【数据库】聊聊常见的索引优化-上
数据库对于现有互联网应用来说,其实是非常重要的后端存储组件,而大多数系统故障都是由于存储所导致的,而数据库是重中之重,所以为了比较好掌握SQL的基本优化手段,打算用两篇文章从基本的联合索引优化、group by/order by 优化、以及索引设计原则、分页查询、join 查询、count 统计,以及阿里sql手册进行介绍。
本篇先介绍粗体字的相关内容,下一篇介绍剩余部分。
数据准备
CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='员工记录表';
INSERT INTO employees(name,age,position,hire_time) VALUES('LiLei',22,'manager',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('HanMeimei', 23,'dev',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('Lucy',23,'dev',NOW());
‐‐ 插入一些示例数据
drop procedure if exists insert_emp;
delimiter ;;
create procedure insert_emp()
begin
declare i int;
set i=1;
while(i<=100000)do
insert into employees(name,age,position) values(CONCAT('zhuge',i),i,'dev');
set i=i+1;
end while;
end;;
delimiter ;
call insert_emp();
联合索引
第一个字段用范围不会走索引

如上所示,name、age、position是一个联合索引,name使用范围查询后,索引失效。
使用强制索引后,发现减少了查询数据量。
添加强制索引
EXPLAIN SELECT * FROM employees force index(idx_name_age_position) WHERE name > 'LiLei' AND age = 22 AND position = 'manager';

