day02-08 python基础语法
模块一 python基础语法
day2–快速上手
今日概要
课程目标:学习Python最基础的语法知识,可以用代码快速实现一些简单的功能。
课程概要:
- 初识编码(密码本)
- 编程初体验
- 输出
- 初识数据类型
- 变量
- 注释
- 输入
- 条件语句
1.编码(密码本)
计算机中所有的数据本质上都是以0和1的组合来存储。
在计算机中有这么一个编码的概念(密码本)。
小 -> 01111111 00011010 010110110
佩 -> 01001111 10010000 001110100
齐 -> 11111111 00000000 010101010
在计算机中有很多种编码
每种编码都有自己的一套密码本,都维护这自己的一套规则,如:
utf-8编码:
小 -> 01111111 00011010 010110110
佩 -> 01001111 10010000 001110100
齐 -> 11111111 00000000 010101010
gbk编码:
小 -> 11111111 00000010
佩 -> 01001111 01111111
齐 -> 00110011 10101010
所以,使用的不同的编码保存文件时,硬盘的文件中存储的0/1也是不同的。
注意事项:以某个编码的形式进行保存文件,以后就要以这种编码去打开这个文件。否则就会出现乱码。
UTF-8编码去保存小佩齐:01111111 00011010 010110110 01001111 10010000 001110100 11111111 00000000 010101010
GBK编码形式去打开:乱码
2.编程初体验
-
编码必须要保持:保存和打开一直,否则会乱码。
-
默认Python解释器是以UTF-8编码的形式打开文件。如果想要修改Python的默认解释器编码,可以这样干:
# -*- coding:gbk -*- print("我是你二大爷") -
建议:所有Python代码文件的都要以UTF-8编码保存和读取。
3.输出与换行
将结果或内容呈现给用户。
print("种一棵树好的时间是十年前,其次是当下")
print就是打印输出。
关于输出:
-
默认print在尾部会加换行符
print("看风景美如画") print("想吟诗赠天下") 输出会带换行符: 看风景美如画 想吟诗赠天下 -
不换行
print("人生苦短",end="") print("我学python",end="") 输出: 人生苦短我学pythonprint("看着风景美如画",end=",") print("本想吟诗增天下",end=".") 输出: 看着风景美如画,本想吟诗增天下.使用逗号分割与
end=""是打印不换行,也可以再end=""等于中指定换行符。 -
一个print换行,sep=’\n’
print("文能提笔安天下,","武能上马定乾坤。","心存谋略何人胜,","古今英雄唯是君。",sep='\n') 输出: 文能提笔安天下, 武能上马定乾坤。 心存谋略何人胜, 古今英雄唯是君。
4.初识数据类型
- int 整型,整数
- str 字符串
- bool 布尔类型中有两个值:True / False
- …
4.1 整型(int)
整型,其实就是以前数学课上讲的整数(不包含小数),在写代码时用于表示整数相关的东西,例如:年龄、存款、尺寸、手机号等。
一般我们提到的:5、18、22、99、… 等整数 在Python中都称为是整型,且支持加减乘除,取余,指数等操作。
print(666)
print(2 + 10)
print(2 * 10)
print(10 / 2)
print(10 % 3)
print(2 ** 4)
4.2 字符串(str)
字符串,其实就是我们生活中的文本信息。例如:姓名、地址、自我介绍等。
字符串有一个特点,他必须由引号引起来,如:
单行字符串
print("Bella是逗比")
print('逗比是Bella')
print('天坑"Bella')
print("中国北京昌平区")
多行字符串
print("""中国北京昌平区""")
print('''中国北京昌平区''')
在需要打印双引号的时候,可以用单引号引起来,也支持三(单双)引号,表示多行内容。
print("""xxxx
yyyy
ooooo
xxxzzz
""")
输出多行:
xxxx
yyyy
ooooo
xxxzzz
对于字符串:只支持加与乘
-
加,两个字符串可以通过加号拼接起来。
print( "Bella" + "坑逼" ) -
乘,让整型和字符串进行相乘,以实现让字符串重复出现N次并拼接起来。
print(3 * "我想吃饺子")
总结:
+可以拼接字符串
*可以让整数和字符串进行相乘,以达到实现让字符串重复出现N次拼接的效果
小技巧
print()括号两边不要使用空格
使用 pycharm--code--Reformat Code 可以让代码自动格式化,变得更加规范
4.3布尔类型
布尔类型中总共就两个值:True/False
print(1 > 2)
print(False)
print(1 == 1)
print(True)
name = input("请输入入你的用户名:")
if name == "Bella":
print("用户登录成功")
else:
print("用户登录失败")
整型与字符串之间无法比较大小,只能比较是否相等。
1 > 2
1 == 3
"Bella" == "ella"
1 == "Bella"
1 > "Bella" # 是无法进行比较大小
4.4类型转换
数据类型int/str/bool,他们都有自己不同的定义方式;
- int,整型定义时,必须是数字,且无引号,例如:5,8,9
- str,字符串定义时,必须用双引号括起来,例如: “中国”,“小猪佩奇”,“888”
- bool,布尔值定义时,只能写True和False
不同的数据类型都有不同的功能,例如:整型可以加减乘除等运算,而字符串只能加(拼接)和乘法。
如果想要做转换可遵循一个基本规则:想转换什么类型就让他包裹一下。
例如:str(666)="666"是将整型转换为字符串,int(“888”)是将字符串转整型888.
# 字符串转换为整型(渡可渡-之人)
int("666")
int("999")
"6" + "9" 的结果应该是: "69"
int("6") + int("9") 的结果是:15
int("贝拉是sb") 报错
# 布尔类型转换为整型
int(True) 转换完等于 1
int(False) 转换完等于 0
转换为字符串
# 整型转字符串
str(345)
str(666) + str(9) 结果为:"6669"
# 布尔类型转换为字符串
str(True) "True"
str(False) "False"
转换为布尔类型
# 整型转布尔
bool(1) True
bool(2) True
bool(0) False
bool(-10) True
# 字符串转布尔
bool("Bella") True
bool("什么鬼") True
bool("") False
bool(" ") True
三句话搞定类型转换:
-
其他所有类型转换为布尔类型时,除了空字符,0 以外其他都是True。
-
字符串转整型时,只有这种 “998” 格式的字符串才可以转换为整型,其他都报错
-
想要转换为哪种类型,就是用这类型的英文包裹起来。
str(...) int(...) bool(...)
注:类型转换不是改变原来值,实际是在底层新创建了一个值。例如有整数6,然后使用str(6)转换得到"6",实际上这个字符串"6" 是依据整数6新创建的。
5.变量
变量,其实就是我们生活中起别名和外号,让变量名指向某个值,格式为:【变量名 = 值】,以后可以通过变量名来操作其对应的值。
nane = "小猪佩奇"
print(name)
age = 10
name = "Bella"
flag = 1 > 18
address = "深圳南山" + "必胜客"
addr = "深圳南山" + "必胜客" + name
print(addr)
print(flag)
age = 18
numer = 1 == 2
# 注意区分 "=" 与 "=="
注意:
- 给变量赋值 age = 18
- 让age代指值 age=18
5.1变量名的规范
-
变量名只能有字母,数字,下划线组成
-
不能以数字开头
-
不能使用python内置的关键字
>>> import keyword >>> keyword.kwlist ['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']两个建议:
- 连接建议使用下划线(小写)
- 见名知意
5.2 变量内存指向关系
内存指向,变量在电脑的内存中是怎么存储
情景一
name = "suse"
>>> name="suse"
>>> print(name)
suse
在计算机的内存中创建一块区域保存字符串"suse",name变量名则指向这块区域。
情景二
name = "suse"
name = "bella"
>>> name = "suse"
>>> name = "bella"
>>> print(name)
bella
在计算机的内存中创建一块区域保存字符串"suse",name变量名则指向这块区域。然后又再内存中创建了一块域保存字符串"bella",name变量名则指向"bella"所在的区域,不再指向"suse"所在区域(无人指向的数据会被标记为垃圾,由解释器自动化回收)
情景三
name = "suse"
new_name = name
>>> name = "suse"
>>> new_name = name
>>> print(name)
suse
>>> print(new_name)
suse
在计算机的内存中创建一块区域保存字符串"suse",name变量名则指向这块区域。new_name变量名指向name变量,因为被指向的是变量名,所以自动会转指向到name变量代表的内存区域。
情景四
name = "suse"
new_name = name
name = "bella"
>>> name = "suse"
>>> new_name = name
>>> name = "bella"
>>> print(name)
bella
>>> print(new_name)
suse
在计算机的内存中创建一块区域保存字符串"suse",name变量名则指向这块区域, 然后new_name指向name所指向的内存区域,最后又创建了一块区域存放"bella",让name变量指向"bella"所在区域.
情景五
num = 18
age = str(num)
>>> num = 18
>>> age = str(num)
>>> print(num)
18
>>> print(age)
18
在计算机的内存中创建一块区域保存整型18,name变量名则会指向这块区域。通过类型转换依据整型18再在内存中创建一个字符串"18",age变量指向保存这个字符串的内存区域。
除了变量的内存管理以为还有关于垃圾回收,驻留机制等知识。
6. 注释
写代码时候,如果想要对某写内容进行注释处理,即:解释器忽略不会按照代码去运行。
-
单行注释
注意:快捷键 command + ? 、 control + ? -
多行注释
# #号注释 # 声明一个name变量 # 声明一个name变量 name = "Bella" """ 三个双引号 多行注释内容 多行注释内容 """ age = 19 ''' 三个单引号 多行注释 '''
7. 输入
输入,可以实现程序和用户之间的交互。
# 1.右边 input("请输出用户名:") 使用用户输入内容
# 2.将用户输入的内容赋值给name变量
name = input("请输入用户名:")
if name == "bella":
print("登录成功")
else:
print("登录失败")
# 将输入复制给变量,然后输出
data = input(">>>")
print(data)
特别注意: 用户输入的任何内容本质上都是字符串。
1.提示输入姓名,然后给姓名后面拼接一个“烧饼”,提示输入姓名,然后给姓名后面拼接一个“烧饼”,最终打印结果。
name = input("请输入用户名:")
test = name + "烧饼"
print(test)
2.提示输入 姓名/位置/行为,然后做拼接并打印:xx 在 xx 做 xx 。
name = input("请输入用户名:")
address = input("请输入位置:")
action = input("请输入行为:")
text = name + "在" + address + action
print(text)
3.提示输入两个数字,计算两个数的和。
number1 = input("请输入一个数字:") # "1"
number2 = input("请输入一个数字:") # "2"
value = int(number1) + int(number2)
print(value)
8.条件语句
if 条件 :
条件成立之后的代码...
条件成立之后的代码...
条件成立之后的代码...
else:
条件不成立之后执行的代码...
条件不成立之后执行的代码...
条件不成立之后执行的代码...
name = input("请输入用户名:")
if name == "bella":
print("sb")
else:
print("good")
统一缩进,使用四个空格或者tab。
8.1 基本条件语句
-
示例1
print("开始") if True: print("123") else: print("456") print("结束") -
示例2
print("开始") if 5==5: print("123") else: print("456") print("结束") -
示例3
num = 10 if mum > 10: print("num变量对应值大于10") else: print("num变量对应值小于10") -
示例4
usename = "huitailang" password = "888" if username == "huitailang" and password == "888": print("恭喜,登录成功") else: print("登录失败") -
示例5
usename = "xiyangyang" if usename == "xiyangyang" or username == "lanyangyang": print("羊村大会员") else: print("普通用户") -
示例6
number = 19 if number%2 == 1: print("number是奇数") else: print("number是偶数")number = 19 data = number%2 == 1 if data: print("number是奇数") else: print("number是偶数") -
示例7
if 条件: 成立print("开始") if 5 == 5: print("5等于5") print("结束")
8.2 多条件判断
if 条件A:
A成立,执行此缩进中的所有代码
...
elif 条件B:
B成立,执行此缩进中的所有代码
...
elif 条件C:
C成立,执行此缩进中的所有代码
...
else:
上述ABC都不成立。
num = input("请输入数字")
data = int(num)
if data>6:
print("太大了")
elif data == 6:
print("刚刚好")
else:
print("太小了")
score = input("请输入分数")
data = int(score)
if data > 90:
print("优")
elif data > 80:
print("良")
elif data > 70:
print("中")
elif data > 60:
print("差")
else:
print("不及格")
8.3条件嵌套
if 条件A:
if 条件A1:
...
else:
...
elif 条件B:
...
模拟10086客服
print("欢迎致电10086,我们提供了如下服务:1.话费相关;2.业务办理;3.人工服务")
choice = input("请选择服务序号:")
if choice == "1":
print("话费相关业务")
cost = input("查询话费请按1;交话费请按2")
if cost == "1"
print("查询话费余额为100")
elif cost == "2":
print("交话费")
else:
print("输入错误")
elif choice == "2":
print("业务办理")
elif choice == "3":
print("人工服务")
else:
print("序号输入错误")
优化
score = input("请输入一个数字:")
data = int(score)
if 90 <= data <= 100:
print("A")
elif 80 <= data <= 89:
print("B")
elif 60 <= data <= 79:
print("C")
elif 40 <= data <= 59:
print("D")
elif 0 <= data <=39:
print("E")
else:
print("输入错误")
day3 python基础
1. 循环语句
- while循环
- for循环
while 添加:
...
...
...
print("123")
while 条件:
...
...
...
print(456)
1.1循环语句基本使用
示例1:
print("开始")
while True:
print("你是最棒的")
print("结束")
# 输出:
开始
你是最棒的
你是最棒的
...
