【SpringBoot学习】02-2开发实用篇(热部署、配置、NoSQL、整合第三方技术)
SpringBoot(B站黑马)学习笔记
01基础篇
02-1运维实用篇(打包与运行、多环境配置、日志)
02-2开发实用篇(热部署、配置、NoSQL、整合第三方技术)
03SpringCache
04SpringSecurity
文章目录
- SpringBoot(B站黑马)学习笔记
- 前言
- 02-2开发实用篇
- 热部署
-
- 手动启动热部署
- 自动启动热部署
- 热部署范围配置
- 关闭热部署
- 配置高级
-
- @ConfigurationProperties(第三方bean属性绑定)
- 松散绑定
- 常用计量单位绑定
- 数据校验
- 测试
- 数据层解决方案
-
- SQL
- NoSQL
-
- 认识NoSQL
- Redis
-
- 安装
- 基本使用
- Springboot整合Redis
- Springboot读取Redis的客户端
- Springboot操作redis客户端实现技术切换(jedis)
- Mongodb
-
- 安装
- Elasticsearch(ES)
-
- 安装
- 基本操作
- Springboot整合ElasticSearch
- Springboot整合ES使用客户端对象操作ES
- 整合第三方技术
-
- 缓存
-
- 入门案例(缓存模拟)
- SpringCache
- 手机验证码缓存案例
-
- 生成验证码
- 验证码校验
- 变更缓存供应商
- SpringBoot整合Ehcache缓存
- SpringBoot整合Redis缓存
- SpringBoot整合Memcache缓存
- SpringBoot整合jetcache缓存
-
- jetcache纯远程缓存
- jetcache纯本地缓存
- jetcache本地+远程方案
- jetcache方法缓存
- 数据同步问题
- 数据报表
- SpringBoot整合j2cache缓存
- 任务
-
- 入门案例
- SpringBoot整合Quartz
- SpringBoot整合Task
- 邮件
-
- SpringBoot整合JavaMail
-
- 发送简单邮件
- 发送多组件邮件(附件、复杂正文)
- 消息队列
-
- 消息的概念
- 注:
前言
SpringBoot(B站黑马)学习笔记 02-2开发实用篇(热部署、配置、NoSQL、整合第三方技术)
02-2开发实用篇
实用篇学习目标:
-
运维实用篇
- 能够掌握SpringBoot程序多环境开发
- 能够基于Linux系统发布SpringBoot工程
- 能够解决线上灵活配置SpringBoot工程的需求
-
开发实用篇
- 能够基于SpringBoot整合任意第三方技术
热部署
什么是热部署,所谓热部署就是在应用正在运行的时候升级软件,却不需要重新启动应用。对与Java应用程序来说,热部署就是在运行时更新代码后不用重新启动服务器。修改完代码效果马上生效,不重新启动服务器。
环境准备
原先的SpringBoot整合ssm

我们现在的项目是没有热部署效果的。做热部署的整个思想是,当我们启动的服务器发现了程序变化了,这个时候它做一个重启。也就是服务器发现你的程序发生变化了他在做一个内部的重启。这时候问题来了,原来的服务器Tomcat是独立的,是通过配置的形式加载当前运行的项目。现在不一样了,服务器是SpringBoot内置的,现在的服务器是受SpringBoot管控,和我们自己的程序平级,那现在你的服务器还能感知到你的程序发生变化吗,你的服务器自身就是这里边的一部分了,所以它感觉不到。想让它感觉到怎么办,必须得在spring容器上做文章。简单来说,再搞一个程序X在spring容器中盯着你原始开发的程序A不就行了吗,如果你自己开发的程序A变化了,那么程序X就命令tomcat容器重新加载程序A就OK了。并且这样做有一个好处,spring容器中东西不用全部重新加载一遍,只需要重新加载你开发的程序那一部分就可以了。
而这个程序X springboot已经帮我们做好了,我们只需导入依赖进去就行。
手动启动热部署

启动热部署仅仅启动的是Restart过程而不包含ReLoad过程,项目启动包含了Restart和ReLoad两个过程。热部署仅仅加载当前开发者自定义开发的资源,不加载jar资源
导入依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-devtoolsartifactId>
dependency>
第一次测试热部署
(左)第一次请求打印一行,修改语句后(右)发现热部署没有运行,打印的还是一行。
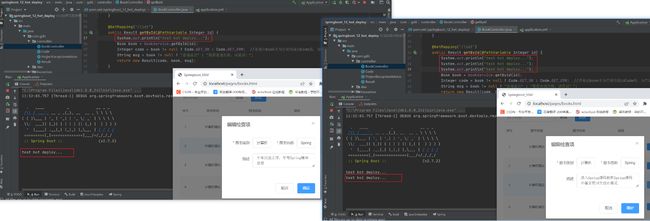
原因是热部署需要手动点击构建命令来激活

第二次测试

自动启动热部署
每次启动热部署都要点击激活,对我们来说跟启动没什么区别。怎么解决呢。通过idea的配置可以自动激活热部署。
第一步:设置自动构建项目
Files->settings 找到Compiler进行勾选

第二步:允许在程序运行时进行自动构建
使用快捷键 Ctrl + Alt + Shift + / 打开维护面板,选择第1项【Registry…】

在维护面板找到如下选项进行勾选即可

这样程序在运行的时候就可以进行自动构建了,实现了热部署的效果。
触发条件:idea失去焦点5秒回自动构建
如果每敲一个字母,服务器就重新构建一次,这未免有点太频繁了,所以idea设置当idea工具失去焦点5秒后进行热部署。就是从idea工具中切换到其他工具时进行热部署,比如改完程序需要到浏览器上去调试,这个时候idea就自动进行热部署操作。
热部署范围配置
通过修改项目中的文件,可以发现其实并不是所有的文件修改都会激活热部署的,原因在于在开发者工具中有一组配置,当满足了配置中的条件后,才会启动热部署,配置中默认不参与热部署的目录信息如下
- /META-INF/maven
- /META-INF/resources
- /static
- /public
- /templates
以上目录中的文件如果发生变化,是不参与热部署的。如果想修改配置,可以通过application.yml文件进行设定哪些文件不参与热部署操作
spring:
devtools:
restart:
# 设置不参与热部署的文件或文件夹
exclude: static/**,public/**,config/application.yml
关闭热部署
线上环境运行时是不可能使用热部署功能的,所以需要强制关闭此功能,通过配置可以关闭此功能。
spring:
devtools:
restart:
enabled: false
还存在一种情况,我们设置关闭了,别人在另一个地方又开启了。我们就需要往更高层级中配置关闭热部署
@SpringBootApplication
public class Application {
public static void main(String[] args) {
//关闭热部署
System.setProperty("spring.devtools.restart.enabled","false");
SpringApplication.run(Application.class, args);
}
}
前面提到过的属性加载优先级。开始是在第三级:配置数据(application.properties文件),我们往更高层级的是第六级 系统属性。还不行就再往高级走
参考网址:https://docs.spring.io/spring-boot/docs/current/reference/html/features.html#features.external-config

配置高级
环境准备 只导了个lombok依赖,其它都没有


@ConfigurationProperties(第三方bean属性绑定)
前面我们在yml数据读取方式的第三种中介绍使用了@ConfigurationProperties注解,通过实体类读取。
注意:是通过核心容器获取bean,不是自动注入,IOC
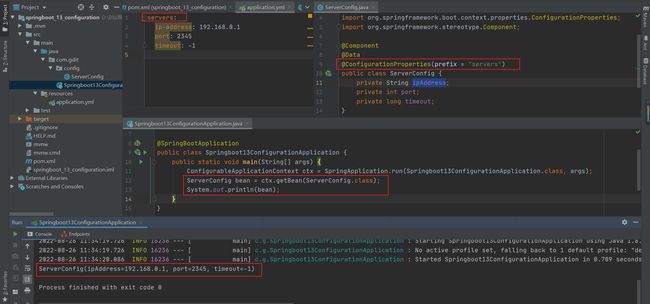
这样我们就可以通过自定义实体类获取配置文件中的属性,但存在一个问题,如果第三方bean要使用配置文件中的属性呢,而第三方开发的bean源代码不是你自己书写的,你也不可能到源代码中去添加@ConfigurationProperties注解,这种问题该怎么解决呢
使用@ConfigurationProperties注解其实可以为第三方bean加载属性,格式特殊一点而已。


以配置druid为例
(注意:druid已经和springboot有整合了,这里配置只是为了演示没有和springboot整合的也按这个思路配)
导入依赖
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druidartifactId>
<version>1.2.6version>
dependency>
使用@ConfigurationProperties注解为第三方bean进行属性绑定,注意前缀是全小写的datasource
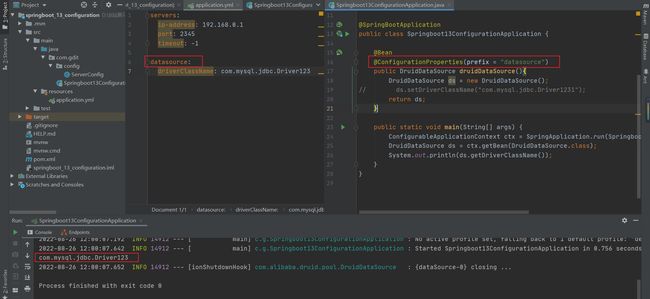
注意:演示DruidDataSource把它当成一个对象,目的不是连接数据库,是为了知道@ConfigurationProperties不仅能在自定义实体类使用,也可以在方法上使用。添加到类上是为spring容器管理的当前类的对象绑定属性,添加到方法上是为spring容器管理的当前方法的返回值对象绑定属性,其实本质上都一样。
这里就出现了一个新问题,目前我们定义bean的方式有通过@Component类注解定义,又有@Bean定义。而@ConfigurationProperties不仅可以写在类上,又可以写在方法上,那找起来就很麻烦了。为了解决这个问题,spring给我们提供了一个全新的注解,专门标注使用@ConfigurationProperties注解绑定属性的bean是哪些。这个注解叫做@EnableConfigurationProperties。(有点类似于Spring管理配置类的@Import注解)

在配置启动类上开启@EnableConfigurationProperties注解,并标注要使用@ConfigurationProperties注解绑定属性的类

加上后启动我们会发现,它报错了,bean不唯一。原因是我们把ServerConfig使用@Component注解把其声明成bean了,而当使用@EnableConfigurationProperties注解时,spring会默认将其标注的类定义为bean。这就定义两次了,因此无需再次声明@Component注解了。
去除@Component注解即可

总结
- 使用@ConfigurationProperties可以为使用@Bean声明的第三方bean绑定属性
- 当使用@EnableConfigurationProperties声明进行属性绑定的bean后,无需使用@Component注解再次进行bean声明
松散绑定
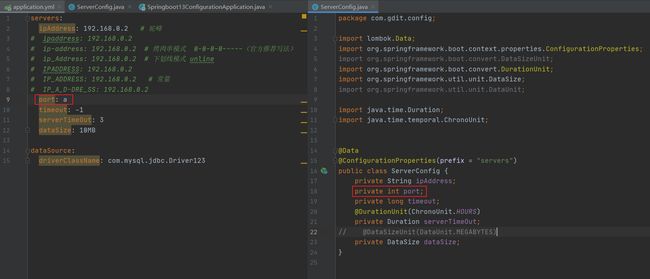
我们在书写时倡导规范书写,使用驼峰法,所以我们将配置文件中的datasource改成dataSource,当我们运行项目时没改注解内的参数会发现能够成功运行。但我们把注解内的参数改成跟配置文件相同则会爆错


上方发现我们把属性换成相同的大写绑定不上,小写却能绑定。这就是宽松绑定/松散绑定
对于我们使用@ConfigurationProperties注解时,它使用绑定属性对于名称的要求是非常灵活的,能够充分兼容各种编程爱好者的书写习惯,它设定了若干种匹配格式。

