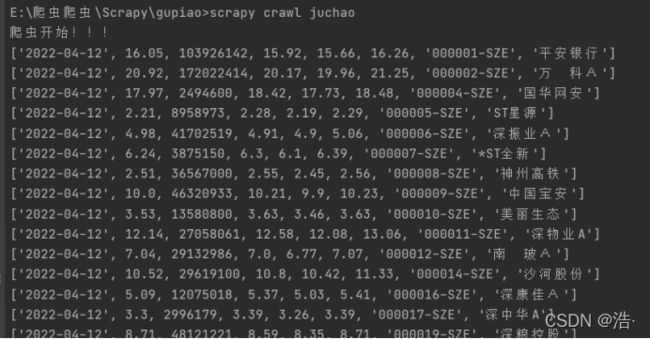
Scrapy实战案例--抓取股票数据并存入SQL数据库(JS逆向)
目标网址:http://webapi.cninfo.com.cn/#/marketDataZhishu
之前在这篇文章里面对该网站的JS进行了一个逆向的解析:JS逆向解析案例
接下来我们来创建一个Scrapy项目来爬取某潮的数据并保存在数据库中
过程:
1、创建一个Scrapy项目
2、将之前用于解析的JS文件放入项目中
3、修改items.py文件,添加要爬取的数据表
4、配置参数,修改setting.py
5、补充spiders文件夹下的核心文件
6、进入自己的数据库、创建数据表
7、写入管道文件pipelines.py,用于保存数据到SQL中
效果截图:

一、创建一个Scrapy项目:
1、打开cmd,用cd命令移动到需要创建项目的位置,
2、输入 :scrapy startproject 项目名。来创建项目
3、cd到创建好的项目目录下
cmd下输入:scrapy genspider 爬虫名 爬取网站的域名
即scrapy genspider 爬虫名 cninfo.com.cn
域名不知道怎么查的可以在这cninfo.com.cn的Whois信息 - 站长工具点击whois然后复制网址过去就能得到该网站的域名

二、将之前用于解析的JS文件放入项目中
新建一个JS文件夹,将解析用的js文件放入文件夹中。
js代码(这部分具体怎么来的可以看一下我的上一篇文章JS逆向解析-巨潮):
/* 通过这个函数获取
var indexcode={
getResCode:function(){
var time=Math.floor(new Date().getTime()/1000);
return window.JSonToCSV.missjson(""+time);
}
}
从这可以知道最终调用了.missjson(""+time)
*/
// 这里要将函数改一下格式
function missjson(input) {
var keyStr = "ABCDEFGHIJKLMNOP" + "QRSTUVWXYZabcdef" + "ghijklmnopqrstuv" + "wxyz0123456789+/" + "=";
var output = "";
var chr1, chr2, chr3 = "";
var enc1, enc2, enc3, enc4 = "";
var i = 0;
do {
chr1 = input.charCodeAt(i++);
chr2 = input.charCodeAt(i++);
chr3 = input.charCodeAt(i++);
enc1 = chr1 >> 2;
enc2 = ((chr1 & 3) << 4) | (chr2 >> 4);
enc3 = ((chr2 & 15) << 2) | (chr3 >> 6);
enc4 = chr3 & 63;
if (isNaN(chr2)) {
enc3 = enc4 = 64;
} else if (isNaN(chr3)) {
enc4 = 64;
}
output = output + keyStr.charAt(enc1) + keyStr.charAt(enc2)
+ keyStr.charAt(enc3) + keyStr.charAt(enc4);
chr1 = chr2 = chr3 = "";
enc1 = enc2 = enc3 = enc4 = "";
} while (i < input.length);
return output;
}
注意:除了js文件之外其他的都是自动生成的,手动创建的话会报错的。