示例2:
print("开始")
while 1 > 2:
print("如果祖国遭受到侵犯,热血男儿当自强。")
print("结束")
# 输出:
开始
结束
示例3:
data = True
print("开始")
while data:
print("如果祖国遭受到侵犯,热血男儿当自强。")
print("结束")
# 输出:
开始
如果祖国遭受到侵犯,热血男儿当自强。
如果祖国遭受到侵犯,热血男儿当自强。
如果祖国遭受到侵犯,热血男儿当自强。
...
示例4:
print("开始")
flag = True
while flag:
print("滚滚黄河,滔滔长江。")
flag = False
print("结束")
# 输出:
开始
滚滚黄河,滔滔长江。
结束
示例5:
print("开始")
num = 1
while num < 3:
print("滚滚黄河,滔滔长江。")
num = 5
print("结束")
# 输出:
开始
滚滚黄河,滔滔长江。
结束
示例6:
print("开始")
num = 1
while num < 5:
print("给我生命,给我力量。")
num = num + 1
print("结束")
# 输出:
开始
给我生命,给我力量。
给我生命,给我力量。
给我生命,给我力量。
给我生命,给我力量。
结束
练习题:重复3次输出我爱我的祖国。
num = 1
while num < 4:
print("我爱我的祖国")
num = num + 1
我爱我的祖国
我爱我的祖国
我爱我的祖国
1.2 综合小案例
请实现一个用户登录系统,如果密码错误则反复提示让用户重新输入,直到输入正确才停止。
print("系统运行开始")
flag = True
while flag:
user = input("请输入用户名:")
pwd = input("请输入登录密码:")
if user == "xxx" and pwd == "1":
print("登录成功")
flag = False
else:
print("用户或密码错误")
print("系统运行结束")
1.3 break
break,用于在while循环中终止循环
print("开始")
while True:
print("1")
break
print("2")
print("结束")
# 输出
开始
1
结束
示例:
print("开始运行系统")
while True:
user = input("请输入用户名:")
pwd = input("请输入密码:")
if user == "Bella" and pwd == "suse":
print("登录成功")
break
else:
print("用户或密码错误,请重新登录")
print("系统结束")
想要结束循环可以通过两种方式实现:1.条件判读 2.break关键字 两种在使用时无好坏之分,只要能实现功能就行。
1.4 continue
在循环中用于结束本次循环,开始下一次循环
print("开始")
while True:
print(1)
continue
print(2)
print(3)
print("结束")
开始
1
1
...
示例1:
print("开始")
i = 1
while i < 101:
if i == 7:
i = i + 1
continue
print(i)
i = i + 1
print("结束")
示例2:
print("开始")
i = 1
while True:
if i == 7:
i = i + 2
continue # 结束当前循环
print(i)
i = i + 1
if i == 20:
break # 终止循环
print("结束")
# 输出
开始
1
2
3
4
5
6
9
10
...
19
对于break和continue都是放在循环语句中用于控制循环过程的,一旦遇到break就停止所有循环,一旦遇到continue就停止本次循环,开始下次循环。有了break 和 continue可以在一定程度上简化我们的代码逻辑。
1.5 while else
当while后的条件不成立时,else中的代码就会执行。
while 条件:
代码
else:
代码
while False:
pass
else:
print(12345)
while True:
print(123)
break
else:
print(666)
# 输出
123
2.字符串格式化
字符串格式化,使用更便捷的形式实现字符串的拼接。
2.1 % 百分号
2.1.1 基本格式化操作
name = "佩奇"
# 占位符
# text = "我叫%s,今年18岁" %"佩奇"
text = "我叫%s,今年18岁" %name
name = "佩奇"
age = 18
# text = "我叫%s,今年%s岁" %("佩奇",18)
# text = "我叫%s,今年%s岁" %(name,age)
text = "我叫%s,今年%d岁" %(name,age)
其他占位符
https://www.cnblogs.com/peiqi/articles/5484747.html
message = "%(name)s你什么时候过来呀?%(user)s今天不在呀。" % {"name": "死鬼", "user": "喜洋洋"}
print(message)
2.1.2 百分比
text = "兄弟,这个片我已经下载了90%了,居然特么的断网了"
print(text)
text = "%s,这个片我已经下载了90%%了,居然特么的断网了" %"兄弟"
print(text)
# 输出:
兄弟,这个片我已经下载了90%了,居然特么的断网了
一旦字符串格式化中存在百分比的显示,请一定要加 %% 以实现输出 %。
2.2 format<推荐>
text = "我叫{0},今年18岁".format("佩奇")
text = "我叫{0},今年{1}岁".format("佩奇",18)
text = "我叫{0},今年{1}岁,真实的姓名是{0}。".format("佩奇",18)
text = "我叫{},今年18岁".format("佩奇")
text = "我叫{},今年{}岁".format("佩奇",18)
text = "我叫{},今年{}岁,真是的姓名是{}。".format("佩奇",18,"佩奇")
text = "我叫{n1},今年18岁".format(n1="佩奇")
text = "我叫{n1},今年{age}岁".format(n1="佩奇",age=18)
text = "我叫{n1},今年{age}岁,真是的姓名是{n1}。".format(n1="佩奇",age=18)
text = "我叫{0},今年{1}岁"
data1 = text.format("佩奇",666)
data2 = text.format("贝拉",73)
text = "我叫%s,今年%d岁"
data1 = text %("佩奇",20)
data2 = text %("贝拉",84)
2.3 f (python3.6+)
到Python3.6版本,更便捷。
text = f"嫂子喜欢{'跑步'},跑完之后满身大汗"
action = "跑步"
text = f"嫂子喜欢{action},跑完之后满身大汗"
name = "喵喵"
age = 19
text = f"嫂子的名字叫{name},今年{age}岁"
print(text)
# 用的较多的模式
text = f"嫂子的名字叫喵喵,今年{19 + 2}岁"
print(text)
# 在Python3.8引入
text = f"嫂子的名字叫喵喵,今年{19 + 2=}岁"
print(text)
# 输出
嫂子的名字叫喵喵,今年19 + 2=21岁
# 进制转换
v1 = f"嫂子今年{22}岁"
print(v1)
v2 = f"嫂子今年{22:#b}岁"
print(v2)
v3 = f"嫂子今年{22:#o}岁"
print(v3)
v4 = f"嫂子今年{22:#x}岁"
print(v4)
# 理解
text = f"我是{'Bella'},我爱大铁锤"
name = "Bella"
text = f"我是{name},我爱大铁锤"
name = "BELLA"
text = f"我是{ name.upper() },我爱大铁锤"
# 输出:我是Bella,我爱大铁锤
# .upper() 将name的值变成大写 .capitaliza() 首字母大写
3.运算符
写代码时常见的运算符可以分为5种:
- 算数运算符,例如:加减乘除

# 整除
print( 9//2 )
输出:
4
-
比较运算符,例如:大于,小于

注意:python3中不支持
<> -
赋值运算,例如:变量赋值

num = 1 while num < 100: print(num) # num = num + 1 等价 num += 1 num += 1 -
成员运算,例如:是否包含

v1 = "Be" in "Bella" # True/False # 让用户输入一段文本,检测文本是否包含敏感词 text = input("请输入内容: ") if "苍老师" in text: print("少儿不宜") else: print(text) -
逻辑运算,例如:且或非
计算前,or和and会将值先转换为bool值再来判断True 与 False。

data = 1 > 2
if not data:
print(data)
3.1 运算符优先级
-
算数优先级 大于 比较运算符
if 2 + 10 > 11: print("真") else: print("假") -
比较运算优先级 大于 逻辑运算符
if 1 > 2 and 2 < 10: print("成立") else: print("不成立") -
逻辑运算符内部三个优先级 not > and > or
if not and 1 > 2 or 3 == 8: print("真") else: print("假")
上述这三个优先级从高到底总结:加减乘除 > 比较 >not and or 可以通过加括号改变优先级,括号优先级最高。
# or,看第一个值,如果第一个值为真,结果就应该是第一个值,否则就结果就是第二个值。
# and,看第一个值,如果第一个值为真,结果就应该是第二个值,否则结果就是第一个值。
# 如果多个and和or的情况,先计算and再计算or
作业练习
-
实现用户登录系统,并且要支持连续三次输错之后直接退出,并且在每次输错误时显示剩余错误次数(提示:使⽤字符串格式化)。
count = 1 limit = 3 while count <= 3: usename = input("请输入用户名:") pwd = input("请输入密码:") if usename == "dave" and pwd == "888": print("登录成功") break else: print("用户或密码错误") count += 1 limit -= 1 text = "剩余{}次".format(limit) print(text) # 老师的第二种解法 count = 0 while count < 3: count += 1 user = input("请输入用户名:") pwd = input("请输入密码:") if user == "dave" and pwd == "123": print("成功") break else: message = "用户名或者密码错误,剩余错误次数为{}次".format(3 - count) print(message) count = 3 while count > 0: count -= 1 user = input("请输入用户名:") pwd = input("请输入密码:") if user == "dave" and pwd == "123": print("成功") break else: message = "用户名或者密码错误,剩余错误次数为{}次".format(count) print(message) -
猜年龄游戏
要求:允许用户最多尝试3次,3次都没猜对的话,就直接退出,如果猜对了,打印恭喜信息并退出。count = 1 while count < 4: year = input("请输入一个数:") if int(year) == 18: print("bingo") break else: print("猜错了!") count += 1 -
猜年龄游戏升级版
要求:允许用户最多尝试3次,每尝试3次后,如果还没猜对,就问用户是否还想继续玩,如果回答Y,就继续让其猜3次,以此往复,如果回答N,就退出程序,如果猜对了,就直接退出。count = 1 while count < 4: year = input("请输入一个数:") if int(year) == 18: print("bingo") break else: print("猜错了!") count += 1 if count == 4: agen = input("是否继续游戏(Y/N)?:") if agen == "N": break elif agen == "Y": count = 1 else: print("输出错误,gameover!") break print("程序结束")
day04 进制与编码
1.python代码运行方式
- 脚本式
- 交互式
2.进制
-
二进制
逢二进一
0 1 10 -
八进制
-
十进制
-
十六进制
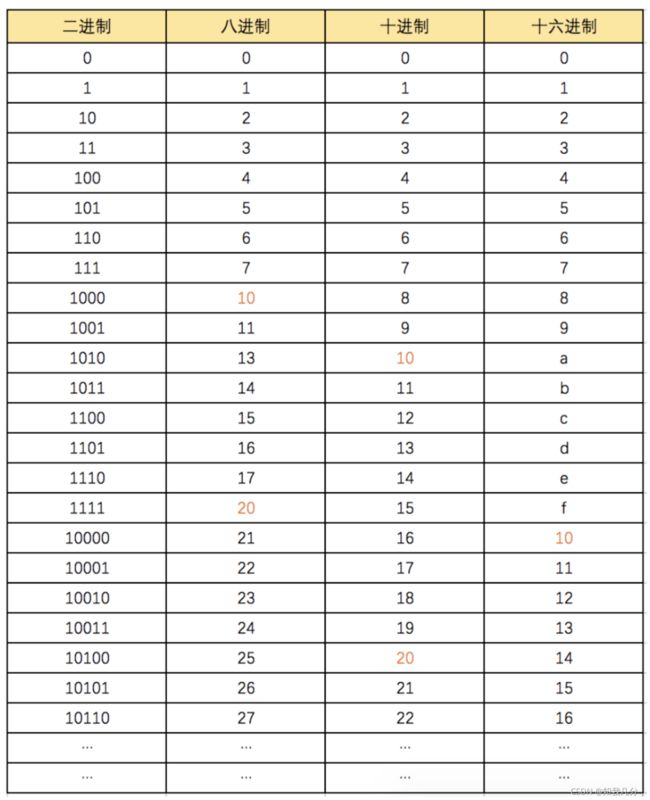
2.1进制转换
二八十六进制直接无法直接转换,必须通过十进制互相转换。
v1 = bin(25) # 十进制转为二进制
print(v1) # "0b110011"
v2 = oct(23) # 十进制转换为八进制
print(v2) # "0o27"
v3 = hex(28) # 十进制转为十六进制
print(v3) # "0x1c"
