Python 协程 asyncio 极简入门与爬虫实战
在了解了 Python 并发编程的多线程和多进程之后,我们来了解一下基于 asyncio 的异步IO编程--协程
01
协程简介
协程(Coroutine)又称微线程、纤程,协程不是进程或线程,其执行过程类似于 Python 函数调用,Python 的 asyncio 模块实现的异步IO编程框架中,协程是对使用 async 关键字定义的异步函数的调用;
一个进程包含多个线程,类似于一个人体组织有多种细胞在工作,同样,一个程序可以包含多个协程。多个线程相对独立,线程的切换受系统控制。同样,多个协程也相对独立,但是其切换由程序自己控制。
02
一个简单例子
我们来使用一个简单的例子了解协程,首先看看下面的代码:
import time
def display(num):
time.sleep(1)
print(num)
for num in range(10):
display(num)很容易看得懂,程序会输出0到9的数字,每隔1秒中输出一个数字,因此整个程序的执行需要大约10秒 时间。值得注意的是,因为没有使用多线程或多进程(并发),程序中只有一个执行单元(只有一个线程在 执行),而 time.sleep(1) 的休眠操作会让整个线程停滞1秒钟,
对于上面的代码来说,在这段时间里面 CPU是闲置的没有做什么事情。
我们再来看看使用协程会发生什么:
import asyncio
async def display(num): # 在函数前使用async关键字,变成异步函数 await asyncio.sleep(1)
print(num)异步函数不同于普通函数,调用普通函数会得到返回值,而调用异步函数会得到一个协程对象。我们需要将协程对象放到一个事件循环中才能达到与其他协程对象协作的效果,因为事件循环会负责处理子程 序切换的操作。
简单的说就是让阻塞的子程序让出CPU给可以执行的子程序。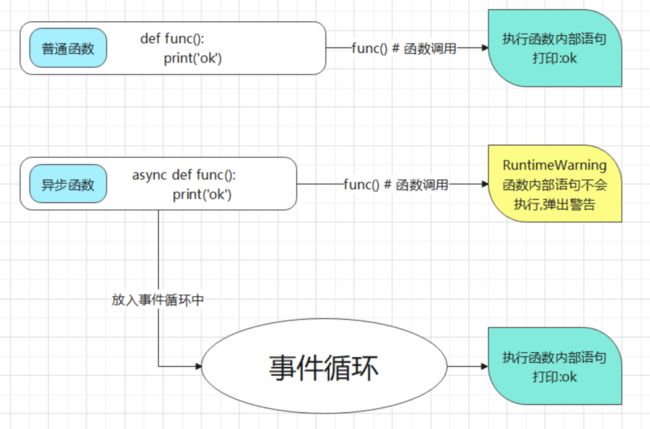
03
基本概念
异步IO是指程序发起一个IO操作(阻塞等待)后,不用等IO操作结束,可以继续其它操作;做其他事情,当IO操作结束时,会得到通知,然后继续执行。异步IO编程是实现并发的一种方式,适用于IO密集型任务
Python 模块 asyncio 提供了一个异步编程框架,全局的流程图大致如下: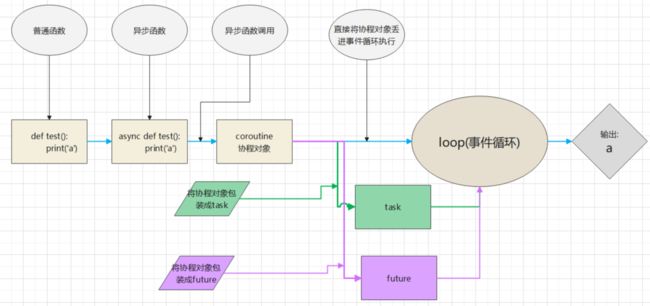
下面对每个函数都从代码层面进行介绍
async: 定义一个方法(函数),这个方法在后面的调用中不会被立即执行而是返回一个协程对象;
async def test(): print('hello 异步')
test() # 调用异步函数
输出:RuntimeWarning: coroutine 'test' was never awaitedcoroutine: 协程对象,也可以将协程对象添加到时间循环中,它会被事件循环调用;
async def test():
print('hello 异步')
c = test() # 调用异步函数,得到协程对象-->c
print(c)
输出:event_loop: 事件循环,相当于一个无限循环,可以把一些函数添加到这个事件中,函数不会立即执行, 而是满足某些条件的时候,函数就会被循环执行;
async def test():
print('hello 异步')
c = test() # 调用异步函数,得到协程对象-->c
loop = asyncio.get_event_loop() # 创建事件循环
loop.run_until_complete(c) # 把协程对象丢给循环,并执行异步函数内部代码
输出:hello 异步await: 用来挂起阻塞方法的执行;
import asyncio
def running1():
async def test1():
print('1')
await test2()
print('2')
async def test2():
print('3')
print('4')
loop = asyncio.get_event_loop()
loop.run_until_complete(test1())
if __name__ == '__main__':
running1()输出:
task: 任务,对协程对象的进一步封装,包含任务的各个状态;
async def test():
print('hello 异步')
c = test() # 调用异步函数,得到协程对象-->c
loop = asyncio.get_event_loop() # 创建事件循环
task = loop.create_task(c) # 创建task任务
print(task)
loop.run_until_complete(task) # 执行任务
输出:
> # task
hello 异步 # 异步函数内部代码一样执行 future: 代表以后执行或者没有执行的任务,实际上和task没有本质区别;这里就不做代码展示;
首先使用一般方式方法创建一个函数:
def func(url):
print(f'正在对{url}发起请求:')
print(f'请求{url}成功!')
func('www.baidu.com')结果如下所示:
正在对www.baidu.com发起请求:
请求www.baidu.com成功04
基本操作
创建协程对象
通过 async 关键字定义一个异步函数,调用异步函数返回一个协程对象。
异步函数就是在函数执行过程中挂起,去执行其他异步函数,等待挂起条件(time.sleep(n))消失后,再回来执行,接着我们来修改上述代码:
async def func(url):
print(f'正在对{url}发起请求:')
print(f'请求{url}成功!')
func('www.baidu.com')结果如下:
RuntimeWarning: coroutine 'func' was never awaited这就是之前提到的,使用async关键字使得函数调用得到了一个协程对象,协程不能直接运行,需要把协程 加入到事件循环中,由后者在适当的时候调用协程;
创建task任务对象
task任务对象是对协程对象的进一步封装;
import asyncio
async def func(url):
print(f'正在对{url}发起请求:')
print(f'请求{url}成功!')
c = func('www.baidu.com') # 函数调用的写成对象--> c
loop = asyncio.get_event_loop() # 创建一个时间循环对象
task = loop.create_task(c)
loop.run_until_complete(task) # 注册加启动
print(task)结果如下:
正在对www.baidu.com发起请求:
请求www.baidu.com成功!
result=None> future的使用
前面我们提及到future和task没有本质区别
async def func(url):
print(f'正在对{url}发起请求:')
print(f'请求{url}成功!')
c = func('www.baidu.com') # 函数调用的写成对象--> c
loop = asyncio.get_event_loop() # 创建一个时间循环对象
future_task = asyncio.ensure_future(c)
print(future_task,'未执行')
loop.run_until_complete(future_task) # 注册加启动
print(future_task,'执行完了')结果如下:
>未执行
正在对www.baidu.com发起请求:
请求www.baidu.com成功!
result=None> 执行完了 await关键字的使用
在异步函数中,可以使用await关键字,针对耗时的操作(例如网络请求、文件读取等IO操作)进行挂起,比如异步程序执行到某一步时需要很长时间的等待,就将此挂起,去执行其他异步函数
import asyncio, time
async def do_some_work(n): #使用async关键字定义异步函数
print('等待:{}秒'.format(n))
await asyncio.sleep(n) #休眠一段时间
return '{}秒后返回结束运行'.format(n)
start_time = time.time() #开始时间
coro = do_some_work(2)
loop = asyncio.get_event_loop() # 创建事件循环对象
loop.run_until_complete(coro)
print('运行时间: ', time.time() - start_time)运行结果如下:
等待:2秒
运行时间: 2.00131201744079605
多任务协程
任务(Task)对象用于封装协程对象,保存了协程运行后的状态,使用 run_until_complete() 方法将任务注册到事件循环;
如果我们想要使用多任务,那么我们就需要同时注册多个任务的列表,可以使用 run_until_complete(asyncio.wait(tasks)),
这里的tasks,表示一个任务序列(通常为列表)
注册多个任务也可以使用run_until_complete(asyncio. gather(*tasks))
import asyncio, time
async def do_some_work(i, n): #使用async关键字定义异步函数
print('任务{}等待: {}秒'.format(i, n))
await asyncio.sleep(n) #休眠一段时间
return '任务{}在{}秒后返回结束运行'.format(i, n)
start_time = time.time() #开始时间
tasks = [asyncio.ensure_future(do_some_work(1, 2)),
asyncio.ensure_future(do_some_work(2, 1)),
asyncio.ensure_future(do_some_work(3, 3))]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
for task in tasks:
print('任务执行结果: ', task.result())
print('运行时间: ', time.time() - start_time)运行结果如下:
任务1等待: 2秒
任务2等待: 1秒
任务3等待: 3秒
任务执行结果: 任务1在2秒后返回结束运行 任务执行结果: 任务2在1秒后返回结束运行 任务执行结果: 任务3在3秒后返回结束运行 运行时间: 3.002867698669433606
实战|爬取LOL皮肤
首先打开官网:

可以看到英雄列表,这里就不详细展示了,我们知道一个英雄有多个皮肤,我们的目标就是爬取每个英雄的所有皮肤,保存到对应的文件夹里;
打开一个英雄的皮肤页面,如下所示:

黑暗之女,下面的小兔对应的就是该隐兄弟皮肤,然后通过查看network发现对应的皮肤数据在js文件里;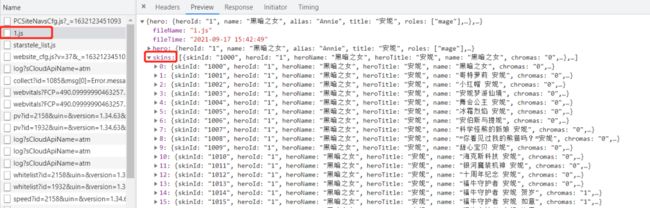
然后我们发现了英雄皮肤存放的url链接规律:
url1 = 'https://game.gtimg.cn/images/lol/act/img/js/hero/1.js'
url2 = 'https://game.gtimg.cn/images/lol/act/img/js/hero/2.js'
url3 = 'https://game.gtimg.cn/images/lol/act/img/js/hero/3.js'我们发现只有id参数是动态构造的,规律是:
'https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js'.format(i)但是这个id只有前面的是按顺序的,在展示全部英雄的页面找到对应英雄的id,
这里截取的是最后几个英雄的id,所以要全部爬取,需要先设置好id,由于前面的是按顺序的,这里我们就爬 取前20个英雄的皮肤;
1. 获取英雄皮肤ulr地址:
前面的英雄id是按顺序的所有可以使用range(1,21),动态构造url;
def get_page():
page_urls = []
for i in range(1,21):
url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js'.format(i)
print(url)
page_urls.append(url)
return page_urls2. 请求每一页的url地址
并对网页进行解析获取皮肤图片的url地址:
def get_img():
img_urls = []
page_urls = get_page()
for page_url in page_urls:
res = requests.get(page_url, headers=headers)
result = res.content.decode('utf-8')
res_dict = json.loads(result)
skins = res_dict["skins"]
for hero in skins:
item = {}
item['name'] = hero["heroName"]
item['skin_name'] = hero["name"]
if hero["mainImg"] == '':
continue
item['imgLink'] = hero["mainImg"]
print(item)
img_urls.append(item)
return img_urls说明:
res_dict = json.loads(result): 将得到的json格式字符串转化为字典格式;heroName:英雄名字(这个一定是一样的,方便我们后面根据英雄名创建文件夹);name:表示完整的 名字,包括皮肤名(这个一定是不一样的) 有的'mainImg'是空的,我们需要进行一个判断;
3. 创建协程函数
这里我们根据英雄名创建文件夹,然后就是注意图片的命名,不要忘记/,目录结构确立
async def save_img(index, img_url):
path = "皮肤/" + img_url['name']
if not os.path.exists(path):
os.makedirs(path)
content = requests.get(img_url['imgLink'], headers=headers).content
with open('./皮肤/' + img_url['name'] + '/' + img_url['skin_name'] + str(index) + '.jpg', 'wb') as f:
f.write(content)主函数:
def main():
loop = asyncio.get_event_loop()
img_urls = get_img() print(len(img_urls))
tasks = [save_img(img[0], img[1]) for img in enumerate(img_urls)]
try:
loop.run_until_complete(asyncio.wait(tasks))
finally:
loop.close()4. 程序运行
if __name__ == '__main__':
start = time.time()
main()
end = time.time()
print(end - start)运行结果:
下载233张图花费了42s,可以看到速度还行,文件目录结果如下: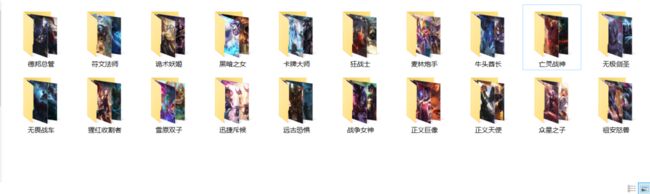
与requests对比
异步爬取图片之后,我们有必要使用requests去进行同步数据爬取,进行效率对比,所以在原有代码的 基础上进行修改,这里直接略过,思路都是一样的,这是把一部当中的事件循环替换成循环即可:
img_urls = get_img()
print(len(img_urls))
for i,img_url in enumerate(img_urls):
save_img(i,img_url)
我们可以看到,使用协程的速度要比 requests 快了一些。
以上就是本文的全部内容,感兴趣的读者可以自己动手敲一遍代码~
![]()
E N D
![]()
各位伙伴们好,詹帅本帅假期搭建了一个个人博客和小程序,汇集各种干货和资源,也方便大家阅读,感兴趣的小伙伴请移步小程序体验一下哦!(欢迎提建议)
推荐阅读
牛逼!Python常用数据类型的基本操作(长文系列第①篇)
牛逼!Python的判断、循环和各种表达式(长文系列第②篇)
牛逼!Python函数和文件操作(长文系列第③篇)
牛逼!Python错误、异常和模块(长文系列第④篇)