uCore OS Lab 0操作系统实验准备
Lab 0
文章目录
- Lab 0
- 1 **安装一个操作系统的开发过程:**
- 2 实验环境
-
- 2.1 使用 Linux 实验环境
- 2.2 可能用到的软件
- 3 了解编程开发调试的基本工具
-
- 3.1 gcc 的基本用法
-
- 3.1.1 AT & T汇编基本语法
- 3.1.4 GCC 基本内联汇编
- 3.1.5 GCC 扩展内联汇编
- 3.1.6 **Extended Asm**
-
- 汇编模板(assembler template)
- 操作数(Operands)
- 破坏列表 Clobber List
- 特征修饰符 Volatile
- 约束 Constraints
- 约束 Constraints Modifiers修饰符
- 常用代码示例
- 3.2 make 和 Makefile
-
- 3.2.1 makefile 的规则
- 设置断点(Break Points)
- 设置观察点(Watch Points)
- 设置捕捉点(Catch Points)
- 维护停止点
- 停止条件维护
- 为停止点设定运行命令
- 断电菜单
- 恢复程序运行和单步调试
- 信号(Signals)
- 线程(Thread Stops)
- Eclipse + CDT 下载安装
- 4 基于硬件模拟器实现源码级调试
-
- 4.1 安装硬件模拟器 QEMU
- 4.2 Linux 环境下的源码级安装 QEMU
- 4.3 使用 QEMU
-
- 4.3.1 运行参数
-
- 常用调试命令
- 4.4 结合 gdb 和 qemu 源码级调试 uCore
-
- 编译可调式的目标文件
- ucore 代码编译
- 使用远程调试
- 使用 gdb 配置文件
- 加载调试目标
- 设定调试目标架构
- 5 了解处理器硬件
-
- 5.1 Intel 80386 运行模式
- 5.2 Intel 80386内存架构
- 5.3 Intel 80386 寄存器
- 6 了解 uCore 编程方法和通用数据结构
-
- 6.1 面向对象编程方法
- 6.2 通用数据结构双向循环链表
-
- 6.2.1 双向循环链表
- ucore运行环境:X86 硬件模拟器,QEMU、VirtualBox、VMware Player
- ucore开发环境:GCC的gcc、gas、ld和MAKE,或集成开发环境Eclipse-CDT
- 分析源代码:understand
- 软件开发版本管理:GIT、SVN
- 比较文件和目录的不同,发现不同实验中的差异性和进行文件合并操作:meld、kdiff3、UltraCompare
- 调试(debug)发现设计中得出错误:gdb(配合QEMU)等调试工具软件
1 安装一个操作系统的开发过程:
- Bootloader+toy ucore: 理解操作系统启动前的硬件状态和要做的准备工作,了解运行操作系统的外设硬件支持,操作系统如何加载到内存中,理解两类中断—“外设中断”,“陷阱中断”,内核态和用户态的区别;
- **物理内存管理:**理解x86分段/分页模式,了解操作系统如何管理物理内存;
- **虚拟内存管理:**理解OS虚存的基本原理和目标,以及如何结合页表+中断处理(缺页故障处理)来实现虚存的目标,如何实现基于页的内存替换算法和替换过程;
- **内核线程管理:**理解内核线程创建、执行、切换和结束的动态管理过程,以及内核线程的运行周期等;
- **用户进程管理:**理解用户进程创建、执行、切换和结束的动态管理过程,以及在用户态通过系统调用得到内核中各种服务的过程;
- **处理器调度:**理解操作系统的调度过程和调度算法;
- **同步互斥与进程间通信:**理解同步互斥的具体实现以及对系统性能的影响,研究死锁产生的原因,如何避免死锁,以及线程/进程间如何进行信息交换和共享;
- **文件系统:**理解文件系统的具体实现,与进程管理和内存管理等的关系,缓存对操作系统IO访问的性能改进,虚拟文件系统(VFS)、buffer cache和disk driver之间的关系。
- 每个开发步骤都是建立在上一个步骤之上的
- 从理解操作系统原理到实践操作系统设计与实现的探索过程
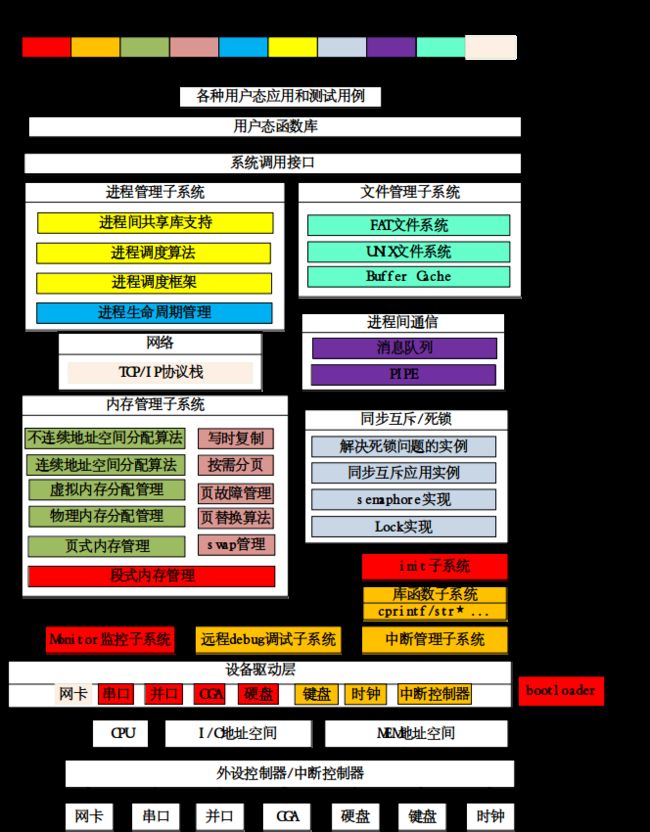
2 实验环境
2.1 使用 Linux 实验环境
-
安装 Ubuntu Linux 20.04
- 参考博客
- 姓名:zihao
- 密码:123456
- 注意:不要 skip
-
命令行方式的编译、调试、运行操作系统
-
命令模式的基本结构和概念:实现需要的所有操作
-
进入命令模式:GNOME菜单->附件->终端
-
命令行终端提示符:表示计算机已就绪,等待用户输入操作指令。此时输入任何指令按回车后,该指令将会被提交到计算机运行
-
常用指令:
- ls:查询文件列表
- ls /: 列出根目录
- ls -l: 列出更详细的文件清单
- ls -a:列出包括隐藏文件(以.开头的文件)
- pwd:查询当前所在目录
- cd /目录路径 : 进入其他目录
- echo “字符串”: 在屏幕输出字符
- cat:显示文件内容
- less/more作为选项显示比较大的文件内容
- cp: 复制文件
- mv:移动文件
- touch:建立一个空文本文件
- mkdir:建立一个目录
- rm:删除文件/目录
- ls:查询文件列表
-
选项:
- -p: 让系统显示某一项的类型,比如是文件/文件夹/快捷链接
- -i(interactive):在系统删除操作前输出确定指示
- -r(recursive): 删除文件夹
-
其他基本指令:
- ps:查询当前进程
- 列出所启动的所有进程
- -a : 列出所有的(包括其他用户)
- ps auxww: 列出除一些特殊进程以外的所有进程,并会以一个高可读的形式显示结果,每一个进程都会有较为详细的解释
- ps:查询当前进程
-
控制流程
-
输入/输出
- input:读取通过标准输入设备输入的信息
- output:输出指定的输出内容。在遇到操作错误时,系统会自动调用这个命令输出标准错误提示
-
重定向
-
管道:把几个简单命令联合成为复杂的功能
|grep -i command < myfile | sort > result.text- 搜索myfile中的命令,将输出分类并写入到分类文件result.text
-
后台进程:要启动一个进程到后台,追加 & 到命令后面
-
sleep 60 & -
睡眠命令在后台运行,宁依然可以与计算机交互。除了不同步启动命令外,
-
如果一个命令将占用很多时间,想让其放入后台运行
