【ES使用】Java API操作ES宝典(8.x版本)
大家好,我是老坛。
本篇文章全部代码资源请关注同名公众号:老坛聊开发
回复:"8.x模板" 即可获取
Elasticsearch是一个分布式的RESTful 风格的搜索和数据分析引擎,它使用方便,查询速度快,因此也被越来越多的开发人员使用。
在Java项目中,使用ES的场景也十分常见。除了作为某些特定资源的存储之外也可以作为像ELK这样的日志收集系统里的存储引擎。总之,对于非关系型而查找需求较多的场景,ES的表现还是非常不错的。
本篇文章介绍的是8.x版本的ES相关Java API操作,如果你使用的版本是7.x及其以下的话可以去看我的另一篇文章:
【ES使用】Java API操作ES宝典(7.x版本及其以下) https://blog.csdn.net/qq_34263207/article/details/127793370
https://blog.csdn.net/qq_34263207/article/details/127793370
目录
1. 准备工作
1.1 引入依赖
1.2 配置文件
2. ES操作
2.1 简单操作
2.1.1 插入数据
2.1.2 查询数据
2.1.3 修改数据
2.1.4 删除数据
2.2 复杂查询
2.2.1 match查询
2.2.2 term查询
2.2.3 match_phrase查询
2.2.4 multi_match查询
2.2.5 fuzzy查询
2.2.6 range查询
2.2.7 bool查询
2.3 排序和分页
3.代码模板
4.总结
1. 准备工作
在使用api之前,需要进行一些准备工作。这里我们要进行依赖的引入与config配置文件的编写。
1.1 引入依赖
从8.x开始,spring boot data目前还是不支持的,需要所以没有starter来给我们引入,这里需要引入的是两个其它的依赖:
co.elastic.clients
elasticsearch-java
8.1.1
jakarta.json
jakarta.json-api
2.0.1
8.1.1版本我用起来是没有问题的,8.0.1版本我用起来会报错,目前也没有查到原因,大家和我引入的版本保持一致即可。
这里我默认大家使用的都是spring的环境,如果没有引入spirng-web包的小伙伴请再自行引入jackson-core包!
关于不同版本的ES和Java API版本对应关系大家可以查阅我的这篇文章:
【ES知识】es版本与java api版本对照一览https://blog.csdn.net/qq_34263207/article/details/127790216
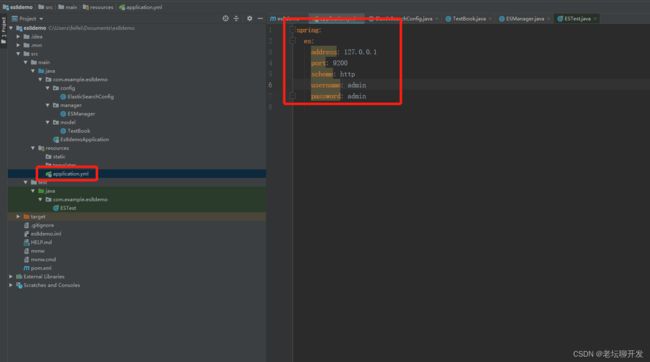
1.2 配置文件
我们先在yml里写一下ES相关的配置信息,方便config使用:
es:
address: 127.0.0.1
port: 9200
scheme: http
username: admin
password: admin然后写一下config文件:
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.json.jackson.JacksonJsonpMapper;
import co.elastic.clients.transport.ElasticsearchTransport;
import co.elastic.clients.transport.rest_client.RestClientTransport;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.impl.nio.client.HttpAsyncClientBuilder;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticSearchConfig {
@Value("${spring.es.address}")
String address;
@Value("${spring.es.port}")
Integer port;
@Value("${spring.es.scheme}")
String scheme;
@Value("${spring.es.username}")
String username;
@Value("${spring.es.password}")
String password;
@Bean
public ElasticsearchClient esRestClientWithCred(){
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
// 配置连接ES的用户名和密码,如果没有用户名和密码可以不加这一行
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(username, password));
RestClientBuilder restClientBuilder = RestClient.builder(new HttpHost(address, port, scheme))
.setHttpClientConfigCallback(new RestClientBuilder.HttpClientConfigCallback() {
@Override
public HttpAsyncClientBuilder customizeHttpClient(HttpAsyncClientBuilder httpAsyncClientBuilder) {
return httpAsyncClientBuilder.setDefaultCredentialsProvider(credentialsProvider);
}
});
RestClient restClient = restClientBuilder.build();
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
