基于AI+大数据技术的恶意样本分析(一)
阅读Enhancing State-of-the-art Classifiers with API Semantics to Detect Evolved Android Malware翻译及笔记
使用API语义增强最先进的分类器来检测不断发展的安卓恶意软件
论文出处:CCS '20: Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications SecurityOctober 2020 Pages 757–770
原文链接
摘要
机器学习(ML)分类器已被广泛应用于检测安卓恶意软件,但与此同时,ML分类器的应用也面临着一个新出现的问题。考虑到恶意软件的进化,这种分类器的性能会随着时间的推移而显著降低——或者被称为年龄。先前的研究已经提出使用再训练或主动学习来逆转和改进老年模型。然而,底层的分类器本身仍然是盲目的,不知道恶意软件的进化。不出所料,这种对进化不敏感的再训练或主动学习是要付出代价的,也就是说,给数万个恶意软件样本贴上标签和大量人力努力的代价。在本文中,我们提出了第一个框架,称为APIGraph,利用进化的安卓恶意软件之间的相似性恶意软件使用来增强最先进的恶意软件分类器,从而自然地减缓分类器的老化。我们的评估显示,由于分类器老化的速度较慢,APIGraph节省了在标记新的恶意软件样本时主动学习所需的大量人力。
关键字 :
进化的恶意软件检测,API语义,模型老化
1、介绍
机器学习(ML)分类器在实践中被广泛应用于检测安卓恶意软件,并取得了惊人的性能。尽管取得了成功,但在恶意软件检测中应用ML的一个新兴问题是恶意软件的发展,以增强功能和避免被检测到,从而导致随着时间的推移,ML分类模型的性能显著下降。这个问题被定义为模型老化或类似的概念,如时间衰减[39]、模型退化[24]和恶化[9]。模型老化是严重的:2019年卡巴斯基的一份白皮书[23]显示,一种基于ml的商业分类器的检出率在短短三个月内就从近100%急剧下降到80%以下,在另一种配置下甚至是60%。
考虑到老化问题的严重性,先前的工作提出了检测模型老化和提高恶意软件分类器性能的方法。例如,DroidOL[37]和机器人[49]通过在线学习不断引入新的恶意软件样本。另一个例子是,超越[21]检测模型老化的早期信号,并对模型进行再训练以进行改进。在超越之后,[39]引入了主动学习来选择一小组具有代表性的进化恶意软件样本进行改进。然而,尽管之前的工作可以逆转老化和改进衰减的模型,底层模型仍然在很大程度上没有意识到恶意软件的进化,特别是进化的恶意软件之间的语义。不出所料,他们需要成千上万的带有标签的新恶意软件样本来让底层模型开始进化,这涉及到在标记方面的大量人工工作。
在本文中,我们研究的研究问题是理解为什么恶意软件的进化会降低模型的性能,然后用进化语义增强现有的分类器,以减缓老化。当衰老被减缓时,需要更少的新样本——因此更少的人工标记努力——通过再训练、主动学习或在线学习来改进分类器。鉴于这个问题,我们的关键观察是,在进化过程中,恶意软件样本通常保持相同的语义,但切换到不同的实现,这样进化后的恶意软件就可以避免被现有的分类器检测到。例如,原始的恶意软件可以通过HTTP请求发送一个像IMEI这样的用户标识符,但进化后的恶意软件可以通过套接字发送一个不同的标识符,比如IMSI。在语义上,它们几乎是相同的,但直接观察到的实现是不同的。
具体来说,我们设计了一个框架APIGraph,基于官方文档中提供的信息并从官方文档中提取,构建所谓的Androidapi关系图。图中的每个节点表示一个关键实体,如API、异常或权限;每条边表示两个实体之间的关系,例如一个API抛出异常或需要权限。然后,APIGraph通过将每个API实体转换为集群并将类似API进行嵌入,从关系图中提取API语义。以API集群格式提取的API语义可以进一步用于现有的Android恶意软件分类器中,以检测进化的恶意软件,从而减缓老化。