三、修改items.py文件,添加要爬取的数据表
先看一下能爬取的数据:
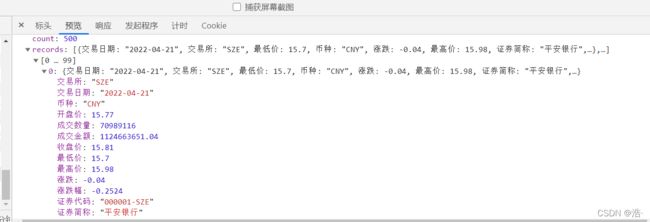
选取直接想要爬取的数据添加在items.py文件中,用scrapy.Field()传输数据
items.py部分代码:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class GupiaoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Transaction_date = scrapy.Field() # 交易日期
Opening_price = scrapy.Field() # 开盘价
Number_of_transactions = scrapy.Field() # 成交数量
Closing_price = scrapy.Field() # 收盘价
minimum_price = scrapy.Field() # 最低价
Highest_price = scrapy.Field() # 最高价
Securities_code = scrapy.Field() # 证券代码
Securities_abbreviation = scrapy.Field() # 证券简称
pass
'''
爬取数据示例
交易所: "SZE"
交易日期: "2022-04-13"
币种: "CNY"
开盘价: 15.89
成交数量: 89062806
成交金额: 1415496125.98
收盘价: 15.8
最低价: 15.72
最高价: 16.08
涨跌: -0.12
涨跌幅: -0.7538
证券代码: "000001-SZE"
证券简称: "平安银行"
'''
四、修改设置文件setting.py
在setting.py文件中修改头部UA、参数等等,屏蔽爬虫日志、同时开启管道pipelines
# Scrapy settings for gupiao project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'gupiao'
SPIDER_MODULES = ['gupiao.spiders']
NEWSPIDER_MODULE = 'gupiao.spiders'
# ------------------获取mcode值----------------------------
import execjs
import js2py
# 调用js文件
with open('E:/爬虫爬虫/Scrapy/gupiao/gupiao/js/123.js', 'r', encoding='utf-8')as f:
read_js = f.read()
return_js = execjs.compile(read_js) #
# 用来获取time参数
time1 = js2py.eval_js('Math.floor(new Date().getTime()/1000)')
mcode = return_js.call('missjson', '{}'.format(time1))
# ------------------获取mcode值----------------------------
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
DEFAULT_REQUEST_HEADERS = {
'mcode': mcode,
'Referer': 'http://webapi.cninfo.com.cn/',
}
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# 屏蔽掉爬虫日志
LOG_LEVEL="WARNING"
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
# 开启管道
'gupiao.pipelines.GupiaoPipeline': 300,
}
五、补充spiders文件夹下的文件
到这一步我们在爬取前需要准备的数据基本已经准备完成了,接下来补充spiders文件夹下的主文件开始爬取网站
import scrapy
from gupiao.items import GupiaoItem # 获取存储的参数列表
class JuchaoSpider(scrapy.Spider):
name = 'juchao'
allowed_domains = ['cninfo.com.cn']
start_urls = ['http://cninfo.com.cn/']
def start_requests(self):
data1 = { # 通过创建的data1字典来构造Form Data表单数据
'tdate': '2022-04-12',
'market': 'SZE',
}
url = 'http://webapi.cninfo.com.cn/api/sysapi/p_sysapi1007'
# POST请求,所以使用scrapy.FormRequest()方法来发送网络请求
# 发送完后通过回调函数callback来将响应内容返回给parse()方法
yield scrapy.FormRequest(url=url,formdata=data1,callback=self.parse)
def parse(self, response):
p = response.json()
if p != None: # 防止取到空
pda = p.get('records') # 获取json文件下参数的对应位置
for i in pda:
item = GupiaoItem()
item['Transaction_date'] = i.get('交易日期')
item['Opening_price'] = i.get('开盘价')
item['Number_of_transactions'] = i.get('成交数量')
item['Closing_price'] = i.get('收盘价')
item['minimum_price'] = i.get('最低价')
item['Highest_price'] = i.get('最高价')
item['Securities_code'] = i.get('证券代码')
item['Securities_abbreviation'] = i.get('证券简称')
yield item
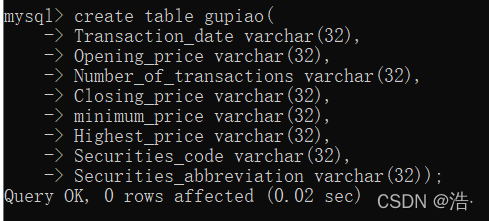
六、进入数据库、创建数据表
1、进入数据库:cmd中输入 mysql -u root -p 输入账号密码
2、创建数据库用于存储:create database 表名;
3、选择数据库、创建数据表:(这里注意一点,表下的字段一定要跟上面的对应得上)
use 表名;
create table 表名(
Transaction_date varchar(32),
Opening_price varchar(32),
Number_of_transactions varchar(32),
Closing_price varchar(32),
minimum_price varchar(32),
Highest_price varchar(32),
Securities_code varchar(32),
Securities_abbreviation varchar(32));
七、写入管道文件pipelines.py,用于保存数据到SQL中
代码:
import pymysql
class GupiaoPipeline:
conn = None
cursor = None
def open_spider(self,spider):
print('爬虫开始!!!')
# 登录sql
self.conn=pymysql.Connection(host='localhost',user='root',passwd='123456',db='juchao')
def process_item(self,item,spider):
print(list(item.values()))
self.cursor=self.conn.cursor()
# 写入数据库
sql2 = "insert into gupiao(Transaction_date,Opening_price,Number_of_transactions,Closing_price,minimum_price,Highest_price,Securities_code,Securities_abbreviation) value(%s,%s,%s,%s,%s,%s,%s,%s);"
# 这一块用来测试输出一下
'''
for i in a:
print(i)
'''
self.cursor.execute(sql2,list(item.values())) # 执行sql语句,将item的值赋予sql中
self.conn.commit()
def close_spider(self,spider):
print('爬虫结束!!!')
self.cursor.close()八、运行Scrapy文件
在根目录下cmd输入:scrapy crawl 爬虫名 来启用爬虫
运行效果截图: