【LMM 014】NExT-GPT:能够输入和生成任意模态的多模态大模型
论文标题:NExT-GPT:Any-to-Any Multimodal Large Language Model
论文作者:Shengqiong Wu, Hao Fei*, Leigang Qu, Wei Ji, Tat-Seng Chua
作者单位: NExT++ Lab, National University of Singapore
论文原文:https://arxiv.org/abs/2309.05519
论文出处:–
论文被引:57(01/05/2024)
项目主页:https://next-gpt.github.io/
论文代码:https://github.com/NExT-GPT/NExT-GPT
Abstract
虽然多模态大语言模型(MM-LLMs)最近取得了令人振奋的进展,但它们大多受限于只能理解输入端的多模态,而无法生成多种模态的内容。由于人类总是通过各种模态感知世界并与人交流,因此开发能够接受和提供任何模态内容的 any-to-any MM-LLM 对人类级人工智能至关重要。为了填补这一空白,我们提出了一种端到端的通用任意 MM-LLM 系统 NExT-GPT。我们将 LLM 与多模态适配器和不同的扩散解码器连接起来,使 NExT-GPT 能够感知输入,并以文本,图像,视频和音频的任意组合生成输出。通过利用现有的训练好的高性能编码器和解码器,NExT-GPT 只需对某些投影层进行少量参数(1%)的微调,这不仅有利于降低训练成本,还能方便地扩展到更多潜在模态。此外,我们还引入了模态切换指令微调(Modality-switching Instruction Tuning,MosIT),并手动为 MosIT 构建了一个高质量的数据集,在此基础上,NEXT-GPT 具备了复杂的跨模态语义理解和内容生成能力。总之,我们的研究展示了构建能够模拟通用模态的统一人工智能Agent的可能性,为社区中更多的类人人工智能研究铺平了道路。
1 Introduction
最近,人工智能生成内容(AIGC)在某些技术上取得了前所未有的进展,例如文本生成的 ChatGPT [59] 和视觉生成的扩散模型 [21]。其中,大型语言模型(LLMs)的崛起尤为引人注目,如 Flan-T5 [13],Vicuna [12],LLaMA [80] 和 Alpaca [79],展示了其强大的人类水平的语言推理和决策能力,为人工通用智能(AGI)的发展指明了道路。我们的世界本质上是多模态的,人类通过不同的感觉器官感知世界,获取不同的模态信息,如语言,图像,视频和声音,这些信息往往相辅相成,相互协同。基于这样的直觉,纯文本的 LLM 最近被赋予了视觉,视频,音频等其他模态的理解和感知能力。
一种值得注意的方法是使用适配器(Adapter),将其他模态的预训练编码器与文本 LLM 相匹配。这一努力推动了多模态 LLM(MM-LLM)的快速发展,如 BLIP-2 [43],Flamingo [1],MiniGPT-4 [109],Video-LaMA [103],LLaVA [52],PandaGPT [77],SpeechGPT [102]。然而,这些研究大多只关注输入端的多模态内容理解,缺乏输出文本以外的多种模态内容的能力。我们强调,真实的人类认知和交流不可或缺地需要任何信息模态之间的无缝转换。因此,探索任意对任意的 MM-LLM 对于实现真正的 AGI(即接受任意模态的输入并以任意模态的适当形式提供响应)至关重要。
为了模仿人类的任意模态转换,人们做出了一些努力。
- 最近,CoDi[78] 在实现同时处理和生成任意模态组合的能力方面取得了长足进步,但它的核心缺乏 LLM 的推理和决策能力,而且也仅限于简单的配对内容生成。
