web端自动化测试1--selenium基础
文章目录
-
- 一、自动化测试相关知识
-
- 1 什么是自动化测试
- 2 为什么进行自动化测试
- 3 自动化测试的分类
-
- 一.自动化功能测试:
- 二.性能测试
- 4 web自动化条件和使用范围
-
- 使用自动化的前提条件
- 使用自动化测试的场景
- 5 web自动化常用的工具
-
- 常见的自动化web测试工具
- QTP与Selenium的比较
- 趋势
- 二、元素定位
-
- 1 环境与工具
- 2 css选择器
-
- 1.什么是CSS选择器?
- 3 xpath
-
- 1.什么是xpath?
- 2.什么是XML?
- 3.XML与HTML的区别
- 4.xpath路径表达式
- 三、selenium自动化测试框架
-
- 1.Selenium概述
-
- 什么是Selenium?
- Selenium的特点
- Selenium的工作原理
- Selenium的环境搭建(火狐环境)
- 2.牛刀小试之Selenium IDE
-
- 简介
- 安装 selenium IDE
- 3.Selenium API基础
-
- 1.浏览器驱动对象
- 2.页面操作
- 4.Selenium API高级
-
- 1.多标签之间的切换
- 2.多表单的切换
- 3.鼠标和键盘操作
- 4. 弹出框操作
- 5.下拉框操作
- 6.调用js代码
- 7.浏览器等待
- 8.cookies操作
- 5.Selenium API简单封装
- 四、unittest模块
-
- 1 unittest基本概念
- 2 unittest基本用法
- 3 unittest断言
- 4 unittest命令行接口
- 5 unittest与selenium



一、自动化测试相关知识
1 什么是自动化测试
软件自动化测试就是通过测试工具或者其他手段,按照测试人员的预定计划对软件产品进行自动化测试,他是软件测试的一个重要组成部分,能够完成许多手工测试无法完成或者难以实现的测试工作,正确合理的实施自动化测试,能够快速,全面的对软件进行测试,从而提高软件质量,节省经费,缩短软件的发布周期。
2 为什么进行自动化测试
自动化测试主要有这么些好处:
1、缩短测试周期
比如说某个公司做的是通信类产品,一般通信类软件生命周期是非常长的,因此回归测试成为了家常便饭,出一个版本就需要投入人力进行回归,这样带来的问题就是需要回归测试周期能够尽量缩短。而自动化测试能够有效的解决这个问题,如果实现了这些自动化测试脚本,可以在夜间,午休等时间进行测试用例回归,实现无人值守测试,大大提高了测试效率,从多个版本累计看来,有效缩短了测试周期。
2、避免人为出错
说到自动化测试,与之对应的就是手工测试,所谓“人非圣贤,孰能无过”,传统的手工测试很大部分依赖于人,简单概括起来出错的可能性会有:
- 用例执行方法出错
- 输入数据出错
- 用例执行步骤出错
- 测试报告数据出错
- 忘了执行某些用例
- 忘了设置预置条件
- 错误的理解被测系统的行为
通过实现自动化,可以避免出现这些错误。
3、测试信息存储
自动化测试主要通过自动化脚本实现,和传统的手工用例相比,脚本中可以记录测试点,测试拓扑图,测试设计思路等信息,是非常理想的测试信息存储处,即“脚本体现思路”。另外带来的好处就是新人接收测试时,可以快速掌握已测试点,因为可以通过运行了解测试。
4、轻易获取覆盖率
在较好的自动化框架下,测试执行完自动化脚本,可以轻易的获取到代码覆盖率,进而根据覆盖情况分析,进行测试用例补充。由于使用了自动化测试,我们可以从手动测试中解放出来,将经理集中在设计测试用例上,这样就能更好的提高测试质量
5、其他
比如:自动生成清晰的测试报告,定时执行测试套,数据驱动测试的测试套重用等。这些是本人暂未体会到的,但和一个网友交流时获取的。
3 自动化测试的分类
自动化测试分类:
一.自动化功能测试
二.自动化性能测试
一.自动化功能测试:
- 单元测试(一般在代码生产过程中,由程序猿自己进行测试)
比如我们去4s店买车,有这么两款车,你会选哪个?