例如我们在ServerConfig内读取配置文件属性时会发现它能够读各种写法


松散绑定只支持@ConfigurationProperties注解,@Value注解并不支持,如:
名称相同能够成功读取

但名称不同时就会出错,所以松散绑定并不支持@Value注解
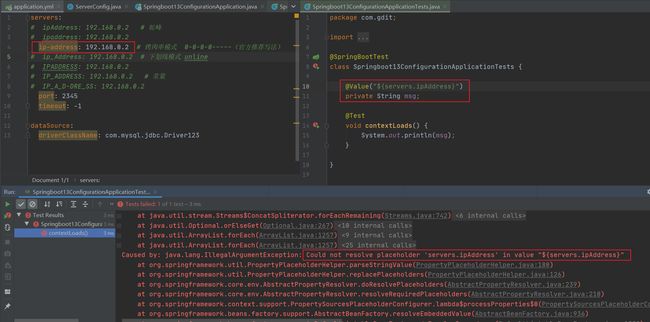
回到最开始的问题,在@ConfigurationProperties注解内属性换成相同的大写绑定不上,小写却能绑定

它报错的原因是说规范名称应为烤肉串形式(“-”分隔)、小写字母数字字符,并且必须以字母开头
@ConfigurationProperties注解绑定属性支持属性名宽松绑定,但是 绑定前缀名命名规范:仅能使用纯小写字母、数字、下划线作为合法的字符

常用计量单位绑定
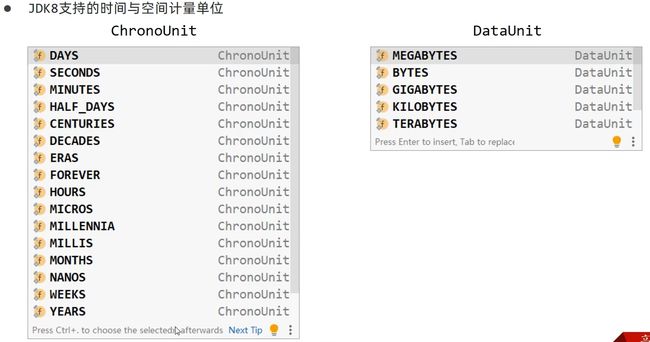
当我们在配置文件中设置属性超时时间 300000000 很明显存在阅读困难的问题,而且单位是什么也不清楚。所以JDK8以后提供了专门的数据类型,专门处理此类问题。

JDK8推出的与单位有关的各种数据类型 如:

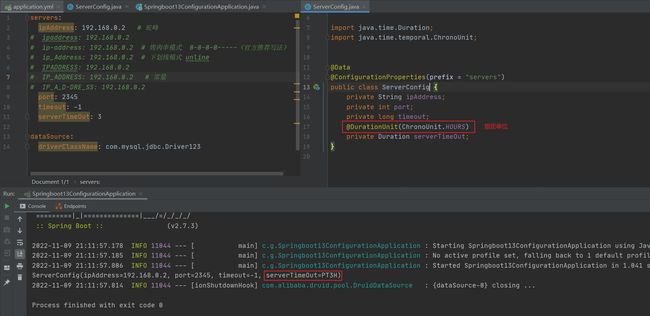
Duration 默认单位秒 PT是标准单位进制,可以指定单位种类


DataSize配置存储容量 默认单位为B(字节)可以指定单位种类,它会帮我们乘出来。


10MB=(10×1024)KB=(10×1024×1024)B
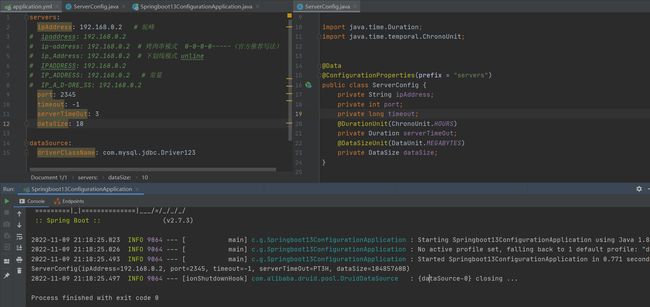
这样难免会难以阅读,可以去掉指定类型后直接写MB 如:
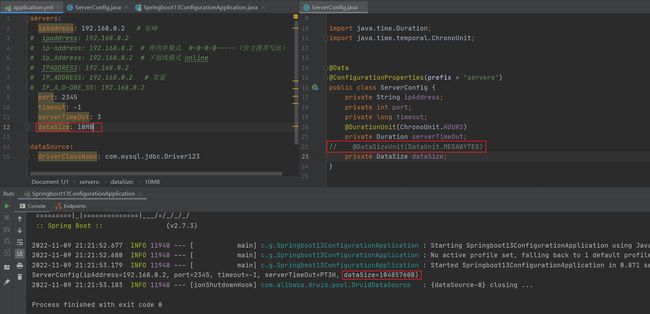
数据校验
如果在配置文件写的是字符,bean中接收的却是整型,那运行不就报错了,这时我们就需要有东西帮助我们进行数据校验
- 开启数据校验有助于系统安全性,J2EE规范中JSR303规范定义了一组有关数据校验相关的API



- 导入Validation数据校验框架

注:不建议带版本号,Springboot帮我们匹配好了最佳兼容的V(版本),避免了依赖冲突

- 开启对当前bean的属性注入校验
- 设置具体的规则

测试运行发现报错,Validation的接口没有找到实现类,提示添加类似Hibernate的校验器

原因是Validation数据校验框架类似于JDBC是一套标准规范(接口),对应MySQL驱动是一套基于MySQL数据库的实现类。所以Validation是一套规范(接口),具体实现类是Hibernate
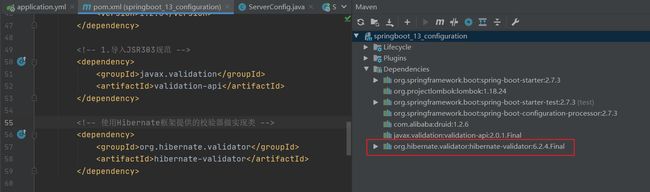
添加Hibernate校验引擎的依赖
再次运行,成功进行校验,发现超过8888出现提示

测试
数据层解决方案
SQL
NoSQL
认识NoSQL

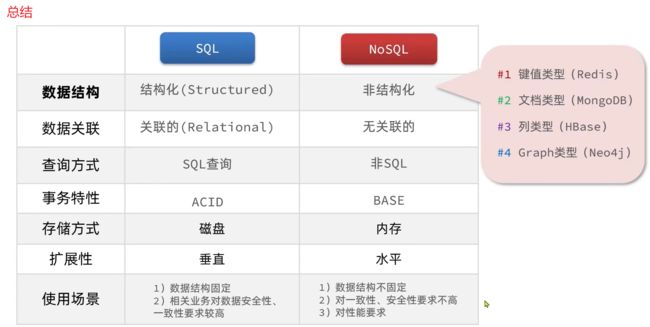
传统关系型数据库是结构化数据,每一张表都有严格的约束信息:字段名.字段数据类型.字段约束等等信息,插入的数据必须遵守这些约束;
而NoSql则对数据库格式没有严格约束,往往形式松散,自由。可以是键值型(Key-Value),也可以是文档型(Document json形式的),甚至可以是图格式(Graph 不常用)

传统数据库的表与表之间往往存在关联,例如外键;而非关系型数据库不存在关联关系,要维护关系要么靠代码中的业务逻辑,要么靠数据之间的耦合;

传统关系型数据库会基于Sql语句做查询,语法有统一标准,只要是关系型数据库都可以用Sql语句查询,不管是MySQL还是Oracle都可以;
而不同的非关系数据库查询语法差异极大,五花八门各种各样;

传统关系型数据库能满足事务ACID的原则;而非关系型数据库往往不支持事务,或者不能严格保证ACID的特性,只能实现基本的一致性;

-
市面上常见NoSQL解决方案
- Redis
- Mongo
- ES
说明:因为每个小伙伴学习这门课程的时候起点不同,为了便于各位学习者更好的学习,每种技术在讲解整合前都会先讲一下安装和基本使用,然后再讲整合。此外上述这些技术最佳使用方案都是在Linux服务器上部署,但是考虑到各位小伙伴的学习起点差异过大,所以下面的课程都是以Windows平台作为安装基础讲解,如果想看Linux版软件安装,可以再找到对应技术的学习文档查阅学习。(这里只学了基本使用和整合,详细学习看专门的教程视频)
Redis
-
Redis是一款key-value存储结构的内存级NoSQL数据库
- 支持多种数据存储格式
- 支持持久化
- 支持集群
安装
windows版安装包下载地址:https://github.com/tporadowski/redis/releases(官网只有Linux版本的,其它版本都是大佬写的)
下载的安装包有两种形式,一种是一键安装的msi文件,还有一种是解压缩就能使用的zip文件,哪种形式都行,这里就不介绍安装过程了,本课程采用的是msi一键安装的msi文件进行安装的。

下载完成后直接双击运行进行安装(啥都没勾,只改了安装路径)

安装完成

服务端启动命令
- redis-server.exe redis.windows.conf
客户端启动命令
- redis-cli.exe
在文件路径输入cmd进入命令行窗口

输入redis-server.exe启动发现报错,原因是没有给配置文件。把配置文件加上,发现还是报错,这是windows版的小bug,我们再打开一个当前路径的cmd窗口,输入redis-cli启动客户端,输入shutdown命令然后再输入exit退出。重新输入redis-server.exe redis.windows.conf就能启动了
如果redis-server.exe redis.windows.conf不能正常启动就先redis-cli启动客户端输入shutdown后退出再启动就行。

基本使用
启动服务器后在客户端进行操作
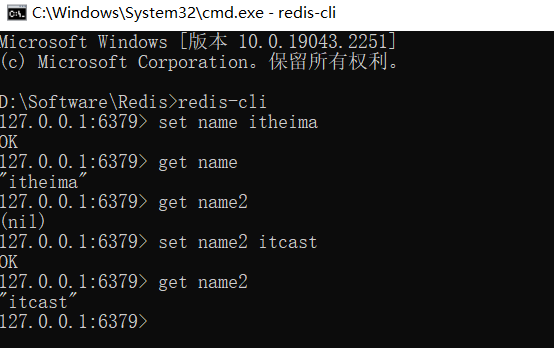
放置一个字符串数据到redis中,先为数据定义一个名称,比如name,age等,然后使用命令set设置数据到redis服务器中即可 如:
- set name itheima
- set age 12
从redis中取出已经放入的数据,根据名称取,就可以得到对应数据。如果没有对应数据就会得到(nil) 如:
- get name
- get age

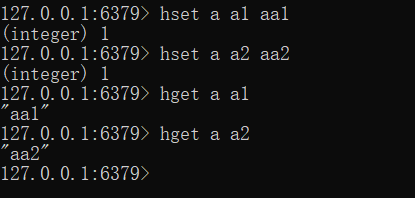
以上使用的数据存储是一个名称对应一个值,如果要维护的数据过多,可以使用别的数据存储结构。例如hash,它是一种一个名称下可以存储多个数据的存储模型,并且每个数据也可以有自己的二级存储名称。向hash结构中存储数据格式如下:
- hset a a1 aa1
- hset a a2 aa2
- (表示在key为a下存储了两个key-value数据 一个key:a1 value:aa1 一个key:a2 value:aa2)
获取hash结构中的数据命令如下
- hget a a1 #得到aa1
- hget a a2 #得到aa2
清除所有数据
- flushdb
(其余详细操作看Redis详细篇视频)
Springboot整合Redis



环境准备
启动redis服务器

1.勾选springboot整合redis的依赖

<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
2.编写配置文件进行基础配置

操作redis,最基本的信息就是操作哪一台redis服务器,所以服务器地址属于基础配置信息,不可缺少。但是即便你不配置,目前也是可以用的。因为以上两组信息都有默认配置,刚好就是上述配置值。
3.编写测试类
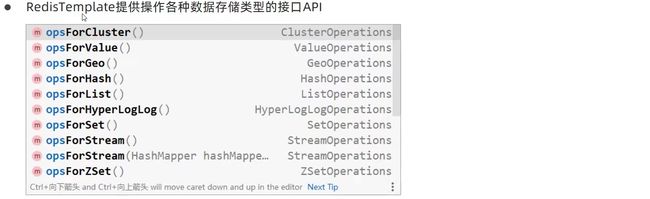
在操作redis时,需要先确认操作何种数据(例如我们前面介绍的set、hset等),根据数据种类得到操作接口。例如使用opsForValue()获取string类型的数据操作接口,使用opsForHash()获取hash类型的数据操作接口,剩下的就是调用对应api操作了。各种类型的数据操作接口如下:
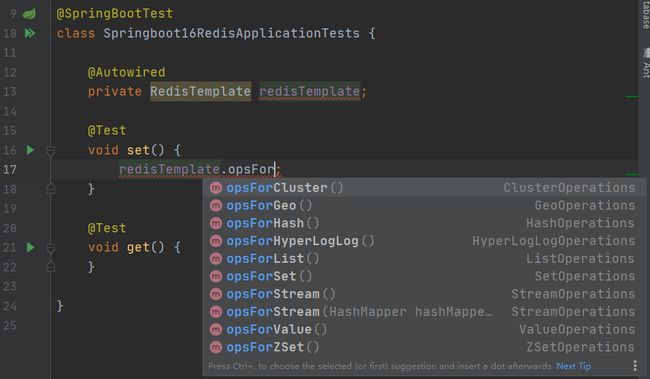