-
sleep 60
< ctrl z> # 停止
bg #转入后台
fg # 转回前台
-
ctrl c:杀死一个前台程序
-
-
-
环境变量
-
获得软件包
-
命令行获取软件包
-
apt-get: 自动从互联网软件库中搜索、安装、升级以及卸载软件或者操作系统 -
一般需要root 执行权限
-
语法
sudo apt-get install gcc -
常见 apt 命令:
-
apt-get install # 下载 以及所依赖的软件包,同时进行软件包的安装或者升级
apt-get remove #移除以及所依赖的软件包
apt-cache search #搜索满足pattern 的软件包
apt-cache show/showpkg #显示软件包 的完整描述
-
-
-
解决 apt 下载速度太慢:
- 选择最佳服务器
-
图形界面软件包获取
菜单栏->系统管理 -> 新德里软件包管理器
-
配置升级源
-
Ubuntu的软件包获取依赖升级源,可以通过修改 “/etc/apt/sources.list” 文件来修改升级源(需要 root 权限);或者修改新立得软件包管理器中 “设置 > 软件库”。
-
-
-
查找帮助文件
- 命令
man - 对 Linux 下常用命令、安装软件、以及C语言常用函数进行查询
- 语法
man 命令
- 命令
2.2 可能用到的软件
-
编辑器
-
gnome
-
Vim
-
下载安装VIm
sudo spt-get install vim -
查看 vim 版本命令
vim --version -
编辑配置文件至
~/.vimrc-
在启动vim时,当前用户根目录下的.vimrc文件会被自动读取,该文件可以包含一些设置甚至脚本,所以,一般情况下把.vimrc文件创建在当前用户的根目录下比较方便
-
-
set nocompatible set encoding=utf-8 set fileencodings=utf-8,chinese set tabstop=4 set cindent shiftwidth=4 set backspace=indent,eol,start autocmd Filetype c set omnifunc=ccomplete#Complete autocmd Filetype cpp set omnifunc=cppcomplete#Complete set incsearch set number set display=lastline set ignorecase syntax on set nobackup set ruler set showcmd set smartindent set hlsearch set cmdheight=1 set laststatus=2 set shortmess=atI set formatoptions=tcrqn set autoindent
-
-
-
exuberant-ctags: 为程序语言对象生成索引,其结果能够被一个文本编辑器或者其他工具简捷迅速的定位
3 了解编程开发调试的基本工具
3.1 gcc 的基本用法
-
使用 vim 编辑一个 .c 文件
-
用 gcc 编译文件:
gcc -Wall hello.c -o hello-
该命令将文件‘hello.c’中的代码编译为机器码并存储在可执行文件 ‘hello’中。机器码的文件名是通过 -o 选项指定的。该选项通常作为命令行中的最后一个参数。如果被省略,输出文件默认为 ‘a.out
-
-
-Wall: 开启编译器几乎所有常用的警告 -
运行可执行文件:输入可执行文件的路径
-
./hello -
该命令将可执行文件载入内存,并使CPU开始执行其包含的指令
./ 当前目录
因此
./hello: 载入并执行当前目录下的可执行文件 hello
-
3.1.1 AT & T汇编基本语法
-
Ucore 用的是 AT&T 格式的汇编
- 1.寄存器引用: 在寄存器号前加
% - 2.操作数顺序:从左到右
- 3.立即数:在数前面加
$- 16 进制常数:
0x $
- 16 进制常数:
- 4**.符号常数**:直接引用
- 在前加
$:引用符号地址
- 在前加
- 5.操作数长度:加在指令后
- b : 8-bit
- w: 16-bit
- l: 32-bit
- 若没有指定操作数长度,编译器按照目标操作数的长度来设置
- 6**.内存引用**:
- Intel 格式的简介内存引用:
section:[base+index*scale+displacement]
- AT&T 格式的间接内存引用:
section:displacement(base,index,scale)
- Intel 格式的简介内存引用:
- 1.寄存器引用: 在寄存器号前加
-
与 Intel格式的汇编的不同
-
-
* 寄存器命名原则 AT&T: %eax Intel: eax * 源/目的操作数顺序 AT&T: movl %eax, %ebx Intel: mov ebx, eax * 常数/立即数的格式 AT&T: movl $_value, %ebx Intel: mov eax, _value 把value的地址放入eax寄存器 AT&T: movl $0xd00d, %ebx Intel: mov ebx, 0xd00d * 操作数长度标识 AT&T: movw %ax, %bx Intel: mov bx, ax * 寻址方式 AT&T: immed32(basepointer, indexpointer, indexscale) Intel: [basepointer + indexpointer × indexscale + imm32) -
OS 工作于保护模式下时,用 32 位线性地址,所以在计算地址时不用考虑 segment :offse
-
上式中的地址
immed32+basepointer+indexpointer*indexscale -
* 直接寻址 AT&T: foo Intel: [foo] foo是一个全局变量。注意加上$是表示地址引用,不加是表示值引用。对于局部变量,可以通过堆栈指针引用。 * 寄存器间接寻址 AT&T: (%eax) Intel: [eax] * 变址寻址 AT&T: _variable(%eax) Intel: [eax + _variable] AT&T: _array( ,%eax, 4) Intel: [eax × 4 + _array] AT&T: _array(%ebx, %eax,8) Intel: [ebx + eax × 8 + _array]