1.昨天刚组装好,跑了一天没有问题
2.每一个零件生产之后都经过国家标准的质量检测,组装完成后测试没有问题
- 功能测试
主要由测试人员进行功能测试,目前大部分应用以web为主。 - 接口测试
主要由测试人员进行接口测试,利用相关工具进行
自动化功能测试的主要工作:主要是编写代码、脚本,让软件自动运行,发现缺陷,代替部分的手工测试。但一般只有大的项目才需要进行自动化,中小型项目不推荐使用自动化测试。
二.性能测试
主要是使用测试工具,Loadrunner、Jmeter等,对软件进行压力测试、负载测试、强度测试等等,因为这些无法用手工进行代替,所以必须自动化。
4 web自动化条件和使用范围
使用自动化的前提条件
- 手动测试已经完成
- 项目周期长
- 需求稳定
使用自动化测试的场景
- 频繁的回归测试
- 互联网迭代频繁
- 传统行业需求变化不大,应用频繁
- 性能测试
5 web自动化常用的工具
常见的自动化web测试工具
- QTP(收费)
QTP是Mercury公司的Quick Test Professional的简称,是一种自动测试工具。使用QTP的目的是想用它来执行重复的自动化测试,主要是用于回归测试和测试同一软件的新版本。因此你在测试前要考虑好如何对应用程序进行测试,例如要测试哪些功能、操作步骤、输入数据和期望的输出数据等,后来Mecury公司被惠普收购 - Selenium(开源)
Selenium是ThroughtWorks一个强大的基于浏览器的开源自动化测试工具,通常用来编写web应用的自动化测试 - RFT(收费)
IBM Rational Test Professional的简称,是一款先进的自动化的功能和回归测试工具,使用与测试人员和GUI开发人员,基础是针对Java,.NET的对象计数和基于web应用程序的录制,回放功能。 - Watir(开源)
使用Ruby实现的开源web自动化测试框架,小巧灵活 - Sahi(开源)
印度一家公司开发的web自动化测试工具,简单易用,支持Ajax和web2.0
QTP与Selenium的比较
- Selenium是开源的、免费的,QTP是商业版、收费的
- Selenium支持java/python/ruby/php等,QTP早期版本只支持vbs
- Selenium只能测试浏览器,QTP则都可以
- Selenium支持操作系统多,而QTP只支持Windows
- Selenium支持各大主流浏览器:I.E./Firefox/Chrome,而QTP只支持I.E.
趋势
- 谷歌趋势(需要)
- 百度指数
二、元素定位
前言:我们在手动测试的时候通过眼看,手操作鼠标点击,手敲击键盘输入来执行我们的测试用例,那么我们在使用自动化测试的时候就需要解放我们的双手双眼,让计算机来帮我们做刚刚说的那些工作,而我们的元素定位是让计算机找到可以操作的按钮的最终要的方法
学习目标:
- 掌握主流浏览器及相应插件的使用
- 掌握xpath,css选择器其中一种定位方式,了解另外一种
1 环境与工具
材料:
1)firefox35
2)firebug插件
3)firepath插件
2 css选择器
1.什么是CSS选择器?
- CSS 中,选择器是一种模式,用于选择需要添加样式的元素。计算机能够通过css选择器定位到相应元素,我们在编写自动化测试脚本的时候很多时候是在不断地找到css选择器。
通过id,class等定位元素

通过元素之间的嵌套定位元素

通过元素的属性定位元素

通过父子关系定位元素

通过元素状态定位元素
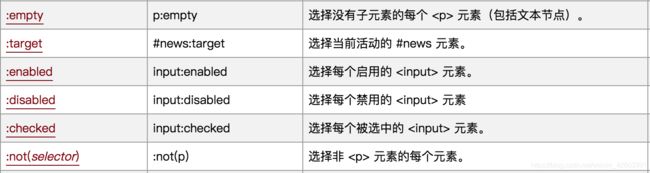
其他
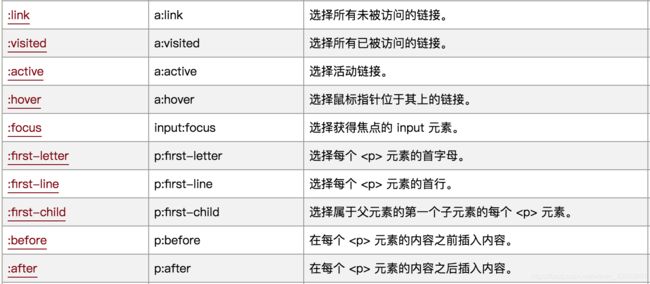
学习练习网站
CSS选择器
3 xpath
1.什么是xpath?
- XPath即为XML路径语言,它是一种用来(标准通用标记语言的子集)在 HTML\XML 文档中查找信息的语言。
W3School官方文档:http://www.w3school.com.cn/xpath/index.asp
2.什么是XML?
XML 指可扩展标记语言(EXtensible Markup Language)
XML 是一种标记语言,很类似 HTML
XML 的设计宗旨是传输数据,而非显示数据
3.XML与HTML的区别

4.xpath路径表达式
选取节点
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
下面列出了最常用的路径表达式:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| … | 选取当前节点的父节点。 |
| @ | 选取属性。 |
| 在下面的表格中,我们已列出了一些路径表达式以及表达式的结果: | |
| 路径表达式 | 结果 |
| – | – |
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore | 选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
| 谓语(Predicates) |
谓语用来查找某个特定的节点或者包含某个指定的值的节点,被嵌在方括号中。
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position() < 3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=’eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
| 选取未知节点 | |
| XPath 通配符可用来选取未知的 XML 元素。 | |
| 通配符 | 描述 |
| – | – |
- |匹配任何元素节点。
@* |匹配任何属性节点。
node() |匹配任何类型的节点。
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
路径表达式 |结果
|–|–
/bookstore/* |选取 bookstore 元素的所有子元素。
//* |选取文档中的所有元素。
//title[@*] |选取所有带有属性的 title 元素。
选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:

补充:
//*[text()=“x’x’x”] 文本内容是xxx的元素
//*[starts-with(@attribute,’xxx’)] 属性attribute以xxx开头的元素
//*[contains(@attribute,’xxxxx’)] 属性attribute中含有xxx的元素
//*[@attribute1=value1 and @attribute2=value2] 同时有两个属性attribute1和attribute2值的元素
三、selenium自动化测试框架
1.Selenium概述
什么是Selenium?
