数据结构——堆排序
什么是堆排序
堆排序就是利用堆(假设利用大堆)进行排序的算法。他的基本思想是,将待排序的序列构造成一个大顶堆。此时,整个序列的最大值就是堆顶的根节点。将他移走(其实就是将其与堆数组的末尾元素交换,此时末尾元素就是最大值),然后将剩余的n-1个序列重新构造成一个堆,这样就会得到n个元素中的次大值。如此反复执行,便能得到一个有序序列了。
建堆
首先我们需要对数组中元素int a[] = { 6,1,2,7,9,3,4,5,10,8 }建大堆。下面我们开始建堆。
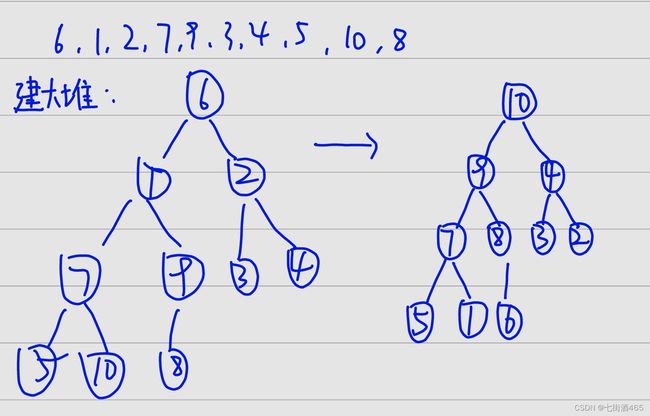
向下调整
我们知道完全二叉树的孩子结点child=parent*2+1;我们建大堆就需要找大的结点的值。
我们假设左结点的值大,如果右节点a[child+1]>左节点a[child],那child=child+1;即
while ()
{
if (a[child + 1] > a[child])
{
child = child + 1;
}
}接下来我们用child的值和父亲节点parent的值比较,如果,a[child]>a[parent],则交换这两个值,然后新的parent结点为child,新的child=新的parent*2+1,如果不满足这个条件的话,就跳出break。
void AdjustDown(int* a, int n, int parent)
{
int child = parent * 2 + 1;
while ()
{
if (a[child + 1] > a[child])
{
child = child + 1;
}
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}这个时候我们要判断这个循环什么时候停止,child每次和parent交换完都会child=parent*2+1;当child>n结点个数的时候就不需要继续再往下找大了,即循环停止。
即
while (child这个时候我们还需要考虑的是我们在找左节点和右节点中较大的值的时候,如果此时child==n的话,那child+1就会越界了。所以我们要加上限定条件child+1 这个时候我们已经完成了向下调整。此时我们只需要把数组中数据建大堆即可。 首先我们要先用for循环从最后一个结点开始找他的父节点和左右节点中大的与父节点比较,所以找的第一个父节点为(n-1)-1/2;i--,直到i>=0时一直向下调整建堆。 这个时候大堆就已经建好了,此时堆顶元素是这个堆的最大值,我们用堆尾元素(end=n-1)与堆顶元素,此时最大值就来到了堆尾,然后继续向下调整保证前n-1个数还能保持大堆,再把end--,把最大的固定其位置,直到n=0时停止 这个时候堆排序就完整的写完啦。我们测试运行。 堆排序的效率到底有多高呢?我们来分析一下。它的运行时间主要消耗在初始构建堆和重建堆的反复筛选上。在构建堆的过程中,因为我们是完全二叉树从最下层最右边的非终端节点开始构建,将他与其孩子进行比较,若有必要进行交换,对于每个非终端结点来说,其实最多进行两次比较和呼唤操作,因次整个构建堆的时间复杂度为O(n)。 在正式排序时,第 i 次取堆顶记录重建堆需要用 O ( logi )的时间(完全二叉树的某个结点到根结点的距离为 (log i+1),并且需要取 n -1次堆顶记录,因此,重建堆的时间复杂度为 O ( nlogn )。void AdjustDown(int* a, int n, int parent)
{
int child = parent * 2 + 1;
while (child建大堆
void HeapSort(int*a,int n)
{
for (int i = (n - 1 - 1) / 2; i >= 0; i--)//建堆
{
AdjustDown(a, n, i);
}
}int end = n - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
end--;
}测试
int main()
{
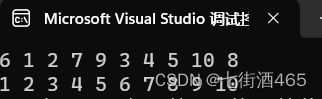
int a[] = { 6,1,2,7,9,3,4,5,10,8 };
int n = sizeof(a) / sizeof(a[0]);
for (int i = 0; i < n; i++)
{
printf("%d ", a[i]);
}
printf("\n");
HeapSort(a, n);
for (int i = 0; i < n; i++)
{
printf("%d ", a[i]);
}
return 0;
}
复杂度
所以总体来说,堆排序的时间复杂度为 O ( nlogn )。由于堆排序对原始记录的排序状态并不敏感,因此它无论是最好、最坏和平均时间复杂度均为 O ( nlogn )。这在性能上显然要远远好过于冒泡、简单选择、直接插入的 O (n2)的时间复杂度了。
空间复杂度上,它只有一个用来交换的暂存单元,也非常的不错。不过由于记录的比较与交换是跳跃式进行的,因此堆排序也是一种不稳定的排序方法。
另外,由于初始构建堆所需的比较次数较多,因此,它并不适合待排序序列个数较少的情况。源码
#include