- 另一方面,一些研究(如 Visual-ChatGPT [88] 和 HuggingGPT [72] )试图将 LLM 与外部工具相结合,以实现近似任意对任意(any-to-any)的多模态理解和生成。遗憾的是,由于采用了完整的流水线架构,这些系统都面临着严峻的挑战。首先,不同模块之间的信息传输完全基于 LLM 生成的离散文本,级联过程不可避免地会引入噪音和传播错误。更关键的是,整个系统只能利用现有的预训练工具进行推理。由于缺乏错误传播方面的端到端整体训练,内容理解和多模态生成的能力可能非常有限,尤其是在解释复杂和隐含的用户指令方面。总之,我们亟需为任意模态构建端到端 MM-LLM。

为了实现这一目标,我们提出了 NExT-GPT,这是一种任意对任意的 MM-LLM,可无缝处理文本,图像,视频和音频四种模态任意组合的输入和输出。如图 1 所示,NExT-GPT 包括三个层级。
- 首先,利用已有的编码器对各种模态的输入进行编码,然后通过投影层将这些表征投影到 LLM 可理解的类语言表征中。
- 其次,利用现有的开源 LLM 作为核心,处理输入信息以进行语义理解和推理。LLM 不仅能直接生成文本标记(tokens),还能生成独特的模态信号标记,作为指令指示解码层是否要输出相应的模态内容。
- 第三,产生的带有特定指令的多模态信号经过映射后,会进入不同的编码器,最终生成相应模态的内容。
由于 NExT-GPT 包含各种模态的编码和生成,从头开始训练该系统将耗费大量成本。相反,我们利用现有的预训练高性能编码器和解码器,如 Q-Former [43],ImageBind [25] 和最先进的潜在扩散模型 [68, 69 , 8, 2, 51, 33]。通过加载现成的参数,我们不仅避免了冷启动训练,还促进了更多模态的潜在增长。对于三层的特征对齐,我们只考虑对输入投影层和输出投影层进行局部微调,编码侧对齐以 LLM 为中心,解码侧对齐以指令为中心。此外,为了让 MM-LLM 在复杂的跨模态生成和推理方面具备人类水平的能力,我们引入了模态切换指令微调(Modality-switching Instruction Tuning,MosIT),使系统具备复杂的跨模态语义理解和内容生成能力。为了解决社区中缺乏此类跨模态指令调谐数据的问题,我们手动收集并注释了一个由 5000 个高质量样本组成的 MosIT 数据集。利用 LoRA 技术[32],我们在 MosIT 数据上对整个 NExT-GPT 系统进行了微调,更新了投影层和某些 LLM 参数。
总之,这项工作展示了开发更像人类的 MM-LLM Agent的可能性,它能够模拟通用模态。本项目的贡献如下:
- 首次提出了一种端到端的通用任意 MM-LLM NExTGPT,它能够进行语义理解和推理,并生成文本,图像,视频和音频的自由输入和输出组合。
- 引入了轻量级对齐学习技术,在编码端采用以 LLM 为中心的对齐方式,在解码端采用指令遵循对齐方式,只需对参数进行最小限度的微调(只需 1%的参数)即可实现有效的语义对齐。
- 注释了一个高质量的模态切换指令微调数据集,该数据集涵盖了文本,图像,视频和音频等各种模态组合的复杂指令,帮助 MM-LLM 进行类似人类的跨模态内容理解和指令推理。
2 Related Work
Cross-modal Understanding and Generation
我们的世界充满了多模态信息,我们不断地参与到理解和制作跨模态内容的复杂任务中。人工智能界相应地出现了各种形式的跨模态学习任务,如图像/视频描述[99, 16, 56, 56, 27, 49],图像/视频问题解答[94 , 90 , 48 , 98, 3],文本到图像/视频/语音合成[74, 30, 84, 23 , 17 , 51 , 33],图像到视频合成[18, 37]等,所有这些任务在过去几十年中都取得了快速发展。研究人员提出了高效的多模态编码器,旨在构建包含各种模态的统一表征。同时,由于不同模态的特征空间各不相同,因此必须进行模态对齐学习。此外,为了生成高质量的内容,人们提出了许多性能强大的方法,如 Transformer [82 , 101 , 17 , 24],GANs [53 , 7, 93 , 110],VAEs [81 , 67],Flow 模型 [73 , 6] 以及目前最先进的扩散模型 [31, 64 , 57 , 22, 68]。特别是,基于扩散的方法最近在大量跨模态生成任务中表现出色,如 DALL-E [66] 和 Stable Diffusion [68]。以往所有的跨模态学习都仅限于理解多模态输入,而最近的 CoDi [78] 则带来了突破性的发展。利用扩散模型的强大功能,CoDi 能够从并行的任意输入模态组合中生成任意组合的输出模态,包括语言,图像,视频或音频。遗憾的是,CoDi 可能仍然无法实现类似人类的输入内容深度推理,只能进行并行的跨模态输入和生成。