- Selenium是ThoughtWorks公司的一个强大的开源Web功能测试工具系列,采用Javascript来管理整个测试过程,包括读入测试套件、执行测试和记录测试结果。
Selenium的特点
1)它采用Javascript单元测试工具JSUnit为核心,只要在测试用例中把预期的用户行为与结果都描述出来,我们就得到了一个可以自动化运行的功能测试套件。
2)Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。
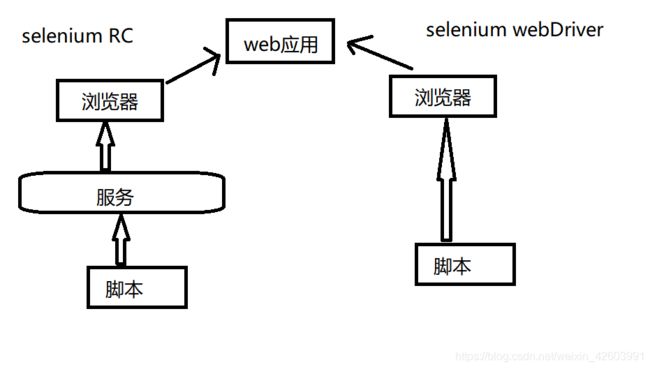
Selenium的工作原理
- selenium IDE(插件,相当于录屏软件)、selenium RC、selenium WebDriver(重点)、selenium Gird
selenium RC 速度慢 执行脚本中间有个服务器 不支持移动端
selenium webDriver 速度快 脚本直接和浏览器交互 支持移动端
Selenium的环境搭建(火狐环境)
1.安装python版本(安装完检测:cmd命令输入python -V)
python下载地址
2.selenium框架
第一步后输入pip install -U selenium即可;检测方式:输入pip show selenium
3.Firefox浏览器(官网下载)-这里使用V55.0.1
各火狐浏览器版本地址
4.火狐浏览器驱动(将驱动安装在python目录下;安装前将python安装路径添加到电脑环境变量)–这里使用V0.19.1
Firefox驱动下载地址
5.可选IDE软件pycharm作为工具
- pycharm常用快捷键
Ctrl + / 行注释(可选中多行)
Ctrl + Alt + L 代码格式化
Ctrl + D 复制选定的区域
Ctrl + Y 删除当前行
Shift + Enter 换行(不用鼠标操作了)
Ctrl + Shift +/- 展开/折叠全部代码块
Ctrl + Shift + up 快速上移某一行
Ctrl + Shift + down 快速下移某一行
Alt + Enter 快速修正代码
Ctrl + Space 基本的代码完成(类、方法、属性)
2.牛刀小试之Selenium IDE
简介
Selenium的IDE(集成开发环境)是一个易于使用的Firefox插件,用于开发Selenium测试案例。它提供了一个图形用户界面,用于记录使用Firefox浏览器,用来学习和使用Selenium用户操作,但它只能用于只用Firefox浏览器不支持其它浏览器。(录制功能是Selenium IDE的一个重要特性)
安装 selenium IDE
1.下载 Mozilla Firefox 浏览器
Firefox下载地址
2.下载 selenium IDE插件
selenium IDE 下载地址

3.Selenium API基础
1.浏览器驱动对象
- 库的导入
- 创建浏览器对象
- 浏览器尺寸相关操作
- 浏览器位置相关操作
- 浏览器关闭操作
# 导入webdriver
from selenium import webdriver
# 创建一个浏览器对象
dr = webdriver.Firefox()
# 设置全屏
dr.maximize_window()
# 获取当前浏览器尺寸
size = dr.get_window_size()
print(size)
# 设置浏览器尺寸
dr.set_window_size(400, 400)
size = dr.get_window_size()
print(size)
# print(dir(dr))
# 获取浏览器位置
position = dr.get_window_position()
print(position)
# 设置浏览器位置
dr.set_window_position(100, 200)
# 关闭浏览器
dr.close() # 关闭当前标签/窗口
# dr.quit() 关闭所有标签/窗口
2.页面操作
- url的格式
形式 scheme://host[:port#]/path/…/[?query-string][#anchor]
scheme:协议(例如:http, https, ftp)
host:服务器的IP地址或者域名
port:服务器的端口(如果是走协议默认端口,80 or 443)
path:访问资源的路径
http://www.cnblogs.com/be-saber/p/4734951.html
query-string:参数,发送给http服务器的数据,参数使用&隔开
anchor:锚(跳转到网页的指定锚点位置)
https://detail.tmall.com/item.htm?id=545181862652
- 页面请求操作
# 导入webdriver
from selenium import webdriver
import time
# 创建一个浏览器对象
dr = webdriver.Firefox()
# 访问百度
time.sleep(2)
url1 = 'http://www.baidu.com'
dr.get(url1)
# 访问虎牙
time.sleep(2)
url2 = 'https://www.huya.com/'
dr.get(url2)
# 后退操作
time.sleep(2)
dr.back()
# 前进操作
time.sleep(2)
dr.forward()
# 关闭
dr.quit()
- 获取断言信息
- 什么是断言
断言是编程术语,表示为一些布尔表达式,程序员相信在程序中的某个特定点该表达式值为真,可以在任何时候启用和禁用断言验证,因此可以在测试时启用断言而在部署时禁用断言。
- 获取断言操作
# 导入webdriver
from selenium import webdriver
# 创建一个浏览器对象
dr = webdriver.Firefox()
# 访问百度
url = 'http://www.baidu.com/'
dr.get(url)
# 显示当前URL
print(dr.current_url)
# 显示当前的页面标题
print(dr.title)
# 保存快照操作
# 自动写文件保存
# dr.get_screenshot_as_file('baidu.png')
# 自己写文件保存
data1 = dr.get_screenshot_as_png()
with open('baidu2.png', 'wb') as f:
f.write(data1)
# 网页源码
data2 = dr.page_source
# 以二进制类型写入文件
with open('baidu.html', 'wb') as f:
f.write(data2.encode())
# str类型数据(data)转换成byte类型(二进制类型)
# b_data=data2.encode()
# data2=b_data.decode()
dr.close()
- 元素的定位
- 元素定位方法分类(调用方式):
直接调用型(推荐) driver.find_element_by_xxx(value)
# 导入库
from selenium import webdriver
import time
# 解决selenium webdriver打开不了带插件Firefox浏览器
profileDir = r"C:\Users\xxx\AppData\Roaming\Mozilla\Firefox\Profiles\izzusuhg.default"
profile = webdriver.FirefoxProfile(profileDir)
# 创建一个浏览器对象
dr = webdriver.Firefox(profile)
# 访问百度
url = 'http://www.baidu.com/'
dr.get(url)
# 定位到搜索框元素
el = dr.find_element_by_id('kw')
# print(el)
# print(type(el))
# 向输入框中输入数据
el.send_keys('wyf是沙雕')
el_click = dr.find_element_by_id('su')
el_click.click()
time.sleep(2)
dr.close()
使用By类型(需要导入By)
from selenium.webdriver.common.by import By
driver.find_element(By_xxx,value)
- 元素8种定位方式(重点):

- 元素的操作
对元素的相关操作,一般要先获取到元素,再调用相关方法
element = driver.find_element_by_xxx(value)
1)点击和输入
点击操作
element.click()
清空/输入操作(只能操作可以输入文本的元素)
element.clear() 清空输入框
element.send_keys(data) 输入数据
2)提交操作
element.submit()
3)获取元素信息
获取文本内容(既开闭标签之间的内容)
element.text
获取属性值(获取element元素的value属性的值)
element.get_attribute(value)
获取元素尺寸(了解)
element.size
获取元素是否可见(了解)
element.is_dispalyed()
4.Selenium API高级
1.多标签之间的切换
场景:有的时候点击一个链接,新页面并非由当前页面跳转过去,而是新开一个页面打开,这种情况下,计算机需要识别多标签或窗口的情况。
1)获取所有窗口的句柄
handles = driver.window_handlers()
调用该方法会得到一个列表,在selenium运行过程中的每一个窗口都有一个对应的值存放在里面。
2)通过窗口的句柄进入的窗口
driver.switch_to_window(handles[n])
driver.switch_to.window(handles[n])
通过窗口句柄激活进入某一窗口
2.多表单的切换
在网页中,表单嵌套是很常见的情况,尤其是在登录的场景
- 什么是多表单?