我们将APIGraph应用于之前的四个安卓恶意软件分类器,即MamaDroid[32]、机器人[49]、Drebin[3]和Drebin-DL[18],并使用自己根据现有指南[39]创建的数据集对它们进行评估,[39]包含从2012年到2018年超过322K的安卓应用程序。我们的评估显示,APIGraph结合上述四种恶意软件分类器可以显著减少标记努力,即根据分类器的不同,从33.07%到96.30%。我们还测量了Tesseract提出的新度量时面积(AUT),并在APIGraph的帮助下显示模型老化显著减缓。
贡献。本文有以下贡献。
- 论文表明,尽管安卓恶意软件会随着时间的推移而进化,但许多语义仍然相同或相似,这让我们有机会在进化后检测它们。
- 论文提出在关系图中表示AndroidAPI的相似性,并设计一个系统APIGraph来构建API关系图并从关系图中提取语义。
- 作者构建了一个跨越7年的大规模进化数据集——该数据集几乎是[39]评估模型老化的先进数据集的三倍。
- 作者将APIGraph的结果,即API集群,应用于四个最先进的安卓恶意软件检测器,并表明手动标记工作的努力显著减少,这些模型的老化显著减慢。

图1:一个激励的例子,说明进化过程中不同恶意软件变化的语义相似性。
2、概述
在本节中,我们将从一个激励的示例开始,然后对系统架构的概述。
2.1 A Motivating Example 一个激励的示例
我们举例说明了一个真实世界的、激励的例子来解释APIGraph如何在进化过程中捕获各种恶意软件版本的语义。据TrendMicro[34,35]称,恶意软件XLoader是一种间谍软件和银行木马,它可以窃取个人身份信息(PII)和金融数据。尽管从2018年4月到2019年底,XLoader已经演变成6个不同的变体,在实现上发生了巨大的变化,但这些变体中的许多语义仍然保持不变。
为了清晰的描述,我们将XLoader的实现反向工程并简化为三个具有代表性的代码片段(称为V1、V2和V3),如图1所示。我们列出了两种类型的语义,它们在这三个版本中保存下来,但具有不同的实现:(i)PII集合,和(ii)向恶意软件服务器发送PII。首先,PII集合从V1中的一个单一源演化到V2中的两个源,然后是V3中的多个源。具体来说,V1只收集设备ID,即IMEI、V2添加MAC地址、V3IMSI和ICCID。其次,恶意软件通过三种不同的实现将PII发送到恶意软件服务器,它们分别是一个HTTP请求(V1中的第6-10行)、一个普通套接字连接(V2中的第7-9行)和一个SSL套接字连接(V3中的第9-11行)。
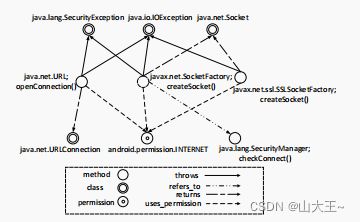
图2:一个说明性的关系图,演示了APIGraph如何捕获图1中不同版本的XLoader的语义。
接下来,我们将解释APIGraph如何在发送PII方面捕获三个不同版本的XLoader之间的语义相似性,从而帮助使用V1训练的ML分类器检测进化的V2和V3。图2显示了由APIGraph构建的关系图的一小部分,它捕获了Androidapi、权限和异常的相互作用。所有三个api——即打开连接、SocketFactory.createSocket和ssl。SSLSocketFactory.createSocket-抛出IOExcepet和使用互联网权限;这三个api中的两个共享更多的异常和权限。也就是说,这三个api在关系图中的邻域上足够接近,可以在一个聚类中聚在一起。因此,ML分类器在关系图的帮助下,可以捕获V2/V3和V1之间的相似性,并在进化后检测出V2和V3为恶意软件。
2.2系统架构
图3显示了APIGraph的整体架构,它构建在一个被称为API关系图的概念的中心部分之上,该概念捕获了所有AndroidAPI的语义意义和相似性。APIGraph有两个主要阶段:(i)构建API关系图,和(ii)利用API关系图。首先,APIGraph通过收集与某个API级别相关的AndroidAPI文档并提取实体——如API和权限——以及这些实体之间的关系来构建一个API关系图。
