python3爬虫(5):财务报表爬取入库
转载请注明作者和出处: http://blog.csdn.net/c406495762
Github代码获取:https://github.com/Jack-Cherish/python-spider
知乎:https://www.zhihu.com/people/Jack–Cui/
Python版本: Python3.x
运行平台: Windows
IDE: Sublime text3
- 一 前言
- 二 小福利
- 三 实战背景
- 四 网站分析
- 五 编写代码
- 在SQLyog中创建表
- 编写代码
- 六 总结
一 前言
沃伦·巴菲特( Warren Buffett),全球著名的投资商。从事股票、电子现货、基金行业。在2017年7月17日,《福布斯富豪榜》发布,沃伦·巴菲特以净资产734亿美元排名第四。作为”股神”,他的投资理念被许多人追捧。与其共进午餐的慈善活动都可以拍卖到345.67万美元,从中我们可以轻易地看出,他的投资界低位、影响力有多大。

他的投资名言有很多:
- 风险,是来自你不知道你在做什么。
- 若你不打算持有某只股票达十年,则十分钟也不要持有。
- 投资的秘诀,不是评估某一行业对社会的影响有多大,或它的发展前景有多好,而是一间公司有多强的竞争优势。这优势可以维持多久,产品和服务的优越性持久而深厚,才能给投资者带来优厚的回报。
- 我最喜欢的持股时间是……永远!
- 要投资成功,就要拼命阅读。不但读有兴趣购入的公司资料,也要阅读其它竞争者的资料。
从他的这些名言中,我们不难发现,巴菲特做的是长期投资,他投一家公司,抱定的目标是持续持有,不因为价格原因而出售。他看准一家公司,会分析这家公司的竞争优势,也会分析这家公司的对手的竞争优势,然后做出投资决策。他是怎么确定一家公司是否值得自己长期投资,是否具有竞争优势的呢?
其中,最有效、最常用的手段之一就是分析上市公司财务报表
网上有很多《跟巴菲特学看上市公司财务报表》诸如此类的文章,仁者见仁智者见智。本文重点不在于,如何分析财务报表,而是如何获得财务报表,为后续的方便分析做准备!
二 小福利
对于金融这些东西,我是不折不扣的菜菜菜鸟。但是我爱看这些东西,偶尔看一看,还是蛮开心的。我是怎么接触到这些的呢?不得不说下洗脑神书《富爸爸,穷爸爸》,这本书讲得就是这些内容:
- 1.找好的工作
- 2.存钱
- 3.如果找不到好工作,就节约开支存钱。
- 4.把存下来的钱买资产,绝不持币,保证现金流。
- 5.资产就是可以给你带来被动收入的东西。
- 6.当被动收入超过你的开支的时候,你可以把所有的时间拿来创业。
- 7.奔向财务自由。
一说到财务自由,我就来劲儿,好生向往。不过,我也会思考一个问题:对于我来说,我有了一千万,我就算财务自由了吗?
不扯太远,给纯小白的一点推荐:学习理财思想,可以看看《富爸爸,穷爸爸》。想学学经融学的,可以看网易云公开课的《麻省理工学院公开课:MBA金融学》:http://open.163.com/movie/2016/3/H/C/MBGQ5P18G_MBGS0UEHC.html
三 实战背景
每个上市公司的财务报表都是免费提供的,可以在他们的官网进行下载。但是这样一个一个找,太麻烦。有没有一个网站,集成好各个上市公司的财务信息呢?当然有,而且很多!各个金融门户网站都有!
今天,我们看哪个金融门户网站?网易财经!