i1 = int("0b11001",base=2) # 25
i2 = int("0o27",base=8) # 23
i3 = int("0x1c",base=16) # 28
3.计算机中的单位
-
b(bit),位
1 1位 10 2位 111 3位 1001 四位 -
B (byte),字节
8位是一个字节 10010110 1个字节 10010110 10010110 2个字节 -
KB (kilobyte),千字节
1024 个字节就是1个千字节 1kb = 1024B = 1024 * 8b -
M (Megabyte),兆
1024KB 就是1M 1M = 1024KB =1024 * 1024B = 1024 * 1024 * 8b -
G (Gigabyte),千兆
1024M 就是1G 1G = 1024M = 1024 * 1024 KB = 1024 * 1024 * 1024B = 1024 * 1024 * 1024 * 8b -
T (Terabyte),万亿字节
1024G 就是 1T -
…其他更大的单位PB/EB/ZB/YB/BB/NB/DB 依次以1024进制类推
4. 编码
4.1 ASCII编码
ASCII规定使用1个字节来表示字母与二进制的对应关系,共2**8 = 256种
https://www.asciitable.com/


4.2 gb-2312编码
gb-2312编码,由国家信息标准委员会制作(1980年)。
gbk编码,对gb2312进行扩展,包含了中日韩等文字(1995年)。
在与二进制做对应关系时,有如下逻辑:
- 单字节表示,用一个字节表示对应关系。2**8 = 256
- 双字节表示,用两个字节表示对应关系。2**16 = 65536中可能性。
4.3 Unicode
Unicode也被称为万国码,为全球的每个文字都分配了一个码位(二进制表示)。https://unicode-table.com/en/blocks/
-
ucs2
用固定的2个字节去表示一个文字。 00000000 00000000 悟 ... 2**16 = 65535 -
ucs4
用固定的4个字节去表示一个文字。 00000000 00000000 00000000 00000000 无 ... 2**32 = 4294967296文字 十六进制 二进制 ȧ 0227 1000100111 ȧ 0227 00000010 00100111 ucs2 ȧ 0227 00000000 00000000 00000010 00100111 ucs4 # 位数不够,拿来来凑,向下包含 乔 4E54 100111001010100 乔 4E54 01001110 01010100 ucs2 乔 4E54 00000000 00000000 01001110 01010100 ucs4 1F606 11111011000000110 1F606 00000000 00000001 11110110 00000110 ucs4
无论是ucs2还是ucs4都有缺点:浪费空间
文字 十六进制 二进制
A 0041 01000001
A 0041 00000000 01000001
A 0041 00000000 00000000 00000000 01000001
Unicode的应用:在文件存储和网络传输时,不会直接使用Unicode,而在内存中会用Unicode
4.4 utf-8编码
包含所有文件和二进制的对应关系,全球应用最为广泛的一种编码。
本质上:utf-8是对Unicode的压缩,用尽量少的二进制去与文字进行对应。
unicode码位范围 utf-8
0000 ~ 007F 用1个字节表示
0080 ~ 07FF 用2个字节表示
0800 ~ FFFF 用3个字节表示
10000 ~ 10FFFF 用4个字节表示
具体压缩的流程:
-
第一步:选择转换模板
码位范围(十六进制) 转换模板 0000 ~ 007F 0XXXXXXX 0080 ~ 07FF 110XXXXX 10XXXXXX 0800 ~ FFFF 1110XXXX 10XXXXXX 10XXXXXX 10000 ~ 10FFFF 11110XXX 10XXXXXX 10XXXXXX 10XXXXXX 例如: "B" 对应的unicode码位为 0042,那么他应该选择的一个模板。 "ǣ" 对应的unicode码位为 01E3,则应该选择第二个模板。 "小" 对应的unicode码位为 6B66,则应该选择第三个模板。 "佩" 对应的unicode码位为 6C9B,则应该选择第三个模板。 "齐" 对应的unicode码位为 9F50,则应该选择第三个模板。 对应的unicode码位为 1F606,则应该选择第四个模板。 注意:一般中文都使用第三个模板(3个字节),这也就是平时大家说中文在utf-8中会占3个字节的原因了。 -
第二步:在模板中填入数据
- "小" -> 6B66 -> 110 101101 100110 - 根据模板去套入数据 1110XXXX 10XXXXXX 10XXXXXX 1110XXXX 10XXXXXX 10100110 1110XXXX 10101101 10100110 11100110 10101101 10100110 在UTF-8编码中 ”小“ 11100110 10101101 10100110 - -> 1F606 -> 11111 011000 000110 - 根据模板去套入数据 11110000 10011111 10011000 10000110
4.5 Python相关的编码
字符串(str) "Bella媳妇叫铁锤" unicode处理 一般在内存
字节(byte) b"markfdsfdsdfskdfsd" utf-8编码 or gbk编码 一般用于文件或网络处理
v1 = "小"
v2 = "小".encode("utf-8")
v2 = "小".encode("gbk")
将一个字符串写入到一个文件中。
name = "嫂子热的满身大汗"
data = name.encode("utf-8")
# 打开一个文件
file_object = open("log.txt",mode="wb")
# 在文件中写内容
file_object.write(data)
# 关闭文件
file_object.close()
总结
本章的知识点属于理解为主,了解这些基础之后有利于后面知识点的学习,接下来对本节所有的知识点进行归纳总结:
-
计算机上所有的东西最终都会转换成为二进制再去运行。
-
ascii编码、unicode字符集、utf-8编码本质上都是字符与二进制的关系。
- ascii,字符和二进制的对照表。
- unicode,字符和二进制(码位)的对照表。
- utf-8,对unicode字符集的码位进行压缩处理,间接也维护了字符和二进制的对照表。
-
ucs2和ucs4指的是使用多少个字节来表示unicode字符集的码位。
-
目前最广泛的编码为:utf-8,他可以表示所有的字符且存储或网络传输也不会浪费资源(对码位进行压缩了)。
-
二进制、八进制、十进制、十六进制其实就是进位的时机不同。
-
基于Python实现二进制、八进制、十进制、十六进制之间的转换。
-
一个字节8位
-
计算机中常见单位b/B/KB/M/G的关系。
-
汉字,用gbk编码需要用2个字节;用utf-8编码需要用3个字节。
-
基于Python实现将字符串转换为字节(utf-8编码)
# 字符串类型 name = "小佩齐" print(name) # 小佩齐 # 字符串转换为字节类型 data = name.encode("utf-8") print(data) # b'\xd0\xa1\xc5\xe5\xc6\xeb' # 把字节转换为字符串 old = data.decode("utf-8") print(old) -
基于Python实现将字符串转换为字节(gbk编码)
# 字符串类型 name = "小佩齐" print(name) # 小佩齐 # 字符串转换为字节类型 1.utf-8 data = name.encode("utf-8") print(data) # b'\xe5\xb0\x8f\xe4\xbd\xa9\xe9\xbd\x90' utf8,中文3个字节 2.gbk data = name.encode("gbk") print(data) # b'\xd0\xa1\xc5\xe5\xc6\xeb' gbk,中文2个字节 # 把字节转换为字符串 old = data.decode("gbk") print(old)
day05 – 数据类型(上)
常见的数据类型:
- int ,整数类型,整型
- bool,布尔类型
- str,字符串类型
- list,列表类型
- tuple,元组类型
- dict,集合类型
- float,浮点数类型,浮点型
每种数据类型都有自己的特定以及应用场景,以后的开发中需要根据实际的开发取卡选择合适的数据类型。
int类型
v1 = 123
v2 = 666
bool类型
v1 = True
v2 = False
str类型
v1 = python
v2 = golang
list类型
v1 = [11, 22, 33]
v2 = [c, c++, java, bash]
dict类型
v1 = ["k1":1, "k2":2]
v2 = ["name": python, "age":18]
key:value类型
每种数据类型的讲解,会按照以下四个维度来进行:
- 定义
- 独有功能
- 公共功能
- 类型转换
- 其他
1.整型
整型其实就是十进制整数的统称,比如:1,888,999 等都属于整型,一般用于表示年龄,序号等。
1.1定义
number = 10
age = 99
1.2独有功能
无
v1 = 5
print(bin(v1)) # 0b101
# 调用v1(int)的都有功能,获取v1的二进制有多少个位组成。
result1 = v1.bit_length()
print(result1) # 3
v2 = 10
print(bin(10)) # 0b1010
# 调用v2(int)的独有功能,获取v2的二进制有多少个位组成
result2 = v2.bit_length()
print(result2) # 4
1.3公共功能
加减乘除
v1 = 4
v2 = 8
v3 = v1 + v2
1.4转换
在项目开发和面试中经常会出现一些 “字符串” 和 布尔值 转换为 整型的情况。
# 布尔值转整型
n1 = int(True) # True转换为整数1
n2 = int(False) # False转换为整数0
# 字符串转整型
v1 = int("186",base=10) # 把字符串看成十进制的值,然后转换为十进制整数,结果:v1 = 186
v2 = int("0b1001",base=2) # 把字符串看成二进制的值,然后再转换为十进制整数,结果:v2 = 9(0b表示二进制)
v3 = int("0o144",base=8) # 把字符串看成八进制的值,然后转换为十进制整数,结果:v3 = 100 (0o表示八进制)
v4 = int("0x59",base=16) #把字符串看成十六进制的值,然后转换为十进制整数,结果为:v4 = 89 (0x表示十六进制)
# 浮点数(小数)
v5 = int(8.7) # 8
1.5 其他
1.5.1 长整型
- python3:整型(无限制)
- python2:整型,长整型
在python2中跟整数相关的数据类型有两种:int(整型),long(长整型),他们都是整数只不过能表示的值范围不同
>>> v1 = 9223372036854775807
>>> v1
9223372036854775807 # int 类型
>>>
>>> v2 = 9223372036854775808
>>> v2
9223372036854775808L # long类型(都以L结尾)
- int,可表示的范围: -9223372036854775808 - 9223372036854775807
- log,整数值超出int范围之后会自动转换为long类型,无限制。
1.5.2 地板除
-
py3
v1 = 9/2 print(v1) # 4.5 -
py2
v1 = 9/2 print(v1) # 4 from __future__import division v1 = 9/2 print(v1) #4.5
2.布尔类型
布尔值,不是真True,就是False
2.1 定义
data = False
mark_is_sb = True
2.2 独有功能
无
2.3公共功能
无
v1 = True + True
print(v1) #2
2.4. 转换
在以后的项目开发中。会经常使用其他类型转换为布尔值的情况,此处只需要记住一个规律即可
整数0,空字符串,空列表,空元组,空字典转换为布尔值时均为False
其他均为True
2.5其他
2.5.1 做条件自动转换
如果在if ,while条件后写一个值当做条件时,他会默认转换为布尔类型,然后在做条件判断
if 0:
print("太六了")
else:
print(999)
if "小猪佩奇":
print("你好")
if "羊村":
print("你是lyy?")
else:
print("你是htl?")
while 1>9:
pass
if 值:
pass
while 值:
pass
3.字符串类型
字符串,我们平时会用他来表示文本信息,例如:姓名,地址,自我介绍等
3.1定义
v1 = "勤治百病"
v2 = '勤治百病'
v3 = "勤'治百病"
v4 = '勤"治百病'
v5 = """
一勤除百弊,
终生学习尓。
人生苦短,
我学python。
"""
# 三个引号,可以支持多行/换行 表示一个 字符串,其他的都只能在 一行中 表示一个字符串。
3.2独有功能 (常用18/总计48)
基本执行格式1:
"xxxxx".功能(...)
基本执行格式2:
v1 = "xxxx"
v1.功能(...)