ElasticsearchClient client = new ElasticsearchClient(transport);
return client;
}
}
大家直接粘走使用即可,亲测可用。
2. ES操作
我将ES操作定义为了简单操作和复杂操作两部分。简单操作主要是围绕ES的id去做增删改查,而复杂操作是进行复杂查询时候所用到的。
2.1 简单操作
该部分主要是针对id去对ES做了增删改查,而这里的API使用到的类也比较有特点,我简单画了一张图方便大家理解:

可以看到,我们的所有操作都是基于ElasticsearchClient的,而该client定义在之前我们的config里面,要用到的时候注入过来就好了。对于增删改查的每一种操作,都有相应的request和response类来给我们使用,因为对于ES的操作本质上还是发送http请求。
更多优质文章资源请关注同名公众号:老坛聊开发
先介绍一下我用到的实体对象:
@Data
public class TextBook {
String bookName;
String author;
Integer num;
}2.1.1 插入数据
@SpringBootTest
@Slf4j
public class ESTest {
@Resource
ElasticsearchClient client;
String index = "textbook";
@Test
public void insertSingle() throws IOException {
// 创建要插入的实体
TextBook textBook = new TextBook();
textBook.setBookName("老坛聊开发");
textBook.setEdition("老坛");
textBook.setEditionTime("20221109");
// 方法一
IndexRequest相比于7.x版本的api,这里使用了builder的方式来创建request,但实际上结合java8的lambda表达式可以写的更清爽:
@SpringBootTest
@Slf4j
public class ESTest {
@Resource
ElasticsearchClient client;
String index = "textbook";
@Test
public void insertSingle() throws IOException {
// 创建要插入的实体
TextBook textBook = new TextBook();
textBook.setBookName("老坛聊开发");
textBook.setEdition("老坛");
textBook.setEditionTime("20221109");
// 方法二
IndexResponse indexResponse2 = client.index(b -> b
.index(index)
.document(textBook)
);
}
}用这种方式我们甚至都不用管中间的一些类和过程,直接就可以从client出发完成整个流程拿到response,这也是我用了8.x的api后最为惊艳的地方,这里我也建议大家这样去写,非常简洁快速,后面的各种操作我也会用这种方式来书写。
2.1.2 查询数据
@SpringBootTest
@Slf4j
public class ESTest {
@Resource
ElasticsearchClient client;
String index = "textbook";
@Test
public void grepSingle(String id) throws IOException {
GetResponse response = client.get(g -> g
.index(index)
.id(id),
TextBook.class
);
if (response.found()) {
TextBook textBook = response.source();
log.info("返回结果 " + JSON.toJSONString(textBook));
} else {
log.info ("textBook not found");
}
}
} 这里我们使用GetResponse时要先指定一个泛型,就是我们要查询的实体,同时该类型也作为参数传入查询方法中。
这里使用了GetResponse的found方法先确认一下是否取到了数据,取到了就可以进行获取。
2.1.3 修改数据
@SpringBootTest
@Slf4j
public class ESTest {
@Resource
ElasticsearchClient client;
String index = "textbook";
@Test
public void updateSingle(String id) throws IOException {
// 创建要更新的实体
TextBook textBook = new TextBook();
textBook.setBookName("老坛聊开发");
textBook.setEdition("老坛");
textBook.setEditionTime("20221109");
UpdateResponse updateResponse = client.update(u -> u
.doc(textBook)
.id(id),
TextBook.class
);
}
}2.1.4 删除数据
@SpringBootTest
@Slf4j
public class ESTest {
@Resource
ElasticsearchClient client;
String index = "textbook";
@Test
public void deleteSingle(String id) throws IOException {
DeleteResponse deleteResponse = client.delete(d -> d
.index(index)
.id(id)
);
}
}2.2 复杂查询
