适合小白学习的GAN(生成对抗网络)算法超详细解读
前言
“GANs are 'the coolest idea in deep learning in the last 20 years.' ”--Yann LeCunn, Facebook’s AI chief
今天我们就来认识一下这个传说中被誉为过去20年来深度学习中最酷的想法——GAN。
- GAN之父的主页:http://www.iangoodfellow.com/
- GAN论文地址:https://arxiv.org/pdf/1406.2661.pdf
目录
前言
一、GAN背景与简介
二、GAN原理
2.1生成器和判别器
2.2GAN的形成过程
2.3GAN的训练过程
三、GAN的特点及优缺点
☀️3.1特点
☀️3.2优点
☀️3.3缺点
四、各种各样的GAN
4.1DCGAN
4.2CGAN
4.3CycleGAN
五、GAN的实际应用
5.1图像生成
5.2文本生成
5.3语音生成

一、GAN背景与简介
在GAN算法出来之前, 由于之前的方法在最大似然估计和相关策略中出现的许多复杂的概率计算,得到的结果难以近似,所以关于图像生成的任务表现一直都不太好。
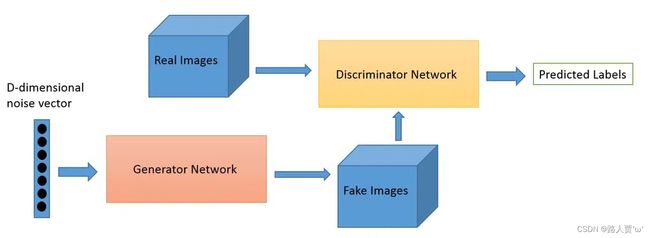
2014年10月,Ian J. Goodfellow等人在Generative Adversarial Networks中提出了一个通过对抗过程估计生成模型的新框架——GAN(Generative adversarial network),GAN其实是两个网络的组合:生成器(Generator)负责生成模拟数据;判别器(Discriminator)负责判断输入的数据是真实的还是生成的。生成器要不断优化自己生成的数据让判别网络判断不出来,判别器也要优化自己让自己判断得更准确。二者关系形成对抗,因此叫对抗网络。
在GAN的原作中,作者将生成器比喻为印假钞票的犯罪分子,判别器则类比为警察。犯罪分子努力让钞票看起来逼真,警察则不断提升对于假钞的辨识能力。二者互相博弈,随着时间的进行,都会越来越强。那么类比于图像生成任务,生成器不断生成尽可能逼真的假图像。判别器则判断图像是否是真实的图像,还是生成的图像,二者不断博弈优化。最终生成器生成的图像使得判别器完全无法判别真假。
二、GAN原理
关于GAN的原理,网上有太多文章,但大部分都是直接放一堆公式开始从头推。知道大家也不爱看,所以放心~本文不会放一堆公式,只是提供一种简单的理解思路。如果想深入研究的,可以看看别的博主的文章噢~
2.1生成器和判别器
首先介绍一下机器学习中两类模型:生成模型(Generative Model)和判别模型(Discriminative Model)。
- 生成模型:需要给定某种特征信息,来随机产生新的观测数据。
- 判别模型:需要输入特定变量 ,通过该模型来预测 。
举个栗子:
- 生成模型:给一堆猫的图片,生成一张新的猫咪(不在数据集里)。
- 判别模型:给定一张图,判断这张图里的动物是猫还是狗。
对于判别模型,损失函数是容易定义的,因为输出的目标相对简单。但对于生成模型,损失函数的定义就不是那么容易。我们对于生成结果的期望,往往是一个暧昧不清,难以数学公理化定义的范式。所以不妨把生成模型的回馈部分,交给判别模型处理。这就是Goodfellow将机器学习中的两大类模型,Generative和Discrimitive给紧密地联合在了一起 。
GAN有两大法宝——G和D:
①生成器(Generator):
- 作用:负责凭空编造假的数据出来。
- 详细解释:通过机器生成假的数据(大部分情况下是图像),最终目的是“骗过”判别器。
- 过程:G是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。
②判别器(Discriminator):
- 作用:负责判断传来的数据是真还是假。
- 详细解释:判断这张图像是真实的还是机器生成的,目的是找出生成器做的“假数据”。
- 过程:D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
2.2GAN的形成过程
在训练过程中,生成器G的目标就是尽量生成真实的图片去欺骗判别器D,而判别器D则努力地去识别出图像的真假,这样,G和D构成了一个动态的“博弈过程”。随着时间的推移,生成器和判别器在不断地进行对抗,如下图所示:

接下来我们解释一下上图:
- z:随机噪声(就是随机生成的一些数,也就是GAN生成图像的源头)。
- D:通过真图和假图的数据,进行一个二分类神经网络训练,得出true和fack。
- G:根据一串随机数就可以捏造一个“假图像”出来,用这些假图去欺骗D,D负责辨别这是真图还是假图,会给出一个score。
比如,G生成了一张图,在D这里得分很高,那证明G是很成功的;如果D能有效区分真假图,则G的效果还不太好,需要调整参数。在最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 1。
这样我们的目的就达成了:我们得到了一个生成式的模型G,它可以用来生成图片。
2.3GAN的训练过程
GAN的训练过程如下:
- 随机生成一组潜在向量z,并使用生成器生成一组假数据。
- 将一组真实数据和一组假数据作为输入,训练判别器。
- 使用生成器生成一组新的假数据,并训练判别器。
- 重复步骤2和3,直到生成器生成的假数据与真实数据的分布相似。
如下图所示:
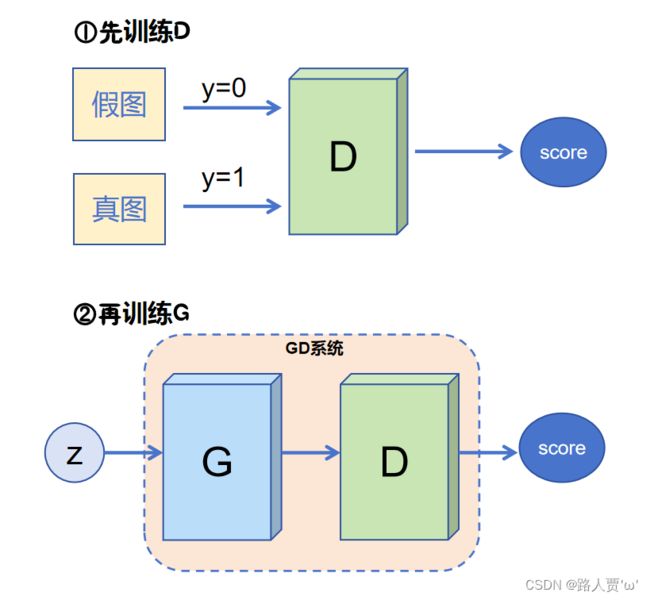
(1)先训练D
上一轮G产生的图片和真实图片直接拼接在一起,作为x。然后根据顺序摆放0和1,假图对应0,真图对应1。然后就可以通过x输入生成一个score(从0到1之间的数),通过score和y组成的损失函数,就可以进行梯度反传了。
(2)再训练G
这时需要把G和D当作一个整体,我们就叫DG系统吧,这个系统的输出仍然是score。输入一组随机向量,就可以在G生成一张图,通过D对生成的这张图进行打分,这就是DG系统的前向过程。score=1就是DG系统需要优化的目标,score和y=1之间的差异可以组成损失函数,然后可以反向传播梯度。注意,这里的D的参数是不可训练的。这样就能保证G的训练是符合D的打分标准的。
三、GAN的特点及优缺点
☀️3.1特点
- 相比较传统的模型,GAN存在两个不同的网络,而不是单一的网络,并且训练方式采用的是对抗训练方式。
- GAN中G的梯度更新信息来自判别器D,而不是来自数据样本。
☀️3.2优点
- GAN是一种生成式模型,相比较其他生成模型(玻尔兹曼机和GSNs)只用到了反向传播,而不需要复杂的马尔科夫链。
- 相比其他所有模型,GAN可以产生更加清晰,真实的样本。
- GAN采用的是一种无监督的学习方式训练,可以被广泛用在无监督学习和半监督学习领域。
- 相比于变分自编码器,GAN没有引入任何决定性偏置( deterministic bias),变分方法引入决定性偏置,因为他们优化对数似然的下界,而不是似然度本身,这看起来导致了VAEs生成的实例比GANs更模糊。
- 相比VAE, GANs没有变分下界,如果鉴别器训练良好,那么生成器可以完美的学习到训练样本的分布。换句话说,GANs是渐进一致的,但VAE是偏差的。
- GAN应用到一些场景上,比如图片风格迁移,超分辨率,图像补全,去噪,避免了损失函数设计的困难,不管三七二十一,只要有一个的基准,直接上判别器,剩下的就交给对抗训练了。
☀️3.3缺点
- 训练GAN需要达到纳什均衡,有时候可以用梯度下降法做到,有时候做不到。我们还没有找到很好的达到纳什均衡的方法,所以,但我认为在实践中它还是比训练玻尔兹曼机稳定的多训练GAN相比VAE或者PixelRNN是不稳定的。
- GAN不适合处理离散形式的数据,比如文本。
四、各种各样的GAN
4.1DCGAN
DCGAN是最有名的GAN网络:

技术要点:
- 将max-pooling替换为卷积层,保住了spatial information,提升了image quality。
- 用transposed convolution(逆卷积)来进行 upsampling 上采样。
- 全面消除全连接层。
- 全面采用batch normalization (BN)。
4.2CGAN
原本GAN网络的输入时一个N*1维的高斯噪声,每一维经过映射能控制生成的什么信息,就没有人知道。于是,有人就像把其中一个维度不再输入噪声,而是训练数据的label信息,这样通过这个label值我们就能生成不同种类的图像了,这就是 Conditional GAN (CGAN)。
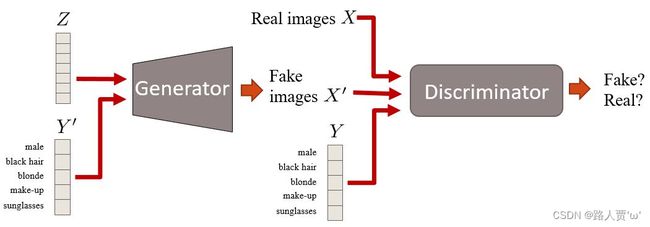
4.3CycleGAN
pix2pix必须使用成对的数据进行训练。但很多情况下成对数据是很难获取到的,比如说,我们想把马变成斑马,现实生活中是不存在对应的真实照片的。
现在我们就用Cycle-constraint Adversarial Network也就是CycleGAN解决这个问题。这种网络不需要成对的数据,只需要输入数据的一个集合(比如一堆马的照片)和输出数据的一个集合(比如一堆斑马的照片)就可以了。
但是直接使用不成对的数据是不奏效的。网络会直接忽略输入,随机产生输出!所以,我们还得对网络增加限制(constraint)才行。
那怎么加限制呢?除了之前提到的把马变成斑马的网络G,我们还需要一个把斑马变回马的网络F。那么,一匹马x用G变成斑马s = G ( x ) ,然后再用F把它变回马F ( s ),得到的马和一开始的马应该是一样的,也就是x = F ( G ( x ) ) 。
反过来,斑马变马再变回斑马也要满足要求,注意这一步最好不要省略。虽然理论上只用一个条件是可以的,但是现实实现中,有很多因素,比如计算的准备度,优化的问题,应用中都是把所有约束都加上。
我们同时优化G和F,最后就能拿到一个想要的网络G。
剩下的不再详细介绍,大家感兴趣的可以自己看论文:
(表格来源:一文看懂「生成对抗网络 - GAN」基本原理+10种典型算法+13种应用)
| 算法 | 论文 | 代码 |
|---|---|---|
| GAN | 论文地址 | 代码地址 |
| DCGAN | 论文地址 | 代码地址 |
| CGAN | 论文地址 | 代码地址 |
| CycleGAN | 论文地址 | 代码地址 |
| CoGAN | 论文地址 | 代码地址 |
| ProGAN | 论文地址 | 代码地址 |
| WGAN | 论文地址 | 代码地址 |
| SAGAN | 论文地址 | 代码地址 |
| BigGAN | 论文地址 | 代码地址 |
还有各个GAN的loss function:
(图片来源:一篇文章弄懂GAN网络 - 知乎 (zhihu.com))

五、GAN的实际应用
GAN在图像生成、文本生成、语音生成等领域都取得了广泛的应用。以下是GAN在一些应用场景中的应用实例:
5.1图像生成
GAN在图像生成中的应用最为广泛。通过训练一个生成器和一个判别器,可以生成高质量、多样性的图像。以下是一些GAN在图像生成中的应用实例:
(1) DeepFake技术
DeepFake技术是一种基于GAN的图像合成技术,可以将一个人的脸部特征转移到另一个人的脸上,从而实现人脸替换。该技术在娱乐、影视等领域具有广泛的应用。

(2)图像修复
GAN可以通过学习原始图像和损坏图像之间的差异,生成高质量的修复图像。这种技术在医疗、保险等领域具有广泛的应用。

5.2文本生成
GAN可以生成高质量、多样性的文本,具有广泛的应用场景。以下是一些GAN在文本生成中的应用实例:
(1)对话系统
GAN可以通过学习用户的输入和输出,生成具有上下文连贯性的对话内容,从而实现人机对话。这种技术在智能客服、智能助手等领域具有广泛的应用。
(2)文本摘要
GAN可以通过学习原始文本和摘要之间的差异,生成高质量的文本摘要。这种技术在新闻、金融等领域具有广泛的应用。
5.3语音生成
GAN可以生成高质量、自然的语音,具有广泛的应用场景。以下是一些GAN在语音生成中的应用实例:
(1)语音合成
GAN可以通过学习语音信号和语音文本之间的关系,生成自然的语音。这种技术在智能客服、智能助手等领域具有广泛的应用。
(2)语音转换
GAN可以将一种语音转换成另一种语音,例如将男声转换为女声,或者将中文语音转换成英文语音。这种技术在语音翻译、语音识别等领域具有广泛的应用。