1.判断字符串是否以xxx开头?得到一个布尔值
v1 = "只要学不死,就往死里学"
# True
result = v1.startswith("只要学不死")
print(result) # 值为True
# 案例
v1 = input("请输入住址:")
if v1.startswith("北京市"):
print("北京人口")
else:
print("非北京人口")
2.判断字符串是否以 xxx 结尾?得到一个布尔值
v1 = "学习使我快乐"
result = v1.endswith("快乐")
print(result) # 值为True
# 案例
address = input("请输入地址:")
if address.endswith("村"):
print("农村户口")
else:
print("非农村户口")
3.判断字符串是否为十进制数?得到一个布尔值
v1 = "1238871"
result = v1.isdecimal()
print(result) # True
# 案例,两个数相加
v1 = input("请输入值:") # "666"
v2 = input("请输入值:") # "999"
if v1.isdecimal() and v2.isdecimal():
data = int(v1) + int(v2)
print(data)
else:
print("请正确输入数字")
v1 = "123"
print(v1.isdecimal()) # True
v2 = "①"
print(v2.isdecimal()) # False
v3 = "123"
print(v3.isdigit()) # True
v4 = "①"
print(v4.isdigit()) # True
4.默认去除字符串两边的空格,换行符,制表符,得到一个新字符串
data = input("请输入内容:") # 佩奇,佩奇 # 可能会存在空格
print(data)
msg = " H e ll o啊,树哥 "
data = msg.strip()
print(data) #将msg两边的空白去掉,
得到 "H e ll o啊,树哥"
msg = " H e ll o啊,树哥 "
data = msg.lstrip()
print(data) # 将msg左边(前面)的空白去掉,得到 "H e ll o啊,树哥 "
msg = " H e ll o啊,树哥 "
data = msg.rstrip()
print(data) # 将msg右边(后边)的空白去掉,得到 " H e ll o啊,树哥"
4.1 去除空格,换行符\n,制表符\t
# 案例
code = input("请输入4位验证码:") # FB87
data = code.strip()
if data == "FB87":
print('验证码正确')
else:
print("验证码错误")
4.2 去除字符串两边指定的内容
msg = "哥H e ll o啊,树哥"
data = msg.strip("哥")
print(data) # 将 两边的"哥" 去掉,得到"H e ll o啊,树"
msg = "哥H e ll o啊,树哥"
data = msg.lstrip("哥")
print(data) # 将msg 左边的 "哥" 去掉,得到 "H e ll o啊,树哥"
msg = "哥H e ll o啊,树哥"
data = msg.rstrip("哥")
print(data) # 将msg右边的 "哥" 去掉,得到"哥H e ll o啊,树"
5.字符串变大写,得到一个新字符串
msg = "my name is dave"
data = msg.upper()
print(msg) # 输出:my name is dave
print(data) # 输出为:"MY NAME IS DAVE"
# 案例
code = input("请输入四位验证码:") # FB87 fb87
value = code.upper() # FB87
data = value.strip() # FB87
if data == "FB87":
print('验证码正确')
else:
print('验证码错误')
# 注意事项
"""
code的值"fb88 "
value的值"FB88 "
data的值"FB88"
"""
6.字符串变小写,得到一个新字符串
msg = "My Name Is Dave"
data = msg.lower()
print(data) # 输出为:my name is dave
# 案例
code = input("请输入4位验证码:")
value = code.strip().lower()
if value == "fb87":
print("验证码正确")
else:
print("验证码错误")
7.字符串内容替换,得到一个新的字符串
data = "人生苦短,我学python"
value = data.replace("python","golang")
print(data) # 人生苦短,我学python
print(value) # 人生苦短,我学golang
# 案例
video_file_name = "高清无码爱情片.mp4"
new_file_name = video_file_name.replace("mp4","avi") # "高清无码爱情片.avi"
final_file_name = new_file_name.replace("爱情","文艺") # "高清无码文艺片.avi"
print(final_file_name)
# 案例
video_file_name = "高清无码爱情动作片.mp4"
new_file_name = video_file_name.replace("mp4","avi") # "高清无码爱情动作片.avi"
final_file_name = video_file_name.replace("爱情","武打") # "高清无码武打动作片.mp4"
print(final_file_name)
#
# 案例
content = input("请输入评论信息") # python是最好的语言
content = content.replace("python","php") # php是最好的语言
content = content.replace("好","美") # php是最美的语言
print(content) # php是最美的语言
char_list = ["尼玛", "你大爷", "扯淡", "滚犊子"]
content = input("请输入评论信息:")
for item in char_list:
content = content.replace(item,"**")
print(content)
8.字符串切割,得到一个列表
data = "佩奇|root|[email protected]"
result = data.split('|') # ["佩奇", "root", "[email protected]"]
print(data) # "佩奇|root|[email protected]"
print(result) # 输出 ["佩奇","root","[email protected]"] 根据特定字符切开之后保存在列表中,方便以后的操作
# 案例:判断用户名密码是否正确
info = "佩奇,root" # 备注:字符串中存储了用户名和密码
user_list = info.split(',') # 得到一个包含了2个元素的列表 [ "佩奇" , "root" ]
# user_list[0]
# user_list[1]
user = input("请输入用户名:")
pwd = input("请输入密码:")
if user == user_list[0] and pwd == user_list[1]:
print("登录成功")
else:
print("用户名或密码错误")
8.1 data.split("|", 1) 括号中的1代表 从左至右切1次
data = "佩奇|root|[email protected]"
v1 = data.split("|") # ['佩奇', 'root', '[email protected]']
print(v1)
v2 = data.split("|", 1) # ['佩奇', 'root|[email protected]']
print(v2)
# data.split("|", 2) 括号中的2代表 从左至右切2次,还剩余一个所以结果一样
v3 = data.split("|", 2) # ['佩奇', 'root', '[email protected]']
print(v3)
8.2 split表示从从左至右,rsplit表示从右至左
data = "佩奇,root,[email protected]"
v1 = data.rsplit(',')
print(v1) # ['佩奇', 'root', '[email protected]']
v2 = data.rsplit(',',1)
print(v2) # ['佩奇,root', '[email protected]']
应用场景
file_path = "xxx/xxxx/xx.xx/xxx.mp4"
data_list = file_path.rsplit('.',1)
data_list[0]
data_list[1]
print(data_list[0])
print(data_list[1])
# 输出:
xxx/xxxx/xx.xx/xxx
mp4
9.字符串拼接,得到一个新的字符串
data_list = ["suse","is","verygood"]
v1 = "_".join(data_list)
print(v1) # suse_is_verygood
data_list = ["suse","is","verygood"]
v1 = "@@##".join(data_list)
print(v1) # suse@@##is@@##verygood
10.格式化字符串,得到新的字符串
name = "{0}喜欢学习很多种编程语言,例如有:{1},{2} 等"
data = name.format("小明","Java","python")
print(date) # 小明喜欢学习很多种编程语言,例如有:Java,python 等
print(name) # {0}喜欢学习很多种编程语言,例如有:{1},{2} 等
name = "{}喜欢学习很多种编程语言,例如有:{},{} 等"
data = name.format("老王","golang","C++")
print(data) # 老王喜欢学习很多种编程语言,例如有:golang,C++ 等
name = "{name}喜欢的编程语言有很多种,;例如:{h1},{h2}等"
data = name.format(name="老王",h1="C#",h2="php")
print(data) # 老王喜欢的编程语言有很多种,;例如:C#,php等
11.字符串转换为字节类型
data = "饺子" # Unicode 字符串类型
v1 = data.encode("utf-8") # utf-8,字节类型
v2 = data.encode("gbk") # gbk,字节类型
print(v1) # b'\xe9\xa5\xba\xe5\xad\x90'
print(v2) # b'\xbd\xc8\xd7\xd3'
# 转回 Unicode
s1 = v1.decode("utf-8") # 饺子
s2 = v2.decode("gbk") # 饺子
print(s1)
print(s2)
12.将字符串内容居中,居左,居右展示
v1 = "kubernetes"
data = v1.center(21,"-")
print(data) # ------kubernetes-----
data = v1.ljust(21,"*")
print(data) # kubernetes***********
data = v1.rjust(21,"$")
print(data) # $$$$$$$$$$$kubernetes
13.填充0
data = "dave"
v1 = data.zfill(10)
print(v1) # 000000dave
# 应用场景:处理二进制数据
data = "101" # 00000101
v1 = data.zfill(8)
print(v1) # 00000101
查看其他独有功能的方法
1.在pycharm上输入 str
2.Ctrl + 右击 进入
3.点击 左上角 project 栏目 右边的 设置(show options Menu) 按钮,勾选 show Members
4.点击 设置按钮左边的 定位 图标 select opened file(Alt + F1, 1)
3.3 公共功能
1.相加:字符串 + 字符串
v1 = "k8s" + "docker"
print(v1)
2.相乘:字符串 * 整数
data = "玫瑰" * 3
print(data) # 玫瑰玫瑰玫瑰
3.长度
data = kubernetes
value = len(data)
print(value) # 10
4.获取字符串中的字符,索引
message = "来学习python编程呀"
# 依次对应序号
来 学 习 p y t h o n 编 程 呀
0 1 2 3 4 5 6 7 8 9 10 11
........ -3 -2 -1
print(message[0]) # "来"
print(message[1]) # "学"
print(message[-1]) # "呀"
注意: 字符串中只能通过索引取值,无法修改值。字符串在内部存储时不允许对内部元素修改,想与修改只能重新创建。
message = "来做点py交易呀"
index = 0
while index < len(message):
value = message[index]
print(value)
index += 1
message = "来做点py交易呀"
index = len(message) -1
wile index >= 0:
value = message[index]
print(value)
index -= 1
5.获取字符串中的子序列,切片
message = "来做点py交易呀"
print(message[0:2]) # "来做"
print(message[3:7]) # "py交易"
print( message[3:] ) # "py交易呀"
print( message[:5] ) # "来做点py"
print(message[4:-1]) # "y交易"
print(message[4:-2]) # "y交"
print( message[4:len(message)] ) # "y交易呀"
注意: 字符串的切片只能够读取数据,无法修改数据。字符串在内部存储时不允许对内部元素修改,想要修改只能重新创建。
message = "来做点py交易呀"
value = message[:3] + "Python" + message[5:]
print(value)
6.步长,跳着取字符串的内容
name = "生活不是电影,生活比电影苦"·
print( name[ 0:5:2 ] ) # 输出:生不电 【前两个值表示区间范围,最后一个值表示步长】
print( name[ :8:2 ] ) # 输出:生不电, 【区间范围的前面不写则表示起始范围为0开始】
print( name[ 2::3 ] ) # 输出:不电,活电苦 【区间范围的后面不写则表示结束范围为最后】
print( name[ ::2 ] ) # 输出:生不电,活电苦 【区间范围不写表示整个字符串】
print( name[ 8:1:-1 ] ) # 输出:活生,影电是不 【倒序】
name = "生活不是电影,生活比电影苦"
print(name[8:1:-1]) # 输出:活生,影电是不 【倒序】
print(name[-1:1:-1]) # 输出:苦影电比活生,影电是不 【倒序】
# 面试题:给你一个字符串,请将这个字符串翻转。
value = name[-1::-1]
print(value) # 苦影电比活生,影电是不活生
7.循环
-
while循环
message = "来做点py交易呀" index = 0 while index < len(message): value = message[index] print(value) index += 1 -
for循环
message = "来做点py交易啊" for char in message: print(char) -
range,帮助我们创建一系列的数字
range(10) # [0,1,2,3,4,5,6,7,8,9] range(1,10) # [1,2,3,4,5,6,7,8,9] range(1,10,2) # [1,3,5,7,9] range(10,1,-1) # [10,9,8,7,6,5,4,3,2] -
For + range
for i in range(10): print(i)message = "来学习py编程呀" for i in range(5): print(message[i])message = "来做点py交易呀" for i in range( len(message) ): print(message[i])
一般应用场景:
-
while,一般在做无限制(未知)循环次数时使用。
while True: ...# 用户输入一个值,如果不是整数则一直输入,直到是整数了才结束。 num = 0 while True: data = input("请输入内容:") if data.isdecimal(): num = int(data) break else: print("输入错误,请重新输入!") -
for循环,一般应用在已知的循环数量的场景。
message = "来做点py交易呀" for char in message: print(char)for i in range(30): print(message[i]) -
break和continue关键字
message = "来做点py交易呀" for char in message: if char == "p": continue print(char) # 输出: 来 做 点 y 交 易 呀message = "来做点py交易呀" for char in message: if char == "p": break print(char) # 输出: 来 做 点for i in range(5): print(i)# 0 1 2 3 4 for j in range(3): break print(j) # 0 1 2 # 0 1 2 # 0 1 2 # 0 1 2 # 0 1 2
3.4 转换
num = 999
data = str(num)
print(data) # "999"
data_list = ["kubernetes","k8s","k3s"]
data = str(data_list)
一般情况下,只有整型转字符串才有意义。
3.5 其他
3.5.1 字符串不可被修改
name = "小猪佩奇"
name[1]
name[1:2]
num_list = [11,22,33]
num_list[0]
num_list[0] = 666
总结
- 整型在python2 和 python3 中的区别?
- 进制之间的转换
- 其他类型转换为布尔类型时,空为 0 和 False,其他均为True
- 条件语句中可自动化转换布尔类型来做判断
- 字符串中常见的独有功能
- 字符串中常见的公共功能
- 字符串创建之后是不可以被修改的
day06–数据类型(中)
常见的数据类型:
- int,整型
- bool,布尔类型
- str,字符串类型
- list,列表类型
- tuple,元组类型
- dict,字典类型
- set,集合类型
- float,浮点类型
目标:掌握列表和元组数据类型的各种操作
概要:
- list,列表类型,用于存储一些数据的容器(有序 & 可修改)
- tuple,元组类型,用于存储一些数据的容器(有序 & 不可修改)
1.列表(list)
1.1定义
列表(list),是一个 有序 且 可变的容器,在里面可以存放多个不同类型的元素。
user_list = ["大桥","小乔","西施"]
number_list = [666,888,999,-666]
data_list = [1,True,"武大郎","宝强","贾乃亮"]
user_list = []
user_list.append("昊天锤")
user_list.append(123)
user_list.append(True)
print(user_list) # ["昊天锤",123,True]
不可变类型:字符串,布尔,整型(已最小,内部数据无法进行修改)
可变类型:列表 (内部数据元素可以修改)
1.2 独有功能
python中为所有的列表类型的数据提供了一批独有的功能。
字符串和列表的对比:
-
字符串,不可变,即:创建好之后内部就无法修改。【独有的功能都是新创建一份数据】
name = "mark" data = name.upper() print(name) print(data) -
列表,可变,即:创建之后内部元素可以修改。【独有功能基本都是直接操作列表内部,不会创建新的一份数据】
user_list = ["钻石","玫瑰","巧克力"] user_list.append("MM") print(user_list) # ["钻石","玫瑰","巧克力","MM"]
列表中的常见独有功能如下:
-
追加,在原列表中的尾部追加值。