-
3.1.4 GCC 基本内联汇编
-
GCC 支持在 C++ 代码中嵌入汇编代码:GCC Inline ASM——GCC 内联汇编
- 有利于将一些C++无法表达的指令直接嵌入
- 允许我们直接写汇编,来编写简洁代码
-
GCC 提供了两内联汇编语句(Inline asm statements):
- 基本内联汇编语句(basic inline asm statements)
- 格式:
asm("statements");
- 格式:
- 扩展内联汇编语句(extended inline asm statements)
- 基本内联汇编语句(basic inline asm statements)
-
"asm"和“_asm_”的含义一致: 声明一个内联汇编表达式- asm 是 GCC 关键字 asm的宏定义
#define _asm_ asm
- asm 是 GCC 关键字 asm的宏定义
-
若有多行汇编,每行最后加
\n\t- \n : 换行符
- \t : tab符号
- 为了 使得 gcc 在编译内联汇编代码,成为一般的汇编代码时能够保证换行,和有一定的空格
- GCC 编译出来的汇编代码就是双引号中的内容
-
gcc 在处理汇编时,把asm()的内容打印到汇编文件中,格式控制字符是必要的
-
asm("movl %eax, %ebx"); asm("xorl %ebx, %edx"); asm("movl $0, _boo);在上面的例子中,由于我们在内联汇编中改变了 edx 和 ebx 的值,但是由于 gcc 的特殊的处理方法,即先形成汇编文件,再交给 GAS 去汇编,所以 GAS 并不知道我们已经改变了 edx和 ebx 的值,如果程序的上下文需要 edx 或 ebx 作其他内存单元或变量的暂存,就会产生没有预料的多次赋值,引起严重的后果。对于变量 _boo也存在一样的问题。为了解决这个问题,就要用到扩展 GCC 内联汇编语法。
3.1.5 GCC 扩展内联汇编
参考博客
-
#define read_cr0() ({ \ unsigned int __dummy; \ __asm__( \ "movl %%cr0,%0\n\t" \ :"=r" (__dummy)); \ __dummy; \ }) -
GCC 扩展内联汇编基本格式
-
asm [volatile] (Assembler Template
: Output operands
[ : Input Operands
[ : Clobbers ] ] )
-
asm 代表汇编代码的开始
-
[volatile] : 可选项,避免 asm 指令被删除、移动或组合
-
指令
“movl %%cr0,%0\n\t” -
数字前缀:
%1, 表示使用寄存器的样板操作数- 指令中几个操作数,表示有几个变量需要与寄存器结合,由gcc在编译时根据后面的输出部分和输入部分的约束条件进行相应的处理
- 可使用的操作数总数取决于具体CPU中通用寄存器的数量
%%cr0: 两个 % ,表示用到具体的寄存器
-
Output Operands list:输出部分,用以规定对输出变量(目标操作数)如何与寄存器结合的约束(constraint)。输出部分可以有多个约束,以逗号分开
-
每个约束语法:
“=约束字母” 关于变量结合的约束 -
:"=r" (_dummy)- =r 表示相应的目标操作数(%0),可以使用任何一个通用寄存器,并且变量 _dummy 存放在这个寄存器中
-
:"=m" (_dummy)- =m 表示相应的目标操作数是存放在内存单元 _dummy 中
-
几个主要的约束字母
字母 含义 m, v, o 内存单元 R 任何通用寄存器 Q 寄存器eax, ebx, ecx,edx之一 I, h 直接操作数 E, F 浮点数 G 任意 a, b, c, d 寄存器eax/ax/al, ebx/bx/bl, ecx/cx/cl或edx/dx/dl S, D 寄存器esi或edi I 常数(0~31)
-
-
Input Operand list: 输入部分
- 与输出部分相似,但没有
=
- 与输出部分相似,但没有
-
[
3.1.6 Extended Asm
参考博客
-
内联函数:在C语言中,指定编译器将一个函数代码直接复制到调用其代码的地方执行。
- 内联函数降低了函数的调用开销
- 指定编译器将一个函数处理为内联函数,只要在函数申明前加上 inline 关键字
-
内联汇编:用汇编语句写成的内联函数
- GCC(CNU Compiler Collection for Linux) 中声明一个内联汇编函数,用 asm 关键字
- 操作 C 语言变量
-
在扩展形式中,可以指定操作数,选择输入输出寄存器,指明要修改的寄存器列表
-
形式:
-
asm ( assembler template : output operands /* optional */ : input operands /* optional */ : list of clobbered registers /* optional */ ); -
assembler template: 汇编指令部分 -
括号内的operands:C 语言表达式中常量字符串,不同部分之间用冒号分隔
相同部分语句中的每个小部分用逗号分隔
最多指定10个操作数
-
-
若没有 output operands ,有input operands,需要保留output 前的冒号
-
asm ( "cld\n\t" "rep\n\t" "stosl" : /* no output registers */ : "c" (count), "a" (fill_value), "D" (dest) : "%ecx", "%edi" );
-
-
例子:用汇编代码把a的值赋给b
-
int a=10, b; asm ( "movl %1, %%eax; movl %%eax, %0;" :"=r"(b) /* output */ :"r"(a) /* input */ :"%eax" /* clobbered register */ );- b 是输出操作数,用 %0 访问
- a 是输入操作数,用 %1 访问
- r 是constraint:让 GCC 自己选择一个寄存器存储变量a
- 输出部分constraint 前需要 = 修饰
- 用 %% 和 % 区分操作数和寄存器
- 操作数已经用一个%做前缀,寄存器只能用%%做前缀
- clobbered register:代表内联汇编代码会改变寄存器eax的内容
-
汇编模板(assembler template)