下面介绍一下ES的复杂查询,也是我们使用更多一些的查询方式,这里面和ES的语法会结合的更紧密一些,强烈建议大家有一定的ES语法基础之后再来阅读。关于ES的基础语法的学习大家可以看我的这篇文章:
【ES知识】ES基础查询语法一览https://blog.csdn.net/qq_34263207/article/details/127849806
有了labmda表达式的简化加成,这部分相比于7.x的api清爽了相当多,任何形式的查询真的都是一行代码搞定。
2.2.1 match查询
@SpringBootTest
@Slf4j
public class ESTest {
@Resource
ElasticsearchClient client;
String index = "textbook";
@Test
public void grepTextBook() throws IOException {
SearchResponse matchSearch = client.search(s -> s
.index(index)
.query(q -> q
.match(t -> t
.field("bookName")
.query("老坛")
)
),
TextBook.class);
for (Hit hit: matchSearch.hits().hits()) {
TextBook pd = hit.source();
System.out.println(pd);
}
}
} 对应了ES的match查询,它等价的ES语法就是:
GET textbook/_search
{
"query": {
"match": {
"bookName":"老坛"
}
}
}大家还可以发现这种写法的另一个好处就是写起来更像是去写原生的ES查询命令了,隐藏了Java API复杂各种类和中间过程的使用。
2.2.2 term查询
@SpringBootTest
@Slf4j
public class ESTest {
@Resource
ElasticsearchClient client;
String index = "textbook";
@Test
public void grepTextBook() throws IOException {
SearchResponse termSearch = client.search(s -> s
.index(index)
.query(q -> q
.term(t -> t
.field("bookName")
.value("老坛")
)
),
TextBook.class);
for (Hit hit: termSearch.hits().hits()) {
TextBook pd = hit.source();
System.out.println(pd);
}
}
} 对应了ES的term查询,它等价的ES语法就是:
GET textbook/_search
{
"query": {
"term": {
"bookName":"老坛"
}
}
}2.2.3 match_phrase查询
@SpringBootTest
@Slf4j
public class ESTest {
@Resource
ElasticsearchClient client;
String index = "textbook";
@Test
public void grepTextBook() throws IOException {
SearchResponse matchPhraseSearch = client.search(s -> s
.index(index)
.query(q -> q
.matchPhrase(m -> m
.field("bookName")
.query("老坛")
)
),
TextBook.class);
for (Hit hit: matchPhraseSearch.hits().hits()) {
TextBook pd = hit.source();
System.out.println(pd);
}
}
} 对应了ES的match_phrase查询,它等价的ES语法就是:
更多优质文章资源请关注同名公众号:老坛聊开发
GET textbook/_search
{
"query": {
"match_phrase": {
"bookName":"老坛"
}
}
}2.2.4 multi_match查询
@SpringBootTest
@Slf4j
public class ESTest {
@Resource
ElasticsearchClient client;
String index = "textbook";
@Test
public void grepTextBook() throws IOException {
SearchResponse multiMatchSearch = client.search(s -> s
.index(index)
.query(q -> q
.multiMatch(m -> m
.query("老坛")
.fields("author", "bookName")
)
),
TextBook.class);
for (Hit hit: multiMatchSearch.hits().hits()) {
TextBook pd = hit.source();
System.out.println(pd);
}
}
} 对应了ES的multi_match查询,它等价的ES语法就是:
GET textbook/_search
{
"query": {
"multi_match": {
"query": "老坛",
"fields": ["author","bookName"]
}
}
}2.2.5 fuzzy查询
@SpringBootTest
@Slf4j
public class ESTest {
@Resource
ElasticsearchClient client;
String index = "textbook";
@Test
public void grepTextBook() throws IOException {