其次,APIGraph利用API关系图来增强现有的恶意软件检测器。具体来说,APIGraph使用图嵌入算法将关系图中的所有实体转换为向量。这里的见解是,嵌入空间中两个实体之间的向量差反映了关系的语义意义。因此,APIGraph通过求解一个优化问题来生成所有的实体嵌入,使其具有相同关系的两个实体的向量相似。然后,APIGraph将嵌入空间中的所有API实体聚类,将语义上相似的API聚在一起。这些API集群被进一步用于增强现有的分类器,以便它们可以在检测过程中使用某些API级别捕获Android恶意软件的语义等价进化,从而减缓老化。
3、设计
在本节中,我们首先定义关键概念,即我们的API关系图,然后描述如何构建和利用这个API关系图。
一个API关系图=<,>被定义为一个有向图,其中是所有节点(称为实体)的集合,而是两个节点之间的所有边(称为关系)的集合。API关系图是异构的,即有不同的实体和关系类型。
实体类型。 API关系图中有四种实体类型,它们是Android中的基本概念:方法、类、包和权限。前三种实体类型是组织Java程序的关键代码元素,最后一种描述了AndroidAPI在执行期间所需要的资源。这四个实体一起提供了足够的能力来捕获api之间的内部关系。
关系类型。 我们按照之前的工作[25,30]提供的关系分类法定义了10种关系类型,它涵盖了关于API配置文件的不同信息。这十种类型的关系,如表1所示,也被总结为五类,如下描述。
- 组织类别描述了不同实体之间的代码布局关系。考虑到这四种实体类型,我们定义了class_of关系连接类实体与其所属的包实体,function_of关系连接方法实体与其所属实体的类实体,继承关系连接类实体与其继承的类实体。
- 包括三种类型的关系:uses_parameter、返回、抛出关系,它们反映了一个方法实体,可以分别使用一个类实体作为其参数、返回值或抛出的异常。
- 用法类别指定如何使用API。我们关注这种关系的两种类型:条件关系指定一个方法实体对另一个方法实体的条件使用,例如,一个API只能在调用另一个API后使用;替代关系描述一个方法实体可以被另一个方法实体取代。
- 引用类别具有一个refers_to关系,它描述了两个实体之间的一般关系。例如,API文档在使用诸如“请参见……”这样的句子来描述一个方法实体时,可以引用另一个方法实体。
- 权限类别包含uses_permission关系,描述方法实体可能需要的权限实体的关系。
为了构建API关系图,我们需要提取上述类型的实体和关系。在本节的其余部分中,我们将首先介绍AndroidAPI参考文档的组织结构。然后,我们描述了如何从这些文档中提取不同类型的实体和关系。

图3:APIGraph的整体架构。

表1:在APIGraph中定义的关系类型。
3.2 API文件收集
APIGraph从官方网站1下载所有平台API的API和API参考文档。每个Android版本都有相应的API级别,例如Android10的API级别为29。APIGraph抓取API级别14到29的文档,它们对应于Android4.0到android10,它们是目前主要的活跃安卓版本。
AndroidAPI参考文档是分层组织的。从顶层到底层,都有一些软件包、类和方法。API文档是在类的级别上给出的。每个类都有一个HTML文件来描述基本的类层次结构信息,以及这个类中所有方法的详细文档。图4显示了安卓电话文档示例。电话管理器和一个方法得到了()。文档可以分为两部分:1)结构化信息,包括类配置文件和原型、方法的返回值和抛出的异常;2)几种文本格式的非结构化描述,其中描述了API的功能、需求和指令。
3.3 实体提取
在我们的API关系图中有四种实体类型。我们通过以下方式从文档中提取这些实体类型:
- 首先,由于API文档是按类组织的,因此APIGraph从每个类的文档文件中提取一个类实体。如图4所示,一个类的名称是用结构化的文本来描述的。