实际上就是使用iframe/frame,引用了其他页面的链接,真正的页面数据并没有出现在当前源码中,但是在浏览器中我们看到,简单理解可以使页面中开了一个窗口显示另一个页面
- 处理方法
直接使用id值切换进表单
driver.switch_to.frame(value)/driver.switch_to_frame(value)
定位到表单元素,再切换进入
el = driver.find_element_by_xxx(value)
driver.switch_to.frame(el) /driver.switch_to_frame(el)
跳回最外层的页面
driver.switch_to.default_content()
跳回上层的页面
driver.switch_to.parent_frame()
3.鼠标和键盘操作
手动测试时键盘的操作在selenium页有实现,关于鼠标的操作由ActionChains()类来提供,关于键盘的操作由Key()类来提供
- 鼠标操作
from selenium import webdriver
# 导入动作链类,动作链可以储存鼠标的动作,并一起执行
from selenium.webdriver import ActionChains
# 开浏览器
driver = webdriver.Firefox()
# 访问百度
url = 'http://www.baidu.com'
driver.get(url)
* 鼠标右击操作
# 操作元素前,需要将操作的元素定位出来并且穿入相应的动作中,如果要执行操作,需要调用perform()
el = driver.find_element_by_xxx(value)
ActionChains(driver).context_click(el).perform()
* 双击操作
el = driver.find_element_by_xxx(value)
ActionChains(driver).double_click(el).perform()
* 鼠标悬停
el = driver.find_element_by_xxx(value)
ActionChains(driver).move_to_element(el).perform()
- 键盘操作
键盘操作使用的是Keys类,一般配合send_keys使用
* 导入
from selenium.webdriver.common.key import Key
* 常用键盘操作
send_keys(Keys.BACK_SPACE) 删除键(BackSpace)
send_keys(Keys.SPACE) 空格键(Space)
send_keys(Keys.TAB) 制表键(Tab)
send_keys(Keys.ESCAPE) 回退键(Esc)
send_keys(Keys.ENTER) 回车键(Enter)
send_keys(Keys.CONTROL,‘a’) 全选(Ctrl+A)
send_keys(Keys.CONTROL,‘c’) 复制(Ctrl+C)
send_keys(Keys.CONTROL,‘x’) 剪切(Ctrl+X)
send_keys(Keys.CONTROL,‘v’) 粘贴(Ctrl+V)
send_keys(Keys.F1) 键盘 F1
……
send_keys(Keys.F12) 键盘 F12
案例:必应搜索-键盘操作
from selenium import webdriver
# 导入Key类,key类中包含很多键盘按钮操作
from selenium.webdriver.common.keys import Keys
import time
# 打开浏览器
driver = webdriver.Firefox()
# 访问必应搜索
url= 'http://cn.bing.com/'
driver.get(url)
# 定位到输入框
el = driver.find_element_by_id('sb_form_q')
# 输入关键字
el.send_keys('selenium')
time.sleep(1)
el.send_keys(Keys.CONTROL,'a')
time.sleep(1)
# 执行剪切操作
el.send_keys(Keys.CONTROL,'x')
time.sleep(1)
# 执行粘贴操作
el.send_keys(Keys.CONTROL,'v')
time.sleep(1)
# 清空操作
el.clear()
#输入 单词
el.send_keys('seleniumn')
time.sleep(1)
# 退格删除
el.send_keys(Keys.BACK_SPACE)
time.sleep(5)
driver.quit()
4. 弹出框操作
- 进入到弹出框中
driver.switch_to.alert()
2) 接收警告
accept()
3) 解散警告
dismiss()
4) 发送文本到警告框
send_keys(data)
案例:百度设置-警告框
from selenium import webdriver
import time
# 创建一个浏览器
driver = webdriver.Firefox()
# 访问百度
url = 'http://www.baidu.com'
driver.get(url)
# 定位到设置
el = driver.find_element_by_link_text('设置')
el.click()
# 定位搜索设置,并点击
el_set = driver.find_element_by_css_selector('.setpref')
el_set.click()
# 定位保存设置按钮
el_save = driver.find_element_by_css_selector('.prefpanelgo')
el_save.click()
time.sleep(2)
# 进入警告框中,并且点击接受
# driver.switch_to.alert.accept()
# 进入警告框,并且解散警告框
driver.switch_to.alert.dismiss()
time.sleep(5)
driver.quit()
5.下拉框操作
selenium关于下拉框的操作都交由Select类进行处理,一般获取到下拉框元素之后使用该类构建对象,调用对象的响应方法就能操作元素
1) 导入Select类
from selenium.webdriver.support.select import Select
2) 将定位到的下拉框元素传入Select类中
selobj = Select(element) 下拉框元素已经定位到
3) 调用响应方法选择下拉框中的选项
select_by_index() 通过索引选择,index 索引从 0 开始
select_by_value() 通过值选择(option标签的一个属性值)
select_by_visible_text() 通过文本选择(下拉框的值)
all_selected_options 查看所有已选
first_selected_option 查看第一个已选
is_multiple 查看是否是多选
options 查看选项元素列表
取消选择
deselect_by_index()
deselect_by_value()
deselect_by_visible_text()
6.调用js代码
- 什么是JS?
JavaScript是世界上最流行的脚本语言,因为你在电脑、手机、平板上浏览的所有的网页,简单地说,JavaScript是一种运行在浏览器中的解释型的编程语言,用来给HTML网页增加动态功能。
JavaScript 是属于网络的脚本语言,被数百万计的网页用来改进设计、验证表单、检测浏览器、创建cookies,以及更多的应用。
- 为什么要执行js代码?
