并发(12)
目录
81.CopyOnWriteArrayList有何缺陷,说说其应用场景?
82.要想用线程安全的队列有哪些选择?
83.ConcurrentLinkedQueue实现的数据结构?
84.ConcurrentLinkedQueue底层原理?
85.ConcurrentLinkedQueue的核心方法有哪些?
86.说说ConcurrentLinkedQueue的HOPS(延迟更新的策略)的设计?
87.ConcurrentLinkedQueue适合什么样的使用场景?
88.什么是BlockingDeque?适合用在什么样的场景?
89.BlockingQueue大家族有哪些?
90.BlockingQueue常用的方法?
81.CopyOnWriteArrayList有何缺陷,说说其应用场景?
CopyOnWriteArrayList有几个缺点:
1.由于写操作的时候,需要拷贝数组,会消耗内存,如果原数组的内容比较多的情况下,可能导致young gc或者full gc
2.不能用于实时读的场景,像拷贝数组,新怎元素都需要时间,所以调用一个set操作之后,读取到数据可能还是旧的,虽然CopyOnWriteArrayList能做到最终一致性,但是还没法满足实时性要求;
CopyOnWriteArrayList合适读多写少的场景,不过这类慎用
因为谁也没法保证CopyOnWriteArrayList到底要放置多少数据,万一数据稍微有点多,每次add/set都要重新复制数组,这个代价实在太高昂了。在高性能的互联网应用中,这种操作分分钟引起故障。
82.要想用线程安全的队列有哪些选择?
Vector,Collections.synchronizedList(List
83.ConcurrentLinkedQueue实现的数据结构?
ConcurrentLinkedQueue的数据结构与LinkedBlockingQueue的数据结构相同,都是使用的链表结构。
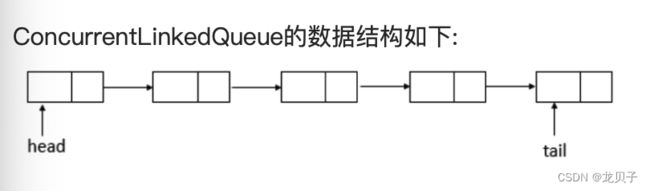
说明:ConcurrentLinkedQueue采用的链表结构,并且包含一个头结点和一个尾结点。
84.ConcurrentLinkedQueue底层原理?

说明:
属性中包含了head域和tail域,表示链表的头结点和为节点,同时,ConcurrentLinkedQueue也使用了反射机制和CAS机制来更新头结点和尾结点,保证原子性。
85.ConcurrentLinkedQueue的核心方法有哪些?
offer(),poll(),peek(),isEmpty()等队列常用方法。
86.说说ConcurrentLinkedQueue的HOPS(延迟更新的策略)的设计?
通过上面对offer和poll方法的分析,我们发现tail和head是延迟更新的,两者更新触发时机为:
1.tail更新触发时机:当tail指向的节点的下一个节点不为null的时候,会执行定位队列真正的队尾节点的操作,找到队尾节点后完成插入之后才会通过casTail进行tail更新;当tail指向的节点的下一个节点为null的时候,只插入节点不更新tail 。
2.head更新触发时机:当head指向的节点的item域为null的时候,会执行定位队列真正的队头节点的操作,找到队头节点后完成删除才会通过updateHead进行head更新;当head指向的节点的item域不为null的时候,只删除节点不更新head。
并且在更新操作时,源码中会有注释为:hop two nodes at a time。所以这种延迟更新策略就被叫做HOPS的大概原因(猜的),从上面更新时的状态图可以看出,head和tail的更新是”跳着的“即中间总是间隔了一个。那么这样设计的意图是什么呢?
如果让tail永远作为队列的队尾节点,实现的代码量会更少,而且逻辑更易懂。但是,这样子做有一个缺点,如果大量的入队操作,每次都要执行CAS进行tail的更新,汇总起来对性能也是会大大的损耗。如果能减少CAS更新的操作,无疑可以大大提升入队的操作效率,所以doug lea大师每间隔1次(tail和队尾节点的距离为1)进行才利用CAS更新tail。对head的更新也是同样的道理,虽然,这样设计会多出在循环中定位队尾节点,但总体来说读的操作效率要远远高于写的性能,因此,多出来的在循环中定位尾节点的操作性能损耗相对而言是很小的。
87.ConcurrentLinkedQueue适合什么样的使用场景?
ConcurrentLinkedQueue通过无锁来做到了更高的并发量,是个高性能的队列,但是使用场景相对不如阻塞队列常见,毕竟取数据也要不停地去循环,不如阻塞的逻辑好设计,但是在并发量特别大的情况下,是个不错的选择,性能上好很多,而且这个队列的设计也是特别费力,尤其的使用的改良算法和对哨兵的处理。整体的思路都是比较严谨的,这个也是使用了无锁造成的,我们自己使用无锁的条件的话,这个队列是个不错的参考。
88.什么是BlockingDeque?适合用在什么样的场景?
BlockingQueue通常用于一个线程生产对象,而另一个线程消费这些对象的场景。
下图是对这个原理的阐述:
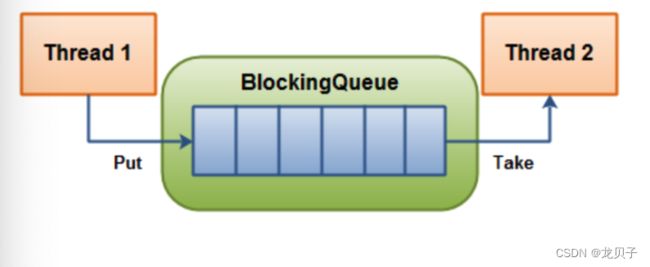
一个线程往里边放,另外一个线程从里面取的一个BlockingQueue。
一个线程将会持续生产新对象并将其插入到队列之中,直到队列达到他所能容纳的临界点。也就是说,他是有限的。如果该阻塞队列到达了其临界点,负责生产的线程将会在往里面插入新对象时发生阻塞。他会一直处于阻塞之中,直到负责消费的线程从队列中拿走一个对象。负责消费的线程将会一直从该阻塞队列中拿出对象。如果消费线程尝试去从一个空的队列中提取对象的话,这个消费线程将会处于阻塞之中,直到一个生产线程把一个对象丢进队列。
89.BlockingQueue大家族有哪些?
ArrayBlockQueue,DelayQueue,LinkedBlockingQueue,SynchronousQueue....
90.BlockingQueue常用的方法?
BlockingQueue具有4组不同的方法用于插入,移除以及对队列中的元素进行检查。如果请求的操作不能得到立即执行的话,每个方法的表现也不同。
这些方法如下:
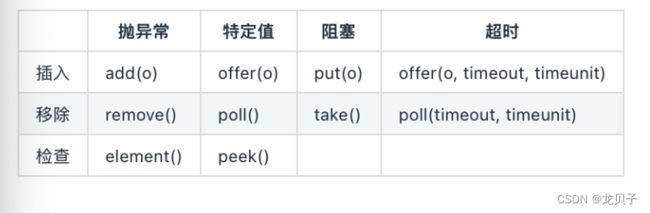
四组不同的行为方式解释:
抛异常:如果试图的操作无法立即执行,抛一个异常。
特定值:如果试图的操作无法立即执行,返回一个特定的值(常常是true/false)。
阻塞:如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行。
超时:如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行,但等待时间不会超过给定值。返回一个特定值以告知该操作是否成功(典型的是true/false)