- 其次,APIGraph通过将包名从完整的类名中拆分来提取包实体。
- 第三,APIGraph将每个类的文档文件解析为文档对象模型(DOM),然后提取属于一个类的方法实体。
- 第四,APIGraph解析清单文件2,其中列出了提取权限实体的所有权限。

图4:一个关于android.电话的API文档的示例。电话管理器。

表2:提取4种关系类型的模板,其中“ENT”表示一个实体。
3.4关系提取
如前所述,由于一些关系,如class_of关系,是组织成结构良好的HTML元素的,而一些关系,如refers_to关系,是嵌入在非结构化文本中的,因此我们采用两种方法从API文档中提取关系。
3.4.1 关系从结构化文本中进行解析。根据表1中定义的关系类型,文档中在结构上描述了6个关系。APIGraph通过直接的文档解析来提取这类关系。以下是详细信息。首先,APIGraph在提取类、方法和包实体的过程中提取function_of和class_of关系。其次,APIGraph从每个类文档文件中的类概要文件部分中提取继承关系。最后,APIGraph提取uses_parameter,返回并在每个方法的原型部分抛出关系。
3.4.2 从非结构化文本中获得的基于3.4.2模板的关系匹配。APIGraph在NLP(自然语言处理)技术的帮助下,使用基于模板的关系匹配方法提取四种类型的关系,即条件、替代、refers_to和uses_permission。请注意,APIGraph还从现有工作[4,5]生成的两个API权限映射中提取uses_permission关系,以补充从API文档中提取的关系,因为AndroidAPI文档中的这些信息可能是不完整的。一般来说,基于模板的关系提取有三个步骤:(i)手动形成匹配模板,(ii)模板集的迭代扩展,(iii)nlp增强的模板匹配。
手动制定匹配的模板。 在此步骤中,我们将手动检查1%的API文档,以调查用于描述这些关系的模式。表2给出了几个正则表达式格式的示例模板,这些模板是手动制定的,以匹配来自非结构化文本的关系。例如,模板“参见ENT”匹配当前方法实体和ENT实体之间的refers_to关系。模板集的迭代扩展。在这一步中,APIGraph采用了一种半自动的策略来迭代地制定关系匹配的模板。本过程中有三个子步骤,如下所述:
- 首先,我们随机选择1%的api并收集它们的文档。
- 其次,我们使用现有的模板集,利用NLP技术从这些文档中提取关系(请在下一段中解释)。
- 第三,在匹配完成后,我们手动检查是否存在现有模板集未捕获的关系。如果答案是肯定的,我们将手动为它们制定模板,并从第一步开始重复。否则,APIGraph完成制定模板以提取所有api的关系。
在上述过程的指导下,模板集在手动查看5%的API文档后收敛。最后,我们总结了217个条件、备选、refers_to和uses_permission关系的模板。表2显示了每个关系的模板编号。整个模板构建过程需要两名安全专家大约三天左右。请注意,Android文档随着时间的推移是稳定的。例如,只添加了1.4%的(834)api,1.6%的(989)api将其描述从API_level28更改为29,并且所有新添加或更改的描述都不需要额外的模板。
nlp增强模板匹配 。APIGraph通过两个步骤将模板与非结构化的API文档进行匹配。首先,APIGraph将段落分成句子,然后通过以下方法对每个句子进行预处理:
- stemming。APIGraph将每个单词简化为它的基本形式,例如,“需要”和“需要”被定义为“需要”。
- 共同参考解决方案。APIGraph采用基于声明的共引用解析[25],将所有的代词解析为基础实体。例如,句子“这个方法需要互联网许可”中的“这个方法”被解析为句子所属的方法。
- 实体名称规范化。APIGraph通过遵循到其原始定义的超链接来替换所有多态名称的精确值,以便APIGraph使实体的表示规范化。例如,这个名字是机器人。清单。权限。互联网和它的恒定价值”。文件中都使用:APIGraph用后者取代前者。