在很多场景下联合索引的返回值,就是我们希望的返回值,所以我们可以直接将* 替换成自己想要的值。其实就是覆盖索引优化
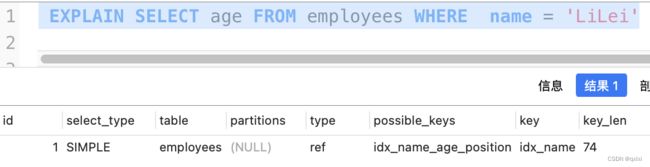
like ‘%xxx’ 索引失效
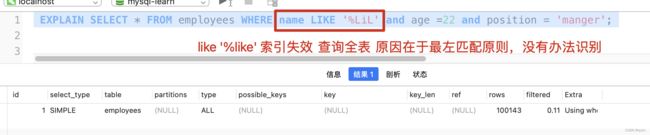
索引下推
其实就是在5.6之前是根据查询的数据按照对应的主键在逐个回表操作。但是5.6之后做了优化,可以先将不符合记录的过滤之后,在进行回表操作,可以有效减少回表的次数。但是并不能减少查询全行数据的效果。
EXPLAIN SELECT * FROM employees WHERE name LIKE 'LiL%' and age =22 and position = 'manger';
Mysql如何选择合适的索引
尽管通过explain可以分析mysql是否使用了索引,扫描行数等,但是想要获取更多细节,分析mysql如何分析sql的过程,可以借助于trace工具。
set session optimizer_trace="enabled=on",end_markers_in_json=on; -- 开启trace
EXPLAIN SELECT * FROM employees WHERE name >'zz';
SELECT * FROM information_schema.OPTIMIZER_TRACE;
set session optimizer_trace="enabled=off"; -- 关闭trace
执行完毕之后就可以获取到分析过程,整体过程其实就是分成三部分。1.准备sql 2.优化sql 3.执行sql
{
"steps": [
{
"join_preparation": { // 第一阶段:准备sql
"select#": 1,
"steps": [
{
"expanded_query": "/* select#1 */ select `employees`.`id` AS `id`,`employees`.`name` AS `name`,`employees`.`age` AS `age`,`employees`.`position` AS `position`,`employees`.`hire_time` AS `hire_time` from `employees` where (`employees`.`name` > 'zz')"
}
] /* steps */
} /* join_preparation */
},
{
"join_optimization": { // 第二阶段 SQL优化阶段
"select#": 1,
"steps": [
{
"condition_processing": { // 条件处理
"condition": "WHERE",
"original_condition": "(`employees`.`name` > 'zz')",
"steps": [
{
"transformation": "equality_propagation",
"resulting_condition": "(`employees`.`name` > 'zz')"
},
{
"transformation": "constant_propagation",
"resulting_condition": "(`employees`.`name` > 'zz')"
},
{
"transformation": "trivial_condition_removal",
"resulting_condition": "(`employees`.`name` > 'zz')"
}
] /* steps */
} /* condition_processing */
},
{
"substitute_generated_columns": {
} /* substitute_generated_columns */
},
{
"table_dependencies": [ // 表依赖详情
{
"table": "`employees`",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits": [
] /* depends_on_map_bits */
}
] /* table_dependencies */
},
{
"ref_optimizer_key_uses": [
] /* ref_optimizer_key_uses */
},
{
"rows_estimation": [ // 预估表的成本
{
"table": "`employees`",
"range_analysis": {
"table_scan": { // 全表扫描情况
"rows": 100143, // 扫描行数
"cost": 10104.7 // 查询成本
} /* table_scan */,
"potential_range_indexes": [ // 查询可能使用的索引
{
"index": "PRIMARY", // 主键索引
"usable": false,
"cause": "not_applicable"
},
{
"index": "idx_name_age_position", // 辅助索引
"usable": true,
"key_parts": [
"name",
"age",
"position",
"id"
] /* key_parts */
}
] /* potential_range_indexes */,
"setup_range_conditions": [
] /* setup_range_conditions */,
"group_index_range": {
"chosen": false,
"cause": "not_group_by_or_distinct"
} /* group_index_range */,
"skip_scan_range": {