双手奉上它的地址:http://quotes.money.163.com/hkstock/
这个网站长这样:
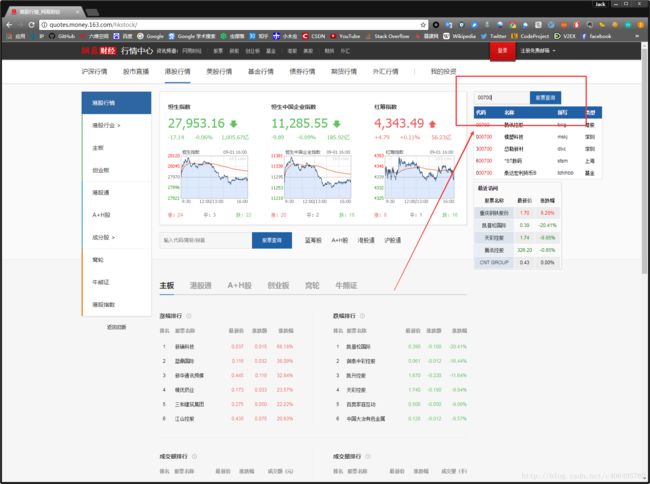
点击查看大图
我们可以通过股票查询,查看股票情况。比如我输入00700,查看腾讯控股在美股的情况。

点击查看大图
可以看到,我截图的时间,腾讯控股”绿了”,也就是跌了。点击财务数据,我们就可以看到腾讯控股的财务报表。
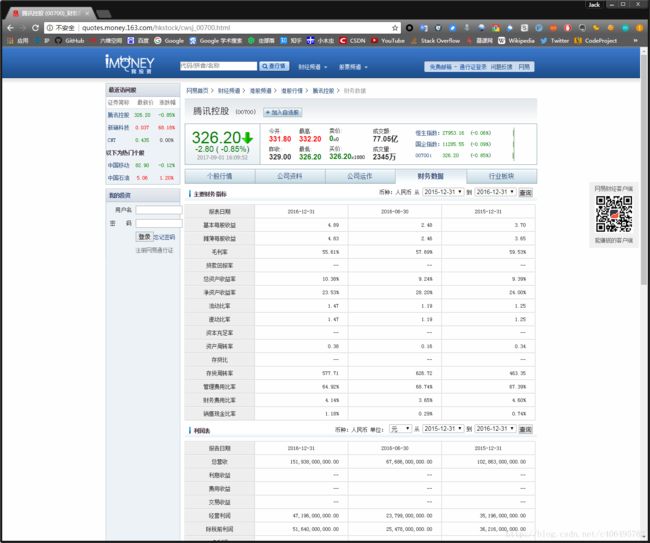
点击查看大图
这个财务数据栏目中,提供了《主要财务指标》、《利润表》、《资产负债表》以及《现金流量表》。可以看到,该网站提供了财务数据在线浏览功能,但是没有提供财务报表下载功能,如何将每年的财务数据获取,并存入数据库,方便我们后续的分析呢?没错,这就是本文的主题:财务报表爬取入库。
四 网站分析
我们以腾讯控股的财务数据为例进行分析。这是它的URL:http://quotes.money.163.com/hkstock/cwsj_00700.html
看一下这个URL地址有什么特点?腾讯控股的股票代码是00700。对的,你没猜错,’http://quotes.money.163.com/hkstock/cwsj_’ + 股票代码 + ‘.html’,就是各个上市公司的财务数据页面。思考一个问题,下图的这些数据,我们需要爬取吗?
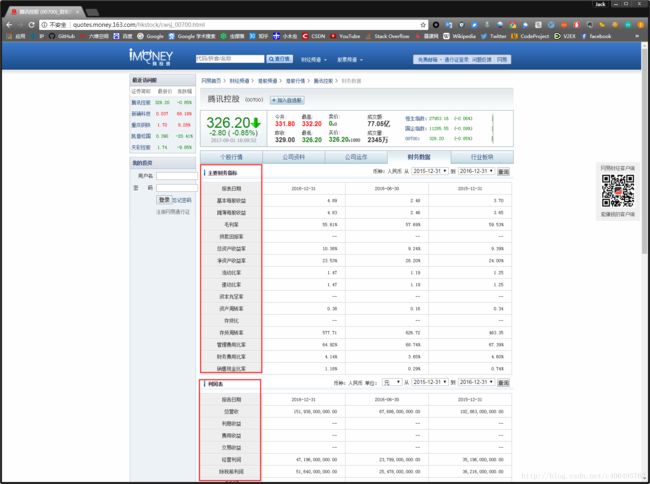
点击查看大图
答曰:不需要!为什么?因为财务报表的格式是统一的。我们需要的是这些报表里的数据,而不是表的栏目名称,这些栏目名称,我们直接手动敲入到数据库中就可以了,直接作为数据库的列名。那么,这些报表数据如何获取呢?请看下图:

点击查看大图
在时间选择框这里,我们可以获取到一共有哪些时间的财务报表。点击查询按钮,我们就可以进行查询,对点击主要财务指标的查询按钮这个动作,使用Fiddler进行抓包分析。抓包截图如下:
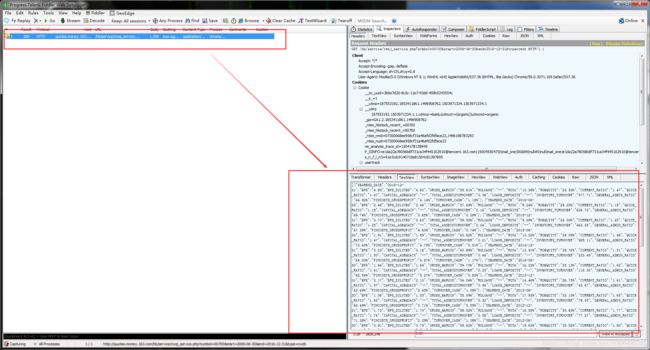
点击查看大图
我们可以看到,这个点击查询按钮,发送的请求地址和返回数据。从上图可以看出返回的数据是以JSON格式存储的。那么我们只要解析出这个JSON数据,就可以获得《主要财务指标》了。同理,通过抓包可知,主要财务指标、利润表、资产负债表、现金流量表请求的URL分别如下:
http://quotes.money.163.com/hk/service/cwsj_service.php?symbol=00700&start=2006-06-30&end=2016-12-31&type=cwzb
http://quotes.money.163.com/hk/service/cwsj_service.php?symbol=00700&start=2006-06-30&end=2016-12-31&type=lrb
http://quotes.money.163.com/hk/hk/service/cwsj_service.php?symbol=00700&start=2006-12-31&end=2016-12-31&type=fzb
http://quotes.money.163.com/hk/service/cwsj_service.php?symbol=00700&start=2006-06-30&end=2016-12-31&type=llb
发现规律了吗?
symbol=股票代码
start=最早的财务报表时间
end=最近的财务报表时间
type=报表缩写(cwz代表主要财务指标,lrb代表利润表,fzb代表负债表,llb代表现金流量表)
已经知道了各个请求的地址,那么接下来就是解析JSON数据了。

点击查看大图
可以看到,数据存储是用的英文,我们得与下图的中文进行对应,创建一个字典进行存储。

点击查看大图
别问我,我是怎么对应出来的。我只想说,我花费了半个多小时,对数据,对得我头晕眼花。
最终生成的对照表如下:

点击查看大图
五 编写代码
在继续看文本之前,希望你已经掌握以下知识:
- SQL基础语法:http://www.runoob.com/sql/sql-tutorial.html
- MySQL数据库的安装与使用:http://blog.csdn.net/c406495762/article/details/56279888