其次,APIGraph将所有模板与API描述中的每个预处理句子进行匹配。如果找到了与模板的匹配,那么APIGraph就会从模板指定的句子中提取关系。如果一个句子不能与任何模板匹配,APIGraph将删除该句子。
3.5利用API关系图
为了利用API关系图,APIGraph将把关系图中的每个API转换为一个嵌入表示,然后将这些嵌入分组到集群中。API嵌入的概念是受单词嵌入[36]和图嵌入的启发,是将关系图中的每个API转换为一个向量,表示其语义意义。我们的转换算法(见算法1),利用先前称为TransE[8]的算法,并将TransE拟合到我们的关系图问题中,描述如下:
(1) APIGraph提取权限实体,并基于公共权限添加新的关系(第3-5行)。这里的直觉是,Android中的权限保留语义,而APIGraph更关注权限。
(2)APIGraph将每个API实体∈(第6-7行)和每个关系∈(第8-9行)分别嵌入向量,∈R。
(3)APIGraph应用TransE算法(第10-14行),在三元组集中对每个三元组(ℎ,,)的∥ℎ+−∥22进行最小化,其中ℎ和是实体,是一个关系。这里的直觉是,如果两个头实体ℎ1,ℎ2与一个共同的尾实体有相同的关系,那么它们的嵌入物ℎ1,ℎ2应该很接近。
(4)APIGraph使用k-Means将API嵌入到不同的组中,并通过Elbow方法[43]确定集群数。
在APIGraph成功聚类api后,APIGraph采用聚类,特别是每个聚类中心的嵌入,来表示集群中独立api的语义。

4.API关系图的结果及实验设置
在本节中,我们将描述生成的API关系图的一些统计数据,在评估中使用的数据集,以及在我们的实验中使用的现有的ML分类器。
4.1API关系图的统计数据
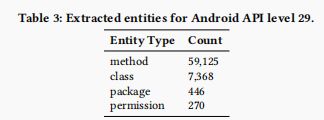
表3:AndroidAPI级别29的提取实体。

表4:AndroidAPI级别29的提取关系。
**实施。**我们的APIGraph原型包含1,627行Python代码,包括AndroidAPI参考文档的收集和解析、关系图的构建以及嵌入的生成和聚类。具体来说,我们使用spaCy(一个PythonNLP工具包)来执行句子分割、翻译和共引用解析,我们的API嵌入和聚类分别是用TensorFlow[44]和技能学习[41]构建的。根据肘部方法[43],我们选择2000作为总簇数。
由APIGraph生成的API关系图的结果用实体和关系来进行描述。具体来说,我们使用API级别29作为示例。表4显示了所提取的实体:有67,209个实体,其中包括59,125个方法、7,368个类、446个软件包和270个权限。请注意,随着API随时间的发展,不同的API级别有不同数量的实体。表4列出了为每种类型提取的关系数量:这些实体之间有121345个关系。
4.2数据集
我们的数据集跨越了7年,包含了322,594个安卓应用程序,即32,089个恶意应用程序和290,505个良性应用程序,如表5所示。以下由[39]记录的数据集有两个重要的特性:时间一致性和空间一致性。前者确保数据样本根据其外观进行排序,并在七年内几乎平均分布;后者认为恶意软件的比例接近现实世界中恶意软件的比例,根据安卓系统的数据,恶意软件的比例为10%。请注意,我们的数据集几乎是目前最先进的数据集的两倍。下面是我们如何构建这个数据集。
- 步骤1:初始恶意软件的选择和验证。我们从三个开放的存储库中下载了所有给定的安卓恶意软件,包括病毒共享[45]、病毒总[46]3和AMD数据集[27,48]。在我们写论文时,这是三个最大的开源数据集,它们一起包含了109,897个独特的恶意软件。然后,我们将所有样本输入病毒Total,只保留109,770个由至少154个反病毒(AV)引擎报告的恶意软件样本。
- 步骤2:良性应用程序的初始选择和验证。在AndroZoo[13]的帮助下,我们下载了106万个谷歌播放应用程序。同样,我们将所有的应用程序提供给病毒总数,只保留1033073个被病毒总数的所有av报告为良性的。