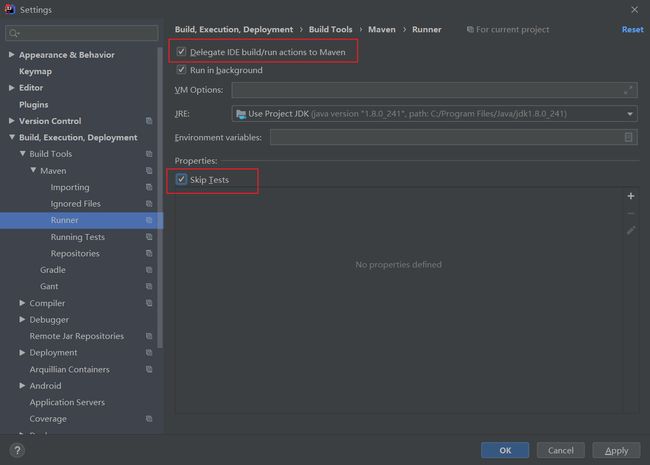
温馨提示:如果运行提示找不到符号,这时2020版idea的bug,勾选下面的选项就行

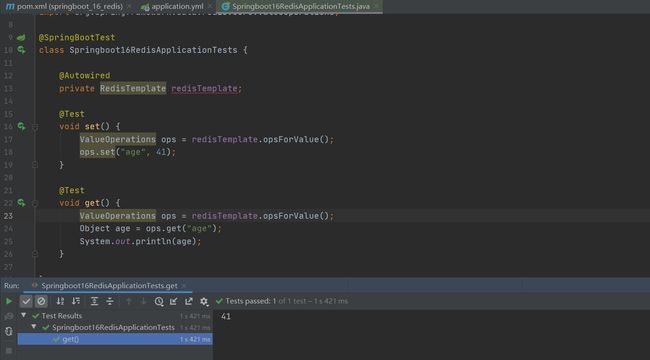
Springboot读取Redis的客户端


我们在上方redis基本使用中set了一些数据,尝试在idea中读取这些数据会发现读出来是null,然后我们在redis客户端读取idea中set的数据发现也是空的。如
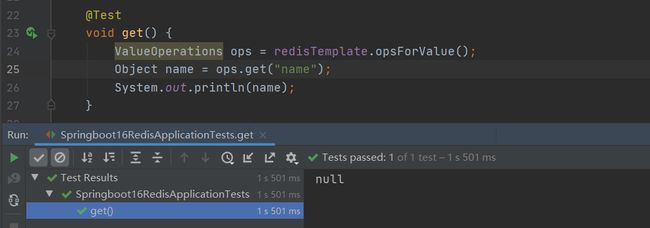

为什么?难道idea和redis客户端用的不是同一个库吗,我们把redis服务器关掉后测试idae发现报错,不能连接redis。那证明是使用同一个。

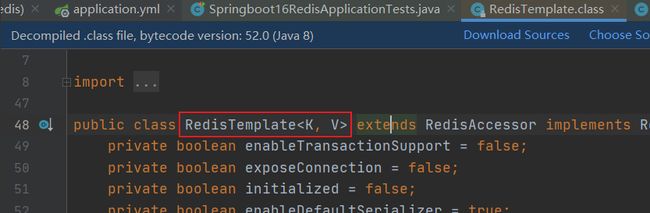
原因在于RedisTemplate对象,源码中它是使用泛型的形式,我们没有指定泛型它就默认是Object类型,是以对象为操作的基本单元,而redis客户端里是以字符串操作为基本单元,因此当操作的数据以对象的形式存在时,会进行转码,转换成字符串格式后进行操作。

我们在redis客户端查找所有的key:keys *; 其中一长串的就是转码后的形式

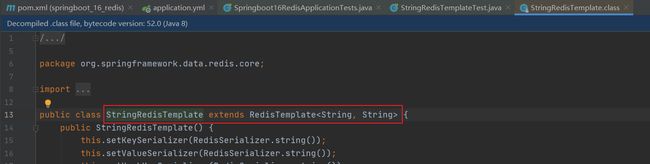
springboot整合redis时提供了专用的API接口StringRedisTemplate,可以理解为这是RedisTemplate的一种指定数据泛型的操作API。
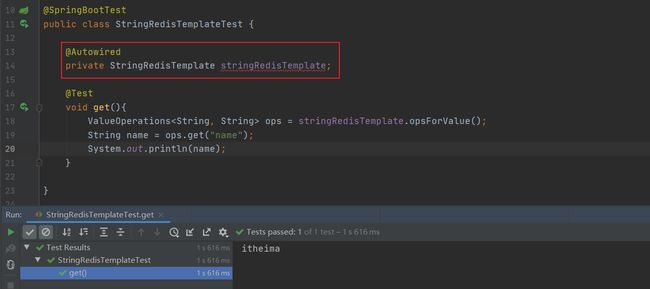
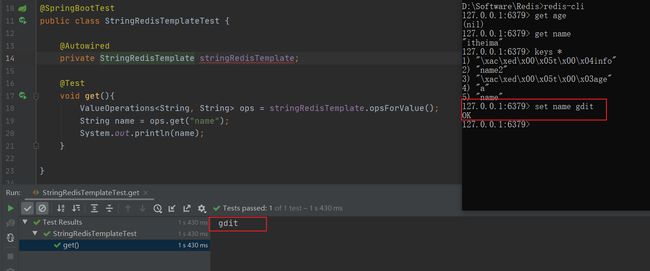
redis客户端修改一下name的值在idea获取,证实确实是同一个
其实StringRedisTemplate就是指定了泛型的RedisTemplate,看源码就知道了
Springboot操作redis客户端实现技术切换(jedis)
我们在操作redis的时候,传统的操作客户端技术有一个叫jedis技术。springboot整合默认提供的是lettucs客户端技术,我们也可以根据需要切换成指定客户端技术,例如jedis客户端技术,切换成jedis客户端技术操作步骤如下:
1.导入依赖
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
dependency>

2.在配置文件指定客户端

3.根据需要设置对应的配置

lettcus与jedis区别(了解)
- jedis连接Redis服务器是直连模式,当多线程模式下使用jedis会存在线程安全问题,解决方案可以通过配置连接池使每个连接专用,这样整体性能就大受影响
- lettcus基于Netty框架进行与Redis服务器连接,底层设计中采用StatefulRedisConnection。 StatefulRedisConnection自身是线程安全的,可以保障并发访问安全问题,所以一个连接可以被多线程复用。当然lettcus也支持多连接实例一起工作
Mongodb
- MongoDB是一个开源、高性能、无模式的文档型数据库,它是NoSQL数据库产品中的一种,是最像关系型数据库的非关系型数据库。
安装
windows版安装包下载地址:https://www.mongodb.com/try/download
官网有企业版和社区版,我们选择下载社区版的zip压缩包就行
直接解压到指定文件夹

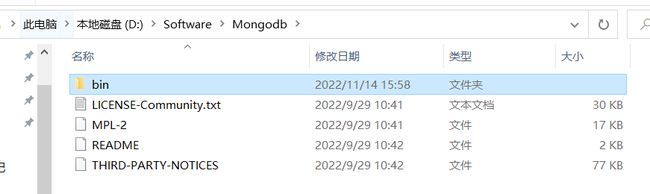
Mongodb它还是一款数据库,他有数据存储的位置。我们要指定它数据存储的位置,在Mongodb目录下新建data文件夹,Mongodb运行起来会有很多的数据文件,所以在里面再建一个db文件夹存数据,其它还有很多配置文件。

服务器启动命令
- mongod --dbpath=…\data\db
- (启动服务器时需要指定数据存储位置,通过参数–dbpath进行设置,可以根据需要自行设置数据存储路径。)
客户端启动命令
- mongo --host=127.0.0.1 --port=27017
- (默认服务端口27017)
在bin文件路径输入cmd进入命令行窗口
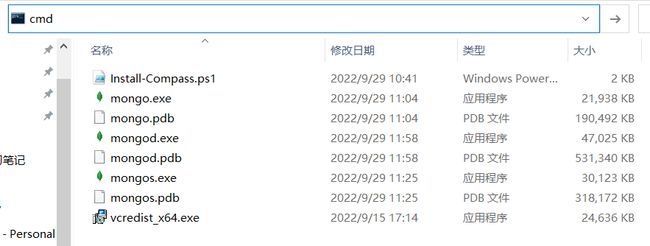
输入启动服务器指令会在db文件夹下生成很多文件,这些文件都是初次构建一次性的,后面就不会在生成了



再在bin路径新建一个cmd输入客户端启动命令(直接输mongo就行,它会采用默认配置)

(剩下的基本使用跟springboot整合先跳过,需要再回来补)
Elasticsearch(ES)
- Elasticsearch是一个分布式全文搜索引擎
那什么是全文搜索呢?比如用户要买一本书,以Spring为关键字进行搜索,不管是书名中还是书的介绍中,甚至是书的作者名字,只要包含Spring就作为查询结果返回给用户查看,上述过程就使用了全文搜索技术。搜索的条件不再是仅用于对某一个字段进行比对,而是在一条数据中使用搜索条件去比对更多的字段,只要能匹配上就列入查询结果,这就是全文搜索的目的。而ES技术就是一种可以实现上述效果的技术。

要实现全文搜索的效果,不可能使用数据库中like操作去进行比对,这种效率太低了。ES设计了一种全新的思想,来实现全文搜索。具体操作过程如下:
1.根据提供的数据进行分 词
- 例如“Spring实战第5版”就会被拆分成三个词,分别是“Spring”、“实战”、“第5版”
2.分词后它会将关联数据保存起来,对应每条数据的id,先匹配到id然后由id再得到数据,这样在它的系统中就会有一个一个关键字对应一个一个的简要数据的一组数据格式

在传统的数据库中有一个加速查询的设定叫索引,创建了表设定有主键,主键就是索引。这样根据主键查的时候速度就快。而我们现在全文搜索的操作也是为了加速查询,也叫索引,但是和传统的索引不同,传统的索引是根据id查数据,而全文搜索刚好反过来,是根据关键字数据查id,然后再由id查数据。它有一个全新的名字叫“倒排索引”
我们要想全文搜索技术,就要提前建立它们的数据联系(创建文档)
如:Spring——>1,2,3,4,5——>1.x,xx,xx Spring对1,1对后面一堆是一个文档,Spring对2,2对后面一堆是一个文档
每一条对应的数据就可以称作是一个文档。我们通过创建无数的文档将它们存起来,后面再使用就方便
然后就是使用文档
安装
windows版安装包下载地址:https://www.elastic.co/cn/downloads/elasticsearch
下载后直接解压到指定文件夹即可(建议和视频版本一致,不然容易报错)

双击elasticsearch.bat即可启动ES(第一次启动时间会有点长)

浏览器输入http://localhost:9200/出现一串json数据就算成功启动了


基本操作
索引操作

![]()

在操作ES时把它当成一个数据库服务器,那么在操作数据库服务器的第一步就是先创建一个数据库,然后才是操作表、记录等。而ES和数据库很像,但它没有数据库的概念,它有索引的概念。我们可以把操作索引当作操作MySQL里的数据库,所以ES中得先有索引才能往后操作。
要操作ES可以通过发Rest风格的Web请求来进行,也就是说发送一个请求就可以执行一个操作。比如新建索引,删除索引这些操作都可以使用发送请求的形式来进行。
输入地址:http://localhost:9200/books books就是索引名称(相当于名称叫books的数据库)
-
创建索引
- http://localhost:9200/books PUT请求(注意索引名称不能重复,重复put就会报错)