- Python操作mysql数据库的方法:http://www.runoob.com/python/python-mysql.html
- SQLyog的安装与使用:SQLyog是一个快速而简洁的图形化管理MYSQL数据库的工具,它能够在任何地点有效地管理你的数据库。我在我的百度云网盘上传了它的破解版:http://pan.baidu.com/s/1o8hw2Wa
- Python3爬虫基础:http://blog.csdn.net/column/details/15321.html
由于篇幅原因,这些内容不可能全写到文章中,对于上述内容的学习,可以到我提供的链接中进行学习,博客链接都是我写过的文章。爬虫部分需要掌握的内容有:
- requests库的使用:http://blog.csdn.net/c406495762/article/details/72597755
- Beautifulsoup库的使用:http://blog.csdn.net/c406495762/article/details/71158264
1 在SQLyog中创建表。
我们创建一个名字为financialdata的数据库,并根据网站情况创建四个表,分别为cwzb(主要财务指标 )、fzb(资产负债表 )、llb(现金流量表 )、lrb(利润表):

点击查看大图
除了财务报表中的数据,我们还需要额外添加股票名、股票代码、报表日期,用以区分不同股票,不同时间的财务报表情况。各个数据的数据类型,我是粗略分配的,可以根据实际情况和自己的需求进行设置。当然,如果为了省事,可以像我一样:除了报表时间设置为date类型外,其他都设置为char(30)类型即可。好了准备工作都好了,我们开始编写代码吧,需要注意的一点是:在创建数据库连接的时候,我们需要指定charset参数,将其设置为’utf8’,因为数据库中存在中文,如果不设置,数据无法导入。当然,记得更改你的数据库名和密码。
2 编写代码
编写代码如下:
#-*- coding:UTF-8 -*-
import pymysql
import requests
import json
import re
from bs4 import BeautifulSoup
if __name__ == '__main__':
#打开数据库连接:host-连接主机地址,port-端口号,user-用户名,passwd-用户密码,db-数据库名,charset-编码
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='yourpasswd',db='financialdata',charset='utf8')
#使用cursor()方法获取操作游标
cursor = conn.cursor()
#主要财务指标
cwzb_dict = {'EPS':'基本每股收益','EPS_DILUTED':'摊薄每股收益','GROSS_MARGIN':'毛利率',
'CAPITAL_ADEQUACY':'资本充足率','LOANS_DEPOSITS':'贷款回报率','ROTA':'总资产收益率',
'ROEQUITY':'净资产收益率','CURRENT_RATIO':'流动比率','QUICK_RATIO':'速动比率',
'ROLOANS':'存贷比','INVENTORY_TURNOVER':'存货周转率','GENERAL_ADMIN_RATIO':'管理费用比率',
'TOTAL_ASSET2TURNOVER':'资产周转率','FINCOSTS_GROSSPROFIT':'财务费用比率','TURNOVER_CASH':'销售现金比率','YEAREND_DATE':'报表日期'}
#利润表
lrb_dict = {'TURNOVER':'总营收','OPER_PROFIT':'经营利润','PBT':'除税前利润',
'NET_PROF':'净利润','EPS':'每股基本盈利','DPS':'每股派息',
'INCOME_INTEREST':'利息收益','INCOME_NETTRADING':'交易收益','INCOME_NETFEE':'费用收益','YEAREND_DATE':'报表日期'}
#资产负债表
fzb_dict = {
'FIX_ASS':'固定资产','CURR_ASS':'流动资产','CURR_LIAB':'流动负债',
