计算机组成原理:流水线Pipelining
RISC 管道Pipelines
RISC 处理器管道的运行方式大致相同,尽管管道中的阶段不同。虽然不同的处理器具有不同的步骤数,但它们基本上是MIPS R3000处理器中使用的这五个步骤的变体:
1.从内存中获取指令
2.读取寄存器并解码指令
3.执行指令或计算地址
4.访问数据存储器中的操作数
5.将结果写入寄存器
由于RISC指令比前RISC处理器(现在称为CISC或复杂指令集计算机)中使用的指令更简单,因此它们更有利于流水线。虽然CISC指令的长度各不相同,但RISC指令的长度相同,可以在单个操作中获取。理想情况下,RISC 处理器管道中的每个阶段都应采用 1 个时钟周期,以便处理器在每个时钟周期完成一条指令,并且平均每条指令一个周期 (CPI)。
管道的问题
然而。。。
在实践中,RISC处理器每条指令运行多个周期。处理器可能偶尔会因数据依赖关系和分支指令而停止。
当指令依赖于先前指令的结果时,就会发生数据依赖关系。特定指令可能需要尚未存储的寄存器中的数据,因为这是尚未达到管道中该步骤的先前指令的工作。
例如:
add $r3, $r2, $r1
add $r5, $r4, $r3
...
...更多独立于前两个的指令...
在此示例中,第一条指令告诉处理器添加寄存器 r1 和 r2 的内容,并将结果存储在寄存器 r3 中。第二个指示它添加 r3 和 r4 并将总和存储在 r5 中。我们将这组指令放在管道中。当第二条指令处于第二阶段时,处理器将尝试从寄存器读取r3和r4。但请记住,第一条指令仅比第二条指令领先一步,因此正在添加r1和r2的内容,但结果尚未写入寄存器r3。因此,第二条指令无法从寄存器 r3 读取,因为它尚未写入,必须等到存储所需的数据。因此,管道停滞,许多空指令(称为气泡bubbles)进入管道。数据依赖性对长管道的影响大于对较短管道的影响,因为指令需要更长的时间才能到达长管道的最终寄存器写入阶段。
MIPS" 解决这个问题的解决方案是代码重新排序。如果(如上面的示例所示),则以下指令与前两个指令无关,则可以重新排列代码,以便在两个依赖指令之间执行这些指令,并且管道可以有效地流动。代码重新排序的任务通常留给编译器,编译器识别数据依赖关系并尝试最大程度地减少性能停滞。
分支指令(Branch instructions)是那些告诉处理器根据另一条指令的结果来决定要执行的下一条指令的指令。如果分支以尚未完成其通过管道的路径的指令的结果为条件,则分支指令在管道中可能会很麻烦。
e.g.:
Loop : add $r3, $r2, $r1
sub $r6, $r5, $r4
beq $r3, $r6, Loop
上面的示例指示处理器添加 r1 和 r2 并将结果放在 r3 中,然后从 r5 中减去 r4,将差值存储在 r6 中。在第三条指令中,beq 代表如果相等的分支。如果 r3 和 r6 的内容相等,处理器应执行标记为"循环"的指令。否则,它应继续执行下一个指令。在此示例中,处理器无法决定采用哪个分支,因为 r3 或 r6 的值尚未写入寄存器。
处理器可能会停止,但处理分支指令的更复杂的方法是分支预测。处理器猜测要采用的路径 --如果猜测错误,则必须清除写入寄存器的任何内容,并且必须使用正确的指令再次启动管道。分支预测的一些方法依赖于刻板行为。指向后方的分支大约在 90% 的时间内被占用,因为向后指向的分支通常位于循环的底部。另一方面,指向前方的树枝仅被占用大约50%的时间。因此,处理器在分支指向后方时始终遵循分支,而不是在分支指向前方时遵循分支,这是合乎逻辑的。分支预测的其他方法不太静态:使用动态预测的处理器为每个分支保留历史记录,并使用它来预测未来的分支。这些处理器在 90% 的时间内预测是正确的。
还有一些处理器放弃了整个分支预测的考验。RISC System/6000从分支的两端获取并开始解码指令。当它确定应遵循哪个分支时,它会在管道中向下发送要执行的正确指令。
流水线开发 Pipelining Developments
为了使处理器更快,已经设计了各种优化管道的方法。
超级管道是指将管道划分为更多步骤。管道级越多,管道速度越快,因为每个阶段都更短。(如同你用一根管子和五根管子放水的区别)理想情况下,具有五个阶段的管道应比非管道处理器(或者更确切地说,具有一个阶段的管道)快五倍。指令以每个阶段完成的速度执行,每个阶段花费的时间是非流水线指令所用时间的五分之一。因此,具有8步流水线的处理器(MIPS R4000)将比其5步对应物更快。MIPS R4000 将其管道分成更多部分,将一些步骤一分为二。例如,指令获取现在分两个阶段完成,而不是一个阶段。这些阶段如下所示:
Instruction Fetch (First Half) //取指令(上半部分)
Instruction Fetch (Second Half)//取指令(后半部分)
Register Fetch //获取寄存器
Instruction Execute //执行指令
Data Cache Access (First Half)//数据缓存存取(上半部分)
Data Cache Access (Second Half)//数据快取存取(下半部分)
Tag Check//标签检查
Write Back//回信
超标量流水线(Superscalar pipelining)涉及并行的多个管道。复制处理器的内部组件,以便它可以在其部分或全部管道阶段启动多个指令。RISC System/6000具有分叉流水线,具有不同的浮点和整数指令路径。如果程序中混合了这两种类型,则处理器可以保持两个分叉同时运行。这两种类型的指令在分叉之前共享两个初始阶段(指令提取和指令调度Instruction Fetch and Instruction Dispatch)。然而,超标量流水线通常是指所有管道阶段的多个副本(就洗衣而言,这意味着四个洗衣机,四个烘干机和四个折叠衣服的人)。今天的许多机器都试图找到两到六条指令,它可以在每个管道阶段执行。但是,如果某些指令是相关的,则仅发出第一条指令或指令。
动态管道(Dynamic pipelines)能够围绕失速进行调度。动态管道分为三个单元:指令获取和解码单元( the instruction fetch and decode unit )、五到十个执行或功能单元以及一个提交单元。每个执行单元都有预留站,它们充当缓冲区(buffer)并保存操作数和操作。
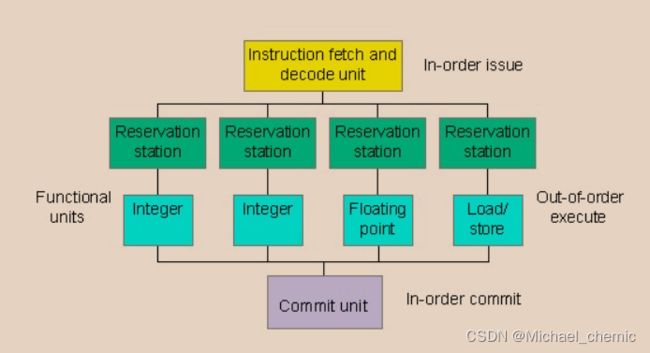
虽然功能单元可以自由无序执行,但指令获取/解码和提交单元必须运行,以保持简单的流水线行为。当执行指令并计算结果时,提交单元决定何时可以安全地存储结果。如果发生停顿,处理器可以安排执行其他指令,直到解决失速问题。这一点,再加上多个单元同时执行指令的效率,使动态管道成为一种有吸引力的替代方案。对了,洗衣机部分删减。