-
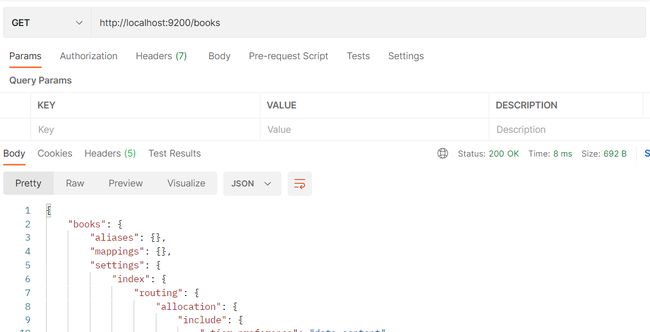
查询索引
- http://localhost:9200/books GET请求

-
删除索引
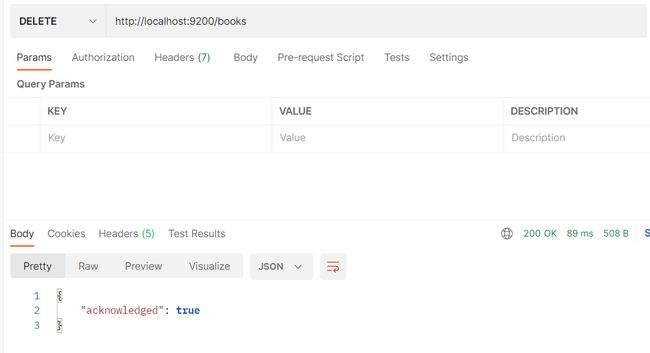
- http://localhost:9200/books DELETE请求
我们现在创建的索引是不具有分词效果的,原因是我们没有给这个索引指定分词器。在查询索引里有个mappings设置,这可以设定索引的详细信息,但目前是空白。可以在创建索引时添加请求参数,设置分词器。

提供分词功能是使用分词器来实现的,官方也有提供对应的分词器,目前流行的是IK分词器。下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
IK分词器就是个插件,下载后解压到ES安装目录的plugins目录中即可,安装分词器后需要重新启动ES服务器。

使用IK分词器创建索引格式:
- 通过json数据的格式设置,最终会设置到mappings上


再GET查询mappings就有东西了,我们现在创建的books索引就带上了分词的设定,数据再进来的时候就会按这个设定进行操作

注意:这些只是蜻蜓点水普及ES,很多操作要看专门的课程教程,这里只讲后面要用的基础操作
文档操作
目前我们已经有了索引了,但是索引中还没有数据,所以要先添加数据,ES中称数据为文档,下面进行文档操作。


-
添加文档,有三种方式
- POST请求 http://localhost:9200/books/_doc #使用系统生成id

- POST请求 http://localhost:9200/books/_create/1 #使用指定id

- POST请求 http://localhost:9200/books/_doc/1 #使用指定id,不存在就创建,存在更新(版本递增)

-
查询文档
- GET请求 http://localhost:9200/books/_doc/1 #查询单个文档
- GET请求 http://localhost:9200/books/_search #查询全部文档
-
条件查询
- GET请求 http://localhost:9200/books/_search?q=name:springboot # q=查询属性名:查询属性值
-
删除文档
-
- DELETE请求 http://localhost:9200/books/_doc/1
-
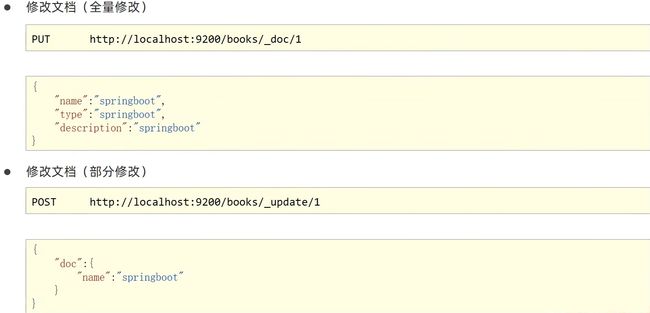
修改文档(全量更新—会全覆盖)
- PUT请求 http://localhost:9200/books/_doc/1


-
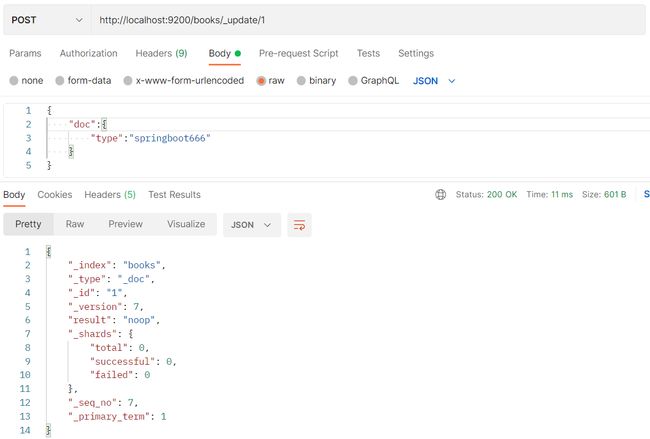
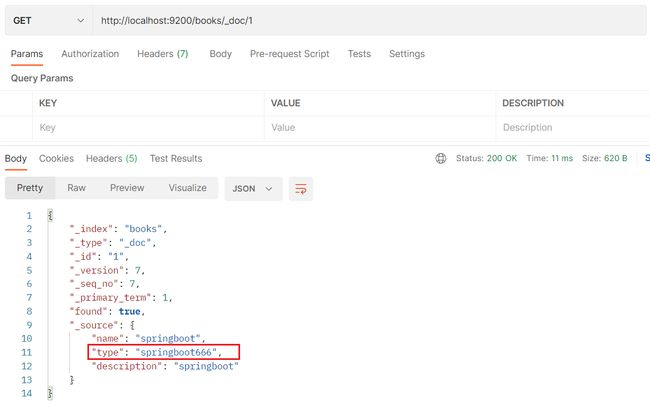
修改文档(部分更新,给什么更新什么,其它不动)
- POST请求 http://localhost:9200/books/_update/1
Springboot整合ElasticSearch
(注意:此黑马视频是2021-10-26上传的,截至2022-11-17整合ES又有不同的方式。参考:https://www.kongzid.com/archives/els21)
环境准备
启动ES服务器

新建项目依赖

Low Level Client整合(低级别客户端整合)
1.导入整合ES依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-elasticsearchartifactId>
dependency>
2.编写配置文件进行基础配置
指定服务器 (目前uris写法过时了)

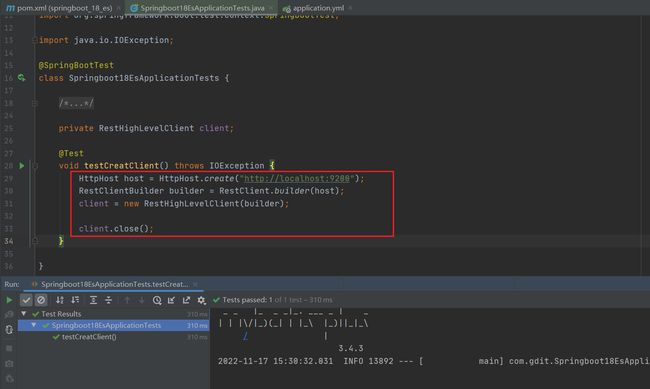
3.编写测试类
自动注入客户端(不推荐使用,这是ES老版本的)

上述操作形式是ES早期的操作方式,使用的客户端被称为Low Level Client(低级别客户端),这种客户端操作方式性能方面略显不足,于是ES开发了全新的客户端操作方式,称为High Level Client(高级别客户端)。高级别客户端与ES版本同步更新,但是springboot最初整合ES的时候使用的是低级别客户端,所以企业开发需要更换成高级别的客户端模式。
High Level Client整合(高级别客户端整合)
1.导入整合ES依赖
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-high-level-clientartifactId>
dependency>
2.编写配置文件进行基础配置
springboot整合ES高级别客户端还没来得及整合,所以不能在yml文件中配置,必须手工硬编码告知服务器(看下面红字,有惊喜)
温馨提示:如果运行提示找不到符号,这是2020版idea的bug,勾选下面的选项就行

此黑马视频是2021-10-26上传的,截至2022-11-17已经实现了springboot整合ES高级别客户端,并且可以使用自动注入的方式,不用手工硬编码了
编写配置文件进行基础配置

Springboot整合ES使用客户端对象操作ES
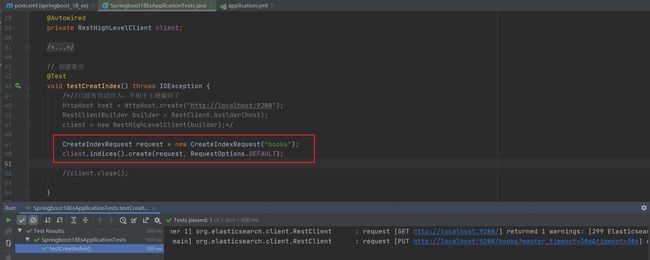
3.使用客户端对象操作ES
创建索引:
创建索引(IK分词器):
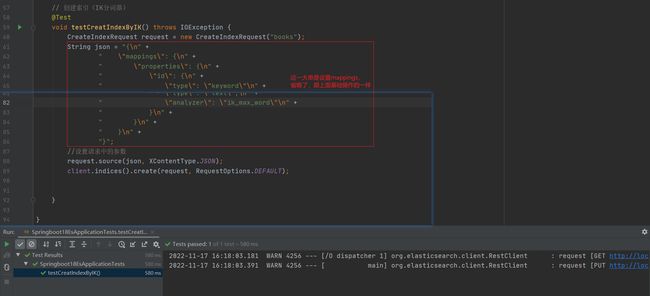

添加文档(就是添加数据)
- 添加单文档


注意:因为是从数据库查出的对象转成JSON,记得添加fastjson依赖
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.62version>
dependency>
- 添加全文档

批量做时,先创建一个BulkRequest的对象,可以将该对象理解为是一个保存request对象的容器,将所有的请求都初始化好后,添加到BulkRequest对象中,再使用BulkRequest对象的bulk方法,一次性执行完毕。
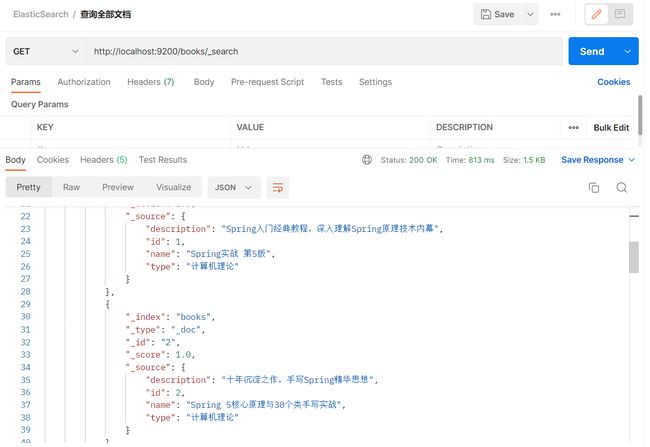
查询文档
- 按id查询


- 按条件查询

按条件查询文档使用的请求对象是SearchRequest,查询时调用SearchRequest对象的termQuery方法,需要给出查询属性名,此处支持使用合并字段,也就是前面定义索引属性时添加的all属性。最后获取命中多少条数据,将其遍历后转成对象打印出来
整合第三方技术
缓存
现在我们使用的程序,不管是手机APP还是网页浏览,其实都是通过程序到数据库去拿数据,最后进行展示,这是我们程序的最主要工作。那这就会产生一个问题,长期对数据库进行数据访问,这样对数据库的压力就会越来越大,进而造成数据库成为整个系统的操作瓶颈。简单来说就是数据库扛不住了。

