爬虫(三)爬取男人装的图片以及正则表达式的用法
首先分析网站的url
导入re,requests模块
import requests
import re
#目标网址的url
url='http://enrz.com/fhm/2017/12/27/99997.html'
#伪装的请求头
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
#获取url里面的源代码
response=requests.get(url=url,headers=headers)
#将源代码转码
info=response.content.decode('utf-8')
将左下角的鼠标放到图片上点击,我们就可以转到图片的地址
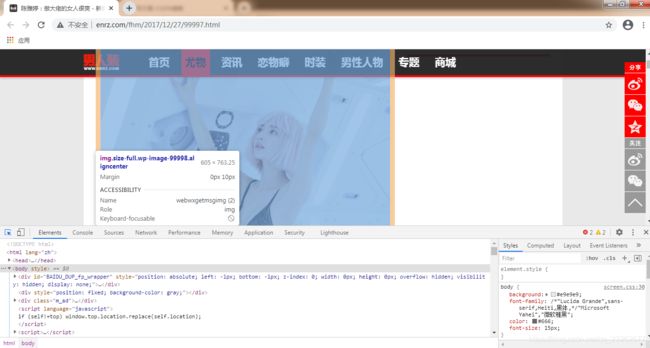
我们找到图片的那个地址,复制到代码中
![]()
import requests
import re
#通用匹配符 ----(.*?)----需要提取的内容
# .*? ---- 是需要省略的内容
#目标网址的url
url='http://enrz.com/fhm/2017/12/27/99997.html'
#伪装的请求头
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
response=requests.get(url=url,headers=headers)
info=response.content.decode('utf-8')
png=' '
'
接下来我们用正则表达式去替代内容,替代完之后。
import requests
import re
#通用匹配符 ----(.*?)----需要提取的内容
# .*? ---- 是需要省略的内容
#目标网址的url
url='http://enrz.com/fhm/2017/12/27/99997.html'
#伪装的请求头
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
response=requests.get(url=url,headers=headers)
info=response.content.decode('utf-8')
png=') '
'
接下来我们用re正则中的findall向下寻找所有。
import requests
import re
#通用匹配符 ----(.*?)----需要提取的内容
# .*? ---- 是需要省略的内容
#目标网址的url
url='http://enrz.com/fhm/2017/12/27/99997.html'
#伪装的请求头
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
response=requests.get(url=url,headers=headers)
info=response.content.decode('utf-8')
png=''
png_list=re.findall(png,info)
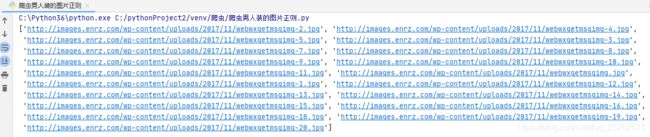
接下来我们先创建一个文件夹用来储存照片,导入os模块
import os
#判断文件夹是否创建
if not os.path.exists('tupian'):
os.mkdir('tupian')
print('正在创建')
else:
print('已创建,正在覆盖')
接下来我们要将爬取的图片导入我们的文件夹内
num=0
#遍历列表
for item in png_list:
#访问遍历出来的链接
itea=requests.get(item).content
#打开文件夹tupian,tupian/ 指tupian下的 /指的是下的意思 用占位符创建文件的名字
with open('tupian/%s.jpg'%num,'wb') as rfile:
#将内容写入文件夹下
rfile.write(itea)
num+=1
print(f'正在爬取第{num}张'
至此我们就可以在文件夹中看到爬取下来的图片啦!

最后附上程序完整代码
import requests
import re
import os
#通用匹配符 ----(.*?)----需要提取的内容
# .*? ---- 是需要省略的内容
#目标网址的url
url='http://enrz.com/fhm/2017/12/27/99997.html'
#伪装的请求头
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
response=requests.get(url=url,headers=headers)
info=response.content.decode('utf-8')
png=''
#()中的两个参数 第一个png指的是向下寻找与png相匹配的内容,那么在哪里找呢,在info这个转码完之后的源代码里面找 所以写的是(png,info)
png_list=re.findall(png,info)
#判断文件夹是否创建
if not os.path.exists('tupian'):
os.mkdir('tupian')
print('正在创建')
else:
print('已创建,正在覆盖')
#遍历列表
num=0
for item in png_list:
#访问遍历出来的链接
itea=requests.get(item).content
#打开文件夹tupian,tupian/ 指tupian下的 /指的是下的意思 用占位符创建文件的名字
with open('tupian/%s.jpg'%num,'wb') as rfile:
#将内容写入文件夹下
rfile.write(itea)
num+=1
print(f'正在爬取第{num}张')
看完的点个赞吧,喜欢的可以点点关注!