因为selenium鞭长莫及,没有操作滚动条的方法,而一般操作滚动条都是使用js实现的。
- selenium执行js
1.重要的js代码
* js = "window.scrollTo(x,y) "
x为水平拖动距离,y为垂直拖动举例
* js= “var q=document.documentElement.scrollTop=n”
n为从顶部往下移动滚动举例
2.driver.execute_script(js) 执行js代码
案例:hao123持续下拉
from selenium import webdriver
import time
# 创建浏览器
driver = webdriver.Firefox()
# 访问好123
url = 'https://www.hao123.com/'
driver.get(url)
for i in range(100):
# x管水平,y管垂直
js = 'window.scrollTo(0,%s)'%(i*100)
driver.execute_script(js)
time.sleep(0.5)
# js1= "var q=document.documentElement.scrollTop=0"
# driver.execute_script(js1)
driver.quit()
7.浏览器等待
1.为什么要进行等待
网速慢;网站内容过多;如果不进行等待而直接定位元素,可能会抛出异常
2.selnium中等待的分类
显示等待;隐式等待
3.显示等待
显示等待是根据条件进行等待,等待条件出现
实现:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECWebDriverWait(driver, timeout, poll_frequency=0.5,
ignored_exceptions=None)WebDriverWait类是由WebDirver 提供的等待方法。在设置时间内,
默认每隔一段时间检测一次当前页面元素是否存在,如果超过设置 时间检测不到则抛出异常。
案例:显示等待百度
from selenium import webdriver
# 导入By
from selenium.webdriver.common.by import By
# 导入webdriver等待类
from selenium.webdriver.support.ui import WebDriverWait
# 导入预期条件设置类
from selenium.webdriver.support import expected_conditions as EC
# 创建一个浏览器
driver = webdriver.Firefox()
# 访问百度
url = 'http://www.baidu.com'
driver.get(url)
# 浏览器总共等待10秒,在10秒内,每隔0.5秒去使用id的方式定位一下元素,如果定位到,就结束等待,如果定位不到同时没有大于10秒,则继续等待
el = WebDriverWait(driver,10,0.5).until(EC.presence_of_element_located((By.ID,'lg')))
driver.close()
4.隐式等待
隐式等待是根据是件进行等待,等待特定时间
driver.implicitly_wait(n)
n的单位为秒,n为最大值,在这个最大值内只要元素定位到就结束等待
案例:亚马逊
from selenium import webdriver
#创建浏览器
driver = webdriver.Firefox()
url = 'https://www.amazon.cn/'
driver.get(url)
driver.implicitly_wait(20)
driver.close()
8.cookies操作
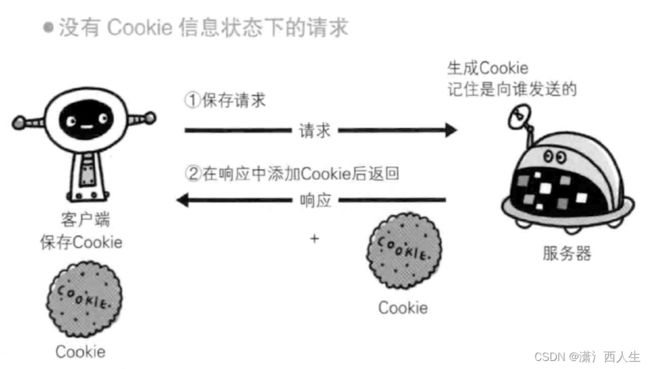
1.什么是cookies
cookie,有时也用其复数形式cookies,指某些网站为了辨别用户身份、进行会话保持而储存在用户本地终端上的数据(通常经过加密)
2.为什么要使用cookies
1.因为HTTP是无状态协议,他不对之前的访问状态做管理,也就是说无法根据之前的登录状态进行本次访问的管理
2.没有状态管理就不能保持登录状态,这样会很麻烦
3.cookies的使用原理
1.浏览器访问某个服务器上的应用
2.服务器返回信息,让浏览器设置一些数据,这些数据也会记录
3.浏览器接收到信息,进行设置
4.浏览器再次访问某个服务器上的web应用,这时候带上设置的cookie
5.服务器接收到信息,获取到cookie,进行比对,确认身份
6.后续正常共同
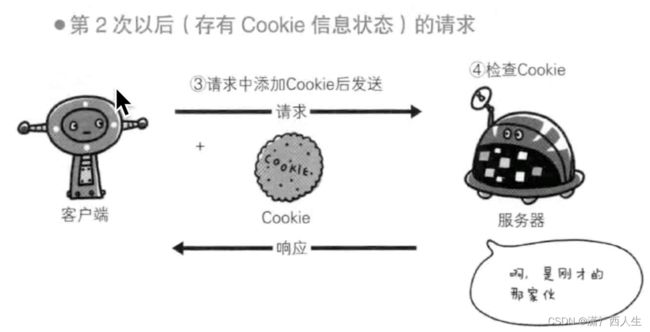
3.selenium对cookies的操作
get_cookies() 获取所有cookies get_cookie(key) 获取key对应的值 add_cookie(cookie_dict) 设置cookies delete_cookie(name) 删除指定名称的cookie delete_all_cookies() 删除所有cookie
案例:有道
from selenium import webdriver
# 创建浏览器
driver = webdriver.Firefox()
# 访问有道
url = 'http://www.youdao.com/'
driver.get(url)
# 获取cookies,直接调用,不需要参数
data = driver.get_cookies()
print(data)
# 删除所有cookies
driver.delete_all_cookies()
# 设置cookies
cookie = {"name":"itcast","value":"soft_test"}
driver.add_cookie(cookie)
# 获取
data1 = driver.get_cookies()
print(data1)
5.Selenium API简单封装
学到这里,我们发现selenium的api有很多,我们如果全部记忆太过复杂,很多时候我们可以把常用的操作进行简单封装。
1.什么是函数封装?