"potential_skip_scan_indexes": [
{
"index": "idx_name_age_position",
"usable": false,
"cause": "query_references_nonkey_column"
}
] /* potential_skip_scan_indexes */
} /* skip_scan_range */,
"analyzing_range_alternatives": { // 分析各个索引使用成本
"range_scan_alternatives": [
{
"index": "idx_name_age_position",
"ranges": [
"'zz' < name" // 索引使用范围
] /* ranges */,
"index_dives_for_eq_ranges": true,
"rowid_ordered": false, //使用该索引获取的记录是否按照主键排序
"using_mrr": false,
"index_only": false, //是否使用覆盖索引
"in_memory": 1,
"rows": 1, // 索引扫描行数
"cost": 0.61, // 索引使用成本
"chosen": true // 是否选择该索引
}
] /* range_scan_alternatives */,
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
} /* analyzing_roworder_intersect */
} /* analyzing_range_alternatives */,
"chosen_range_access_summary": {
"range_access_plan": {
"type": "range_scan",
"index": "idx_name_age_position",
"rows": 1,
"ranges": [
"'zz' < name"
] /* ranges */
} /* range_access_plan */,
"rows_for_plan": 1,
"cost_for_plan": 0.61,
"chosen": true
} /* chosen_range_access_summary */
} /* range_analysis */
}
] /* rows_estimation */
},
{
"considered_execution_plans": [
{
"plan_prefix": [
] /* plan_prefix */,
"table": "`employees`",
"best_access_path": { // 最优访问路径
"considered_access_paths": [ //最终选择的访问路径
{
"rows_to_scan": 1,
"filtering_effect": [
] /* filtering_effect */,
"final_filtering_effect": 1,
"access_type": "range", //访问类型 scan全表扫描
"range_details": {
"used_index": "idx_name_age_position"
} /* range_details */,
"resulting_rows": 1,
"cost": 0.71,
"chosen": true
}
] /* considered_access_paths */
} /* best_access_path */,
"condition_filtering_pct": 100,
"rows_for_plan": 1,
"cost_for_plan": 0.71,
"chosen": true
}
] /* considered_execution_plans */
},
{
"attaching_conditions_to_tables": {
"original_condition": "(`employees`.`name` > 'zz')",
"attached_conditions_computation": [
] /* attached_conditions_computation */,
"attached_conditions_summary": [
{
"table": "`employees`",
"attached": "(`employees`.`name` > 'zz')"
}
] /* attached_conditions_summary */
} /* attaching_conditions_to_tables */
},
{
"finalizing_table_conditions": [
{
"table": "`employees`",
"original_table_condition": "(`employees`.`name` > 'zz')",
"final_table_condition ": "(`employees`.`name` > 'zz')"
}
] /* finalizing_table_conditions */
},
{
"refine_plan": [
{
"table": "`employees`",
"pushed_index_condition": "(`employees`.`name` > 'zz')",
"table_condition_attached": null
}
] /* refine_plan */
}
] /* steps */
} /* join_optimization */
},
{
"join_explain": { // 第三阶段:sql执行阶段
"select#": 1,
"steps": [
] /* steps */
} /* join_explain */
}
] /* steps */
}
Order by与Group by优化
case 1