data_list = [] v1 = input("请输入姓名:") data_list.append(v1) v2 = input("请输入姓名:") data_list.append(v2) print(data_list)# 案例1 user_list = [] while True: user = input("请输入用户名(Q退出):") if user == "Q": break user_list.append(user) print(user_list)# 案例2 welcome = "欢迎使用NB游戏".center(30,"*") print(welcome) user_count = 0 while True: count = input("请输入游戏人数:") if count.isdecimal(): user_count = int(count) break else: print("输入格式错误,人数必须是数字。") message = "{}人参加游戏NB游戏。".format(user_count) print(message) user_name_list = [] for i in range(1,user_count + 1): tips = "请输入玩家姓名({}/{}):".format(i,user_count) name = input(tips) user_name_list.append(name) print(user_name_list) -
批量追加,将一个列表中的元素逐一添加另外一个列表
tools = ["苹果","梨子","橘子"] tools.extend([11,22,33]) #fruits中的值逐一追加到tools中 print(tools) # ["苹果","梨子","橘子",11,22,33]tools = ["菜刀","水果刀","柴刀"] weapon = ["AK47","M6"] # tools.extend(weapon) # weapon 中的值逐一追加到tools中 # print(tools) # ["菜刀","水果刀","柴刀","AK47","M6"] weapon.extend(tools) print(tools) # ["菜刀","水果刀","柴刀"] print(weapon) # ["AK47","M6","菜刀","水果刀","柴刀"]# 等价于(扩展) weapon = ["AK47","M6"] for item in weapon: print(item) # 输出: # AK47 # M6 tools = ["菜刀","水果刀","柴刀"] weapon = ["AK47","M6"] for item in weapon: tools.append(item) print(tools) # ['菜刀', '水果刀', '柴刀', 'AK47', 'M6'] -
插入,在原列表的指定索引位置插入值
user_list = ["a","b","c"] user_list.insert(0,"x") user_list.insert(2,"y") print(user_list) # ['x', 'a', 'y', 'b', 'c']# 案例 name_list = [] while True: name = input("请输入购买火车票用户姓名(Q/q退出):") if name.upper() == "Q": break if name.startswith("刁"): name_list.insert(0,name) else: name_list.append(name) print(name_list) # 注意: 1.inset(0,name)如果符合条件,每次都会插入到索引0这个位置,如果不符合则按顺序插入到最后。 2.当索引小最前面的0时,永远放在最前面,如果大于整体长度的索引,不管大多数都会被插入到最后面的位置。即使索引不存在也不会报错。 -
在原列表中根据值删除(从左到右找到第一个删除) 【慎用,里面没有则会报错。
user_list = ["宝强","羽凡","mark","乃亮","mark"] user_list.remove("mark") print(user_list) # 加个判断,防止不存在的时候报错 user_list = ["宝强","羽凡","mark","乃亮","mark"] if "mark" in user_list: user_list.remove("mark") print(user_list) # 由于只能删除从左至右的第一个,使用while循环可以删除多个 user_list = ["宝强","羽凡","mark","乃亮","mark"] while True: if "mark" in user_list: user_list.remove("mark") else: break print(user_list)# 案例:自动抽奖程序 import random # 导入随机模块 data_list = ["iphone13","充气娃娃","大保健一次","泰国三日游","绿水鬼"] while data_list: # data_list中有值则为True,会一直循环,直至空列表为False结束循环 name = input("自动抽奖程序,请输入自己的姓名:") # 随机从data_list抽取一个值出来 value = random.choice(data_list) # '绿水鬼' choice print( "恭喜{},抽中{}.".format(name,value) ) data_list.remove(value) # 剔除被抽中的奖品 -
在原列表中根据索引剔除某个元素(根据索引位置删除)
user_list = ["宝强","羽凡","mark","乃亮","mark"] # 0 1 2 3 4 # 根据索引进行删除 user_list.pop(1) print(user_list) # ['宝强', 'mark', '乃亮', 'mark'] # 不加索引,默认删除最后一个 user_list.pop() # 不加索引,默认删除最后一个 print(user_list) # ['宝强', 'mark', '乃亮'] # 不但删除并获取到删除的值 item = user_list.pop(1) print(item) # mark print(user_list) # ['宝强', '乃亮']# 案例,排队买火车票 # ["a","b","c","d","e","f"] user_queue = [] while True: name = input("北京~上海火车票,购买请输入姓名排队(Q退出):") if name == "Q": break user_queue.append(name) ticket_count = 3 for i in range(ticket_count): username = user_queue.pop(0) message = "恭喜{},购买火车票成功。".format(username) print(message) # user_queue = ["a","b","c"] faild_user = ",".join(user_queue) # a,b,c faild_message = "非常抱歉,票已售完,以下几位用户请选择其他出行方式,名单:{}。".format(faild_user) print(faild_message) -
清空原列表
user_list = ["宝强","羽凡","mark","乃亮","mark"] user_list.clear() print(user_list) # [] -
根据值获取索引,(从左到右找到第一个删除,慎用,找不到报错)
user_list = ["宝强","羽凡","mark","乃亮","mark"] # 0 1 2 3 4 if "mark" in user_list: index = user_list.index("mark") print(index) else: print("不存在") -
列表元素排序
# 数字排序 num_list = [11, 22, 4, 5, 11, 99, 88] print(num_list) num_list.sort() # 让num_list 从小到大排序 print(num_list) num_list.sort(reverse=True) # 让num_list从大到小排序 print(num_list) # key 后面可以接函数 # 字符串如何进行排序? # 字符串排序 user_list = ["王宝强", "Ab陈羽凡", "mark", "贾乃亮", "贾乃", "1"] # [29579, 23453, 24378] # [65, 98, 38472, 32701, 20961] # [65, 108, 101, 120] # [49] print(user_list) # sort的排序原理,会转换为Unicode,先比较第一个码点,如果第一个相同则比较第二个,依次类推,谁小则谁在前面。 #如: [ "x x x" ," x x x x x " ] user_list.sort() print(user_list)注意:排序时内部元素无法进行比较时,程序会报错(尽量数据类型统一)。
-
反转原列表
user_list = ["a","b","c","d","e"] user_list.reverse() print(user_list) # 输出 ['e', 'd', 'c', 'b', 'a']在pycharm 输入list ,ctrl 点击 查看其他功能
1.3 公共功能
-
相加,两个列表相加获取生成一个新的列表。
data = ["a","b"] + ["c","d"] print(data) # ["a","b","c","d"] v1 = ["a","b"] v2 = ["c","d"] v3 = v1 + v2 print(v3) # ["a","b","c","d"] -
相乘,列表*整型 将列表中的元素再创建N份并生成一个新的列表。
data = ["a","b"] * 2 print(data) # ["a","b","a","b"] v1 = ["a","b"] v2 = v1 * 2 print(v1) # ["a","b"] print(v2) # ["a","b","a","b"] -
运算符in包含
由于列表内部是由多个元素组成,可以通过in来判断元素是否在列表中。user_list = ["狗子","二蛋","三毛","mark"] result = "mark" in user_list # result = "mark" not in user_list print(result) # True if "mark" in user_list: print("在,把他删除") user_list.remove("mark") else: print("不在")user_list = ["狗子","二蛋","三毛","mark"] if "mark" in user_list: print("在,把他删除") user_list.remove("mark") else: print("不在") # 字符串也支持 in 判断 元素是否在里面 text = "中国万岁" data = "万" in text# 案例:判断元素是否在里面,在则删除 user_list = ["狗子","二蛋","三毛","mark"] if "mark" in user_list: print("在,把他删除") user_list.remove("mark") else: print("不在")# 案例:判断元素是否在里面,在则获取它索引,最后根据它的索引把它删除 user_list = ["王宝强","陈羽凡","mark","贾乃亮","mark"] if "mark" in user_list: index = user_list.index("mark") user_list.pop(index) print(user_list)# 案例:敏感词替换 text = input("请输入文本内容:") # 随机输入内容,进行敏感词替换 forbidden_list = ["亚洲","欧美","日韩"] for item in forbidden_list: text = text.replace(item,"**") print(text) # 当元素特别多是,效率会非常低,会使用到集合,字典等效率会比较高注意:列表检查元素是否存在时,是采用逐一比较的方式,效率会比较低。
-
获取长度
user_list = ["范德彪","刘华强",'尼古拉斯赵四'] print( len(user_list) ) -
索引,一个元素的操作
# 读 user_list = ["范德彪","刘华强",'尼古拉斯赵四'] print( user_list[0] ) print( user_list[2] ) print( user_list[3] ) # 没有这个索引则报错# 改 user_list = ["范德彪","刘华强",'尼古拉斯赵四'] user_list[0] = "佩奇" print(user_list) # ["佩奇","刘华强",'尼古拉斯赵四']# 删,注意区分三种方式 user_list = ["a","b",'c'] del user_list[1] # 根据索引删除,无法取到备删除的值 user_list.remove("b") # 根据值删除,取被删除的值时输出为none ele = user_list.pop(1) # 根据索引删除,并且可以取得被删除的值注意:超出索引范围会报错。
提示:由于字符串是不可变类型,所以他只有索引读的功能,而列表可以进行 读、改、删 -
切片,多个元素的操作(很少用)
# 读 user_list = ["范德彪","刘华强",'尼古拉斯赵四'] print( user_list[0:2] ) # ["范德彪","刘华强"] print( user_list[1:] ) print( user_list[:-1] )# 改 user_list = ["范德彪", "刘华强", '尼古拉斯赵四'] user_list[0:2] = [11, 22, 33, 44] print(user_list) # 输出 [11, 22, 33, 44, '尼古拉斯赵四'] user_list = ["范德彪", "刘华强", '尼古拉斯赵四'] user_list[2:] = [11, 22, 33, 44] print(user_list) # 输出 ['范德彪', '刘华强', 11, 22, 33, 44] user_list = ["范德彪", "刘华强", '尼古拉斯赵四'] user_list[3:] = [11, 22, 33, 44] print(user_list) # 输出 ['范德彪', '刘华强', '尼古拉斯赵四', 11, 22, 33, 44] # 如果输入的索引超过最大值,则会添加到列表的最后,反正如果输入的索引小于最小最,则会添加到最前。 user_list = ["范德彪", "刘华强", '尼古拉斯赵四'] user_list[10000:] = [11, 22, 33, 44] print(user_list) # 输出 ['范德彪', '刘华强', '尼古拉斯赵四', 11, 22, 33, 44] user_list = ["范德彪", "刘华强", '尼古拉斯赵四'] user_list[-10000:1] = [11, 22, 33, 44] print(user_list) # 输出 [11, 22, 33, 44, '刘华强', '尼古拉斯赵四']# 删 user_list = ["范德彪", "刘华强", '尼古拉斯赵四'] del user_list[1:] print(user_list) # 输出 ['范德彪'] # 索引:操作单个元素,切片操作多个元素。 -
步长
user_list = ["范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能"] # 0 1 2 3 4 print( user_list[1:4:2] ) print( user_list[0::2] ) print( user_list[1::2] ) print( user_list[4:1:-1] )# 案例:实现列表的翻转 user_list = ["范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能"] new_data = user_list[::-1] print(new_data) data_list = ["范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能"] data_list.reverse() print(data_list) # 给你一个字符串请实现字符串的翻转? name = "小佩奇" name[::-1] -
for循环
user_list = ["范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能"] for item in user_list: print(item)user_list = ["范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能"] for index in range( len(user_list) ): item = user_index[index] print(item)切记,循环的过程中对数据进行删除会踩坑【面试题】。
# 错误方式, 有坑,结果不是你想要的。 user_list = ["刘德华", "范德彪", "刘华强", '刘尼古拉斯赵四', "宋小宝", "刘能"] for item in user_list: if item.startswith("刘"): user_list.remove(item) print(user_list) # 不能在循环的过程中,边循环获取列表的数据,边删除列表的数据,会导致循环的时候数据拿错。 # 因为删除后,索引会忘前移,导致数据取错。# 正确方式,倒着删除。 user_list = ["刘德华", "范德彪", "刘华强", '刘尼古拉斯赵四', "宋小宝", "刘能"] for index in range(len(user_list) - 1, -1, -1): item = user_list[index] if item.startswith("刘"): user_list.remove(item) print(user_list)
1.4 转换
-
int,bool 无法转换成列表
-
str
name = "孙悟空" data = list(name) print(data) # ['孙', '悟', '空'] -
元组
v1 = (11,22,33,44) # 元组 vv1 = list(v1) # 列表 [11,22,33,44] v2 = {"aa","bb","cc"} # 集合 vv2 = list(v2) # 列表 ["aa","bb","cc"]
1.5 其他
1.5.1 嵌套
列表属于容器,内部可以存放各种数据,所有它也支持列表的嵌套,如:
data = [ "谢广坤",["海燕","赵本山"],True,[11,22,[999,123],33,44],"宋小宝" ]
# 共五个元素
对于嵌套的值,可以根据索引的知识点来进行类比学习,例如:
data = [ "谢广坤",["海燕","赵本山"],True,[11,22,33,44],"宋小宝" ]
print( data[0] ) # "谢广坤"
print( data[1] ) # ["海燕","赵本山"]
print( data[0][2] ) # "坤"
print( data[1][-1] ) # "赵本山"
data.append(666)
print(data) # [ "谢广坤",["海燕","赵本山"],True,[11,22,33,44],"宋小宝",666]
data[1].append("谢大脚")
print(data) # [ "谢广坤",["海燕","赵本山","谢大脚"],True,[11,22,33,44],"宋小宝",666 ]
del data[-2]
print(data) # [ "谢广坤",["海燕","赵本山","谢大脚"],True,[11,22,33,44],666 ]
data[-2][1] = "mark"
print(data) # [ "谢广坤",["海燕","赵本山","谢大脚"],True,[11,"mark",33,44],666 ]
data[1][0:2] = [999,666]
print(data) # [ "谢广坤",[999,666,"谢大脚"],True,[11,"mark",33,44],666 ]
# 创建用户列表
# 如:用户列表: [ ["mark","123"],["eric","666"] ]
"""
user_list = [["mark","123"],["eric","666"],]
user_list.append(["mark","123"])
user_list.append(["eric","666"])
"""
user_list = []
while True:
user = input("请输入用户名:")
pwd = input("请输入密码:")
data = []
data.append([user])
data.append([pwd])
user_list.append(data)
user_list = []
while True:
user = input("请输入用户名(Q退出):")
if user == "Q":
break
pwd = input("请输入密码:")
data = [user,pwd]
user_list.append(data)
print(user_list)
2.元组
列表(list),是一个 有序 且 可变 的容器,在里面可以存放多个不同类型的元素。
元组(tuple),是一个 有序 且 不可变 的容器,在里面可以存放多个不同类型的元素。
如何体现不可变?
记住一句话:《“我儿子永远不能换成是别人,但我儿子可以长大”》
2.1 定义
v1 = (11,22,33)
v2 = ("周润发","mark")
v3 = (True,123,"mark",[11,22,33,44])
# 建议:议在元组的最后多加一个逗v3 = ("周润发","mark",)
# 如下情况单个元素加逗号才是元组,不加是整型
d1 = (1) # 1 整型
d2 = (1,) # (1,) 元组
# 多个元素不加逗号也是元组
d3 = (1,2)
d4 = (1,2)
注意:建议在元组的最后多加一个逗号,用于标识它是一个元组。
# 面试题
1. 比较值 v1 = (1) 和 v2 = 1 和 v3 = (1,) 有什么区别?
# v1 v2 整型,v3元组
2. 比较值 v1 = ( (1),(2),(3) ) 和 v2 = ( (1,) , (2,) , (3,),) 有什么区别?