这时我们进行分析,这么大的操作量难道每次都不一样吗?其实有些时候它是进行反复相同内容的操作,比如双11、618在访问某些产品的时候,还有其它的用户在访问这一组数据。这时候就有人提出来,能不能找一块空间,程序访问的时候先去访问它,然后它去数据库读数据,读完之后再给到程序。这样一旦这个空间内有我们经常访问的数据,就不用再走这个过程了,只需要程序与这个空间进行反复的数据交互,这样就能有效降低数据库的压力了。而这个空间称之为缓存(Cache)
- 缓存是一种介于数据永久存储介质与应用程序之间的数据临时存储介质
- 使用缓存可以有效的减少低俗数据读取过程的次数(例如磁盘IO),提高系统性能
- 缓存不仅可以用于提高永久性存储介质的数据读取效率,还可以提供临时的数据存储空间。

入门案例(缓存模拟)
环境准备
<dependencies>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-boot-starterartifactId>
<version>3.4.3version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druid-spring-boot-starterartifactId>
<version>1.2.6version>
dependency>
<dependency>
<groupId>com.mysqlgroupId>
<artifactId>mysql-connector-jartifactId>
<scope>runtimescope>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
dependencies>

测试(现在每查询一次就会去数据库进行数据交互)

模拟缓存
使用Map集合当作缓存容器
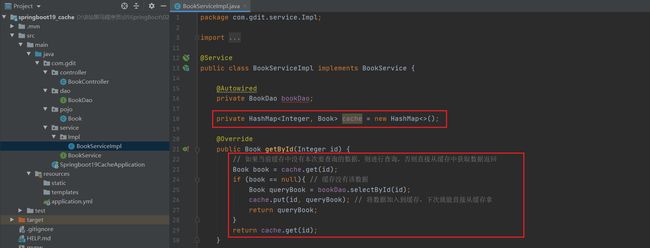
测试
第一次查询Map集合中没有数据,就去数据库查然后返回给前端,并将此条数据加入Map中。第二次查这条数据就直接从Map中拿。(注意观察sql语句出现的次数,第一次会显示,第二次不显示。因为第二次是从Map拿不是数据库拿)


我们现在的数据来源是数据库,有些情况并不是从数据库来的,是从外面进来的。缓存不仅能够存储数据库读出来的数据,还能存储一些临时数据,是整个系统运行过程中产生的。这些数据不存进数据库但要进行存储,比如手机验证码登录,验证码并不存到数据库,它是后台系统临时生成的然后发短信给用户,用户根据短信的验证码跟后台匹配进行登录,这个过程并没有数据库参与,是临时数据。下面对此进行模拟

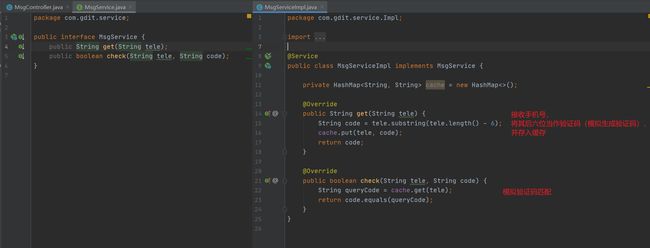

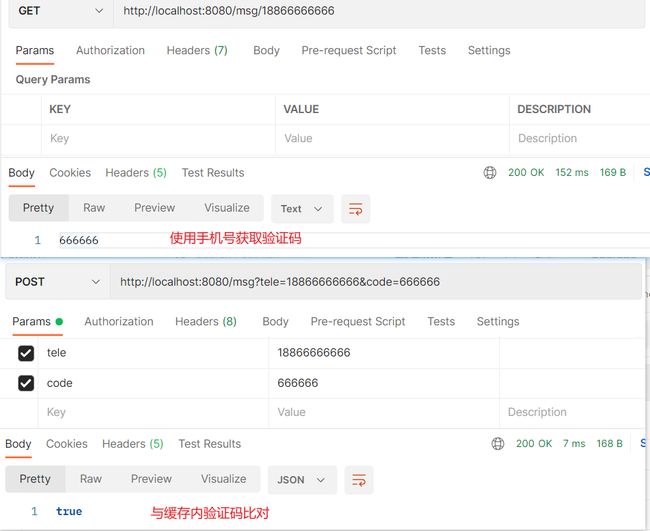
注意:上述两个案例还存在很多漏洞,例如数据一直都存在map中,数据不断加,内存总有一天会爆,因为这里只是快速模拟缓存,真正缓存并不是这样处理。
SpringCache
- SpringBoot提供了缓存技术,方便缓存使用
缓存使用
- 启用缓存
- 设置进入缓存的数据
- 设置读取缓存的数据



1.引入springboot缓存的依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-cacheartifactId>
dependency>
2.启用缓存
在springboot启动类上加上@EnableCaching注解开启缓存功能

3.使用缓存
@Cacheable(value = “cacheSpace”, key = “#id”)
查询完后就会把数据放到key叫id的空间内,而存储空间是value叫cacheSpace。value配置缓存的位置,可以理解是变量名,但它不是完整的变量名,最终存储的变量以key的名称为准。简单来说value=“cacheSpace"是大空间,key=”#id"是小的名称。value名称可以随便起,key名称要保障唯一性,key默认值是使用方法参数值。
注意:缓存的内容是返回值,如果方法没有返回值是无法缓存的
当第一次操作这个方法的时候,发现id在cacheSpace空间内没有值,它就会把返回值加入这个空间里。第二次操作,它会到cacheSpace空间检查是否有叫id的值,没有值还是加入空间,有的话就在空间内取出对应的值返回,就不走查询数据库了。

测试


@Cacheable注解
@Cacheable注解是由Spring提供的,可以作用与类或方法上(通常在数据查询方法上),用于对方法的查询结果进行缓存存储。@Cacheable 执行顺序:先进行缓存查询,如果为空则进行方法查询,并将返回值进行缓存;如果缓存中有数据,不进行方法查询,而是直接使用缓存数据进行返回。
注意:缓存的内容是返回值,如果方法没有返回值是无法缓存的


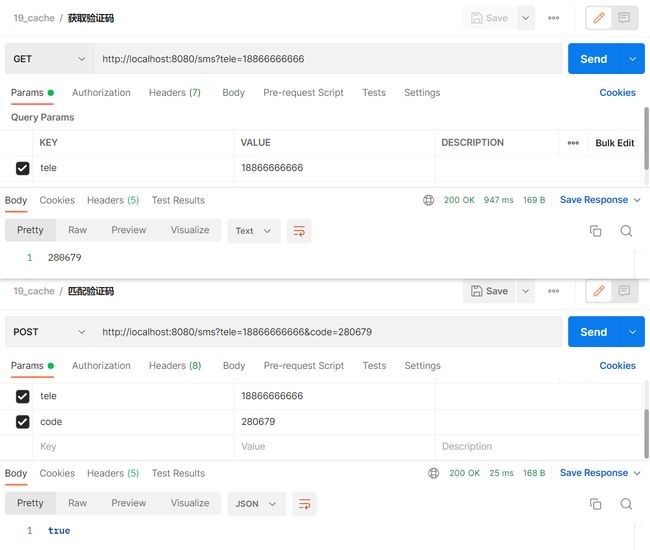
手机验证码缓存案例

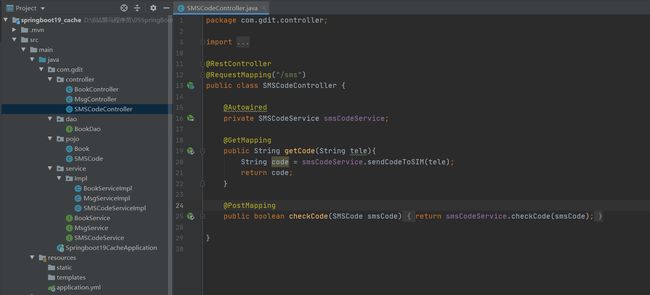
环境准备
还是用上面那个工程,添加了以下类

生成验证码
1.制作工具类生成6位验证码

2.使用缓存(记得导入缓存坐标和启动缓存)

测试
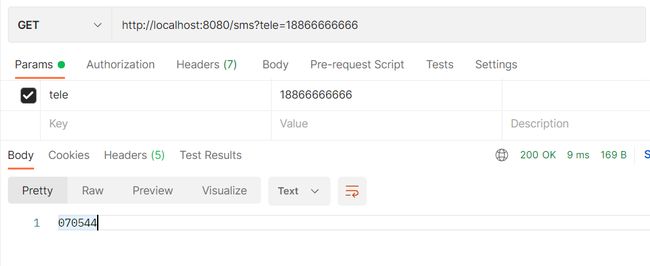
这么做存在一个问题,验证码一般3分钟或5分钟就会失效,但我们目前写的方法第一次获取验证码存入缓存后就一直是这个,下一次根据key= "#tele"查询到还是同一个。所以@Cacheable注解在这并不适用。我们需要的是仅仅是把我们的运行操作放到缓存中,但不要从缓存中读。@Cacheable注解不仅代表往里放 还有往外取的功能,(第二次操作,它会到空间检查是否有叫tele的值,有的话就在空间内取出对应的值返回)。可以使用@CachePut注解,它只有往里放的功能,其参数和@Cacheable注解一样。

@CachePut
@CachePut注解是由Spring提供的,可以作用与类或方法上(通常用在数据更新方法上),该注解的作用是更新缓存数据。@CachePut执行顺序:先进性方法调用,然后将返回值进行缓存。
@CachePut注解也提供了多个属性,这些属性与@Cacheable注解的属性完全一样
注意:缓存的内容是返回值,如果方法没有返回值是无法缓存的
补充:
@CacheEvict
@CacheEvict 注解是由 Spring 提供的,可以作用于类或方法(通常用在数据删除方法上 ),该注解的作用是删除缓存数据。@CacheEvict 注解的默认执行顺序是,先进行方法调用,然后清除缓存。
@CacheEvict注解提供了多个属性,这些属性与@Cacheable 注解的属性基本相同。除此之外,@CacheEvic 注解额外提供了两个特殊属性 allEntries 和 beforelnvocation,其说明如下。
(1)allEntries 属性
allEntries 属性表示是否清除指定缓存空间中的所有缓存数据,默认值为 false(即默认只删除指定 key 对应的缓存数据。例如@CacheEvict(cacheNames =“comment” ,allEntries = true表示方法执行后会删除缓存空间 comment 中所有的数据。
(2)beforelnvocation 属性
beforelnvocation 属性表示是否在方法执行之前进行缓存清除,默认值为 false( 即默认在执行方法后再进行缓存清除)。例如@CacheEvictcacheNames =“comment”,beforelnvocation = true)表示会在方法执行之前进行缓存清除。
测试
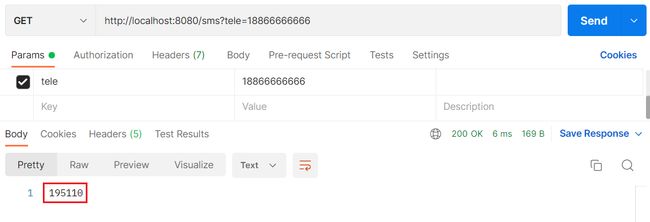

验证码校验
验证码校验关键是怎么从缓存中取出验证码数据,我们可以创建一个方法使用@Cacheable注解,让该方法获取缓存的验证码数据,@Cacheable注解如果有就返回缓存数据,没有就返回null