- 嵌入在C中的汇编指令
- 每条指令放在一个双引号内,或都在一个双引号
- 每条指令后
\n\t - 访问 C 语言变量用 %0,%1…
操作数(Operands)
-
格式
"constraint" (C expr) //"=r"(result) -
asm 内部使用C语言字符串作为操作数
-
操作数都要放在双引号内
- 对于 output 操作数要用 =
-
constraint 和 修饰都放在双引号内
-
constraint:指定操作数的寻址类型(内存寻址或者寄存器寻址),也用来指明使用那个寄存器
-
若有多个操作数,使用逗号隔开
-
在汇编模板部分,按顺序用数字去引用操作数
-
输出操作数表达式必须是左值,输入操作数不一定是
- 可以使用表达式或者变量
-
例子:把一个数字乘以五
-
asm ( "leal (%1,%1,4), %0" : "=r" (five_times_x) : "r" (x) ); -
输入操作数是 x,未指定具体使用那个寄存器
-
-
修改 constraint 部分内容,使得 GCC 固定使用同一个寄存器处理输入输出操作数,但未指定具体哪个寄存器
-
asm( "lea (%0,%0,4),%0" : "=r" (five_times_x) : "0" (x) );
-
-
需要指定具体的寄存器
-
asm ( "leal (%%ecx,%%ecx,4), %%ecx" : "=c" (x) : "c" (x) );
-
-
不需要填写ClobberList
- 指定GCC自己选择合适的寄存器
- 因为 GCC 知道x将存入 ecx ,GCC完全知道ecx的值
破坏列表 Clobber List
- 如果某个指令改变了某个寄存器的值,就必须在第三个冒号后标识出该寄存器
- 为了告知 GCC ,让其不在假定之前寄存器中的值依然合法
- 输入输出寄存器不用放入Clobber List
- GCC 能够知道asm将使用这些寄存器
- 已经被显示地指定输入输出
- 其他使用到的寄存器无论是显示或隐式都需要标明
- 若指令中已无法意料的形式修改了内存值,需要在 Clobber List 中加入 memory
- 使得 GCC 不去缓存这些内存值
- Clobber List 中列出的寄存器可以被多次写读
特征修饰符 Volatile
-
要求汇编代码必须在被放置的位置执行(不能被循环优化或移除循环)
-
禁止这些代码被移动或删除
-
asm volatile ();
约束 Constraints
-
寄存器操作数 constraints:
r-
操作数将被存储在通用寄存器中
-
asm ("movl %%eax, %0": "=r" (myval));- 变量 myval 将被保存在 GCC 自己选择的寄存器中
- eax 中的值被拷贝到这个寄存器中
- 在内存中的 myval 值也会按照这个寄存器值更新
- r GCC 可能会在任何一个可用的通用寄存器中保存这个值
-
具体指定使用那个寄存器:
-
r Register(s) a %eax, %ax, %al b %ebx, %bx, %bl c %ecx, %cx, %cl d %edx, %dx, %adl S %esi, %si D %edi, %di
-
-
内存操作数constraint:
m- 当操作数在内存中时,任何对其操作会直接在内存中运行
- 指定寄存器:内存操作时会把值存在一个寄存器中,修改后再将该值 协会到该内存中
- 当操作数在内存中时,任何对其操作会直接在内存中运行
-
匹配 constraint
约束 Constraints Modifiers修饰符
常用代码示例
3.2 make 和 Makefile
- GNU make 是一种代码维护工具
- 项目中,根据程序各个模块的更新情况,自动的维护和生成目标代码
- 执行 make 命令时,需要 makefile 文件,以告诉make命令,需要怎样去编译和链接程序
- 编译和链接的规则
- 如果这个工程没有编译过,那么我们的所有c文件都要编译并被链接。
- 如果这个工程的某几个c文件被修改,那么我们只编译被修改的c文件,并链接目标程序。
- 如果这个工程的头文件被改变了,那么我们需要编译引用了这几个头文件的c文件,并链接目标程序。
- 编写好 makefile 后,只需要 make 命令,就可自动的根据当前的文件修改情况来确定哪些文件需要重新编译并重新链接
3.2.1 makefile 的规则
-
target … :prerequisites …
command
…
…
- target 是一个目标文件 : 可以是 object 文件,也可以是执行文件,也可以是一个 label
- prerequisite:要生成那个 target 所需要的文件
- command:make 需要执行的命令(任意的 shell 命令)
- 文件依赖关系
- target 文件依赖于 prerequisite 中的文件
- 生成规则 定义在 command 中
- 如果 prerequisites 中有文件比 target 文件新,那么command所定义的命令就被执行
##3.3 gdb 的使用
参考博客
- 调试命令
gcc -g -Wall 原文件.c -o 输出的目标文件- -g : 调试 C/C++ 程序,在编译时,就需要把调试信息加到可执行文件中
- 没有 -g 的话,看不见程序函数名、变量名,而是运行时的内存代码
- 启动 gdb :进入 gdb 环境和加载被调试程序同时进行:
gdb 可执行文件名gdb 可执行文件名 core- 用gdb 同时调试一个运行程序和core文件(程序非法执行后 core dump 后产生的文件)
gdb 可执行文件名- 若程序是一个服务程序,可以指定服务程序运行时的进程 ID
- gdb 启动开关
help:查看命令种类help 命令:查看种类中的命令
- 调试已运行的程序
-
ps查看正在运行的程序 ID,gdb格式挂接正在运行的程序PID gdb关联上源代码,并进行gdb,在 gdb 环境中 用attach命令来挂接进程 PID ,用detach取消挂接
-
- 暂停/恢复程序运行
- 可以设置程序在哪行停,在什么条件下停,在受到什么信号时停
info program查看程序是否在运行,进程号,被暂停原因- 暂停方式:
- BreakPoint: 断点
- WatchPoint: 观察点
- CatchPoint:捕捉点
- Signals:信号
- ThreadStops:线程停止
- 恢复程序运行:
c/continue
设置断点(Break Points)