# v1输出:(1, 2, 3)
# v2输出:((1,), (2,), (3,))
2.2独有功能(无)
无
###2.3 公共功能
-
相加,两个元组相加获取生成一个新的元组
data = ("赵四","刘能") + ("宋晓峰","范德彪") print(data) # ("赵四","刘能","宋晓峰","范德彪") v1 = ("赵四","刘能") v2 = ("宋晓峰","范德彪") v3 = v1 + v2 print(v3) # ("赵四","刘能","宋晓峰","范德彪") -
相乘,元组 * 整型,将元组中的元素再创建N 份并生成一个新的列表
data = ("赵四","刘能") * 2 print(data) # ("赵四","刘能","赵四","刘能") v1 = ("赵四","刘能") v2 = v1 * 2 print(v1) # ("赵四","刘能") print(v2) # ("赵四","刘能","赵四","刘能") -
获取长度
user_list = ("范德彪","刘华强",'尼古拉斯赵四',) print( len(user_list) ) -
索引
user_list = ("范德彪","刘华强",'尼古拉斯赵四',) print( user_list[0] ) print( user_list[2] ) print( user_list[3] ) # 超出索引范围会报错 -
切片
user_list = ("范德彪","刘华强",'尼古拉斯赵四',) print( user_list[0:2] ) print( user_list[1:] ) print( user_list[:-1] ) -
步长
user_list = ("范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能") print( user_list[1:4:2] ) print( user_list[0::2] ) print( user_list[1::2] ) print( user_list[4:1:-1] )# 字符串 & 元组 #如果要反转只有如下一种方式,并且可以生成新的字符串和元组,内部是无法修改的。 user_list = ("范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能") data = user_list[::-1] print(data) # ('刘能', '宋小宝', '尼古拉斯赵四', '刘华强', '范德彪') # 列表,反转两种方式,把本身反转了,没有生成新的数据 user_list = ["范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能"] data = user_list[::-1] user_list.reverse() print(user_list) -
for 循环
user_list = ("范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能") for item in user_list: print(item)user_list = ("范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能") for item in user_list: if item == '刘华强': continue print(name)目前只有 str ,list,tuple 可以被for 循环。
#也可以通过 len + range + for + 索引 对元组循环 user_list = ("范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能") for index in range(len(user_list)): item = user_list[index] print(item) # 循环输出每个元素
2.4 转换
其他类型转换为元组,使用tuple(其他类型),目前只有字符串和列表转换为元组
data = tuple(其他)
# str / list
name = "小猪佩奇"
data = tuple(name)
print(data) # 输出 ("小","猪","佩","奇")
name = ["小猪佩奇",18,"chine"]
data = tuple(name)
print(data) # 输出 ('小猪佩奇', 18, 'chine')
2.5 其他
2.5.1 嵌套
由于元组和列表都可以充当 容器,他们内部可以放很多元素,并且也支持元素内的各种嵌套
tu = ( '春眠不觉晓', '处处闻帝鸟', ('夜来风雨声','花落知多少') )
tu1 = tu[0]
tu2 = tu[1]
tu3 = tu[2][0]
tu4 = tu[2][1]
tu5 = tu[2][1][3]
print(tu1) # 春眠不觉晓
print(tu2) # 处处闻帝鸟
print(tu3) # 夜来风雨声
print(tu4) # 花落知多少
print(tu5) # 多
练习题1:判断是否可用实现,如果可用实现请写代码实现
li = ["mark", [11,22,(88,99,100,),33], "suse", ("htl", "xyy",), "wenzhou"]
# 0 1 2 3 4
# 1.请将 "suse" 修改成 "苏西"
li[2] = "苏西"
第二种:
index = li.index("suse")
li[index] = "苏西"
print(li)
# 2.请将 ("htl", "xyy",) 修改为 ['灰太狼','喜洋洋']
li[3] = ['灰太狼','喜洋洋']
# 3.请将 88 修改为 87
元组不能修改,报错
# 4.请将 "wenzhou" 删除,然后再在列表第0个索引位置插入 "周周"
li.remove("wenzhou")
del li[-1]
li.pop(4)
li.insert(0,"周周")
练习题2:记住一句话:《“我儿子永远不能换成是别人,但我儿子可以长大”》
data = ("123",666,[11,22,33], ("mark","杰克马",[999,666,(5,6,7)]) )
# 1.将 “123” 替换成 9 报错
# 2.将 [11,22,33] 换成 "深圳马" 报错
# 3.将 11 换成 99
data[2][0] = 99
print(data) # ("123",666,[99,22,33], ("mark","杰克马",[999,666,(5,6,7)]) )
# 4.在列表 [11,22,33] 追加一个44
data[2].append(44)
print(data) # ("123",666,[11,22,33,44], ("mark","杰克马",[999,666,(5,6,7)]) )
练习题3:动态的创建用户并添加到用户列表中。
user_list = []
while True:
user = input("请输入用户名:")
if user == "Q":
break
pwd = input("请输入密码:")
item = (user,pwd,)
user_list.append(item)
#print(user_list)
# 实现:用户登陆案例
print("登陆程序")
username = input("请输入用户名:")
password = input("请输入密码:")
is_success = False
for item in user_list:
if username == item[0] and password == item[1]:
is_success = True
break
if is_success:
print("登陆成功")
else:
print("登陆失败")
总结
- 概述
- 列表,以后写程序会用的非常多,需要多加练习
- 元组,以后写程序用的较少,主要以了解其特殊和用法为主
- 列表和元组的区别
- 可变类型和不可变类型
- 列表独有功能 & 不可变功能
- 列表和元组等数据的嵌套
- 元组中(1) 和 (1,)的区别
- 元组的元素不能被替换,但元组的元素是可变类型,可变类型的内部是可以修改的。
day07 数据类型(下)
常见的数据类型:
- int,整型
- bool,布尔类型
- str,字符串类型
- list,列表类型
- tuple,元组类型
- dict,字典类型
- set,集合类型
- float,浮点类型
概要:
- set集合,一个不允许重复 & 可变类型 (元素可哈希)
- dict 字典,一个容器且元素必须是键值对
- float类型,生活中常见的小数
1.集合(set)
集合是一个无序,可变,不允许数据重复的容器。
1.1定义
v1 = {11,22,33,"jack"}
-
无序,无法通过索引取值
-
可变,可以添加和删除元素
v1 = {11,22,33,44} v1.add(55) print(v1) # {11,22,33,44,55} -
不允许数据重复
v1 = {11,22,33,44} v1.add(22) print(v1) # {11,22,33,44}
一般什么时候使用集合呢?
需要维护一大堆不重复的数据时就可以使用它。比如:做爬虫去网上找图片的链接,为了避免链接重复,可以选择用集合去存储链接地址。
注意:定义空集合时,只能使用v = set(),不能使用v = {},因为这样是定义了一个空字典。
v1 = []
v11 = list()
v2 = ()
v22 = tuple()
v3 = set()
v4 = {} # 空字典
v44 = dict()
1.2独有功能
- 添加元素
data = {"刘嘉玲", '关之琳', "王祖贤"}
data.add("郑裕玲")
print(data)
data = set()
data.add("周杰伦")
data.add("林俊杰")
print(data)
-
删除元素
data = {"刘嘉玲", '关之琳', "王祖贤","张曼⽟", "李若彤"} data.discard("关之琳") print(data) -
交集
s1 = {"a","b","c"} s2 = {"c","d","e"} s4 = s1.intersection(s2) # 取两个集合的交集 print(s4) # {'c'} # 取两个集合的交集 s3 = s1 & s2 print(s3) -
并集
s1 = {"a", "b", "c"} s2 = {"d", "e", "c"} s4 = s1.union(s2) # 取两个集合的并集 {'c', 'd', 'a', 'e', 'b'} print(s4) s3 = s1 | s2 # 取两个集合的并集 print(s3) -
差集
s1 = {"a", "b", "c"} s2 = {"d", "e", "c"} s4 = s1.difference(s2) # 差集,s1中有,且s2中没有的值 {"a","b"} s6 = s2.difference(s1) # 差集,s2中有,且s1中没有的值 {"d","e"} s3 = s1 - s2 # 差集,s1中有且s2中没有的值 s5 = s2 - s1 # 差集,s2中有且s1中没有的值
1.3 公共功能
-
减,计算差集
s1 = {"刘能", "赵四", "⽪⻓⼭"} s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"} s3 = s1 - s2 s4 = s2 - s1 print(s3) # {'赵四', '刘能'} 其实是输出的是被减数没有的值 print(s4) # {'冯乡⻓', '刘科⻓'} -
& ,计算 交集
s1 = {"刘能", "赵四", "⽪⻓⼭"} s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"} s3 = s1 & s2 print(s3) # 输出共同的元素,即为交集 -
|, 计算并集
# 输出两个集合的元素,并且去重
s1 = {"刘能", "赵四", "⽪⻓⼭"}
s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"}
s3 = s1 | s2
print(s3)
- 长度
v = {"刘能", "赵四", "尼古拉斯"}
data = len(v)
print(data)
-
for 循环
v = {"刘能", "赵四", "尼古拉斯"} for item in v: print(item)
1.4 转换
其他类型如果想要转换为集合类型,可以通过set进行转换,并且如果数据有重复自动剔除
提示:int ,list,tuple,dict 都可以转换为集合。
v1 = "小猪佩奇"
v2 = set(v1)
print(v2) # {'奇', '佩', '猪', '小'}
v1 = [11,22,33,11,3,99,22]
v2 = set(v1)
print(v2) # {11,22,33,3,99}
# 元组,列表转换为集合,自动去重
v1 = (11,22,3,11)
v2 = set(v1)
print(v2) # {11,22,3}
提示:也是去重的一种手段。
# 集合,列表,元组 可以互相转换
data = {11,22,33,3,99}
v1 = list(data) # [11,22,33,3,99]
v2 = tuple(data) # (11,22,33,3,99)
1.5 其他
1.5.1 集合的存储原理
创建一个集合的时候,python的内部会创建一个对应的哈希表。
v1 = set()
v1.add("佩奇")
当去存储v1 = {"佩奇"} 这个值时。
第一步:利用哈希函数将"佩奇" 转换为一个数值,如:471654523781124323
第二步:去余数,(实际掩码做 & 运算)471654523781124323 % 7 = 3,假设 有七个元素,则去7的模,等于3,则放在在哈希表的 3 索引位置。整因为每次运算的结果不一样,所以是无效的。
第三步:将"佩奇"放在哈希表的3索引位置
1.5.2 元素必须可哈希
因为存储原理,集合的元素必须是可以哈希的值,即:内部通过函数函数把值转换成一个数字。并且每次的执行结果都是不同的。

目前可哈希的数据类型:int,bool,str,tuple,而list,set是不可哈希的。
总结:集合的元素只能是int,bool,str,tuple。
-
转换成功
v1 = [11,22,33,11,3,99,22] v2 = set(v1) print(v2) # [11,22,33,3,99] -
转换失败
v1 = [11,22,["jack","eric"],33] v2 = set(v1) # 报错 print(v2) 执行结果如下: D:\python39\python.exe C:/Users/dw/Desktop/python笔记/模块一/代码/day5/day07.py Traceback (most recent call last): File "C:\Users\dw\Desktop\python笔记\模块一\代码\day5\day07.py", line 24, in <module> v2 = set(v1) # 报错 TypeError: unhashable type: 'list' Process finished with exit code 1
1.5.3 查找速度特别快
因为存储原理特殊,集合的查找效率非常高(数据量大了才明显)
-
低效率
# 一个个从前到后比较,当数量非常大的时候效率非常低 # 列表 user_list = ["佩奇","jack","mark"] if "jack" in user_list: print("在") else: print("不在") # 元组 user_tuple = ["佩奇","jack","mark"] if "jack" in user_tuple: print("在") else: print("不在") -
效率高
# 集合,比较一次, user_set = {"佩奇","jack","mark"} if "jack" in user_set: print("在") else: print("不在")
1.5.4 对比和嵌套
| 类型 | 是否可变 | 是否有序 | 元素要求 | 是否可哈希 | 转换 | 定义空 |
|---|---|---|---|---|---|---|
| list | 是 | 是 | 无 | 否 | list(其他) | v=[] 或 v =list() |
| tuple | 否 | 是 | 无 | 是 | tuple(其他) | v = [] 或 v = tuple |
| set | 是 | 否 | 可哈希 | 否 | set(其他) | v = set() |
数据类型直接的嵌套
# 列表中可以放任意类型的数据
data_list = [
"jack", # 字符串
11, #整型
(11, 22, 33, {"jack", "eric"}, 22), # 元组,数组中有整型,集合
[11, 22, 33, 22], # 列表
{11, 22, (True, ["中国", "北京"], "沙河"), 33} # 集合,集合中放了整型,元组(元组中又有bool,列表,str),整型。
]
总结:集合中不能放列表,但是可以放元组。元组中可放列表,但当元组存在集合中时,不能存放列表,会报错,因为不能哈希。不但集合的元素要能哈希,集合的元素中的元素也必须可以哈希。

注意:由于True 和 False 本质上存储的是 1 和 0 ,而集合又不允许重复,所有在整数 0, 1, 和 False,True 出现在集合中会有如下现象:
v1 = {True, 1}
print(v1) # {True}
v2 = {1, True}
print(v2) # {1}
v3 = {0, False}
print(v3) # {0}
v4 = {False, 0}
print(v4) # {False}
# True 转换为 1,False 转换为 0 ,因为集合不运行重复,所有在整数 0,1 和 False,True都出现在集合时,只会取到前一个值。
练习
#1. 循环提示用户输入,如果输入值在v1中存在,则追加到v2中,如果v1中不存在,则添加到v1中。(如果输入N或n则停止循环)
v1 = v1 = {'abc','阿sir','肖申克'}
v2 = []
while True:
result = input("请输入用户名(N/n退出):")
if result.upper() == "N":
break
if result in v1:
v2.append(result)
else:
v1.add(result)
print(v1)
print(v2)
None类型
python的数据类型中有一个特殊的None,意味着这个值啥都不是或表示空。相当于其他语言中的null一样的作用。
在一定程度上可用帮助我们去节省内存,例如:
v3 = []
v4 = []
...