测试

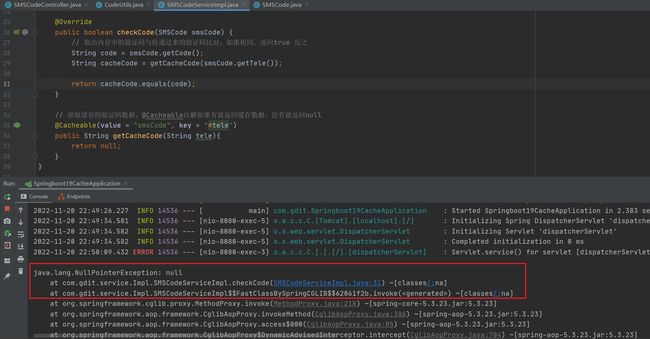
测试直接报错空指针,equals()方法括号内是null顶多返回false,前面是null必定会报空指针错误。
为什么会一直返回null,关键是我们的@Cacheable注解运行没有?同一个类中调用,没有使用ioc容器中的对象调用方法,注解没有被扫描。使用ioc容器的方法,注解才会被扫描。经过spring管理的应该是autowire注入才是创建的spring管理的类,在方法内部调用并没有用容器new一个对象,纯粹只是方法内部调用,并没有经过@Cacheable注解,所以它就一直返回null。例如上面的@CachePut注解之所以能生效是因为controller里autowire注入SMSCodeService,然后通过它去调用这个方法注解才生效。
解决办法:将获取缓存验证码数据方法放到CodeUtils工具类里,它已经被定义成bean,所以通过CodeUtils这个bean调用就会经过@Cacheable注解。
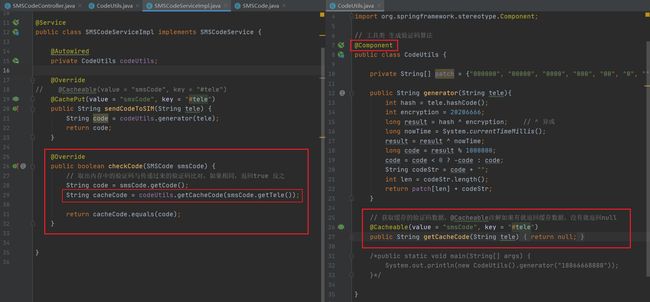
测试
匹配成功测试

匹配失败测试

注意:当手机号不对方法返回的还是null,空指针错误,只要把cacheCode.equals(code)换成code.equals(cacheCode)就行,上面这样换是为了演示注解为什么不会被扫描到
变更缓存供应商
SpringBoot提供的缓存技术除了默认的缓存方案,还可以对其它缓存技术进行整合,统一接口,方便缓存技术的开发与管理(就是说使用缓存技术的话,这一套接口是通用的,只需要换实现就行了,代码不用动)
SpringBoot提供的整合缓存技术
- Generic
- JCache
- Ehcache
- Hazelcast
- Infinispan
- Couchbase
- Redis
- Caffeine
- Simple(默认)
- memcached(这个没有提供,但常用)
- jetcache(阿里出品)
之前我们都是使用springboot默认内置的缓存技术Simple(内存级),接下来介绍几种专业的缓存供应商提供的缓存技术
SpringBoot整合Ehcache缓存




1.添加ehcache依赖

<dependency>
<groupId>net.sf.ehcachegroupId>
<artifactId>ehcacheartifactId>
dependency>
2.编写配置文件配置缓存技术实现使用Ehcache

测试运行
程序直接报错,原因是对于Ehcache来说,这是一个Spring体系外的技术,Ehcache它有自己的配置,我们必须得加载进去。
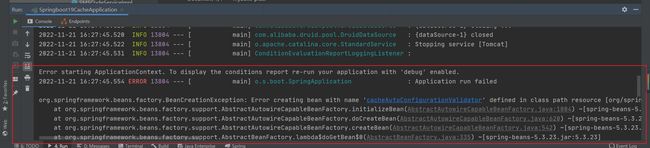
3.加入Ehcache的配置文件
ehcache.xml

测试运行
获取验证码还是报错,没有找到smsCode
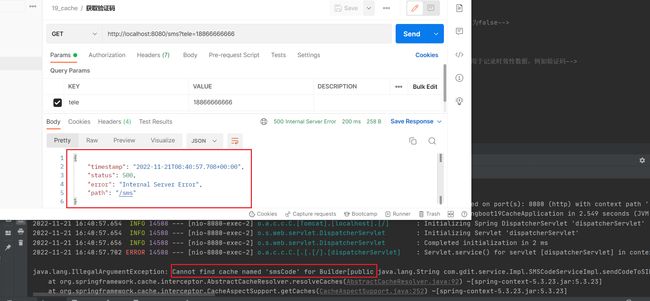
为什么报这个错,现在我们在缓存使用位置处写了下面这样的代码,代表它要去缓存中找一个名称叫做smsCode的配置,在哪呢?它在ehcache.xml是找不到的,因为我们没有配置。之前没写是因为我们使用的是默认缓存技术Simple不需要写。而ehcache的配置有独立的配置文件格式,因此还需要指定ehcache的配置,以便于读取相应配置
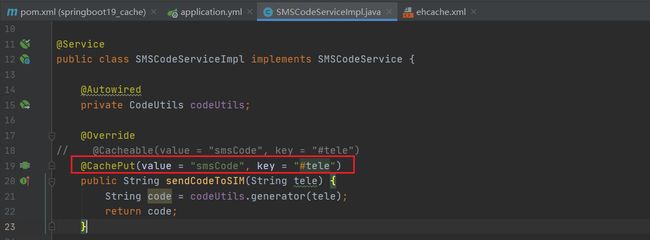
4.配置缓存位置
ehcache.xml中除了默认配置外,还可以接着配各式各样的缓存,而每一个缓存使用name属性来区分。只有写上这个之后@CachePut(value = “smsCode”, key = “#tele”)才能存到ehcache所对应的配置中。
这个设定需要保障ehcache中有一个缓存空间名称叫做smsCode的配置,前后要统一。在企业开发过程中,通过设置不同名称的cache来设定不同的缓存策略,应用于不同的缓存数据。

测试运行
这次就成功运行不报错了

提示:改ehcache.xml中的配置属性能实现不同的效果,例如把timeToIdleSeconds和timeToLiveSeconds都改成10,就能实现10秒后清除改缓存,从而让验证码失效
到这里springboot整合Ehcache就做完了,可以发现一点,原始代码没有任何修改,仅仅是加了一组配置就可以变更缓存供应商了,这也是springboot提供了统一的缓存操作接口的优势,变更实现并不影响原始代码的书写。
SpringBoot整合Redis缓存



1.添加redis依赖

<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
2.启动redis服务器(参考上方Redis部分)

3.编写配置文件配置缓存技术实现使用redis(redis不用xml配置文件,可以直接在yml中配置)
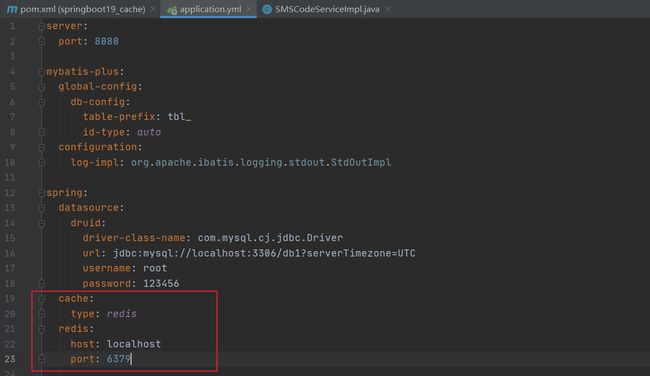
测试运行
成功运行,没报错
在redis客户端中查询所有key,会发现它已经存进去了

相关配置,例如10秒到期销毁相关缓存
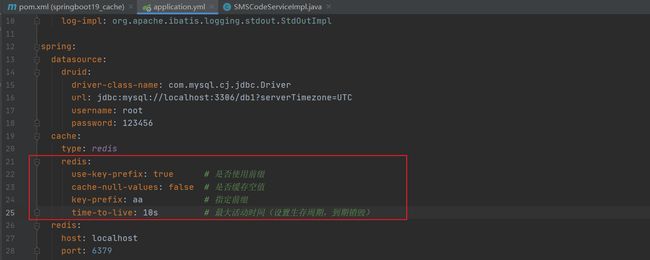
- use-key-prefix 是否使用前缀

- cache-null-values 是否缓存空值
- key-prefix 指定前缀(如果use-key-prefix也同为true就会叠加,use-key-prefix为false这个配了true也没有)

- time-to-live 最大活动时间(设置生存周期,到期销毁)
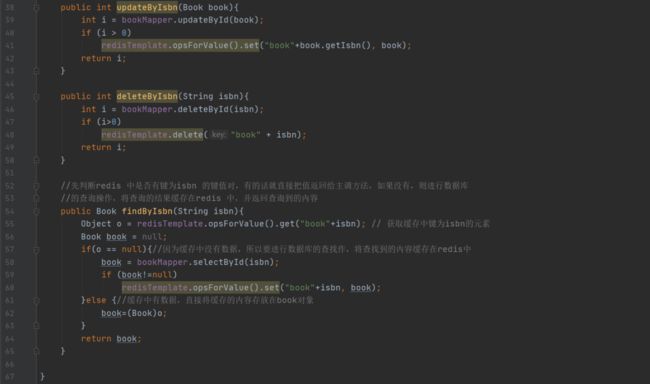
补充:基于API的Redis缓存实现

SpringBoot整合Memcache缓存
(暂时跳过)
SpringBoot整合jetcache缓存
前面学习的几种缓存各有各的优点,但存在一个问题,它们的配置太松散了。例如:ehcache中在ehcache.xml进行相关配置,redis在yml中进行配置,memcache又是在代码中配置。还有就是现在的缓存方案要么用本地的形式,后面还有远程形式(解决了多台服务器共享缓存),本地速度快无法共享,远程可以共享速度慢,那如何做到既有远程又有本地的需求呢——jetcache(阿里出品)
jetcache严格意义上来说,并不是一个缓存解决方案,只能说他算是一个缓存框架,然后把别的缓存放到jetcache中管理,这样就可以支持AB缓存一起用了。
-
jetCache对SpringCache进行了封装,在原有功能基础上实现了多级缓存、缓存统计、自动刷新、异步调用、数据报表等功能
-
jetCache设定了本地缓存与远程缓存的多级缓存解决方案,目前jetcache支持的缓存方案本地缓存支持两种,远程缓存支持两种
-
本地缓存(local)
- LinkedHashMap
- Caffeine
-
远程缓存(remote)
- Redis
- Tair
-
上述本地远程缓存可随意组合使用,也可以单独使用某一个,我们以LinkedHashMap+Redis的方案实现本地与远程缓存方案同时使用







环境准备
启动redis服务器和客户端

<dependencies>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-boot-starterartifactId>
<version>3.4.3version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druid-spring-boot-starterartifactId>
<version>1.2.6version>
dependency>
<dependency>
<groupId>com.mysqlgroupId>
<artifactId>mysql-connector-jartifactId>
<scope>runtimescope>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
dependencies>

其它代码跟上一节一样,只改了SMSCodeServiceImpl和BookServiceImpl实现类,把使用缓存的部分都抹掉了。启动类也没启动缓存的注解

jetcache纯远程缓存
1.引入坐标
<dependency>
<groupId>com.alicp.jetcachegroupId>
<artifactId>jetcache-starter-redisartifactId>
<version>2.6.2version>
dependency>
2.编写配置文件
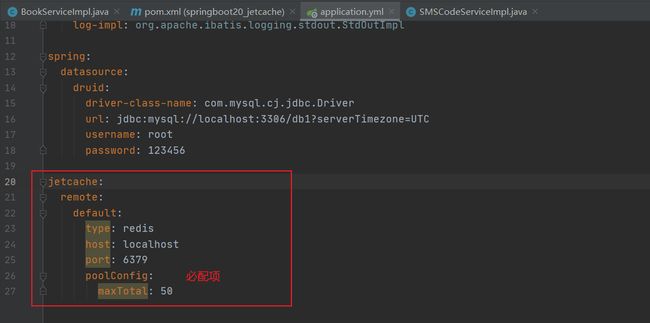
注意:poolConfig是必配项,否则会报错
3.使用
jetcache是替代SpringCache的,所以它和SpringCache的使用操作很像
第一步:启用缓存

