.com/s?wd=/
http://www.baidu.com/s?wd=.
http://www.baidu.com/s?wd=?
都能够得到希望的结果页
这些url中的特殊用途的"%"、"="、"/''、".''、"?''也能得到期待的结果页。
可见百度的强大。
众所周知,百度是用php实现的,而且也看不到它的源码。所以我很好奇。
我相信php能解决的问题,java也能解决,不就是个编码的问题嘛。然后发现request除了有getParameter()这个方法。还有一个叫getQueryString()的方法,这才是必杀技,它会得到url中从?开始后面的所有内容表示的iso-8859-1的字符串。
同样是"我"字,用getQueryString()得到的结果
地址栏输入:
FireFox : getQueryString();//"?name=%E6%88%91"
IE : getQueryString();//"?name=ÎÒ"
表单:
UTF-8 : getQueryString();//"?name=%E6%88%91"
GBK : getQueryString();//"?name=%ce%d2"
"%"、"="、"/"、"."、"?"还是它们自己,比如"?name=%"
这样可以利用,得到的queryString中=右边带不带%来解决了,不再用getHeader("referer")了。不带%的,就用gbk。带%的怎么办呢,它可能是utf-8,也可能是gbk啊。
我用百度表单提交了“이민호”这个韩文搜索串(李敏镐的韩文名,不感冒,只是拿来测试用的),发现没什么异常,能够得到正确的结果。上面使用表单提交是可控的,表单和JavaScript可以处理一些事情, 它会自动添加“ie=utf-8”的参数。但是当我把ie=utf-8这一参数去掉,直接用"http://www.baidu.com/?wd=이민호"地址栏提交时,只提供wd=이민호,不提供其他的参数,然后发现我把百度给干败了。
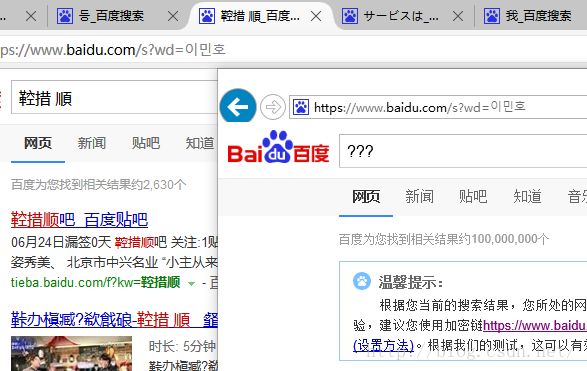
先来看IE的结果:可想而知,百度只是对中文做了搜索优化,他总是试图把得到的搜索串往中文转。也就是说得到不带%的就用gbk解码,结果이민호在gbk中不存在,得到了“???”,
再来看FireFox的结果,而“이민호”用utf-8编码然后url编码为“%EC%9D%B4%EB%AF%BC%ED%98%B8”,这个字符串是带%的,怎么办呢。以下是对“이민호”的URL编解码
String lmh="이민호";
//将lmh编码为带%的url格式"%EC%9D%B4%EB%AF%BC%ED%98%B8";
String lmhUtf8Url = URLEncoder.encode(lmh, "utf-8");
//将utf-8格式的url分别使用gbk和utf-8解码
String gbk = URLDecoder.decode(lmhUtf8Url, "gbk");
String utf = URLDecoder.decode(lmhUtf8Url, "utf-8");
System.out.println(gbk);//鞚措順�
System.out.println(utf);//이민호虽然发送的是utf-8的url编码,因为没有传“ie=utf-8”这个参数,它还是优先尝试用gbk解码,解码为"鞚措順�",然后去除不是中文的部分,所以搜索结果变成了“鞚措順”。
然后我分别用
http://www.baidu.com/s?wd=이민호&ie=gbk
http://www.baidu.com/s?wd=이민호&ie=utf-8
http://www.baidu.com/s?wd=이민호
这三个网址在FireFox、IE地址栏访问,发现了这个:
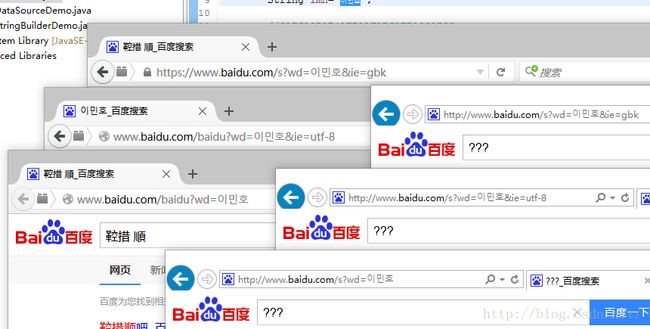
只有用firefox且添加了ie=utf-8猜得到了正确的结果。
而当我把“http://www.baidu.com/s?wd=이민호”替换为“http://www.baidu.com/s?wd=我爱이민호”,发现在forefox又得到了正确结果:
总结起来就是:
百度并不是根据user-agent这个请求头采取解码方案,也不用“referer”请求头分辨请求来源。而是:
首先看搜索串有没有%,没有的用gbk。有%的,采用ie=xxx的xxx解码。如果没有ie=xxx,就优先采用utf对带%的url进行解码,如果包含汉字,就执行搜索,如果解码后,发现里面不包含汉字,就转用gbk去解码。用java代码去模拟,就是这样:
String queryString = request.getQueryString();
String wd = request.getParameter("wd");
String decoded_wd = null;//解码后
if (wd != null) {// wd不为空才进行解码
if (!queryString.contains("%")) {// 不包含 % 就用 gbk 解码
decoded_wd = new String(wd.getBytes("iso-8859-1"), "gbk");
} else { // 包含%分支 之有ie参数
String ie = request.getParameter("ie");
// 如果 ie 有值 且是受支持的,比如只能是utf-8和gbk
if ("utf-8".equals(ie) || "gbk".equals(ie)) {
decoded_wd = new String(wd.getBytes("iso-8859-1"), ie);
}
} else {// 包含%分支之,ie没有值, 或值不受支持
// 先用utf-8
decoded_wd = new String(wd.getBytes("iso-8859-1"), "utf-8");
//如果解码后不包含中文 ,再用gbk
if (!isContainsChineseChar(decoded_wd)) {
decoded_wd = new String(wd.getBytes("iso-8859-1"), "gbk");
}
}
}