Multimodal Large Language Models
LLM 已经对整个人工智能界乃至其他领域产生了深远的影响和变革。最著名的 LLM,即 OpenAI 的 ChatGPT [59] 和 GPT4 [60],通过指令微调 [61, 47, 104, 52] 和来自人类反馈的强化学习(RLHF)[75] 等对齐技术,已经展示了非凡的语言理解和推理能力。一系列开源 LLM,如 Flan-T5 [13],Vicuna [12],LLaMA [80] 和 Alpaca [79],极大地推动了社区的进步和贡献 [109, 100]。之后,人们开始努力构建处理多模态输入和任务的 LLM,从而发展出 MM-LLM 。
一方面,大多数研究人员通过将训练好的各种模态编码器与 LLMs 的文本特征空间对齐来构建基本的 MM-LLMs,从而让 LLMs 感知其他模态输入[35, 109, 76, 40]。例如,
- Flamingo [1] 使用交叉注意层将冻结图像编码器与 LLMs 连接起来。
- BLIP-2 [43] 采用 Q-Former 将输入图像查询转换为 LLM。
- LLaVA [52] 采用简单的投影方案将图像特征连接到词嵌入空间。
- 在构建能够理解视频(如 Video-Chat [44] 和 Video-LaMA [103]),音频(如 SpeechGPT [102])等的 MM-LLMs 方面,也有各种类似的做法。
- 其中,PandaGPT [77] 通过集成多模态编码器(即 ImageBind [25]),同时实现了对六种不同模态的全面理解。
然而,这些 MM-LLM 都受到只能感知多模态数据的限制,无法生成任意模态的内容。为了实现具有多模态输入和输出的 LLMs,一些人探索将 LLMs 作为决策者,并利用现有的现成多模态编码器和解码器作为执行多模态输入和输出的工具,例如 Visual-ChatGPT [88],HuggingGPT [72] 和 AudioGPT [34]。如前所述,在离散流水线方案下,纯文本(即 LLM 文本指令)模块之间的信息传递不可避免地会引入噪音。此外,缺乏对整个系统的全面微调也大大限制了语义理解的效果。我们的工作兼顾了上述两种类型的优点,即以端到端的方式学习任意对任意的 MM-LLM。
3 Overall Architecture
图 1 是该框架的概览示意图。NExT-GPT 包括三个主要层次:编码阶段,LLM 理解和推理阶段以及解码阶段。
Multimodal Encoding Stage
首先,我们利用现有的成熟模型对不同模态的输入进行编码。有一系列针对不同模态的编码器可供选择,例如 QFormer [43],ViT [19],CLIP [65]。在这里,我们利用的是 ImageBind [25],它是一种横跨六种模态的统一高性能编码器。有了 ImageBind,我们就无需管理大量异构模态编码器。然后,通过线性投影层,不同的输入表征被映射为类似语言的表征,这些表征对于 LLM 来说是可理解的。
LLM Understanding and Reasoning Stage
LLM 被用作 NExT-GPT 的核心Agent。在技术上,我们采用了 Vicuna-7b-delta-v0, [12],它是基于文本的开源 LLM,被广泛应用于现有的 MM-LLM 中 [77, 103]。LLM 将不同模态的表征作为输入,并对输入进行语义理解和推理。它的输出包括:
- 1)直接的文本响应。
- 2)每种模态的信号标记,这些信号标记作为指令指示解码层是否生成多模态内容,以及如果生成则生成什么内容。
Multimodal Generation Stage
