hive的基本操作
最近新学了hive,想通过写文章的方式对所学知识进行巩固,同时希望可以帮助到大家
Hive是基于Hadoop的一个数据仓库工具
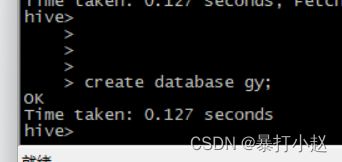
1.创建数据库(创建方法是和Mysql一样的)
create database 数据库名字;
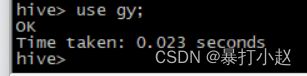
2.使用数据库(创建完之后需要对数据库进行使用才能进行下一步操作)
use 数据库名称;
3.创建表格
create table 表名(id int,name string,age int) ;

4.向表格 中添加数据
insert into 表名 values(1,'zs',20);

5.将本地文件加载到hive中(因为hive不知道1加载的文件用什么隔开,所以需要指定一下)
例如:create table users(id int,name string,age int) row format delimited fields terminated by ' ' (用空格间隔开)

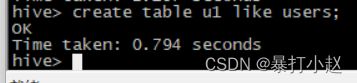
6.创建一模一样的表格
create table 新建表格名字 like 已经创建好的表格名字,本例以创建和user一样的表格为例
7.去重:
insert overwrite table u2 select * from users where age<=19;
8.将users表中age<18的数据查询出来放到u2表,将id>2放到u3
from user insert overwrite table u2 select * where age<=19 insert into table u3 select * where id>2;
9.将users表中age<18的数据查询出来放到本地目录中
insert overwrite local directory '/home/hivedata' row format delimited fields terminated by ',' select * from users where age<18
10.将users表放到hdfs中
insert overwrite directory '/users' row format delimited fields terminated by ' ' select * from users where id<2;
11.修改表名:
alert table users rename to u1;
12.添加列:
alert table u1 add columns (gender string,height double)
13.创建外部表
create external table score(name string,china int,math int,english int) row format delimited fields terminated by ' ' location '/score';
14.当删除内部表的时候,hdfs上的数据会一起删除;当删除外部表时,hdfs上的数据不会被删除
create table cities(id int,name string) partitioned by(orovince string) row format delimited
create table cities(id int,name string) partitioned by(province string) row format delimited fields terminated by ' ';
alter table cities add partition(province='henan') location '/user/hive/wareh
15.多字段分区
create table students(id int,grade string) partitioned by(grade int,class string) row format delimited fields terminated by ' ';
16.建立分桶机制
1.set hive.enforce.bucketing=true;
2.create table s_bucket(id int ,name string,class string) clustered by(name) into 4 buskets row format delimited fields terminated by ' ';
3.向建立的分桶表添加数据
insert into s_bucket select * from students;
4.抽样
bucket x out of y y种的x表示起始桶编号,y表示步长
select * from s_bucket tablesample(bucket 1 out of 2 on name);
create table battles(id int,gp array
17.反转函数
select reverse("abcde");
ps:因为课程比较多,还要复习教资,后续有时间我会继续补充的,嘻嘻