【编译原理】9—代码优化与生成Code Optimization and Generation(基本块及其优化方法、数据流分析简介)
9 代码优化与生成Code Optimization and Generation
⭐⭐⭐⭐⭐⭐
Github主页https://github.com/A-BigTree
项目链接https://github.com/A-BigTree/college_assignment
⭐⭐⭐⭐⭐⭐
文章目录
- 9 代码优化与生成Code Optimization and Generation
-
- 9.1 优化的主要来源
-
- 源代码
- 中间代码
- 目标代码
- 代码优化器组织
- 9.2 基本块和流图
-
- 9.2.1 基本块
-
- 基本块划分
- 9.2.2 后续使用信息
-
- 名字的使用
- 9.2.3 流图
- 9.2.4 流图的表示方式
- 9.2.5 循环
- 9.3 基本块的优化
-
- 9.3.1 基本块的DAG表示
- 9.3.2 公共子表达式消除
- 9.3.3 复制传播
- 9.3.4 死代码消除
- 9.4 数据流分析
-
- 数据流抽象
编译器的代码优化和代码生成步骤通常比称为编译器的后端(back end),代码优化器和代码生成器的位置如下图:

9.1 优化的主要来源
Places for Potential Improvements
源代码
Source code
- 用户可以配置程序、更改算法或变换循环;
中间代码
Intermediate code
- 编译器可以改进循环、过程调用或地址计算;
目标代码
Target code
- 编译器可以使用寄存器、选择指令或执行窥视转换(Peephole transformation);
代码优化器组织
Organization of the code Optimizer

- 控制流分析(Control-flow analysis):识别程序流程图中的块和循环;
- 数据流分析(Data-flow analysis):收集有关整个程序的信息,并将这些信息分发到流程图(flow graph)中的每个块;
9.2 基本块和流图
Basic blocks and Flow graph
9.2.1 基本块
Basic blocks
把中间代码划分为基本块(basic block)。每个基本块是满足下列条件的最大的连续三地址码指令序列:
- 控制流只能从基本块中的第一个指令进入该块。也就是说,没有跳转到基本块中间的转移指令;
- 除了基本块的最后一条指令,控制流在离开基本块之前不会停机或者跳转;
基本块划分
Partition into Basic Blocks
- 输入:一个三地址指令序列;
- 输出:输入序列对应的一个基本块的列表,其中每个指令敲恰好被分配给基本块;
- 方法:首先,我们确定中间代码序列中哪些指令是 首指令(leader),即某个基本块的第一条指令。跟在中间程序末端之后的指令的不包含在首指令集合中。选择首指令的规则如下:
- 中间代码的第一个三地址指令是一个首地址;
- 任意一个条件或无条件转移指令之后的指令是一个首指令;
- ==紧跟==在一个条件或无条件转移指令之后的指令是一个首指令;
示例:
源码:
begin
read X;
read Y;
while (X mod Y<>0) do
begin
T:=X mod Y;
X:=Y;
Y:=T
end;
write Y
end
三地址码:
- (1)Read X
- (2)Read Y
- (3) T1:=X mod Y
- (4) If T1<>0 goto (6)
- (5)goto (10)
- (6)T:=X mod Y
- (7)X:=Y
- (8)Y:=T
- (9)goto (3)
- (10)write Y
- (11)halt
基本块划分如下:

9.2.2 后续使用信息
Next-Use Information
如果一个变量的值当前存放在一个寄存器中,且之后一直不会被使用,那么这个寄存器就可以被分派给另一个变量。
名字的使用
The Use of a Name
假设三地址语句i给x赋了一个值。如果语句j的一个运算分量为x,并且从语句i开始可以通过未对x进行的赋值的路径到达语句j,那么我们说语句j使用了在语句i处计算得到的x的值。
我们可以进一步说x在语句i处为活跃变量(Live variable)。
9.2.3 流图
Flow graph
当将一个中间代码程序划分成为基本块后,我们用一个流图来表示它们之间的控制流。流图的结点(nodes)就是这些基本块。
从基本块B到基本块C之间有一条边(edge)当且仅当基本块C的第一个指令可能紧跟在B的最后一个指令之后执行。存在这样一条边的原因有两种:
- 有一个从B的结尾跳转到C的开头的条件或无条件跳转语句;
- 按照原来的三地址语句序列中的顺序,C紧跟在B之后,且B的结尾不存在无条件跳转语句;
我们通常说B是C的前驱(predecessor),而C是B的一个后继(successor);
9.2.4 流图的表示方式
示例:
源码:
for i from 1 to 10 do
for j from 1 to 10 do
a[i,j]=0.0;
for i from 1 to 10 do
a[i,i]=1.0;
中间代码如下:

流图如下:

9.2.5 循环
Loops
因为事实上每个程序会花很多时间执行循环,所以对一个编译器来说,为循环生成优良的代码就变得非常重要。很多代码转换依赖于对流图中“循环”的识别。如果下列条件成立,我们就说流图中的一个结点集合L是一个循环。
- 在L中有一个被称为循环入口(loop entry)的结点,它是唯一的其前驱可能在L之外的结点。也就是说,从整个流图的入口结点开始到L中的任何结点的路径都必然经过循环入口结点,并且这个循环入口结点不是整个流图的入口结点本身;
- L中的每个结点都有一个到达L的入口结点的非空路径,并且该路径全部在L中;
上面示例的流图中有三个循环:
- B 3 B_3 B3自身
- B 6 B_6 B6自身
- { B 2 , B 3 , B 4 } \{B_2,B_3,B_4\} {B2,B3,B4}
9.3 基本块的优化
Optimization of Basic Blocks
9.3.1 基本块的DAG表示
DAG(有向无环图)
我们按照如下方式为一个基本块构造DAG:
- 基本块中出现的每个变量有一个对应的DAG的结点表示其初始化;
- 基本块中的每个语句s都有一个相关的结点N。N的子结点是基本块中的其他语句的对应结点。这些语句是在之前、最后一个对s所使用的某个运算分量进行定值的语句;
- 结点N的标号是s中的运算符;同时还有一组变量被关联到N,表示s是在此基本块内最晚对这些变量进行定值的语句;
- 某些结点被指明为输出结点(output node)。这些结点的变量在基本块的出口处活跃。也就是说,这些变量的值可能以后会在流图的另一个基本块中要被使用到;
对于基本块:
a = b + c;
b = a - d;
c = b + c;
d = a - d;
该基本块的DAG如下图:

9.3.2 公共子表达式消除
Common subexpression elimination
如果表达式E在某次出现之前已经被计算过,并且E中的变量的值从那次计算之后就一直没被改变,那么E的该次计算就称为一个公共子表达式(common subexpression)。如果将E的上一次计算结果赋予变量x,且x的值在中间没有被改变,那么我们就可以使用前面计算得到的值,从而避免重新计算E。
快速排序的代码片断的流图:
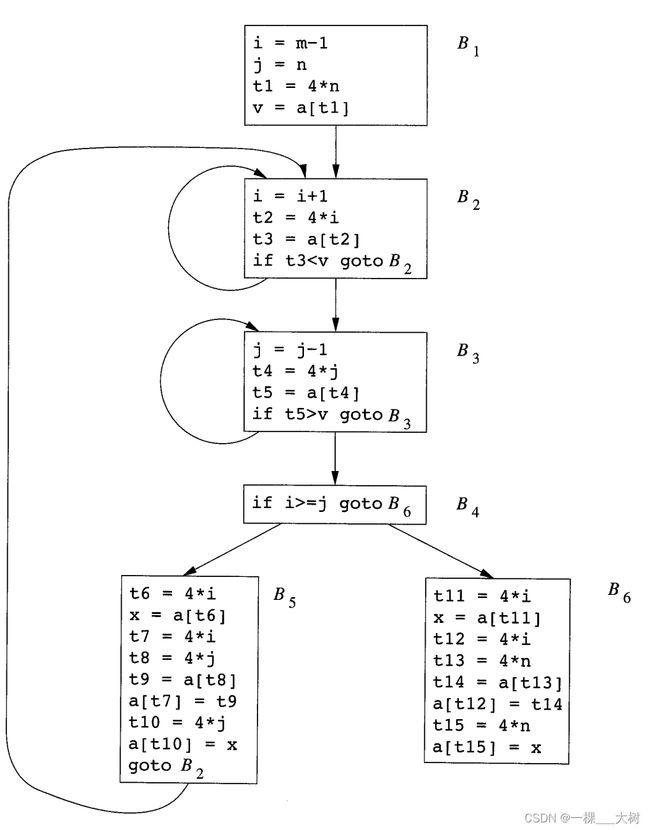
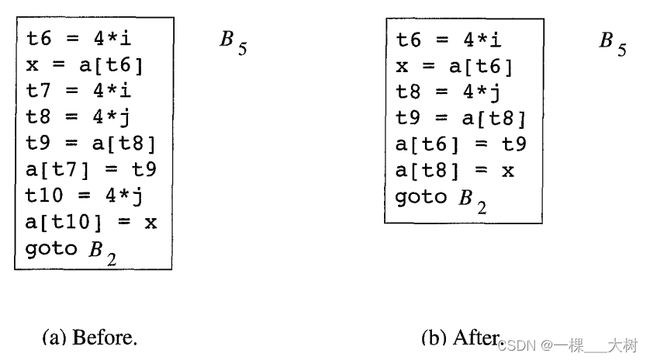
局部公共子表达式消除前后:
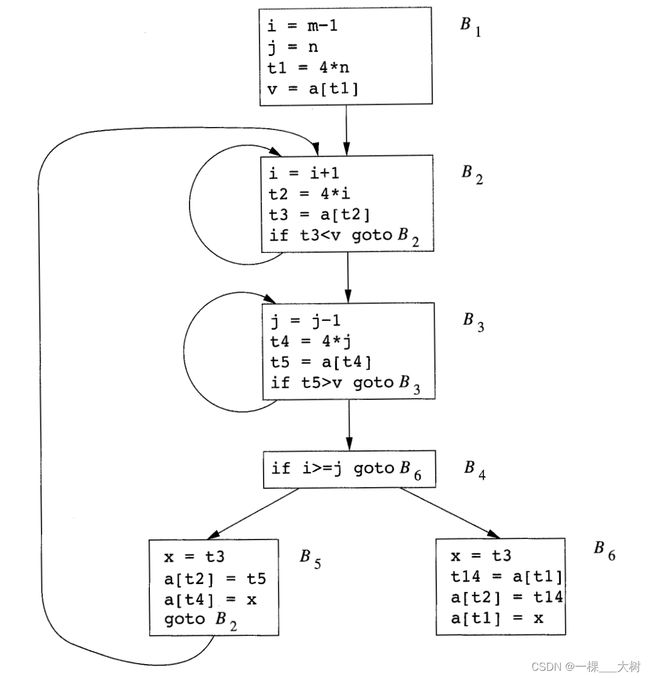
经过**公共子表达式消除**之后的 B 5 B_5 B5和 B 6 B_6 B6:
9.3.3 复制传播
Copy propagation
考虑形如u=v的赋值表达式,这种表达式被称为复制语句(copy statement),或者简称复制。因为常用的公共子表达式消除算法会引入这些复制语句,其他一些优化算法也会引起这样的语句。
在公共子表达式消除过程中引入的复制语句:

进行复制传播转换后的基本块 B 5 B_5 B5:

9.3.4 死代码消除
Dead Code Elimination
如果一个变量在某一程序点上的值可能会在以后被使用,那么我们就说这个变量在该点上活跃(live)。否则,它在该点上就是死的(dead)。与此相关的一个想法就是死(或者说无用)代码。所谓死代码就是其计算结果永远不会被使用的语句。程序员不大可能有意引入死代码,死代码多半是因为前面执行过的某些转换而造成的。
先进行复制传播再进行死代码消除,基本块 B 5 B_5 B5的进一步改进:

9.4 数据流分析
Data-flow analysis
上面介绍的所有优化都依赖于数据流分析。“数据流分析”指的是一组用来获取有关数据如何沿着程序执行路径流动的相关信息的技术。比如,实现全局公共子表达式消除的方法之一要求我们确定在程序的任何可能执行的路径上,两个在文字上相同的表达式是否会给出相同的值。另一个例子是,如果某一个赋值语句的结果在任何后续的执行路径中都没有被使用,那么我们可以把这个赋值语句当作死代码消除。
数据流抽象
The Data-Flow Abstraction
流图会给出可能执行路径的信息:
- 在一个基本块内部,一个语句之后的程序点和它的下一个语句之前的程序点相同;
- 如果有一个从基本块 B 1 B_1 B1到基本块 B 2 B_2 B2的边,那么 B 2 B_2 B2的第一个语句之前的程序点可能紧跟在 B 1 B_1 B1的最后一个语句后的程序点之后;
这样,我们可以把从点 p 1 p_1 p1到点 p n p_n pn的一个执行路径(excution path,简称路径)定义为满足下列条件的点的序列 p 1 , p 2 , … , p n p_1,p_2,\dots,p_n p1,p2,…,pn:对于每个 i = 1 , 2 , … , n − 1 i=1,2,\dots,n-1 i=1,2,…,n−1:
- 要么 p i p_i pi是紧靠在一个语句前面的点,且 p i + 1 p_{i+1} pi+1是紧跟在该语句后面的点;
- 要么 p i p_i pi是某个基本块的结尾,且 p i + 1 p_{i+1} pi+1是该基本块的一个后继基本块的开头;
下图说明数据流抽象的例子程序:
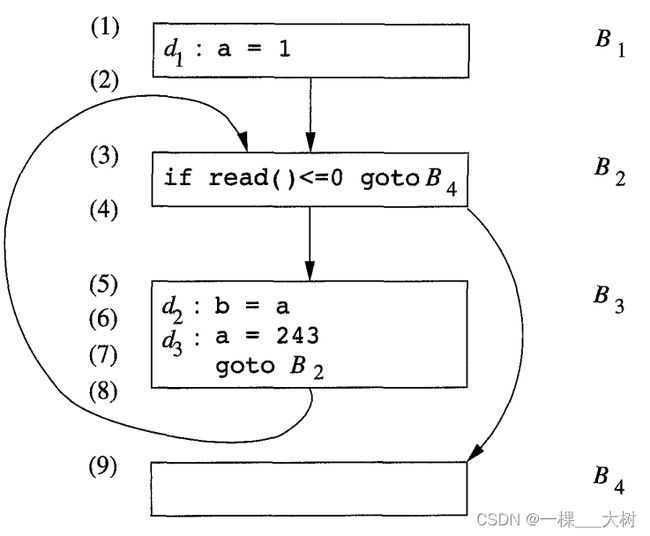
为了帮助用户调试他们的程序,我们可能希望找到在某个程序点上一个变量可能有哪些值,以及这些值可能在哪里定值。比如,我们可能对程序点(5)上的所有程序状态进行如下总结:a的值总是{1, 243}中的一个,而它有 { d 1 , d 2 } \{d_1,d_2\} {d1,d2}中的一个定值。可能沿着某些路径到达某个程序点的定值称为到达定值(reaching definition)。
⭐⭐⭐⭐⭐⭐
Github主页https://github.com/A-BigTree
项目链接https://github.com/A-BigTree/college_assignment
⭐⭐⭐⭐⭐⭐