'INVENTORY':'存款','CASH':'现金及银行存结','OTHER_ASS':'其他资产',
'TOTAL_ASS':'总资产','TOTAL_LIAB':'总负债','EQUITY':'股东权益',
'CASH_SHORTTERMFUND':'库存现金及短期资金','DEPOSITS_FROM_CUSTOMER':'客户存款',
'FINANCIALASSET_SALE':'可供出售之证券','LOAN_TO_BANK':'银行同业存款及贷款',
'DERIVATIVES_LIABILITIES':'金融负债','DERIVATIVES_ASSET':'金融资产','YEAREND_DATE':'报表日期'}
#现金流表
llb_dict = {
'CF_NCF_OPERACT':'经营活动产生的现金流','CF_INT_REC':'已收利息','CF_INT_PAID':'已付利息',
'CF_INT_REC':'已收股息','CF_DIV_PAID':'已派股息','CF_INV':'投资活动产生现金流',
'CF_FIN_ACT':'融资活动产生现金流','CF_BEG':'期初现金及现金等价物','CF_CHANGE_CSH':'现金及现金等价物净增加额',
'CF_END':'期末现金及现金等价物','CF_EXCH':'汇率变动影响','YEAREND_DATE':'报表日期'}
#总表
table_dict = {'cwzb':cwzb_dict,'lrb':lrb_dict,'fzb':fzb_dict,'llb':llb_dict}
#请求头
headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.109 Safari/537.36',}
#上市股票地址
target_url = 'http://quotes.money.163.com/hkstock/cwsj_00700.html'
req = requests.get(url = target_url, headers = headers)
req.encoding = 'utf-8'
html = req.text
page_bf = BeautifulSoup(html, 'lxml')
#股票名称,股票代码
name = page_bf.find_all('span', class_ = 'name')[0].string
code = page_bf.find_all('span', class_ = 'code')[0].string
code = re.findall('\d+',code)[0]
#打印股票信息
print(name + ':' + code)
print('')
#存储各个表名的列表
table_name_list = []
table_date_list = []
each_date_list = []
url_list = []
#表名和表时间
table_name = page_bf.find_all('div', class_ = 'titlebar3')
for each_table_name in table_name:
#表名
table_name_list.append(each_table_name.span.string)
#表时间
for each_table_date in each_table_name.div.find_all('select', id = re.compile('.+1$')):
url_list.append(re.findall('(\w+)1',each_table_date.get('id'))[0])
for each_date in each_table_date.find_all('option'):
each_date_list.append(each_date.string)
table_date_list.append(each_date_list)
each_date_list = []
#插入信息
for i in range(len(table_name_list)):
print('表名:',table_name_list[i])
print('')
#获取数据地址