第二步:操作缓存
自定义缓存空间
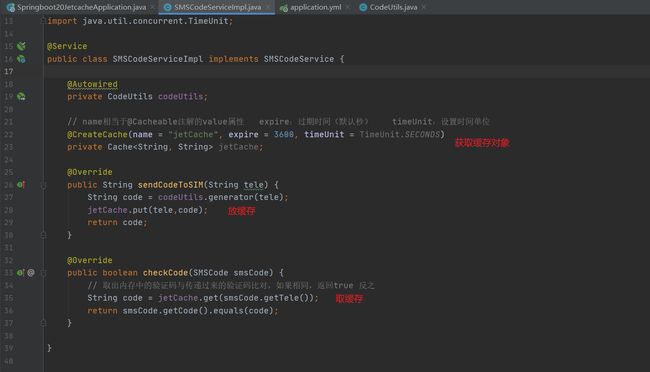
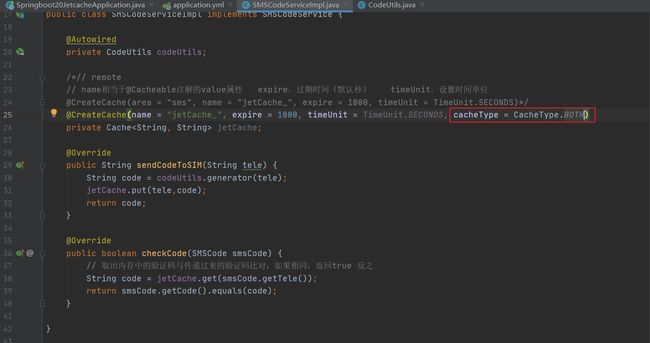
@CreateCache(name = “jetCache”, expire = 3600, timeUnit = TimeUnit.SECONDS)
name相当于@Cacheable注解的value属性 expire:过期时间(默认秒) timeUnit:设置时间单位
private Cache jetCache;等同于之前我们自定义的hashmap,但它的Cache类肯定做了很多设置的,注意Cache类不要导错包
![]()
put放缓存,get取缓存
测试运行


细节处理:
如果报以下错,在yml配置文件中加上 spring.main.allow-circular-references为true


上述方案中使用的是配置中定义的default缓存,其实这个default是个名字,可以随便写,也可以随便加。例如再添加一种缓存解决方案,如果想使用名称是sms的缓存,需要再创建缓存时指定参数area,声明使用对应缓存即可
area默认值就是default,所以前面default写错一个字母都找不到配置
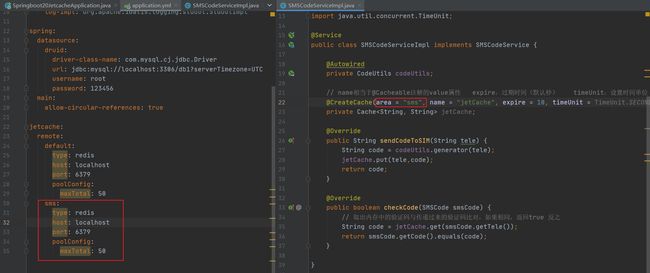

jetcache纯本地缓存
1.引入坐标

<dependency>
<groupId>com.alicp.jetcachegroupId>
<artifactId>jetcache-starter-redisartifactId>
<version>2.6.2version>
dependency>
2.编写配置文件

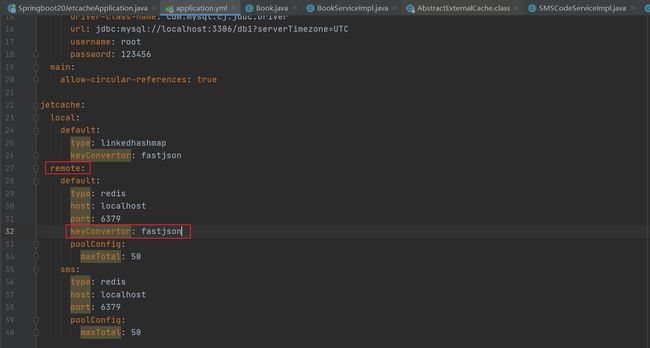
keyConvertor为必配项,因为一个key对应一个value,一般key都是字符串的,但它也支持对象Object类型。这时如果把对象Object作为key的话,它的比对工作量就会很高。为了加速数据获取时key的匹配速度,jetcache要求指定key的类型转换器。简单说就是,如果你给了一个Object作为key的话,我先用key的类型转换器给转换成字符串,然后再保存。等到获取数据时,仍然是先使用给定的Object转换成字符串,然后根据字符串匹配。由于jetcache是阿里的技术,这里推荐key的类型转换器使用阿里的fastjson。jetcache依赖中包含了fastjson的依赖,不用重新导入了。
3.使用
第一步:启用缓存

第二步:操作缓存
自定义缓存空间

cacheType属性
- CacheType.LOCAL 只用本地
- CacheType.REMOTE 只用远程
- CacheType.BOTH 两个都用
- 不写默认只用远程
测试
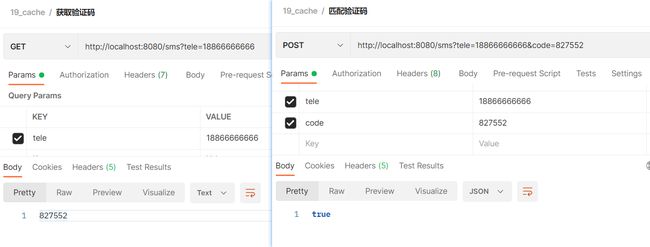

缓存使用本地,没经过远程redis
jetcache本地+远程方案
本地和远程方法都有了,两种方案一起使用如何配置呢?其实就是将两种配置合并到一起就可以了。

在创建缓存的时候,配置cacheType为BOTH即则本地缓存与远程缓存同时使用。
cacheType如果不进行配置,默认值是REMOTE,即仅使用远程缓存方案。关于jetcache的配置,参考以下信息
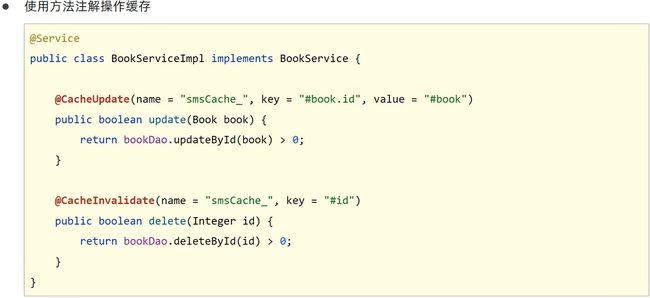
jetcache方法缓存
SpringCache中对普通模块增删改查的缓存注解特别好用,往方法上一加缓存就能用了,jetcache有吗?当然,jetcache相当于对SpringCache的升级当然也有这种方式




环境准备
还是原来那个项目,使用jetcache本地+远程方案
启动redis服务器
1.启用方法缓存
启动类添加@EnableMethodCache(basePackages = “com.gdit”),记得添加包名,支持数组形式
记得一定要跟@EnableCreateCacheAnnotation注解一起用,因为它也是用注解做的索引

2.在方法上添加注解
@Cached,其内属性的使用和@CreateCache差不多,可以指定销毁时间,时间单位,指定本地还是远程或者组合。

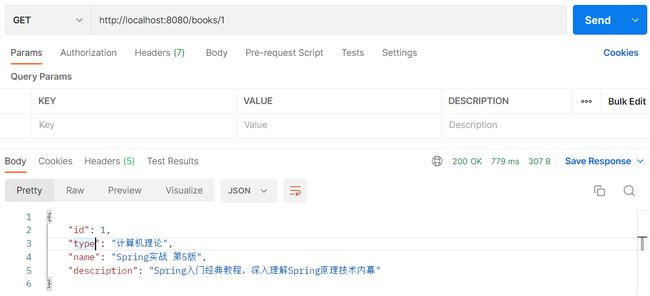
测试运行
能成功查询出数据,但控制台报错了 空指针异常,原因是@Cached注解默认是存储远程,而我们在远程没有配置keyConvertor(该属性详见纯本地缓存那),只在本地配置了,加上就好。

3.配置文件配置keyConvertor
测试运行
再次运行,能成功查询并返回,但控制台又报错了,Book没有序列化的异常。为什么要对Book做序列化呢,之前在SpringBoot读取Redis客户端有提到过,Java中我们以对象的形式操作数据,但现在对象要放到Redis中去,Redis不支持存储Java的对象。所以应该先把Java对象转一个能够让redis存储的东西,然后再存进去。其内部用了序列化和反序列化机制,存的时候序列化,取的时候反序列化,所以在Book类实现一个接口Serializable。然后在配置中告诉它要进行序列化和反序列化(好麻烦)

3.序列化和反序列化(实体类实现Serializable并在配置文件中告知)

测试运行

远程成功,测试本地


本地远程都可以,redis里也成功存储

数据同步问题
万一取缓存的时候数据变了怎么办,就是说现在数据存进缓存了,其他人这个时候碰巧把数据库改了,而这边没有更新。由于远程方案中redis保存的数据可以被多个客户端共享,这就存在了数据同步问题。jetcache提供了3个注解解决此问题,分别在更新、删除操作时同步缓存数据,和读取缓存时定时刷新数据

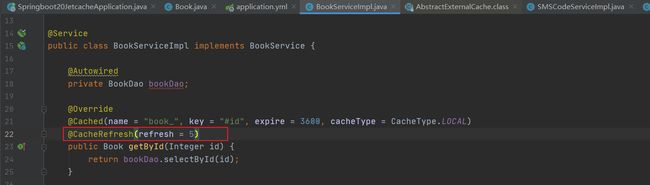
例如执行了更新操作,它会取缓存找name = “book_”, key = "#book.id"的值并用value = "#book"替换
测试


删除注解,执行删除后会把缓存也删掉,之后查询就会走数据库。
定时刷新数据,为时刻保持于数据库同步,可以设定按时间去数据库同步数据。(这个慎用,不然太频繁会加重数据库负担)
数据报表
jetcache还提供有简单的数据报表功能,帮助开发者快速查看缓存命中信息,只需要添加一个配置即可

单位是分钟,设置后,每1分钟在控制台输出缓存数据命中信息

SpringBoot整合j2cache缓存
暂时跳过
任务
-
定时任务是企业级应用中的常见操作
- 年度报表
- 缓存统计报告
- … …
这里说的任务系统指的是定时做某一项工作(定时任务),假如说是月度报表计算量比较少,点一下产生报表马上计算就能满足需要查看报表。但是如果是年度报表呢,首先它要计算的不是一个数据,是成千上万的数据。其次它要计算的数据量十分庞大,比如支付宝年度要进行统计,你知道要多长时间吗,所以这项工作就必须提前开始做。什么时候开始呢,假如要统计2022年的报表,那必须在2022年12月31日23:59:59以后才能开始统计,因为这个时候数据才完整。但是第二天一大早又想看 那必须让它凌晨干这些事。那么谁去点这个按钮呢,不需要人点,我们只需要做一个定时任务在2023年1月1日早晨00:10:00开始计算就行,只要在早晨想看报表之前完成就行不管它要计算几个小时。不仅这些大型项目进行定时任务,小任务也会有,比如上一节缓存的数据报表,每隔一段时间计算缓存命中情况,再比如抢购类活动的商品上架,不可能手工去上架万一早了或晚了怎么办这就不公平了,这些都离不开定时任务。
入门案例
使用Java现成的API完成定时任务
环境准备(就导入了一个lombok依赖)
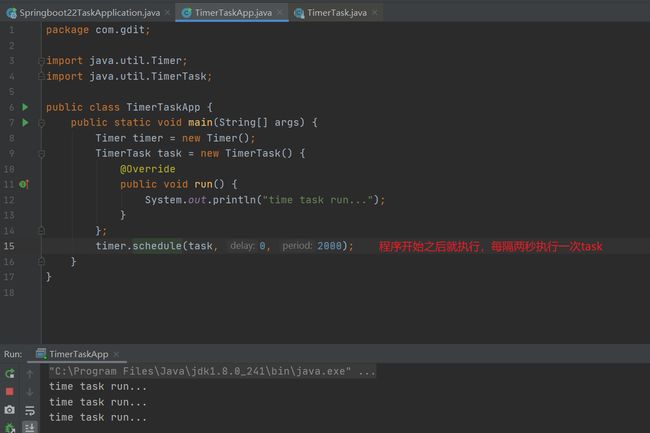
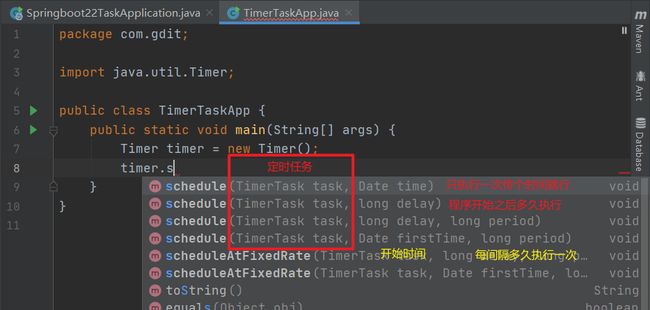
只靠Java内部api实现显然不够,所以出现了定时任务框架
-
市面上流行的定时任务技术
- Quartz
- Spring Task
SpringBoot整合Quartz
Quartz技术是一个比较成熟的定时任务框架,怎么说呢?有点繁琐,用过的都知道,配置略微复杂。springboot对其进行整合后,简化了一系列的配置,将很多配置采用默认设置,这样开发阶段就简化了很多。
-
相关概念
- 工作(Job):用于定义具体执行的工作
- 工作明细(JobDetail):用于描述定时工作相关的信息
- 触发器(Trigger):用于描述触发工作的执行规则,通常使用cron表达式定义规则
- 调度器(Scheduler):描述了工作明细与调度器的对应关系
触发器绑定工作明细,工作明细中指定工作,而不是触发器直接绑定工作