- 步骤3:最终的数据集构建。我们根据样本的外观时间戳订购所有样本,并在7年内的每个月选择一个子集。具体来说,我们一个月最多选择500个恶意软件样本:如果那个月的数字小于500,我们选择所有;如果超过500,我们随机选择500个。我们还随机选择一个月内9次恶意软件的良性应用程序。
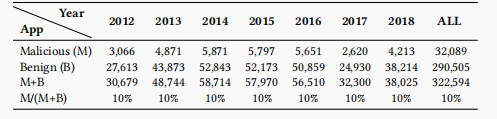
表5:评估数据集。该数据集包含了从2012年到2018年的322,594个应用程序。对于每个月,恶意软件的比例为10%。当有足够的应用程序可用时,大多数月份包含约5K的应用程序,以成为具有代表性和有效的评估。

表6:安卓恶意软件分类器中的评估。请注意,DroidEvolver使用了一个包含5个线性在线学习算法的模型池
4.3候选分类器和增强
我们描述了在评估中使用的四个最先进的、具有代表性的恶意软件分类器,并在表6中列出了它们。我们选择了在测试器[39]中使用的所有三个分类器,以及最近的一个最先进的工作,即机器人进化器[49],它通过一个模型池延迟分类器老化。这四种分类器跨越了不同的机器学习算法,它们对api的使用也有所不同,但它们都面临着老化问题。特别是,在测试中使用的三个分类器不更新自己;虽然droidevolver基于5个模型的多数投票通过在线学习更新自己,但大多数也可以老化,这样的错误可能会传播到所有的模型。
现在让我们详细描述这四个分类器,以及APIGraph如何通过减缓老化过程来增强这些工作。值得注意的是,我们的分类器取决于外观的目标应用,也就是说,如果分类器的目标应用程序从2012年,我们的增强将使用API关系图API的18级,因为这是2012年最新的API水平。
- MamaDroid[32]提取API调用对(即调用者和被调用者),然后将它们抽象为包调用对。5接下来,MamaDroid构建一个马尔可夫链来建模不同包之间的转换,并将包之间的转换概率作为学习算法中应用程序的特征向量。我们得到了MamaDroid的整个源代码,并使用与论文相同的配置。APIGraph将用API集群对替换MamaDroid实现中使用的每个API调用对,然后在Markov链中使用这些调用对。
- [49]通过静态分析找到一个应用程序中所有使用的API,然后构建一个API出现的二进制向量作为应用程序的特征向量。在此之后,DroidEvolver维护了一个由五种线性在线学习算法组成的模型池,以使用加权投票算法对一个应用程序进行分类。当池中的某个模型老化时,它将根据其他未老化模型的结果进行增量更新。我们得到了DroidEvolver的源代码,并联系了作者,以确保我们的实验与他们的论文进行得一致。在我们的增强中,APIGraph将API出现的二进制向量替换为API集群出现的一个向量。
- Drebin[3]收集了广泛的特性,如所使用的硬件、API调用、权限和基于SVM的分类器的网络地址。根据API特性,Drebin考虑了一组受限的和可疑的API,它们可以访问关键的和敏感的数据或资源。我们严格按照本文的详细描述和配置来实现Drebin。APIGraph还将上述子集中API出现的二进制向量替换为为了增强的API集群出现的向量。
- Drebin-DL[18]使用与Drebin相同的特征集,但采用深度神经网络(DNN)作为算法进行分类。我们也遵循之前的工作[18]来实现Drebin-DL。使用APIGraph对Drebin-DL的增强与Drebin相同。
5评估
在本节中,我们将评估APIGraph在增强最先进的分类器以及捕获Androidapi之间的语义相似性方面的有效性。具体来说,我们的评估回答了以下四个研究问题。
- RQ1:模型的可维护性分析。APIGraph在维护恶意软件分类器的高性能方面,APIGraph节省了多少人工标记工作?(见5.1)
- RQ2:模型可持续性分析。APIGraph在减缓分类器老化方面的效果如何?(见5.2)
- RQ3:特征空间稳定性分析。APIGraph在捕获来自同一家族的进化恶意软件之间的相似性方面有多有效?(见5.3)
- RQ4:API闭合性分析。按APIGraph分组的集群中的api有多近?(见5.4)
5.1RQ1:模型可维护性分析
本研究问题的目的是找出APIGraph在保持高性能分类器的同时可以节省多少人力资源。具体来说,我们比较了主动学习在维护原始分类器和增强分类器方面所需的人力努力。让我们来看看一些细节。首先,比较采用了两个指标,即(i)要标记的恶意软件的数量和(ii)再训练的频率。其次,采用不确定抽样[39]实现主动学习,主动选择最不确定的预测进行标记。我们进一步采用了主动学习的两种设置,即引入新样本的最小1分数和一个固定的新样本比率。
5.1.1 具有固定再训练阈值的主动学习。在第一种设置中,当分类器的1分数低于低阈值时,使用主动学习选择最多1%的不确定样本进行再训练,然后逐渐将该百分比提高1%,直到1分数达到另一个更高的阈值ℎ。在实验中,2012年对所有应用程序的分类器进行训练。然后,我们采用上述标准,应用2013年1月至2018年12月的主动学习,观察要标注的恶意软件数量和再训练频率。
结果:表7显示了2013年至2018年需要标记的恶意软件数量和再训练频率(=0.8,ℎ=0.9)。APIGroid、Droid、Drebin-Dl分别节省了33.07%、37.82%、96.30%和67.29%,并降低了再培养频率。这里有三件事值得注意。首先,Drebin和Drebin-DL都不知道模型老化,因此,APIGraph可以节省大量人类的努力也就不足为奇了。其次,尽管DroidEvolver知道模型的老化,并试图通过在线学习来改进模型,但APIGraph仍然可以节省大量的人力。原因是机器人进化器的大多数结果也可能会出错,从而导致这些错误传播到其他未老化的模型。最后,Drebin与APIGraph结合后,需要标记的样本数量最少。这很有趣,因为尽管Drebin-DL的性能比Drebin更好,但Drebin使用更简单的Mlin更容易维护。
我们还扩展了样本,将标记和再训练时间扩展为累积分布数和月分布数,并在图5中显示它们。一个有趣的现象是,机器人进化者和Drebin-DL的标记样本数量在好几个月里几乎保持不变,但随后突然大量增加,特别是没有APIGraph的帮助。原因是,机器人进化和drebin-dl在一定程度上具有捕捉恶意软件进化的能力,但一旦它们没有捕捉到一种类型的进化,其后果是灾难性的,特别是对机器人进化。这是因为drove会将错误的进化信息传播到池中的其他模型,导致错误的同步。
5.1.2主动学习与不同的学习比例。第二个主动学习设置是将每个月新引入的应用程序的比例固定为1%、2.5%、5%、10%和50%,并测试每个分类器的AUT(1,12m)。类似地,我们用2012年的应用程序训练一个分类器,并从2013年1月到2018年12月每月测试这个分类器。注意,AUT是由Tesseract[39]提出的度量,它定义了每个图中曲线下的面积来表示模型的可持续性,如公式1所示。

表7:[RQ1]图5总结了在固定重训练阈值下主动学习的再训练时间和标记样本数量(=0.8,ℎ=0.9)。

表8:原始(无)和增强(无)分类器的AUT(1,12m)。

其中,f为性能度量(例如,1分数、精度、召回率等),N是测试槽的数量,而()是在时间k时评估的性能度量,在我们的例子中,最终的度量是AUT(1,12m)。接近1的AUT指标意味着随着时间的推移有更好的性能。
结果:我们在表8中显示了应用APIGraph前后的四种评估分类器的结果。这里有两件事值得注意。首先,每个分类器带有APIGraph的AUT都高于没有APIGraph的AUT。这表明,APIGraph确实可以减缓四种不同分类器的模型老化,无论它们是否感知进化。其次,使用APIGraph增强的模型的老化减速是显著的:例如,在增强drovolver后,只有1%的应用的再训练比原始分类器的50%的再训练获得更好的性能。