url = 'http://quotes.money.163.com/hk/service/cwsj_service.php?symbol={}&start={}&end={}&type={}&unit=yuan'.format(code,table_date_list[i][-1],table_date_list[i][0],url_list[i])
req_table = requests.get(url = url, headers = headers)
value_dict = {}
for each_data in req_table.json():
value_dict['股票名'] = name
value_dict['股票代码'] = code
for key, value in each_data.items():
if key in table_dict[url_list[i]]:
value_dict[table_dict[url_list[i]][key]] = value
# print(value_dict)
sql1 = """
INSERT INTO %s (`股票名`,`股票代码`,`报表日期`) VALUES ('%s','%s','%s')""" % (url_list[i],value_dict['股票名'],value_dict['股票代码'],value_dict['报表日期'])
print(sql1)
try:
cursor.execute(sql1)
# 执行sql语句
conn.commit()
except:
# 发生错误时回滚
conn.rollback()
for key, value in value_dict.items():
if key not in ['股票名','股票代码','报表日期']:
sql2 = """
UPDATE %s SET %s='%s' WHERE `股票名`='%s' AND `报表日期`='%s'""" % (url_list[i],key,value,value_dict['股票名'],value_dict['报表日期'])
print(sql2)
try:
cursor.execute(sql2)
# 执行sql语句
conn.commit()
except:
# 发生错误时回滚
conn.rollback()
value_dict = {}
# 关闭数据库连接
cursor.close()
conn.close()
看下运行效果:我们已经顺利地将腾讯控股的财务报表带入数据库中了:
点击查看大图
上述代码比较粗糙,继续完善代码。对代码进行重构,创建一个获取数据报表的类。根据用户输入股票代码,下载相应股票的财务报表,并显示下载进度,实现效果如下所示:

点击查看大图
一直在看,何不自己写个代码试试?实现效果如上图所示!只有自己动手,才能体会到编程的快乐,对知识掌握也就更加扎实。
如果你觉得代码编写的代码差不多了,想对照代码看一看或者感觉自己无需动手,这种东西就可以轻松掌握。那么可以从我的Github获取上图实现效果的代码:https://github.com/Jack-Cherish/python-spider/blob/master/financical.py
六 总结
本文没有实现批量上市公司财务报表的获取与入库。因为方法有很多,首先,我们可以根据用户提供的股票代码进行批量下载。比如用户输入:00700,00701,00702。然后程序根据输入的股票代码,进行相应的解析,创建出对应的URL链接,即可实现批量下载。另外,也可以通过程序自动获取链接,比如网易财经提供了各个股票板块的涨幅排行榜、跌幅排行榜、成交额排行榜等,我们通过获取这些股票的链接,也可以进行财务报表批量下载。方法很简单,因此不再累述。
其他:
- 一个我不认识的,看我爬虫教程的朋友跟我说,想看爬取数据入库的文章。我说我会出,现在遵守了承诺!
- 大家有想看的爬虫内容可以留言,我会视情况(时间不足),出相应教程的。
- 在使用MySQL创建数据库连接的时候,如果数据库(utf8编码)中有中文,一定要记得设置charset参数为utf8(对应数据库编码)!
- 学习SQL很有帮助,数据库查询很方便,方便我们进行数据分析。
- 所有爬虫实战的代码,均可以在我的Github进行下载(Star数量要破100了!给个助攻好不好?):https://github.com/Jack-Cherish/python-spider
- 如有问题,请留言。如有错误,还望指正,谢谢!