break: 在进入指定函数时停住break: 在指定行号停住break +offset: 在当前行号前面的 offset 行停住break -offset: 在当前行号后面 offset 行挺住break filename: linenum: 在源文件 filename 的 linenum 行停住break filename: function: 在源文件filename的function入口处同住break *address: 在程序运行的内存地址处停住break: 没有参数时,表示在下一条指令处停住break ... if: 在条件成立时停住...是上述参数,conditon 表示条件
- 查看断点:n 为断点号
info breakpoints [n]info break [n]
设置观察点(Watch Points)
观察点一般来观察某个表达式(或变量)的值是否变化,若变化则停住
watch: 为表达式 expr 设置观察点rwatch: 当表达式 expr 被读时,停住awatch: 当表达式的值被读或写时,停住info watchpoints: 列出所有观察点
设置捕捉点(Catch Points)
设置捕捉点来捕捉程序运行时的一些事件
catch: 当event发生时,停住- throw 一个C++ 抛出的异常
- catch 一个C++捕捉到的异常
- exec 调用系统调用 exec 时
- fork 调用系统调用 fork 时
- vfork 调用系统调用 vfork 时
- load
- unload
tcatch: 值设置一次捕捉点,当程序停住后,该店被自动删除
维护停止点
停止点即上述三类
- clear
clear: 清除所有已定义的停止点clear/clear: 清除所有设置在函数上的停止点clear/clear: 清除所有设置在指定行上的停止点
- delete
delete [breakpoints] [range...]: 删除指定的断点,断点号,若不指定断点号则删除所有断点。range 表示断点号范围
- disable:gdb 不会删除,enable 可以恢复
disable [breakpoints] [range]:enable [breakpoints] [range]enable [breakpoints] once range...enable [breakpoints] delete range ...
停止条件维护
断点条件设置好后,用 conditon 命令修改条件(仅break和watch支持if)
condition: 修改断点号为 bnum 的停止条件为 exprcondition: 清除断点号为 bnum 的停止条件
为停止点设定运行命令
断电菜单
恢复程序运行和单步调试
当程序被停住,可以用 continue 命令恢复程序运行直到结束,或下一个断点,
也可以使用 step 或 next 命令单步跟踪程序
continue [ignore-count]/ c / fg- 恢复程序运行至结束或者下一个断点
- 或者设置忽略的次数
step- 单步跟踪,若有函数调用会进入函数
next- 单步跟踪,若有函数调用,不会进入函数
set step-modset step-mod onset step-mod offfinishuntil / u- 退出循环体
stepinexti
信号(Signals)
线程(Thread Stops)
-
功能强大的调试程序
- 设置断点
- 监视程序变量的值
- 程序的单步执行
- 显示/修改变量的值
- 显示/修改寄存器
- 查看程序的堆栈情况
- 远程调试
- 调试线程
-
必须先用 -g 或 -ggdb 编译选项编译源文件,才能使用 gdb 调试程序
- 运行 gdb 调试程序命令:
gdb progname
- 运行 gdb 调试程序命令:
-
在 gdb 提示符处键入 help ,
- aliases:命令别名
- breakpoints:断点定义
- data:数据查看
- files:指定并查看文件
- internals:维护命令
- running:程序执行
- stack:调用栈查看
- status:状态查看
- tracepoints: 跟踪程序执行
-
help 命令:该命令的详细 -
gdb 常用命令
-
break FILENAME:NUM 在特定源文件特定行上设置断点 clear FILENAME:NUM 删除设置在特定源文件特定行上的断点 run 运行调试程序 step 单步执行调试程序,不会直接执行函数 next 单步执行调试程序,会直接执行函数 backtrace 显示所有的调用栈帧。该命令可用来显示函数的调用顺序 where continue 继续执行正在调试的程序 display EXPR 每次程序停止后显示表达式的值,表达式由程序定义的变量组成 file FILENAME 装载指定的可执行文件进行调试 help CMDNAME 显示指定调试命令的帮助信息 info break 显示当前断点列表,包括到达断点处的次数等 info files 显示被调试文件的详细信息 info func 显示被调试程序的所有函数名称 info prog 显示被调试程序的执行状态 info local 显示被调试程序当前函数中的局部变量信息 info var 显示被调试程序的所有全局和静态变量名称 kill 终止正在被调试的程序 list 显示被调试程序的源代码 quit 退出 gdb
-
Eclipse + CDT 下载安装
参考博客
- JDK: 是 Java 语言的软件开发包,包含了 Java 的运行环境
- Eclipse :运行依赖于 JDK
- CDT:C/C++ Developing Tools
4 基于硬件模拟器实现源码级调试
4.1 安装硬件模拟器 QEMU
- 用于模拟一台 X86 计算机,让 uCore 运行在 QEMU 上
- 直接使用 Ubuntu 中提供的 QEMU
sudo apt-gett install qemu-system
4.2 Linux 环境下的源码级安装 QEMU
参考博客
- 安装时遇到的问题:
- analysis: 未安装到默认路径
- problem;输入
qemu无反应 - solution:参考博客
- 若输入
qemu-system-x86_64说明安装成功,需要对其进行链接:sudo ln -s /usr/bin/qumu-system-x86_64 /usr/bin/qemu`
4.3 使用 QEMU
4.3.1 运行参数
-
默认安装路径:
/usr/local/bin -
运行命令:
qemu -
qemu 运行多参数格式