基于 Transformer 的输出投影层接收来自 LLM(如有)的带有特定指令的多模态信号,将信号标记表示映射为后续多模态解码器可以理解的表示。在技术上,我们采用了目前现成的不同模态的潜在条件扩散模型,即
- 用于图像合成的 Stable Diffusion (SD) [68]
- 用于视频合成的 Zeroscope [8]
- 用于音频合成的 AudioLDM [51]
信号表示被输入到条件扩散模型的条件编码器中,用于生成内容。

表 1 总结了整个系统的配置。在整个系统中,只有较低尺度参数的输入和输出投影层(与整个巨大容量框架相比)需要在接下来的学习过程中更新,其余所有编码器和解码器都被冻结。也就是说,131M(=4+33+31+31+32)/ [131M + 12.275B(=1.2+7+1.3+1.8+0.975)],只有 1%的参数需要更新。这也是我们的 MM-LLM 的主要优势之一。


图 2 进一步说明了 NExT-GPT 的推理过程。给定用户输入的任意模态组合,相应的模态编码器和投影器会将其转换为特征表示,并将其传递给 LLM。然后,LLM 决定生成哪些内容,即文本标记和模态信号标记。如果 LLM 确定要生成某种模态内容(语言除外),就会输出一种特殊类型的标记[40],表示激活了该模态;反之,不输出特殊标记则表示停用了该模态。在技术上,
- 将
'设计为图像信号标记' (i=0,...,4) - 将
'设计为音频信号标记'(i = 0,···,8) - 将
'设计为视频信号标记'(i = 0,···,24)
经过 LLM 处理后,文本响应将输出给用户;而某些激活模态的信号token的表示则传递给相应的扩散解码器,用于生成内容。
4 Lightweight Multimodal Alignment Learning
为了弥合不同模态特征空间之间的差距,确保对不同输入的流畅语义理解,对 NExT-GPT 进行对齐学习至关重要。由于我们设计的松耦合系统主要有三层,因此只需更新编码侧和解码侧的两个投影层即可。
4.1 Encoding-side LLM-centric Multimodal Alignment
按照现有 MM-LLM 的常见做法,我们考虑将不同的输入多模态特征与文本特征空间(核心 LLM 可理解的表征)进行对齐。因此,这被直观地命名为以 LLM 为中心的多模态对齐学习。为了完成对齐(alignment),我们从现有的语料库和基准中准备了 ‘X-caption’ pair(‘X’ stands for image, audio, or video)数据。我们使用 LLM 生成每个输入模态的描述与黄金描述(gold caption)的对比。图 3(a) 展示了学习过程。

4.2 Decoding-side Instruction-following Alignment
在解码端,我们集成了来自外部资源的预训练条件扩散模型。我们的主要目的是将扩散模型与 LLM 的输出指令对齐。然而,在每个扩散模型和 LLM 之间执行全面的对齐过程将带来巨大的计算负担。作为替代方案,我们在此探索一种更高效的方法,即解码侧指令遵循对齐,如图 3(b) 所示。具体来说,由于各种模态的扩散模型仅以文本标记输入为条件。在我们的系统中,这种条件与来自 LLM 的模态信号标记有很大差异,这导致扩散模型在准确解释来自 LLM 的指令方面存在差距。因此,我们考虑最小化 LLM 的模态信号标记表示(在每个基于 Transformer 的投影层之后)与扩散模型的条件文本表示之间的距离。由于只使用了文本条件编码器(扩散骨干被冻结),因此学习仅仅基于纯描述文本,即不需要任何视觉或音频资源。这也确保了训练的高度轻量化。
5 Modality-switching Instruction Tuning
5.1 Instruction Tuning