1.引入坐标
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-quartzartifactId>
dependency>
2.创建具体执行的工作

3.编写配置类
创建两个东西,工作明细和触发器,触发器绑定工作明细,工作明细中指定工作
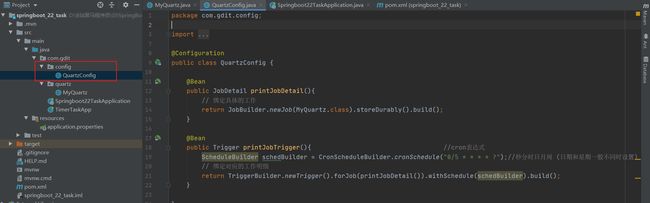
newJob(MyQuartz.class)指定具体的工作,它会去执行这个类的executeInternal方法。
.storeDurably()持久化,工作创建之后假定没有使用是否持久化存起来,因为一旦不用它 这个对象就没有意义就会被干掉,记得加上就行
触发器需要绑定任务,使用forJob()操作传入绑定的工作明细对象。此处可以为工作明细设置名称然后使用名称绑定,也可以直接调用对应方法绑定。触发器中最核心的规则是执行时间,此处使用调度器定义执行时间,执行时间描述方式使用的是cron表达式。有关cron表达式的规则,各位小伙伴可以去参看相关课程学习,略微复杂,而且格式不能乱设置,不是写个格式就能用的,写不好就会出现冲突问题。
测试运行
直接启动SpringBoot启动类就行,启动容器他就会加载QuartzConfig,因为我们把它定义成配置类了。

SpringBoot整合Task
整合Quartz会发现,这玩意太麻烦了,所以spring根据定时任务的特征,将定时任务的开发简化到了极致。怎么说呢?要做定时任务总要告诉容器有这功能吧,然后定时执行什么任务直接告诉对应的bean什么时间执行就行了,就这么简单
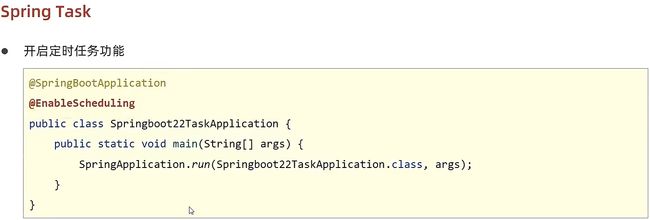


1.启动类添加@EnableScheduling注解开启定时任务功能

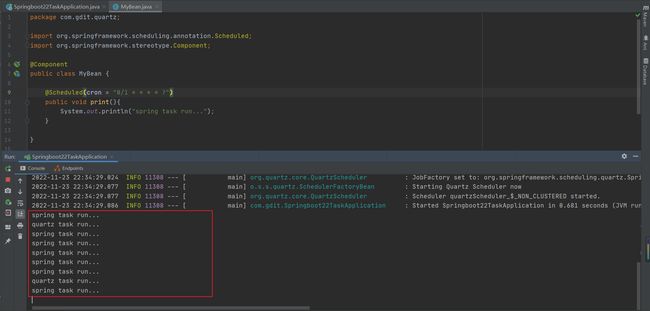
2.编写定时任务
记得定义成bean
用的cron表达式

测试运行
springtask没1秒执行一次,quartz没关所以每5秒执行一次
还可以对定时任务进行相关配置
邮件
SpringBoot整合JavaMail
发邮件是java程序的基本操作,springboot整合javamail其实就是简化开发。
相关概念
- SMTP(Simple Mail Transfer Protocol):简单邮件传输协议,用于发送电子邮件的传输协议
- POP3(Post Office Protocol - Version 3):用于接收电子邮件的标准协议
- IMAP(Internet Mail Access Protocol):互联网消息协议,是POP3的替代协议
(开发主要操作发送邮件,也有接收邮件 很少)
发送简单邮件



环境准备
就一个空的SpringBoot项目,也没有勾选什么起步依赖
1.引入坐标
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-mailartifactId>
dependency>
2.编写yml配置文件

host:用户归属那个邮件系统,例如 smtp.qq.com或smtp.163.com,也就是告知邮件供应商因为是发送邮件所以是smtp
username:最基本的邮件发送账户要告知,
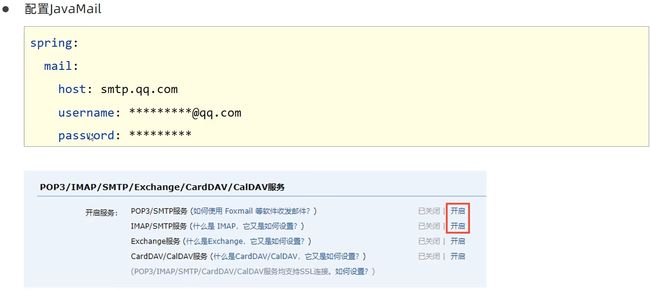
password:这个密码不是邮箱登录密码,而是服务器提供的一个加密后的密码,直接写没用
password获取方式


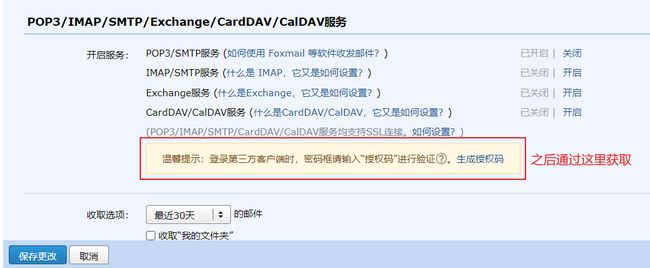
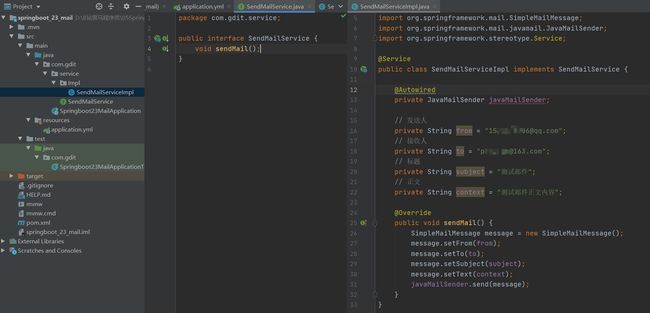
3.编写业务层发送邮件
测试类测试
成功发送


细节

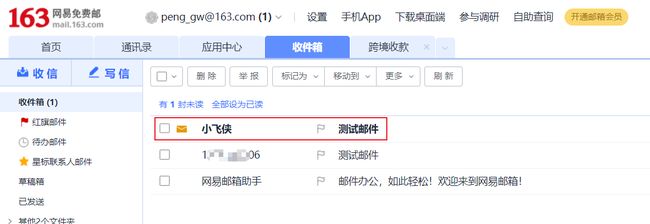
发送多组件邮件(附件、复杂正文)
发送网页正文

发送带有附件的邮件


消息队列
这里只简答的介绍一下,后面学习微服务会详细实现
消息的概念
消息的概念在日常生活中非常常见,而对于Java开发则借鉴了这样的思想,让后把它做出了一种数据处理的机制。比如古代行军打仗在长城设置了很多烽火台,当烽火台的守军发现敌军来犯就点燃烽火,临近的其它烽火台就能看到,然后它们再点燃烽火 一级一级的向下传递,达成一种效果就是敌军进犯的消息能够快速蔓延到前线并作出合理调兵,这个过程就出现消息传递。

在消息传递的过程中有两个主体一定要分清,消息的发送方和消息的接收方,通常发送消息的一方称为消息的生产者,接收消息的一方称为消息的消费者。
除了消息传递过程中的生产者和消费者双方之外还有一组信息,就是消息的模式。同步消息和异步消息。所谓同步消息就是生产者发送完消息,等待消费者处理,消费者处理完将结果告知生产者,然后生产者继续向下执行业务。比如有人向你借钱,你去找他还第一步要问它在吗,等对方回应后才给他聊正事。所谓异步消息就是生产者发送完消息,无需等待消费者处理完毕,生产者继续向下执行其他动作。比如你要结婚了直接通知对方就行,不管他回不回婚礼都要举办。

消息队列
浏览器发给业务服务器一个请求,得到请求业务服务器处理就行。但这个时候浏览器客户端比较多呢,它一次发了无数个请求到业务服务器,那业务服务器压力就会很大,于是由业务服务器拆分成若干个可以处理这个业务的子业务服务器。这样业务服务器接收到请求后就不直接处理,交给后面的子业务系统处理,但是它们处理什么呢,那就得有个中间的桥梁,这个时候就需要一个保存消息的东西,业务系统将所要处理的信息发给这个东西,然后子业务系统再到这个东西里获取要执行的工作,那么整个过程中所有要执行的工作其实最终都转换成消息的格式存在。这个保存消息的东西可以简单理解成一个容器,我们通常称这个东西为队列,因为它是保存消息的所以叫消息队列MQ(Message Queue)
-
企业级应用中广泛使用的三种异步消息传递技术
- JMS
- AMQP
- MQTT
为什么是三大类,而不是三个技术呢?因为这些都是规范,就像JDBC技术,是个规范,开发针对规范开发,运行还要靠实现类,例如MySQL提供了JDBC的实现,最终运行靠的还是实现。
-
JMS
-
JMS(Java Message Service),一个规范,作用等同于JDBC规范,提供了与消息服务相关的API接口。
-
JMS消息模型
- peer-2-peer::点对点模型,消息发送到一个队列中,队列保存消息。队列的消息只能被一个消费者消费,或超时
- publish-subscribe:发布订阅模型,消息可以被多个消费者消费,生产者和消费者完全独立,不需要感知对方的存在
-
JMS消息种类
- TextMessage
- MapMessage
- BytesMessage
- StreamMessage
- ObjectMessage
- Message (只有消息头和属性)
-
JMS实现:ActiveMQ、Redis、HornetMQ、RabbitMQ、RocketMQ(没用完全遵守JMS规范)
-
-
AMQP
-
AMQP(advanced message queuing protocol):一种协议(高级消息队列协议,也是消息代理规范),规范了网络交换的数据格式,兼容JMS操作。
-
优点:具有跨平台性,服务器供应商,生产者,消费者可以使用不同的语言来实现
-
AMQP消息模型
- direct exchange
- fanout exchange
- topic exchange
- headers exchange
- system exchange
-
AMQP消息种类:byte[]
-
AMQP实现:RabbitMQ、StormMQ、RocketMQ等
-
-
MQTT
- MQTT(Message Queueing Telemetry Transport)消息队列遥测传输,专为小设备设计,是物联网(IOT)生态系统中主要成分之一。(由于与JavaEE企业级开发没有交集,此处不作过多的说明)
-
Kafka
- Kafka,一种高吞吐量的分布式发布订阅消息系统,提供实时消息功能。
(上面的概念太多不用记这么多多,记得一点,以后的工作任务 都可以转换成消息来处理,说白了 不管干什么事,最终都可以变成一个消息,然后再由另外一方去拿到这个消息具体干活)
注:
该内容是根据B站黑马程序员学习时所记,相关资料可在B站查询:黑马程序员SpringBoot2全套视频教程,springboot零基础到项目实战(spring boot2完整版)