所以age使用了索引。
case 2


同理可以发现 age用了索引,但是position没有使用索引。
case 3


可以发现,age \ position 前后顺序不一样,导致一个使用了索引一个没有使用索引,用的file sort。
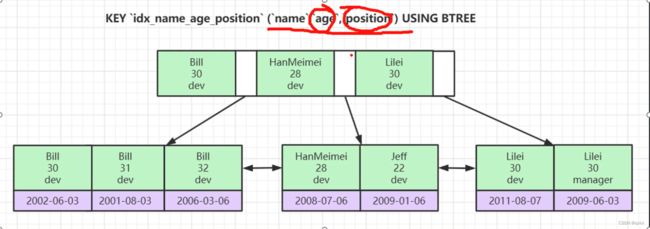
其实对比这张图就可以看出,age\position 复合最左匹配原则,position\age不符合。
case 4

可以看到并没出现file sort。age因为是常量,在排序中被优化。索引没有出现颠倒。
Using filesort文件排序原理详解
case 5


在来看这两个案例,一个用的默认排序,另一个是倒序,前者使用索引,后者是filesort。
case 6

name使用in 因为是范围查询,所以导致直接索引失效
case 7


直接查询*,发现查询10W数据,但是用覆盖索引进行优化之后,可以利用索引。数据直接降低到5W。
总结
- mysql支持两种方式的排序filesort和index,using index是指MySQL扫描索引本身完成排序。index 效率高,file sort效率低
- order by满足两种情况会使用using index
- order by 语句使用最左匹配原则
- where子句与 order by子句条件组合满足索引最左前列
- 尽量在索引上完成排序,遵循最左匹配原则
- order by的条件不在索引列上,就会产生filesort
- 能用覆盖索引就用覆盖索引
- group by与order by蕾丝,也符合最左匹配原则。对于group by的优化如果不需要排序的可以加上order by null禁止排序。注意,where高于having,能写在where中 的限定条件就不要去having限定
单路和双路排序
filesort的两种排序方式
- 单路排序,一次性取所有符合条件的数据,将数据拉到sort buffer中进行排序, sort_mode显示为 < sort_key, additional_fields > or < sort_key, packed_additional_fields >
- 双路排序,先根据条件取出对应的排序字段和可以直接定位数据的行id,在sortbuffer中进行排序。排序完在取其他需要的字段。 < sort_key, rowid >
可以通过 max_length_for_sort_data ( 默认1024字节) 进行设置。 字段总长度小于1024,使用单路排序模式,大于使用双路排序模式。
EXPLAIN SELECT * FROM employees where name = 'zhuge' ORDER BY position;
单路排序
1.根据索引查询到name='zhuge’的主键ID,通过主键id查询到对应行所有数据,取全部数据,存入sortbuffer中。
2.继续执行查找满足条件的数据。
3.继续执行上述1,2过程。
4.对结果进行整体排序,然后返回结构。
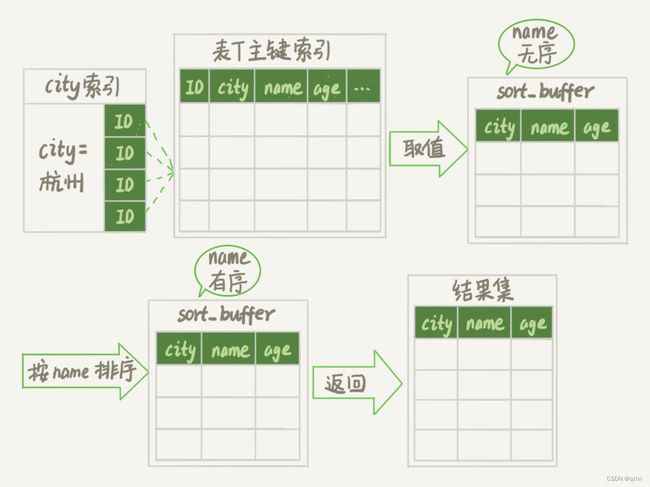
双路排序
1.根据索引查询到name='zhuge’的主键ID,通过主键id查询到对应行所有数据,取age\position字段,存入sortbuffer中。
2.继续执行查找满足条件的数据。
3.继续执行上述1,2过程。
4.对结果进行整体排序,在从原表中通过主键id查找对应全部字段的值返回。
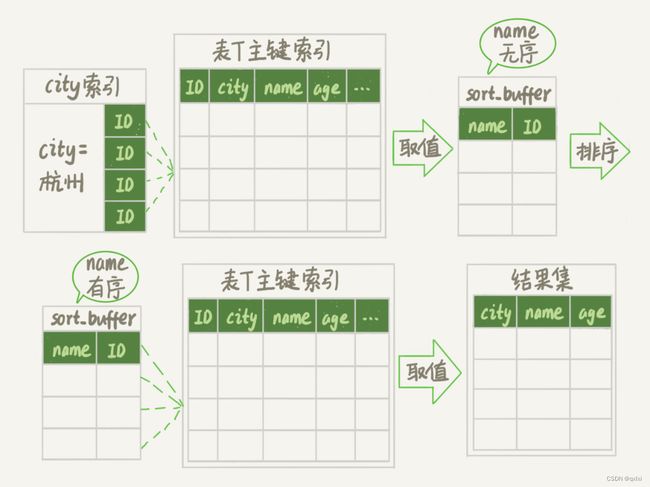
可以看出整体的差别,及时排序时是否全部字段参与,以及最后返回结果是否需要在通过主键查找需要的字段。
那么这两种有什么优劣之分?
其实需要结合具体的服务器配置,如果max_length_for_sort_data 配置的比较小,并且不可以在增加,可以使用双路排序,在有限的内存中保存更多的数据,只是需要在通过一次回表操作查询需要的数据。
而如果服务器配置比较富裕,可以通过 max_length_for_sort_data 配置的大一点,选择单路排序,直接返回对应结果集。
所以,结论就是按照场景进行区分。通过调整 max_length_for_sort_data来控制排序,不同场景使用不同的排序模式,提升性能。
索引设计原则
1.代码先上,索引后加
说白了就是,针对新系统来说的话,可以先把基础的功能开发完毕,然后将相关的SQL整体处理,划分出一些字段,平衡是否需要要添加索引。或者对于常用的字段添加索引。很多时候如果是大表,没有索引的话,每次请求都全表查询,严重的话可能直接把服务干跨。
2.联合索引尽量覆盖条件
比如针对,age、name, position,就可以建立一个组合索引,而不要针对每个索引单独在建立。
3.不要在区分度小的字段加索引
对于一些区分度小的字段,性别、省份等,其实没有必要添加
4.长字符串使用前缀索引
对于长字符串,可以使用 KEY index(name(20),age,position) 建立前缀索引,提升查询速度,也可以减少磁盘空间。
5.where与order by冲突时优先where
冲突的时候,先通过where进行选择最少数据,然后在排序。
6.基于慢sql查询做优化
平时除了一些业务研发,还需要监控系统层面的慢SQL。
推荐看看:https://blog.csdn.net/qq_40884473/article/details/89455740
总结
本篇主要从组合索引的使用,优化以及order by 优化,索引的一些设计原则。下一篇我们聊聊分页,count,join优化。