v3 = [11,22,33,44]
v4 = [111,22,43]
如下写法比上面这种写法,更省内存一点。
v1 = None
v2 = None
...
v1 = [11,22,33,44]
v2 = [111,22,43]
注意:暂时不要考虑python内部的缓存和驻留机制。
目前所有转换为布尔值为False的值有:
0
""
[] or list[]
() or tuple()
set()
None
if None: # 自动转为False
pass
2. 字典(dict)
字典是 无序,键不重复 且 元素只能是键值对的 可变的 容器。
data = { "k1":1, "k2":2 }
-
容器
-
元素必须是键值对
-
键不重复,重复则会被覆盖
data = { "k1":1, "k1":2 } print(data) # {"k1":2} -
无序,(在python3.6+ 字典就是有序了,之前的字典都是无序的。)
data = { "k1":1, "k2":2 } print(data)
2.1 定义
# 方式一:
v1 = {}
# 方式二:
v2 = dict()
# 方式三:
data = {
"k1":1,
"k2":2
}
# 方式四:
info = {
"age":12,
"status":True,
"name":"peiqi",
"hobby":['篮球','足球']
}
字典中对键值的要求:
- 键:必须可以哈希,目前为止学到的可哈希的类型:int bool,str,tuple ;不可哈希的类型:list,set,dict。(集合的元素也必须是可哈希的)
- 值:任意类型
案例分析:
# 合法
data_dict = {
"佩奇":29,
True:5,
123:5,
(11,22,33):["jack","mark"]
}
# 不合法
v1 = {
[1, 2, 3]: '周杰伦',
"age" : 18
}
v2 = {
{1,2,3}: "哈哈哈",
'name':"jack"
}
v3 = {
{"k1":123,"k2":456}: '呵呵呵',
"age":999
}
data_dict = {
1: 29,
True: 5
}
print(data_dict) # {1: 5}
一般在什么场景下会使用到字典?
当需要表示一组固定信息时,用字典可以更加的直观,例如:
# 用户列表
user_list = [ ("jack","123"),("tom","666") ]
...
# 用户列表
user_list = [ {"name":"jack","pwd":"123"}, {"name":"tom","pwd":"123"} ]
2.2 独有功能
-
获取值
info = { "age":18, "status":True, "name":"tom", } data1 = info.get("name") print(data1) # 输出:tom data = info.get("age") print(data) # 输出:12 data = info.get("email") # 键值不存在,默认返回 None ############################################################################################################### # 若集合中确实存在 "data":None 这样的键值对,则可通过如下判断: if data == None: print("此键不存在") else: print(data) if data: print(data) else: print("键不存在") # 字典的键中是否存在 email if "email" in info: data = info.get("email") print(data) else: print("不存在") ############################################################################################################### # 如果hobby存在,则返回hobby的值,如果不存在则将123赋值给hobby并输出。 data = info.get("hobby",123) print(data) # 输出:123get案例:
user_list = { "peiqi": "123", "tom": "uk78", } username = input("请输入用户名:") password = input("请输入密码:") pwd = user_list.get(username) # 如果pwd这个变量不存在,也就是None,说明用户不存在 if pwd == None: print("用户名不存在") else: if password == pwd: print("登陆成功") else: print("密码错误")# 优化案例 user_list = { "peiqi": "123", "tom": "uk78", } username = input("请输入用户名:") password = input("请输入密码:") pwd = user_list.get(username) if pwd: # 默认自动转换为bool,为True if password == pwd: print("登陆成功") else: print("密码错误") else: print("用户名不存在")利用运算符 not 优化,推荐此方法
# 案例 user_list = { "peiqi": "123", "tom": "uk78", } username = input("请输入用户名:") password = input("请输入密码:") pwd = user_list.get(username) if not pwd: print("用户名不存在") else: if password == pwd: print("登陆成功") else: print("密码错误") # 写代码的准则:简单的逻辑处理放在前面,复杂的逻辑放在后面 -
所有的键
info = {"age":12, "status":True, "name":"peiqi","email":"[email protected]"} data = info.keys() print(data) # 输出:dict_keys(['age', 'status', 'name', 'email']) *************************************************************************************************************** # 这个所谓的高仿列表可以转换为真正的列表,一般情况下不会去转换,因为高仿的列表也具有一些功能,如for 循环,判断键是否在里边。 result = list(data) print(result) # ['age', 'status', 'name', 'email'] # py2 -> ['age', 'status', 'name', 'email']注意:在python2 中,字典.keys() 直接获取到的是列表,而python3中返回的是
高仿列表,这个高仿列表可以被循环显示。# 循环,输出每个元素 info = {"age":12, "status":True, "name":"peiqi","email":"[email protected]"} for ele in info.keys(): print(ele)# 键是否存在 info = {"age":12, "status":True, "name":"peiqi","email":"[email protected]"} # info.keys() # dict_keys(['age', 'status', 'name', 'email']) if "age" in info.keys(): print("age是字典的键") else: print("age不是") -
所有的值
info = {"age":12, "status":True, "name":"peiqi","email":"[email protected]"} data = info.values() print(data) # 输出:dict_values([12, True, 'peiqi', '[email protected]'])注意:在python2中 字典.values() 直接获取到的是列表,而在python3在返回的是高仿列表,这个高仿列表可以被循环显示。
# 循环 info = {"age":12, "status":True, "name":"peiqi","email":"[email protected]"} for var in info.values(): print(va1)# 值是否存在 info = {"age":12, "status":True, "name":"peiqi","email":"[email protected]"} if 12 in info.values(): print("12是字典的值") else: print("12不是") -
所有的键值
info = {"age":12, "status":True, "name":"peiqi","email":"[email protected]"} data = info.items() print(data) # 输出:dict_items([('age', 12), ('status', True), ('name', 'peiqi'), ('email', '[email protected]')])# 循环 info = {"age":12, "status":True, "name":"peiqi","email":"[email protected]"} for item in info.items(): print(item(0),item[1]) # item 是一个元组 (键,值) # 输出: age 12 status True name peiqi email xx@live.com# 变量循环,自动拆解 info = {"age":12, "status":True, "name":"peiqi","email":"[email protected]"} for key,value in info.items(): print(key,value) # key代表键,value代表值,将键值从元组中直接拆分出来了 # 输出: age 12 status True name peiqi email xx@live.com# 判断 元组 是否在里面,效率低,基本不用 info = {"age":12, "status":True, "name":"peiqi","email":"[email protected]"} data = info.items() if ('age',12) in data: print("在") else: print("不在") -
设置值(5-8 较少使用)
data = { "name": "佩奇", "email": '[email protected]' } data.setdefault("age",18) print(data) # {'name': '佩奇', 'email': '[email protected]', 'age': 18} # 没有则添加,有则什么都不干 data.setdefault("name","tom") print(data) # {'name': '佩奇', 'email': '[email protected]', 'age': 18} -
更新字典键值对
# info中没有的值直接添加,有的则更新 info = {"age":12, "status":True} info.update( {"age":14,"name":"佩奇"} ) # 传入的值必须是字典 print(info) # 输出: {'age': 14, 'status': True, 'name': '佩奇'} -
移除指定键值对
info = {'age': 14, 'status': True, 'name': '佩奇'} data = info.pop("age") # 移除的值是可以获取到的 print(info) # {'status': True, 'name': '佩奇'} print(data) # 14 -
按照顺序移除(后进先出)
# info.popitem() 移除最后边的值,且将移除的值以元组的方式赋值给data info = {'age': 12, 'status': True, 'name': '佩奇'} data = info.popitem() # ("name","佩奇") print(info) # {'age': 12, 'status': True} print(data) # ('name', '佩奇')- python3.6,popitem移除最后的值
- python3.6之前,popitem随机删除
2.3 公共功能
-
求并集 (python3.9新加入)
v1 = {"k1": 1, "k2": 2} v2 = {"k2": 22, "k3": 33} v3 = v1 | v2 # 或,管道符;并集 print(v3) # {'k1': 1, 'k2': 22, 'k3': 33} # 注意与update区分,update是更新了原有的字典,而 | 是生成了一个新字典,并且是3.9之后新加入的 -
长度
info = {"age":12, "status":True,"name":佩奇"} data = len(info) print(data) # 输出:3 -
是否包含
# 判断键是否在字典里 info = {"age":12, "status":True,"name":"佩奇"} v1 = "age" in info print(v1) v2 = "age" in info.keys() print(v2) if "age" in info: pass else: passinfo = {"age":12, "status":True,"name":"佩奇"} v1 = "佩奇" in info.values() print(v1)info = {"age":12, "status":True,"name":"佩奇"} # 输出info.items()获取到的 dict_items([ ('age', 12), ('status', True), ('name', 'peiqi'), ('email', '[email protected]') ]) v1 = ("age", 12) in info.items() # 判断元组是否里面 print(v1) -
索引(键)
字典不同于元组和列表,字典的索引是 键 ,而列表和元组则是 0,1,2 等数值info = {"age":12, "status":True,"name":"佩奇"} print( info["age"] ) # 输出:12 print( info["name"] ) # 输出:佩奇 print( info["status"] ) # 输出:True print( info["xxxx"] ) # 报错,通过键为索引去获取之后时,键不存在会报错(以后项目开发时建议使用get方法根据键去获取值) value = info.get('xxxx') # None 键不存在不会报错 print(value) -
根据键 修改值 和 添加值 和 删除键值对
上述示例通过键可以找到字典中的值,通过键也可以对字典进行添加和更新操作# 添加值 info = {"age":12, "status":True,"name":"佩奇"} info["gender"] = "男" print(info) # 输出:{"age":12, "status":True,"name":"佩奇","gender":"男"}# 修改值,有则覆盖,没有则添加 info = {"age":12, "status":True,"name":"佩奇"} infor["age"] = "18" print(info) # 输出: {"age":"18", "status":True,"name":"佩奇"} # 注意与setdefault区分,serdefault是有则什么都不做,没有则添加。# 删除值 info = {"age":12, "status":True,"name":"佩奇"} del info["age"] # 删除info 字典中键为age的那个键值对(键不存在则报错) print(info) # 输出:{'status': True, 'name': '佩奇'}info = {"age":12, "status":True,"name":"佩奇"} if "age" in info: # del info["age"] data = info.pop("age") print(info) print(data) else: print("不存在")**注意:**del只能删除键值对,而pop不但能删除还能获取到键值对,不存在都会报错。
-
for 循环
由于字典也属于容器,内部可以包含多个键值对,可以通过循环对其中的:键,值,键值进行循环
info = {"age":12, "status":True,"name":"佩奇"} for item in info: print(item) # 默认输出所有键info = {"age":12, "status":True,"name":"佩奇"} for item in info.keys(): print(item) # 所有键info = {"age":12, "status":True,"name":"佩奇"} for item in info.values(): print(item) # 所有值info = {"age":12, "status":True,"name":"佩奇"} for key,value in info.items(): print(key,value) # 键值对
2.4 转换
想要转换为字典
v = dict( [ ("k1", "v1"), ["k2", "v2"] ] )
print(v) # { "k1":"v1", "k2":"v2" }
info = {"age":12, "status":True,"name":"佩奇"}
v1 = list(info) # ['age', 'status', 'name'] 只输出keys
v2 = list(info.keys()) # ['age', 'status', 'name']
v3 = list(info.values()) # [12, True, '佩奇']
v4 = list(info.items()) # [('age', 12), ('status', True), ('name', '佩奇')]
2.5 其他
1.5.1 存储原理
创建一个空列表时,会对应创建一个哈希表,如:
info = {}
info["name"] = "佩奇"
先拿到name 做哈希处理,hash(),然后做取余处理,除以键值对数取余,得到的余数就是数据存储的位置,所以取值较快。
1.5.2 速度快
info = {
"羊村":["懒洋洋","慢羊羊"],
"狼堡":["灰太狼","红太狼"]
}
for "羊村" in info:
print("在")
# 通过get 或索引去取值也较快
info = {
"羊村":["懒洋洋","慢羊羊"],
"狼堡":["灰太狼","红太狼"]
}
v1 = info["羊村"]
v2 = info.get("羊村")
1.5.3 嵌套
在涉及多种数据类型之间的嵌套时,需要注意以下几点:
-
字典的键必须可哈希(list/set/dict不可哈希),目前可哈希的数据类型:int,bool,str,tuple
info = { (11,22):123 } # 错误,列表不能haxi, info = { (11,[11,22,],22):"jack" } #在可哈希的数据类型中的子元素,也必须柯哈希,否则会报错 -
字典的值可以是任意类型
info = { "k1":{12,3,5}, "k2":{"xx":"x1"} } #报错,集合是不可哈希的,但是集合元素必须是可哈希的。 info = { "k1":{12,3,5,[11,22,33]}, "k2":{"xx":"x1"} } info = { "k1":{12,3,5,[(11,22,33)]}, "k2":{"xx":"x1"} } -
字典的键和集合的元素在遇到 布尔值 和 1, 0 时,需注意重复的情况。
-
元组的元素不可被替换
主要记忆:字典,字符串,列表的功能,使用比较频繁
3. 浮点型
浮点型,一般在开发中用于表示小数。
v1 = 3.14
v2 = 9.89
# 支持加减乘除
关于浮点型的其他知识点如下:
-
在类型转换时,浮点型转换为整型时,会将小数部分去掉。
v1 = 3.14 data = int(v1) print(data) # 3 -
想要保留小数点后N位
v1 = 3.1415926 result = round(v1,3) print(result) # 3.142 # 自动完成四舍五入 -
浮点型的 坑 (所有语言中)
v1 = 0.1
v2 = 0.2
v3 = v1 + v2
print(v3)
执行结果:
D:\Python\python.exe D:/dw/python/day07.py
0.30000000000000004
Process finished with exit code 0
因为底层原理导致。
底层原理视频:https://www.bilibili.com/video/BV1354y1B7o1/
在项目中如果遇到精确的小数计算应该怎么办?