qemu [options] [disk_image]- disk_image:硬盘镜像文件
-
部分参数:
-
`-hda file' `-hdb file' `-hdc file' `-hdd file' 使用 file 作为硬盘0、1、2、3镜像。 `-fda file' `-fdb file' 使用 file 作为软盘镜像,可以使用 /dev/fd0 作为 file 来使用主机软盘。 `-cdrom file' 使用 file 作为光盘镜像,可以使用 /dev/cdrom 作为 file 来使用主机 cd-rom。 `-boot [a|c|d]' 从软盘(a)、光盘(c)、硬盘启动(d),默认硬盘启动。 `-snapshot' 写入临时文件而不写回磁盘镜像,可以使用 C-a s 来强制写回。 `-m megs' 设置虚拟内存为 msg M字节,默认为 128M 字节。 `-smp n' 设置为有 n 个 CPU 的 SMP 系统。以 PC 为目标机,最多支持 255 个 CPU。 `-nographic' 禁止使用图形输出。 其他: 可用的主机设备 dev 例如: vc 虚拟终端。 null 空设备 /dev/XXX 使用主机的 tty。 file: filename 将输出写入到文件 filename 中。 stdio 标准输入/输出。 pipe:pipename 命令管道 pipename。 等。 使用 dev 设备的命令如: `-serial dev' 重定向虚拟串口到主机设备 dev 中。 `-parallel dev' 重定向虚拟并口到主机设备 dev 中。 `-monitor dev' 重定向 monitor 到主机设备 dev 中。 其他参数: `-s' 等待 gdb 连接到端口 1234。 `-p port' 改变 gdb 连接端口到 port。 `-S' 在启动时不启动 CPU, 需要在 monitor 中输入 'c',才能让qemu继续模拟工作。 `-d' 输出日志到 qemu.log 文件。
-
-
将用到的命令:
qemu -hda ucore.img -parallel stdip: 使得ucore在qemu模拟的 x86 硬件环境中执行qemu -S -s -hda ucore.img -monitor stdio: 用于与 gdb 配合进行源码调试
常用调试命令
-
qemu 中 monitor 的常用命令:
-
help 查看 qemu 帮助,显示所有支持的命令。 q|quit|exit 退出 qemu。 stop 停止 qemu。 c|cont|continue 连续执行。 x /fmt addr xp /fmt addr 显示内存内容,其中 ‘x’ 为虚地址,‘xp’ 为实地址。 参数 /fmt i 表示反汇编,缺省参数为前一次参数。 p|print’ 计算表达式值并显示,例如 $reg 表示寄存器结果。 memsave addr size file pmemsave addr size file 将内存保存到文件,memsave 为虚地址,pmemsave 为实地址。 breakpoint 相关: 设置、查看以及删除 breakpoint,pc执行到 breakpoint,qemu 停止。(暂时没有此功能) watchpoint 相关: 设置、查看以及删除 watchpoint, 当 watchpoint 地址内容被修改,停止。(暂时没有此功能) s|step 单步一条指令,能够跳过断点执行。 r|registers 显示全部寄存器内容。 info 相关操作 查询 qemu 支持的关于系统状态信息的操作。
-
-
single arg: arg为参数,设置单步标志命令single on: 允许单步- 在此情况下使用
cont进行单步操作
- 在此情况下使用
single off: 禁止单步
4.4 结合 gdb 和 qemu 源码级调试 uCore
编译可调式的目标文件
- 需要在使用 gcc 编译源文件时,添加参数 -g
- 这样编译出来的目标文件中才会包含可以用于 gdb 调试的相关符号信息
ucore 代码编译
- 编译过程:解压缩后的 ucore 源码包中使用 make 命令
- 将生成一些列目标文件
- 例如 lab1:
[]:~/lab1$ make- ucore.img: 被qemu访问过的虚拟硬盘文件
- kernel: ELF 格式的 toy ucore kernel 执行文件,被嵌入到了 ucore.img 中
- bootblock:虚拟的硬盘主引导扇区(512字节),包含了 bootloader 执行代码,被嵌入到了 ucore.img 中
- sign:外部执行程序,用来生成虚拟的硬盘主引导扇区
- 保存修改:
- 使用 diff 命令对修改后的 ucore 代码 和 ucore 源码进行比较,比较之前使用 make clean 清除掉不必要文件
- 应用修改:
使用远程调试
-
与 qemu 配合进行源代码级别的调试,需要先让 qemu 进入等待 gdb 调试器的接入并且还不能让 qemu 的CPU执行
- 因此启动 qemu 时,需要使用 -S -s
qemu -S -s:qemu 中的CPU并不会马上执行
-
然后启动 gdb ,
target remote 127.0.0.1:1234连接到qemu -
c: qemu 继续执行 -
遇到的问题:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k7sm4cLB-1617714592074)(E:\LearningNotes\TH操作系统\操作系统实验\lab0.assets\image-20210403211514163.png)]
- analysis:
- solution:
-
为了使得 gdb 获知符号信息,需要指定调试目标文件,gdb 中
file ./bin/kernel- gdb 便可载入这个文件中的符号信息
-
遇到的问题:
* -
通过 gdb 可以对 ucore 代码进行调试
-
例如: 调试memset函数:
- 运行
qemu -S -s -hda ./bin/ucore.img -monitor stdio - 运行 gdb 并与 qemu 进行连接
- 设置断点并执行
- qemu 单步调试
- 运行
使用 gdb 配置文件
加载调试目标
- 因为在指定了执行文件时就已经加载了文件中包含的调试信息,因此不用在使用 gdb 命令专门加载
- 但是在使用 qemu 进行远程调试的时候,我们必须手动加载符号表,即
file
设定调试目标架构
- 在调试的时候,若需要调试不是 i386 保护模式代码,比如8086实模式代码,需要设定当前使用的架构:
(gdb) set arch i8086
5 了解处理器硬件
- 了解处理器体系结构(了解硬件对 uCore 的影响)和机器指令集(读懂 uCore 的汇编)
- uCore 目前支持的硬件环境是基于Intel 80386以上的计算机系统
5.1 Intel 80386 运行模式
- 一般CPU 只有一种运行模式,
- 能够支持多个程序在各自独立的内存空间中并发执行,
- 且有用户特权级和内核特权级的区分,使得一般用户不能破坏操作系统内核和执行特权级指令
- 80386 处理器有四种运行模式
- 实模式
- 保护模式
- SMM 模式
- 虚拟8086 模式
- 实模式
- 个人计算机早期8086处理器采用的一种简单运行模式
- 加电启动后处于实模式运行状态
- 实模式状态下,软件可访问的物理内存地址空间不能超过1 MB,且无法发挥 Intel 80386以上级别32位 CPU 的4 GB 内存管理能力
- 实模式将整个物理内存看成分段区域,程序代码和数据位于不同区域
- 操作系统和用户程序未区别对待,每一个指针都指向实际的物理地址
- 注意:若用户程序的一个指针指向了操作系统区域或者其他用户程序区域,并修改,后果不堪设想
对于ucore无必要涉及
- 保护模式
- 主要目标是确保应用程序无法对操作系统进行破坏
- 实际上,80386就是通过在实模式下初始化控制寄存器(如GDTR,LDTR,IDTR与TR等管理寄存器)以及页表,然后再通过设置CR0寄存器使其中的保护模式 使能位置位,从而进入到80386的保护模式
- 当80386工作在保护模式下的时候,其所有的32根地址线都可供寻址,物理寻址空间高达4 GB
- 在保护模式下,支持内存分页机制,提供了对虚拟内存的良好支持
- 保护模式下80386支持多任务,还支持优先级机制,不同的程序可以运行在不同的特权级上
- 特权级一共分0~3四个级别,操作系统运行在最高的特权级0上,应用程序则运行在比较低的级别上;
- 配合良好的检查机制后,既可以在任务间实现数据的安全共享也可以很好地隔离各个任务。
5.2 Intel 80386内存架构
- 32 位的处理器:可以寻址的物理内存地址空间为 2^32 = 4 G 字节
- 三个地址空间概念:
- 物理地址
- 处理器提交到总线上用于访问计算机系统中的内存和外设的最终地址
- 一个计算机系统中只有一个物理地址空间
- 线性地址
- 80386处理器通过段(Segment)机制控制下的形成的地址空间
- 段机制
- 在操作系统的管理下,每个运行的应用程序有相对独立的一个或多个内存空间段,每个段有各自的起始地址和长度属性,大小不固定,这样可让多个运行的应用程序之间相互隔离,实现对地址空间的保护。
- 在操作系统完成对80386处理器段机制的初始化和配置(主要是需要操作系统通过特定的指令和操作建立全局描述符表,完成虚拟地址与线性地址的映射关系)后,80386处理器的段管理功能单元负责把虚拟地址转换成线性地址
- 页机制
- 页机制,每个页的大小是固定的**(4 KB),可完成对内存单元的安全保护,隔离**,可有效支持大量应用程序分散的使用大内存的情况
- 在操作系统完成对80386处理器页机制的初始化和配置(主要是需要操作系统通过特定的指令和操作建立页表,完成虚拟地址与线性地址的映射关系)后,应用程序看到的逻辑地址先被处理器中的段管理功能单元转换为线性地址,然后再通过80386处理器中的页管理功能单元把线性地址转换成物理地址。
- 逻辑地址
- 物理地址
页机制和段机制有一定程度的功能重复,但Intel公司为了向下兼容,使得两者一直共存
- 分段机制启动,分页机制为启动时:逻辑地址——段机制处理——>线性地址==物理地址
- 两个机制都启动时:逻辑地址——段机制处理——>线性地址——页机制处理——>物理地址
5.3 Intel 80386 寄存器
-
80386 寄存器可分为8类:宽度都为 32 位
-
通用寄存器(General Register)
-
EAX(累加器)/EBX(基址寄存器)/ECX(计数器)/EDX(数据寄存器)/
ESI(源地址指针寄存器)/EDI(目的地址指针寄存器)/ESP(堆栈指针寄存器)/EBP(基址指针寄存器)
- 低十六位:AX/BX/CX/DX/SI/DI/SP/BP
- 可以单独存取AX,BX,CX,DX 的高八位和低八位
- AH,AL/BH,BL/CH,CL/DH,DL
- 低十六位:AX/BX/CX/DX/SI/DI/SP/BP
-
-
段寄存器(Segment Register): 都是 16 位的
- CS, 代码段(Code Segment)
- DS, 数据段(Data Segment)
- ES, 附加数据段(Extra Segment)
- SS, 堆栈段(Stack Segment)
- FS, 附加段
- GS, 附加段
-
指令指针寄存器(Instruction Pointer)
- EIP 的低 16 位就是8086的IP,他存储的是下一条要执行指令的内存地址,在分段地址转换中,表示指令的段内偏移地址
-
标志寄存器(Flag Register):
- EFLAGS,和8086的16位标志寄存器相比,增加了4个控制位,者20位控制/标志位:
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UFwqPvRX-1617714592076)(https://objectkuan.gitbooks.io/ucore-docs/content/lab0_figs/image006.png)]
- 控制/标志位含义:
- EFLAGS,和8086的16位标志寄存器相比,增加了4个控制位,者20位控制/标志位:
-
系统地址寄存器
-
控制寄存器
-
调试寄存器
-
测试寄存器
-
6 了解 uCore 编程方法和通用数据结构
6.1 面向对象编程方法
- uCore 设计中采用了一定的面向对象编程方法
- 需要注意,我们并不需要用 C 语言模拟出一个常见C++编译器已经实现的对象模型
- uCore 的面向对象编程方法,目前主要是采用了类似 C++ 的接口(interface)
- 即是让实现细节不同的某类内核子系统(比如物理内存分配器、调度器,文件系统等)有共同的操作方式
- 虽然内存子系统的实现千差万别,但它的访问接口是不变的
- 接口在 C 语言中,表现为一组函数指针的集合
- 接口设计的难点是如何找出各种内核子系统的共性访问/操作模式,从而可以根据访问模式提取出函数指针列表
6.2 通用数据结构双向循环链表
6.2.1 双向循环链表
-
数据结构课程中