函数封装是一种函数的功能,它把一个程序员写的一个或者多个功能通过函数、类的方式封装起来,对外只提供一个简单的函数接口。
2.对selenium的常用操作进行封装
1)封装开启关闭浏览器
2)封装定位操作
3)封装对元素的基本操作
案例1:封装开启关闭浏览器
from selenium import webdriver
import time
class Common(object):
# 初始化
def __init__(self):
# 创建浏览器
self.driver = webdriver.Firefox()
# 浏览器最大化
self.driver.maximize_window()
# 访问指定url
def open_url(self, url):
self.driver.get(url)
self.driver.implicitly_wait(10)
def close_driver(self):
self.driver.quit()
# 结束的时候清理了
def __del__(self):
time.sleep(3)
self.driver.quit()
if __name__ == '__main__':
com = Common()
com.open_url('http://www.baidu.com')
com.open_url('http://www.hao123.com')
com.close_driver()
案例2:封装定位操作 封装对元素的基本操作
from selenium import webdriver
import time
class Commonshare(object):
# 初始化方法
def __init__(self):
# 创建浏览器对象
self.driver = webdriver.Firefox()
# 设置隐式等待
self.driver.implicitly_wait(5)
# 设置浏览器的最大化
self.driver.maximize_window()
def open_url(self,url):
# 请求指定站点
self.driver.get(url)
time.sleep(3)
def locateElement(self, locate_type, value):
# 判断定位方式并调用相关方法
el = None
if locate_type == 'id':
el = self.driver.find_element_by_id(value)
elif locate_type == 'name':
el = self.driver.find_element_by_name(value)
elif locate_type == 'class':
el = self.driver.find_element_by_class_name(value)
elif locate_type == 'text':
el = self.driver.find_element_by_link_text(value)
elif locate_type == 'xpath':
el = self.driver.find_element_by_xpath(value)
elif locate_type == 'css':
el = self.driver.find_element_by_css_selector(value)
# 如果el不为None,则返回
if el is not None:
return el
# 指定对某一元素的点击操作
def click(self, locate_type, value):
# 调用定位方法进行元素定位
el = self.locateElement(locate_type,value)
# 执行点击操作
el.click()
time.sleep(1)
# 对指定的元素进行数据输入
def input_data(self,locate_type,value,data):
# 调用定位方法进行元素定位
el = self.locateElement(locate_type,value)
# 执行输入操作
el.send_keys(data)
# 获取指定元素的文本内容
def get_text(self, locate_type, value):
# 调用定位方法进行元素定位
el = self.locateElement(locate_type, value)
return el.text
# 获取指定元素的属性值
def get_attr(self, locate_type, value, data):
# 调用定位方法进行元素定位
el = self.locateElement(locate_type, value)
return el.get_attribute(data)
# 收尾清理方法
def __del__(self):
time.sleep(3)
self.driver.quit()
if __name__ == '__main__':
pass
四、unittest模块
1 unittest基本概念
1.什么是是unittest框架?