```python
import decimal
v1 = decimal.Decimal("0.1")
v2 = decimal.Decimal("0.2")
v3 = v1 + v2
print(v3) # 0.3
# type()查看数据类型
总结
-
集合是有序,不重复,元素必须可哈希,可变的一个容器(子孙元素都必须是可哈希)
-
集合的查找速度比较快(底层是基于哈希进行存储)
-
集合可以具有交并集 的功能
-
字典是无序,键不重复,且元素只能是键值对的可变的一个容器,键子孙元素都必须是可哈希的
-
python3.6+ 之后字典变为有序
-
python3.9 新增了 一个 { } | { } 的运算
-
字典的常见功能
-
在python2 和 python3 中,字典的keys(),values(),items() 三个功能获取的数据类型不一样
-
None是代表内存中的一个空值
0 "" [] or list() () or tiple() set() None {} or dict() # 以上转换为布尔值都为 False -
浮点型用于表示小数,但是由于其内部存储原理可能会引发数据存储不够精准。
取值自动拆分并赋值
v = "k1:1"
v1,v2 = v.split(":")
print(v1,v2)
# 输出:
k1 1
# 自动拆分并分别赋值,支持多个拆分赋值
优化代码准则
- 尽可能少if嵌套
- 简单的逻辑先处理
day08 代码规范与知识点补充
1. 代码规范
程序员写代码是有规范的,不只是实现功能。
1.1 名称
在python开发过程中会长江文件夹/文件/变量等,这些在命名时有一些潜规则(编写代码时也需要注意PEP8规范)。
- 文件夹,小写 & 小写下划线连接,例如:commands,data_list等。
- 文件,小写 & 小写下划线连接,例如:
page.py、db_convert.py等。 - 变量
- 全家变量,大写 & 大写下划线连接,例如:
NAME = 孙悟空BASE_NAME = 18 - 局部变量,小写 & 小写下划线连接,例如:
dadta = [11,22,33]user_parent_id = 9等。
- 全家变量,大写 & 大写下划线连接,例如:
1.2 注释
作为程序员,写代码注释是非常基础且有用的技能,方便以后对代码进行维护和理解。
-
文件夹注释

-
文件注释
""" 这个文件主要为项目提供工具和转换的功能,除此之外还有日志.... 例如: ... ... ... """ -
代码注释
name = "悟空" # 在名称后面添加一个齐天大圣 date = name + "齐天大圣" print(data)# 多行代码,批量注释 """ name = "悟空" date = name + "齐天大圣" print(data) .... """
1.3 todo
基于注释可以实现todo注释的效果,例如:

1.4 条件嵌套
以后写条件语句一定要想办法减少嵌套的层级(最好不要超过3层)
1.5简单逻辑先处理
实例1:
goods = [
{"name": "电脑", "price": 1999},
{"name": "鼠标", "price": 10},
{"name": "游艇", "price": 20},
{"name": "美女", "price": 998}
]
for index in range(len(goods)):
item = goods[index]
print(index + 1, item['name'], item['price'])
while True:
num = input("请输入要选择的商品序号(Q/q):") # "1"
if num.upper() == "Q":
break
if num.isdecimal():
num = int(num)
if 0 < num < 5:
target_index = num - 1
choice_item = goods[target_index]
print(choice_item["name"], choice_item['price'])
else:
print("序号范围选择错误")
else:
print("用户输入的序号格式错误")
实例2:
goods = [
{"name": "电脑", "price": 1999},
{"name": "鼠标", "price": 10},
{"name": "游艇", "price": 20},
{"name": "美女", "price": 998}
]
for index in range(len(goods)):
item = goods[index]
print(index + 1, item['name'], item['price'])
while True:
num = input("请输入要选择的商品序号(Q/q):") # "1"
if num.upper() == "Q":
break
if not num.isdecimal():
print("用输入的格式错误")
break
num = int(num)
if num > 4 or num < 0:
print("范围选择错误")
break
target_index = num - 1
choice_item = goods[target_index]
print(choice_item["name"], choice_item['price'])
1.6 循环
尽量少循环多干事,提高代码效率
key_list = []
value_list = []
info = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
for key, value in info.items():
key_list.append(key)
value_list.append(value)
# 下面这段代码虽然更加简洁,但是循环次数更多,效率更低
info = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
key_list = list(info.keys())
value_list = list(info.values())
1.7 变量和值
# 推荐
name = "悟空"
age = '2000'
可以基于pycharm的格式化工具来实现自动处理。
python代码规范:PEP8规范。
2.知识点补充
2.1 pass
一般python的代码块是基于 : 和 缩进 来实现,python规定代码块中必须要有代码才算完整,在没有代码的的情况下为了保证语法的完整性可以用pass替代,例如:
if 条件 :
pass
else:
pass
# 没有动作时使用pass使代码块变得完整
for i in range(xxx):
pass
2.2 is比较
is 和 == 的区别是什么?
==,用于比较两个值是否相等- is,用于表示内存地址是否一致
# 示例1
v1 = []
v2 = []
print( v1 == v2 ) # True,两个值相当
print( v1 is v2 ) # False,不属于同一块内存。
# 示例2
v1 = []
v2 = v1
print( v1 == v2 ) # True,两个值相当
print( v1 is v2 ) # True,属于同一块内存。
# 示例3
v1 = None
v2 = None
print(v1 == v2) # True,两个值相当
print(v1 is v2) # True,属于同一块内存。
2.3 位运算
计算机底层本质上都是二进制,我们平时在计算机做的很多操作底层都会转换为二进制的操作,位运算就是对二进制的操作。
-
&与运算 (都为1,才为1)a = 60 # 60 = 0011 1100 b = 13 # 13 = 0000 1101 c = a & b # 12 = 0000 1100 -
|或运算 (只要有一个为1,结果就是1)a = 60 # 60 = 0011 1100 b = 13 # 13 = 0000 1101 c = a | b # 61 = 0011 1101 -
^,异或运算(a,b值不同为1,值相同还是0)a = 60 # 60 = 0011 1100 b = 13 # 13 = 0000 1101 c = a ^ b # 49 = 0011 0001 -
~取反a = 60 # 60 = 0011 1100 c = ~a; # -61 = 1100 0011 -
<<,左移动# 向左边移动两位,不够的通过加0 a = 60 # 60 = 0011 1100 c = a << 2; # 240 = 1111 0000 -
>>,右移动# 向右移动,把最右边两位删除 a = 60 # 60 = 0011 1101 c = a >> 2; # 15 = 0000 1111
平时在开发中,二进制的位运算几乎很少使用,在计算机底层 或 网络协议底层用的会比较多,例如:
-
计算 2**n
2**0 1 << 0 1 1 2**1 1 << 1 10 2 2**2 1 << 2 100 4 2**3 1 << 3 1000 8 ... # 2的几次方就向左移动几位 -
计算应该数的一般
v1 = 10 >> 1 print(v1) # 值为5 v2 = 20 >> 1 print(v2) # 值为 10 -
网络传输数据,文件太大还未传完,(websocket 源码为例)
第1个字节 第2个字节 ... 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-------+-+-------------+-------------------------------+ |F|R|R|R| opcode|M| Payload len | Extended payload length | |I|S|S|S| (4) |A| (7) | (16/64) | |N|V|V|V| |S| | (if payload len==126/127) | | |1|2|3| |K| | | +-+-+-+-+-------+-+-------------+ - - - - - - - - - - - - - - - + FIN位置是0,表示这是一部分数据,后续还有数据。 FIN位置是1,表示这是最后数据,已发送完毕。# 例如:接收到的第一个字节的值为245(11110101),让v的二进制和 1000 0000 做 & 与运算。 v = 245 # 245 11110101 # 128 10000000 10000000 data = v & 128 if data == 0: print("还有数据") else: print("已完毕")
data)
```python
# 多行代码,批量注释
"""
name = "悟空"
date = name + "齐天大圣"
print(data)
....
"""
1.3 todo
基于注释可以实现todo注释的效果,例如:
[外链图片转存中…(img-lGXTt5TO-1631880194298)]
1.4 条件嵌套
以后写条件语句一定要想办法减少嵌套的层级(最好不要超过3层)
[外链图片转存中…(img-sJF49ME0-1631880194298)]
1.5简单逻辑先处理
实例1:
goods = [
{"name": "电脑", "price": 1999},
{"name": "鼠标", "price": 10},
{"name": "游艇", "price": 20},
{"name": "美女", "price": 998}
]
for index in range(len(goods)):
item = goods[index]
print(index + 1, item['name'], item['price'])
while True:
num = input("请输入要选择的商品序号(Q/q):") # "1"
if num.upper() == "Q":
break
if num.isdecimal():
num = int(num)
if 0 < num < 5:
target_index = num - 1
choice_item = goods[target_index]
print(choice_item["name"], choice_item['price'])
else:
print("序号范围选择错误")
else:
print("用户输入的序号格式错误")
实例2:
goods = [
{"name": "电脑", "price": 1999},
{"name": "鼠标", "price": 10},
{"name": "游艇", "price": 20},
{"name": "美女", "price": 998}
]
for index in range(len(goods)):
item = goods[index]
print(index + 1, item['name'], item['price'])
while True:
num = input("请输入要选择的商品序号(Q/q):") # "1"
if num.upper() == "Q":
break
if not num.isdecimal():
print("用输入的格式错误")
break
num = int(num)
if num > 4 or num < 0:
print("范围选择错误")
break
target_index = num - 1
choice_item = goods[target_index]
print(choice_item["name"], choice_item['price'])
1.6 循环
尽量少循环多干事,提高代码效率
key_list = []
value_list = []
info = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
for key, value in info.items():
key_list.append(key)
value_list.append(value)
# 下面这段代码虽然更加简洁,但是循环次数更多,效率更低
info = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
key_list = list(info.keys())
value_list = list(info.values())
1.7 变量和值
# 推荐
name = "悟空"
age = '2000'
可以基于pycharm的格式化工具来实现自动处理。
python代码规范:PEP8规范。
2.知识点补充
2.1 pass
一般python的代码块是基于 : 和 缩进 来实现,python规定代码块中必须要有代码才算完整,在没有代码的的情况下为了保证语法的完整性可以用pass替代,例如:
if 条件 :
pass
else:
pass
# 没有动作时使用pass使代码块变得完整
for i in range(xxx):
pass
2.2 is比较
is 和 == 的区别是什么?
==,用于比较两个值是否相等- is,用于表示内存地址是否一致
# 示例1
v1 = []
v2 = []
print( v1 == v2 ) # True,两个值相当
print( v1 is v2 ) # False,不属于同一块内存。
# 示例2
v1 = []
v2 = v1
print( v1 == v2 ) # True,两个值相当
print( v1 is v2 ) # True,属于同一块内存。
# 示例3
v1 = None
v2 = None
print(v1 == v2) # True,两个值相当
print(v1 is v2) # True,属于同一块内存。
2.3 位运算
计算机底层本质上都是二进制,我们平时在计算机做的很多操作底层都会转换为二进制的操作,位运算就是对二进制的操作。
-
&与运算 (都为1,才为1)a = 60 # 60 = 0011 1100 b = 13 # 13 = 0000 1101 c = a & b # 12 = 0000 1100 -
|或运算 (只要有一个为1,结果就是1)a = 60 # 60 = 0011 1100 b = 13 # 13 = 0000 1101 c = a | b # 61 = 0011 1101 -
^,异或运算(a,b值不同为1,值相同还是0)a = 60 # 60 = 0011 1100 b = 13 # 13 = 0000 1101 c = a ^ b # 49 = 0011 0001 -
~取反a = 60 # 60 = 0011 1100 c = ~a; # -61 = 1100 0011 -
<<,左移动# 向左边移动两位,不够的通过加0 a = 60 # 60 = 0011 1100 c = a << 2; # 240 = 1111 0000 -
>>,右移动# 向右移动,把最右边两位删除 a = 60 # 60 = 0011 1101 c = a >> 2; # 15 = 0000 1111
平时在开发中,二进制的位运算几乎很少使用,在计算机底层 或 网络协议底层用的会比较多,例如:
-
计算 2**n
2**0 1 << 0 1 1 2**1 1 << 1 10 2 2**2 1 << 2 100 4 2**3 1 << 3 1000 8 ... # 2的几次方就向左移动几位 -
计算应该数的一般
v1 = 10 >> 1 print(v1) # 值为5 v2 = 20 >> 1 print(v2) # 值为 10 -
网络传输数据,文件太大还未传完,(websocket 源码为例)
第1个字节 第2个字节 ... 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-------+-+-------------+-------------------------------+ |F|R|R|R| opcode|M| Payload len | Extended payload length | |I|S|S|S| (4) |A| (7) | (16/64) | |N|V|V|V| |S| | (if payload len==126/127) | | |1|2|3| |K| | | +-+-+-+-+-------+-+-------------+ - - - - - - - - - - - - - - - + FIN位置是0,表示这是一部分数据,后续还有数据。 FIN位置是1,表示这是最后数据,已发送完毕。# 例如:接收到的第一个字节的值为245(11110101),让v的二进制和 1000 0000 做 & 与运算。 v = 245 # 245 11110101 # 128 10000000 10000000 data = v & 128 if data == 0: print("还有数据") else: print("已完毕")