-
专门的成员变量 data
-
两个指向该类型的指针 next 和 prev
-
typedef struct foo { ElemType data; struct foo *prev; struct foo *next; } foo_t;
-
-
特点:
- 尾节点的后继指向首节点

-
潜在问题:由于每种特定数据结构类型不一致,需要为每种特定数据结构类型 定义针对这个数据结构的特定链表插入、删除等操作
-
在uCore中,借鉴了 Linux 内核的双向链表实现:
-
struct list_entry_t { struct list_entry_t *prev, *next; }; -
链表节点 list_entry_t 没有包含数据域,而是在具体的数据结构中包含该链表节点
-
-
例如 lab 2 中的空闲内存块列表,空闲块链表的头指针定义为:
-
/* free_area_t - maintains a doubly linked list to record free (unused) pages */ typedef struct { list_entry_t free_list; // the list header unsigned int nr_free; // # of free pages in this free list } free_area_t;
-
-
每一个空闲块链表节点定义为:
-
/* * * struct Page - Page descriptor structures. Each Page describes one * physical page. In kern/mm/pmm.h, you can find lots of useful functions * that convert Page to other data types, such as phyical address. * */ struct Page { atomic_t ref; // page frame's reference counter …… list_entry_t page_link; // free list link };
-
-
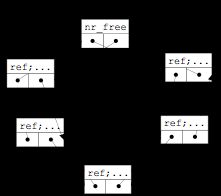
-
通用双向循环链表结构
- 避免了为每个特定数据结构类型 定义针对这个数据结构的特定链表的麻烦,
- 让所有的特定数据结构共享通用的链表操作函数
-
通用双向循环链表函数定义:
-
初始化:
-
uCore 只定义了链表节点,没有专门定义链表头
-
内联函数(inline function)list_init:
-
static inline void list_init(list_entry_t *elm) { elm->prev = elm->next = elm; }
-
-
调用 list_init(free_area.free_list) ,
- 声明了一个名为 free_area.free_list 的链表头
- 空链表,链表头的 next 和 prev 都初始化指向自己
- 可以用next 是否指向自己判断是否为空
-
-
插入:
-
表头插入(list_add_after)
-
表尾插入(list_add_before)
-
由于双向循环链表的链表头 next 和 prev 分别指向链表中第一个和最后一个节点,两者实现区别并不大
-
uCore
- list_add(elm, listelm, listelm->next) 实现表头插入
- list_add(elm, listelm->prev, listelm) 实现表尾插入
-
list_add:
-
static inline void __list_add(list_entry_t *elm, list_entry_t *prev, list_entry_t *next) { prev->next = next->prev = elm; elm->next = next; elm->prev = prev; }
-
-
表头插入:插入在listelm 后,即插在链表的最前位置
-
表尾插入:插入在 listelm->prev 之后,即插入在链表最后位置
-
-
删除
-
删除空闲块链表中的 Page 结构的链表节点时,调用 内联函数 list_del , list_del 进一步调用了_list_del 完成具体的删除操作
-
static inline void list_del(list_entry_t *listelm) { __list_del(listelm->prev, listelm->next); } static inline void __list_del(list_entry_t *prev, list_entry_t *next) { prev->next = next; next->prev = prev; } -
如果要确保 被删除的节点 listelm 不在指向链表中其他节点,可以通过调用 list_init 来把 listelm 的pre、next 指针分别指向自身——可以通过 list_del_int 完成
-
-
访问链表节点所在的宿主数据结构
-
list_entry_t 通用双向循环链表 仅仅保存了某特定数据结构中链表节点成员变量的地址
-
如何通过这个链表节点成员变量访问到他的所有者(某特定数据结构的变量)
-
Linux 提供了针对该数据结构 XXX 的 leXXX 的宏
- le 为 list entry 简称,是指向数据结构 XXX 中 list_entry_t 成员变量的指针,即存储在双向链表中的结点地址值
- member 是指 XXX数据类型中包含的链表节点的成员变量
-
//free_area是空闲块管理结构,free_area.free_list是空闲块链表头 free_area_t free_area; list_entry_t * le = &free_area.free_list; //le是空闲块链表头指针 while((le=list_next(le)) != &free_area.free_list) { //从第一个节点开始遍历 struct Page *p = le2page(le, page_link); //获取节点所在基于Page数据结构的变量 …… }
-
-
le2page 宏:
-
// convert list entry to page #define le2page(le, member) \ to_struct((le), struct Page, member)
-
-