尽管编码和解码两端都与 LLM 保持一致,但在实现让整个系统忠实地遵循和理解用户指令并生成所需的多模态输出这一目标方面仍存在差距。为了解决这个问题,进一步的指令微调(Instruction Tuning,IT)[97 , 77, 52] 被认为是提高 LLM 的能力和可控性所必需的。IT 涉及使用 ‘(INPUT, OUTPUT)’ pairs 对整个 MM-LLM 进行额外训练,其中 ‘INPUT’ 表示用户指令,‘OUTPUT’ 表示符合给定指令的所需模型输出。在技术上,我们利用 LoRA [32],使 NExT-GPT 中的一小部分参数在 IT 阶段与两层投影同时更新。如图 4 所示,当 IT 对话样本输入系统时,LLM 会重构并生成输入的文本内容(并以多模态信号标记表示多模态内容)。根据gold注释(gold annotations)和 LLM 的输出进行优化。除 LLM 微调外,我们还对 NExT-GPT 的解码端进行了微调。我们将输出投影编码的模态信号标记表示与扩散条件编码器编码的gold多模态描述表示相一致。因此,综合微调过程更接近与用户进行忠实,有效互动的目标。
5.2 Instruction Dataset
对于NExT-GPT的IT,我们考虑以下数据集。
‘Text+X’ — ‘Text’ Data
MM-LLM IT 的常用数据集包含文本和多模态内容(即 “X” 可以是图像,视频,音频或其他内容)输入,而输出则是 LLM 的文本响应。这类数据已经有很多,例如 LLaVA [52],miniGPT-4 [109],VideoChat [44],我们直接使用它们来达到我们的微调目的。
‘Text’ — ‘Text+X’ Data
与现有的 MM-LLM 显著不同的是,在我们的任意到任意场景中,目标不仅包括文本的生成,还包括多模态内容,即 ‘Text+X’。因此,我们构建了 ‘Text’ — ‘Text+X’ 数据,即文本到多模态(即 T2M)数据。基于现有语料库和基准[71, 50, 5, 38]中丰富的 ‘X-caption’ 对,并结合一些模板,我们借用 GPT-4 制作了不同的文字说明来包装描述,从而得到数据。
MosIT Data
编写全面涵盖所需目标行为的高质量指令并非易事。我们注意到,上述信息技术数据集无法满足我们的任意 MM-LLM 场景的要求。首先,在人机交互过程中,用户和 LLM 的输入和输出涉及多种动态变化的模态。此外,我们允许在此过程中进行多轮对话,因此需要处理和理解复杂的用户意图。然而,上述两类数据缺乏可变模态,而且对话时间相对较短,无法充分模拟真实世界的场景。
为了促进任意 MM-LLM 的发展,我们提出了一种新颖的模态切换指令微调(Modality-switching Instruction Tuning,MosIT)。MosIT 不仅支持复杂的跨模态理解和推理,还能生成复杂的多模态内容。结合 MosIT,我们手工精心构建了一个高质量的数据集。MosIT数据涵盖了广泛的多模态输入和输出,提供了必要的复杂性和可变性,以促进MM-LLM的训练,使其能够处理不同的用户交互,并准确地提供所需的响应。具体来说,我们设计了一些人类角色和机器角色之间的模板对话示例,并在此基础上促使 GPT-4 在各种场景下生成更多对话,其中包含 100 多个主题或关键词。交互内容要求多样化,例如,‘Human’ 可以提出直接或隐含的要求,‘Machine’ 可以执行感知,推理,建议,规划等操作。互动内容应具有逻辑关联性,语义内在性和复杂性,"机器"的每次回应都应包含深入的推理细节。每次对话应包括 3-7 个回合(即 QA 对),其中 ‘Human’-‘Machine’ 交互应在输入或输出端涉及多种模态,并交替切换模态。每当对话中包含多模态内容(如图像,音频和视频)时,我们都会从外部资源中寻找最佳匹配内容,包括检索系统(如 Youtube7)甚至 AIGC 工具(如 Stable-XL[63],Midjourney)。经过人工检查和过滤不合适的实例后,我们总共获得了 5K 个高质量对话。在表 2 中,我们将现有的多模态 IT 数据集与我们的 MosIT 数据进行了比较。

6 Experiments
6.1 Any-to-any Multimodal Generation
我们尝试量化 NExT-GPT 在某些基准数据集上的生成质量,包括文本到 X 的生成,X 到文本的生成和文本条件模态编辑等常见设置。我们通过在用户和模型之间只进行一轮交互来模拟任务。