SearchResponse fuzzySearch = client.search(s -> s
.index(index)
.query(q -> q
.fuzzy(f -> f
.field("bookName")
.fuzziness("2")
.value("老坛")
)
),
TextBook.class);
for (Hit hit: fuzzySearch.hits().hits()) {
TextBook pd = hit.source();
System.out.println(pd);
}
}
} 对应了ES的fuzzy查询,它等价的ES语法就是:
GET textbook/_search
{
"query": {
"fuzzy": {
"bookName":{
"value":"老坛",
"fuzziness":2
}
}
}
}2.2.6 range查询
@SpringBootTest
@Slf4j
public class ESTest {
@Resource
ElasticsearchClient client;
String index = "textbook";
@Test
public void grepTextBook() throws IOException {
SearchResponse rangeSearch = client.search(s -> s
.index(index)
.query(q -> q
.range(r -> r
.field("bookName")
.gt(JsonData.of(20))
.lt(JsonData.of(20))
)
),
TextBook.class);
for (Hit hit: rangeSearch.hits().hits()) {
TextBook pd = hit.source();
System.out.println(pd);
}
}
} 对应了ES的range查询,它等价的ES语法就是:
GET textbook/_search
{
"query": {
"range": {
"num": {
"gt":20,
"lt":30
}
}
}
}2.2.7 bool查询
@SpringBootTest
@Slf4j
public class ESTest {
@Resource
ElasticsearchClient client;
String index = "textbook";
@Test
public void grepTextBook() throws IOException {
SearchResponse boolSearch = client.search(s -> s
.index(index)
.query(q -> q
.bool(b -> b
.must(m -> m
.term(t -> t
.field("author")
.value("老坛")
)
)
.should(sh -> sh
.match(t -> t
.field("bookName")
.query("老坛")
)
)
)
),
TextBook.class);
for (Hit hit: boolSearch.hits().hits()) {
TextBook pd = hit.source();
System.out.println(pd);
}
}
} 对应了ES的bool查询,它等价的ES语法就是:
GET textbook/_search
{
"query":{
"bool":{
"should":{
"match":{
"bookName":"老坛"
}
},
"must":{
"term":{
"author":"老坛"
}
}
}
}
}2.3 排序和分页
排序和分页直接像ES的语法一样,体现在和query的平级即可。这里已match为例进行介绍。
@SpringBootTest
@Slf4j
public class ESTest {
@Resource
ElasticsearchClient client;
String index = "textbook";
@Test
public void grepTextBook() throws IOException {
SearchResponse matchSearch = client.search(s -> s
.index(index)
.query(q -> q
.match(t -> t
.field("bookName")
.query("老坛")
)
)
.from(1)
.size(100)
.sort(so -> so
.field(f -> f
.field("num")
.order(SortOrder.Desc)
)
),
TextBook.class);
for (Hit hit: matchSearch.hits().hits()) {
TextBook pd = hit.source();
System.out.println(pd);
}
}
} 这是一个根据num字段进行降序排序的查询,按页容量为100对数据进行分页,取第二页数据。
它等价的ES语法就是:
GET textbook/_search
{
"query":{
"match":{
"bookName":"老坛"
}
},
"from":1,
"size":100,
"sort":{
"num":{
"order":"desc"
}
}
}3.代码模板
本篇文章中介绍的全部es操作老坛已整理成模板项目了:

请关注同名公众号:老坛聊开发
并回复:"8.x模板" 获取代码模板
只要大家根据自己的实际环境修改配置即可直接跑起来啦,亲测有效!
4.总结
到这里Java对ES的操作基本上聊的差不多了,题主这里介绍的未必详尽,只是一些我们通常会用到的操作,如果还想详细了解更多的内容请阅读官方文档:
Javadoc and source code | Elasticsearch Java API Client [8.5] | Elastic
另外,题主这里只是为了给大家讲明白如何使用举了几个例子,并不一定效率最高或者使用常见最为恰当,还是需要大家学习一下ES的语法根据自己的实际业务场景去选用,谢谢大家~