Unittest单元测试框架是专门用来进行测试的框架
2.主要概念:
test fixture: 代表了用例执行前的准备工作和用例执行之后的清理工作。
test case: 测试用例,这个相信大家都不陌生。是测试的最小单位,一般检查一组输入的响应(输出)是否符合预期。unittest模块提供了TestCase类来帮助我们创建测试用例;
test suite: 经常被翻译成”测试套件”,也有人称为”测试套”,是测试用例或测试套件的集合,一般用来把需要一起执行的用例组合到一起;
test runner: 用来执行测试用例并输出测试结果的组件。可以是图形界面或命令行界面;
# 导入unittest模块
import unittest
# 继承TestCase类,TestCase类是测试用例类
class Test1(unittest.TestCase):
def setUp(self):
print('hello')
def tearDown(self):
print('bye')
def test_001(self):
print('001')
def test_002(self):
print('002')
def test_003(self):
print('003')
# class Test2(unittest.TestCase):
#
# def test_001(self):
# print('201')
#
# def test_002(self):
# print('202')
if __name__ == '__main__':
# unittest.main()
# 创建测试套件
suit = unittest.TestSuite()
# 定义一个测试用例列表
case_list= ['test_001','test_002','test_003']
for case in case_list:
suit.addTest(Test1(case))
# 运行测试用例,verbosity=2为每一个测试用例输出报告,run的参数是测试套件
unittest.TextTestRunner(verbosity=2).run(suit)
# 1.unittest.main()运行时,框架自动寻找TestCase子类,并且运行
# 2.在TestCase类中,只把以test开头的方法当做测试用例,然后执行
# 3.setUp()用于初始化一些参数,在测试用例执行前自动被调用,tearDown()用于清理,在测试用例执行后被调用
2 unittest基本用法
1.通过继承unittest.TestCase进行编写,继承unittest.TestCase的类会被框架识别为测试用例。
2.setUp和TearDown是用于事前和事后做相关处理动作的,就是前面说的Test Fixture,会在每个测试用例运行前后被框架自动调用
3.所有以test开头的方法会被框架自动识别为测试用例,并自动调用执行,不是以test开头的不会被调用
4.unittest.main()是最简单的测试执行方式
5.调用unittest.main()方法后,继承自unittest.TestCase类的类会被自动识别为测试用例并且被调用。
3 unittest断言
断言是测试用例的核心。我们使用assertEqual()来判断预期结果,用assertTrue()和assertFalse来做是非判断。
案例
断言测试
import unittest
class Test(unittest.TestCase):
def setUp(self):
print('start')
def tearDown(self):
print('bye')
def test_001(self):
self.assertEqual('1','1')
def test_002(self):
self.assertEqual('1','0')
if __name__ == '__main__':
unittest.main()
4 unittest命令行接口
unittest支持命令行接口,我们可以在命令行里指定运行具体的测试用例。
python -m unittest test.Tese1
5 unittest与selenium
前面我们简单学习了unittest的用法,接下来我们将unittest与selenium融合在一起进行web自动化测试
1.Commonlib目录存放通用模块(我们封装的selenium模块)
2.创建Business目录 ,根据业务创建测试功能模块
# 导入selenium封装类
from Commonlib.Commonlib import Commonshare
class Login(Commonshare):
def login(self,user,pwd):
self.open_url('http://www.yhd.com/')
self.click('class','hd_login_link')
self.input_data('id','un',user)
self.input_data('id','pwd',pwd)
self.click('id','login_button')
if __name__ == '__main__':
log = Login()
log.login('hack_ai_buster','1qaz2wsx#EDC')
3.创建Testcase目录存放测试用例
from Business.Login import Login
import unittest
class Test(unittest.TestCase):
def setUp(self):
print('hello')
def tearDown(self):
print('bye')
# 定义正确登陆的测试用例
def test_001(self):
log = Login()
# 用账号密码登录
log.login('hack_ai_buster','1qaz2wsx#EDC')
# 获取登录之后的用户名
data = log.get_text('class','hd_login_name')
# 断言,判断登录后的用户名是否和预期用户名相同
self.assertEqual('hack_ai_buster',data)
# 账号密码都不输入,直接登录
def test_002(self):
log = Login()
# 用账号密码登录
log.login('', '')
# 获取登录之后的用户名
data = log.get_text('id','error_tips')
# 断言,判断登录后的用户名是否和预期用户名相同
self.assertEqual('请输入账号和密码',data)
# 只输入账号不输入密码,直接登录
def test_003(self):
log = Login()
# 用账号密码登录
log.login('sdfsdadfa', '')
# 获取登录之后的用户名
data = log.get_text('id', 'error_tips')
# 断言,判断登录后的用户名是否和预期用户名相同
self.assertEqual('请输入密码', data)
# 只输入账号不输入密码,直接登录
def test_004(self):
log = Login()
# 用账号密码登录
log.login('sdfsdadfa', '')
# 获取登录之后的用户名
data = log.get_text('id', 'error_tips')
# 断言,判断登录后的用户名是否和预期用户名相同
self.assertEqual('请输入密码itcast', data)
if __name__ == '__main__':
unittest.main()
import unittest
from Testcase.testcase import Test
# 导入HtmlTextRunner,用于生成html的测试报告
from Commonlib.HTMLTestRunner import HTMLTestRunner
class SuitTest(unittest.TestCase):
def test_suit(self):
case_list = ['test_001','test_002','test_003','test_004']
# 创建测试套件
mysuit = unittest.TestSuite()
# 循环将测试用例放到测试套件中
for case in case_list:
mysuit.addTest(Test(case))
# 创建测试运行器,设置为每一个测试用例生成测试报告,运行测试套件中的测试用例
# unittest.TextTestRunner(verbosity=2).run(mysuit)
# 生成html测试报告
with open('report.html','wb')as f:
HTMLTestRunner(
stream=f, # 相当于f.write(报告)
title='第一个测试报告',
description='it黑马第一个测试报告',
verbosity=2 # 为每个测试用例生成测试报告
).run(mysuit)
if __name__ == '__main__':
unittest.main()