‘Text’ — ‘X’ Generation

代表了文本条件模态合成中最常见的任务。表 3,表 4 和表 5 比较了我们的系统和一些最先进的系统。总体而言,NExT-GPT 的性能与表现最好的基线系统相当。
‘X’ — ‘Text’ Generation

表示模态描述任务。表 6,表 7 和表 8 显示了不同任务的结果。总体而言,我们发现 NExT-GPT 在 X 到文本生成方面的性能比 CoDi 基线要好得多,这是因为 NExT-GPT 可以直接从 LLM 生成文本,而 LLM 本身已经对文本进行了专业化处理。
‘Text+X’ — ‘X’ Generation
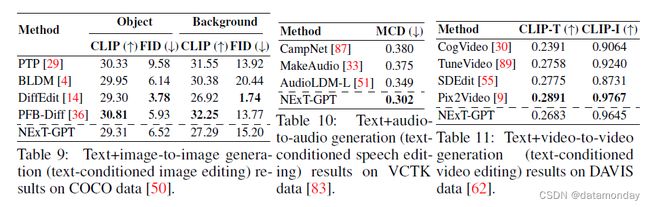
代表文本条件模态编辑任务类别。表 9,10 和 11 显示了在不同任务中的表现。与上述两类任务相比,NEXT-GPT 在文本条件模态编辑任务中的表现并不突出。但是,它仍然表现出了很强的竞争力。
Human Evaluation on Complex Any-to-any QA

我们还对输入和输出之间存在复杂的跨模态交互的更多场景进行了评估。我们主要比较了不同模态转换设置下的模型性能。由于无法使用标准基准,我们在此采用人工评估。我们请多位评估人员对 NExT-GPT 的性能进行评分,评分标准从 1 到 10 分不等。图 5 显示了比较结果。我们发现 NExT-GPT 在生成图像方面比生成视频和音频方面更胜一筹。此外,由于单模态内容的复杂性,生成多模态内容的混合组合也略逊于生成单模态内容。
6.2 Example Demonstrations


为了证明我们提出的 NExT-GPT 在开发类人对话Agent方面的有效性和潜力,我们在此进一步提供了一些令人信服的示例,这些示例生动地说明了该系统在理解和推理各种模态内容方面的卓越能力。图 6,图 7,图 8,图 9,图 10 和图 11 展示了 NExT-GPT 的示例。请访问项目页面了解更多示例,并访问动态视频和音频内容。
7 Conclusion
在这项工作中,我们提出了一种端到端通用任意多模态大语言模型(MM-LLM)。通过将 LLM 与多模态适配器和不同的扩散解码器连接起来,NExT-GPT 能够感知文本,图像,视频和音频的任何组合的输入并生成输出。利用现有的训练好的高性能编码器和解码器,NExT-GPT 的训练只需要某些投影层的少量参数(1%),这不仅有利于降低成本,还能方便地扩展到未来更多的潜在模态。为了使 NExT-GPT 能够进行复杂的跨模态语义理解和内容生成,我们引入了模态切换指令微调(MosIT),并为 MosIT 手动策划了一个高质量的数据集。总之,我们的研究展示了任意对任意 MMLLM 在弥合各种模态之间的差距方面的潜力,并为未来更像人类的人工智能系统铺平了道路。
Limitation and Future work
作为未来的工作,至少有以下四个途径可以探索。
i) Modalities & Tasks Expansion
由于资源有限,目前我们的系统支持四种模态的输入和输出:语言,图像,视频和音频。下一步,我们计划将其扩展到更多的模态(如网页,三维视觉,热图,表格和图片)和任务(如对象检测,分割,接地和跟踪),从而扩大系统的适用性,使其更具通用性。
ii) LLM Variants
目前,我们已经采用了 7B Vicuna 版本的 LLM。我们的下一步计划包括纳入各种类型和尺寸的 LLM,让从业人员可以根据自己的具体要求选择最合适的 LLM。
iii) Multimodal Generation Strategies
虽然我们的系统在跨模态生成内容方面表现出色,但生成输出的质量有时会受到扩散模型能力的限制。探索整合基于检索的方法,对生成过程进行补充,从而提高整个系统的性能,是非常有前途的。
iv) MosIT Dataset Expansion
目前,我们的信息技术数据集还有扩展空间。我们打算大幅增加注释数据的数量,确保提供更全面,更多样的指令集,进一步提高 MM-LLM 理解和有效遵循用户提示的能力。